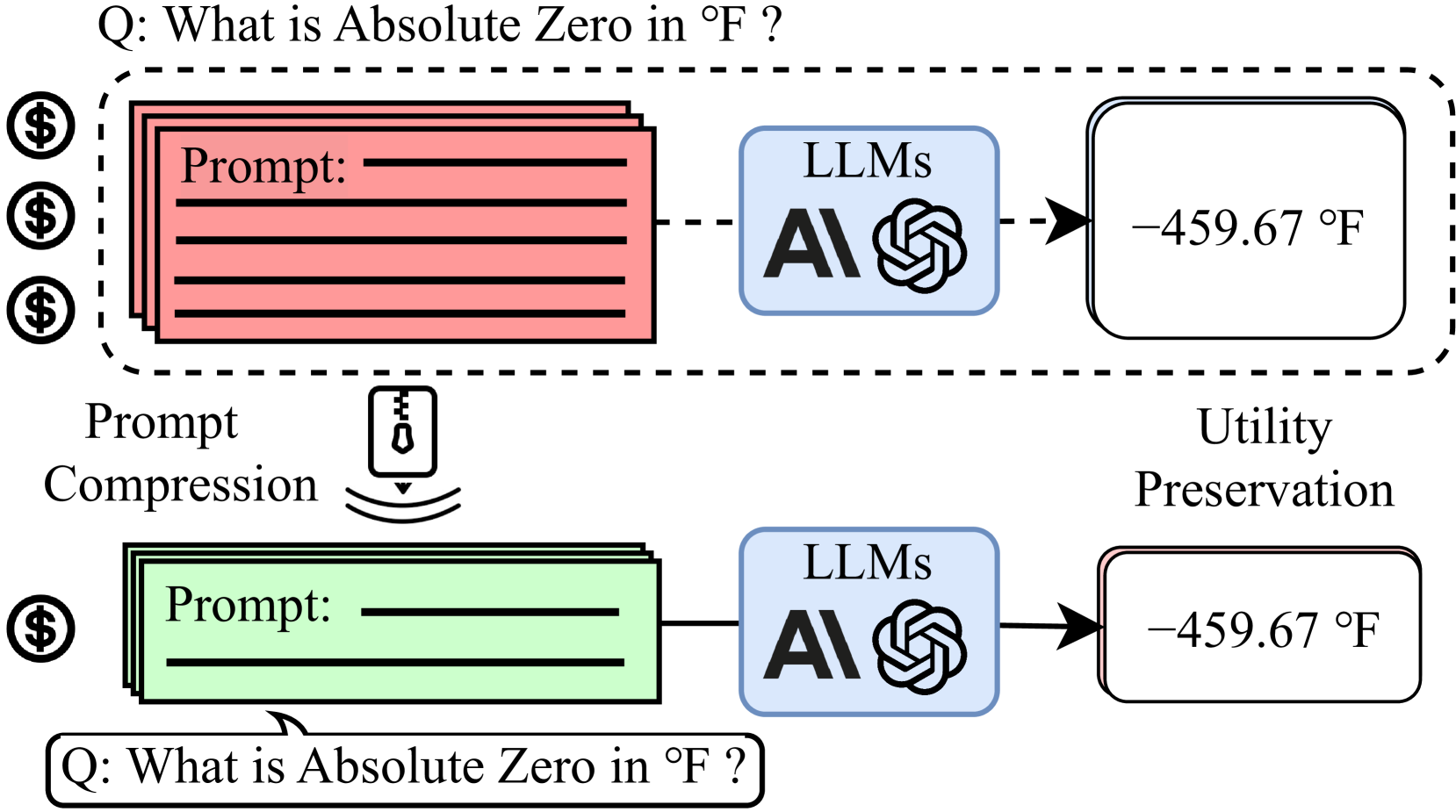
LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models
Huiqiang Jiang, Qianhui Wu, Chin-Yew Lin, Yuqing Yang, Lili Qiu |
 |
Github
Paper |
LongLLMLingua: Accelerating and Enhancing LLMs in Long Context Scenarios via Prompt Compression
Huiqiang Jiang, Qianhui Wu, Xufang Luo, Dongsheng Li, Chin-Yew Lin, Yuqing Yang, Lili Qiu |
 |
Github
Paper |

EntropyRank: Unsupervised Keyphrase Extraction via Side-Information Optimization for Language Model-based Text Compression
Alexander Tsvetkov. Alon Kipnis |
 |
Paper |
LLMZip: Lossless Text Compression using Large Language Models
Chandra Shekhara Kaushik Valmeekam, Krishna Narayanan, Dileep Kalathil, Jean-Francois Chamberland, Srinivas Shakkottai |
 |
Paper | Unofficial Github |

Adapting Language Models to Compress Contexts
Alexis Chevalier, Alexander Wettig, Anirudh Ajith, Danqi Chen |
 |
Github
Paper |
In-context Autoencoder for Context Compression in a Large Language Model
Tao Ge, Jing Hu, Xun Wang, Si-Qing Chen, Furu Wei |
 |
Paper |
Nugget 2D: Dynamic Contextual Compression for Scaling Decoder-only Language Model
Guanghui Qin, Corby Rosset, Ethan C. Chau, Nikhil Rao, Benjamin Van Durme |
 |
Paper |
Boosting LLM Reasoning: Push the Limits of Few-shot Learning with Reinforced In-Context Pruning
Xijie Huang, Li Lyna Zhang, Kwang-Ting Cheng, Mao Yang |
 |
Paper |
ProPD: Dynamic Token Tree Pruning and Generation for LLM Parallel Decoding
Shuzhang Zhong, Zebin Yang, Meng Li, Ruihao Gong, Runsheng Wang, Ru Huang |
 |
Paper |
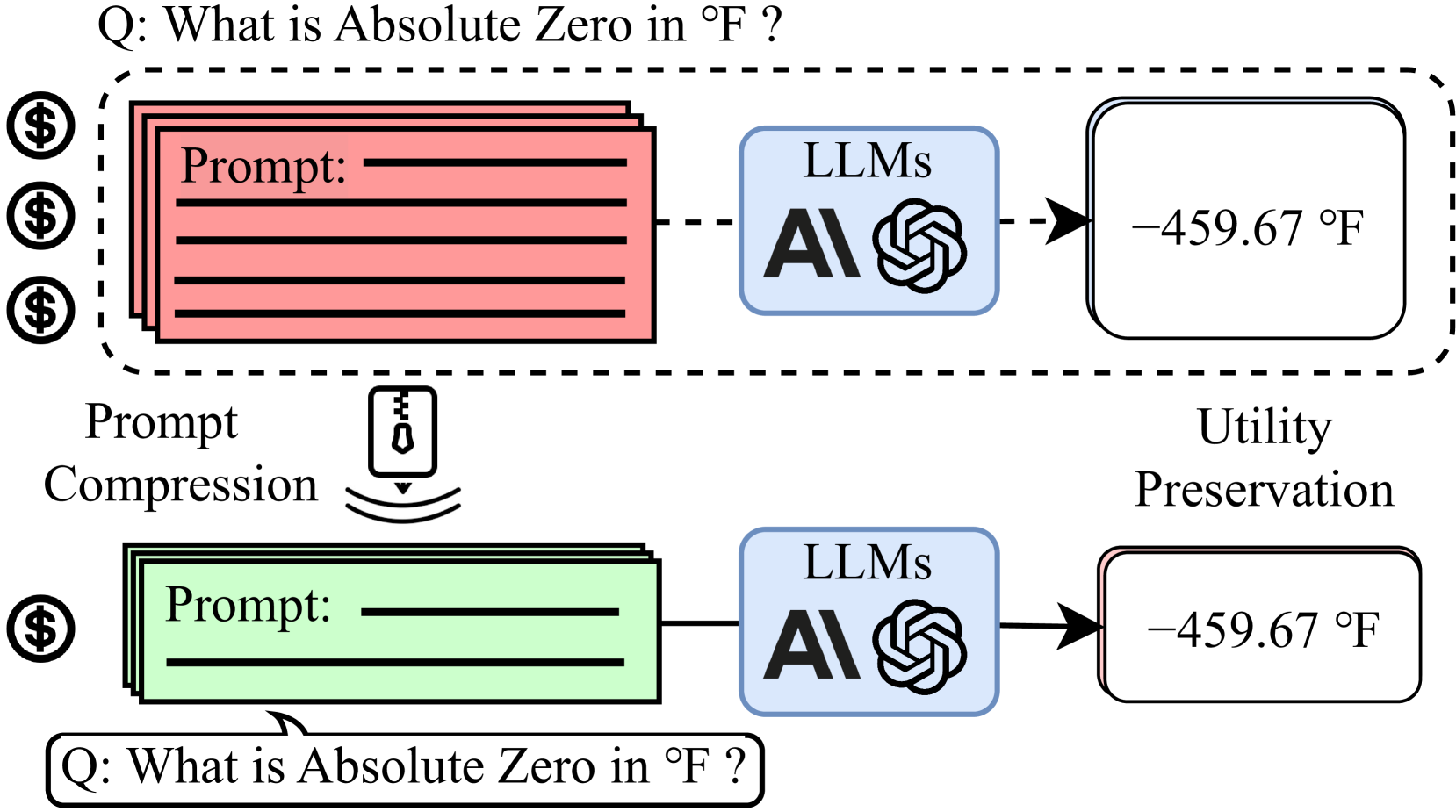
Learning to Compress Prompt in Natural Language Formats
Yu-Neng Chuang, Tianwei Xing, Chia-Yuan Chang, Zirui Liu, Xun Chen, Xia Hu |
 |
Paper |
LLMLingua-2: Data Distillation for Efficient and Faithful Task-Agnostic Prompt Compression
Zhuoshi Pan, Qianhui Wu, Huiqiang Jiang, Menglin Xia, Xufang Luo, Jue Zhang, Qingwei Lin et al |
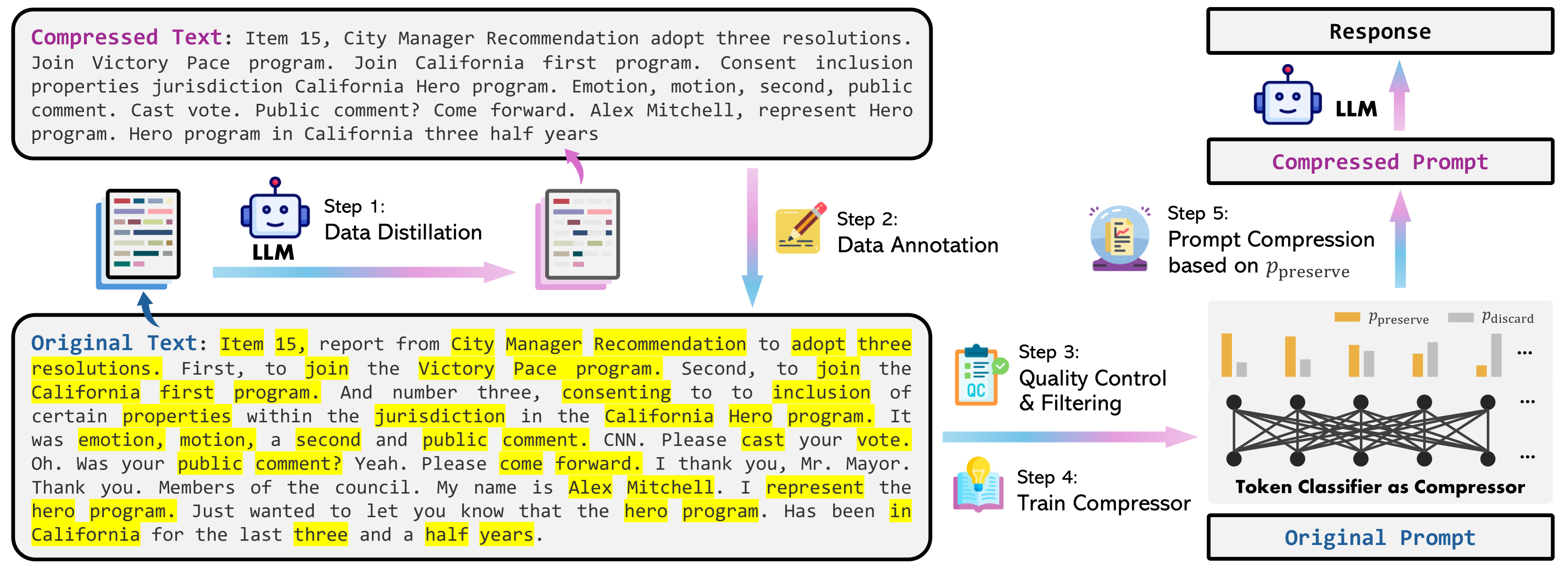 |
Paper |

PCToolkit: A Unified Plug-and-Play Prompt Compression Toolkit of Large Language Models
Jinyi Li, Yihuai Lan, Lei Wang, Hao Wang |
 |
Github
Paper |
PROMPT-SAW: Leveraging Relation-Aware Graphs for Textual Prompt Compression
Muhammad Asif Ali, Zhengping Li, Shu Yang, Keyuan Cheng, Yang Cao, Tianhao Huang, Lijie Hu, Lu Yu, Di Wang |
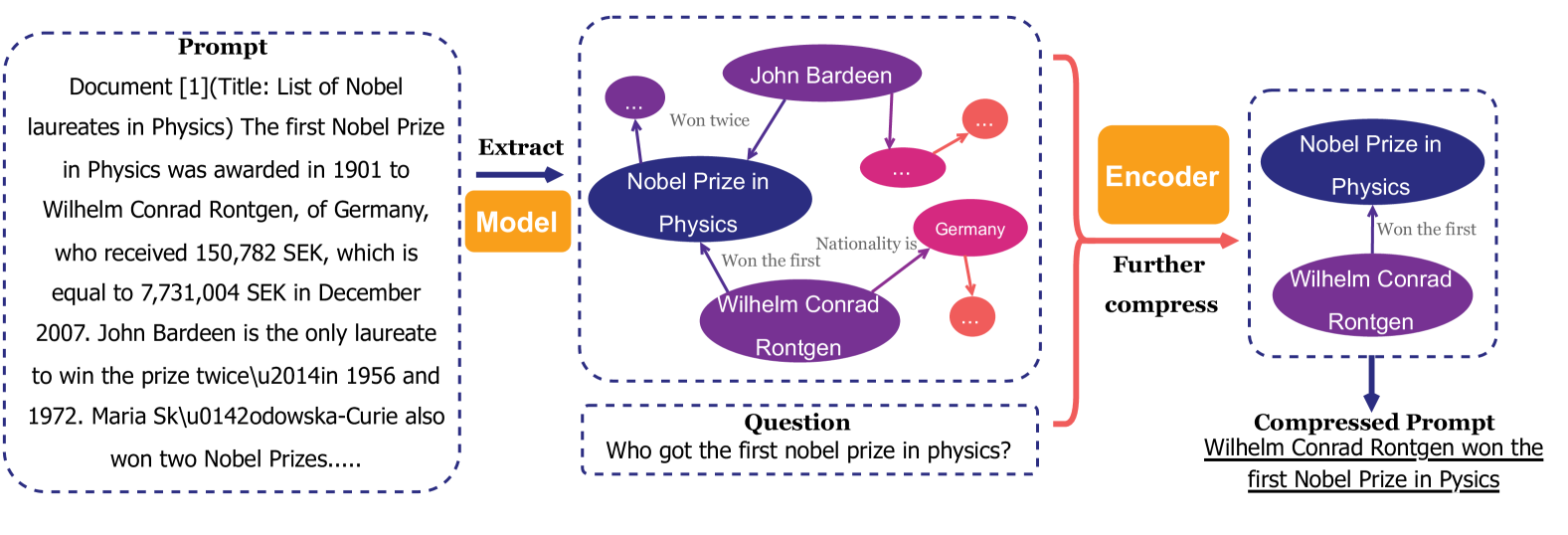 |
Paper |
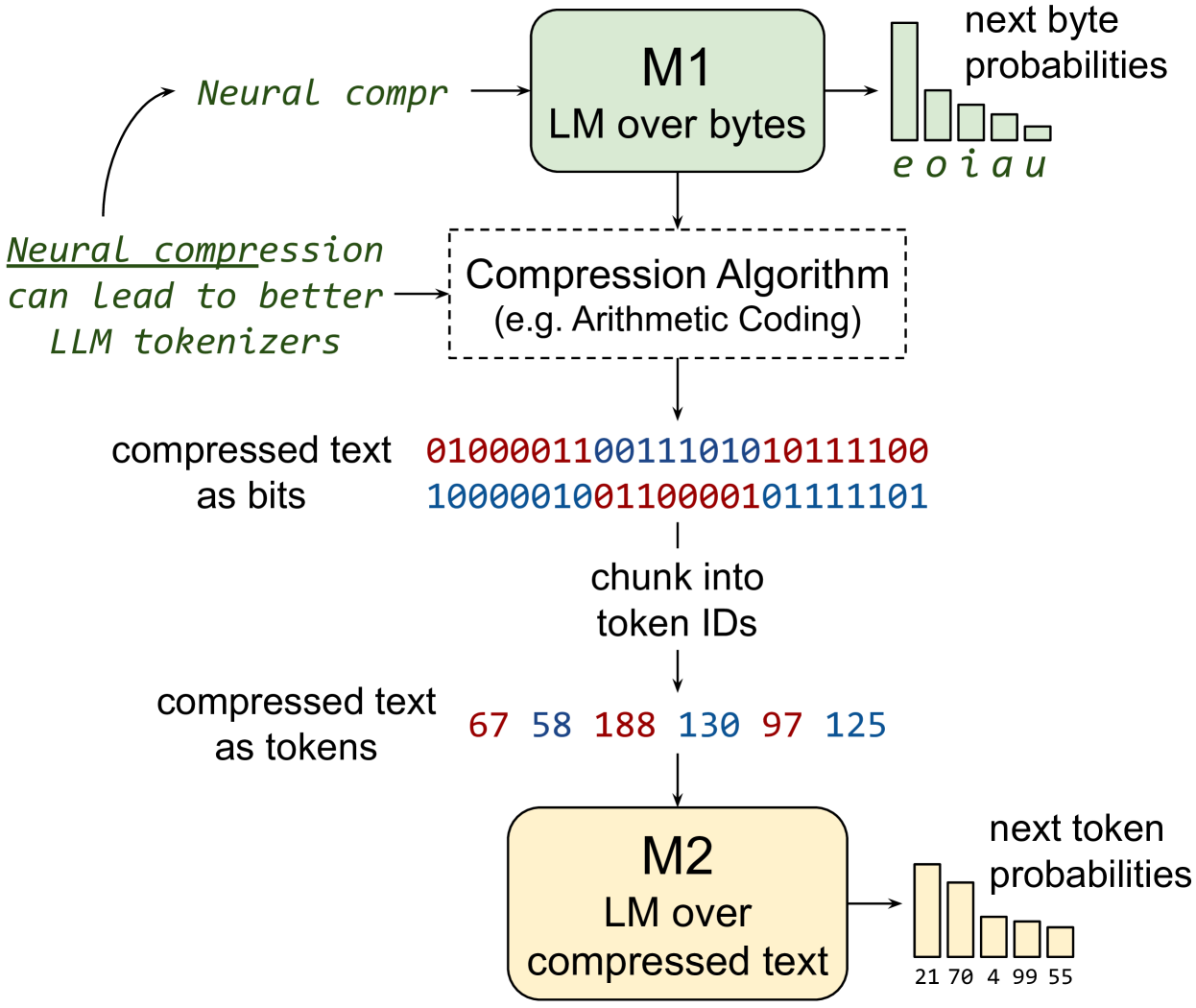
Training LLMs over Neurally Compressed Text
Brian Lester, Jaehoon Lee, Alex Alemi, Jeffrey Pennington, Adam Roberts, Jascha Sohl-Dickstein, Noah Constant |
 |
Paper |

Adapting LLMs for Efficient Context Processing through Soft Prompt Compression
Cangqing Wang, Yutian Yang, Ruisi Li, Dan Sun, Ruicong Cai, Yuzhu Zhang, Chengqian Fu, Lillian Floyd |
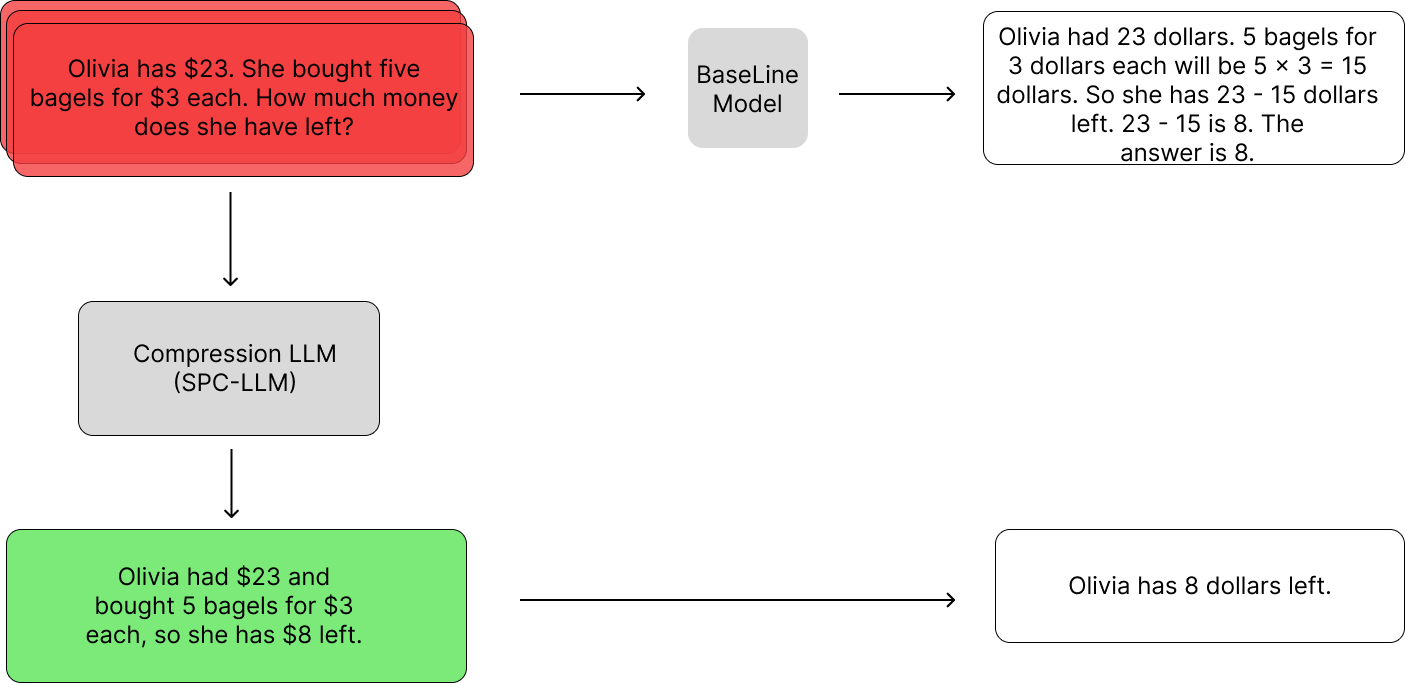 |
Paper |

Rethinking LLM Memorization through the Lens of Adversarial Compression
Avi Schwarzschild, Zhili Feng, Pratyush Maini, Zachary C. Lipton, J. Zico Kolter |
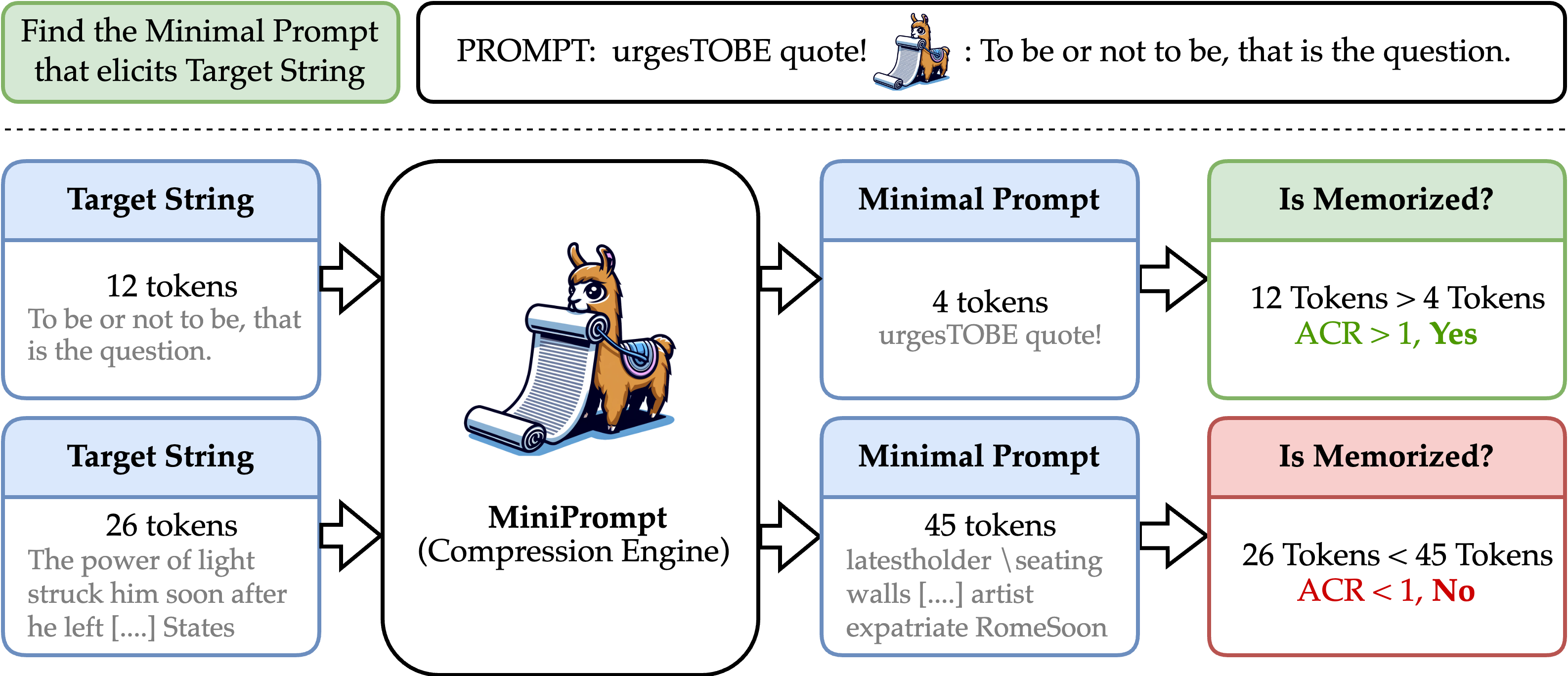 |
Github
Paper
Project |
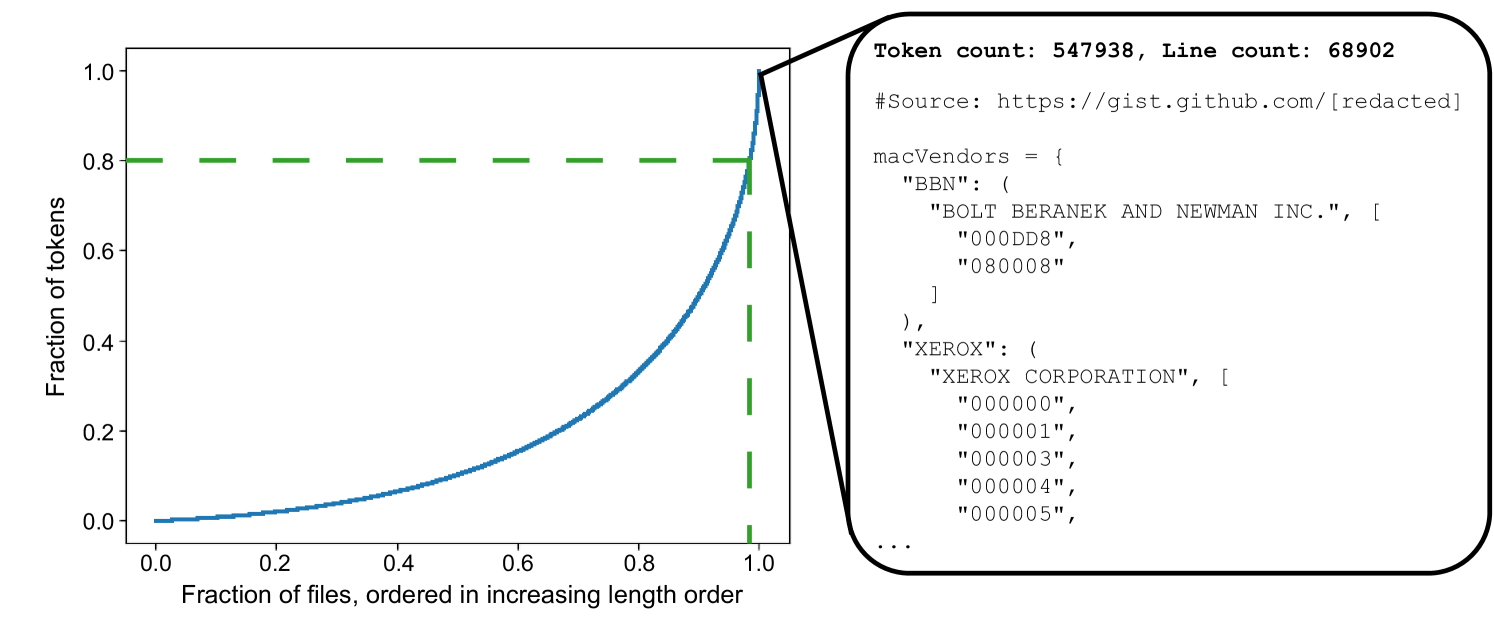
Brevity is the soul of wit: Pruning long files for code generation
Aaditya K. Singh, Yu Yang, Kushal Tirumala, Mostafa Elhoushi, Ari S. Morcos |
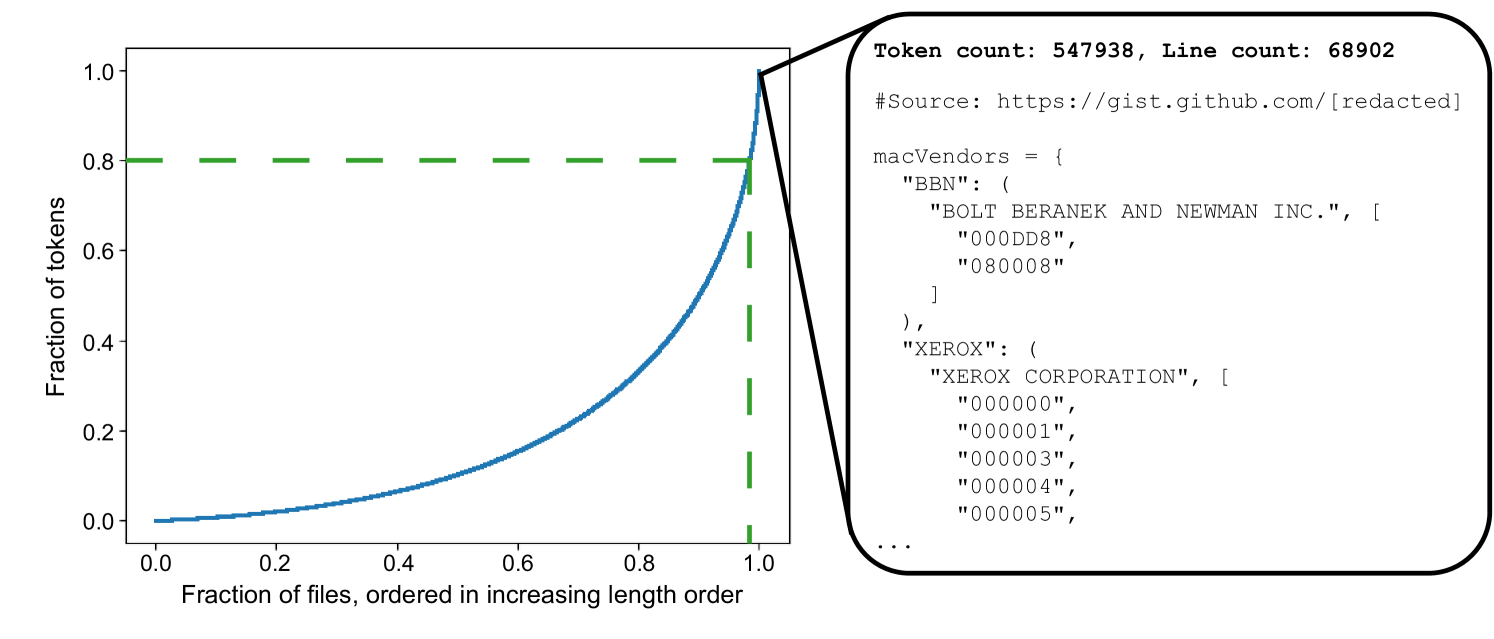 |
Paper |
PromptIntern: Saving Inference Costs by Internalizing Recurrent Prompt during Large Language Model Fine-tuning
Jiaru Zou, Mengyu Zhou, Tao Li, Shi Han, Dongmei Zhang |
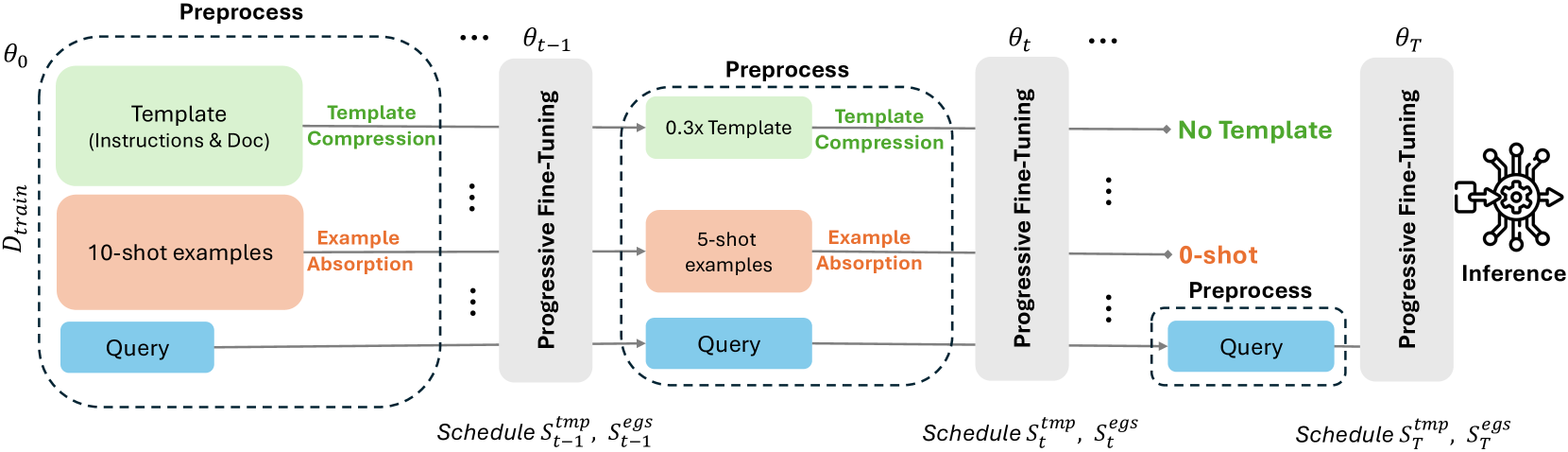 |
Paper |
Entropy Law: The Story Behind Data Compression and LLM Performance
Mingjia Yin, Chuhan Wu, Yufei Wang, Hao Wang, Wei Guo, Yasheng Wang, Yong Liu, Ruiming Tang, Defu Lian, Enhong Chen |
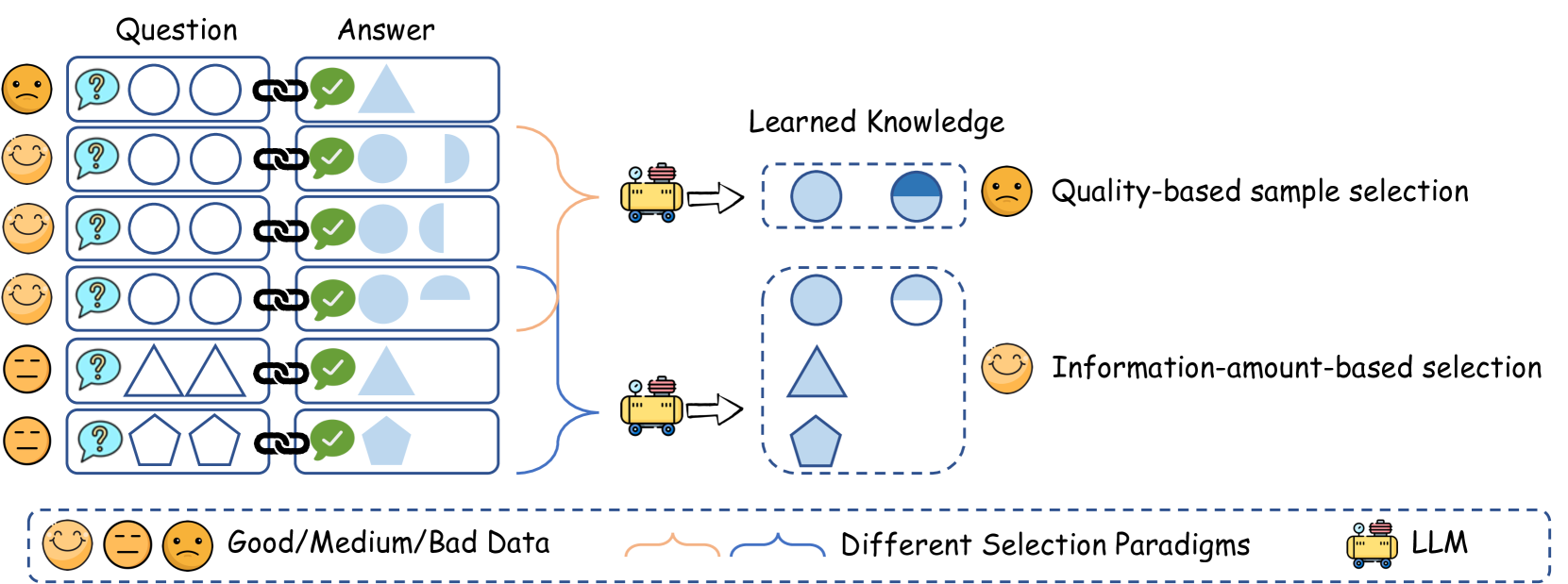 |
Paper |

Characterizing Prompt Compression Methods for Long Context Inference
Siddharth Jha, Lutfi Eren Erdogan, Sehoon Kim, Kurt Keutzer, Amir Gholami |
 |
Paper |

QUITO: Accelerating Long-Context Reasoning through Query-Guided Context Compression
Wenshan Wang, Yihang Wang, Yixing Fan, Huaming Liao, Jiafeng Guo |
 |
Github
Paper |

500xCompressor: Generalized Prompt Compression for Large Language Models
Zongqian Li, Yixuan Su, Nigel Collier |
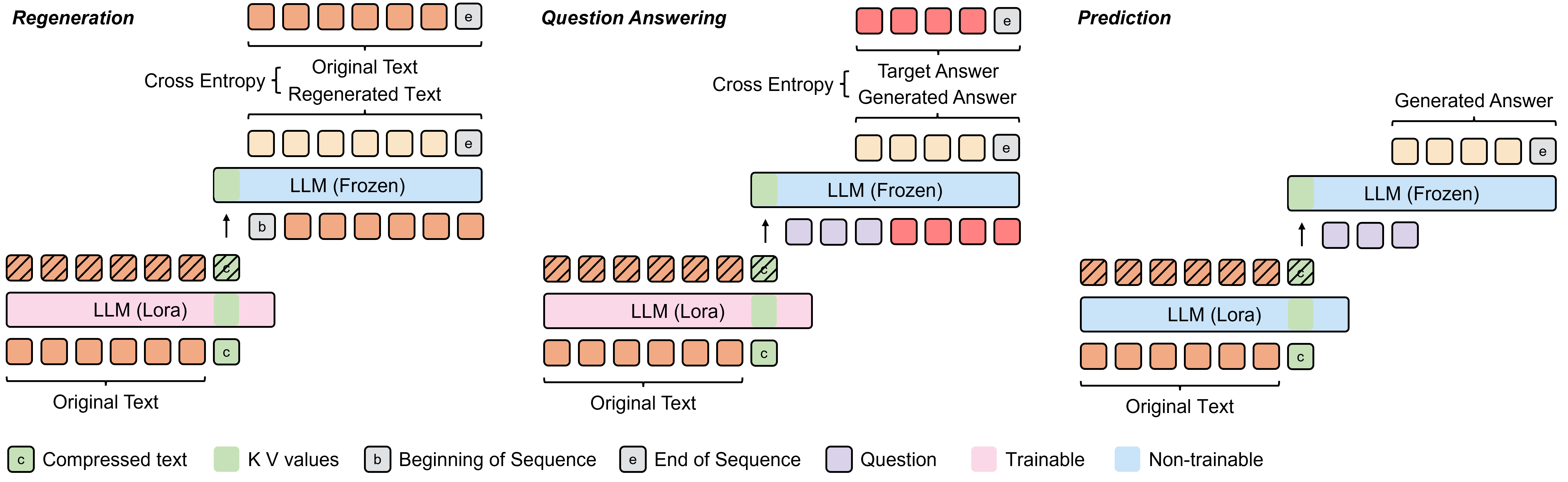 |
Github
Paper |

Enhancing and Accelerating Large Language Models via Instruction-Aware Contextual Compression
Haowen Hou, Fei Ma, Binwen Bai, Xinxin Zhu, Fei Yu |
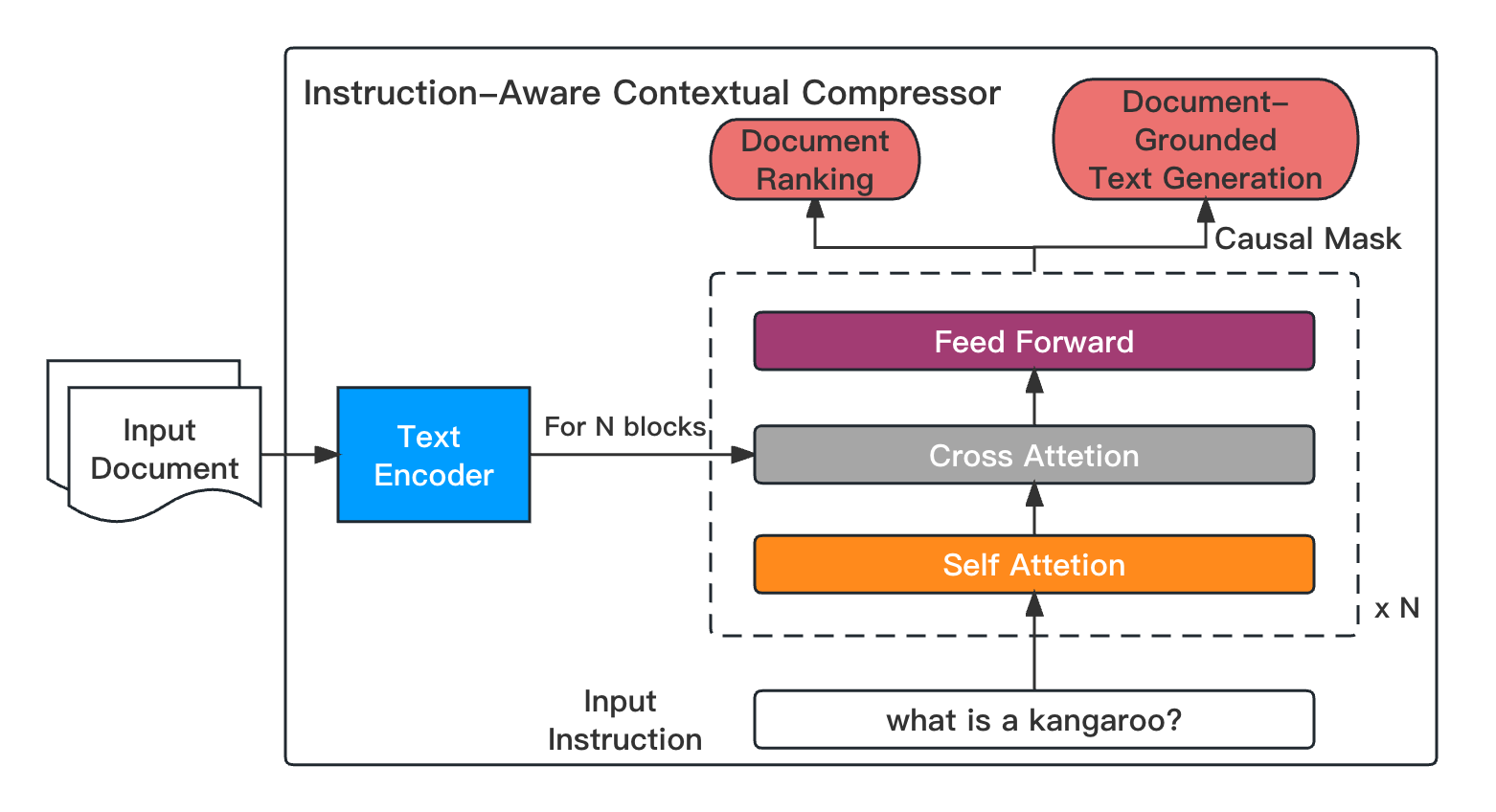 |
Github
Paper |
Efficient LLM Context Distillation
Rajesh Upadhayayaya, Zachary Smith, Chritopher Kottmyer, Manish Raj Osti |
|
Paper |
TACO-RL: Task Aware Prompt Compression Optimization with Reinforcement Learning
Shivam Shandilya, Menglin Xia, Supriyo Ghosh, Huiqiang Jiang, Jue Zhang, Qianhui Wu, Victor Rühle |
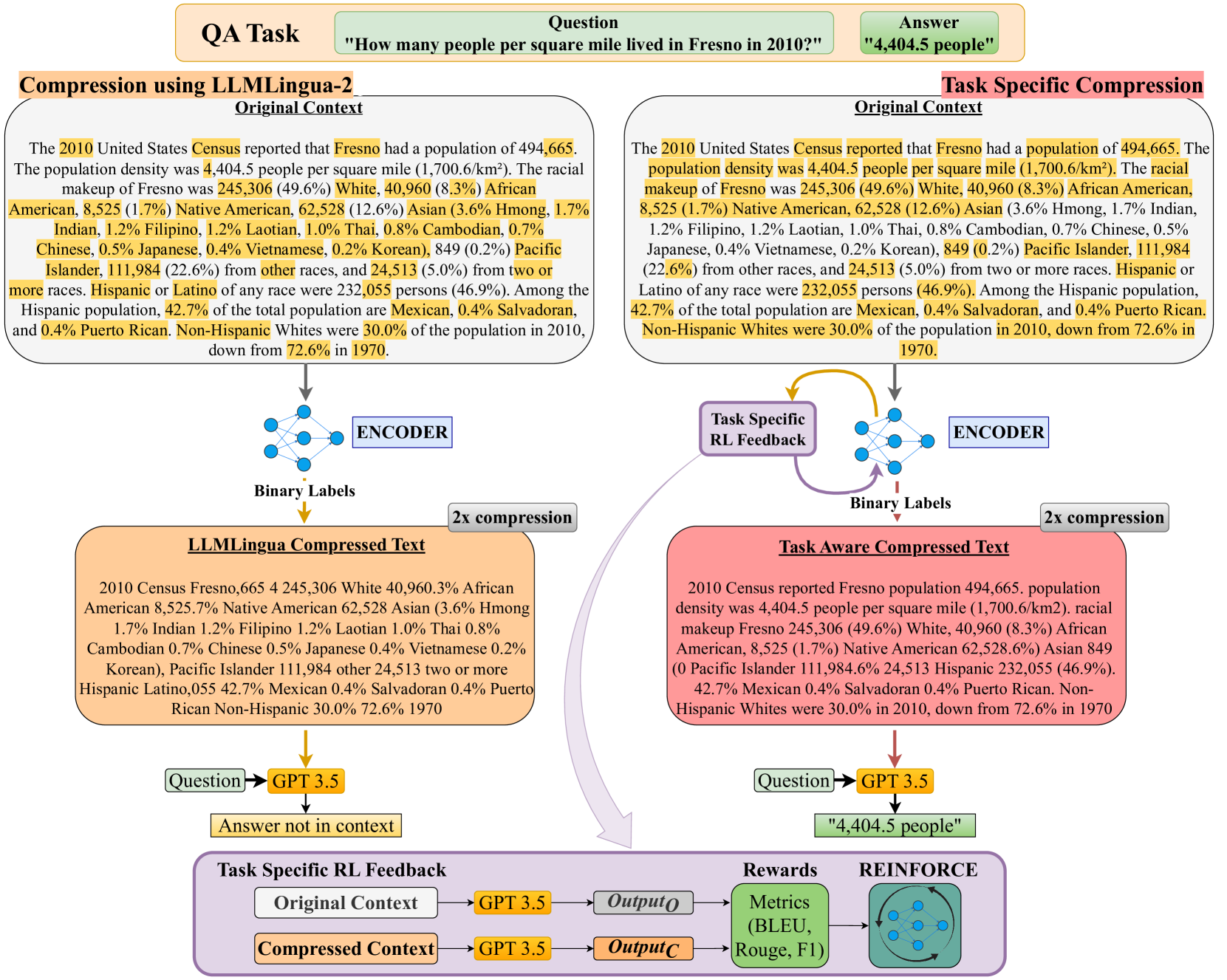 |
Paper |

AlphaZip: Neural Network-Enhanced Lossless Text Compression
Swathi Shree Narashiman, Nitin Chandrachoodan |
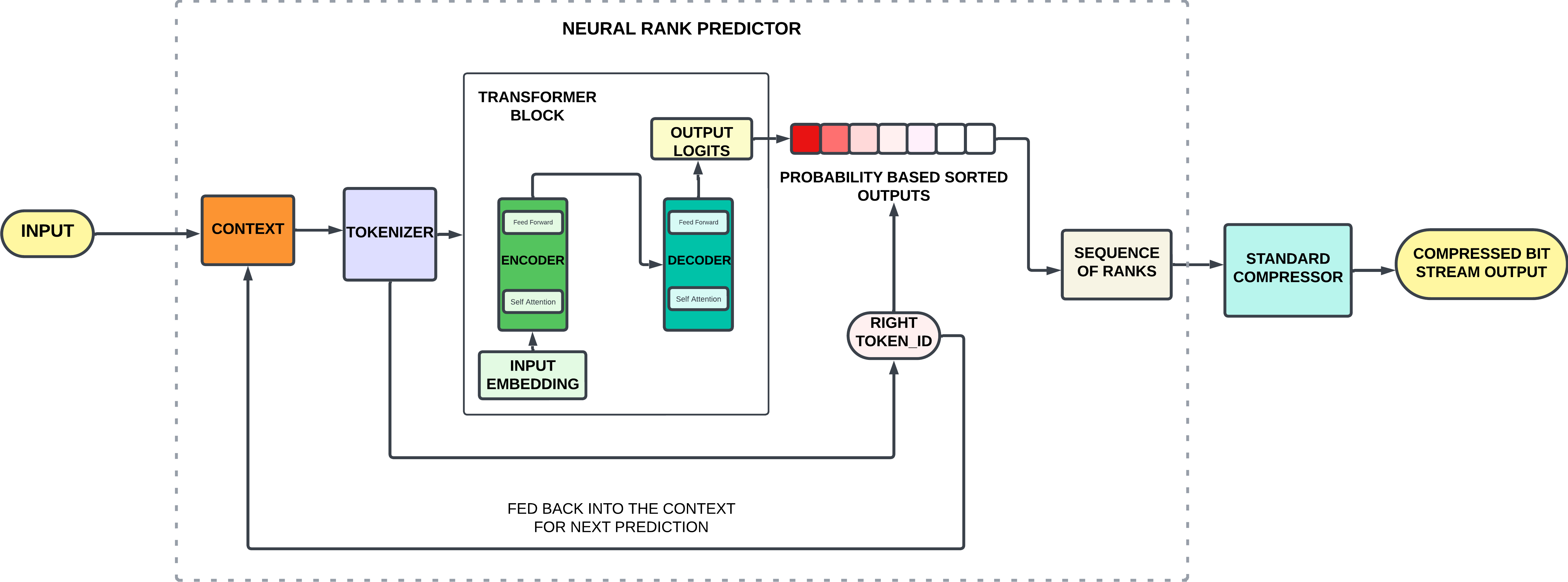 |
Github
Paper |

Parse Trees Guided LLM Prompt Compression
Wenhao Mao, Chengbin Hou, Tianyu Zhang, Xinyu Lin, Ke Tang, Hairong Lv |
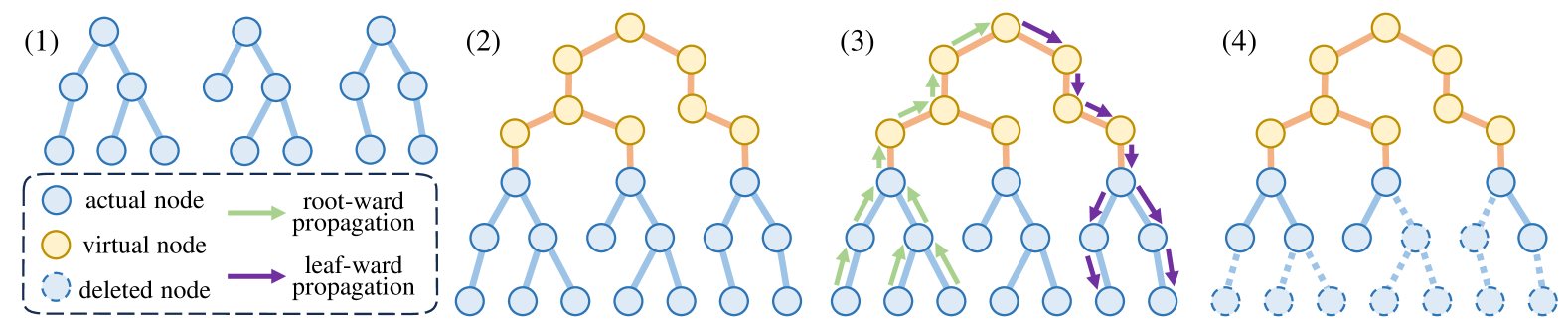 |
Github
Paper |

FineZip : Pushing the Limits of Large Language Models for Practical Lossless Text Compression
Fazal Mittu, Yihuan Bu, Akshat Gupta, Ashok Devireddy, Alp Eren Ozdarendeli, Anant Singh, Gopala Anumanchipalli |
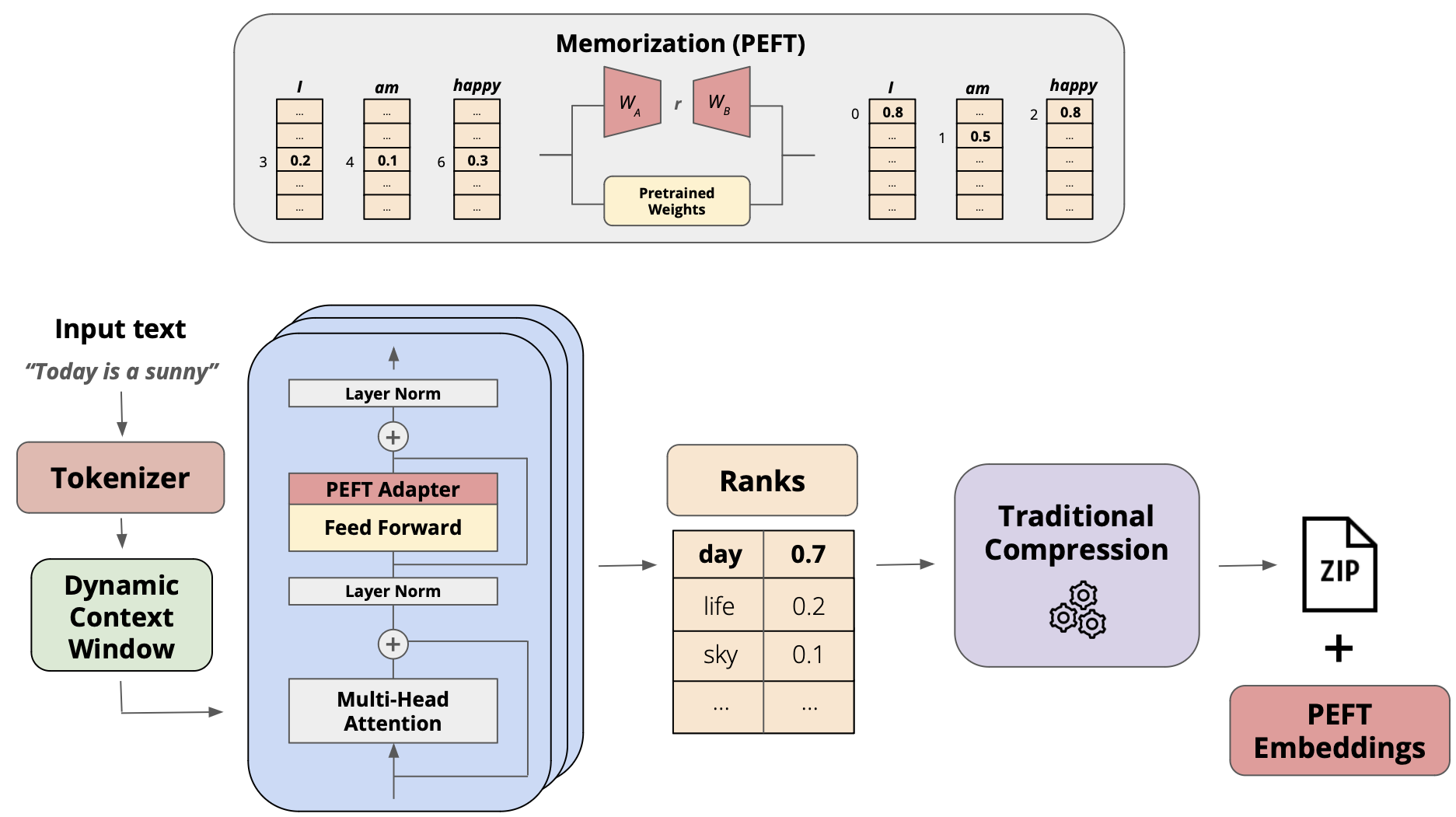 |
Github
Paper |
Perception Compressor:A training-free prompt compression method in long context scenarios
Jiwei Tang, Jin Xu, Tingwei Lu, Hai Lin, Yiming Zhao, Hai-Tao Zheng |
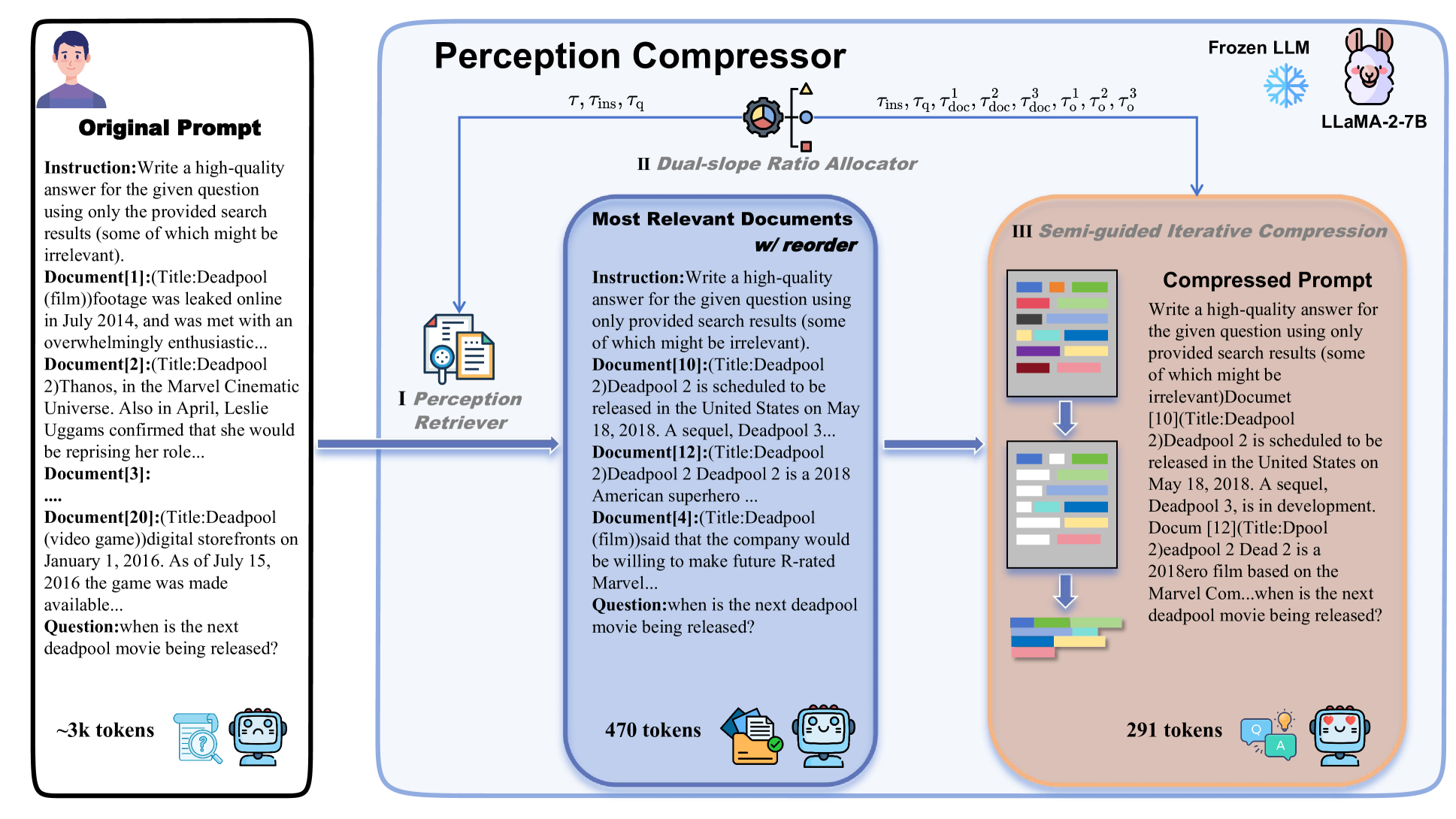 |
Paper |

From Reading to Compressing: Exploring the Multi-document Reader for Prompt Compression
Eunseong Choi, Sunkyung Lee, Minjin Choi, June Park, Jongwuk Lee |
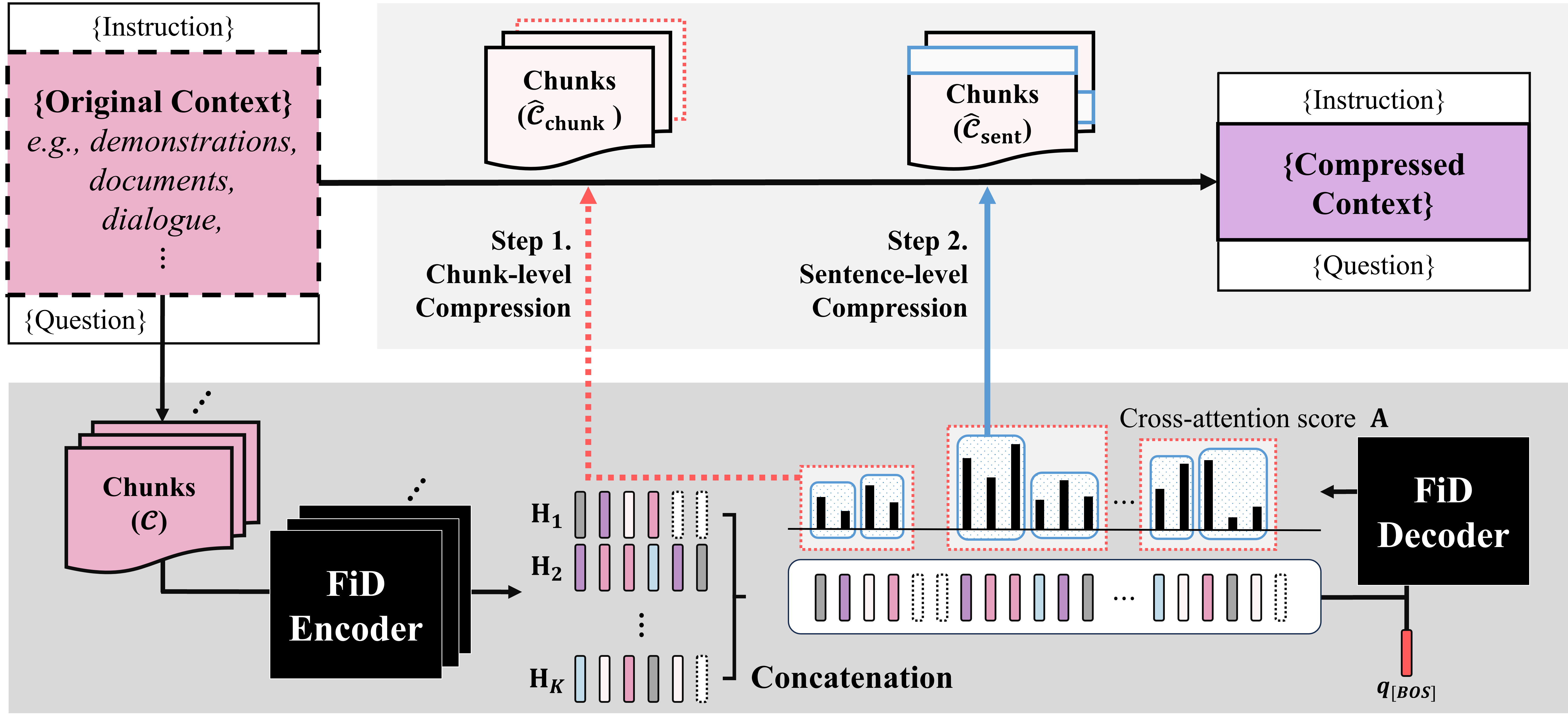 |
Paper |
Selection-p: Self-Supervised Task-Agnostic Prompt Compression for Faithfulness and Transferability
Tsz Ting Chung, Leyang Cui, Lemao Liu, Xinting Huang, Shuming Shi, Dit-Yan Yeung |
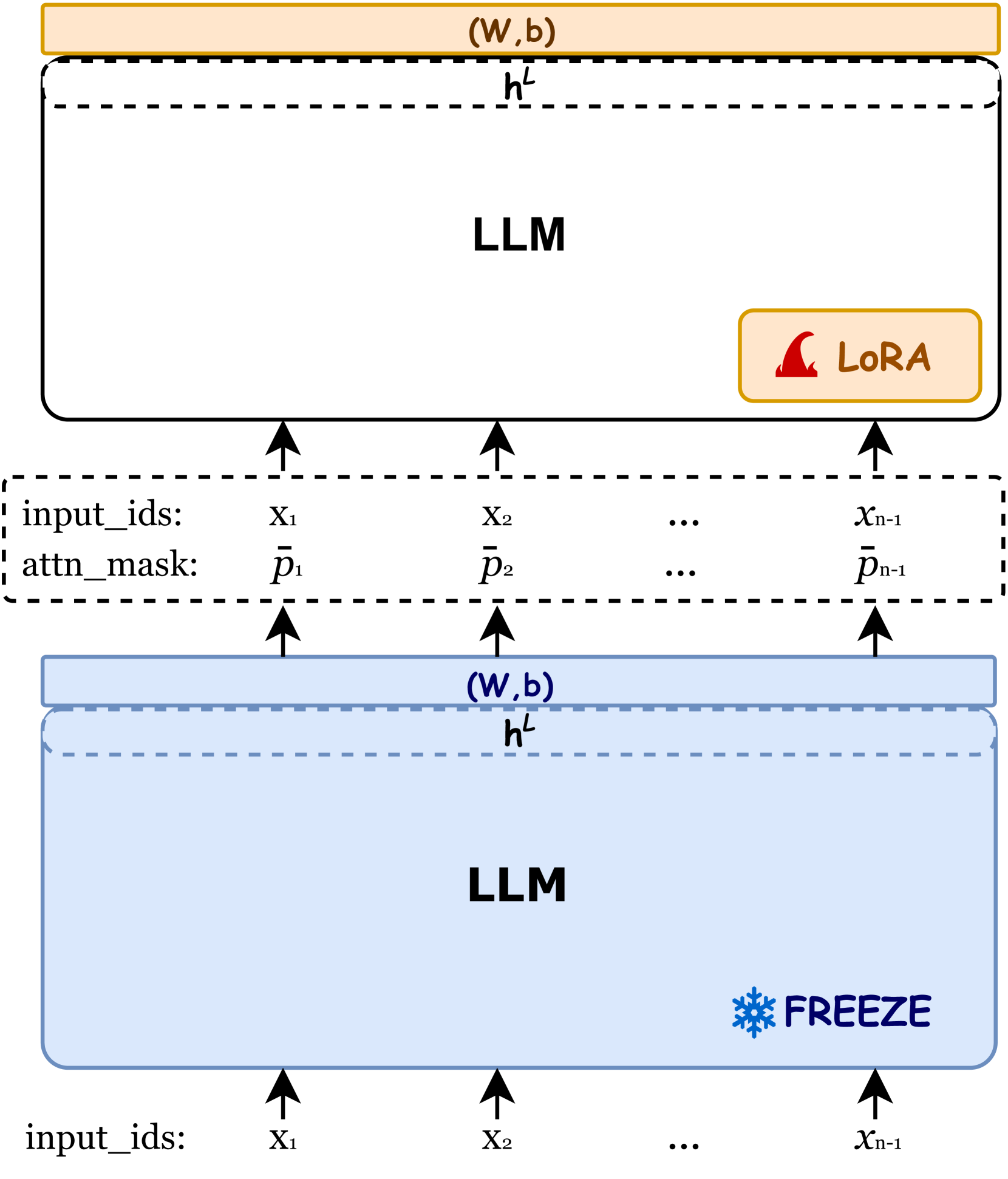 |
Paper |

MultiTok: Variable-Length Tokenization for Efficient LLMs Adapted from LZW Compression
Noel Elias, Homa Esfahanizadeh, Kaan Kale, Sriram Vishwanath, Muriel Medard |
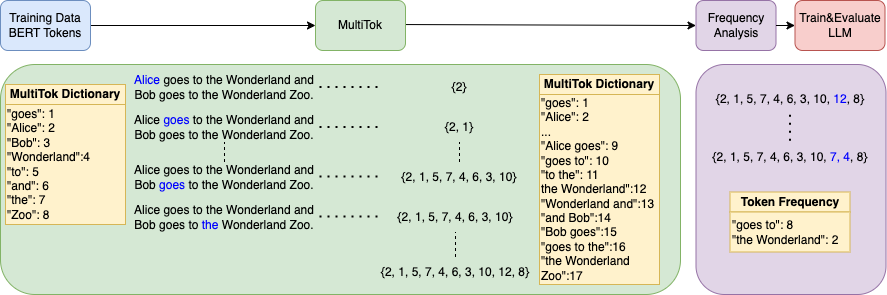 |
Github
Paper |

Generative Context Distillation
Haebin Shin, Lei Ji, Yeyun Gong, Sungdong Kim, Eunbi Choi, Minjoon Seo |
 |
Github
Paper |
JPPO: Joint Power and Prompt Optimization for Accelerated Large Language Model Services
Feiran You, Hongyang Du, Kaibin Huang, Abbas Jamalipour |
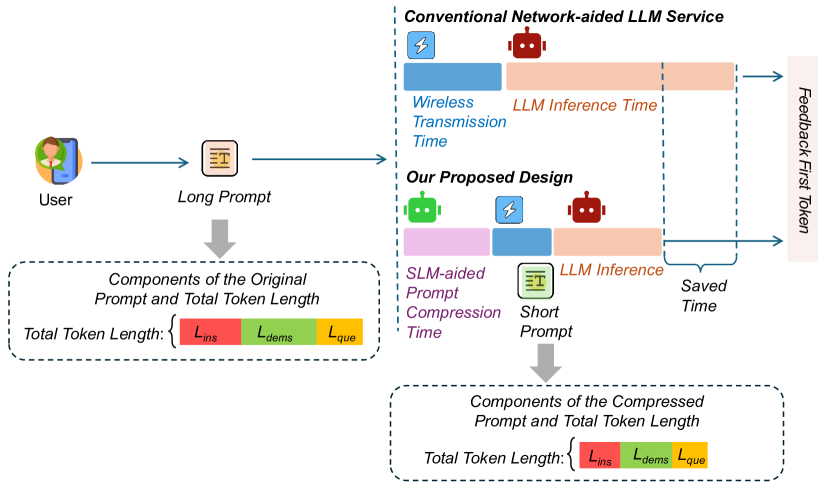 |
Paper |