| Title & Authors | Introduction | Links |
|---|---|---|
 GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers Elias Frantar, Saleh Ashkboos, Torsten Hoefler, Dan Alistarh |
 |
Github Paper |
 SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, Song Han |
 |
Github Paper |
 QLoRA: Efficient Finetuning of Quantized LLMs Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, Luke Zettlemoyer |
 |
Github Paper |
 QuIP: 2-Bit Quantization of Large Language Models With Guarantees Jerry Chee, Yaohui Cai, Volodymyr Kuleshov, Christopher De SaXQ |
 |
Github Paper |
Memory-Efficient Fine-Tuning of Compressed Large Language Models via sub-4-bit Integer Quantization Jeonghoon Kim, Jung Hyun Lee, Sungdong Kim, Joonsuk Park, Kang Min Yoo, Se Jung Kwon, Dongsoo Lee |
 |
Paper |
Quantizable Transformers: Removing Outliers by Helping Attention Heads Do Nothing Yelysei Bondarenko, Markus Nagel, Tijmen Blankevoort |
 |
Github Paper |
 LLM-FP4: 4-Bit Floating-Point Quantized Transformers Shih-yang Liu, Zechun Liu, Xijie Huang, Pingcheng Dong, Kwang-Ting Cheng |
 |
Github Paper |
Enhancing Computation Efficiency in Large Language Models through Weight and Activation Quantization Jangwhan Lee, Minsoo Kim, Seungcheol Baek, Seok Joong Hwang, Wonyong Sung, Jungwook Choi |
 |
Paper |
Agile-Quant: Activation-Guided Quantization for Faster Inference of LLMs on the Edge Xuan Shen, Peiyan Dong, Lei Lu, Zhenglun Kong, Zhengang Li, Ming Lin, Chao Wu, Yanzhi Wang |
 |
Paper |
 OmniQuant: Omnidirectionally Calibrated Quantization for Large Language Models Wenqi Shao, Mengzhao Chen, Zhaoyang Zhang, Peng Xu, Lirui Zhao, Zhiqian Li, Kaipeng Zhang, Peng Gao, Yu Qiao, Ping Luo |
 |
Github Paper |
 AffineQuant: Affine Transformation Quantization for Large Language Models Yuexiao Ma, Huixia Li, Xiawu Zheng, Feng Ling, Xuefeng Xiao, Rui Wang, Shilei Wen, Fei Chao, Rongrong Ji |
 |
Github Paper |
GPT-Zip: Deep Compression of Finetuned Large Language Models Berivan Isik, Hermann Kumbong, Wanyi Ning, Xiaozhe Yao, Sanmi Koyejo, Ce Zhang |
 |
Paper |
 Watermarking LLMs with Weight Quantization Linyang Li, Botian Jiang, Pengyu Wang, Ke Ren, Hang Yan, Xipeng Qiu |
 |
Github Paper |
 AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Xingyu Dang, Song Han |
 |
Github Paper |
 RPTQ: Reorder-based Post-training Quantization for Large Language Models Zhihang Yuan and Lin Niu and Jiawei Liu and Wenyu Liu and Xinggang Wang and Yuzhang Shang and Guangyu Sun and Qiang Wu and Jiaxiang Wu and Bingzhe Wu |
 |
Github Paper |
| ZeroQuant-V2: Exploring Post-training Quantization in LLMs from Comprehensive Study to Low Rank Compensation Zhewei Yao, Xiaoxia Wu, Cheng Li, Stephen Youn, Yuxiong He |
 |
Paper |
 SqueezeLLM: Dense-and-Sparse Quantization Sehoon Kim, Coleman Hooper, Amir Gholami, Zhen Dong, Xiuyu Li, Sheng Shen, Michael W. Mahoney, Kurt Keutzer |
 |
Github Paper |
| Outlier Suppression+: Accurate quantization of large language models by equivalent and optimal shifting and scaling Xiuying Wei , Yunchen Zhang, Yuhang Li, Xiangguo Zhang, Ruihao Gong, Jinyang Guo, Xianglong Liu |
 |
Paper |
| Integer or Floating Point? New Outlooks for Low-Bit Quantization on Large Language Models Yijia Zhang, Lingran Zhao, Shijie Cao, Wenqiang Wang, Ting Cao, Fan Yang, Mao Yang, Shanghang Zhang, Ningyi Xu |
 |
Paper |
| LLM-QAT: Data-Free Quantization Aware Training for Large Language Models Zechun Liu, Barlas Oguz, Changsheng Zhao, Ernie Chang, Pierre Stock, Yashar Mehdad, Yangyang Shi, Raghuraman Krishnamoorthi, Vikas Chandra |
 |
Paper |
 SpQR: A Sparse-Quantized Representation for Near-Lossless LLM Weight Compression Tim Dettmers, Ruslan Svirschevski, Vage Egiazarian, Denis Kuznedelev, Elias Frantar, Saleh Ashkboos, Alexander Borzunov, Torsten Hoefler, Dan Alistarh |
 |
Github Paper |
 OWQ: Lessons learned from activation outliers for weight quantization in large language models Changhun Lee, Jungyu Jin, Taesu Kim, Hyungjun Kim, Eunhyeok Park |
 |
Github Paper |
 Do Emergent Abilities Exist in Quantized Large Language Models: An Empirical Study Peiyu Liu, Zikang Liu, Ze-Feng Gao, Dawei Gao, Wayne Xin Zhao, Yaliang Li, Bolin Ding, Ji-Rong Wen |
 |
Github Paper |
| ZeroQuant-FP: A Leap Forward in LLMs Post-Training W4A8 Quantization Using Floating-Point Formats Xiaoxia Wu, Zhewei Yao, Yuxiong He |
 |
Paper |
| FPTQ: Fine-grained Post-Training Quantization for Large Language Models Qingyuan Li, Yifan Zhang, Liang Li, Peng Yao, Bo Zhang, Xiangxiang Chu, Yerui Sun, Li Du, Yuchen Xie |
 |
Paper |
| QuantEase: Optimization-based Quantization for Language Models - An Efficient and Intuitive Algorithm Kayhan Behdin, Ayan Acharya, Aman Gupta, Qingquan Song, Siyu Zhu, Sathiya Keerthi, Rahul Mazumder |
 |
Github Paper |
| Norm Tweaking: High-performance Low-bit Quantization of Large Language Models Liang Li, Qingyuan Li, Bo Zhang, Xiangxiang Chu |
 |
Paper |
| Optimize Weight Rounding via Signed Gradient Descent for the Quantization of LLMs Wenhua Cheng, Weiwei Zhang, Haihao Shen, Yiyang Cai, Xin He, Kaokao Lv |
 |
Github Paper |
 QA-LoRA: Quantization-Aware Low-Rank Adaptation of Large Language Models Yuhui Xu, Lingxi Xie, Xiaotao Gu, Xin Chen, Heng Chang, Hengheng Zhang, Zhensu Chen, Xiaopeng Zhang, Qi Tian |
 |
Github Paper |
| ModuLoRA: Finetuning 3-Bit LLMs on Consumer GPUs by Integrating with Modular Quantizers Junjie Yin, Jiahao Dong, Yingheng Wang, Christopher De Sa, Volodymyr Kuleshov |
 |
Paper |
 PB-LLM: Partially Binarized Large Language Models Yuzhang Shang, Zhihang Yuan, Qiang Wu, Zhen Dong |
 |
Github Paper |
| Dual Grained Quantization: Efficient Fine-Grained Quantization for LLM Luoming Zhang, Wen Fei, Weijia Wu, Yefei He, Zhenyu Lou, Hong Zhou |
 |
Paper |
| QFT: Quantized Full-parameter Tuning of LLMs with Affordable Resources Zhikai Li, Xiaoxuan Liu, Banghua Zhu, Zhen Dong, Qingyi Gu, Kurt Keutzer |
 |
Paper |
| QLLM: Accurate and Efficient Low-Bitwidth Quantization for Large Language Models Jing Liu, Ruihao Gong, Xiuying Wei, Zhiwei Dong, Jianfei Cai, Bohan Zhuang |
 |
Paper |
| LoftQ: LoRA-Fine-Tuning-Aware Quantization for Large Language Models Yixiao Li, Yifan Yu, Chen Liang, Pengcheng He, Nikos Karampatziakis, Weizhu Chen, Tuo Zhao |
 |
Paper |
| TEQ: Trainable Equivalent Transformation for Quantization of LLMs Wenhua Cheng, Yiyang Cai, Kaokao Lv, Haihao Shen |
 |
Github Paper |
| BitNet: Scaling 1-bit Transformers for Large Language Models Hongyu Wang, Shuming Ma, Li Dong, Shaohan Huang, Huaijie Wang, Lingxiao Ma, Fan Yang, Ruiping Wang, Yi Wu, Furu Wei |
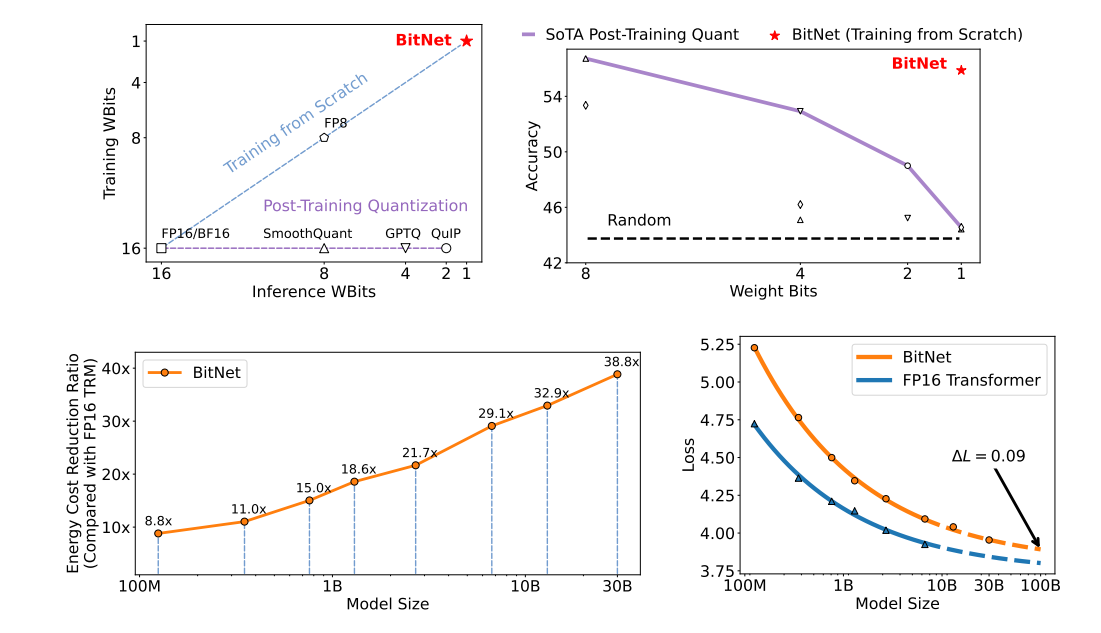 |
Paper |
| Atom: Low-bit Quantization for Efficient and Accurate LLM Serving Yilong Zhao, Chien-Yu Lin, Kan Zhu, Zihao Ye, Lequn Chen, Size Zheng, Luis Ceze, Arvind Krishnamurthy, Tianqi Chen, Baris Kasikci |
 |
Paper |
| AWEQ: Post-Training Quantization with Activation-Weight Equalization for Large Language Models Baisong Li, Xingwang Wang, Haixiao Xu |
 |
Paper |
 AFPQ: Asymmetric Floating Point Quantization for LLMs Yijia Zhang, Sicheng Zhang, Shijie Cao, Dayou Du, Jianyu Wei, Ting Cao, Ningyi Xu |
 |
Github Paper |
| A Speed Odyssey for Deployable Quantization of LLMs Qingyuan Li, Ran Meng, Yiduo Li, Bo Zhang, Liang Li, Yifan Lu, Xiangxiang Chu, Yerui Sun, Yuchen Xie |
 |
Paper |
 LQ-LoRA: Low-rank Plus Quantized Matrix Decomposition for Efficient Language Model Finetuning Han Guo, Philip Greengard, Eric P. Xing, Yoon Kim |
 |
Github Paper |
| Enabling Fast 2-bit LLM on GPUs: Memory Alignment, Sparse Outlier, and Asynchronous Dequantization Jinhao Li, Shiyao Li, Jiaming Xu, Shan Huang, Yaoxiu Lian, Jun Liu, Yu Wang, Guohao Dai |
 |
Paper |
 SmoothQuant+: Accurate and Efficient 4-bit Post-Training WeightQuantization for LLM Jiayi Pan, Chengcan Wang, Kaifu Zheng, Yangguang Li, Zhenyu Wang, Bin Feng |
 |
Github Paper |
| ZeroQuant(4+2): Redefining LLMs Quantization with a New FP6-Centric Strategy for Diverse Generative Tasks Xiaoxia Wu, Haojun Xia, Stephen Youn, Zhen Zheng, Shiyang Chen, Arash Bakhtiari, Michael Wyatt, Yuxiong He, Olatunji Ruwase, Leon Song, Zhewei Yao |
 |
Github Paper |
 Extreme Compression of Large Language Models via Additive Quantization Vage Egiazarian, Andrei Panferov, Denis Kuznedelev, Elias Frantar, Artem Babenko, Dan Alistarh |
 |
Github Paper |
| FP6-LLM: Efficiently Serving Large Language Models Through FP6-Centric Algorithm-System Co-Design Haojun Xia, Zhen Zheng, Xiaoxia Wu, Shiyang Chen, Zhewei Yao, Stephen Youn, Arash Bakhtiari, Michael Wyatt, Donglin Zhuang, Zhongzhu Zhou, Olatunji Ruwase, Yuxiong He, Shuaiwen Leon Song |
 |
Paper |
| L4Q: Parameter Efficient Quantization-Aware Training on Large Language Models via LoRA-wise LSQ Hyesung Jeon, Yulhwa Kim, Jae-joon Kim |
 |
Paper |
 QuIP#: Even Better LLM Quantization with Hadamard Incoherence and Lattice Codebooks Albert Tseng, Jerry Chee, Qingyao Sun, Volodymyr Kuleshov, Christopher De Sa |
 |
Github Paper |
 BiLLM: Pushing the Limit of Post-Training Quantization for LLMs Wei Huang, Yangdong Liu, Haotong Qin, Ying Li, Shiming Zhang, Xianglong Liu, Michele Magno, Xiaojuan Qi |
 |
Github Paper |
 Accurate LoRA-Finetuning Quantization of LLMs via Information Retention Haotong Qin, Xudong Ma, Xingyu Zheng, Xiaoyang Li, Yang Zhang, Shouda Liu, Jie Luo, Xianglong Liu, Michele Magno |
 |
Github Paper |
| ApiQ: Finetuning of 2-Bit Quantized Large Language Model Baohao Liao, Christof Monz |
 |
Paper |
| Towards Next-Level Post-Training Quantization of Hyper-Scale Transformers Junhan Kim, Kyungphil Park, Chungman Lee, Ho-young Kim, Joonyoung Kim, Yongkweon Jeon |
 |
Paper |
 EdgeQAT: Entropy and Distribution Guided Quantization-Aware Training for the Acceleration of Lightweight LLMs on the Edge Xuan Shen, Zhenglun Kong, Changdi Yang, Zhaoyang Han, Lei Lu, Peiyan Dong, Cheng Lyu, Chih-hsiang Li, Xuehang Guo, Zhihao Shu, Wei Niu, Miriam Leeser, Pu Zhao, Yanzhi Wang |
 |
Github Paper |
 BitDistiller: Unleashing the Potential of Sub-4-Bit LLMs via Self-Distillation Dayou Du, Yijia Zhang, Shijie Cao, Jiaqi Guo, Ting Cao, Xiaowen Chu, Ningyi Xu |
 |
Github Paper |
| OneBit: Towards Extremely Low-bit Large Language Models Yuzhuang Xu, Xu Han, Zonghan Yang, Shuo Wang, Qingfu Zhu, Zhiyuan Liu, Weidong Liu, Wanxiang Che |
 |
Paper |
 BitDelta: Your Fine-Tune May Only Be Worth One Bit James Liu, Guangxuan Xiao, Kai Li, Jason D. Lee, Song Han, Tri Dao, Tianle Cai |
 |
Github Paper |
| Any-Precision LLM: Low-Cost Deployment of Multiple, Different-Sized LLMs Yeonhong Park, Jake Hyun, SangLyul Cho, Bonggeun Sim, Jae W. Lee |
 |
Paper |
APTQ: Attention-aware Post-Training Mixed-Precision Quantization for Large Language Models Ziyi Guan, Hantao Huang, Yupeng Su, Hong Huang, Ngai Wong, Hao Yu |
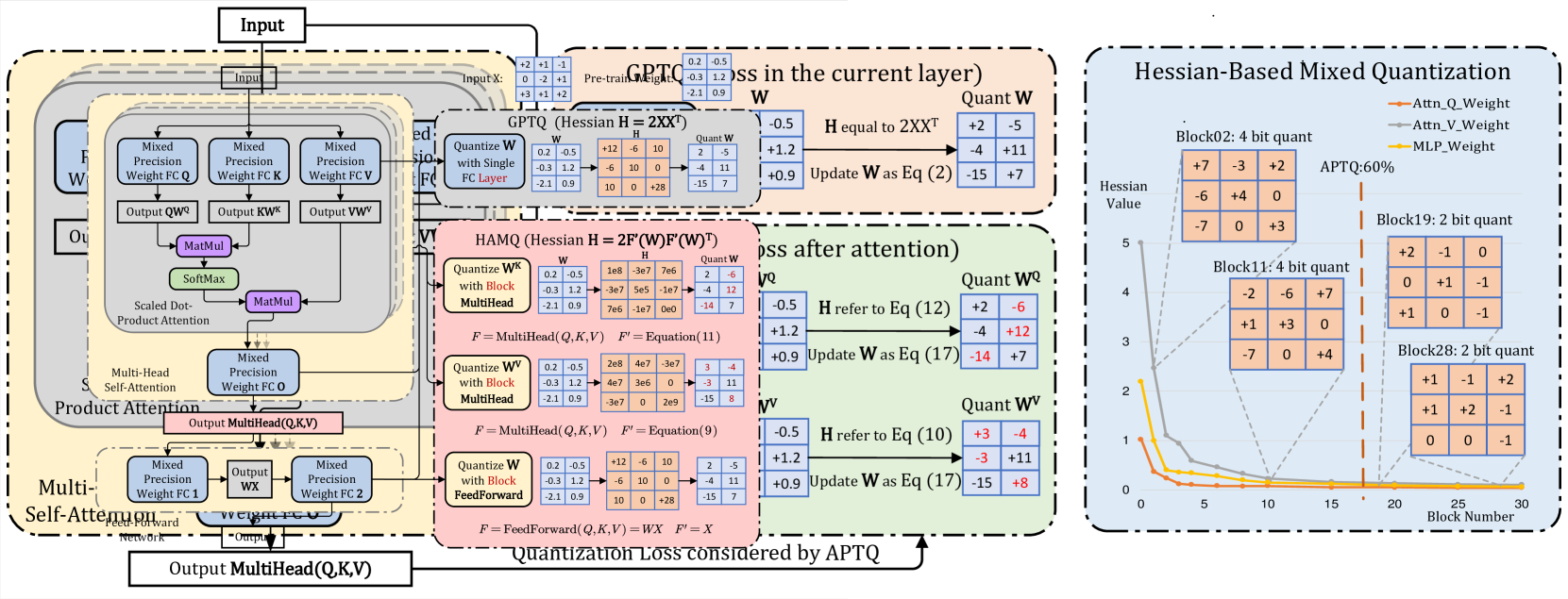 |
Paper |
 GPTVQ: The Blessing of Dimensionality for LLM Quantization Mart van Baalen, Andrey Kuzmin, Markus Nagel, Peter Couperus, Cedric Bastoul, Eric Mahurin, Tijmen Blankevoort, Paul Whatmough |
 |
Github Paper |
| A Comprehensive Evaluation of Quantization Strategies for Large Language Models Renren Jin, Jiangcun Du, Wuwei Huang, Wei Liu, Jian Luan, Bin Wang, Deyi Xiong |
 |
Paper |
| The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits Shuming Ma, Hongyu Wang, Lingxiao Ma, Lei Wang, Wenhui Wang, Shaohan Huang, Li Dong, Ruiping Wang, Jilong Xue, Furu Wei |
 |
Paper |
 Evaluating Quantized Large Language Models Shiyao Li, Xuefei Ning, Luning Wang, Tengxuan Liu, Xiangsheng Shi, Shengen Yan, Guohao Dai, Huazhong Yang, Yu Wang |
 |
Github Paper |
| FlattenQuant: Breaking Through the Inference Compute-bound for Large Language Models with Per-tensor Quantization Yi Zhang, Fei Yang, Shuang Peng, Fangyu Wang, Aimin Pan |
 |
Paper |
| What Makes Quantization for Large Language Models Hard? An Empirical Study from the Lens of Perturbation Zhuocheng Gong, Jiahao Liu, Jingang Wang, Xunliang Cai, Dongyan Zhao, Rui Yan |
 |
Paper |
| FrameQuant: Flexible Low-Bit Quantization for Transformers Harshavardhan Adepu, Zhanpeng Zeng, Li Zhang, Vikas Singh |
 |
Paper |
 QuaRot: Outlier-Free 4-Bit Inference in Rotated LLMs Saleh Ashkboos, Amirkeivan Mohtashami, Maximilian L. Croci, Bo Li, Martin Jaggi, Dan Alistarh, Torsten Hoefler, James Hensman |
 |
Github Paper |
| Accurate Block Quantization in LLMs with Outliers Nikita Trukhanov, Ilya Soloveychik |
 |
Paper |
| Cherry on Top: Parameter Heterogeneity and Quantization in Large Language Models Wanyun Cui, Qianle Wang |
 |
Paper |
| Increased LLM Vulnerabilities from Fine-tuning and Quantization Divyanshu Kumar, Anurakt Kumar, Sahil Agarwal, Prashanth Harshangi |
 |
Paper |
| Quantization of Large Language Models with an Overdetermined Basis Daniil Merkulov, Daria Cherniuk, Alexander Rudikov, Ivan Oseledets, Ekaterina Muravleva, Aleksandr Mikhalev, Boris Kashin |
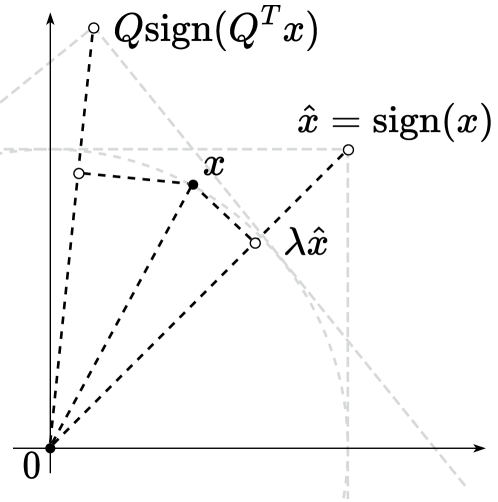 |
Paper |
 decoupleQ: Towards 2-bit Post-Training Uniform Quantization via decoupling Parameters into Integer and Floating Points Yi Guo, Fanliu Kong, Xiaoyang Li, Hui Li, Wei Chen, Xiaogang Tian, Jinping Cai, Yang Zhang, Shouda Liu |
 |
Github Paper |
| Lossless and Near-Lossless Compression for Foundation Models Moshik Hershcovitch, Leshem Choshen, Andrew Wood, Ilias Enmouri, Peter Chin, Swaminathan Sundararaman, Danny Harnik |
Paper | |
 How Good Are Low-bit Quantized LLaMA3 Models? An Empirical Study Wei Huang, Xudong Ma, Haotong Qin, Xingyu Zheng, Chengtao Lv, Hong Chen, Jie Luo, Xiaojuan Qi, Xianglong Liu, Michele Magno |
 |
Github Paper Model |
 When Quantization Affects Confidence of Large Language Models? Irina Proskurina, Luc Brun, Guillaume Metzler, Julien Velcin |
 |
Github Paper |
 QServe: W4A8KV4 Quantization and System Co-design for Efficient LLM Serving Yujun Lin, Haotian Tang, Shang Yang, Zhekai Zhang, Guangxuan Xiao, Chuang Gan, Song Han |
 |
Github Paper |
 LLM-QBench: A Benchmark Towards the Best Practice for Post-training Quantization of Large Language Models Ruihao Gong, Yang Yong, Shiqiao Gu, Yushi Huang, Yunchen Zhang, Xianglong Liu, Dacheng Tao |
 |
Github Paper |
 Exploiting LLM Quantization Kazuki Egashira, Mark Vero, Robin Staab, Jingxuan He, Martin Vechev |
 |
Github Paper |
| CLAQ: Pushing the Limits of Low-Bit Post-Training Quantization for LLMs Haoyu Wang, Bei Liu, Hang Shao, Bo Xiao, Ke Zeng, Guanglu Wan, Yanmin Qian |
 |
Paper |
| SpinQuant -- LLM quantization with learned rotations Zechun Liu, Changsheng Zhao, Igor Fedorov, Bilge Soran, Dhruv Choudhary, Raghuraman Krishnamoorthi, Vikas Chandra, Yuandong Tian, Tijmen Blankevoort |
 |
Paper |
 SliM-LLM: Salience-Driven Mixed-Precision Quantization for Large Language Models Wei Huang, Haotong Qin, Yangdong Liu, Yawei Li, Xianglong Liu, Luca Benini, Michele Magno, Xiaojuan Qi |
 |
Github Paper |
 PV-Tuning: Beyond Straight-Through Estimation for Extreme LLM Compression Vladimir Malinovskii, Denis Mazur, Ivan Ilin, Denis Kuznedelev, Konstantin Burlachenko, Kai Yi, Dan Alistarh, Peter Richtarik |
 |
Github Paper |
| Integer Scale: A Free Lunch for Faster Fine-grained Quantization of LLMs Qingyuan Li, Ran Meng, Yiduo Li, Bo Zhang, Yifan Lu, Yerui Sun, Lin Ma, Yuchen Xie |
 |
Paper |
| I-LLM: Efficient Integer-Only Inference for Fully-Quantized Low-Bit Large Language Models Xing Hu, Yuan Chen, Dawei Yang, Sifan Zhou, Zhihang Yuan, Jiangyong Yu, Chen Xu |
 |
Paper |
 Compressing Large Language Models using Low Rank and Low Precision Decomposition Rajarshi Saha, Naomi Sagan, Varun Srivastava, Andrea J. Goldsmith, Mert Pilanci |
 |
Github Paper |
| MagR: Weight Magnitude Reduction for Enhancing Post-Training Quantization Aozhong Zhang, Naigang Wang, Yanxia Deng, Xin Li, Zi Yang, Penghang Yin |
 |
Paper |
| LCQ: Low-Rank Codebook based Quantization for Large Language Models Wen-Pu Cai, Wu-Jun Li |
 |
Paper |
| Outliers and Calibration Sets have Diminishing Effect on Quantization of Modern LLMs Davide Paglieri, Saurabh Dash, Tim Rocktäschel, Jack Parker-Holder |
Paper | |
| Low-Rank Quantization-Aware Training for LLMs Yelysei Bondarenko, Riccardo Del Chiaro, Markus Nagel |
 |
Paper |
 ShiftAddLLM: Accelerating Pretrained LLMs via Post-Training Multiplication-Less Reparameterization Haoran You, Yipin Guo, Yichao Fu, Wei Zhou, Huihong Shi, Xiaofan Zhang, Souvik Kundu, Amir Yazdanbakhsh, Yingyan Lin |
 |
Github Paper |
 QQQ: Quality Quattuor-Bit Quantization for Large Language Models Ying Zhang, Peng Zhang, Mincong Huang, Jingyang Xiang, Yujie Wang, Chao Wang, Yineng Zhang, Lei Yu, Chuan Liu, Wei Lin |
 |
Github Paper |
| Attention-aware Post-training Quantization without Backpropagation Junhan Kim, Ho-young Kim, Eulrang Cho, Chungman Lee, Joonyoung Kim, Yongkweon Jeon |
 |
Paper |
| Prefixing Attention Sinks can Mitigate Activation Outliers for Large Language Model Quantization Seungwoo Son, Wonpyo Park, Woohyun Han, Kyuyeun Kim, Jaeho Lee |
 |
Paper |
| SDQ: Sparse Decomposed Quantization for LLM Inference Geonhwa Jeong, Po-An Tsai, Stephen W. Keckler, Tushar Krishna |
 |
Paper |
| CDQuant: Accurate Post-training Weight Quantization of Large Pre-trained Models using Greedy Coordinate Descent Pranav Ajit Nair, Arun Sai Suggala |
 |
Paper |
 Variable Layer-Wise Quantization: A Simple and Effective Approach to Quantize LLMs Razvan-Gabriel Dumitru, Vikas Yadav, Rishabh Maheshwary, Paul-Ioan Clotan, Sathwik Tejaswi Madhusudhan, Mihai Surdeanu |
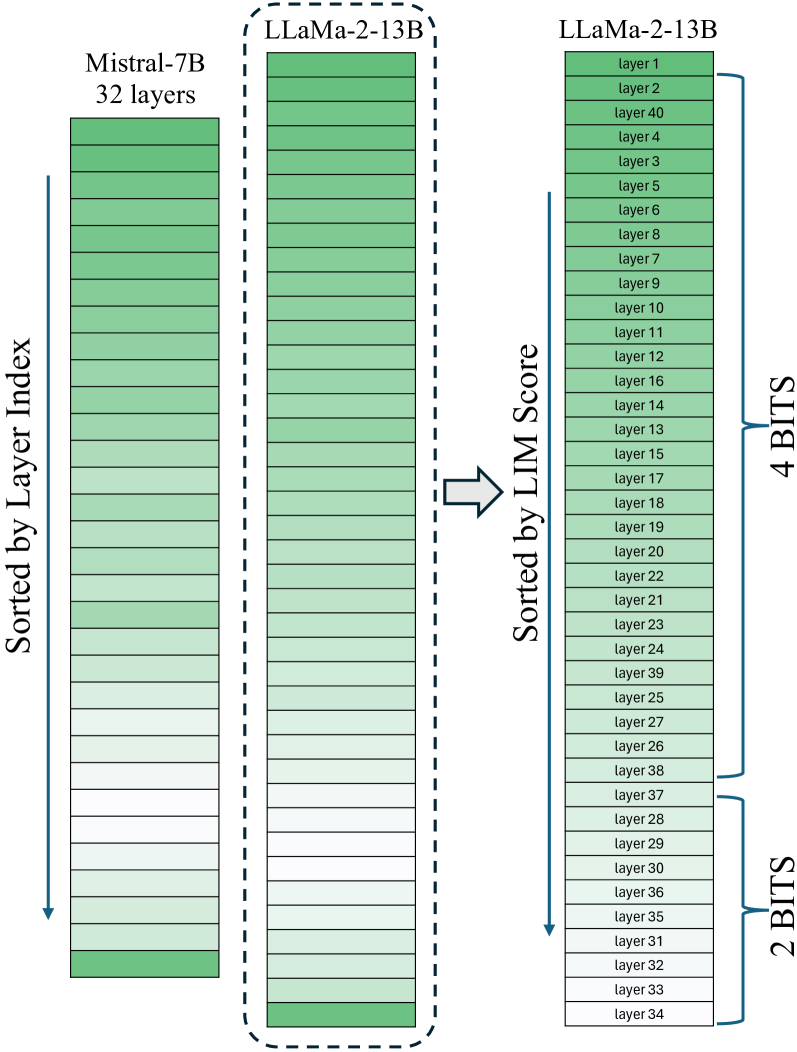 |
Github Paper |
 T-MAC: CPU Renaissance via Table Lookup for Low-Bit LLM Deployment on Edge Jianyu Wei, Shijie Cao, Ting Cao, Lingxiao Ma, Lei Wang, Yanyong Zhang, Mao Yang |
 |
Github Paper |
GPTQT: Quantize Large Language Models Twice to Push the Efficiency Yipin Guo, Yilin Lang, Qinyuan Ren |
 |
Paper |
 FBI-LLM: Scaling Up Fully Binarized LLMs from Scratch via Autoregressive Distillation Liqun Ma, Mingjie Sun, Zhiqiang Shen |
 |
Github Paper |
 RoLoRA: Fine-tuning Rotated Outlier-free LLMs for Effective Weight-Activation Quantization Xijie Huang, Zechun Liu, Shih-Yang Liu, Kwang-Ting Cheng |
 |
Github Paper |
| Prefixing Attention Sinks can Mitigate Activation Outliers for Large Language Model Quantization Seungwoo Son, Wonpyo Park, Woohyun Han, Kyuyeun Kim, Jaeho Lee |
|
Paper |
| LeanQuant: Accurate Large Language Model Quantization with Loss-Error-Aware Grid Tianyi Zhang, Anshumali Shrivastava |
 |
Paper |
 Fast Matrix Multiplications for Lookup Table-Quantized LLMs Han Guo, William Brandon, Radostin Cholakov, Jonathan Ragan-Kelley, Eric P. Xing, Yoon Kim |
 |
Github Paper |
 Spectra: A Comprehensive Study of Ternary, Quantized, and FP16 Language Models Ayush Kaushal, Tejas Pandey, Tejas Vaidhya, Aaryan Bhagat, Irina Rish |
 |
Github Paper |
 LRQ: Optimizing Post-Training Quantization for Large Language Models by Learning Low-Rank Weight-Scaling Matrices Jung Hyun Lee, Jeonghoon Kim, June Yong Yang, Se Jung Kwon, Eunho Yang, Kang Min Yoo, Dongsoo Lee |
 |
Github Paper |
 EfficientQAT: Efficient Quantization-Aware Training for Large Language Models Mengzhao Chen, Wenqi Shao, Peng Xu, Jiahao Wang, Peng Gao, Kaipeng Zhang, Yu Qiao, Ping Luo |
 |
Github Paper |
 Scalify: scale propagation for efficient low-precision LLM training Paul Balança, Sam Hosegood, Carlo Luschi, Andrew Fitzgibbon |
Github Paper |
|
 Accurate and Efficient Fine-Tuning of Quantized Large Language Models Through Optimal Balance Ao Shen, Qiang Wang, Zhiquan Lai, Xionglve Li, Dongsheng Li |
 |
Github Paper |
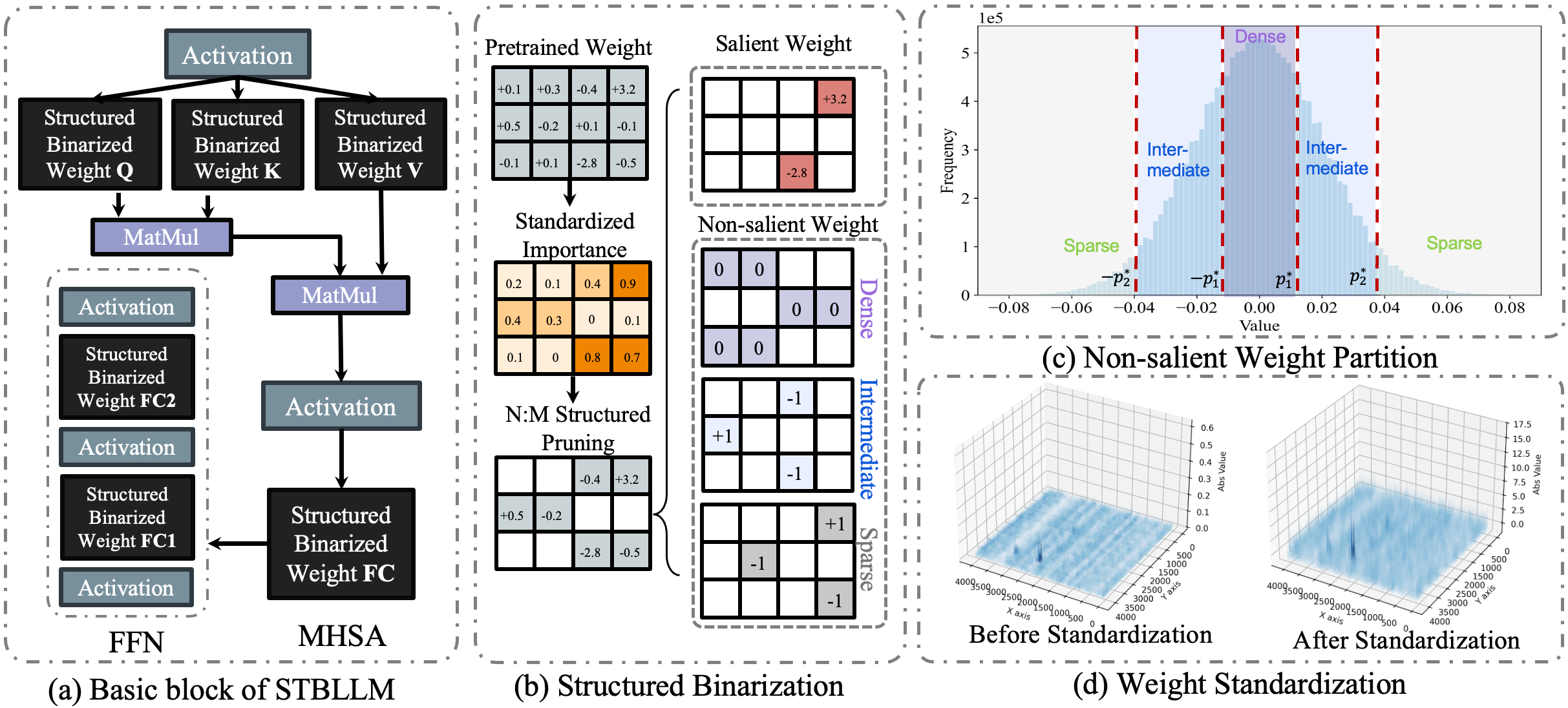
| STBLLM: Breaking the 1-Bit Barrier with Structured Binary LLMs Peijie Dong, Lujun Li, Dayou Du, Yuhan Chen, Zhenheng Tang, Qiang Wang, Wei Xue, Wenhan Luo, Qifeng Liu, Yike Guo, Xiaowen Chu |
 |
Paper |
 ABQ-LLM: Arbitrary-Bit Quantized Inference Acceleration for Large Language Models Chao Zeng, Songwei Liu, Yusheng Xie, Hong Liu, Xiaojian Wang, Miao Wei, Shu Yang, Fangmin Chen, Xing Mei |
 |
Github Paper |
| Matmul or No Matmal in the Era of 1-bit LLMs Jinendra Malekar, Mohammed E. Elbtity, Ramtin Zand Co |
 |
Paper |
 MobileQuant: Mobile-friendly Quantization for On-device Language Models Fuwen Tan, Royson Lee, Łukasz Dudziak, Shell Xu Hu, Sourav Bhattacharya, Timothy Hospedales, Georgios Tzimiropoulos, Brais Martinez |
 |
Github Paper |
| The Uniqueness of LLaMA3-70B with Per-Channel Quantization: An Empirical Study Minghai Qin |
 |
Paper |
| A Comprehensive Evaluation of Quantized Instruction-Tuned Large Language Models: An Experimental Analysis up to 405B Jemin Lee, Sihyeong Park, Jinse Kwon, Jihun Oh, Yongin Kwon |
 |
Paper |
 DuQuant: Distributing Outliers via Dual Transformation Makes Stronger Quantized LLMs Haokun Lin, Haobo Xu, Yichen Wu, Jingzhi Cui, Yingtao Zhang, Linzhan Mou, Linqi Song, Zhenan Sun, Ying Wei |
 |
Github Paper |
| Accumulator-Aware Post-Training Quantization Ian Colbert, Fabian Grob, Giuseppe Franco, Jinjie Zhang, Rayan Saab |
 |
Paper |
 INT-FlashAttention: Enabling Flash Attention for INT8 Quantization Shimao Chen, Zirui Liu, Zhiying Wu, Ce Zheng, Peizhuang Cong, Zihan Jiang, Yuhan Wu, Lei Su, Tong Yang |
 |
Github Paper |
 VPTQ: Extreme Low-bit Vector Post-Training Quantization for Large Language Models Yifei Liu, Jicheng Wen, Yang Wang, Shengyu Ye, Li Lyna Zhang, Ting Cao, Cheng Li, Mao Yang |
 |
Github Paper |
| Addition is All You Need for Energy-efficient Language Models Hongyin Luo, Wei Sun |
 |
Paper |
| SageAttention: Accurate 8-Bit Attention for Plug-and-play Inference Acceleration Jintao Zhang, Jia wei, Pengle Zhang, Jun Zhu, Jianfei Chen |
 |
Paper |
| CrossQuant: A Post-Training Quantization Method with Smaller Quantization Kernel for Precise Large Language Model Compression Wenyuan Liu, Xindian Ma, Peng Zhang, Yan Wang |
 |
Paper |
| PalmBench: A Comprehensive Benchmark of Compressed Large Language Models on Mobile Platforms Yilong Li, Jingyu Liu, Hao Zhang, M Badri Narayanan, Utkarsh Sharma, Shuai Zhang, Pan Hu, Yijing Zeng, Jayaram Raghuram, Suman Banerjee |
 |
Paper |
| Scaling Laws for Mixed quantization in Large Language Models Zeyu Cao, Cheng Zhang, Pedro Gimenes, Jianqiao Lu, Jianyi Cheng, Yiren Zhao |
 |
Paper |
 PrefixQuant: Static Quantization Beats Dynamic through Prefixed Outliers in LLMs Mengzhao Chen, Yi Liu, Jiahao Wang, Yi Bin, Wenqi Shao, Ping Luo |
 |
Github Paper |
 EXAQ: Exponent Aware Quantization For LLMs Acceleration Moran Shkolnik, Maxim Fishman, Brian Chmiel, Hilla Ben-Yaacov, Ron Banner, Kfir Yehuda Levy |
 |
Github Paper |
 Quamba: A Post-Training Quantization Recipe for Selective State Space Models Hung-Yueh Chiang, Chi-Chih Chang, Natalia Frumkin, Kai-Chiang Wu, Diana Marculescu |
 |
Github Paper |
| AsymKV: Enabling 1-Bit Quantization of KV Cache with Layer-Wise Asymmetric Quantization Configurations Qian Tao, Wenyuan Yu, Jingren Zhou |
 |
Paper |
| Channel-Wise Mixed-Precision Quantization for Large Language Models Zihan Chen, Bike Xie, Jundong Li, Cong Shen |
 |
Paper |
| Progressive Mixed-Precision Decoding for Efficient LLM Inference Hao Mark Chen, Fuwen Tan, Alexandros Kouris, Royson Lee, Hongxiang Fan, Stylianos I. Venieris |
 |
Paper |
 DAQ: Density-Aware Post-Training Weight-Only Quantization For LLMs Yingsong Luo, Ling Chen |
 |
Github Paper |
| Continuous Approximations for Improving Quantization Aware Training of LLMs He Li, Jianhang Hong, Yuanzhuo Wu, Snehal Adbol, Zonglin Li |
Paper | |
| Scaling laws for post-training quantized large language models Zifei Xu, Alexander Lan, Wanzin Yazar, Tristan Webb, Sayeh Sharify, Xin Wang |
 |
Paper |
 SLiM: One-shot Quantized Sparse Plus Low-rank Approximation of LLMs Mohammad Mozaffari, Maryam Mehri Dehnavi |
 |
Github Paper |
| SeedLM: Compressing LLM Weights into Seeds of Pseudo-Random Generators Rasoul Shafipour, David Harrison, Maxwell Horton, Jeffrey Marker, Houman Bedayat, Sachin Mehta, Mohammad Rastegari, Mahyar Najibi, Saman Naderiparizi |
 |
Paper |
 FlatQuant: Flatness Matters for LLM Quantization Yuxuan Sun, Ruikang Liu, Haoli Bai, Han Bao, Kang Zhao, Yuening Li, Jiaxin Hu, Xianzhi Yu, Lu Hou, Chun Yuan, Xin Jiang, Wulong Liu, Jun Yao |
 |
Github Paper |
| Pyramid Vector Quantization for LLMs Tycho F. A. van der Ouderaa, Maximilian L. Croci, Agrin Hilmkil, James Hensman |
 |
Paper |
| Evaluating Quantized Large Language Models for Code Generation on Low-Resource Language Benchmarks Enkhbold Nyamsuren |
Paper | |
| QuAILoRA: Quantization-Aware Initialization for LoRA Neal Lawton, Aishwarya Padmakumar, Judith Gaspers, Jack FitzGerald, Anoop Kumar, Greg Ver Steeg, Aram Galstyan |
Paper | |
 1-bit AI Infra: Part 1.1, Fast and Lossless BitNet b1.58 Inference on CPUs Jinheng Wang, Hansong Zhou, Ting Song, Shaoguang Mao, Shuming Ma, Hongyu Wang, Yan Xia, Furu Wei |
 |
Github Paper |
| Understanding the difficulty of low-precision post-training quantization of large language models Zifei Xu, Sayeh Sharify, Wanzin Yazar, Tristan Webb, Xin Wang |
 |
Paper |
| The Impact of Inference Acceleration Strategies on Bias of LLMs Elisabeth Kirsten, Ivan Habernal, Vedant Nanda, Muhammad Bilal Zafar |
Paper | |
 BitStack: Fine-Grained Size Control for Compressed Large Language Models in Variable Memory Environments Xinghao Wang, Pengyu Wang, Bo Wang, Dong Zhang, Yunhua Zhou, Xipeng Qiu |
 |
Github Paper |
 TesseraQ: Ultra Low-Bit LLM Post-Training Quantization with Block Reconstruction Yuhang Li, Priyadarshini Panda |
 |
Github Paper |
| BitNet a4.8: 4-bit Activations for 1-bit LLMs Hongyu Wang, Shuming Ma, Furu Wei |
 |
Paper |
| "Give Me BF16 or Give Me Death"? Accuracy-Performance Trade-Offs in LLM Quantization Eldar Kurtic, Alexandre Marques, Shubhra Pandit, Mark Kurtz, Dan Alistarh |
Paper | |
| GWQ: Gradient-Aware Weight Quantization for Large Language Models Yihua Shao, Siyu Liang, Xiaolin Lin, Zijian Ling, Zixian Zhu et al |
 |
Paper |
| A Comprehensive Study on Quantization Techniques for Large Language Models Jiedong Lang, Zhehao Guo, Shuyu Huang |
Paper | |
| Bi-Mamba: Towards Accurate 1-Bit State Space Models Shengkun Tang, Liqun Ma, Haonan Li, Mingjie Sun, Zhiqiang Shen |
 |
Paper |
| AMXFP4: Taming Activation Outliers with Asymmetric Microscaling Floating-Point for 4-bit LLM Inference Janghwan Lee, Jiwoong Park, Jinseok Kim, Yongjik Kim, Jungju Oh, Jinwook Oh, Jungwook Choi |
 |
Paper |
 BitMoD: Bit-serial Mixture-of-Datatype LLM Acceleration Yuzong Chen, Ahmed F. AbouElhamayed, Xilai Dai, Yang Wang, Marta Andronic, George A. Constantinides, Mohamed S. Abdelfattah |
 |
Github Paper |
| MixPE: Quantization and Hardware Co-design for Efficient LLM Inference Yu Zhang, Mingzi Wang, Lancheng Zou, Wulong Liu, Hui-Ling Zhen, Mingxuan Yuan, Bei Yu |
 |
Paper |
Anda: Unlocking Efficient LLM Inference with a Variable-Length Grouped Activation Data Format Chao Fang, Man Shi, Robin Geens, Arne Symons, Zhongfeng Wang, Marian Verhelst |
 |
Paper |
| SKIM: Any-bit Quantization Pushing The Limits of Post-Training Quantization Runsheng Bai, Qiang Liu, Bo Liu |
 |
Paper |
| CPTQuant -- A Novel Mixed Precision Post-Training Quantization Techniques for Large Language Models Amitash Nanda, Sree Bhargavi Balija, Debashis Sahoo |
 |
Paper |