SiDA: Sparsity-Inspired Data-Aware Serving for Efficient and Scalable Large Mixture-of-Experts Models
Zhixu Du, Shiyu Li, Yuhao Wu, Xiangyu Jiang, Jingwei Sun, Qilin Zheng, Yongkai Wu, Ang Li, Hai "Helen" Li, Yiran Chen |
 |
Paper |

Fast Inference of Mixture-of-Experts Language Models with Offloading
Artyom Eliseev, Denis Mazur |
 |
Github
Paper |

SwitchHead: Accelerating Transformers with Mixture-of-Experts Attention
Róbert Csordás, Piotr Piękos, Kazuki Irie, Jürgen Schmidhuber |
 |
Github
Paper |

Exploiting Inter-Layer Expert Affinity for Accelerating Mixture-of-Experts Model Inference
Jinghan Yao, Quentin Anthony, Aamir Shafi, Hari Subramoni, Dhabaleswar K. (DK)Panda |
 |
Github
Paper |

MoE-Infinity: Activation-Aware Expert Offloading for Efficient MoE Serving
Leyang Xue, Yao Fu, Zhan Lu, Luo Mai, Mahesh Marina |
 |
Github
Paper |

Fiddler: CPU-GPU Orchestration for Fast Inference of Mixture-of-Experts Models
Keisuke Kamahori, Yile Gu, Kan Zhu, Baris Kasikci |
 |
Github
Paper |

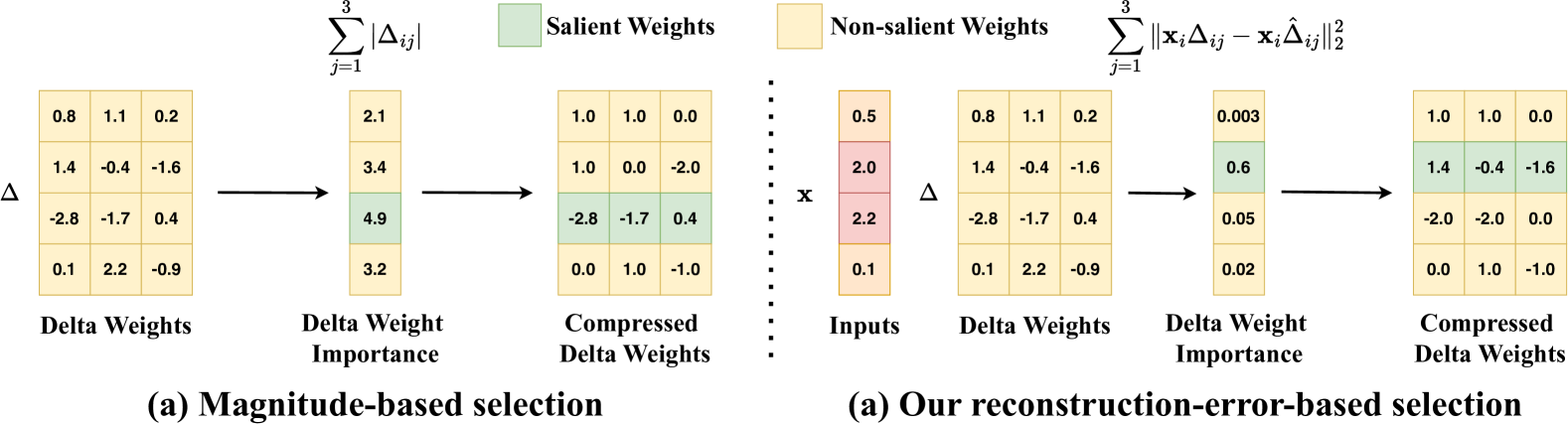
Not All Experts are Equal: Efficient Expert Pruning and Skipping for Mixture-of-Experts Large Language Models
Xudong Lu, Qi Liu, Yuhui Xu, Aojun Zhou, Siyuan Huang, Bo Zhang, Junchi Yan, Hongsheng Li |
 |
Github
Paper |
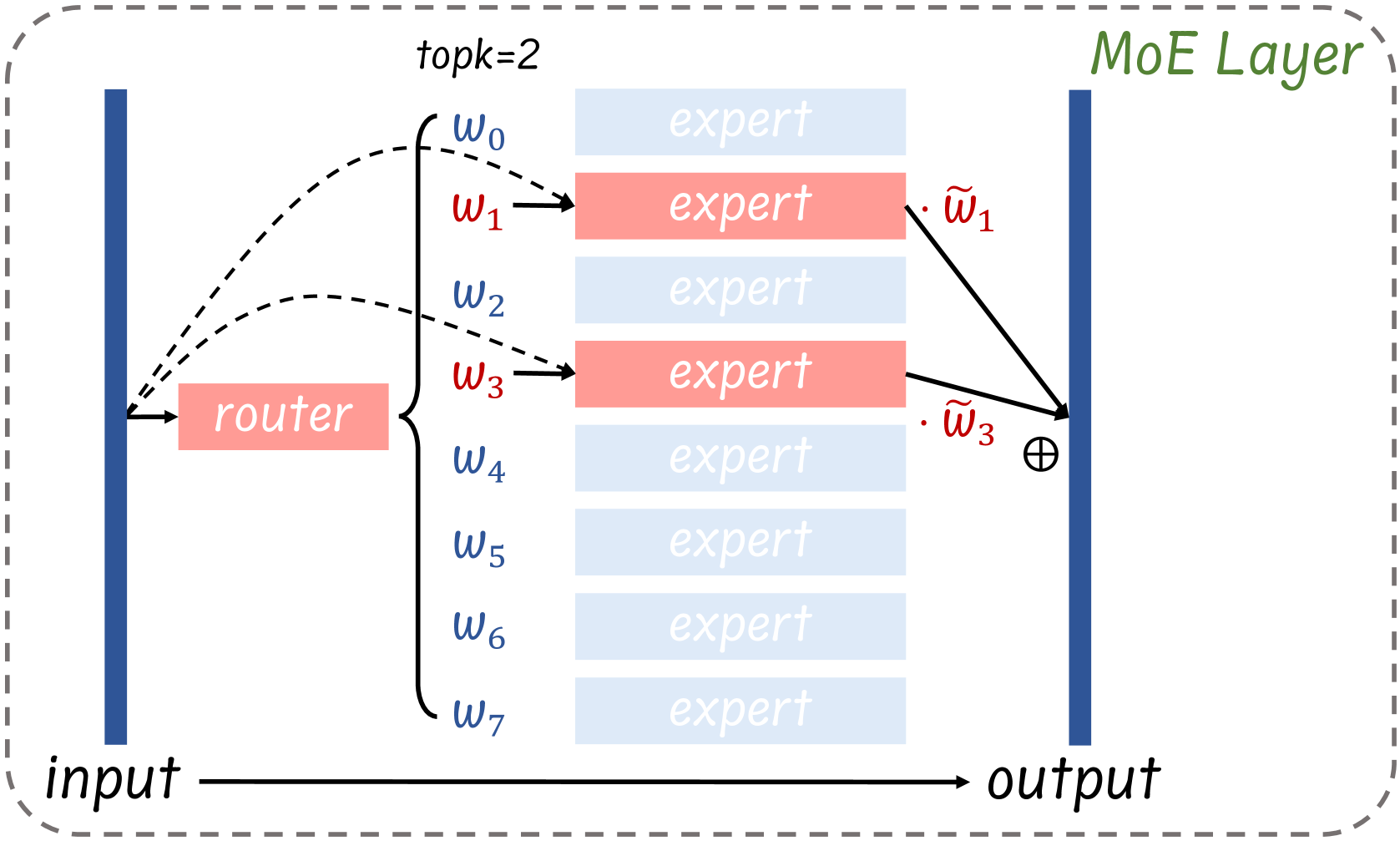
Enhancing Efficiency in Sparse Models with Sparser Selection
Yuanhang Yang, Shiyi Qi, Wenchao Gu, Chaozheng Wang, Cuiyun Gao, Zenglin Xu |
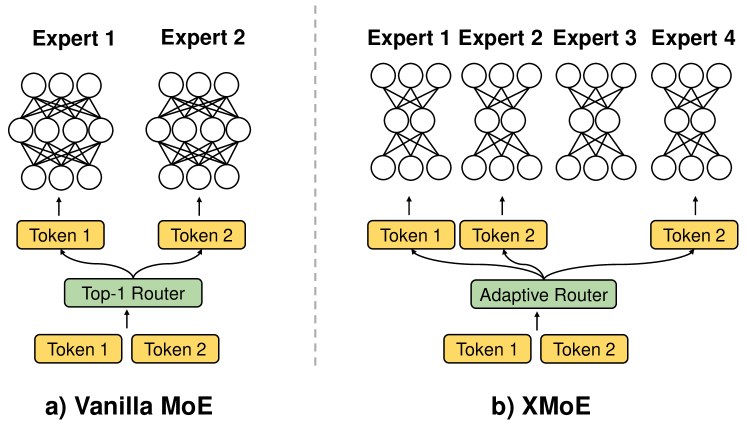 |
Github
Paper |

Prompt-prompted Mixture of Experts for Efficient LLM Generation
Harry Dong, Beidi Chen, Yuejie Chi |
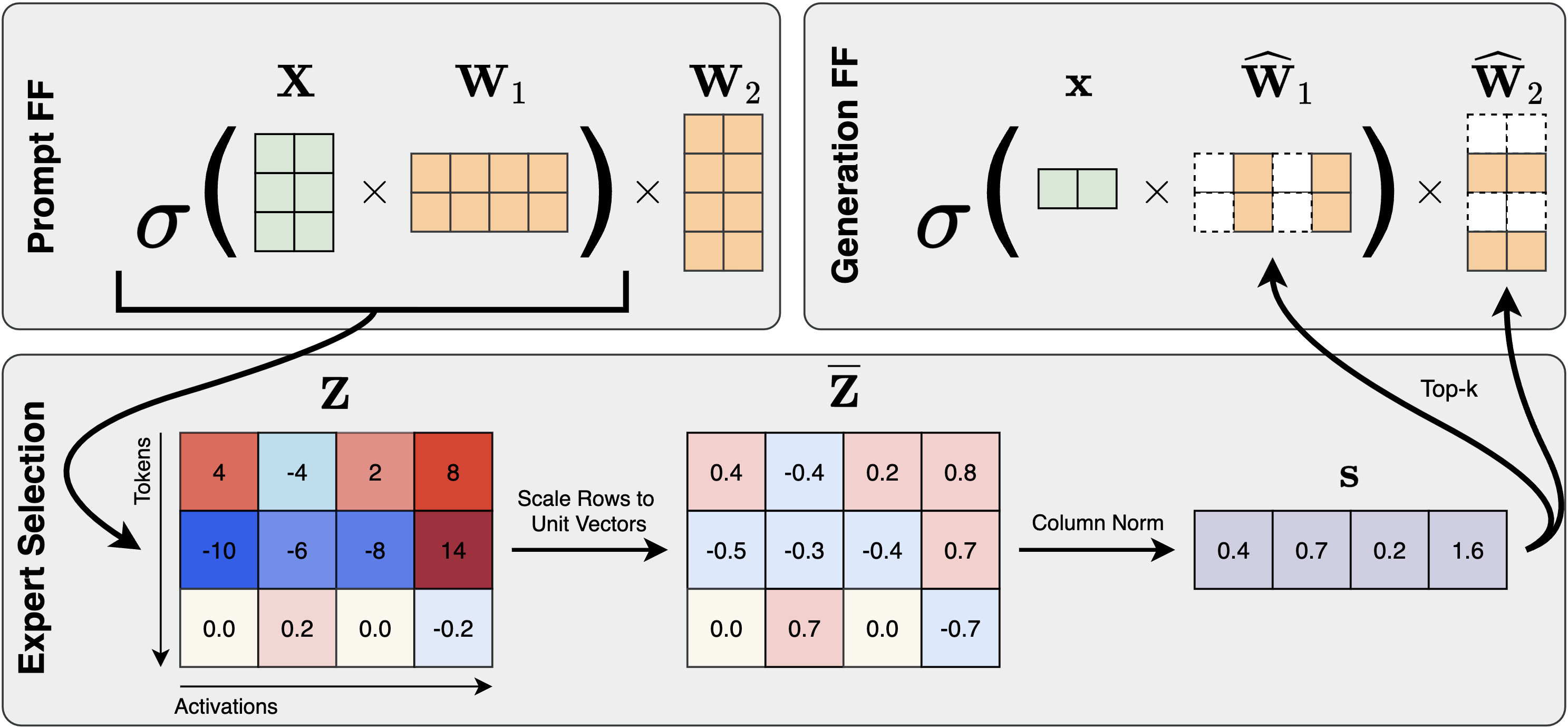 |
Github
Paper |
Shortcut-connected Expert Parallelism for Accelerating Mixture-of-Experts
Weilin Cai, Juyong Jiang, Le Qin, Junwei Cui, Sunghun Kim, Jiayi Huang |
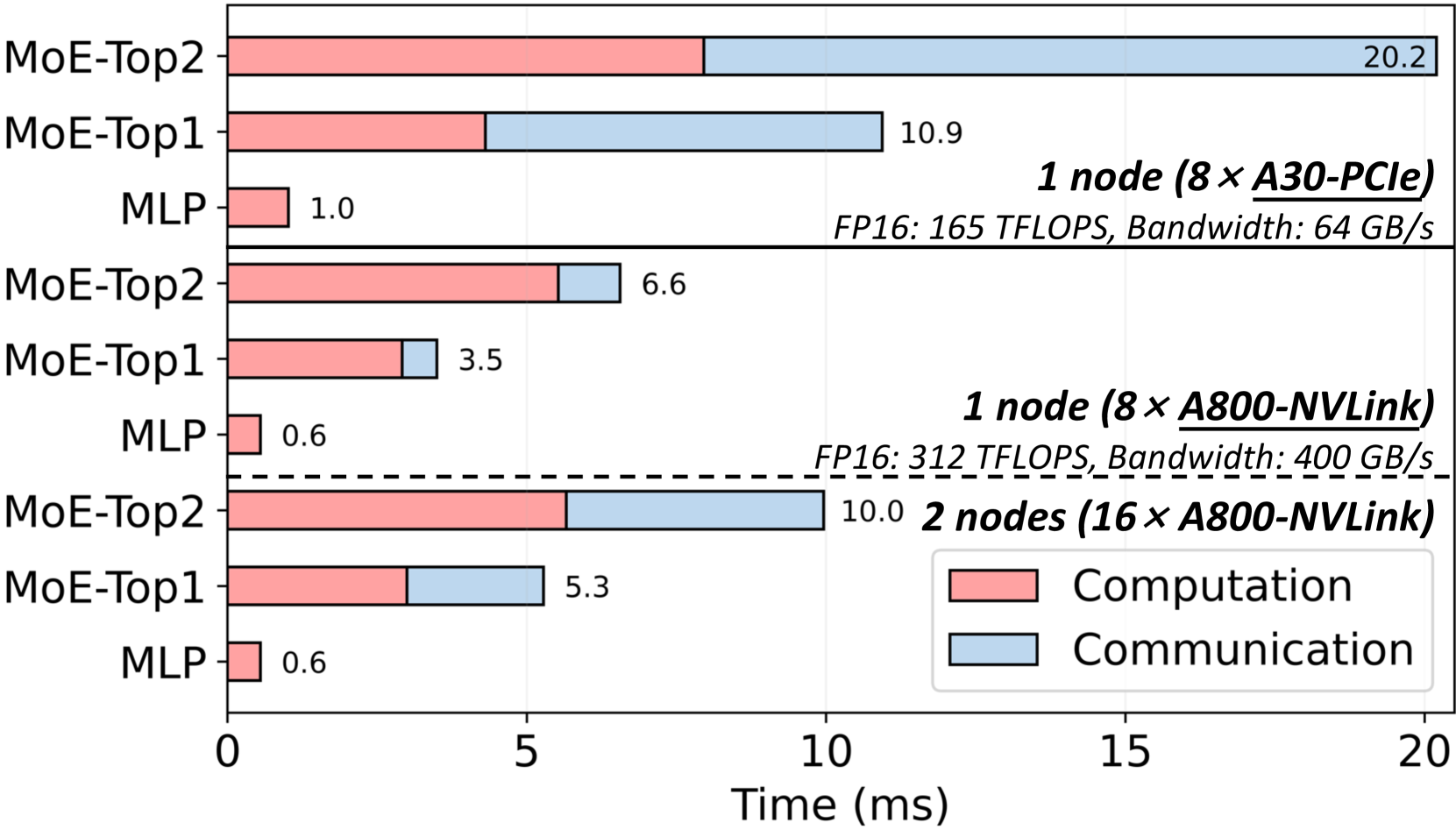 |
Paper |
SEER-MoE: Sparse Expert Efficiency through Regularization for Mixture-of-Experts
Alexandre Muzio, Alex Sun, Churan He |
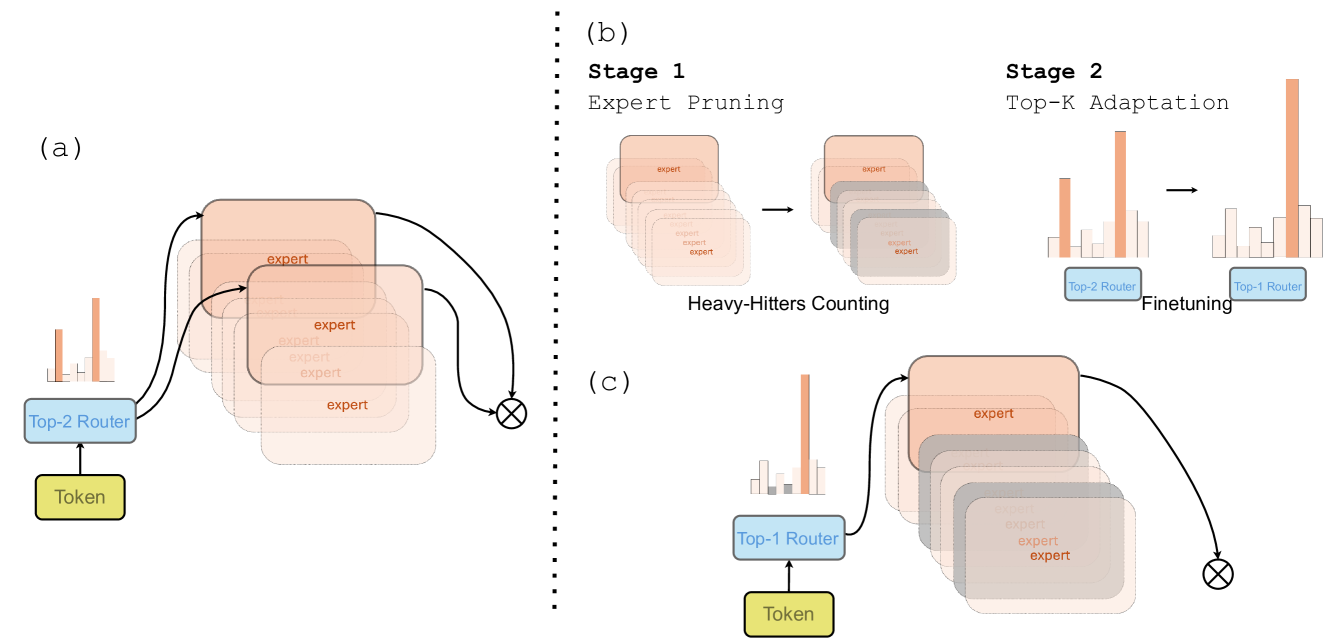 |
Paper |
Dense Training, Sparse Inference: Rethinking Training of Mixture-of-Experts Language Models
Bowen Pan, Yikang Shen, Haokun Liu, Mayank Mishra, Gaoyuan Zhang, Aude Oliva, Colin Raffel, Rameswar Panda |
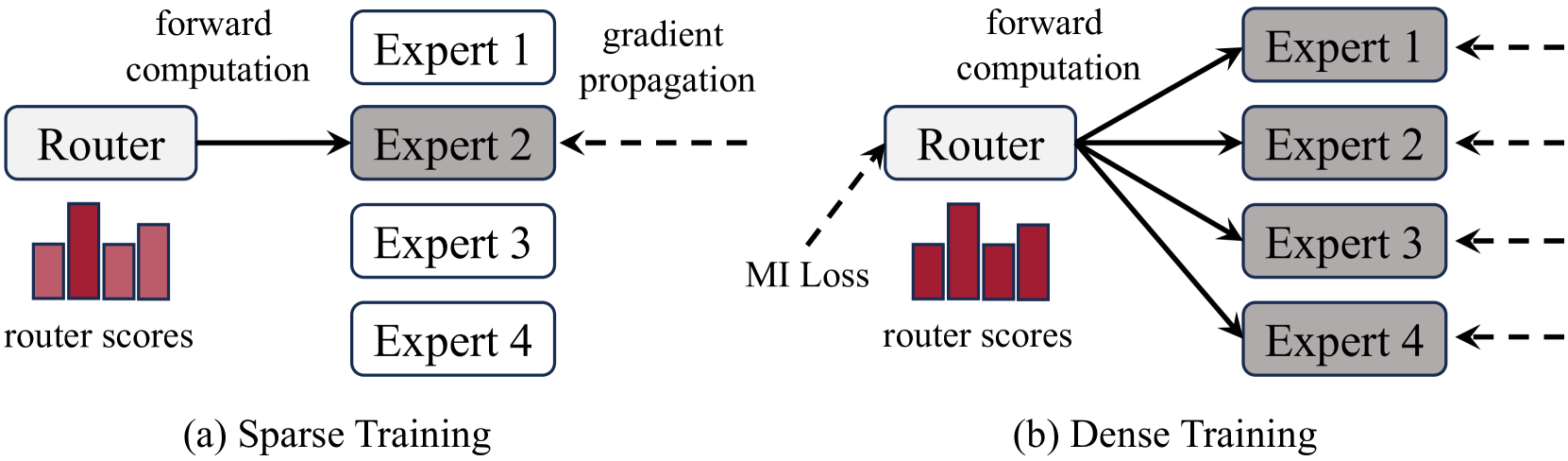 |
Paper |

Lancet: Accelerating Mixture-of-Experts Training via Whole Graph Computation-Communication Overlapping
Chenyu Jiang, Ye Tian, Zhen Jia, Shuai Zheng, Chuan Wu, Yida Wang |
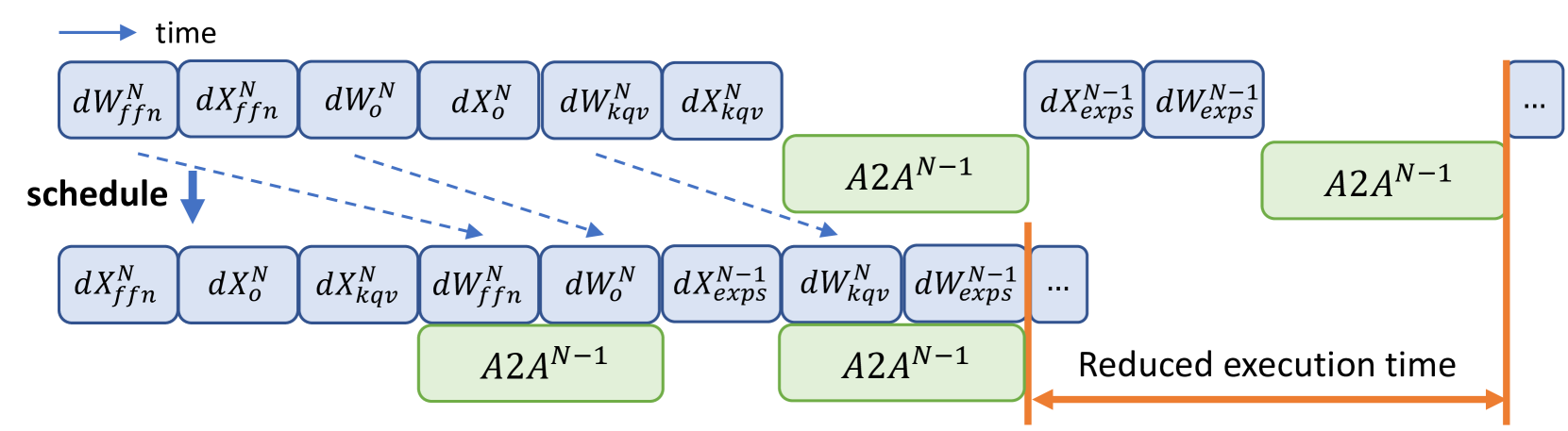 |
Paper |

A Provably Effective Method for Pruning Experts in Fine-tuned Sparse Mixture-of-Experts
Mohammed Nowaz Rabbani Chowdhury, Meng Wang, Kaoutar El Maghraoui, Naigang Wang, Pin-Yu Chen, Christopher Carothers |
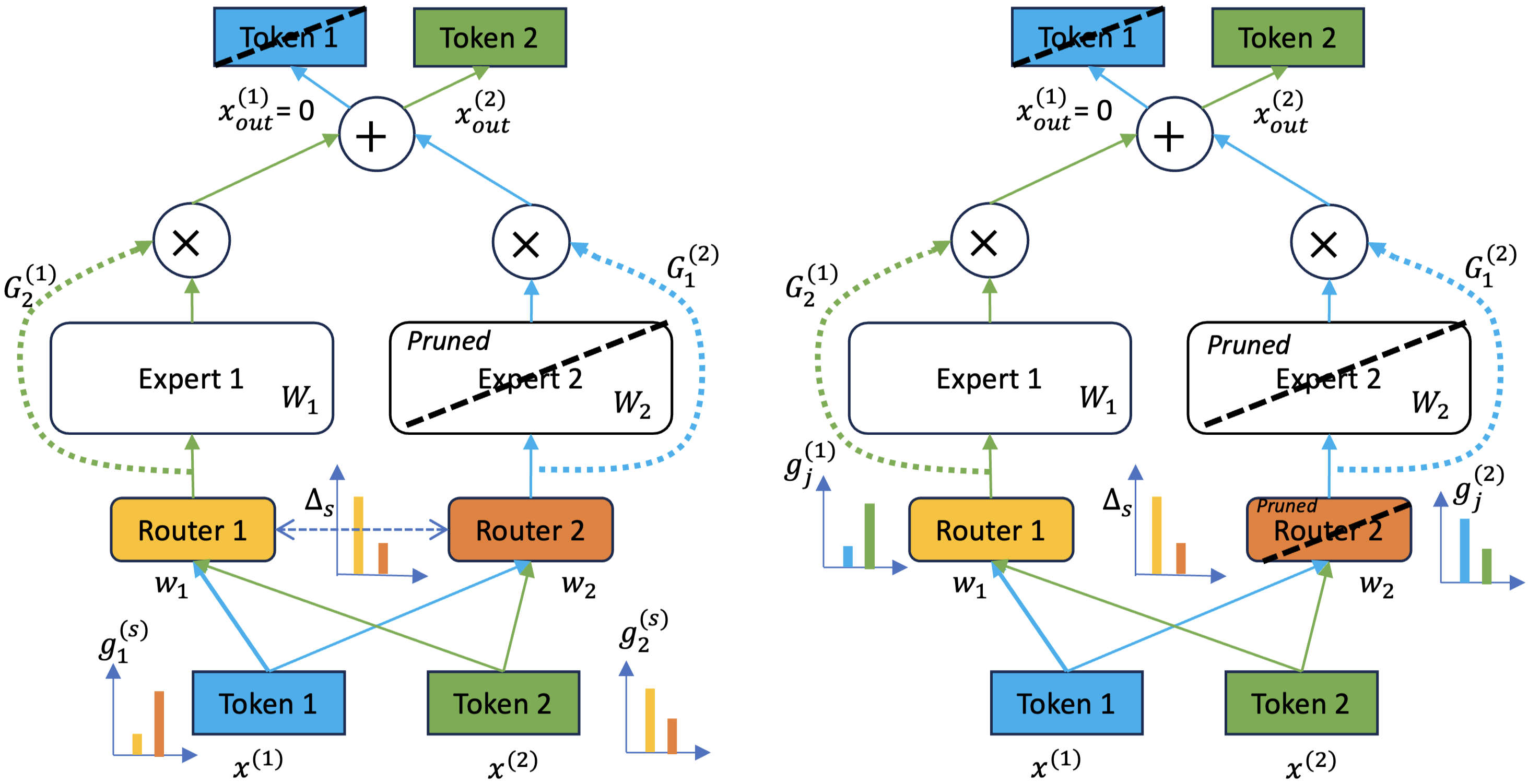 |
Paper |

Dynamic Mixture of Experts: An Auto-Tuning Approach for Efficient Transformer Models
Yongxin Guo, Zhenglin Cheng, Xiaoying Tang, Tao Lin |
 |
Github
Paper |

MoNDE: Mixture of Near-Data Experts for Large-Scale Sparse Models
Taehyun Kim, Kwanseok Choi, Youngmock Cho, Jaehoon Cho, Hyuk-Jae Lee, Jaewoong Sim |
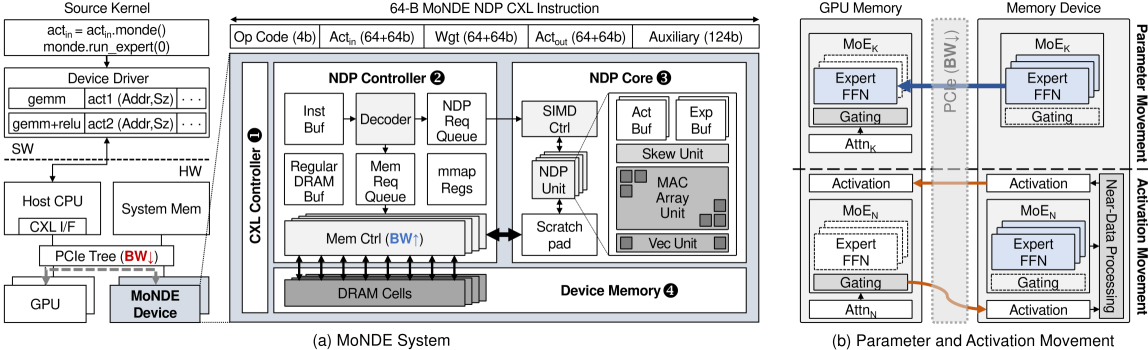 |
Paper |

Demystifying the Compression of Mixture-of-Experts Through a Unified Framework
Shwai He, Daize Dong, Liang Ding, Ang Li |
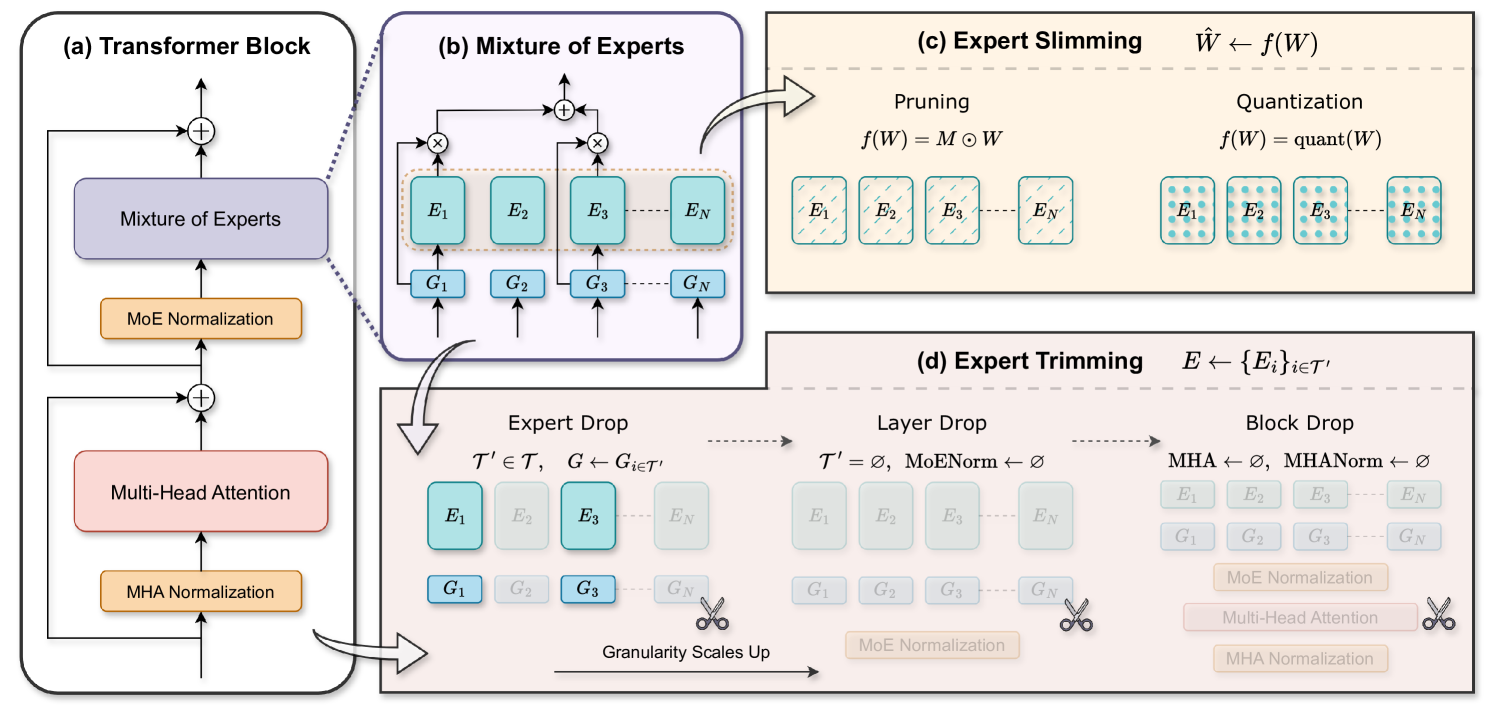 |
Github
Paper |
ME-Switch: A Memory-Efficient Expert Switching Framework for Large Language Models
Jing Liu, Ruihao Gong, Mingyang Zhang, Yefei He, Jianfei Cai, Bohan Zhuang |
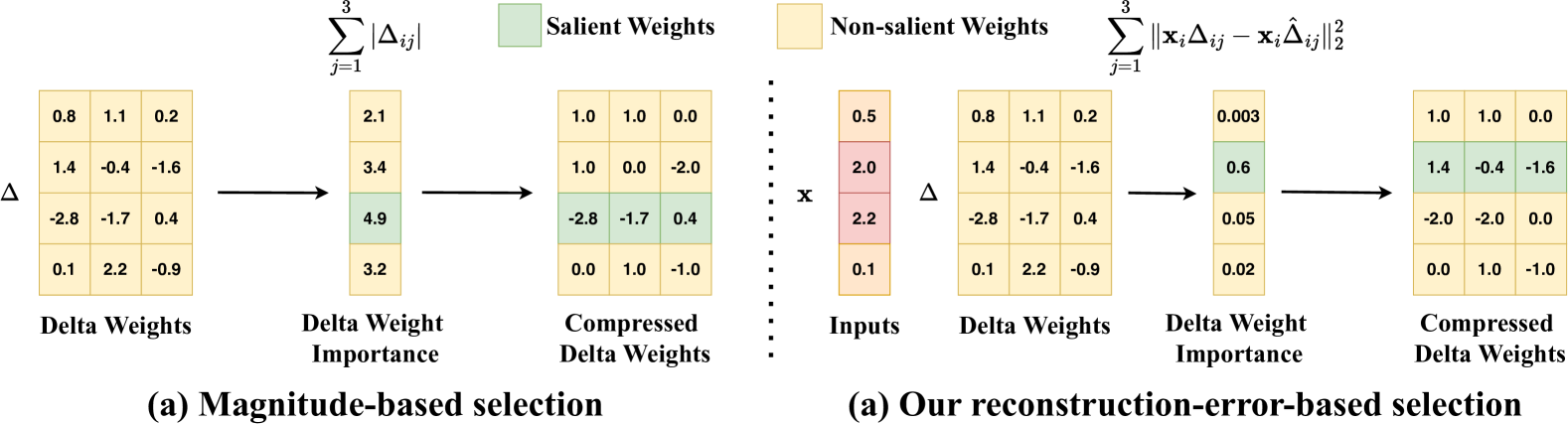 |
Paper |

Examining Post-Training Quantization for Mixture-of-Experts: A Benchmark
Pingzhi Li, Xiaolong Jin, Yu Cheng, Tianlong Chen |
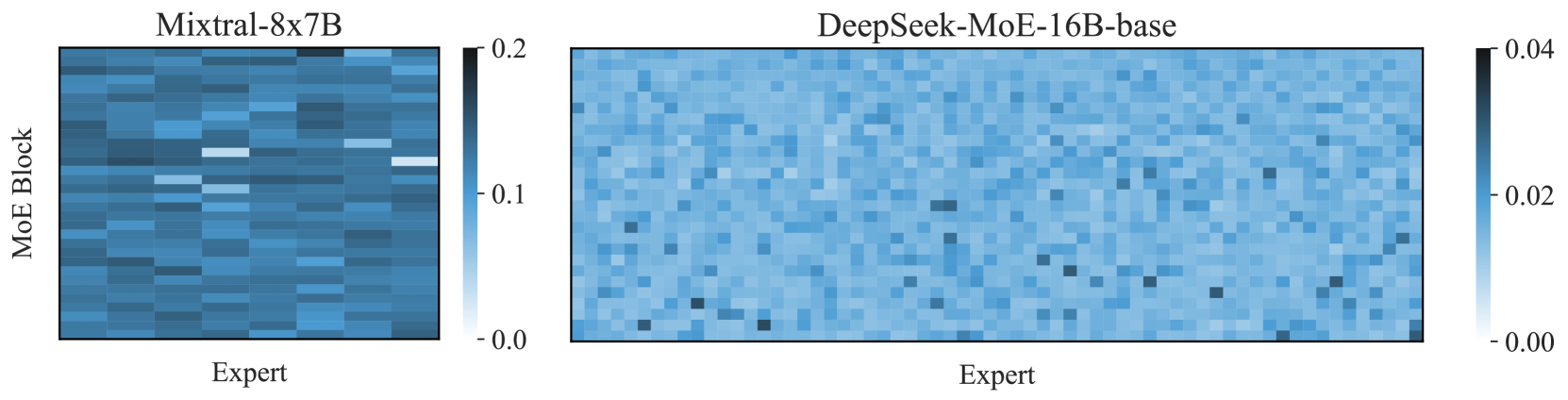 |
Github
Paper |

Efficient Expert Pruning for Sparse Mixture-of-Experts Language Models: Enhancing Performance and Reducing Inference Costs
Enshu Liu, Junyi Zhu, Zinan Lin, Xuefei Ning, Matthew B. Blaschko, Shengen Yan, Guohao Dai, Huazhong Yang, Yu Wang |
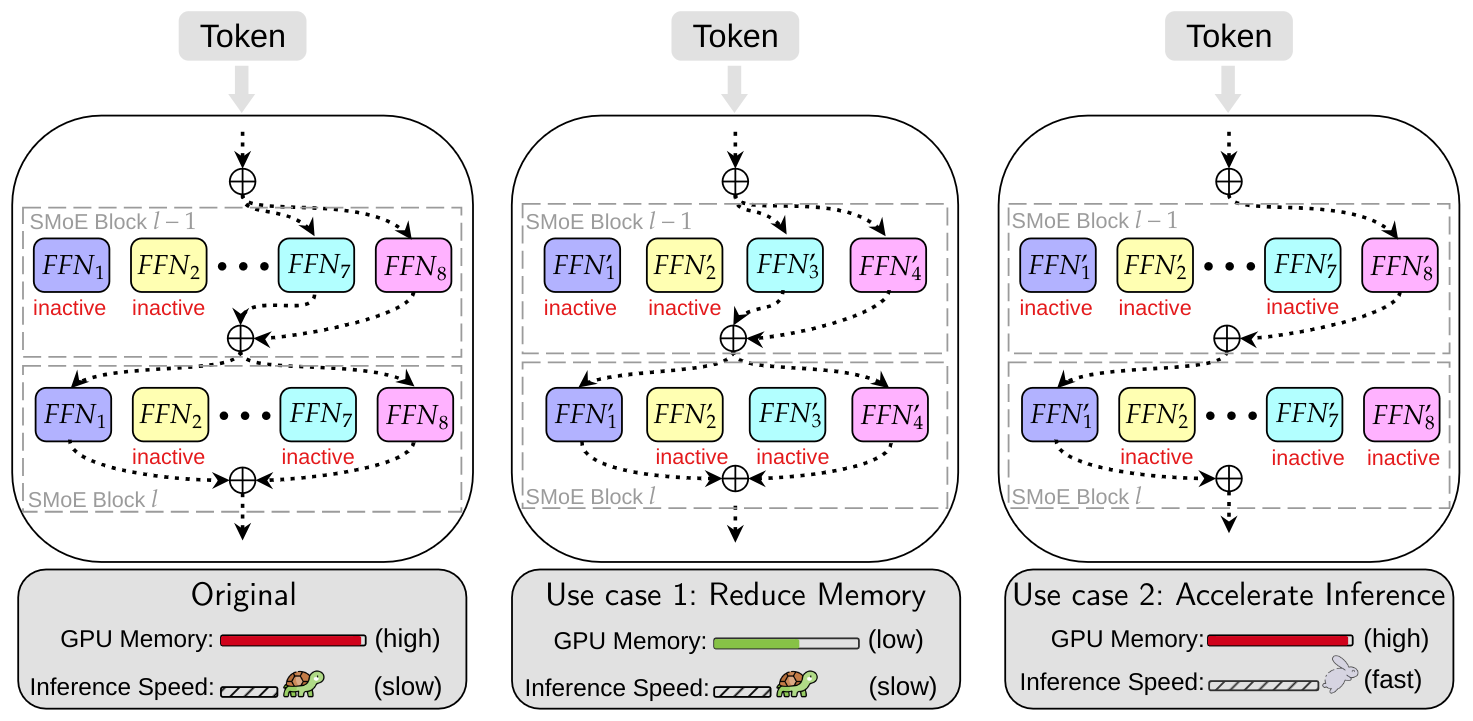 |
Github
Paper |
Diversifying the Expert Knowledge for Task-Agnostic Pruning in Sparse Mixture-of-Experts
Zeliang Zhang, Xiaodong Liu, Hao Cheng, Chenliang Xu, Jianfeng Gao |
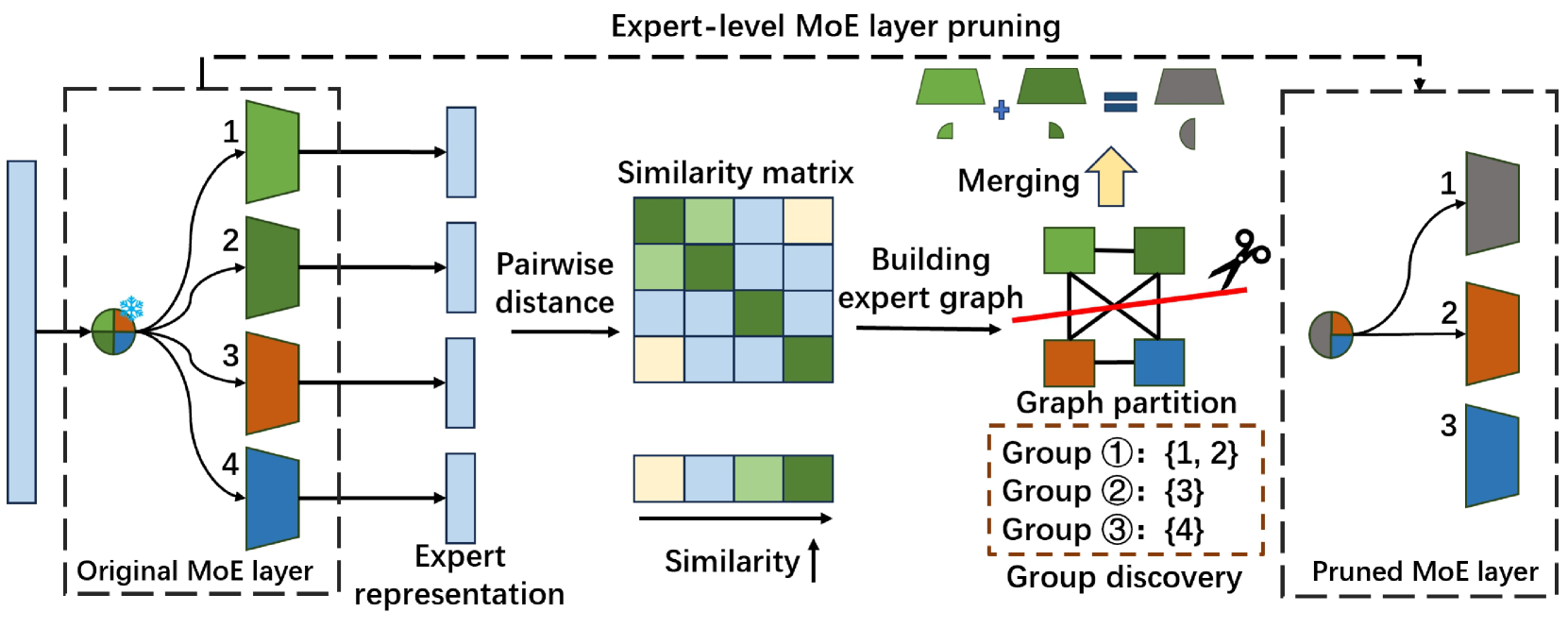 |
Paper |

MC-MoE: Mixture Compressor for Mixture-of-Experts LLMs Gains More
Wei Huang, Yue Liao, Jianhui Liu, Ruifei He, Haoru Tan, Shiming Zhang, Hongsheng Li, Si Liu, Xiaojuan Qi |
 |
Github
Paper |
EPS-MoE: Expert Pipeline Scheduler for Cost-Efficient MoE Inference
Yulei Qian, Fengcun Li, Xiangyang Ji, Xiaoyu Zhao, Jianchao Tan, Kefeng Zhang, Xunliang Cai |
|
Paper |
ExpertFlow: Optimized Expert Activation and Token Allocation for Efficient Mixture-of-Experts Inference
Xin He, Shunkang Zhang, Yuxin Wang, Haiyan Yin, Zihao Zeng, Shaohuai Shi, Zhenheng Tang, Xiaowen Chu, Ivor Tsang, Ong Yew Soon |
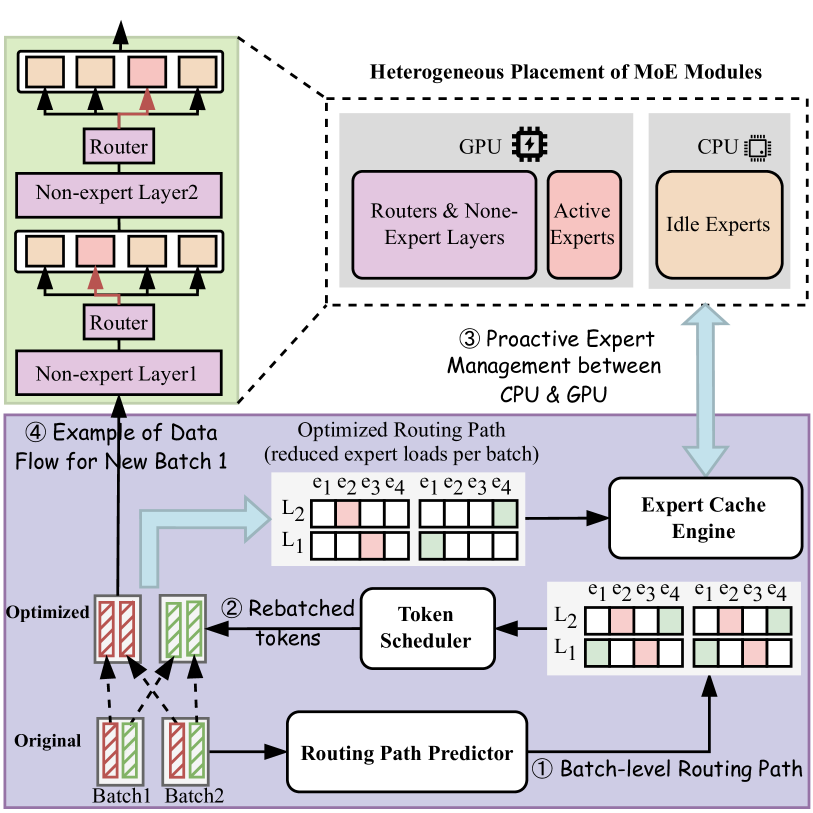 |
Paper |
ProMoE: Fast MoE-based LLM Serving using Proactive Caching
Xiaoniu Song, Zihang Zhong, Rong Chen |
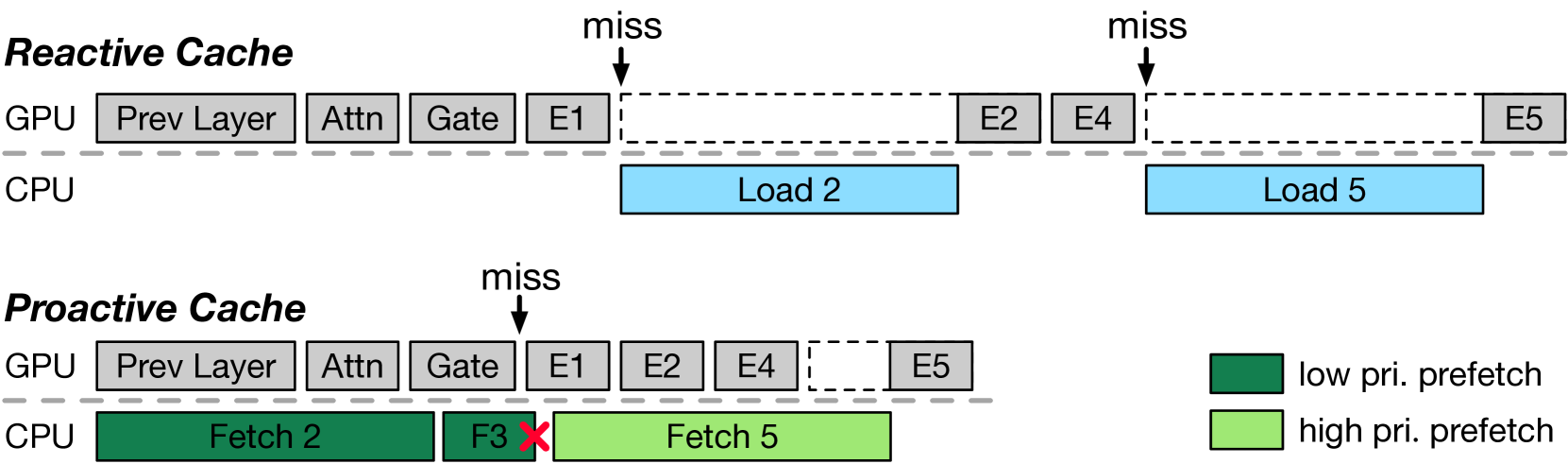 |
Paper |
HOBBIT: A Mixed Precision Expert Offloading System for Fast MoE Inference
Peng Tang, Jiacheng Liu, Xiaofeng Hou, Yifei Pu, Jing Wang, Pheng-Ann Heng, Chao Li, Minyi Guo |
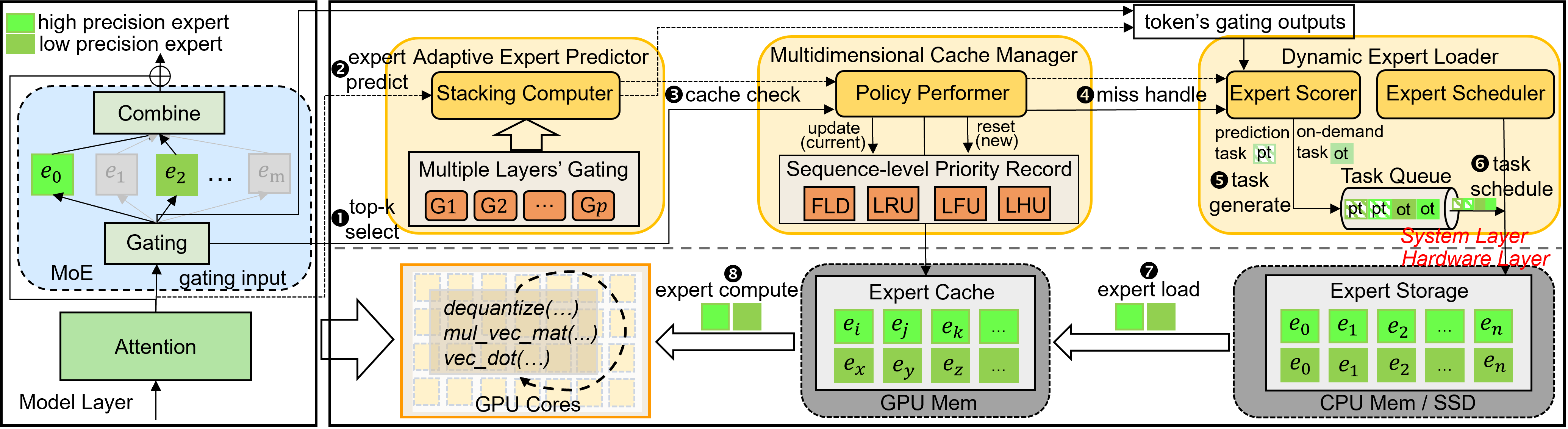 |
Paper |

MoNTA: Accelerating Mixture-of-Experts Training with Network-Traffc-Aware Parallel Optimization
Jingming Guo, Yan Liu, Yu Meng, Zhiwei Tao, Banglan Liu, Gang Chen, Xiang Li |
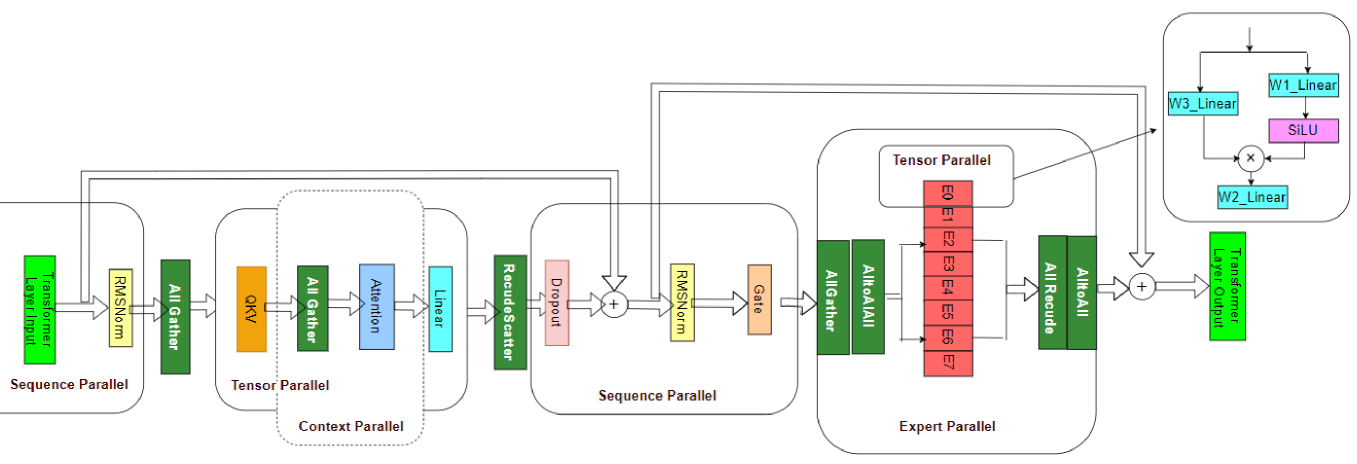 |
Github
Paper |

MoE-I2: Compressing Mixture of Experts Models through Inter-Expert Pruning and Intra-Expert Low-Rank Decomposition
Cheng Yang, Yang Sui, Jinqi Xiao, Lingyi Huang, Yu Gong, Yuanlin Duan, Wenqi Jia, Miao Yin, Yu Cheng, Bo Yuan |
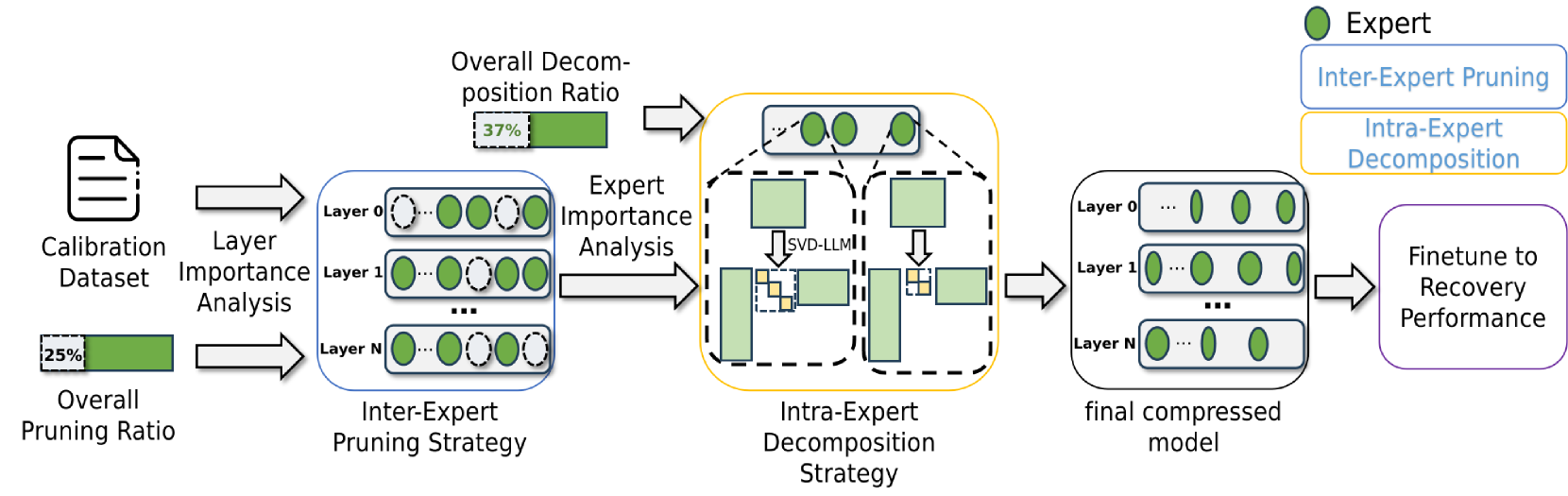 |
Github
Paper |
Mixture of Cache-Conditional Experts for Efficient Mobile Device Inference
Andrii Skliar, Ties van Rozendaal, Romain Lepert, Todor Boinovski, Mart van Baalen, Markus Nagel, Paul Whatmough, Babak Ehteshami Bejnordi |
 |
Paper |
Mixture of Cache-Conditional Experts for Efficient Mobile Device Inference
Andrii Skliar, Ties van Rozendaal, Romain Lepert, Todor Boinovski, Mart van Baalen, Markus Nagel, Paul Whatmough, Babak Ehteshami Bejnordi |
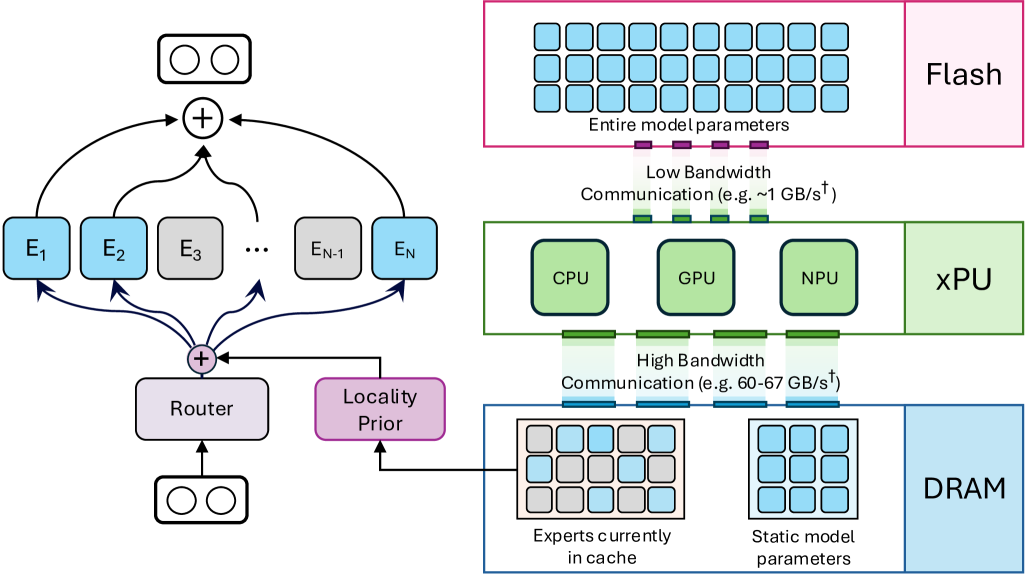 |
Paper |

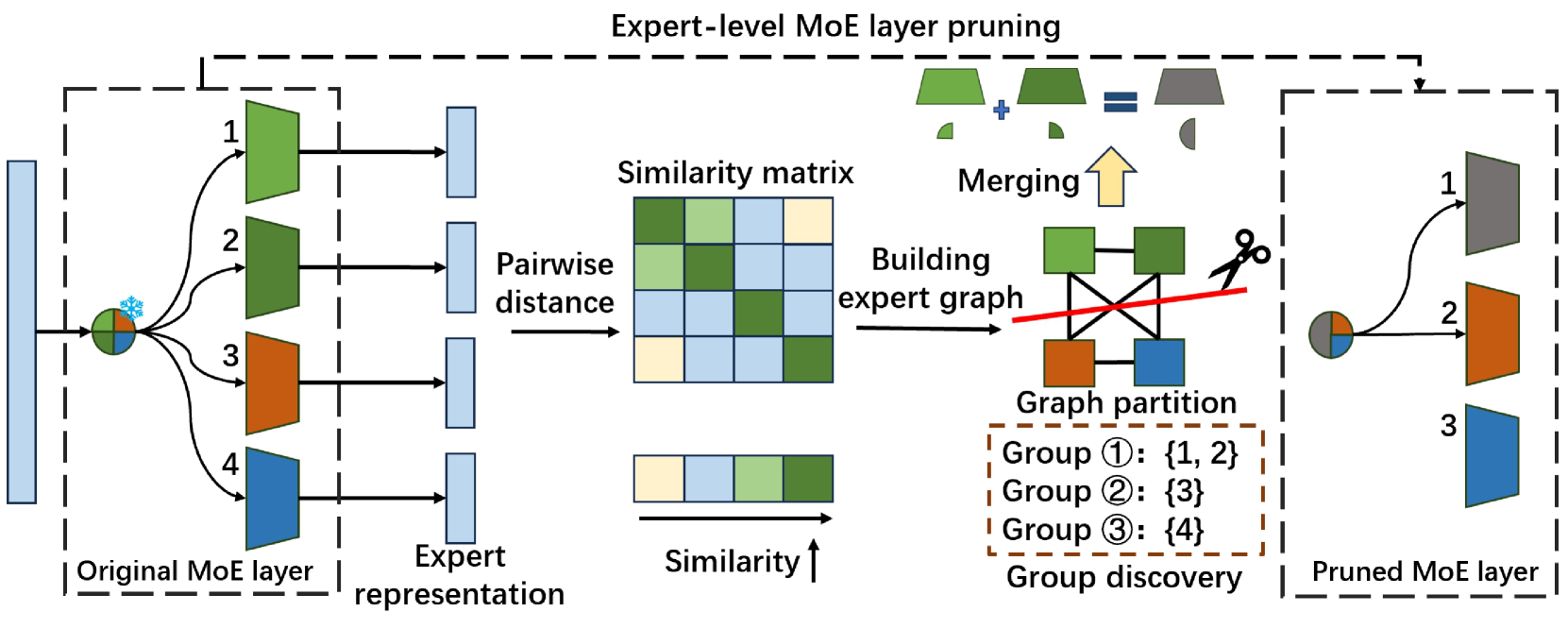
Condense, Don't Just Prune: Enhancing Efficiency and Performance in MoE Layer Pruning
Mingyu Cao, Gen Li, Jie Ji, Jiaqi Zhang, Xiaolong Ma, Shiwei Liu, Lu Yin |
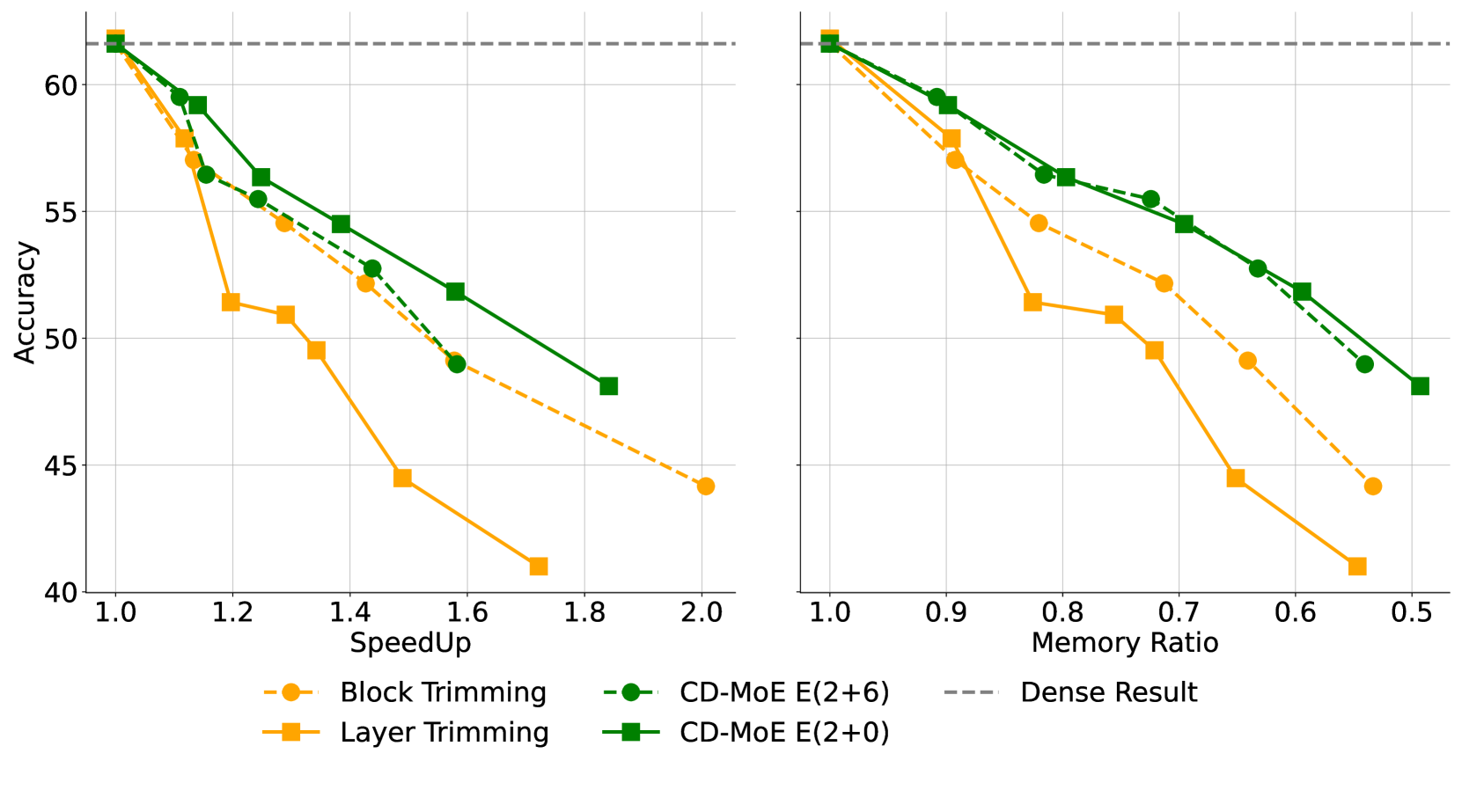 |
Github
Paper |