Unicode (Юникод) – промышленный стандарт кодирования текста и символов в вычислительной технике. Разработан для унификации кодирования всех существующих языков на любых платформах и языках разработки ПО. Поддерживает написание практически всех существующих языков, множество Emoji (эмодзи) и спецсимволы. Поддерживает до ~1,1 млн. уникальных символов.
В 60-е годы в США был разработан стандарт ASCII (American Standard Code for Information Interchange) ставший основным видом кодирования символов для компьютеров, телеграфов и телекоммуникационного оборудования. Он был задуман как замена устаревшим и разнообразным форматам кодирования символов оставшихся со времён развития телеграфа. Изначально ASCII являлась 7-битной и позволяла кодировать 128 символов (27=128). Которые включали в себя управляющие символы, цифры, латинские буквы и знаки препинания.
Изначально ASCII являлась 7-битной и позволяла кодировать 128 символов (27=128). Которые включали в себя управляющие символы, цифры, латинские буквы и знаки препинания.
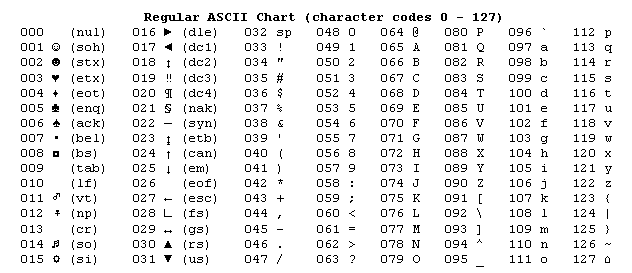
Общие символы ASCII

Основной недостаток ASCII заключался в том, что он поддерживал только латинский алфавит. Это затрудняло его использование с другими языки. Особенно не европейской группы. Проблема была частично решена за счёт расширения кодирования до 8-битного, что позволяет кодировать 256 символов (28=256). Первые 128 символов единые для любой кодировки, а оставшиеся с 129 по 256 используются под национальные символы.
Из-за ограничения в 256 символов под практически каждый язык требуется создавать отдельную кодировку. Для многих языков есть множество вариантов кодировок (например, для русского языка встречается 5 кодировок). Кодировки между системами требуется согласовывать между собой, что создаёт множество проблем при неправильной настройке кодировок на одной из сторон.
ASCII не подходит для языков с иероглифами (китайский, японский и пр.), т.к. кодирования в 256 символов не достаточно для них.
В конце 80-х появился новый формат кодирования Unicode, который объединил все языки в одну кодировку за счёт увеличения разрядности до 4-х байт (231 = ~2.1 млрд.). Но в начале 90-х Unicode не получил популярности по причине увеличения объема занимаемой и передаваемой текстовой информации. Стоимость хранения и передачи данных на тот момент была в сотни раз выше, чем сегодня.
Например, время скачивание текстовой версии произведения “Война и мир” (~3млн. символов) в начале 2000-х через модем на скорости 33600 бит/c (типовая скорость для того времени) составит 12 минут, а в формате Unicode (UTF-32) 48 минут. Сегодня подобное скачивание составит пару секунд.
Начиная с середины 2000-х стоимость накопителей и интернета стремительно падает, а скорость растёт. Интернет становится мультиязычным и Unicode постепенно увеличивает свою долю в программах и интернете. Минусы Unicode становятся не так критичны, как его достоинства для мультиязычного ИТ-мира.
На сегодняшний день большинство сайтов и программ используют Unicode. Стандарт Unicode расширяется с каждым годом и включает в себя всё больше языков и символов.
Каждый символ в Unicode имеет свой уникальный номер. Он выглядит как U+#####. Например, U+0055 это латинская буква S. Порядковые номера символов сгруппированы по смыслу или языку (например, с 0020 по 007F – основные символы латиницы).

Группировки Unicode (первые группы)

На более высоком уровне нумерация делится на 16 плоскостей по 65536 (216) символов. Плоскость обозначает собой “редкость” использования символов и служит в первую очередь для разработчиков шрифтов. Например, плоскость 0 это базовые языки и любой шрифт должен их поддерживать. Плоскость 2 это редкие иероглифические символы которые могут потребовать только в узкоспециализированных задачах и не требуются для большинства шрифтов.
В Unicode символ кодируется 1-4 байтами в зависимости от позиции символа в таблице и выбранной кодировки. Основные форматы кодирования описаны ниже.
Символ кодируется от 1 до 4 байт в зависимости от порядкового номера символа. Первые биты символа обозначают количество байт в символе и позволяет понять из какого диапазона данный символ:
| Диапазон | Байт | Описание |
|---|---|---|
| U-0000 – U-007F | 1 | Базовый латинский алфавит, ASCII, базовые знаки препинания |
| U-0080 – U-07FF | 2 | Национальные и расширенные алфавиты, дополнительные знаки препинания |
| U-0800 – U-FFFF | 3 | Иероглифические и редкие алфавиты, специфические математические символы |
| U-10000 – U-10FFFF | 4 | Мёртвые языки, очень редкие иероглифы, редкие и устаревшие символы |
Обладает обратной совместимостью с ASCII по базовым латинским символам. Т.е. первые 128 символов кодируются аналогично для ASCII и UTF-8.
Эффективен для латинского алфавита, т.к. символы в этом диапазоне занимают 1 байт.
- Оптимальный размер “байт на символ” в случае использования распространенных не иероглифических языков.
- Фиксированный порядок байт.
- Распространенность (>95% веб-сайтов и программ).
- Совместимость с ASCII по первым 128 символам.
- Неэффективное использование пространства при использование иероглифических языков. (~+25% против UTF-16)
Символ кодируется от 2 до 4 байт в зависимости от порядкового номера символа. Диапазон от U+0000 до U+FFFF кодируется 2 байтами, диапазон от U+10000 до U+10FFFF кодируется 4 байтами.
- Более эффективное использование пространства для иероглифических языков, чем у UTF-8/32.
- Неэффективное использование пространства при использование латинского языка.
- В некоторых ситуация нельзя отличить от UTF-32.
Символ содержит в себе 4 байта (31 бит) и позволяет кодировать до ~2.1 млрд. символов (для совместимости с UTF-16 ограничено ~1.1 млн.). Имеет фиксированную длину в 4 байта (02 46 8A CE). Практически не используется на практике, по причине избыточности. В данный момент в Unicode присутствует ~140.000 символов, что составляет <15% от доступного объёма. Изредка используется в API или узкоспециализированных задачах когда требуется фиксированная длина байт. Основной плюс – возможно непосредственной индексации символов, т.к. длина символа всегда 4 байта. Это даёт прирост скорости в некоторых операциях.
- Фиксированная длина символа
- Быстрая индексация
- Неэффективное использования пространства, избыточность. Большая часть содержимого данных будет состоять из нулей.
- В некоторых случая нельзя отличить от UTF-16
В UTF-16/32 существует два варианта последовательности байт. LE (little-endian) и BE (big-endian). В случае LE порядок байт идёт младшего к старшему (67 45 23 01), в случае BE от старшего к младшему (01 23 45 67). Для идентификации последовательности байт используется метка порядка байтов (BOM, byte order mark) которая выставляется первым символом документа (символ U+FEFF). Если в начале текста прочитано FE FF – текст в формате UTF-16 BE, FF FE – формат UTF-16 LE, EF BB BF – UTF-8. Данные символы зарезервированы в Unicode под обозначение порядка байт. По умолчанию используется LE.
В UTF-8 порядок байт всегда LE и символ BOM обычно не используется. Это также позволяет отличить UTF-8 от UTF-16/32.
Примеры кодирования:
| Символ | Номер | Кодировка | Запись в HEX |
|---|---|---|---|
| S | U+0053 | UTF-8 | 53 |
| UTF-16 | 0053 | ||
| UTF-32 | 00000053 | ||
| Й | U+0419 | UTF-8 | D0 99 |
| UTF-16 | 0419 | ||
| UTF-32 | 00000419 | ||
| 갦 | U+AC26 | UTF-8 | EA B0 A6 |
| UTF-16 | AC26 | ||
| UTF-32 | 0000AC26 | ||
| 𐌸 | U+10338 | UTF-8 | F0 90 8C B8 |
| UTF-16 | D800 DF38 | ||
| UTF-32 | 00010338 |
Для текстового редактора и если продукт разрабатывается для стран использующих иероглифы, то есть смысл использовать UTF-16. Это позволит более эффективно использовать пространство, т.к. большинство символов будет умещаться в 2 байта, когда в UTF-8 они будут занимать 3 байта.
В остальных случаях для текстового редактора кодировка UTF-8 является предпочтительней. В случае использования латинского алфавита символы будут занимать 1 байт против 2 байт у UTF-16. В остальных случаях аналогично UTF-16 по 2 байта. И только в редких случаях использования редких иероглифов UTF-8 будет занимать 3 байта вместо 2 байт у UTF-16.
Дополнительным плюсом UTF-8 является совместимость документов с другими текстовыми редакторами. Любой текстовый редактор с поддержкой Unicode понимает UTF-8, но поддержка UTF-16 и UTF-32 присутствует лишь у небольшой части текстовых редакторов.
Данный вывод не подходит для принятия решения использования кодировок в API и БД.
https://unicode-table.com - таблица всех символов Unicode
http://qaz.wtf/u/show.cgi - расшифровщик глифов (combining character)