Welcome to STAT 201 - Statistical Inference for Data Science!¶
Lecture 1¶

Photos/Images by #WOCinTech/#WOCinTech Chat (CC-BY)
-Attribution: these slides are adapted from Vincenzo Coia's slides
- -Teaching Team¶
Instructors:¶
-
-
- Lasantha Premarathna -
TAs:¶
-
-
- Daniel Zhezlov -
- Yifan Yin -
- Marc Wettengel -
- Abhinav Kansal -
Office Hours (online):¶
Zoom link for online office hours can be found through the Zoom tab in the Canvas page. Times are in Pacific Time.
--
-
- Tue: Marc (9am - 10am) -
- Wednesday: Lasantha (11am - 12pm) -
- Thursday: Yifan (10am - 11am) -
- Friday: Daniel (10am - 11am) -
- Friday: Abhinav (5:30pm - 6:30pm) -
Course Guidelines¶
Visit and abide by the course Code of Conduct.
-Basically: be good to each other.
--
-
- Help other students if they're struggling -
- Respect others while they speak; don't interrupt -
- Come to class prepared -
- Value diversity, respect everyone's ideas -
- Be aware of how much you are contributing to class
-
-
- If you tend to speak often, allow others to speak -
- If you tend to stay quiet, challenge yourself to share ideas so others can learn from you -
- - Listen actively, and be mindful of each other's differences -
- Avoid demeaning, devaluing, or "putting down" people -
- Trust that people are doing the best they can. Be as patient as possible with the learning processes of others -
- Respect your teaching team, and expect professionalism and respect in return -
Brief Canvas walkthrough:¶
https://canvas.ubc.ca/courses/110110
-Read the Course Website pages carefully!
- -Lecture/Tutorial Structure¶
-
-
- Readings for each class are posted in the class schedule. -
- I will kick off each lecture with a little intro -
In each week you will have two graded assignments:
--
-
- Mondays:
-
-
- Lecture worksheet run by instructor -
- - Wednesdays:
-
-
- Tutorial worksheet run by TAs -
-
-- Mondays:
All assignments will be due Saturday 11:59pm
-
-- Try, if you can, to complete your assignments throughout the week -
- I do not recommend you leaving all two assignments to the last minute! -
Note about the schedule on SSC¶

IGNORE the STAT 201 T1A Tue 8:00-9:00
-We will have our tutorials on Wednesdays
- -Main Evaluations¶
-
-
- 2 midterms and a final exam -
- Midterm 1 and midterm 2 will take place during class and will be in person -
- a group project -
Collaborate!¶
-
-
- Talk to each other (in class, on Piazza) as you work through the worksheets and tutorials -
⭐ BONUS 1% to the Top 10 Student Answerers
--
-
- Group project at middle-end of course -
- You will be working with the same people every week
-
-
- get to know one another; let's build a community where we help each other learn both during and outside of class! -
-
Icebreaker group activity¶
-
-
- Make sure you are sitting with your group mates
-Check your project group on Canvas (under "People") and refer to the seating plan on Canvas.
- - Introduce yourselves to your groupmates -
- As a group, find one thing that all members of your group have in common. -
- Each member of the group say: what is your best study tip? -

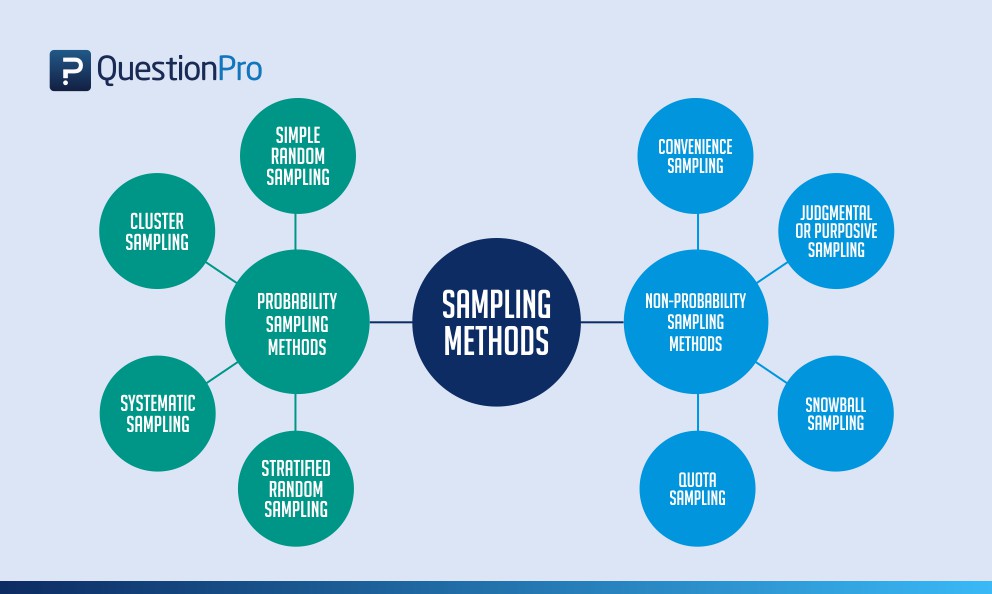
Today's lecture: Sampling¶
-Idea behind the course¶
Suppose you want to know the average grade for all students who have taken this course. -You survey some STAT201 students, calculate the average grade, and present the number. -What’s the problem with this?
-
Image source: Carnegie Mellon University open learning statistics course
- --
-
- It is impossible to collect data from everyone in our population -
- We take a sample, and then make inferences about the whole population -
- But our sample is not perfect, it comes with errors -
I am interested in the proportion of red balls in this bowl¶
 -
-image source: Modern Dive by Kim & McConville
- -We will denote our population parameter (proportion of red balls) as : $p$
 -
- -
- -
-We will denote our point estimate (proportion of red balls in our sample) as $\hat{p}$
 -
-What do you think our sample distribution woud look like?
hist(rbinom(n = 50, size = 1, p = 0.34), main = "Sample distribution", col=c("white","white","white","white","red"),labels = c("33","","","","17"))
- -
-What do you think?¶
-
-
- Can I conclude that the proportion of red balls in our bowl (i.e., population parameter) is approximately 34%? -
- What other information that you would like to know? -
 -
--
-
- No, because the point estimate 0.34 was computed from a single sample which might not be generalized to the whole population -
- We need to measure the margin of error around our point estimate -
Let's take multiple samples¶
-
-
- Use the shovel to remove 50 balls each. -
- Compute the proportion of balls that are red. -
- Return the balls into the bowl. -
- Mix the contents of the bowl a little
-  -
-
-
-
| Sample | -Point estimate $\hat{p}$ | -
|---|---|
| 1 | -0.323 | -
| 2 | -0.332 | -
| 3 | -0.341 | -
| ... | -- |
| 33 | -0.333 | -
 -
-This is called a sampling distribution of point estimates¶
Can you distinguish a sampling distribution from a sample distribution?
- -As we collect more samples, the expected value of our point estimates = population parameter -$$E(\hat{p}) = p$$
-But we never have the resources to collect infinite samples in real life, if we do, what's the point of doing statistical inference anyway?
- -How can we quantify the errors of point estimates?¶
-We compute the standard deviation of point estimates (aka standard error!)
-$$\sigma_{\hat{p}} = \frac{\sigma}{\sqrt{n}}$$ --
-
- $\sigma_{\hat{p}}$: standard deviation of point estimates -
- $\sigma$: standard deviation of population (given) -
- n: sample size -
Can you notice the relationship between standard error and sample size? We will explore this more in week 2
- -Terminology¶
Imagine we are interested in estimating the average income of UBC graduates within 5 year in Canada. We sent out 3 surveys (each survey to 200 random UBC alumni). Discuss with your classmates and define the following terms & give example when appropriate:
--
-
- Population -
- Sampling -
- Sample -
- Sample distribution -
- Point estimate (sample statistics) -
- Sampling distribution -
- Standard error -
## Review R code for sampling
-set.seed(201)
-library(infer)
-library(tidyverse)
-
-student_population <- tibble(student = 1:10000, grade = rnorm(n = 10000, mean = 70, sd = 10))
-
-I'll begin with a quick Jupyter notebook demo using your first assignment, Worksheet 1
- -Now it's your turn!¶
-
-
- Navigate to Canvas, open
worksheet_01
-
If you get stuck:
--
-
- Discuss with your neighbours, the TAs & Instructors, and consult the textbook reading to help you get unstuck when needed! -
- Ask your group mates if you need help with any questions -
- The TAs and myself will walk around and answer questions -
Summary¶
-
-
- Understand the process of statistical inference -
Understand the terminologies in statistical inference
--
-
- Population -
- Sample -
- Sampling -
- Point estimate (sample statistics) -
- Sample distribution -
- Sampling distribution -
- Standard error -
-
Glossary¶
| Unknown population parameter | -Symbol | -Point estimates | -Symbol | -
|---|---|---|---|
| Population mean | -$\mu$ | -Sample mean | -$\bar{x}$ | -
| Population standard deviation | -$\sigma$ | -Sample standard deviation | -$s$ | -
| Population proportion | -$p$ | -Sample proportion | -$\hat{p}$ | -
What did you learn today?¶
-
-
-
-
-
-
 +
+
+
+
+
+ +
+