图像分类是计算机视觉的基础算法之一,是企业应用中最常见的算法,也是许多 CV 应用的重要组成部分。近年来,骨干网络模型发展迅速,ImageNet 的精度纪录被不断刷新。然而,这些模型在实用场景的表现有时却不尽如人意。一方面,精度高的模型往往体积大,运算慢,常常难以满足实际部署需求;另一方面,选择了合适的模型之后,往往还需要经验丰富的工程师进行调参,费时费力。PaddleClas 为了解决企业应用难题,让分类模型的训练和调参更加容易,总结推出了实用轻量图像分类解决方案(PULC, Practical Ultra Lightweight Classification)。PULC融合了骨干网络、数据增广、蒸馏等多种前沿算法,可以自动训练得到轻量且高精度的图像分类模型。
PULC 方案在人、车、OCR等方向的多个场景中均验证有效,用超轻量模型就可实现与 SwinTransformer 模型接近的精度,预测速度提高 40+ 倍。
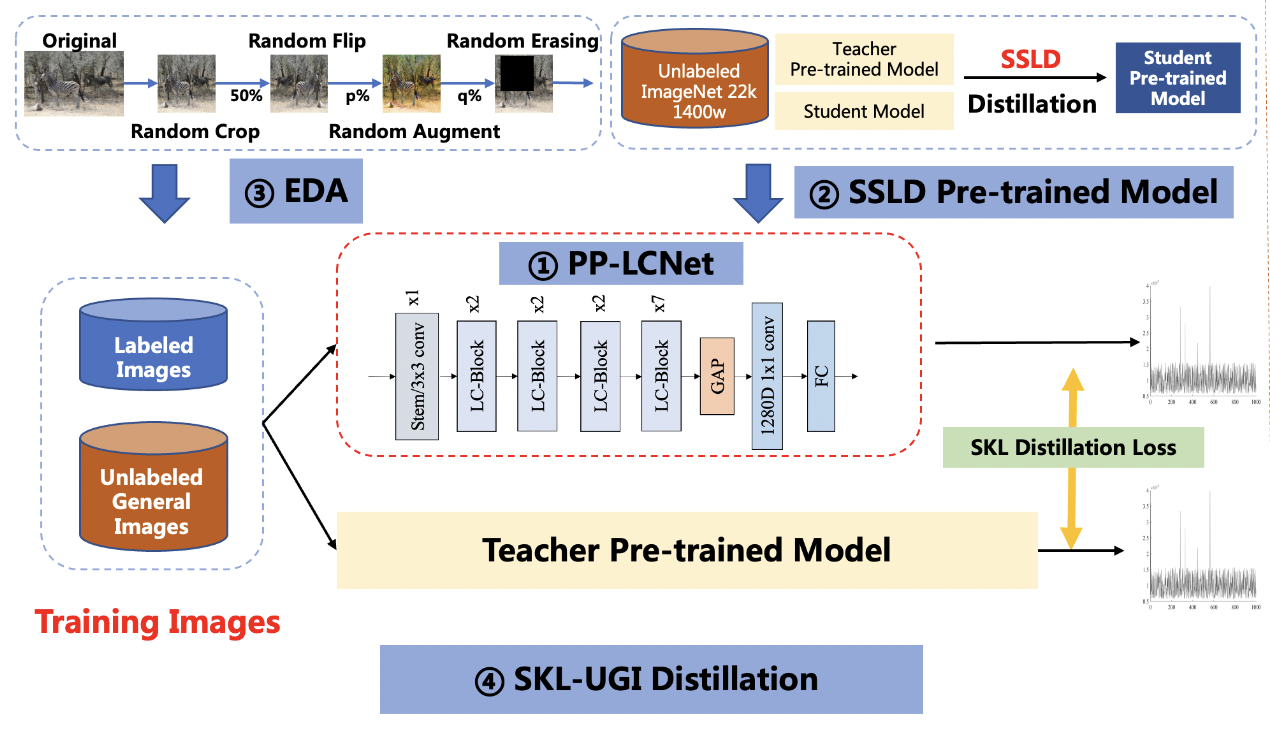
方案主要包括 4 部分,分别是:PP-LCNet轻量级骨干网络、SSLD预训练权重、数据增强策略集成(EDA)和 SKL-UGI 知识蒸馏算法。此外,我们还采用了超参搜索的方法,高效优化训练中的超参数。下面,我们以有人/无人场景为例,对方案进行说明。
备注:针对一些特定场景,我们提供了基础的训练文档供参考,例如有人/无人分类模型等,您可以在这里找到这些文档。如果这些文档中的方法不能满足您的需求,或者您需要自定义训练任务,您可以参考本文档。
PaddleClas 使用 txt 格式文件指定训练集和测试集,以有人/无人场景为例,其中需要指定 train_list.txt 和 val_list.txt 当作训练集和验证集的数据标签,格式形如:
# 每一行采用"空格"分隔图像路径与标注
train/1.jpg 0
train/10.jpg 1
...
如果您想获取更多常用分类数据集的信息,可以参考文档可以参考 PaddleClas 分类数据集格式说明 。
如果您已经有实际场景中的数据,那么按照上节的格式进行标注即可。这里,我们提供了一个快速生成数据的脚本,您只需要将不同类别的数据分别放在文件夹中,运行脚本即可生成标注文件。
首先,假设您存放数据的路径为./train,train/ 中包含了每个类别的数据,类别号从 0 开始,每个类别的文件夹中有具体的图像数据。
train
├── 0
│ ├── 0.jpg
│ ├── 1.jpg
│ └── ...
└── 1
├── 0.jpg
├── 1.jpg
└── ...
└── ...tree -r -i -f train | grep -E "jpg|JPG|jpeg|JPEG|png|PNG" | awk -F "/" '{print $0" "$2}' > train_list.txt其中,如果涉及更多的图片名称尾缀,可以增加 grep -E后的内容, $2 中的 2 为类别号文件夹的层级。
备注: 以上为数据集获取和生成的方法介绍,这里您可以直接下载有人/无人场景数据快速开始体验。
进入 PaddleClas 目录。
cd path_to_PaddleClas
进入 dataset/ 目录,下载并解压有人/无人场景的数据。
cd dataset
wget https://paddleclas.bj.bcebos.com/data/PULC/person_exists.tar
tar -xf person_exists.tar
cd ../PULC 采用了轻量骨干网络 PP-LCNet,相比同精度竞品速度快 50%,您可以在PP-LCNet介绍查阅该骨干网络的详细介绍。 直接使用 PP-LCNet 训练的命令为:
export CUDA_VISIBLE_DEVICES=0,1,2,3
python3 -m paddle.distributed.launch \
--gpus="0,1,2,3" \
tools/train.py \
-c ./ppcls/configs/PULC/person_exists/PPLCNet_x1_0_search.yaml为了方便性能对比,我们也提供了大模型 SwinTransformer_tiny 和轻量模型 MobileNetV3_small_x0_35 的配置文件,您可以使用命令训练:
SwinTransformer_tiny:
export CUDA_VISIBLE_DEVICES=0,1,2,3
python3 -m paddle.distributed.launch \
--gpus="0,1,2,3" \
tools/train.py \
-c ./ppcls/configs/PULC/person_exists/SwinTransformer_tiny_patch4_window7_224.yamlMobileNetV3_small_x0_35:
export CUDA_VISIBLE_DEVICES=0,1,2,3
python3 -m paddle.distributed.launch \
--gpus="0,1,2,3" \
tools/train.py \
-c ./ppcls/configs/PULC/person_exists/MobileNetV3_small_x0_35.yaml训练得到的模型精度对比如下表。
| 模型 | Tpr(%) | 延时(ms) | 存储(M) | 策略 |
|---|---|---|---|---|
| SwinTranformer_tiny | 95.69 | 95.30 | 107 | 使用 ImageNet 预训练模型 |
| MobileNetV3_small_x0_35 | 68.25 | 2.85 | 1.6 | 使用 ImageNet 预训练模型 |
| PPLCNet_x1_0 | 89.57 | 2.12 | 6.5 | 使用 ImageNet 预训练模型 |
从中可以看出,PP-LCNet 的速度比 SwinTransformer 快很多,但是精度也略低。下面我们通过一系列优化来提高 PP-LCNet 模型的精度。
SSLD 是百度自研的半监督蒸馏算法,在 ImageNet 数据集上,模型精度可以提升 3-7 个点,您可以在 SSLD 介绍找到详细介绍。我们发现,使用SSLD预训练权重,可以有效提升应用分类模型的精度。此外,在训练中使用更小的分辨率,可以有效提升模型精度。同时,我们也对学习率进行了优化。 基于以上三点改进,我们训练得到模型精度为 92.1%,提升 2.6%。
数据增强是视觉算法中常用的优化策略,可以对模型精度有明显提升。除了传统的 RandomCrop,RandomFlip 等方法之外,我们还应用了 RandomAugment 和 RandomErasing。您可以在数据增强介绍找到详细介绍。 由于这两种数据增强对图片的修改较大,使分类任务变难,在一些小数据集上可能会导致模型欠拟合,我们将提前设置好这两种方法启用的概率。 基于以上改进,我们训练得到模型精度为 93.43%,提升 1.3%。
模型蒸馏是一种可以有效提升小模型精度的方法,您可以在知识蒸馏介绍找到详细介绍。我们选择 ResNet101_vd 作为教师模型进行蒸馏。为了适应蒸馏过程,我们在此也对网络不同 stage 的学习率进行了调整。基于以上改进,我们训练得到模型精度为 95.6%,提升 1.4%。
经过以上方法优化,PP-LCNet最终精度达到 95.6%,达到了大模型的精度水平。我们将实验结果总结如下表:
| 模型 | Tpr(%) | 延时(ms) | 存储(M) | 策略 |
|---|---|---|---|---|
| SwinTranformer_tiny | 95.69 | 95.30 | 107 | 使用 ImageNet 预训练模型 |
| MobileNetV3_small_x0_35 | 68.25 | 2.85 | 1.6 | 使用 ImageNet 预训练模型 |
| PPLCNet_x1_0 | 89.57 | 2.12 | 6.5 | 使用 ImageNet 预训练模型 |
| PPLCNet_x1_0 | 92.10 | 2.12 | 6.5 | 使用 SSLD 预训练模型 |
| PPLCNet_x1_0 | 93.43 | 2.12 | 6.5 | 使用 SSLD 预训练模型+EDA 策略 |
| PPLCNet_x1_0 | 95.60 | 2.12 | 6.5 | 使用 SSLD 预训练模型+EDA 策略+SKL-UGI 知识蒸馏策略 |
我们在其他 8 个场景中也使用了同样的优化策略,得到如下结果:
| 场景 | 大模型 | 大模型精度(%) | 小模型 | 小模型精度(%) |
|---|---|---|---|---|
| 人体属性识别 | Res2Net200_vd | 81.25 | PPLCNet_x1_0 | 78.59 |
| 佩戴安全帽分类 | Res2Net200_vd | 98.92 | PPLCNet_x1_0 | 99.38 |
| 交通标志分类 | SwinTransformer_tiny | 98.11 | PPLCNet_x1_0 | 98.35 |
| 车辆属性识别 | Res2Net200_vd_26w_4s | 91.36 | PPLCNet_x1_0 | 90.81 |
| 有车/无车分类 | SwinTransformer_tiny | 97.71 | PPLCNet_x1_0 | 95.92 |
| 含文字图像方向分类 | SwinTransformer_tiny | 99.12 | PPLCNet_x1_0 | 99.06 |
| 文本行方向分类 | SwinTransformer_tiny | 93.61 | PPLCNet_x1_0 | 96.01 |
| 语种分类 | SwinTransformer_tiny | 98.12 | PPLCNet_x1_0 | 99.26 |
从结果可以看出,PULC 方案在多个应用场景中均可提升模型精度。使用 PULC 方案可以大大减少模型优化的工作量,快速得到精度较高的模型。
在上述训练过程中,我们调节了学习率、数据增广方法开启概率、分阶段学习率倍数等参数。 这些参数在不同场景中最优值可能并不相同。我们提供了一个快速超参搜索的脚本,将超参调优的过程自动化。 这个脚本会遍历搜索值列表中的参数来替代默认配置中的参数,依次训练,最终选择精度最高的模型所对应的参数作为搜索结果。
配置文件 search.yaml 定义了有人/无人场景超参搜索的配置,使用如下命令即可完成超参数的搜索。
python3 tools/search_strategy.py -c ppcls/configs/PULC/person_exists/search.yaml备注:关于搜索部分,我们也在不断优化,敬请期待。
您也可以根据训练结果或调参经验,修改超参搜索的配置。
修改 lrs 中的search_values字段,可以修改学习率搜索值列表;
修改 resolutions 中的 search_values 字段,可以修改分辨率的搜索值列表;
修改 ra_probs 中的 search_values 字段,可以修改 RandAugment 开启概率的搜索值列表;
修改 re_probs 中的 search_values 字段,可以修改 RnadomErasing 开启概率的搜索值列表;
修改 lr_mult_list 中的 search_values 字段,可以修改 lr_mult 搜索值列表;
修改 teacher 中的 search_values 字段,可以修改教师模型的搜索列表。
搜索完成后,会在 output/search_person_exists 中生成最终的结果,其中,除search_res外 output/search_person_exists 中目录为对应的每个搜索的超参数的结果的权重和训练日志文件,search_res 对应的是蒸馏后的结果,也就是最终的模型,该模型的权重保存在output/output_dir/search_person_exists/DistillationModel/best_model_student.pdparams。