
ACG2vec stands for Anime Comics Games to vector. This repository will continuously maintain various deep learning practices and explorations related to the two-dimensional domain.
Online preview (currently includes text search, image search, text-to-image search, and image score prediction):https://cheerfun.dev/acg2vec/
Open-source repository:https://github.com/OysterQAQ/ACG2vec
Demo page frontend open-source repository: https://github.com/wewewe131/acg2vec-frontend
Please kindly give a star to both of the above repositories 🌟🌟🌟.
The current modules include:
- model: Deep neural network model module, currently including:
- acgvoc2vec: A sentence-transformers model fine-tuned on 51 million pairs of sentences extracted from sources like Wikipedia anime list, Moe-Ning Wikipedia, Bangumi, pixiv, AnimeList, etc., for generating feature vectors of two-dimensional related text. It can be used for various downstream tasks such as tag recommendation, tag search, recommendation systems, etc. You can experience it online at Huggingface: https://huggingface.co/OysterQAQ/ACGVoc2vec
- dclip: Fine-tuned clip (ViT-L/14) model using the danburoo2021 dataset. You can experience it online at Huggingface: https://huggingface.co/OysterQAQ/DanbooruCLIP
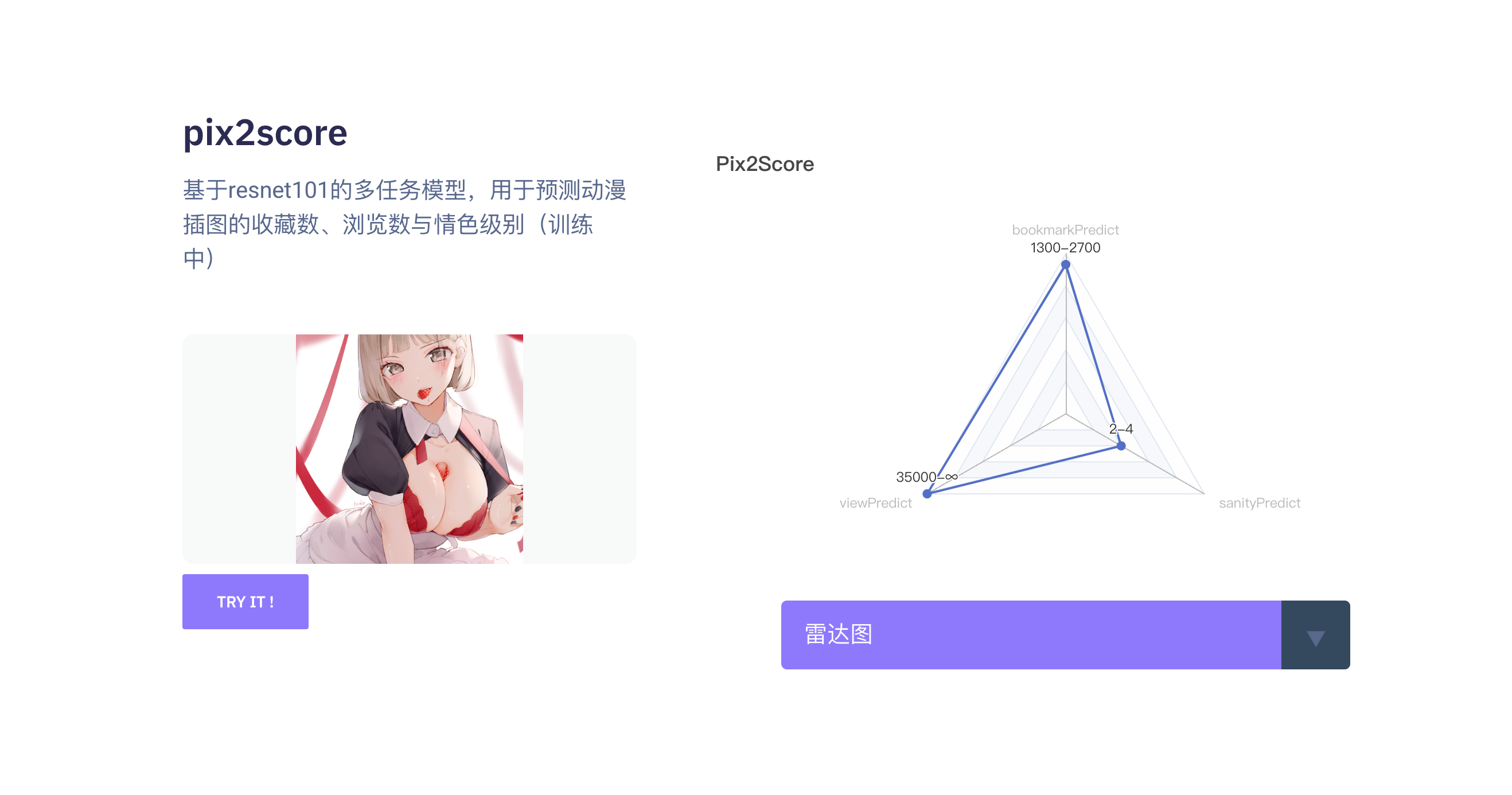
- pix2score: A multi-task model based on resnet101 used for predicting the collection count, view count, and lewdness level of anime illustrations (currently in training).
- illust2vec: A model that extracts image semantic features by removing the prediction head from the DeepDanbooru model and performing mean pooling on the last layer.
- One of the current leading super-resolution models in the field of anime, Real-CUGAN, has been implemented in TensorFlow. This implementation relies on thetfjs framework to achieve adaptive backend support, allowing it to run as an anime super-resolution tool in web browsers.
- webapp: Module providing web services to the outside world. Currently includes out-of-the-box services for predicting anime illustration tags, image search, illustration feature extraction, and text feature extraction.
- docker: Containerized deployment module, including configuration files and resource files required for deployment (work in progress).

An overview of the structure is as follows: The layers from the input layer to activation_96 of DeepDanbooru are used as the feature extractor (with a learning rate set to 1e-5). Each task has a custom ResNet block and a dense prediction head (with a learning rate set to 1e-2).
The prediction tasks are the view count, favorite count, and image view level (text labels can be predicted using the DeepDanbooru model) of pixiv illustrations.
DeepDanbooru is a prediction model based on ResNet, used for predicting label information for anime illustrations. The complete model output dimension is 8000. DeepDanbooru performs well in predicting the multi-label multi-class problem described in the Danbooru dataset, where the label distribution is more balanced, and the descriptions of the images are more accurate. However, the model does not include predictions for image favorite counts and view counts, so it lacks information about the quality of images (generally, illustrations with delicate strokes and exquisite artwork tend to receive more views and favorites).
To address this, the idea is to concatenate the first part of DeepDanbooru with a custom task module to predict favorites and views as proxy tasks. This way, the first part of DeepDanbooru can be fine-tuned with a lower learning rate (while the custom task module uses a normal learning rate) to include quality information of illustrations.
Once the model is fitted, the feature extraction module of the model is taken out separately and appended with an average pooling layer to output a 1024-dimensional vector. This vector serves as the feature vector for the image, which can be used for downstream tasks.
Previously, there was also consideration of fine-tuning CLIP with the Danbooru dataset, but the loss remained unchanged. The reason for this might be related to the efficiency of contrastive learning models, which is highly dependent on batch size. The larger the batch size, the more negative samples correspond to positive samples.
The structure is based on sentence-transformers using its distiluse-base-multilingual-cased-v2 pretrained weights. It was fine-tuned on a dataset of anime-related sentence pairs with a learning rate of 5e-5 using the MultipleNegativesRankingLoss as the loss function.
The dataset mainly includes:
-
Bangumi
- Anime Japanese name - Anime Chinese name
- Anime Japanese name - Synopsis
- Anime Chinese name - Synopsis
- Anime Chinese name - Tags
- Anime Japanese name - Characters
- Anime Chinese name - Characters
- Seiyuu Japanese name - Seiyuu Chinese name
-
Pixiv
- Tag Japanese name - Tag Chinese name
-
AnimeList
- Anime Japanese name - Anime English name
-
Wikipedia
- Anime Japanese name - Anime Chinese name
- Anime Japanese name - Anime English name
- Headings and corresponding text in Chinese, English, and Japanese on detail pages
- Multi-language comparison of synopsis (Chinese, Japanese, and English)
- Anime name - Synopsis in Chinese, Japanese, and English
-
Moegirl
- Anime Chinese name - Synopsis in Chinese
-
Anime Chinese name + Subtitle - Corresponding content
After scraping, cleaning, and processing, the dataset contains 5.1 million text pairs (and is still being continuously increased). The model was trained for 20 epochs with a batch size of 80 to enable the sentence-transformers' weights to adapt to the specific problem space. As a result, it generates text feature vectors that incorporate domain knowledge, where related texts have closer distances in the embedding space. For example, sentences related to a specific anime work or its characters will be closer in the embedding space.
Fine-tuning the CLIP (ViT-L/14) model using the danburoo2021 dataset.
Learning rate is set to 4e-6 and weight decay to 1e-3 for epochs 0-3.
Learning rate is set to 1e-6 and weight decay to 1e-3 for epochs 4-8.
Label preprocessing process:
for i in range(length):
# 加载并且缩放图片
if not is_image(data_from_db.path[i]):
continue
try:
img = self.preprocess(
Image.open(data_from_db.path[i].replace("./", "/mnt/lvm/danbooru2021/danbooru2021/")))
except Exception as e:
#print(e)
continue
# 处理标签
tags = json.loads(data_from_db.tags[i])
# 优先选择人物和作品标签
category_group = {}
for tag in tags:
category_group.setdefault(tag["category"], []).append(tag)
# category_group=groupby(tags, key=lambda x: (x["category"]))
character_list = category_group[4] if 4 in category_group else []
# 作品需要过滤以bad开头的
work_list = list(filter(
lambda e:
e["name"] != "original"
, category_group[3])) if 3 in category_group else []
# work_list= category_group[5] if 5 in category_group else []
general_list = category_group[0] if 0 in category_group else []
caption = ""
caption_2 = None
for character in character_list:
if len(work_list) != 0:
# 去除括号内作品内容
character["name"] = re.sub(u"\\(.*?\\)", "", character["name"])
caption += character["name"].replace("_", " ")
caption += ","
caption = caption[:-1]
caption += " "
if len(work_list) != 0:
caption += "from "
for work in work_list:
caption += work["name"].replace("_", " ")
caption += " "
# 普通标签
if len(general_list) != 0:
caption += "with "
if len(general_list) > 20:
general_list_1 = general_list[:int(len(general_list) / 2)]
general_list_2 = general_list[int(len(general_list) / 2):]
caption_2 = caption
for general in general_list_1:
if general["name"].find("girl") == -1 and general["name"].find("boy") == -1 and len(
re.findall(is_contain, general["name"])) != 0:
caption_2 += general["name"].replace("_", " ")
caption_2 += ","
caption_2 = caption_2[:-1]
for general in general_list_2:
if general["name"].find("girl") == -1 and general["name"].find("boy") == -1 and len(
re.findall(is_contain, general["name"])) != 0:
caption += general["name"].replace("_", " ")
caption += ","
caption = caption[:-1]
else:
for general in general_list:
# 如果标签数据目大于20 则拆分成两个caption
if general["name"].find("girl") == -1 and general["name"].find("boy") == -1 and len(
re.findall(is_contain, general["name"])) != 0:
caption += general["name"].replace("_", " ")
caption += ","
caption = caption[:-1]
# 标签汇总成语句
# tokenize语句
# 返回
# 过长截断 不行的话用huggingface的
text_1 = clip.tokenize(texts=caption, truncate=True)
text_2= None
if caption_2 is not None:
text_2 = clip.tokenize(texts=caption_2, truncate=True)
# 处理逻辑
# print(img)
yield img, text_1[0]
if text_2 is not None:
yield img, text_2[0]Online Experience: Https://cheerfun.org/acg2vec
GitHub Main Repository Address (TensorFlow's savemodel format can be downloaded in the release section): https://github.com/OysterQAQ/ACG2vec (Please give it a star ~)
Based on resnet101, the model is used for classifying the view count, favorite count, and lewdness level of anime illustrations. It was trained on an anime illustration dataset with a learning rate of 1e-3. The input size is 224x224, and the output dictionary is
{
"bookmark_predict": {
"0": "0-10",
"1": "10-30",
"2": "30-50",
"3": "50-70",
"4": "70-100",
"5": "100-130",
"6": "130-170",
"7": "170-220",
"8": "220-300",
"9": "300-400",
"10": "400-550",
"11": "550-800",
"12": "800-1300",
"13": "1300-2700",
"14": "2700-∞"
},
"view_predict": {
"0": "0-500",
"1": "500-700",
"2": "700-1000",
"3": "1000-1500",
"4": "1500-2000",
"5": "2000-2500",
"6": "2500-3000",
"7": "3000-4000",
"8": "4000-5000",
"9": "5000-6500",
"10": "6500-8500",
"11": "8500-12000",
"12": "12000-19000",
"13": "19000-35000",
"14": "35000-∞"
},
"sanity_predict": {
"0": "0-2",
"1": "2-4",
"2": "4-6",
"3": "6-7",
"4": "7-∞"
}
}- Imbalanced Class Proportions: Resolving the issue of imbalanced class proportions by importing the metadata into ClickHouse and finding the n-th quantile to reassign segment ranges.
- Large Dataset: Dealing with the challenge of a large dataset that cannot be loaded into memory at once, the approach used a generator to read the data progressively.
- IO Bottleneck in Training Pipeline: Addressing the IO bottleneck during training caused by data fetching and preprocessing. The solution involved exporting the dataset to the tfrecord binary format, which significantly improved IO performance (achieving approximately 250 MB/s continuous read/write on mechanical hard drives).
- NaN Loss Caused by Mixed Precision Training: Resolving the issue of NaN loss caused by using mixed precision training by adjusting the learning rate.
- Gradient Descent Bias in Multi-task Learning: Handling the bias in gradient descent for multi-task learning, where simple tasks and complex tasks affected the weight updates in the network's later stages. Manual adjustment of loss weights was done to improve the situation, and the PCGrad method was explored, but it did not provide significant improvement.
- NaN Weights during Model Training and Inference: Troubleshooting NaN weights during model training and inference, which was caused by abnormal weights in the batch normalization layers (this also affected model training progress). The issue was addressed by reinitializing the abnormal weights using the corresponding layer initializer and continuing the training. The NaN weights were likely caused by mixed precision training, as detailed in the link provided (https://oysterqaq.com/archives/1463).
- Consistency in Deployment Preprocessing: Ensuring consistency in deployment preprocessing by integrating the base64 image preprocessing layer into the model, eliminating concerns about varying preprocessing behaviors (e.g., resizing) leading to different inference results.
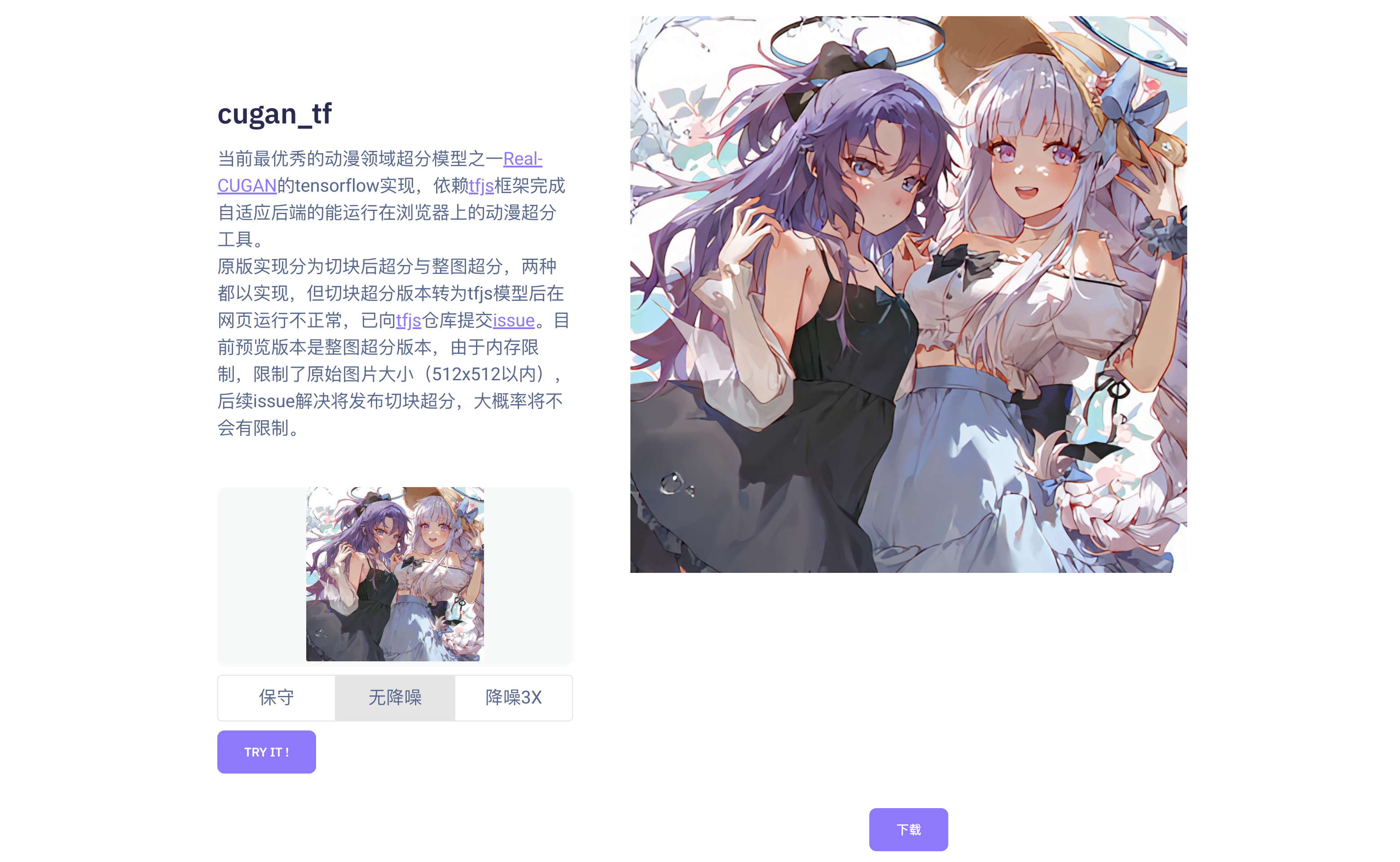
This is the TensorFlow implementation of one of the most outstanding models in the field of anime super-resolution, Real-CUGAN. It relies on the tfjs framework to provide an adaptive backend that can run anime super-resolution in web browsers.
The original implementation includes both chunk-based super-resolution and full-image super-resolution. Both have been implemented, but the chunk-based super-resolution version, when converted to a tfjs model, does not run correctly on web pages. An issue has been raised in the tfjs repository regarding this problem. The current preview version is the full-image super-resolution, which has limitations on the original image size (up to 512x512) due to memory constraints. The chunk-based super-resolution will be released after the issue is resolved and is expected to have no such limitations.
- Default Dimension Order for Images: TensorFlow uses NHWC (batch size, height, width, channels) while PyTorch uses NCHW (batch size, channels, height, width). The convolution weight dimensions also differ.
- Custom Padding for Transposed Convolution in TensorFlow: In TensorFlow, set the padding of Conv2DTranspose layers to 0 and manually crop the output using slice.
- tf.pad Doesn't Accept Negative Values: Use tf.slice as an alternative.
- Batching with Multiple Input Sizes: This might not have a solution.
- Delay Setting Input Size and Getting Size at Runtime: This is a limitation of TensorFlow's graph mode.
- Translate Python Logical Operations to TensorFlow Conditional Branching APIs.
- TensorArray: TensorArray is a substitute for Python lists in graph mode. TensorArray.write(i, x) works directly in eager mode, but in graph mode, you need to assign the reference to itself.
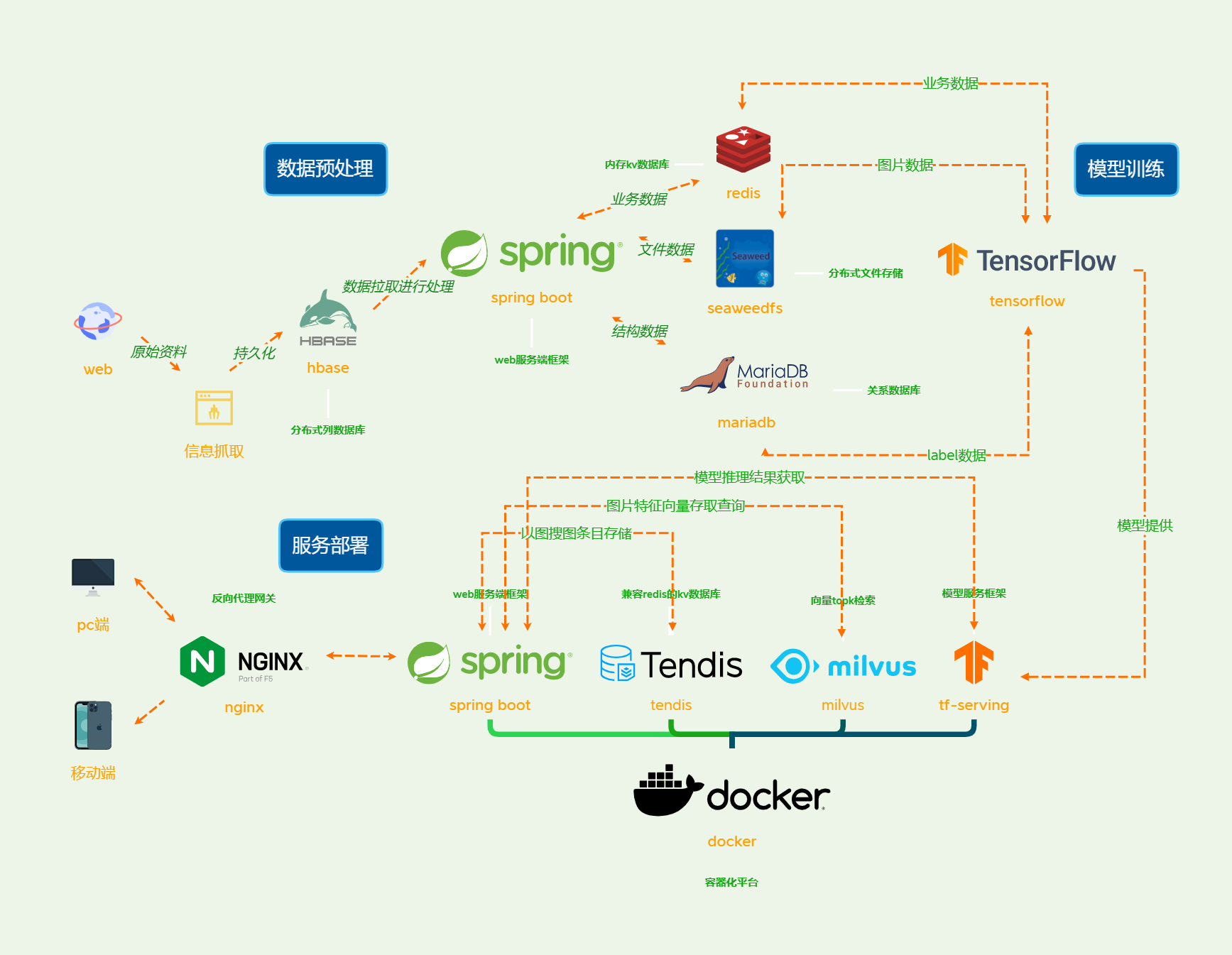
- Tensorflow 2.0 as the model training engine.
- Web service based on Spring Boot.
- Model deployment and forward inference based on TF-serving.
- Top-k approximate vector retrieval based on Milvus.
- Cross-platform deployment based on docker-compose.
- Metadata storage based on Tendis.
Clone this repository and deploy using docker-compose in the docker folder.
git clone https://github.com/OysterQAQ/ACG2vec-docker.git
#Download the model package from the release (1.0.0_for_tf_serving) and unzip it to tf-serving/models folder.
#Deploy using docker-compose
docker-compose up -d基于restful api对外提供服务,以下是api文档(默认端口为8081,可在docker-compose.yaml中修改):
Path: /images/socresByPix2Score
Method: POST
接口描述:
Headers
| 参数名称 | 参数值 | 是否必须 | 示例 | 备注 |
|---|---|---|---|---|
| Content-Type | multipart/form-data | 是 | ||
| Body |
| 参数名称 | 参数类型 | 是否必须 | 示例 | 备注 |
|---|---|---|---|---|
| image | file | 是 |
| 名称 | 类型 | 是否必须 | 默认值 | 备注 | 其他信息 |
|---|---|---|---|---|---|
| message | string | 非必须 | |||
| data | object | 非必须 | |||
| ├─ bookmarkPredict | number [] | 非必须 | item 类型: number | ||
| ├─ | 非必须 | ||||
| ├─ viewPredict | number [] | 非必须 | item 类型: number | ||
| ├─ | 非必须 | ||||
| ├─ sanityPredict | number [] | 非必须 | item 类型: number | ||
| ├─ | 非必须 |
Path: /models/acgvoc2vec/feature
Method: POST
接口描述:
Headers
| 参数名称 | 参数值 | 是否必须 | 示例 | 备注 |
|---|---|---|---|---|
| Content-Type | application/x-www-form-urlencoded | 是 | ||
| Query |
| 参数名称 | 是否必须 | 示例 | 备注 |
|---|---|---|---|
| text | 是 |
| 名称 | 类型 | 是否必须 | 默认值 | 备注 | 其他信息 |
|---|---|---|---|---|---|
| message | string | 非必须 | |||
| data | number [] | 非必须 | item 类型: number | ||
| ├─ | 非必须 |
Path: /models/dclip_text/feature
Method: POST
接口描述:
Headers
| 参数名称 | 参数值 | 是否必须 | 示例 | 备注 |
|---|---|---|---|---|
| Content-Type | application/x-www-form-urlencoded | 是 | ||
| Query |
| 参数名称 | 是否必须 | 示例 | 备注 |
|---|---|---|---|
| text | 是 |
| 名称 | 类型 | 是否必须 | 默认值 | 备注 | 其他信息 |
|---|---|---|---|---|---|
| message | string | 非必须 | |||
| data | number [] | 非必须 | item 类型: number | ||
| ├─ | 非必须 |
Path: /images/labelsByDeepDanbooru
Method: POST
接口描述:
Headers
| 参数名称 | 参数值 | 是否必须 | 示例 | 备注 |
|---|---|---|---|---|
| Content-Type | multipart/form-data | 是 | ||
| Body |
| 参数名称 | 参数类型 | 是否必须 | 示例 | 备注 |
|---|---|---|---|---|
| image | file | 是 |
| 名称 | 类型 | 是否必须 | 默认值 | 备注 | 其他信息 |
|---|---|---|---|---|---|
| message | string | 非必须 | |||
| data | string [] | 非必须 | item 类型: string | ||
| ├─ | 非必须 |
Path: /models/illust2vec/feature
Method: POST
接口描述:
Headers
| 参数名称 | 参数值 | 是否必须 | 示例 | 备注 |
|---|---|---|---|---|
| Content-Type | multipart/form-data | 是 | ||
| Body |
| 参数名称 | 参数类型 | 是否必须 | 示例 | 备注 |
|---|---|---|---|---|
| image | file | 是 |
| 名称 | 类型 | 是否必须 | 默认值 | 备注 | 其他信息 |
|---|---|---|---|---|---|
| message | string | 非必须 | |||
| data | number [] | 非必须 | item 类型: number | ||
| ├─ | 非必须 |
本项目离不开以下开源项目
- DeepDanbooru
- sentence-transformers
- Milvus
- TensorFlow
- Keras
- Spring Boot
- SeaweedFS
- TF-serving
- Tendis
- Docker
