"DatasetDM: Synthesizing Data with Perception Annotations Using Diffusion Models" Arxiv, 2023 Aug
⚠️ paper code website paper local pdf直接看 website ok
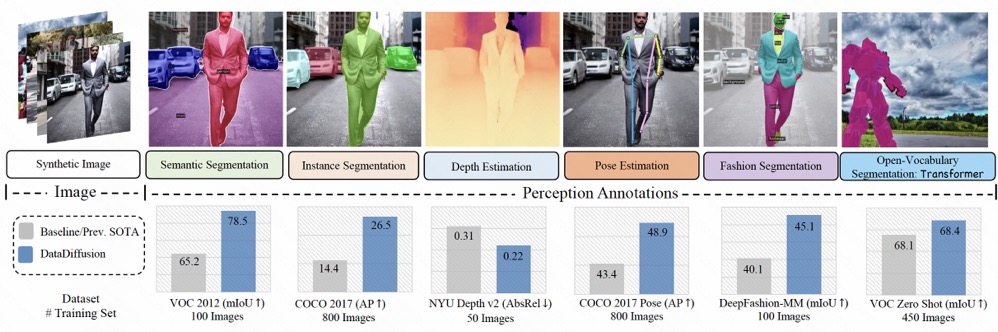
a versatile dataset generation model featuring a perception decoder. 能够同时生成高可信度的图像,和对应的 depth, segmentation, and human pose estimation 信息 😮
-
基于预训练的 diffusion,并且拓展生成图像,到生成 depth 等信息
builds upon the pre-trained diffusion model and extends text-guided image synthesis to perception data generation.
-
实验发现 diffusion 的 latent code 含有丰富语义信息,可以用 decoder 提取出来,只用原始 1%有标注的数据训练。
We show that the rich latent code of the diffusion model can be effectively decoded as accurate perception annotations using a decoder module.
Training the decoder only needs less than 1% (around 100 images) manually labeled images
-
Text-guided data generation: GPT-4 生成 prompt
-
可以生成 depth 等别的信息,因此可以用于下游任务,在几个任务上还达到了 SOTA
achieves 1) state-of-the-art results on semantic segmentation and instance segmentation; 2) significantly more robust on domain generalization than using the real data alone; and state-of-the-art results in zero-shot segmentation setting; and 3) flexibility for efficient application and novel task composition (e.g., image editing).
-
引入深度图
"Control-A-Video: Controllable Text-to-Video Generation with Diffusion Models" website
图像生成方法
只修改 decoder 的一小部分,就可适配不同任务
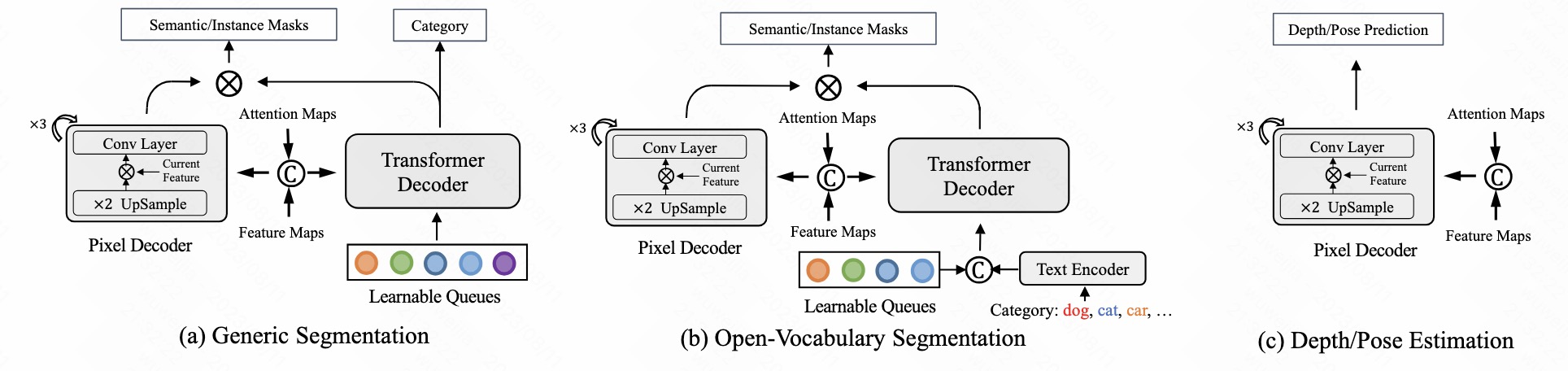
ablation study 看那个模块有效,总结一下
learn what & how to apply to our task
-
用 diffusion 生成深度图,与 GT 的深度图做 loss >> 提高 diffusion denoise 能力
-
看代码如何用 GPT-4 得到 prompt
-
之后能够结合 ControlNet 进行修改
视频修复结合预训练模型,进行风格迁移
-
多个子任务要 decode 时候 >> 用多个 decoder 去从 rich latent code 抽取信息
diffusion 改成用预训练的