- leetcode: Sort List | LeetCode OJ
- lintcode: (98) Sort List
Sort a linked list in O(n log n) time using constant space complexity.
链表的排序操作,对于常用的排序算法,能达到 $$O(n \log n)$$的复杂度有快速排序(平均情况),归并排序,堆排序。快速排序不一定能保证其时间复杂度一定满足要求,归并排序和堆排序都能满足复杂度的要求。在数组排序中,归并排序通常需要使用 $$O(n)$$ 的额外空间,也有原地归并的实现,代码写起来略微麻烦一点。但是对于链表这种非随机访问数据结构,所谓的「排序」不过是指针next值的变化而已,主要通过指针操作,故仅需要常数级别的额外空间,满足题意。堆排序通常需要构建二叉树,在这道题中不太适合。
既然确定使用归并排序,我们就来思考归并排序实现的几个要素。
- 按长度等分链表,归并虽然不严格要求等分,但是等分能保证线性对数的时间复杂度。由于链表不能随机访问,故可以先对链表进行遍历求得其长度。
- 合并链表,细节已在 Merge Two Sorted Lists | Data Structure and Algorithm 中详述。
在按长度等分链表时进行「后序归并」——先求得左半部分链表的表头,再求得右半部分链表的表头,最后进行归并操作。
由于递归等分链表的操作需要传入链表长度信息,故需要另建一辅助函数。新鲜出炉的源码如下。
/**
* Definition of ListNode
* class ListNode {
* public:
* int val;
* ListNode *next;
* ListNode(int val) {
* this->val = val;
* this->next = NULL;
* }
* }
*/
class Solution {
public:
/**
* @param head: The first node of linked list.
* @return: You should return the head of the sorted linked list,
using constant space complexity.
*/
ListNode *sortList(ListNode *head) {
if (NULL == head) {
return NULL;
}
// get the length of List
int len = 0;
ListNode *node = head;
while (NULL != node) {
node = node->next;
++len;
}
return sortListHelper(head, len);
}
private:
ListNode *sortListHelper(ListNode *head, const int length) {
if ((NULL == head) || (0 >= length)) {
return head;
}
ListNode *midNode = head;
int count = 1;
while (count < length / 2) {
midNode = midNode->next;
++count;
}
ListNode *rList = sortListHelper(midNode->next, length - length / 2);
midNode->next = NULL;
ListNode *lList = sortListHelper(head, length / 2);
return mergeList(lList, rList);
}
ListNode *mergeList(ListNode *l1, ListNode *l2) {
ListNode *dummy = new ListNode(0);
ListNode *lastNode = dummy;
while ((NULL != l1) && (NULL != l2)) {
if (l1->val < l2->val) {
lastNode->next = l1;
l1 = l1->next;
} else {
lastNode->next = l2;
l2 = l2->next;
}
lastNode = lastNode->next;
}
lastNode->next = (NULL != l1) ? l1 : l2;
return dummy->next;
}
};- 归并子程序没啥好说的了,见 Merge Two Sorted Lists | Data Structure and Algorithm.
- 在递归处理链表长度时,分析方法和 Convert Sorted List to Binary Search Tree | Data Structure and Algorithm 一致,**
count表示遍历到链表中间时表头指针需要移动的节点数。**在纸上分析几个简单例子后即可确定,由于这个题需要的是「左右」而不是二叉搜索树那道题需要三分——「左中右」,故将count初始化为1更为方便,左半部分链表长度为length / 2, 这两个值的确定最好是先用纸笔分析再视情况取初值,不可死记硬背。 - 找到中间节点后首先将其作为右半部分链表处理,然后将其
next值置为NULL, 否则归并子程序无法正确求解。这里需要注意的是midNode是左半部分的最后一个节点,midNode->next才是链表右半部分的起始节点。 - 递归模型中左、右、合并三者的顺序可以根据分治思想确定,即先找出左右链表,最后进行归并(因为归并排序的前提是两个子链表各自有序)。
遍历求得链表长度,时间复杂度为 $$O(n)$$, 「折半取中」过程中总共有 $$\log(n)$$ 层,每层找中点需遍历 $$n/2$$ 个节点,故总的时间复杂度为 $$ n/2 \cdot O(\log n)$$ (折半取中), 每一层归并排序的时间复杂度介于 $$O(n/2)$$ 和 $$O(n)$$之间,故总的时间复杂度为 $$O(n \log n)$$, 空间复杂度为常数级别,满足题意。
除了遍历链表求得总长外,还可使用看起来较为巧妙的技巧如「快慢指针」,快指针每次走两步,慢指针每次走一步,最后慢指针所指的节点即为中间节点。使用这种特技的关键之处在于如何正确确定快慢指针的起始位置。
/**
* Definition of ListNode
* class ListNode {
* public:
* int val;
* ListNode *next;
* ListNode(int val) {
* this->val = val;
* this->next = NULL;
* }
* }
*/
class Solution {
public:
/**
* @param head: The first node of linked list.
* @return: You should return the head of the sorted linked list,
using constant space complexity.
*/
ListNode *sortList(ListNode *head) {
if (NULL == head || NULL == head->next) {
return head;
}
ListNode *midNode = findMiddle(head);
ListNode *rList = sortList(midNode->next);
midNode->next = NULL;
ListNode *lList = sortList(head);
return mergeList(lList, rList);
}
private:
ListNode *findMiddle(ListNode *head) {
if (NULL == head || NULL == head->next) {
return head;
}
ListNode *slow = head, *fast = head->next;
while(NULL != fast && NULL != fast->next) {
fast = fast->next->next;
slow = slow->next;
}
return slow;
}
ListNode *mergeList(ListNode *l1, ListNode *l2) {
ListNode *dummy = new ListNode(0);
ListNode *lastNode = dummy;
while ((NULL != l1) && (NULL != l2)) {
if (l1->val < l2->val) {
lastNode->next = l1;
l1 = l1->next;
} else {
lastNode->next = l2;
l2 = l2->next;
}
lastNode = lastNode->next;
}
lastNode->next = (NULL != l1) ? l1 : l2;
return dummy->next;
}
};- 异常处理不仅考虑了
head, 还考虑了head->next, 可减少辅助程序中的异常处理。 - 使用快慢指针求中间节点时,将
fast初始化为head->next可有效避免无法分割两个节点如1->2->null1。- 求中点的子程序也可不做异常处理,但前提是主程序
sortList中对head->next做了检测。
- 求中点的子程序也可不做异常处理,但前提是主程序
- 最后进行
merge归并排序。
Note 在递归和迭代程序中,需要尤其注意终止条件的确定,以及循环语句中变量的自增,以防出现死循环或访问空指针。
同上。
归并排序,总的时间复杂度是(nlogn),但是递归的空间复杂度并不是常数(和递归的层数有着关;递归的过程是自顶向下,好理解;这里提供自底向上的非递归方法;
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode* sortList(ListNode* head) {
int len_list = 0;
ListNode *p=head;
while(p){
p = p->next;
len_list++;
}
ListNode *l_list,*r_list,**p_merge_list;
for(int i = 1; i < len_list; i <<= 1){
r_list = l_list = head;
p_merge_list = &head;
for(int j = 0; j < len_list - i ; j += i << 1){
for(int k = 0; k < i; ++k) r_list=r_list->next;
int l_len=i,r_len=min(i, len_list - j - i);
while(l_len || r_len ){
if(r_len > 0 && (l_len == 0 || r_list->val <= l_list->val)){
*p_merge_list = r_list;
p_merge_list=&(r_list->next);
r_list = r_list->next;
--r_len;
}
else{
*p_merge_list = l_list;
p_merge_list=&(l_list->next);
l_list = l_list->next;
--l_len;
}
}
l_list=r_list;
}
*p_merge_list = r_list;
}
return head;
}
};归并排序,分解子问题的过程是O(logn),合并子问题的过程是O(n);
- leetcode: Insertion Sort List | LeetCode OJ
- lintcode: (173) Insertion Sort List
Sort a linked list using insertion sort.
Example
Given 1->3->2->0->null, return 0->1->2->3->null.
插入排序常见的实现是针对数组的,如前几章总的的 Insertion Sort,但这道题中的排序的数据结构为单向链表,故无法再从后往前遍历比较值的大小了。好在天无绝人之路,我们还可以从前往后依次遍历比较和交换。
由于排序后头节点不一定,故需要引入 dummy 大法,并以此节点的next作为最后返回结果的头节点,返回的链表从dummy->next这里开始构建。首先我们每次都从dummy->next开始遍历,依次和上一轮处理到的节点的值进行比较,直至找到不小于上一轮节点值的节点为止,随后将上一轮节点插入到当前遍历的节点之前,依此类推。文字描述起来可能比较模糊,大家可以结合以下的代码在纸上分析下。
"""
Definition of ListNode
class ListNode(object):
def __init__(self, val, next=None):
self.val = val
self.next = next
"""
class Solution:
"""
@param head: The first node of linked list.
@return: The head of linked list.
"""
def insertionSortList(self, head):
dummy = ListNode(0)
cur = head
while cur is not None:
pre = dummy
while pre.next is not None and pre.next.val < cur.val:
pre = pre.next
temp = cur.next
cur.next = pre.next
pre.next = cur
cur = temp
return dummy.next/**
* Definition of ListNode
* class ListNode {
* public:
* int val;
* ListNode *next;
* ListNode(int val) {
* this->val = val;
* this->next = NULL;
* }
* }
*/
class Solution {
public:
/**
* @param head: The first node of linked list.
* @return: The head of linked list.
*/
ListNode *insertionSortList(ListNode *head) {
ListNode *dummy = new ListNode(0);
ListNode *cur = head;
while (cur != NULL) {
ListNode *pre = dummy;
while (pre->next != NULL && pre->next->val < cur->val) {
pre = pre->next;
}
ListNode *temp = cur->next;
cur->next = pre->next;
pre->next = cur;
cur = temp;
}
return dummy->next;
}
};/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
public class Solution {
public ListNode insertionSortList(ListNode head) {
ListNode dummy = new ListNode(0);
ListNode cur = head;
while (cur != null) {
ListNode pre = dummy;
while (pre.next != null && pre.next.val < cur.val) {
pre = pre.next;
}
ListNode temp = cur.next;
cur.next = pre.next;
pre.next = cur;
cur = temp;
}
return dummy.next;
}
}- 新建 dummy 节点,用以处理最终返回结果中头节点不定的情况。
- 以
cur表示当前正在处理的节点,在从 dummy 开始遍历前保存cur的下一个节点作为下一轮的cur. - 以
pre作为遍历节点,直到找到不小于cur值的节点为止。 - 将
pre的下一个节点pre->next链接到cur->next上,cur链接到pre->next, 最后将cur指向下一个节点。 - 返回
dummy->next最为最终头节点。
Python 的实现在 lintcode 上会提示 TLE, leetcode 上勉强通过,这里需要注意的是采用if A is not None:的效率要比if A:高,不然 leetcode 上也过不了。具体原因可参考 Stack Overflow 上的讨论。
最好情况:原链表已经有序,每得到一个新节点都需要 $$i$$ 次比较和一次交换, 时间复杂度为 $$1/2O(n^2) + O(n)$$, 使用了 dummy 和 pre, 空间复杂度近似为 $$O(1)$$.
最坏情况:原链表正好逆序,由于是单向链表只能从前往后依次遍历,交换和比较次数均为 $$1/2 O(n^2)$$, 总的时间复杂度近似为 $$O(n^2)$$, 空间复杂度同上,近似为 $$O(1)$$.
从题解1的复杂度分析可以看出其在最好情况下时间复杂度都为 $$O(n^2)$$ ,这显然是需要优化的。 仔细观察可发现最好情况下的比较次数 是可以优化到 $$O(n)$$ 的。思路自然就是先判断链表是否有序,仅对降序的部分进行处理。优化之后的代码就没题解1那么容易写对了,建议画个图自行纸上分析下。
"""
Definition of ListNode
class ListNode(object):
def __init__(self, val, next=None):
self.val = val
self.next = next
"""
class Solution:
"""
@param head: The first node of linked list.
@return: The head of linked list.
"""
def insertionSortList(self, head):
dummy = ListNode(0)
dummy.next = head
cur = head
while cur is not None:
if cur.next is not None and cur.next.val < cur.val:
# find insert position for smaller(cur->next)
pre = dummy
while pre.next is not None and pre.next.val < cur.next.val:
pre = pre.next
# insert cur->next after pre
temp = pre.next
pre.next = cur.next
cur.next = cur.next.next
pre.next.next = temp
else:
cur = cur.next
return dummy.next/**
* Definition of ListNode
* class ListNode {
* public:
* int val;
* ListNode *next;
* ListNode(int val) {
* this->val = val;
* this->next = NULL;
* }
* }
*/
class Solution {
public:
/**
* @param head: The first node of linked list.
* @return: The head of linked list.
*/
ListNode *insertionSortList(ListNode *head) {
ListNode *dummy = new ListNode(0);
dummy->next = head;
ListNode *cur = head;
while (cur != NULL) {
if (cur->next != NULL && cur->next->val < cur->val) {
ListNode *pre = dummy;
// find insert position for smaller(cur->next)
while (pre->next != NULL && pre->next->val <= cur->next->val) {
pre = pre->next;
}
// insert cur->next after pre
ListNode *temp = pre->next;
pre->next = cur->next;
cur->next = cur->next->next;
pre->next->next = temp;
} else {
cur = cur->next;
}
}
return dummy->next;
}
};/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
public class Solution {
public ListNode insertionSortList(ListNode head) {
ListNode dummy = new ListNode(0);
dummy.next = head;
ListNode cur = head;
while (cur != null) {
if (cur.next != null && cur.next.val < cur.val) {
// find insert position for smaller(cur->next)
ListNode pre = dummy;
while (pre.next != null && pre.next.val < cur.next.val) {
pre = pre.next;
}
// insert cur->next after pre
ListNode temp = pre.next;
pre.next = cur.next;
cur.next = cur.next.next;
pre.next.next = temp;
} else {
cur = cur.next;
}
}
return dummy.next;
}
}- 新建 dummy 节点并将其
next指向head - 分情况讨论,仅需要处理逆序部分。
- 由于已经确认链表逆序,故仅需将较小值(
cur->next而不是cur)的节点插入到链表的合适位置。 - 将
cur->next插入到pre之后,这里需要四个步骤,需要特别小心!
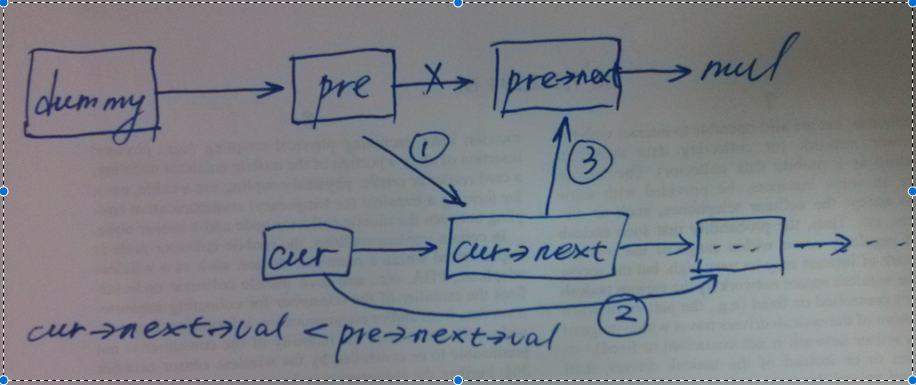
如上图所示,将cur->next插入到pre节点后大致分为3个步骤。
最好情况下时间复杂度降至 $$O(n)$$, 其他同题解1.
- leetcode: Palindrome Linked List | LeetCode OJ
- lintcode: Palindrome Linked List
- Function to check if a singly linked list is palindrome - GeeksforGeeks
Implement a function to check if a linked list is a palindrome.
Given 1->2->1, return true
Could you do it in O(n) time and O(1) space?
根据栈的特性(FILO),可以首先遍历链表并入栈(最后访问栈时则反过来了),随后再次遍历链表并比较当前节点和栈顶元素,若比较结果完全相同则为回文。 又根据回文的特性,实际上还可以只遍历链表前半部分节点,再用栈中的元素和后半部分元素进行比较,分链表节点个数为奇数或者偶数考虑即可。由于链表长度未知,因此可以考虑使用快慢指针求得。
## Definition for singly-linked list
# class ListNode:
# def __init__(self, val):
# self.val = val
# self.next = None
class Solution:
# @param head, a ListNode
# @return a boolean
def is_palindrome(self, head):
if not head or not head.next:
return True
stack = []
slow, fast = head, head.next
while fast and fast.next:
stack.append(slow.val)
slow = slow.next
fast = fast.next.next
# for even numbers add mid
if fast:
stack.append(slow.val)
curt = slow.next
while curt:
if curt.val != stack.pop():
return False
curt = curt.next
return True注意, 在python code中, slow 和 fast pointer 分别指向head 和head.next。 这样指向的好处是:当linked-list 有奇数个数字的时候, 最终位置,slow会停在mid的位置, 而fast指向空。 当linked-list有偶数个node时, 最终位置,slow和slow.next为中间的两个元素, fast指向最后一个node。所以slow的最终位置总是mid 或者mid 偏左一点的位置。这样的位置非常方便分割linked-list,以及其他计算。推荐采用这种方法来寻找linked-list的mid位置。模版优势,请见solution2。
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
public class Solution {
/**
* @param head a ListNode
* @return a boolean
*/
public boolean isPalindrome(ListNode head) {
if (head == null || head.next == null) return true;
Deque<Integer> stack = new ArrayDeque<Integer>();
// find middle
ListNode slow = head, fast = head;
while (fast != null && fast.next != null) {
stack.push(slow.val);
slow = slow.next;
fast = fast.next.next;
}
// skip mid node if the number of ListNode is odd
if (fast != null) slow = slow.next;
ListNode rCurr = slow;
while (rCurr != null) {
if (rCurr.val != stack.pop()) return false;
rCurr = rCurr.next;
}
return true;
}
}注意区分好链表中个数为奇数还是偶数就好了,举几个简单例子辅助分析。
使用了栈作为辅助空间,空间复杂度为 $$O(\frac{1}{2}n)$$, 分别遍历链表的前半部分和后半部分,时间复杂度为 $$O(n)$$.
题解 1 的解法使用了辅助空间,在可以改变原来的链表的基础上,可使用原地翻转,思路为翻转前半部分,然后迭代比较。具体可分为以下四个步骤。
- 找中点。
- 翻转链表的后半部分。
- 逐个比较前后部分节点值。
- 链表复原,翻转后半部分链表。
# class ListNode:
# def __init__(self, val):
# self.val = val
# self.next = None
class Solution:
def is_palindrome(self, head):
if not head or not head.next:
return True
slow, fast = head, head.next
while fast and fast.next:
fast = fast.next.next
slow = slow.next
mid = slow.next
# break
slow.next = None
rhead = self.reverse(mid)
while rhead:
if rhead.val != head.val:
return False
rhead = rhead.next
head = head.next
return True
def reverse(self, head):
dummy = ListNode(-1)
while head:
temp = head.next
head.next = dummy.next
dummy.next = head
head = temp
return dummy.next对比Java code, 会发现,把slow 和fast pointer 放在head和head.next减少了对odd 或者even number的判断。因为slow总是在mid的位置或者mid偏左的位置上, 所以把mid assign 为slow.next总是对的。
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
public class Solution {
/**
* @param head a ListNode
* @return a boolean
*/
public boolean isPalindrome(ListNode head) {
if (head == null || head.next == null) return true;
// find middle
ListNode slow = head, fast = head;
while (fast != null && fast.next != null) {
slow = slow.next;
fast = fast.next.next;
}
// skip mid node if the number of ListNode is odd
if (fast != null) slow = slow.next;
// reverse right part of List
ListNode rHead = reverse(slow);
ListNode lCurr = head, rCurr = rHead;
while (rCurr != null) {
if (rCurr.val != lCurr.val) {
reverse(rHead);
return false;
}
lCurr = lCurr.next;
rCurr = rCurr.next;
}
// recover right part of List
reverse(rHead);
return true;
}
private ListNode reverse(ListNode head) {
ListNode prev = null;
while (head != null) {
ListNode after = head.next;
head.next = prev;
prev = head;
head = after;
}
return prev;
}
}class Solution {
public:
bool isPalindrome(ListNode* head) {
if (!head || !head->next) return true;
// find middle
ListNode* slow = head, *fast = head;
while (fast && fast->next) {
slow = slow->next;
fast = fast->next->next;
}
// skip mid node if the number of ListNode is odd
if (fast) slow = slow->next;
// reverse right part of List
ListNode* rHead = reverse(slow);
ListNode* lCurr = head, *rCurr = rHead;
while (rCurr) {
if (rCurr->val != lCurr->val) {
reverse(rHead);
return false;
}
lCurr = lCurr->next;
rCurr = rCurr->next;
}
// recover right part of List
reverse(rHead);
return true;
}
ListNode* reverse(ListNode* head) {
ListNode* prev = NULL;
while (head) {
ListNode* after = head->next;
head->next = prev;
prev = head;
head = after;
}
return prev;
}
}连续翻转两次右半部分链表即可复原原链表,将一些功能模块如翻转等尽量模块化。
遍历链表若干次,时间复杂度近似为 $$O(n)$$, 使用了几个临时遍历,空间复杂度为 $$O(1)$$.
递归需要两个重要条件,递归步的建立和递归终止条件。对于回文比较,理所当然应该递归比较第 i 个节点和第 n-i 个节点,那么问题来了,如何构建这个递归步?大致可以猜想出来递归的传入参数应该包含两个节点,用以指代第 i 个节点和第 n-i 个节点。返回参数应该包含布尔值(用以提前返回不是回文的情况)和左半部分节点的下一个节点(用以和右半部分的节点进行比较)。由于需要返回两个值,在 Java 中需要使用自定义类进行封装,C/C++ 中则可以使用指针改变在递归调用后进行比较时节点的值。
class Solution:
def is_palindrome(self, head):
result = [head, True]
self.helper(head, result)
return result[1]
def helper(self, right, result):
if right:
self.helper(right.next, result)
is_pal = result[0].val == right.val and result[1]
result = [result[0].next, is_pal]/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
class Result {
ListNode lNode;
boolean isP;
Result(ListNode node, boolean isP) {
this.lNode = node;
this.isP = isP;
}
}
public class Solution {
/**
* @param head a ListNode
* @return a boolean
*/
public boolean isPalindrome(ListNode head) {
Result result = new Result(head, true);
helper(head, result);
return result.isP;
}
private void helper(ListNode right, Result result) {
if (right != null) {
helper(right.next, result);
boolean equal = (result.lNode.val == right.val);
result.isP = equal && result.isP;
result.lNode = result.lNode.next;
}
}
}核心代码为如何在递归中推进左半部分节点而对右半部分使用栈的方式逆向获取节点。左半部分的推进需要借助辅助数据结构Result.
递归调用 n 层,时间复杂度近似为 $$O(n)$$, 使用了几个临时变量,空间复杂度为 $$O(1)$$.
class Solution:
def is_palindrome(self, head):
nodes = []
while head:
nodes.append(head.val)
head = head.next
return nodes == nodes[::-1]将linked-list问题,转化成判断一个array是否为palindrome的问题。
时间复杂度 $$O(n)$$, 空间复杂度也是 $$O(n)$$
- Function to check if a singly linked list is palindrome - GeeksforGeeks
- 回文判断 | The-Art-Of-Programming-By-July/01.04.md
- ctci/QuestionB.java at master · gaylemcd/ctci
Implement an algorithm to delete a nodein the middle of a singly linked list,
given only access to that node.
Example
Given 1->2->3->4, and node 3. return 1->2->4
根据给定的节点并删除这个节点。弄清楚题意很重要,我首先以为是删除链表的中间节点。:( 一般来说删除单向链表中的一个节点需要首先知道节点的前一个节点,改变其指向的下一个节点并删除就可以了。但是从这道题来看无法知道欲删除节点的前一个节点,那么也就是意味着无法改变前一个节点指向的下一个节点,强行删除当前节点将导致非法内存访问。
既然找不到前一个节点,那么也就意味着不能用通常的方法删除给定节点。从实际角度来看,我们关心的往往并不是真的删除了链表中的某个节点,而是访问链表时表现的行为就像是某个节点被删除了一样。这种另类『删除』方法就是——使用下一个节点的值覆盖当前节点的值,删除下一个节点。
/**
* Definition for ListNode.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int val) {
* this.val = val;
* this.next = null;
* }
* }
*/
public class Solution {
/**
* @param node: the node in the list should be deleted
* @return: nothing
*/
public void deleteNode(ListNode node) {
if (node == null) return;
if (node.next == null) node = null;
node.val = node.next.val;
node.next = node.next.next;
}
}注意好边界条件处理即可。
略。$$O(1)$$.