- leetcode: Reorder List | LeetCode OJ
- lintcode: (99) Reorder List
Given a singly linked list L: L_0→_L_1→…→_L__n-1→_L_n,
reorder it to: L_0→_L__n_→_L_1→_L__n-1→_L_2→_L__n_-2→…
You must do this in-place without altering the nodes' values.
For example,
Given {1,2,3,4}, reorder it to {1,4,2,3}.
直观角度来考虑,如果把链表视为数组来处理,那么我们要做的就是依次将下标之和为n的两个节点链接到一块儿,使用两个索引即可解决问题,一个索引指向i, 另一个索引则指向其之后的第n - 2*i个节点(对于链表来说实际上需要获取的是其前一个节点), 直至第一个索引大于第二个索引为止即处理完毕。
既然依赖链表长度信息,那么要做的第一件事就是遍历当前链表获得其长度喽。获得长度后即对链表进行遍历,小心处理链表节点的断开及链接。用这种方法会提示 TLE,也就是说还存在较大的优化空间!
/**
* Definition of ListNode
* class ListNode {
* public:
* int val;
* ListNode *next;
* ListNode(int val) {
* this->val = val;
* this->next = NULL;
* }
* }
*/
class Solution {
public:
/**
* @param head: The first node of linked list.
* @return: void
*/
void reorderList(ListNode *head) {
if (NULL == head || NULL == head->next || NULL == head->next->next) {
return;
}
ListNode *last = head;
int length = 0;
while (NULL != last) {
last = last->next;
++length;
}
last = head;
for (int i = 1; i < length - i; ++i) {
ListNode *beforeTail = last;
for (int j = i; j < length - i; ++j) {
beforeTail = beforeTail->next;
}
ListNode *temp = last->next;
last->next = beforeTail->next;
last->next->next = temp;
beforeTail->next = NULL;
last = temp;
}
}
};- 异常处理,对于节点数目在两个以内的无需处理。
- 遍历求得链表长度。
- 遍历链表,第一个索引处的节点使用
last表示,第二个索引处的节点的前一个节点使用beforeTail表示。 - 处理链表的链接与断开,迭代处理下一个
last。
- 遍历整个链表获得其长度,时间复杂度为
$$O(n)$$. - 双重
for循环的时间复杂度为$$(n-2) + (n-4) + ... + 2 = O(\frac{1}{2} \cdot n^2)$$. - 总的时间复杂度可近似认为是
$$O(n^2)$$, 空间复杂度为常数。
Warning 使用这种方法务必注意
i和j的终止条件,若取i < length + 1 - i, 则在处理最后两个节点时会出现环,且尾节点会被删掉。在对节点进行遍历时务必注意保留头节点的信息!
既然题解1存在较大的优化空间,那我们该从哪一点出发进行优化呢?擒贼先擒王,题解1中时间复杂度最高的地方在于双重for循环,在对第二个索引进行遍历时,j每次都从i处开始遍历,要是j能从链表尾部往前遍历该有多好啊!这样就能大大降低时间复杂度了,可惜本题的链表只是单向链表... 有什么特技可以在单向链表中进行反向遍历吗?还真有——反转链表!一语惊醒梦中人。
/**
* Definition of ListNode
* class ListNode {
* public:
* int val;
* ListNode *next;
* ListNode(int val) {
* this->val = val;
* this->next = NULL;
* }
* }
*/
class Solution {
public:
/**
* @param head: The first node of linked list.
* @return: void
*/
void reorderList(ListNode *head) {
if (head == NULL || head->next == NULL) return;
// find middle
ListNode *slow = head, *fast = head->next;
while (fast != NULL && fast->next != NULL) {
slow = slow->next;
fast = fast->next->next;
}
ListNode *rHead = slow->next;
slow->next = NULL;
// reverse ListNode on the right side
ListNode *prev = NULL;
while (rHead != NULL) {
ListNode *temp = rHead->next;
rHead->next = prev;
prev = rHead;
rHead = temp;
}
// merge two list
rHead = prev;
ListNode *lHead = head;
while (lHead != NULL && rHead != NULL) {
ListNode *temp1 = lHead->next;
lHead->next = rHead;
ListNode *temp2 = rHead->next;
rHead->next = temp1;
lHead = temp1;
rHead = temp2;
}
}
};/**
* Definition for ListNode.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int val) {
* this.val = val;
* this.next = null;
* }
* }
*/
public class Solution {
/**
* @param head: The head of linked list.
* @return: void
*/
public void reorderList(ListNode head) {
if (head == null || head.next == null) return;
// find middle
ListNode slow = head, fast = head.next;
while (fast != null && fast.next != null) {
slow = slow.next;
fast = fast.next.next;
}
ListNode rHead = slow.next;
slow.next = null;
// reverse ListNode on the right side
ListNode prev = null;
while (rHead != null) {
ListNode temp = rHead.next;
rHead.next = prev;
prev = rHead;
rHead = temp;
}
// merge two list
rHead = prev;
ListNode lHead = head;
while (lHead != null && rHead != null) {
ListNode temp1 = lHead.next;
lHead.next = rHead;
rHead = rHead.next;
lHead.next.next = temp1;
lHead = temp1;
}
}
}相对于题解1,题解2更多地利用了链表的常用操作如反转、找中点、合并。
- 找中点:我在九章算法模板的基础上增加了对
head->next的异常检测,增强了鲁棒性。 - 反转:非常精炼的模板,记牢!
- 合并:也可使用九章提供的模板,思想是一样的,需要注意
left,right和dummy三者的赋值顺序,不能更改任何一步。
找中点一次,时间复杂度近似为 $$O(n)$$. 反转链表一次,时间复杂度近似为 $$O(n/2)$$. 合并左右链表一次,时间复杂度近似为 $$O(n/2)$$. 故总的时间复杂度为 $$O(n)$$.
- leetcode: Copy List with Random Pointer | LeetCode OJ
- lintcode: (105) Copy List with Random Pointer
A linked list is given such that each node contains an additional random pointer
which could point to any node in the list or null.
Return a deep copy of the list.
首先得弄懂深拷贝的含义,深拷贝可不是我们平时见到的对基本类型的变量赋值那么简单,深拷贝常常用于对象的克隆。这道题要求深度拷贝一个带有 random 指针的链表,random 可能指向空,也可能指向链表中的任意一个节点。
对于通常的单向链表,我们依次遍历并根据原链表的值生成新节点即可,原链表的所有内容便被复制了一份。但由于此题中的链表不只是有 next 指针,还有一个随机指针,故除了复制通常的 next 指针外还需维护新链表中的随机指针。容易混淆的地方在于原链表中的随机指针指向的是原链表中的节点,深拷贝则要求将随机指针指向新链表中的节点。
所有类似的深度拷贝题目的传统做法,都是维护一个 hash table。即先按照复制一个正常链表的方式复制,复制的时候把复制的结点做一个 hash table,以旧结点为 key,新节点为 value。这么做的目的是为了第二遍扫描的时候我们按照这个哈希表把结点的 random 指针接上。
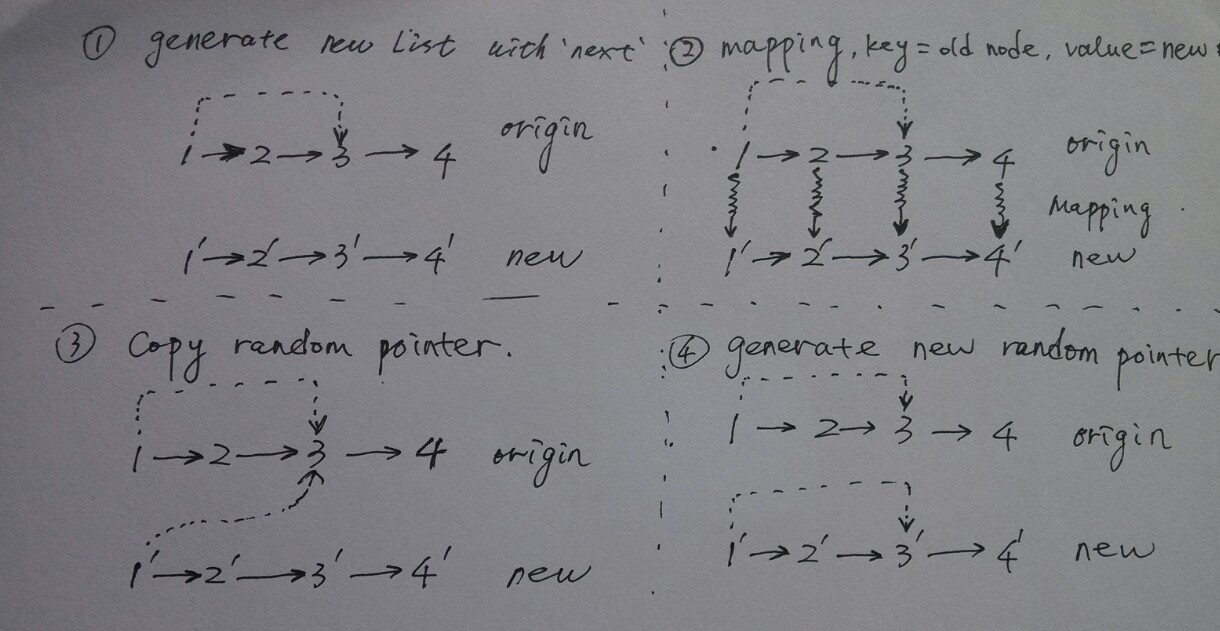
原链表和深拷贝之后的链表如下:
|------------| |------------|
| v ===> | v
1 --> 2 --> 3 --> 4 1' --> 2'--> 3'--> 4'
深拷贝步骤如下;
- 根据 next 指针新建链表
- 维护新旧节点的映射关系
- 拷贝旧链表中的 random 指针
- 更新新链表中的 random 指针
其中1, 2, 3 可以合并在一起。
一图胜千文
# Definition for singly-linked list with a random pointer.
# class RandomListNode:
# def __init__(self, x):
# self.label = x
# self.next = None
# self.random = None
class Solution:
# @param head: A RandomListNode
# @return: A RandomListNode
def copyRandomList(self, head):
dummy = RandomListNode(0)
curNode = dummy
randomMap = {}
while head is not None:
# link newNode to new List
newNode = RandomListNode(head.label)
curNode.next = newNode
# map old node head to newNode
randomMap[head] = newNode
# copy old node random pointer
newNode.random = head.random
#
head = head.next
curNode = curNode.next
# re-mapping old random node to new node
curNode = dummy.next
while curNode is not None:
if curNode.random is not None:
curNode.random = randomMap[curNode.random]
curNode = curNode.next
return dummy.next/**
* Definition for singly-linked list with a random pointer.
* struct RandomListNode {
* int label;
* RandomListNode *next, *random;
* RandomListNode(int x) : label(x), next(NULL), random(NULL) {}
* };
*/
class Solution {
public:
/**
* @param head: The head of linked list with a random pointer.
* @return: A new head of a deep copy of the list.
*/
RandomListNode *copyRandomList(RandomListNode *head) {
if (head == NULL) return NULL;
RandomListNode *dummy = new RandomListNode(0);
RandomListNode *curNode = dummy;
unordered_map<RandomListNode *, RandomListNode *> randomMap;
while(head != NULL) {
// link newNode to new List
RandomListNode *newNode = new RandomListNode(head->label);
curNode->next = newNode;
// map old node head to newNode
randomMap[head] = newNode;
// copy old node random pointer
newNode->random = head->random;
head = head->next;
curNode = curNode->next;
}
// re-mapping old random node to new node
curNode = dummy->next;
while (curNode != NULL) {
if (curNode->random != NULL) {
curNode->random = randomMap[curNode->random];
}
curNode = curNode->next;
}
return dummy->next;
}
};/**
* Definition for singly-linked list with a random pointer.
* class RandomListNode {
* int label;
* RandomListNode next, random;
* RandomListNode(int x) { this.label = x; }
* };
*/
public class Solution {
/**
* @param head: The head of linked list with a random pointer.
* @return: A new head of a deep copy of the list.
*/
public RandomListNode copyRandomList(RandomListNode head) {
if (head == null) return null;
RandomListNode dummy = new RandomListNode(0);
RandomListNode curNode = dummy;
HashMap<RandomListNode, RandomListNode> randomMap = new HashMap<RandomListNode, RandomListNode>();
while (head != null) {
// link newNode to new List
RandomListNode newNode = new RandomListNode(head.label);
curNode.next = newNode;
// map old node head to newNode
randomMap.put(head, newNode);
// copy old node random pointer
newNode.random = head.random;
//
head = head.next;
curNode = curNode.next;
}
// re-mapping old random node to new node
curNode = dummy.next;
while(curNode != null) {
if (curNode.random != null) {
curNode.random = randomMap.get(curNode.random);
}
curNode = curNode.next;
}
return dummy.next;
}
}- 只需要一个
dummy存储新的拷贝出来的链表头,以用来第二次遍历时链接 random 指针。所以第一句异常检测可有可无。 - 第一次链接时勿忘记同时拷贝 random 指针,但此时的 random 指针并没有真正“链接”上,实际上是链接到了原始链表的 node 上。
- 第二次遍历是为了把原始链表的被链接的 node 映射到新链表中的 node,从而完成真正“链接”。
总共要进行两次扫描,所以时间复杂度是 $$O(2n)=O(n)$$, 在链表较长时可能会 TLE(比如 Python). 空间上需要一个哈希表来做结点的映射,所以空间复杂度也是 $$O(n)$$.
从题解1 的分析中我们可以看到对于 random 指针我们是在第二次遍历时单独处理的,那么在借助哈希表的情况下有没有可能一次遍历就完成呢?我们回想一下题解1 中random 节点的处理,由于在第一次遍历完之前 random 所指向的节点是不知道到底是指向哪一个节点,故我们在将 random 指向的节点加入哈希表之前判断一次就好了(是否已经生成,避免对同一个值产生两个不同的节点)。由于 random 节点也在第一次遍历加入哈希表中,故生成新节点时也需要判断哈希表中是否已经存在。
# Definition for singly-linked list with a random pointer.
# class RandomListNode:
# def __init__(self, x):
# self.label = x
# self.next = None
# self.random = None
class Solution:
# @param head: A RandomListNode
# @return: A RandomListNode
def copyRandomList(self, head):
dummy = RandomListNode(0)
curNode = dummy
hash_map = {}
while head is not None:
# link newNode to new List
if head in hash_map.keys():
newNode = hash_map[head]
else:
newNode = RandomListNode(head.label)
hash_map[head] = newNode
curNode.next = newNode
# map old node head to newNode
hash_map[head] = newNode
# copy old node random pointer
if head.random is not None:
if head.random in hash_map.keys():
newNode.random = hash_map[head.random]
else:
newNode.random = RandomListNode(head.random.label)
hash_map[head.random] = newNode.random
#
head = head.next
curNode = curNode.next
return dummy.next/**
* Definition for singly-linked list with a random pointer.
* struct RandomListNode {
* int label;
* RandomListNode *next, *random;
* RandomListNode(int x) : label(x), next(NULL), random(NULL) {}
* };
*/
class Solution {
public:
/**
* @param head: The head of linked list with a random pointer.
* @return: A new head of a deep copy of the list.
*/
RandomListNode *copyRandomList(RandomListNode *head) {
RandomListNode *dummy = new RandomListNode(0);
RandomListNode *curNode = dummy;
unordered_map<RandomListNode *, RandomListNode *> hash_map;
while(head != NULL) {
// link newNode to new List
RandomListNode *newNode = NULL;
if (hash_map.count(head) > 0) {
newNode = hash_map[head];
} else {
newNode = new RandomListNode(head->label);
hash_map[head] = newNode;
}
curNode->next = newNode;
// re-mapping old random node to new node
if (head->random != NULL) {
if (hash_map.count(head->random) > 0) {
newNode->random = hash_map[head->random];
} else {
newNode->random = new RandomListNode(head->random->label);
hash_map[head->random] = newNode->random;
}
}
head = head->next;
curNode = curNode->next;
}
return dummy->next;
}
};/**
* Definition for singly-linked list with a random pointer.
* class RandomListNode {
* int label;
* RandomListNode next, random;
* RandomListNode(int x) { this.label = x; }
* };
*/
public class Solution {
/**
* @param head: The head of linked list with a random pointer.
* @return: A new head of a deep copy of the list.
*/
public RandomListNode copyRandomList(RandomListNode head) {
RandomListNode dummy = new RandomListNode(0);
RandomListNode curNode = dummy;
HashMap<RandomListNode, RandomListNode> hash_map = new HashMap<RandomListNode, RandomListNode>();
while (head != null) {
// link newNode to new List
RandomListNode newNode = null;
if (hash_map.containsKey(head)) {
newNode = hash_map.get(head);
} else {
newNode = new RandomListNode(head.label);
hash_map.put(head, newNode);
}
curNode.next = newNode;
// re-mapping old random node to new node
if (head.random != null) {
if (hash_map.containsKey(head.random)) {
newNode.random = hash_map.get(head.random);
} else {
newNode.random = new RandomListNode(head.random.label);
hash_map.put(head.random, newNode.random);
}
}
//
head = head.next;
curNode = curNode.next;
}
return dummy.next;
}
}随机指针指向节点不定,故加入哈希表之前判断一下 key 是否存在即可。C++ 中 C++ 11 引入的 unordered_map 较 map 性能更佳,使用 count 判断 key 是否存在比 find 开销小一点,因为 find 需要构造 iterator。
遍历一次原链表,判断哈希表中 key 是否存在,故时间复杂度为 $$O(n)$$, 空间复杂度为 $$O(n)$$.
上面的解法很显然,需要额外的空间。这个额外的空间是由 hash table 的维护造成的。因为当我们访问一个结点时可能它的 random 指针指向的结点还没有访问过,结点还没有创建,所以需要用 hash table 的额外线性空间维护。
但我们可以通过链表原来结构中的 next 指针来替代 hash table 做哈希。假设有如下链表:
|------------|
| v
1 --> 2 --> 3 --> 4
节点1的 random 指向了3。首先我们可以通过 next 遍历链表,依次拷贝节点,并将其添加到原节点后面,如下:
|--------------------------|
| v
1 --> 1' --> 2 --> 2' --> 3 --> 3' --> 4 --> 4'
| ^
|-------------------|
因为我们只是简单的复制了 random 指针,所以新的节点的 random 指向的仍然是老的节点,譬如上面的1和1'都是指向的3。
调整新的节点的 random 指针,对于上面例子来说,我们需要将1'的 random 指向3',其实也就是原先 random 指针的next节点。
|--------------------------|
| v
1 --> 1' --> 2 --> 2' --> 3 --> 3' --> 4 --> 4'
| ^
|-------------------------|
最后,拆分链表,就可以得到深度拷贝的链表了。
总结起来,实际我们对链表进行了三次扫描,第一次扫描对每个结点进行复制,然后把复制出来的新节点接在原结点的 next 指针上,也就是让链表变成一个重复链表,就是新旧更替;第二次扫描中我们把旧结点的随机指针赋给新节点的随机指针,因为新结点都跟在旧结点的下一个,所以赋值比较简单,就是 node->next->random = node->random->next,其中 node->next 就是新结点,因为第一次扫描我们就是把新结点接在旧结点后面。现在我们把结点的随机指针都接好了,最后一次扫描我们把链表拆成两个,第一个还原原链表,而第二个就是我们要求的复制链表。因为现在链表是旧新更替,只要把每隔两个结点分别相连,对链表进行分割即可。
# Definition for singly-linked list with a random pointer.
# class RandomListNode:
# def __init__(self, x):
# self.label = x
# self.next = None
# self.random = None
class Solution:
# @param head: A RandomListNode
# @return: A RandomListNode
def copyRandomList(self, head):
if head is None:
return None
curr = head
# step1: generate new List with node
while curr is not None:
newNode = RandomListNode(curr.label)
newNode.next = curr.next
curr.next = newNode
curr = curr.next.next
# step2: copy random pointer
curr = head
while curr is not None:
if curr.random is not None:
curr.next.random = curr.random.next
curr = curr.next.next
# step3: split original and new List
newHead = head.next
curr = head
while curr is not None:
newNode = curr.next
curr.next = curr.next.next
if newNode.next is not None:
newNode.next = newNode.next.next
curr = curr.next
return newHead/**
* Definition for singly-linked list with a random pointer.
* struct RandomListNode {
* int label;
* RandomListNode *next, *random;
* RandomListNode(int x) : label(x), next(NULL), random(NULL) {}
* };
*/
class Solution {
public:
/**
* @param head: The head of linked list with a random pointer.
* @return: A new head of a deep copy of the list.
*/
RandomListNode *copyRandomList(RandomListNode *head) {
if (head == NULL) return NULL;
RandomListNode *curr = head;
// step1: generate new List with node
while (curr != NULL) {
RandomListNode *newNode = new RandomListNode(curr->label);
newNode->next = curr->next;
curr->next = newNode;
//
curr = curr->next->next;
}
// step2: copy random
curr = head;
while (curr != NULL) {
if (curr->random != NULL) {
curr->next->random = curr->random->next;
}
curr = curr->next->next;
}
// step3: split original and new List
RandomListNode *newHead = head->next;
curr = head;
while (curr != NULL) {
RandomListNode *newNode = curr->next;
curr->next = curr->next->next;
curr = curr->next;
if (newNode->next != NULL) {
newNode->next = newNode->next->next;
}
}
return newHead;
}
};/**
* Definition for singly-linked list with a random pointer.
* class RandomListNode {
* int label;
* RandomListNode next, random;
* RandomListNode(int x) { this.label = x; }
* };
*/
public class Solution {
/**
* @param head: The head of linked list with a random pointer.
* @return: A new head of a deep copy of the list.
*/
public RandomListNode copyRandomList(RandomListNode head) {
if (head == null) return null;
RandomListNode curr = head;
// step1: generate new List with node
while (curr != null) {
RandomListNode newNode = new RandomListNode(curr.label);
newNode.next = curr.next;
curr.next = newNode;
//
curr = curr.next.next;
}
// step2: copy random pointer
curr = head;
while (curr != null) {
if (curr.random != null) {
curr.next.random = curr.random.next;
}
curr = curr.next.next;
}
// step3: split original and new List
RandomListNode newHead = head.next;
curr = head;
while (curr != null) {
RandomListNode newNode = curr.next;
curr.next = curr.next.next;
curr = curr.next;
if (newNode.next != null) {
newNode.next = newNode.next.next;
}
}
return newHead;
}
}注意指针使用前需要判断是否非空,迭代时注意是否前进两步,即.next.next
总共进行三次线性扫描,所以时间复杂度是 $$O(n)$$。但不再需要额外空间的 hash table,所以空间复杂度是 $$O(1)$$。