茴香豆 是由书生·浦语团队开发的一款开源、专门针对国内企业级使用场景设计并优化的知识问答工具。在基础 RAG 课程中我们了解到,RAG 可以有效的帮助提高 LLM 知识检索的相关性、实时性,同时避免 LLM 训练带来的巨大成本。在实际的生产和生活环境需求,对 RAG 系统的开发、部署和调优的挑战更大,如需要解决群应答、能够无关问题拒答、多渠道应答、更高的安全性挑战。因此,根据大量国内用户的实际需求,总结出了三阶段Pipeline的茴香豆知识问答助手架构,帮助企业级用户可以快速上手安装部署。
茴香豆特点:
-
三阶段 Pipeline (前处理、拒答、响应),提高相应准确率和安全性
-
打通微信和飞书群聊天,适合国内知识问答场景
-
支持各种硬件配置安装,安装部署限制条件少
-
适配性强,兼容多个 LLM 和 API
-
傻瓜操作,安装和配置方便

本教程将通过茴香豆 Web 版和本地版的搭建,带领同学们学会如何快速搭建一个企业级的 RAG 知识问答系统。
Web 版茴香豆部署在浦源平台,可以让大家零编程体验茴香豆的各种功能。这里 有作者大神亲自的视频演示。
登录 https://openxlab.org.cn/apps/detail/tpoisonooo/huixiangdou-web,可以看到 Web 版茴香豆的知识库注册页面,在对应处输入想要创建的知识库名称和密码,该名称就是 Web 版茴香豆的账户和密码,请牢记,以后对该知识助手进行维护和修改都要使用这个账户和密码。

完成账户创建或者输入已有账户密码后会进入相应知识库的开发页面,当前 Web 版茴香豆功能包括:
-
添加/删除文档
-
编辑正反例
-
打通微信和飞书群
-
开启网络搜索功能(需要填入自己的 Serper token,token 获取参考 3.1 开启网络搜索)
-
聊天测试

点击添加文档的 查看或上传 按钮,对知识库文档进行修改,目前支持 pdf、word、markdown、excel、ppt、html 和 txt 格式文件的上传和删除。上传或删除文件后将自动进行特征提取,生成的向量知识库被用于后续 RAG 检索和相似性比对。

完成相关文档上传后,可以直接用下面的聊天测试窗口测试知识助手的效果:

在真实的使用场景中,调试知识助手回答相关问题和拒答无关问题(如闲聊)是保证回答准确率和效率十分重要的部分。茴香豆的架构中,除了利用 LLM 的功能判断问题相关性,也可以通过手动添加正例(希望模型回答的问题)和反例(希望模型拒答的问题)来调优知识助手的应答效果。
在 Web 版茴香豆中,点击添加正反例下的 查看或编辑 按钮,进入正反例添加页面:
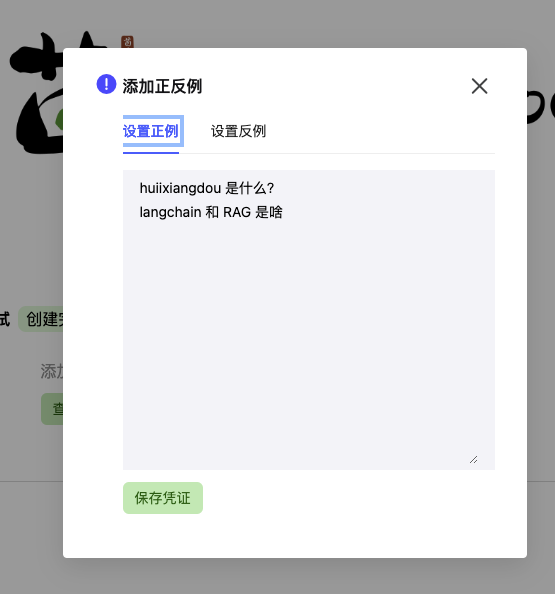

添加好正反例,我们来测试一下:

对于正例相似问题,茴香豆会在知识库中尽量搜寻相关解答,在没有相关知识的情况下,会推测答案,并在回答中提示我们该回答并不准确。这保证了回答的可追溯性。

对于反例问题,茴香豆拒绝作答,这保证了在对话,尤其是企业级群聊中的闲聊、非问题和无关问题触发回答带来的回答混乱和资源浪费。
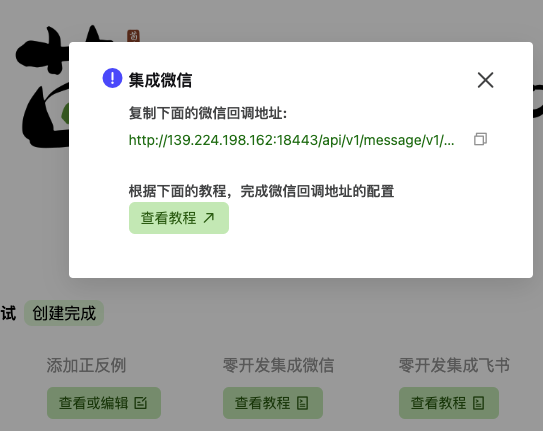
查看微信和飞书群的集成教程,可以在 Web 版茴香豆中直接获取对应的回调地址和 appId 等必需参数。
目前个人微信并未开放官方端口,茴香豆开发者们开发了专门的 茴香豆 Android 助手 app,帮助打通茴香豆和微信群。目前仅支持安卓系统和特定微信版本,测试需要:
-
android 手机
-
微信版本 8.0.47 / 8.0.48 / 8.0.49
-
微信号
点击 Web 版茴香豆的 查看教程 或 https://github.com/InternLM/HuixiangDou/blob/main/docs/zh/add_wechat_accessibility_zh.md 尝试集成茴香豆到微信。
支持多个群群聊的微信接入方法 https://github.com/InternLM/HuixiangDou/blob/main/docs/zh/doc_add_wechat_commercial.md 。
注意!该方法目前只支持一个微信群应答。

点击 Web 版茴香豆的 查看教程 将茴香豆通过飞书群机器人部署到飞书群。
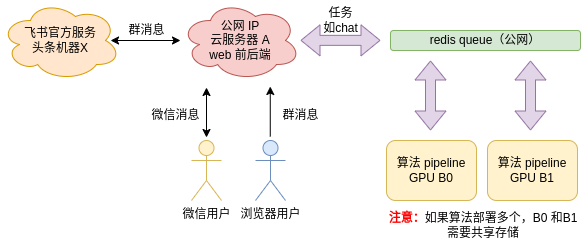
上面的教程是基于部署在浦源平台的 Web 版茴香豆进行 RAG 知识助手的开发。根据企业算力预算和对数据安全的要求不同,茴香豆 Web 版代码也可以搭建在自有服务器上,详细操作文档如下:
https://github.com/InternLM/HuixiangDou/blob/main/web/README.md。
注意!如果需要集成飞书和微信,服务器需要拥有或者透传公网 IP。
在第一部分中,我们利用 Web 版茴香豆实现了零代码开发部署一款 RAG 知识助手,在接下来的部分,我们要动手尝试将茴香豆从源码部署到本地服务器(以 InternlmStudio 为例),并开发一款简单的知识助手 Demo。
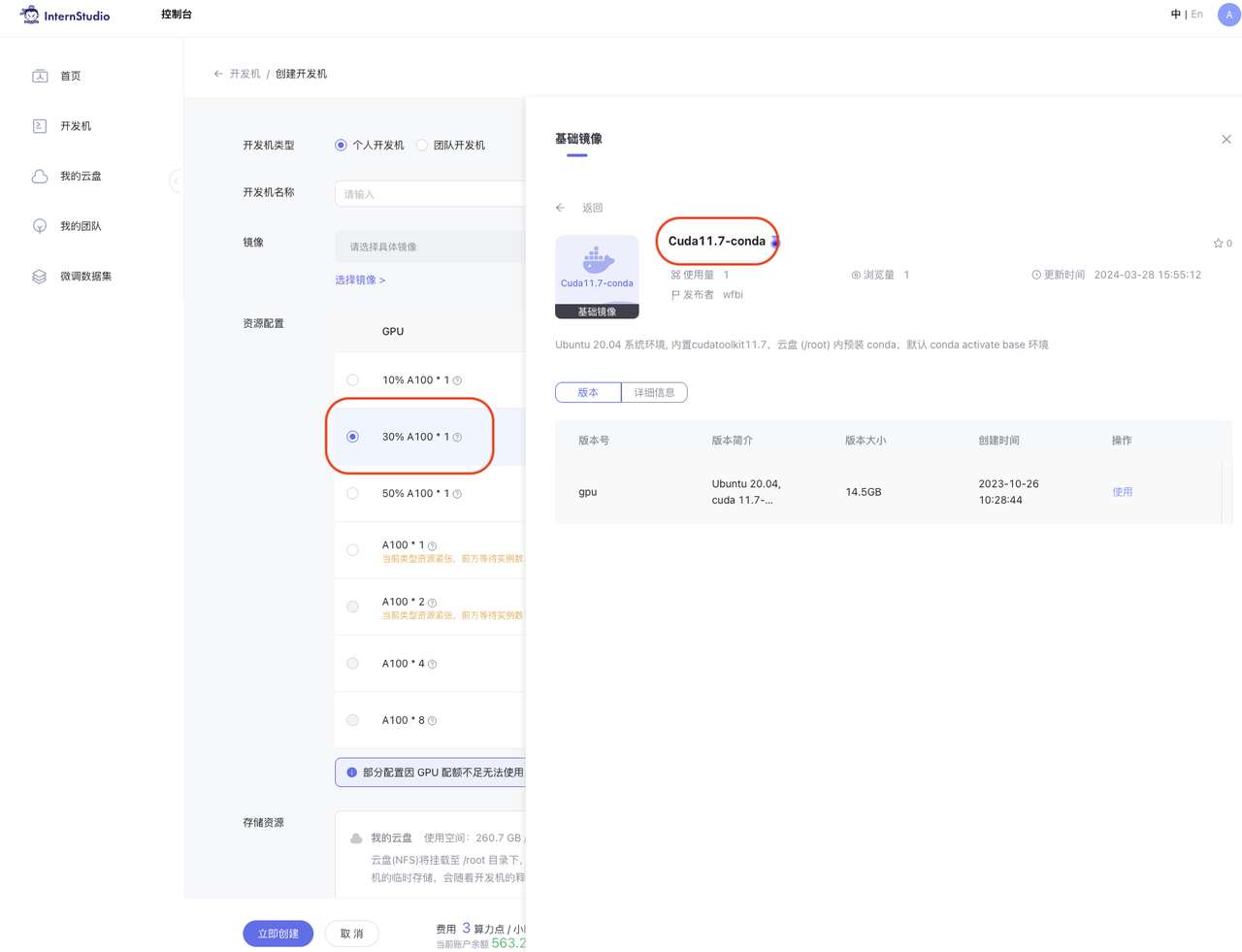
首先登录 InternStudio ,选择创建开发机:

镜像选择 Cuda11.7-conda ,资源类型选择 30% A\*100。输入开发机名称 huixiangdou, 点击立即创建。
在 开发机 页面选择刚刚创建的个人开发机 huixiangdou,单击 启动:

等服务器准备好开发机资源后,点击 进入开发机,继续进行开发环境的搭建。
命令行中输入一下命令,创建茴香豆专用 conda 环境:
studio-conda -o internlm-base -t huixiangdou创建成功,用下面的命令激活环境:
conda activate huixiangdou
环境激活成功后,命令行前的括号内会显示正在使用的环境,请确保所有茴香豆操作指令在 huixiangdou 环境下运行。
下面开始茴香豆本地标准版的安装。
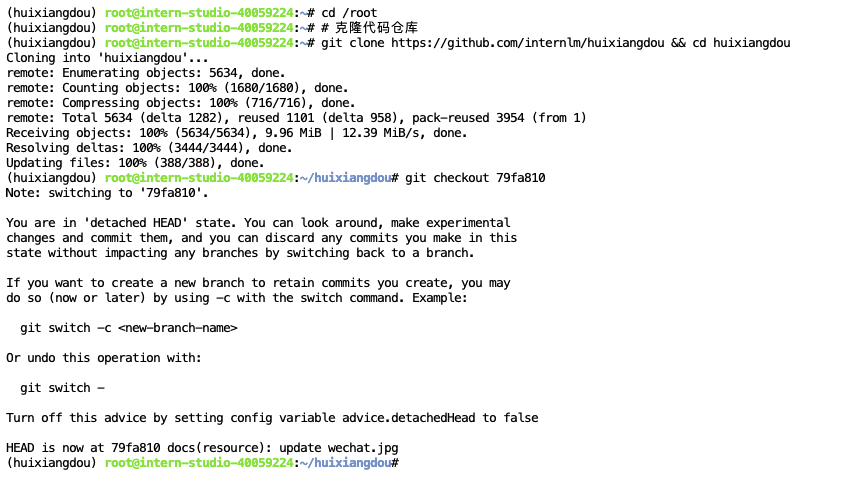
先从茴香豆仓库拉取代码到服务器:
cd /root
# 克隆代码仓库
git clone https://github.com/internlm/huixiangdou && cd huixiangdou
git checkout 79fa810拉取完成后进入茴香豆文件夹,开始安装。
首先安装茴香豆所需依赖:
conda activate huixiangdou
# parsing `word` format requirements
apt update
apt install python-dev libxml2-dev libxslt1-dev antiword unrtf poppler-utils pstotext tesseract-ocr flac ffmpeg lame libmad0 libsox-fmt-mp3 sox libjpeg-dev swig libpulse-dev
# python requirements
pip install BCEmbedding==0.15 cmake==3.30.2 lit==18.1.8 sentencepiece==0.2.0 protobuf==5.27.3 accelerate==0.33.0
pip install -r requirements.txt
# python3.8 安装 faiss-gpu 而不是 faiss茴香豆默认会根据配置文件自动下载对应的模型文件,为了节省时间,本次教程所需的模型已经提前下载到服务器中,我们只需要为本次教程所需的模型建立软连接,然后在配置文件中设置相应路径就可以:
# 创建模型文件夹
cd /root && mkdir models
# 复制BCE模型
ln -s /root/share/new_models/maidalun1020/bce-embedding-base_v1 /root/models/bce-embedding-base_v1
ln -s /root/share/new_models/maidalun1020/bce-reranker-base_v1 /root/models/bce-reranker-base_v1
# 复制大模型参数(下面的模型,根据作业进度和任务进行**选择一个**就行)
ln -s /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-7b /root/models/internlm2-chat-7b完成后可以在相应目录下看到所需模型文件。

茴香豆的所有功能开启和模型切换都可以通过 config.ini 文件进行修改,默认参数如下:

执行下面的命令更改配置文件,让茴香豆使用本地模型:
sed -i '9s#.*#embedding_model_path = "/root/models/bce-embedding-base_v1"#' /root/huixiangdou/config.ini
sed -i '15s#.*#reranker_model_path = "/root/models/bce-reranker-base_v1"#' /root/huixiangdou/config.ini
sed -i '43s#.*#local_llm_path = "/root/models/internlm2-chat-7b"#' /root/huixiangdou/config.ini也可以用编辑器手动修改,文件位置为 /root/huixiangdou/config.ini。
修改后的配置文件如下:
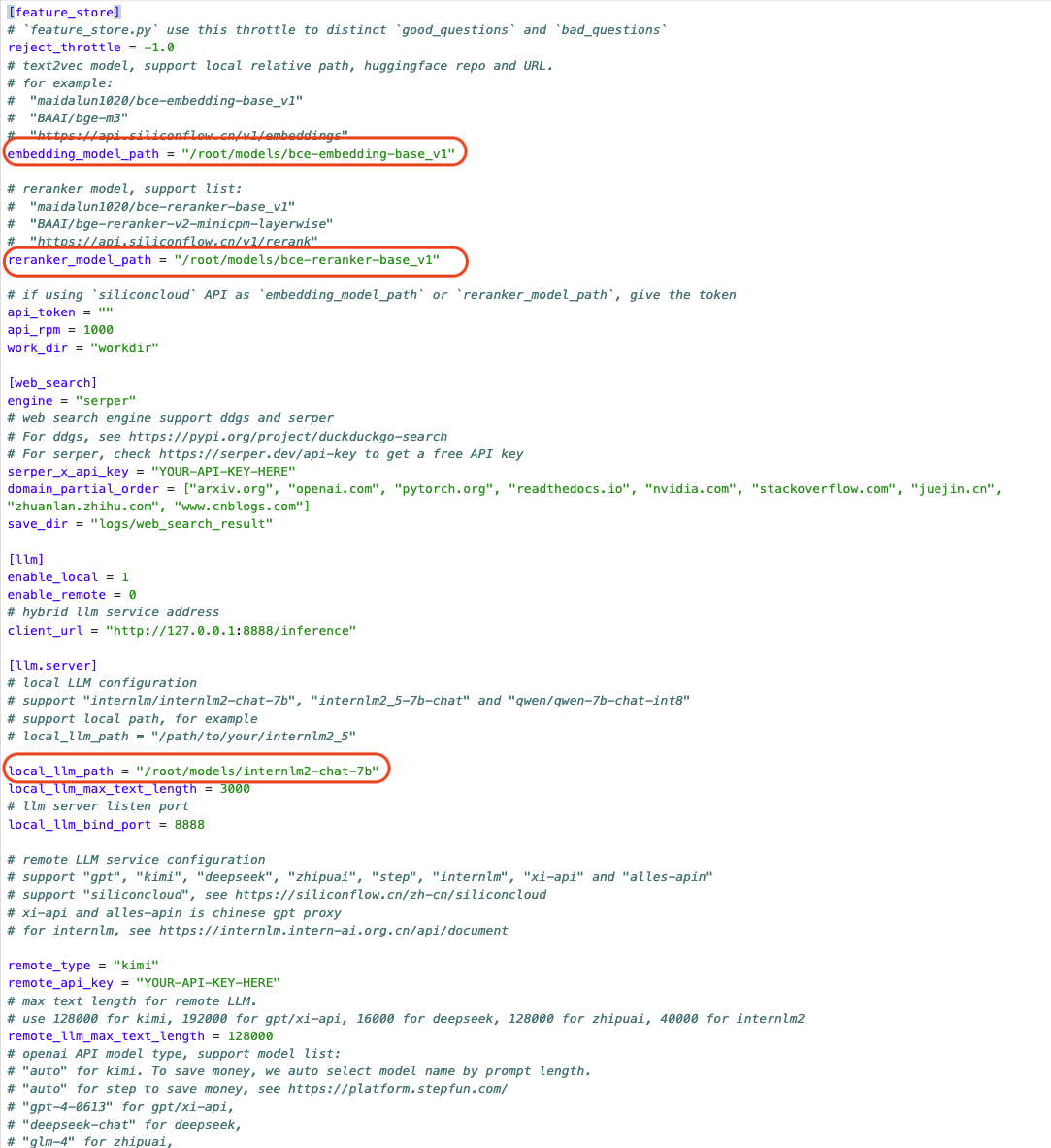
注意!配置文件默认的模型和下载好的模型相同。如果不修改地址为本地模型地址,茴香豆将自动从 huggingface hub 拉取模型。如果选择拉取模型的方式,需要提前在命令行中运行 huggingface-cli login 命令,验证 huggingface 权限。
修改完配置文件后,就可以进行知识库的搭建,本次教程选用的是茴香豆和 MMPose 的文档,利用茴香豆搭建一个茴香豆和 MMPose 的知识问答助手。
conda activate huixiangdou
cd /root/huixiangdou && mkdir repodir
git clone https://github.com/internlm/huixiangdou --depth=1 repodir/huixiangdou
git clone https://github.com/open-mmlab/mmpose --depth=1 repodir/mmpose
# Save the features of repodir to workdir, and update the positive and negative example thresholds into `config.ini`
mkdir workdir
python3 -m huixiangdou.service.feature_store在 huixiangdou 文件加下创建 repodir 文件夹,用来储存知识库原始文档。再创建一个文件夹 workdir 用来存放原始文档特征提取到的向量知识库。

知识库创建成功后会有一系列小测试,检验问题拒答和响应效果,如图所示,关于“mmpose 安装”的问题,测试结果可以很好的反馈相应答案和对应的参考文件,但关于“std::vector 使用”的问题,因为属于 C++ 范畴,不再在知识库范围内,测试结果显示拒答,说明我们的知识助手工作正常。
和 Web 版一样,本地版也可以通过编辑正反例来调整茴香豆的拒答和响应,正例位于 /root/huixiangdou/resource/good_questions.json 文件夹中,反例位于/root/huixiangdou/resource/bad_questions.json。
需要注意的是,每次更新原始知识文档和正反例,都需要重新运行 python3 -m huixiangdou.service.feature_store 命令进行向量知识库的重新创建和应答阈值的更新。

配置中可见,在运行过一次特征提取后,茴香豆的阈值从 -1.0 更新到了 0.33。 配置文件中的 work_dir 参数指定了特征提取后向量知识库存放的位置。如果有多个知识库快速切换的需求,可以通过更改该参数实现。
运行下面的命令,可以用命令行对现有知识库问答助手进行测试:
conda activate huixiangdou
cd /root/huixiangdou
python3 -m huixiangdou.main --standalone

通过命令行的方式可以看到对话的结果以及中间的过程,便于我们确认知识库是否覆盖需求,正反例是否合理。
茴香豆也用 gradio 搭建了一个 Web UI 的测试界面,用来测试本地茴香豆助手的效果。
本节课程中,茴香豆助手搭建在远程服务器上,因此需要先建立本地和服务器之间的透传,透传默认的端口为 7860,在本地机器命令行中运行如下命令:
ssh -CNg -L 7860:127.0.0.1:7860 [email protected] -p <你的ssh端口号>在运行茴香豆助手的服务器端,输入下面的命令,启动茴香豆 Web UI:
conda activate huixiangdou
cd /root/huixiangdou
python3 -m huixiangdou.gradio
看到上图相同的结果,说明 Gradio 服务启动成功,在本地浏览器中输入 127.0.0.1:7860 打开茴香豆助手测试页面:
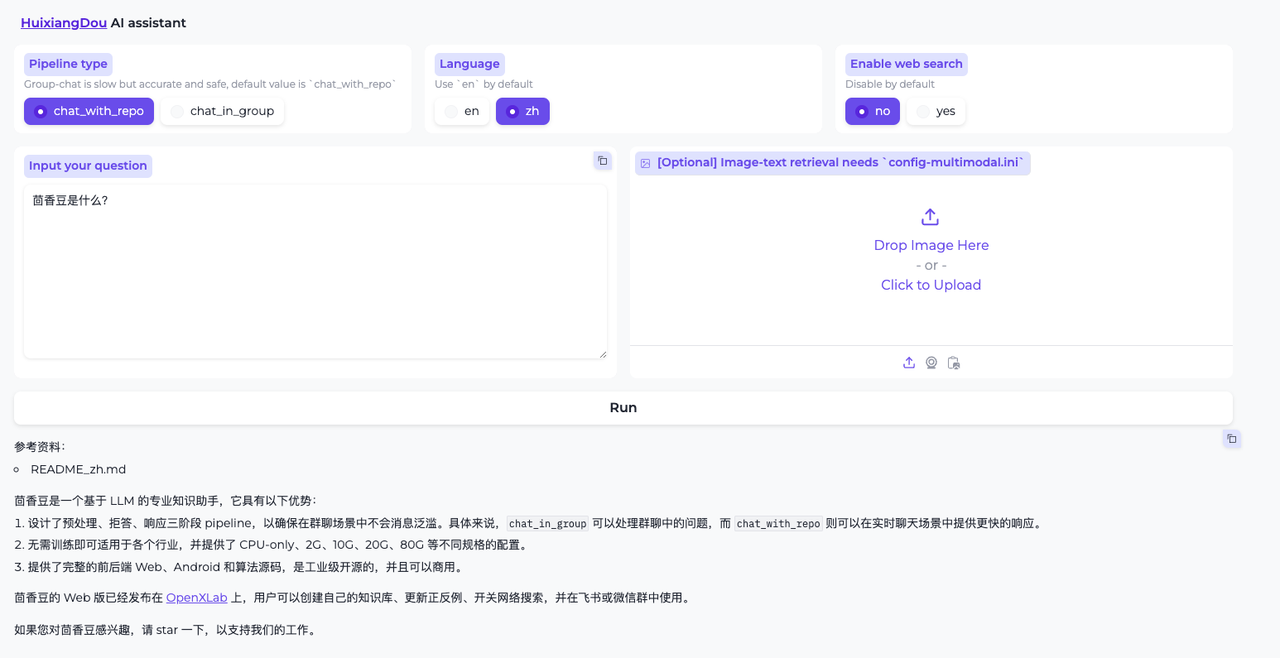
现在就可以用页面测试一下茴香豆的交互效果了。
本地版茴香豆的群集成和 Web 版一样,需要有公网 IP 的服务器,微信仅支持特定 Android 版本。
飞书集成:
-
pip install -r requirements-lark-group.txt -
教程 https://github.com/InternLM/HuixiangDou/blob/main/docs/add_lark_group_zh.md
茴香豆拥有者丰富的功能,可以应对不同企业的需求,下面介绍几个真实场景中常用的高阶功能。
对于本地知识库没有提到的问题或是实时性强的问题,可以开启茴香豆的网络搜索功能,结合网络的搜索结果,生成更可靠的回答。
开启网络搜索功能需要用到 Serper 提供的 API:
-
登录 Serper ,注册:
-
进入 Serper API 界面,复制自己的 API-key:

- 替换
/huixiangdou/config.ini中的 ${YOUR-API-KEY} 为自己的API-key:
[web_search]
check https://serper.dev/api-key to get a free API key
x_api_key = "${YOUR-API-KEY}"
domain_partial_order = ["openai.com", "pytorch.org", "readthedocs.io", "nvidia.com", "stackoverflow.com", "juejin.cn", "zhuanlan.zhihu.com", "www.cnblogs.com"]
save_dir = "logs/web_search_result"其中 domain_partial_order 可以设置网络搜索的范围。
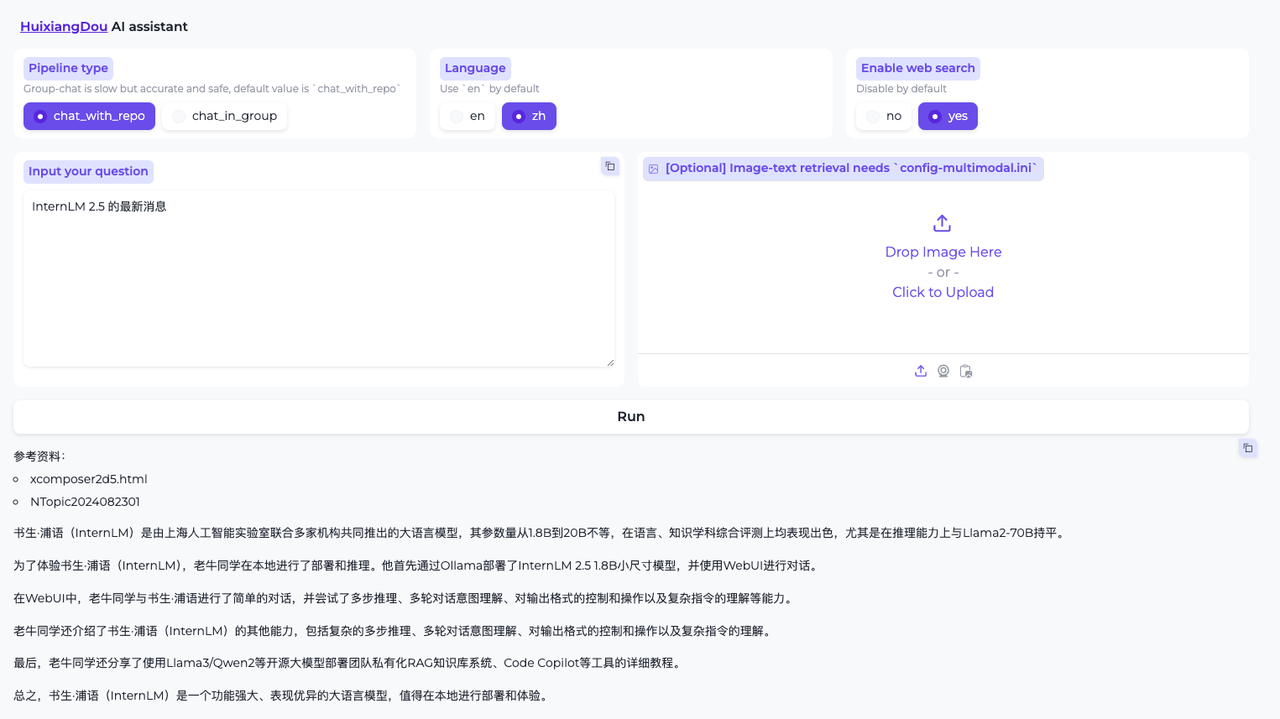 .
.
开启网络搜索功能后的智能助手问答结果。可以看到,尽管文档中并未加入 InternLM 相关的内容,茴香豆依然综合了网络检索结果对提出的问题进行了回答。

除了将 LLM 模型下载到本地,茴香豆还可以通过调用远程模型 API 的方式实现知识问答助手。支持从 CPU-only、2G、10G、20G、到 80G 不同的硬件配置,满足不同规模的企业需求。
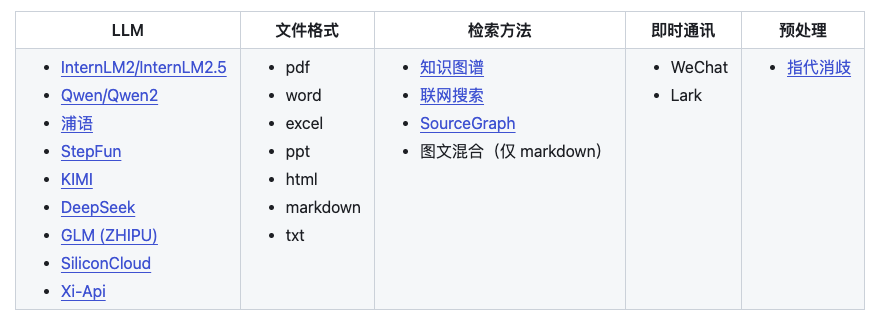
茴香豆中有 3 处调用了模型,分别是 嵌入模型(Embedding)、重排模型(Rerank)和 大语音模型(LLM)。
其中特征提取部分(嵌入、重排)本地运行需要 2G 显存。如果运行的服务器没有显卡,也可以选择调用硅基流动 的 API。
-
登录 SiliconFlow 官网注册账号。
-
登录后,进入体验中心 ,复制个人 API 密匙:
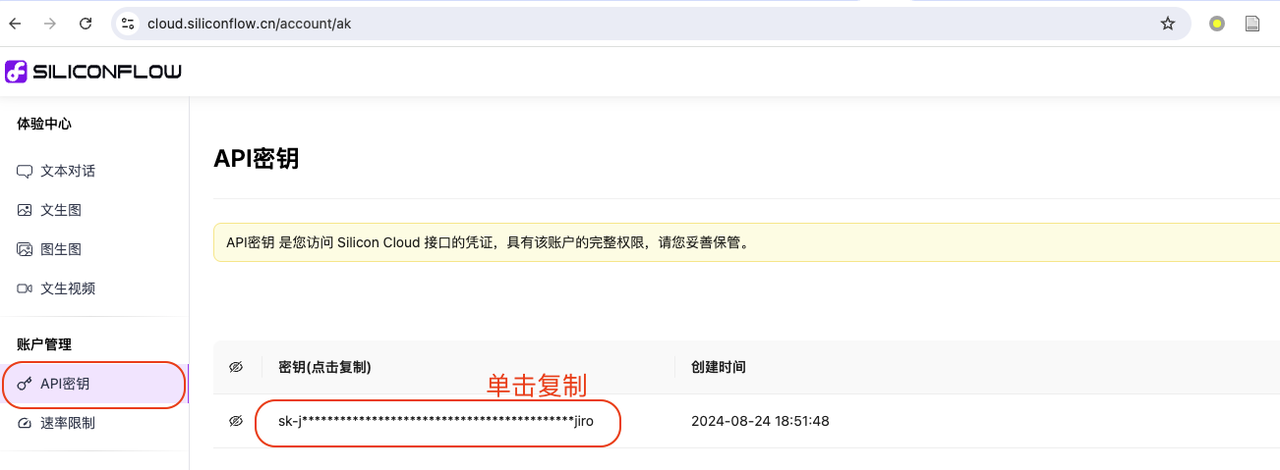
- 将 API,填入到
/huixiangdou/config.ini文件中api_token处,同时注意如图所示修改嵌入和重排模型地址(embedding_model_path,reranker_model_path):

目前茴香豆只支持 siliconflow 中向量&重排 bce 模型的调用,后续会增加其他向量&重排模型的支持。
想要启用远端大语言模型,首先修改 /huixiangdou/config.ini 本地和远程LLM 开关:
enable_local = 0 # 关闭本地模型
enable_remote = 1 # 启用云端模型接着,如下图所示,修改 remote_ 相关配置,填写 API key、模型类型等参数,茴香豆支持 OpenAI 的 API格式调用。
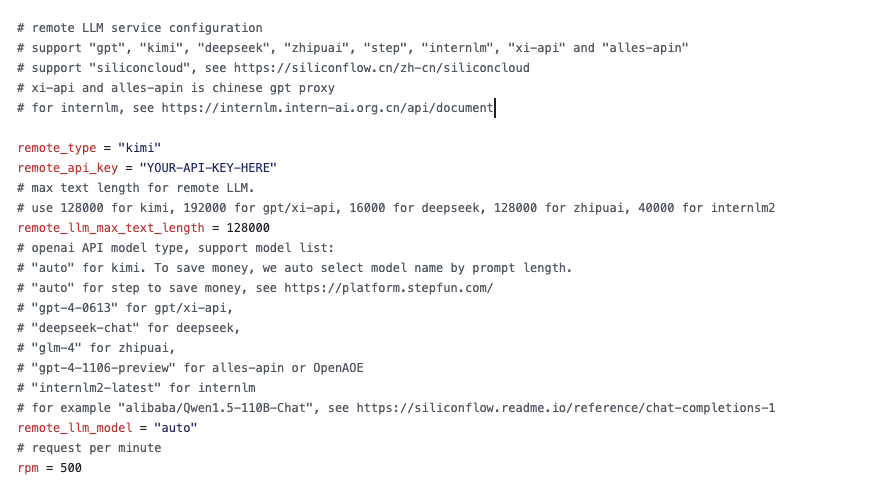
| 远程大模型配置选项 | GPT | Kimi | Deepseek | ChatGLM | Stepfun | InternLM | Siliconcloud | xi-api | alles-apin |
|---|---|---|---|---|---|---|---|---|---|
remote_type |
gpt | kimi | deepseek | zhipuai | step | internlm | - | xi-api | alles-apin |
remote_llm_max_text_length 最大值 |
192000 | 128000 | 16000 | 128000 | - | 40000 | - | 192000 | - |
remote_llm_model |
"gpt-4-0613" | "auto" | "deepseek-chat" | "glm-4" | "auto" | "internlm2-latest" | - | "gpt-4-0613" | "gpt-4-1106-preview" |
-
remote_llm_model为 "auto" 时,会根据提示词长短选择模型大小,以节省开支 -
Siliconcloud 支持的模型请查看 https://siliconflow.cn/zh-cn/models
如果同时开启 local 和 remote 模型,茴香豆将采用混合模型的方案,详见 技术报告,效果更好。
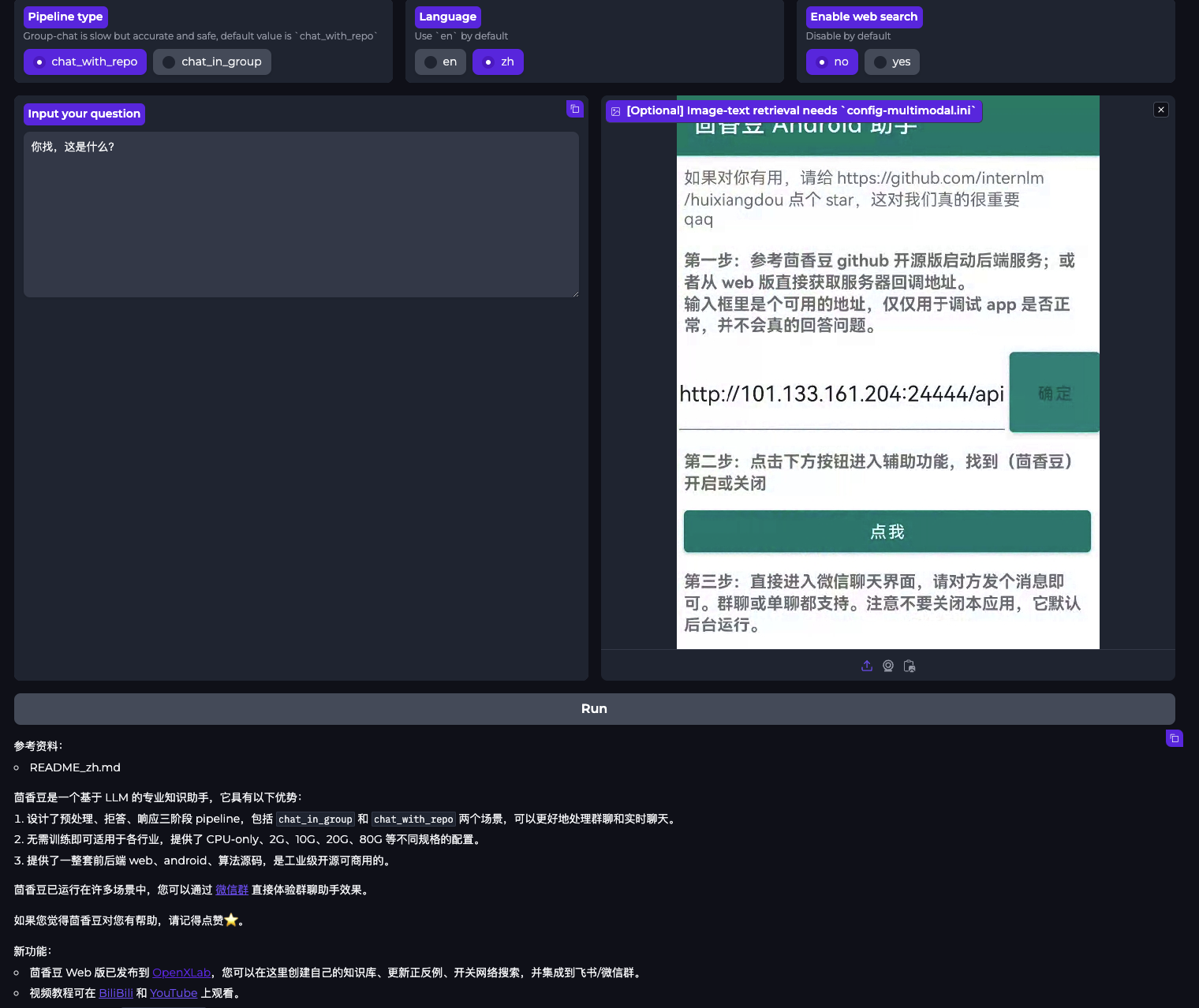
最新的茴香豆支持了多模态的图文检索,启用该功能后,茴香豆可以解析上传的图片内容,并根据图片内容和文字提示词进行检索回答。
图文检索功能需要至少 10G 显存支持本地向量和重排模型运行,下面的示例使用的全部是本地模型,因此需要 40G 的显存,在 Intern-Studio 中需要选择 50% A100 * 1 服务器:

首先,我们需要将茴香豆更新至最新版,如果之前没有下载茴香豆,可以跳过此步骤,参考2.2.1 下载茴香豆直接下载最新版茴香豆。 更新茴香豆:
conda activate huixiangdou
cd huixiangdou
git stash # 弃用之前的修改,如果需要保存,可将冲突文件另存为新文件名
git checkout main
git pull
git checkout bec2f6af9 # 支持多模态的最低版本开启多模态功能需要支持图文的多模态向量和重排模型,本教程使用的是智源旗下的 BGE 开源模型家族。
这次我们使用 huggingface-cli download 的方法从 Huggingface Hub 上拉取模型到本地:
# 设置环境变量
export HF_ENDPOINT='https://hf-mirror.com' # 使用 huggingface 中国镜像加速下载,如果在国外,忽略此步骤
# 下载模型
## 模型文件较大,如果遇到下载报错,重新运行命令就好
huggingface-cli download BAAI/bge-m3 --local-dir /root/models/bge-m3
huggingface-cli download BAAI/bge-visualized --local-dir /root/models/bge-visualized
huggingface-cli download BAAI/bge-reranker-v2-minicpm-layerwise --local-dir /root/models/bge-reranker-v2-minicpm-layerwise
# 需要手动将视觉模型移动到 BGE-m3 文件夹下
mv /root/models/bge-visualized/Visualized_m3.pth /root/models/bge-m3/完整的模型目录应包含如下文件:

接下来,我们安装多模态所需的对应依赖,如果是第一次安装茴香豆,需要按照 2 茴香豆本地标准版搭建 先完成基础版茴香豆的安装。
安装最新的 FlagEmbedding:
conda activate huixiangdou
cd /root/
# 从官方 github 安装最新版
git clone https://github.com/FlagOpen/FlagEmbedding.git
cd FlagEmbedding
pip install .
# 复制 FlagEmbedding 缺失的文件,注意 huixiangdou/lib/python3.10/site-packages 是教程开始设置的环境,如果个人有更改,需要根据自己的环境重新填入对应的地址
cp ~/FlagEmbedding/FlagEmbedding/visual/eva_clip/model_configs /root/.conda/envs/huixiangdou/lib/python3.10/site-packages/FlagEmbedding/visual/eva_clip/
cp ~/FlagEmbedding/FlagEmbedding/visual/eva_clip/bpe_simple_vocab_16e6.txt.gz /root/.conda/envs/huixiangdou/lib/python3.10/site-packages/FlagEmbedding/visual/eva_clip/
# 其他依赖包
pip install timm ftfy peft 现在,我们要修改相应的配置文件,启动多模态。这里,我们启用新的配置文件 config-multimodal.ini。
首先修改向量和重排模型位置为刚刚下载的本地模型地址:
sed -i '6s#.*#embedding_model_path = "/root/models/bge-m3"#' /root/huixiangdou/config-multimodal.ini
sed -i '7s#.*#reranker_model_path = "/root/models/bge-reranker-v2-minicpm-layerwise"#' /root/huixiangdou/config-multimodal.ini接下来修改要调用的 LLM 为本地的 intern2-chat-7b 模型,然后打开本地模型开关,开启远程模型开关:
提示,真实场景的话还是建议使用远程模型或更大的 LLM,7B模型应对多模态效果一般。
sed -i '31s#.*#local_llm_path = "/root/models/internlm2-chat-7b"#' /root/huixiangdou/config-multimodal.ini
sed -i '20s#.*#enable_local = 1#' /root/huixiangdou/config-multimodal.ini
sed -i '21s#.*#enable_remote = 0#' /root/huixiangdou/config-multimodal.ini为了不破坏之前的向量知识库,这里我们更改一下多模态向量知识库的位置:
sed -i '8s#.*#work_dir = "workdir-multi"#' /root/huixiangdou/config-multimodal.ini
sed -i '61s#.*#enable_cr = 0#' /root/huixiangdou/config-multimodal.ini # 关闭指代消岐功能或者手动修改,修改后的配置文件 config-multimodal.ini 如下:

向量知识库的匹配依赖于特征提取时使用的向量和重排模型,多模态功能开启后,我们要使用新的模型,因此需要重新提取一个多模态向量知识库,使用我们刚刚修改好的配置文件:
# 新的向量知识库文件夹
mkdir workdir-multi
# 提取多模态向量知识库
python3 -m huixiangdou.service.feature_store --config_path config-multimodal.ini启动 Gradio UI 界面,试用多模态检索功能:
conda activate huixiangdou
cd /root/huixiangdou
python3 -m huixiangdou.gradio --config_path config-multimodal.ini