
参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
给定两个字符串 text1 和 text2,返回这两个字符串的最长公共子序列的长度。
一个字符串的 子序列 是指这样一个新的字符串:它是由原字符串在不改变字符的相对顺序的情况下删除某些字符(也可以不删除任何字符)后组成的新字符串。
例如,"ace" 是 "abcde" 的子序列,但 "aec" 不是 "abcde" 的子序列。两个字符串的「公共子序列」是这两个字符串所共同拥有的子序列。
若这两个字符串没有公共子序列,则返回 0。
示例 1:
输入:text1 = "abcde", text2 = "ace" 输出:3 解释:最长公共子序列是 "ace",它的长度为 3。
示例 2: 输入:text1 = "abc", text2 = "abc" 输出:3 解释:最长公共子序列是 "abc",它的长度为 3。
示例 3: 输入:text1 = "abc", text2 = "def" 输出:0 解释:两个字符串没有公共子序列,返回 0。
提示:
- 1 <= text1.length <= 1000
- 1 <= text2.length <= 1000 输入的字符串只含有小写英文字符。
本题和动态规划:718. 最长重复子数组区别在于这里不要求是连续的了,但要有相对顺序,即:"ace" 是 "abcde" 的子序列,但 "aec" 不是 "abcde" 的子序列。
继续动规五部曲分析如下:
- 确定dp数组(dp table)以及下标的含义
dp[i][j]:长度为[0, i - 1]的字符串text1与长度为[0, j - 1]的字符串text2的最长公共子序列为dp[i][j]
有同学会问:为什么要定义长度为[0, i - 1]的字符串text1,定义为长度为[0, i]的字符串text1不香么?
这样定义是为了后面代码实现方便,如果非要定义为长度为[0, i]的字符串text1也可以,我在 动态规划:718. 最长重复子数组 中的「拓展」里 详细讲解了区别所在,其实就是简化了dp数组第一行和第一列的初始化逻辑。
- 确定递推公式
主要就是两大情况: text1[i - 1] 与 text2[j - 1]相同,text1[i - 1] 与 text2[j - 1]不相同
如果text1[i - 1] 与 text2[j - 1]相同,那么找到了一个公共元素,所以dp[i][j] = dp[i - 1][j - 1] + 1;
如果text1[i - 1] 与 text2[j - 1]不相同,那就看看text1[0, i - 2]与text2[0, j - 1]的最长公共子序列 和 text1[0, i - 1]与text2[0, j - 2]的最长公共子序列,取最大的。
即:dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]);
代码如下:
if (text1[i - 1] == text2[j - 1]) {
dp[i][j] = dp[i - 1][j - 1] + 1;
} else {
dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]);
}- dp数组如何初始化
先看看dp[i][0]应该是多少呢?
test1[0, i-1]和空串的最长公共子序列自然是0,所以dp[i][0] = 0;
同理dp[0][j]也是0。
其他下标都是随着递推公式逐步覆盖,初始为多少都可以,那么就统一初始为0。
代码:
vector<vector<int>> dp(text1.size() + 1, vector<int>(text2.size() + 1, 0));
- 确定遍历顺序
从递推公式,可以看出,有三个方向可以推出dp[i][j],如图:
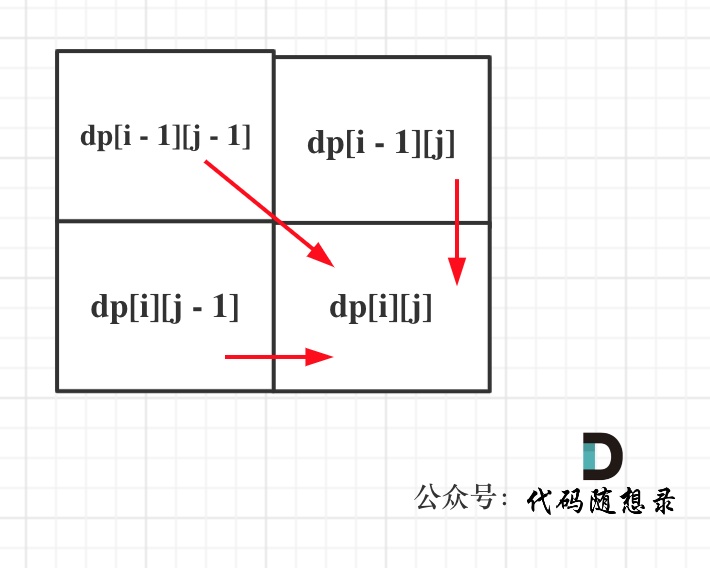
那么为了在递推的过程中,这三个方向都是经过计算的数值,所以要从前向后,从上到下来遍历这个矩阵。
- 举例推导dp数组
以输入:text1 = "abcde", text2 = "ace" 为例,dp状态如图:
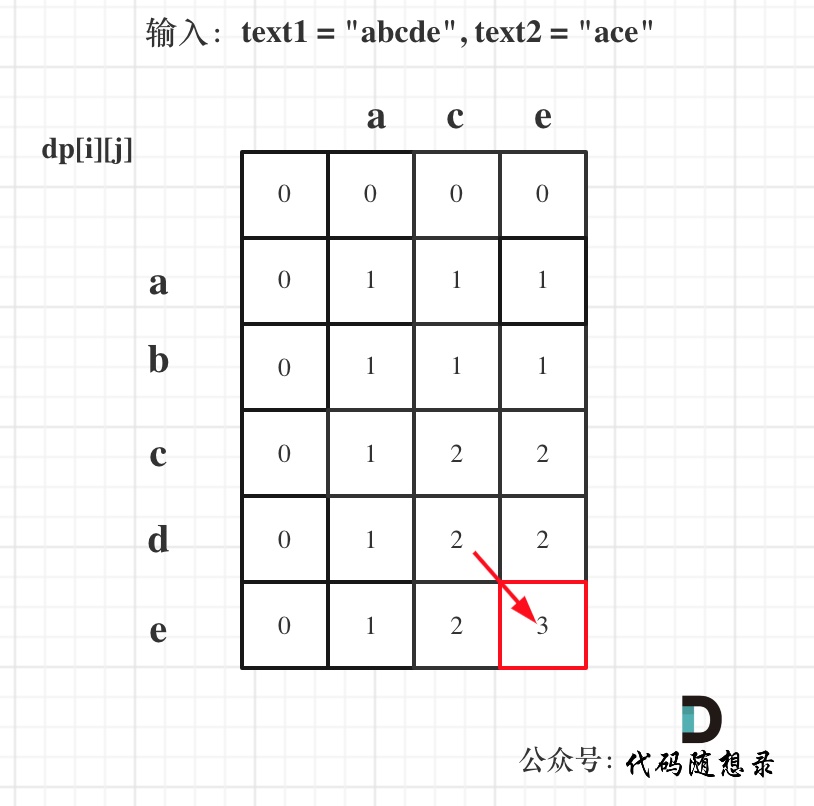
最后红框dp[text1.size()][text2.size()]为最终结果
以上分析完毕,C++代码如下:
class Solution {
public:
int longestCommonSubsequence(string text1, string text2) {
vector<vector<int>> dp(text1.size() + 1, vector<int>(text2.size() + 1, 0));
for (int i = 1; i <= text1.size(); i++) {
for (int j = 1; j <= text2.size(); j++) {
if (text1[i - 1] == text2[j - 1]) {
dp[i][j] = dp[i - 1][j - 1] + 1;
} else {
dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]);
}
}
}
return dp[text1.size()][text2.size()];
}
};Java:
/*
二维dp数组
*/
class Solution {
public int longestCommonSubsequence(String text1, String text2) {
int[][] dp = new int[text1.length() + 1][text2.length() + 1]; // 先对dp数组做初始化操作
for (int i = 1 ; i <= text1.length() ; i++) {
char char1 = text1.charAt(i - 1);
for (int j = 1; j <= text2.length(); j++) {
char char2 = text2.charAt(j - 1);
if (char1 == char2) { // 开始列出状态转移方程
dp[i][j] = dp[i - 1][j - 1] + 1;
} else {
dp[i][j] = Math.max(dp[i - 1][j], dp[i][j - 1]);
}
}
}
return dp[text1.length()][text2.length()];
}
}
/**
一维dp数组
*/
class Solution {
public int longestCommonSubsequence(String text1, String text2) {
int n1 = text1.length();
int n2 = text2.length();
// 多从二维dp数组过程分析
// 关键在于 如果记录 dp[i - 1][j - 1]
// 因为 dp[i - 1][j - 1] <!=> dp[j - 1] <=> dp[i][j - 1]
int [] dp = new int[n2 + 1];
for(int i = 1; i <= n1; i++){
// 这里pre相当于 dp[i - 1][j - 1]
int pre = dp[0];
for(int j = 1; j <= n2; j++){
//用于给pre赋值
int cur = dp[j];
if(text1.charAt(i - 1) == text2.charAt(j - 1)){
//这里pre相当于dp[i - 1][j - 1] 千万不能用dp[j - 1] !!
dp[j] = pre + 1;
} else{
// dp[j] 相当于 dp[i - 1][j]
// dp[j - 1] 相当于 dp[i][j - 1]
dp[j] = Math.max(dp[j], dp[j - 1]);
}
//更新dp[i - 1][j - 1], 为下次使用做准备
pre = cur;
}
}
return dp[n2];
}
}Python:
class Solution:
def longestCommonSubsequence(self, text1: str, text2: str) -> int:
len1, len2 = len(text1)+1, len(text2)+1
dp = [[0 for _ in range(len1)] for _ in range(len2)] # 先对dp数组做初始化操作
for i in range(1, len2):
for j in range(1, len1): # 开始列出状态转移方程
if text1[j-1] == text2[i-1]:
dp[i][j] = dp[i-1][j-1]+1
else:
dp[i][j] = max(dp[i-1][j], dp[i][j-1])
return dp[-1][-1]Go:
func longestCommonSubsequence(text1 string, text2 string) int {
t1 := len(text1)
t2 := len(text2)
dp:=make([][]int,t1+1)
for i:=range dp{
dp[i]=make([]int,t2+1)
}
for i := 1; i <= t1; i++ {
for j := 1; j <=t2; j++ {
if text1[i-1]==text2[j-1]{
dp[i][j]=dp[i-1][j-1]+1
}else{
dp[i][j]=max(dp[i-1][j],dp[i][j-1])
}
}
}
return dp[t1][t2]
}
func max(a,b int)int {
if a>b{
return a
}
return b
}Javascript:
const longestCommonSubsequence = (text1, text2) => {
let dp = Array.from(Array(text1.length+1), () => Array(text2.length+1).fill(0));
for(let i = 1; i <= text1.length; i++) {
for(let j = 1; j <= text2.length; j++) {
if(text1[i-1] === text2[j-1]) {
dp[i][j] = dp[i-1][j-1] +1;;
} else {
dp[i][j] = Math.max(dp[i-1][j], dp[i][j-1])
}
}
}
return dp[text1.length][text2.length];
};TypeScript:
function longestCommonSubsequence(text1: string, text2: string): number {
/**
dp[i][j]: text1中前i-1个和text2中前j-1个,最长公共子序列的长度
*/
const length1: number = text1.length,
length2: number = text2.length;
const dp: number[][] = new Array(length1 + 1).fill(0)
.map(_ => new Array(length2 + 1).fill(0));
for (let i = 1; i <= length1; i++) {
for (let j = 1; j <= length2; j++) {
if (text1[i - 1] === text2[j - 1]) {
dp[i][j] = dp[i - 1][j - 1] + 1;
} else {
dp[i][j] = Math.max(dp[i][j - 1], dp[i - 1][j]);
}
}
}
return dp[length1][length2];
};Rust:
pub fn longest_common_subsequence(text1: String, text2: String) -> i32 {
let (n, m) = (text1.len(), text2.len());
let (s1, s2) = (text1.as_bytes(), text2.as_bytes());
let mut dp = vec![0; m + 1];
let mut last = vec![0; m + 1];
for i in 1..=n {
dp.swap_with_slice(&mut last);
for j in 1..=m {
dp[j] = if s1[i - 1] == s2[j - 1] {
last[j - 1] + 1
} else {
last[j].max(dp[j - 1])
};
}
}
dp[m]
}
