


虚拟试衣网络的核心代码,通过JPP-Net和CP-VTON多阶段深度网络,在更上层提供了易于编程的接口,并整合了一些传统图像处理方法为接口。
实现功能:
- 实现快速的人体图+衣服图=穿搭图片的合成,让人穿上指定的衣服。
- 基于Flask提供Web服务和后端响应服务
客户端和服务通过base64编码图片后,通过Json格式来进行通讯。Json format
Model.py为你唯一需要关心的代码文件。安装了依赖并进行初始化model.init(path...)之后,直接通过model.predict(human_img, c_img, ...)就可以完成模型的前向预测。操作的图片对象均为RGB通道的numpy array。
例子请见模板notebook。
Model核心的外部调用接口为predict函数,关注文档注释提及的5个flag参数即可。
def predict(self, human_img, c_img, need_pre=True, need_bright=False, keep_back=False, need_dilate=False, check_dirty=False):
'''
输入:
human_img为人体图片,c_img为256*192的衣服图片
五个flag:
need_pre为是否需要预处理(crop+resize到256*192)
need_bright为亮度增强,
keep_back为基于mask来保留除了上衣以外的背景部分,
need_dilate为膨胀柔化keep_back计算的mask,需要keep_back开启
check_dirty为增加检查数据是否有肢体遮挡交叉(可能检测不全)
返回:
一个(256,192,3)的穿上衣服的图片,
画面中人体的置信度,0则为触发强排除条件(检测到难样本等)
'''
torch==1.2.0
tensorflow==1.12.0
torchvision==0.2.0
目前代码需要在GPU环境运行,若要修改到CPU环境,请删除所有CPVTON.py和Networks.py两个文件中所有的.cuda()调用。
CPU Mode: Model(.., use_cuda = False)
Tesla P40上,显存约占用7.12GB,单张图片预测约为0.62s(JPPNet 0.6s, CPVTON 0.02s)。
若关注Real Time的高速,请更换人体特征提取思路,如尝试使用CE2P
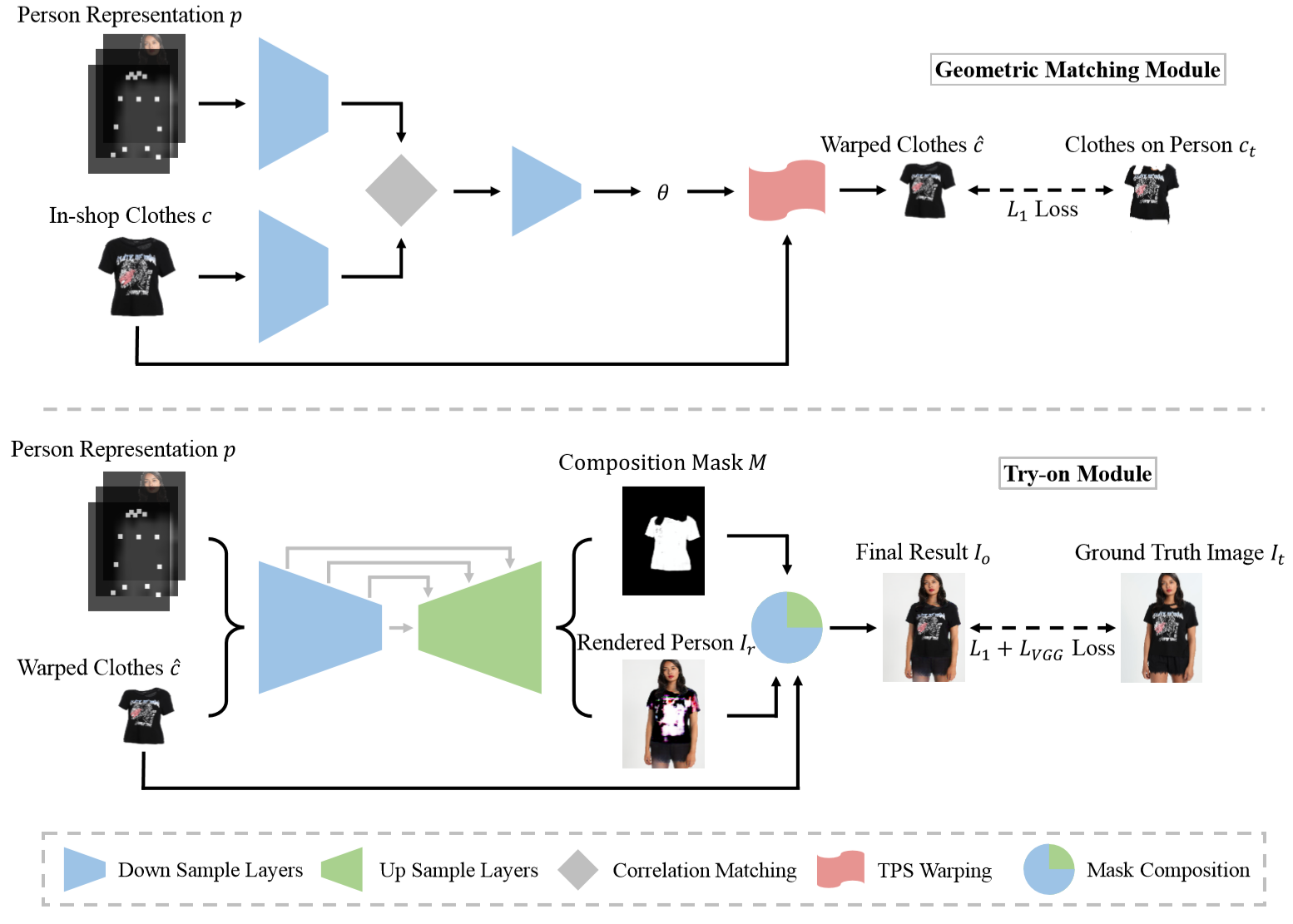
整体的网络由三个部分组成:
- JPP-Net: 用于提取人体的特征,对人体图片进行pose estimation & human parsing
- Geometric Matching Module: 综合人体特征和衣服图片,对衣服进行基于学习的类TPS变换。
- Try-on Module: 综合人体特征和扭曲后的衣服图片,进行人体和衣服合成。
| 文件名 | 功能 |
|---|---|
| main.py | flask服务相关 |
| get.py | client向flask发起predict请求的例子 |
| Model.py | 提供虚拟试衣网络的外部接口 |
| CPVTON.py | CPVTON模型整合预测代码 |
| networks.py | CPVTON模型网络定义 |
| JPPNet.py | JPP-Net 预测代码 |
| static/* | flask的静态访问资源 |
| data/*, example/* | 样例测试图片 |
| template/* | flask的模板html based on Jinjia |
| checkpoints/* | 存预训练模型 |
coming soon..
下载链接:Google Drive and 百度网盘
- 优化整合原模型
- 网页端虚拟试衣服务
- 基础完备的文档和注释
- 客户端post规范文档
- 预训练模型下载
- CPU环境支持
模型的设计基于JPP-Net与CPVTON,及其开源代码。
VITON: An Image-based Virtual Try-on Network,Xintong Han, Zuxuan Wu, Zhe Wu, Ruichi Yu, Larry S. Davis. CVPR 2018
(CP-VTON) Toward Characteristic-Preserving Image-based Virtual Try-On Networks, Bochao Wang, Huabin Zheng, Xiaodan Liang, Yimin Chen, Liang Lin, Meng Yang. ECCV 2018
(JPP-Net) Look into Person: Joint Body Parsing & Pose Estimation Network and A New Benchmark, Xiaodan Liang, Ke Gong, Xiaohui Shen, Liang Lin, T-PAMI 2018.
Powered By Imba, JD Digits