Paddle Lite为Paddle-Mobile的升级版,定位支持包括手机移动端在内更多场景的轻量化高效预测,支持更广泛的硬件和平台,是一个高性能、轻量级的深度学习预测引擎。在保持和PaddlePaddle无缝对接外,也兼容支持其他训练框架产出的模型。
完整使用文档位于 PaddleLite 文档 。
执行阶段和计算优化阶段实现良好解耦拆分,移动端可以直接部署执行阶段,无任何第三方依赖。 包含完整的80个 Op+85个 Kernel 的动态库,对于ARMV7只有800K,ARMV8下为1.3M,并可以裁剪到更低。 在应用部署时,载入模型即可直接预测,无需额外分析优化。
极致的 ARM CPU 性能优化,针对不同微架构特点实现kernel的定制,最大发挥计算性能,在主流模型上展现出领先的速度优势。 支持INT8量化计算,结合 PaddleSlim 模型压缩工具 中 INT8量化训练功能,可以提供高精度高性能的预测能力。 在Huawei NPU, FPGA上也具有有很好的性能表现。
最新 Benchmark 位于 benchmark。
硬件方面,Paddle Lite 的架构设计为多硬件兼容支持做了良好设计。除了支持ARM CPU、Mali GPU、Adreno GPU,还特别支持了华为 NPU,以及 FPGA 等边缘设备广泛使用的硬件。即将支持支持包括寒武纪、比特大陆等AI芯片,未来会增加对更多硬件的支持。
模型支持方面,Paddle Lite和PaddlePaddle训练框架的Op对齐,提供更广泛的模型支持能力。目前已严格验证18个模型85个OP的精度和性能,对视觉类模型做到了较为充分的支持,覆盖分类、检测和定位,包含了特色的OCR模型的支持。未来会持续增加更多模型的支持验证。
框架兼容方面:除了PaddlePaddle外,对其他训练框架也提供兼容支持。当前,支持Caffe 和 TensorFlow 训练出来的模型,通过X2Paddle (https://github.com/PaddlePaddle/X2Paddle) 转换工具实现。接下来将会对ONNX等格式模型提供兼容支持。
PaddleLite 的架构设计着重考虑了对多硬件和平台的支持,并且强化了多个硬件在一个模型中混合执行的能力,多个层面的性能优化处理,以及对端侧应用的轻量化设计。
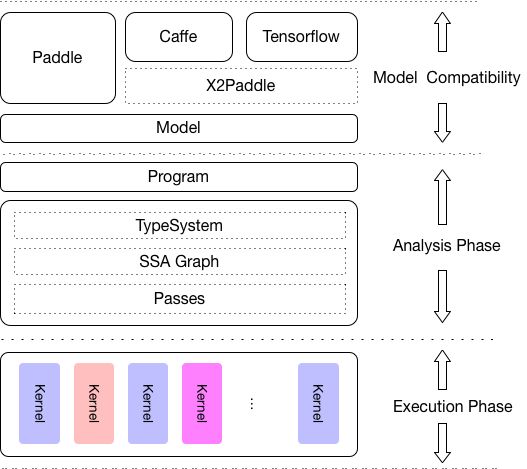
其中,Analysis Phase 包括了 MIR(Machine IR) 相关模块,能够对原有的模型的计算图针对具体的硬件列表进行算子融合、计算裁剪 在内的多种优化。Execution Phase 只涉及到Kernel 的执行,且可以单独部署,以支持极致的轻量级部署。
原Paddle-Mobile作为一个致力于嵌入式平台的PaddlePaddle预测引擎,已支持多种硬件平台,包括ARM CPU、 Mali GPU、Adreno GPU,以及支持苹果设备的GPU Metal实现、ZU5、ZU9等FPGA开发板、树莓派等arm-linux开发板。在百度内已经过广泛业务场景应用验证。对应设计文档可参考: mobile/README
Paddle-Mobile 整体升级重构并更名为Paddle Lite后,原paddle-mobile 的底层能力大部分已集成到新架构 下。作为过渡,暂时保留原Paddle-mobile代码。 主体代码位于 mobile/ 目录中,后续一段时间会继续维护,并完成全部迁移。新功能会统一到新架构 下开发。
metal, web的模块相对独立,会继续在 ./metal 和 ./web 目录下开发和维护。对苹果设备的GPU Metal实现的需求及web前端预测需求,可以直接进入这两个目录。
Paddle Lite 借鉴了以下开源项目:
- ARM compute library
- Anakin ,Anakin对应底层的一些优化实现已被集成到Paddle Lite。Anakin作为PaddlePaddle组织下的一个高性能预测项目,极具前瞻性,对Paddle Lite有重要贡献。Anakin已和本项目实现整合。之后,Anakin不再升级。
- 欢迎您通过Github Issues来提交问题、报告与建议
- 微信公众号:飞桨PaddlePaddle
- QQ群: 696965088


微信公众号 官方技术交流QQ群
- 论坛: 欢迎大家在PaddlePaddle论坛分享在使用PaddlePaddle中遇到的问题和经验, 营造良好的论坛氛围