diff --git a/README.md b/README.md
index 3157d74c91c5..e41b75c46987 100644
--- a/README.md
+++ b/README.md
@@ -25,6 +25,7 @@
## Latest News
+* [2024/05] [Large AI Models Inference Speed Doubled, Colossal-Inference Open Source Release](https://hpc-ai.com/blog/colossal-inference)
* [2024/04] [Open-Sora Unveils Major Upgrade: Embracing Open Source with Single-Shot 16-Second Video Generation and 720p Resolution](https://hpc-ai.com/blog/open-soras-comprehensive-upgrade-unveiled-embracing-16-second-video-generation-and-720p-resolution-in-open-source)
* [2024/04] [Most cost-effective solutions for inference, fine-tuning and pretraining, tailored to LLaMA3 series](https://hpc-ai.com/blog/most-cost-effective-solutions-for-inference-fine-tuning-and-pretraining-tailored-to-llama3-series)
* [2024/03] [314 Billion Parameter Grok-1 Inference Accelerated by 3.8x, Efficient and Easy-to-Use PyTorch+HuggingFace version is Here](https://hpc-ai.com/blog/314-billion-parameter-grok-1-inference-accelerated-by-3.8x-efficient-and-easy-to-use-pytorchhuggingface-version-is-here)
@@ -75,11 +76,9 @@
Inference
@@ -377,6 +376,19 @@ Please visit our [documentation](https://www.colossalai.org/) and [examples](htt
## Inference
+### Colossal-Inference
+
+ +
+
+
+
+ +
+
+
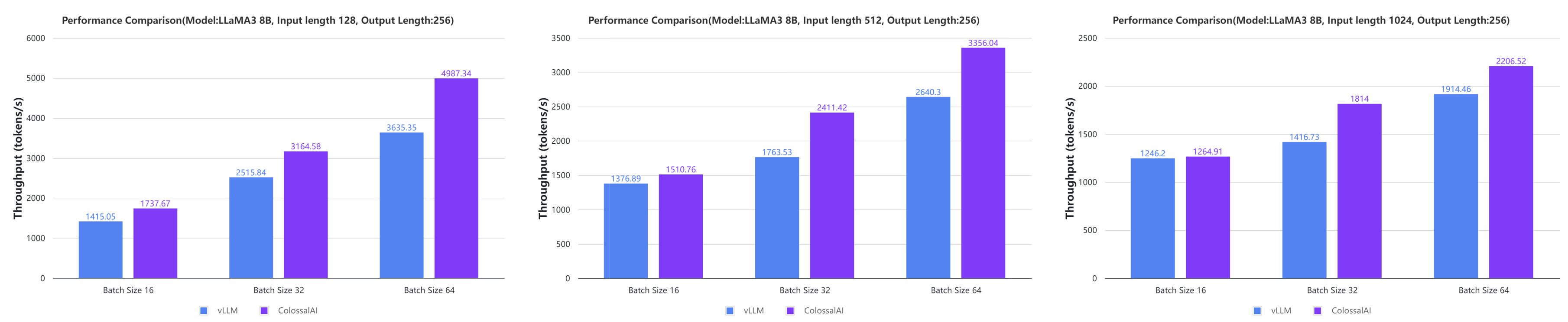
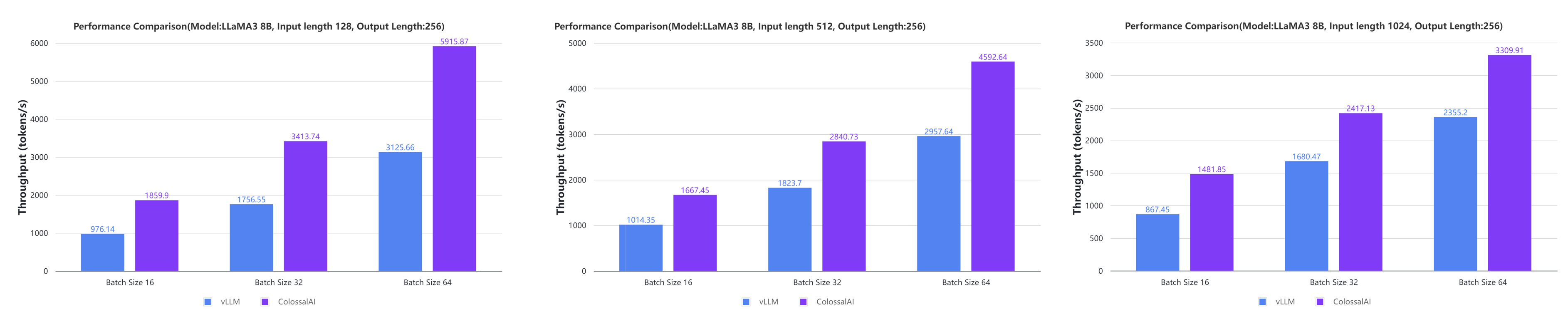
+ - Large AI models inference speed doubled, compared to the offline inference performance of vLLM in some cases.
+[[code]](https://github.com/hpcaitech/ColossalAI/tree/main/colossalai/inference)
+[[blog]](https://hpc-ai.com/blog/colossal-inference)
+
### Grok-1
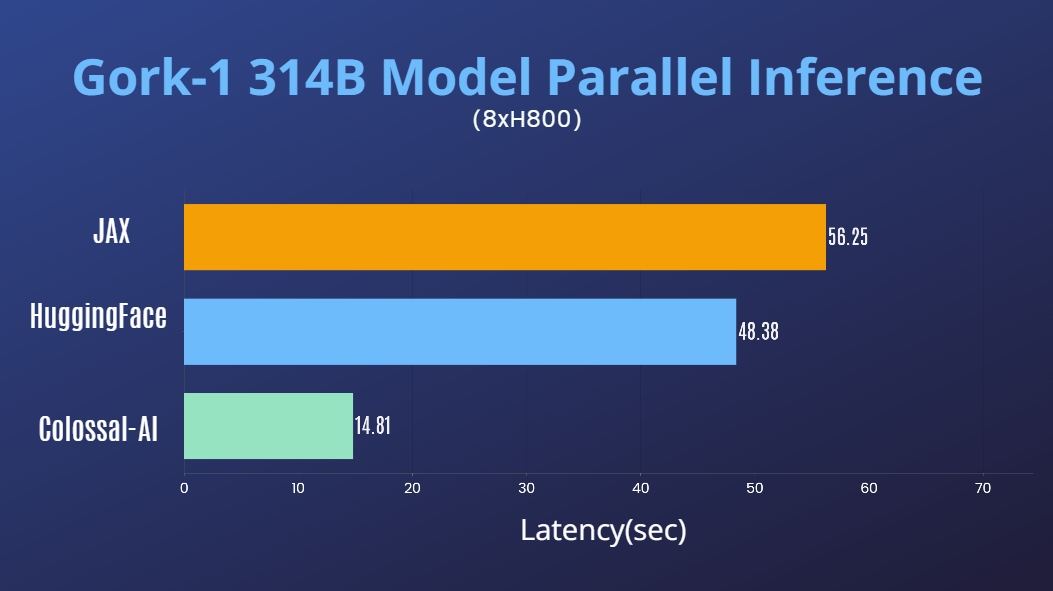 @@ -389,30 +401,13 @@ Please visit our [documentation](https://www.colossalai.org/) and [examples](htt
[[HuggingFace Grok-1 PyTorch model weights]](https://huggingface.co/hpcai-tech/grok-1)
[[ModelScope Grok-1 PyTorch model weights]](https://www.modelscope.cn/models/colossalai/grok-1-pytorch/summary)
+### SwiftInfer
@@ -389,30 +401,13 @@ Please visit our [documentation](https://www.colossalai.org/) and [examples](htt
[[HuggingFace Grok-1 PyTorch model weights]](https://huggingface.co/hpcai-tech/grok-1)
[[ModelScope Grok-1 PyTorch model weights]](https://www.modelscope.cn/models/colossalai/grok-1-pytorch/summary)
+### SwiftInfer
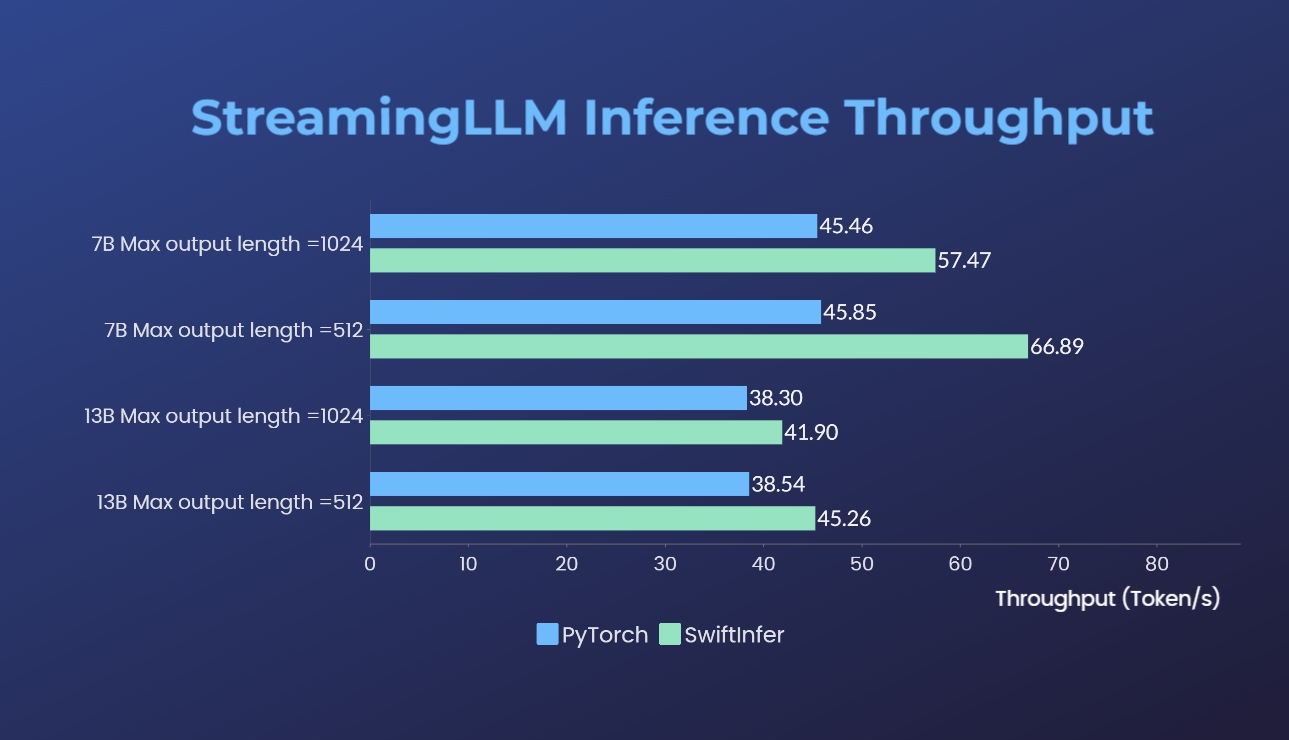
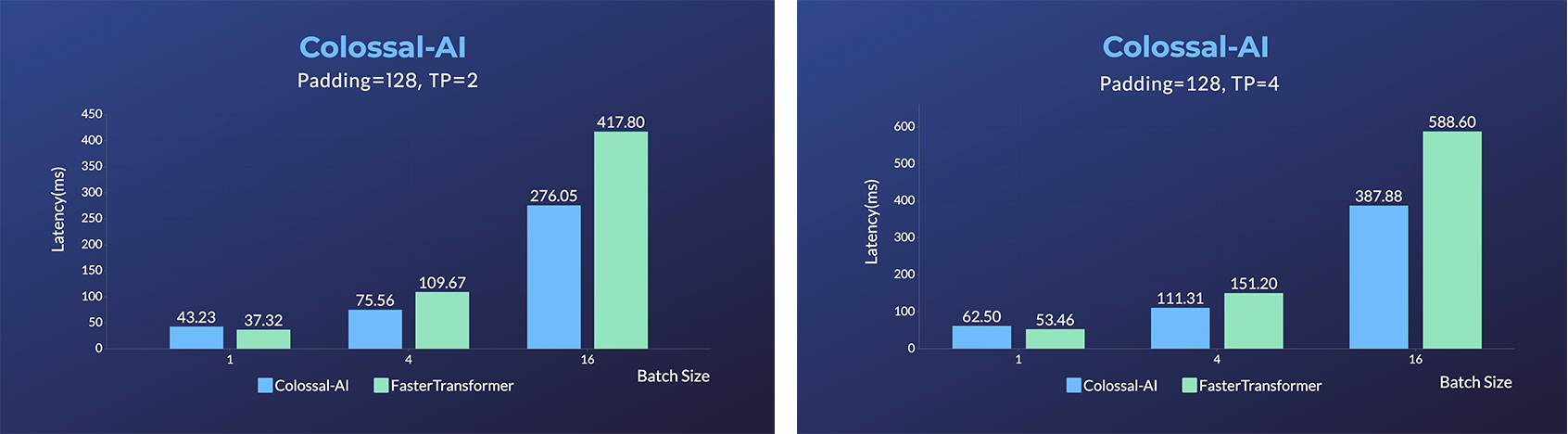
- [SwiftInfer](https://github.com/hpcaitech/SwiftInfer): Inference performance improved by 46%, open source solution breaks the length limit of LLM for multi-round conversations
-
- -
-
-
-- [Energon-AI](https://github.com/hpcaitech/EnergonAI): 50% inference acceleration on the same hardware
-
-
- -
-
-
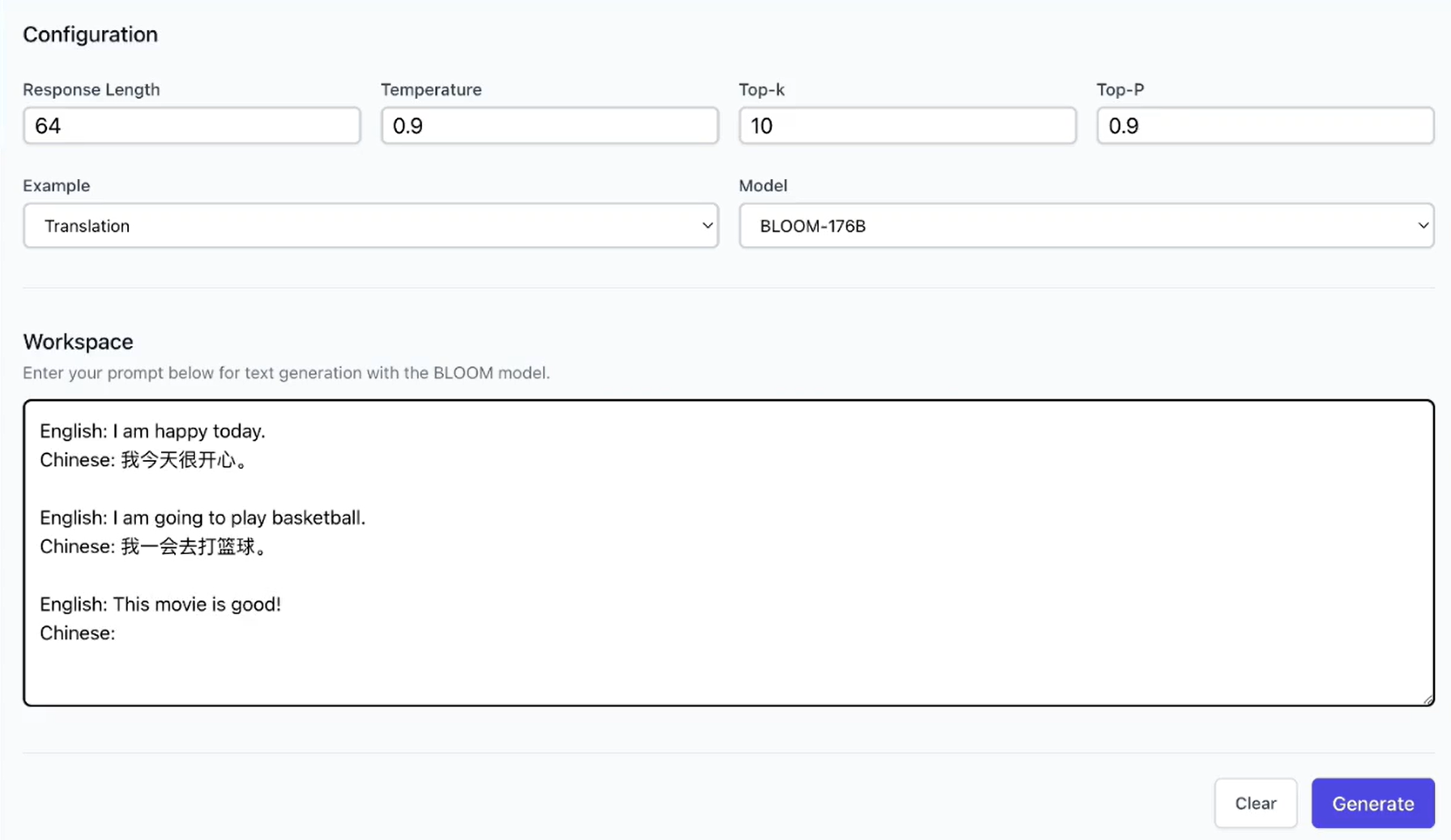
-- [OPT Serving](https://colossalai.org/docs/advanced_tutorials/opt_service): Try 175-billion-parameter OPT online services
-
-
- -
-
-
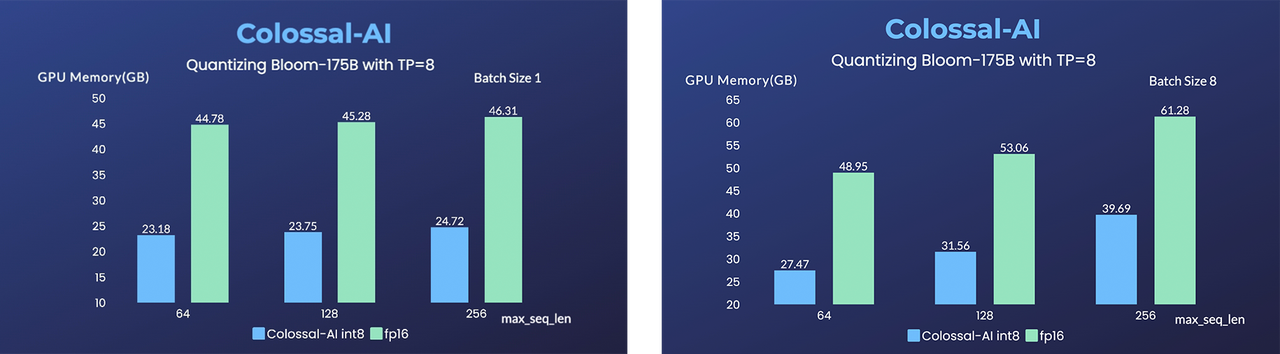
-- [BLOOM](https://github.com/hpcaitech/EnergonAI/tree/main/examples/bloom): Reduce hardware deployment costs of 176-billion-parameter BLOOM by more than 10 times.
-
(back to top)
## Installation
diff --git a/colossalai/inference/README.md b/colossalai/inference/README.md
index cd130a463e7e..cdb32a0f89a2 100644
--- a/colossalai/inference/README.md
+++ b/colossalai/inference/README.md
@@ -18,8 +18,15 @@
## 📌 Introduction
-ColossalAI-Inference is a module which offers acceleration to the inference execution of Transformers models, especially LLMs. In ColossalAI-Inference, we leverage high-performance kernels, KV cache, paged attention, continous batching and other techniques to accelerate the inference of LLMs. We also provide simple and unified APIs for the sake of user-friendliness.
+ColossalAI-Inference is a module which offers acceleration to the inference execution of Transformers models, especially LLMs. In ColossalAI-Inference, we leverage high-performance kernels, KV cache, paged attention, continous batching and other techniques to accelerate the inference of LLMs. We also provide simple and unified APIs for the sake of user-friendliness. [[blog]](https://hpc-ai.com/blog/colossal-inference)
+
+
+
+
+
+
+
## 🕹 Usage
diff --git a/docs/README-zh-Hans.md b/docs/README-zh-Hans.md
index 41110612c307..5878abbaaa19 100644
--- a/docs/README-zh-Hans.md
+++ b/docs/README-zh-Hans.md
@@ -24,6 +24,7 @@
## 新闻
+* [2024/05] [Large AI Models Inference Speed Doubled, Colossal-Inference Open Source Release](https://hpc-ai.com/blog/colossal-inference)
* [2024/04] [Open-Sora Unveils Major Upgrade: Embracing Open Source with Single-Shot 16-Second Video Generation and 720p Resolution](https://hpc-ai.com/blog/open-soras-comprehensive-upgrade-unveiled-embracing-16-second-video-generation-and-720p-resolution-in-open-source)
* [2024/04] [Most cost-effective solutions for inference, fine-tuning and pretraining, tailored to LLaMA3 series](https://hpc-ai.com/blog/most-cost-effective-solutions-for-inference-fine-tuning-and-pretraining-tailored-to-llama3-series)
* [2024/03] [314 Billion Parameter Grok-1 Inference Accelerated by 3.8x, Efficient and Easy-to-Use PyTorch+HuggingFace version is Here](https://hpc-ai.com/blog/314-billion-parameter-grok-1-inference-accelerated-by-3.8x-efficient-and-easy-to-use-pytorchhuggingface-version-is-here)
@@ -74,11 +75,9 @@
推理
@@ -370,6 +369,19 @@ Colossal-AI 为您提供了一系列并行组件。我们的目标是让您的
## 推理
+### Colossal-Inference
+
+
+
+
+
+
+
+
+ - AI大模型推理速度部分接近翻倍,与vLLM的离线推理性能相比
+[[代码]](https://github.com/hpcaitech/ColossalAI/tree/main/colossalai/inference)
+[[博客]](https://hpc-ai.com/blog/colossal-inference)
+
### Grok-1
@@ -388,25 +400,6 @@ Colossal-AI 为您提供了一系列并行组件。我们的目标是让您的
- [SwiftInfer](https://github.com/hpcaitech/SwiftInfer): 开源解决方案打破了多轮对话的 LLM 长度限制,推理性能提高了46%
-
-
-
-
-
-- [Energon-AI](https://github.com/hpcaitech/EnergonAI) :用相同的硬件推理加速50%
-
-
-
-
-
-- [OPT推理服务](https://colossalai.org/docs/advanced_tutorials/opt_service): 体验1750亿参数OPT在线推理服务
-
-
-
-
-
-- [BLOOM](https://github.com/hpcaitech/EnergonAI/tree/main/examples/bloom): 降低1760亿参数BLOOM模型部署推理成本超10倍
-
(返回顶端)
## 安装