MLOps
- 파이프라인: 잘 정의된 프로세스 > 일부 프로세스를 자동화하여 시간과 비용을 절감
- 생산성 향상
- 예측 가능한 품질
- 장애 대응능력 향상 (머신러닝의 경우, 장애라는 개념이 조금 특이함)
- 머신러닝 모델의 배포는 쉽지만, ML 모델을 운영하는 것이 어려움 (비용이 큼)
- 미래의 나를 위해서 지금이 힘들더라도 사전에 준비하는 것
- 예. 리팩토링, 종속성 제거, 단위 테스트, API 강화, 문서화 등
- ML 시스템에서는 추상화(Abstraction)의 경계가 무너짐
- 기존에 알려진 코드 수준의 방식으로 문제 해결이 어려움
- 하나의 거대한 모델이 있을 때, 비슷하게 모델을 정의할 수가 없음
- 어려운 ML 문제
- 데이터의 변화가 빠르게 일어남 (주단위)
- 재학습 주기
- 모델 성능 저하
- 더 많은 데이터로 모델 성능 개선
- 시스템 변화
- 라벨링
- 직접적인 피드백(추천 시스템의 경우, 유저의 피드백이 주기적으로 나타남)
- 수집한 데이터
- 머신러닝 프로그래밍 문제의 특징
코딩 엔지니어링 고정된 데이터셋 진화하는 데이터셋과 metric 통합 불가한 아티팩트 재사용 가능한 모델 문제 정의 없음 문제 정의, 찾기 쉬운 아티팩트 검증되지 않은 데이터셋/모델 예상치, 데이터 검증, 모델 검증 편향된 데이터셋/아티팩트 설명 가능하고, 공정한 데이터셋/아티팩트 ... 시각화, 요약, 이해, 아티팩트 형상 관리 - ML은 본질적으로 실험임
- 다른 feature, 알고리즘, 모델링 기술 및 파라미터 구성을 시도해서 가능한 빨리 문제점에 가장 적합한 것은 찾음
- 무엇이 효과가 있는지 아닌지를 추적하고, 코드 재사용을 극대화/유지
- ML 모델은 코딩 뿐만 아니라, 데이터 때문에 성능이 저하될 수 있음
- 데이터 통계치를 추적하고, 모니터링해서 문제를 인지해야 함
- 배포 트리거
- 요청 시: 파이프라인 수동 실행
- 일정 기준: 새 데이터는 매일, 매주 또는 매월
- 새 학습 데이터: 새 데이터가 들어오는 경우
- 모델 성능 저하: 눈에 띄는 성능 저하가 있을 경우
- 데이터 분포의 중요한 변화(Concept Drift): 피쳐의 데이터 분포에 큰 변화가 있으면 모델이 오래되었다는 것을 뜻함
- 진화하는 데이터셋/Metric ... 이것에 부합하는 ML 모델을 새롭게 배포해야 함
- CI/CD/CT(Continuous Training!)
- 과정
- DS: Offline Data > Model 생성 > Model Registry
- BE: Model Registry > Model Serving > Prediction Service
- 특징
모델을 통한 소통- 파이썬 코드, 학습된 가중치, 환경 (패키지, 버전) 중 하나라도 변경된다면 모델이 동작을 제대로 할 수 없음
- 수동, 대화식 프로세스
- 드문 릴리즈 반복, CI/CD 없음

- 과정
- DS: Feature Store > Model 훈련 > 코드 보관 (Source Repository)
- BE: Feature Store + Source Repository (Pipeline으로 패키징) > Model 훈련 > Model Registry > Model Serving > Prediction Service
- QA: Prediction Service > 모니터링 > 재학습
- 특징
- 실험/운영 환경의 분리
- Pipeline(Container)을 활용 > 환경이 달라서 문제될 일을 없앰
- ML Metadata Store 추가
- Production Model의 Continuous Training(CT)
- Auto Retrain: Data Shift(실제 데이터는 계속 해서 변함) > 성능이 저하되는 문제 > 최근 데이터로 재학습
- Auto Deploy: A제품에 대한 모델 운영 > B제품으로 변경되어 모델 재생성 > 다시 A제품으로 돌아옴 > A에 대한 모델이 있는 찾은 후에 자동 변경
- 효율적인 리소스 관리: 새로운 데이터에 대해서만 모델을 업데이트하여, 학습 시간과 리소스를 절약할 수 있음

- 과정
- CI: 모델에 영향이 가는 요소를 추가했을 때, 실제로 모델이 정상적으로 학습이 되는지 확인 후 학습 Pipeline으로 생성
- 모델에 영향이가는 요소: 훈련 데이터 변경, 코드 수정, 환경 변경(파이썬, 패키지 변경)
- Source Repository > Build, test & package pipeline components
- CD: 학습된 모델이 정상적으로 동작하는지 확인
- Packages > Pipeline deployment
- Trained models > Model Serving
- CI: 모델에 영향이 가는 요소를 추가했을 때, 실제로 모델이 정상적으로 학습이 되는지 확인 후 학습 Pipeline으로 생성
- 자동화된 CI/CD 시스템이 필요
- 이를 통해 데이터 과학자는 Feature Engineering, 모델 아키텍처 및 하이퍼 파라미터에 대한 새로운 아이디어를 신속하게 탐색 가능

- 데이터 전처리 > 모델 학습 > 모델 분석 > 모델 배포를 포함
- 수동으로 진행하다보면 오류가 발생하기 쉬움

- 모델 학습을 위해 원하는 데이터 형태에 맞는 데이터 수집 진행
- Data Versioning을 통해서 모델이 어떤 데이터셋을 통해서 훈련했는지 로그를 잘 확인할 수 있음 (S3 등에서는 자동으로 진행)
- 데이터 검증 진행
- 새모델 버전을 학습하기 전에 검증이 필요함
- 데이터의 통계가 예상대로인지 확인하고, 이상치가 발생할 경우 데이터 과학자에게 경고하도록 설정
- data split를 진행
- 데이터 과학자마다 다른 split를 가질 수 있기 때문에 이때 진행함
- 이때 라벨 값 등이 편향되지는 않았는지 확인
- 데이터 전처리 진행
- 데이터를 학습에 활용하기 위해서 데이터를 미리 처리해야 함
- 예시
- 1-hot Encoding
- 텍스트 문자를 인덱스로 변환하거나 토큰을 워드 벡터로 변환
- 새로운 Feature 생성
- 모델 학습 진행
- 가장 낮은 오차를 사용하여 입력을 수행하고 출력을 예측하는 모델을 학습
- 메모리는 한정되어 있기 때문에, 효율적인 학습을 시키는 것이 중요
- 모델 튜닝 진행
- 파이프라인에 모델 튜닝을 포함하여 일부 튜닝하는 것이 좋음 (Auto ML)
- 모델 분석
- 지표를 활용하여 모델의 예측이 공정한지 확인
- 모델 버전 관리
- 어떤 데이터셋, 하이퍼 파라미터, 모델을 사용하였는지 관리
- A/B Test를 위해서도 필요함
- 모델 배포 진행
- 일회성 구현으로 구성된 모델이라면 모델 업데이트는 쉽지 않음
- PyTorch는 형상 관리하기가 어려움
- 모던한 모델 서버를 사용하면 서버 프로그램 코드를 작성하지 않고도 모델을 배포할 수 있음
- REST/RPC 등의 여러 API 인터페이스를 제공하여 동일한 모델의 여러 버전을 동시에 호스트할 수도 있음 >> 이를 통해서 모델 A/B Test를 진행할 수 있음
- 애플리케이션을 다시 배포하지 않고도 모델을 변경할 수 있음
- 일회성 구현으로 구성된 모델이라면 모델 업데이트는 쉽지 않음
- 피드백 루프 반복
- 새로 배포된 모델의 효과와 성능을 측정할 수 있어야 함
- 데이터 과학자가 새로운 모델 연구에 집중할 수 있도록 함
- 이유
- 확장성과 유연성
- ML은 대량의 데이터와 복잡한 모델 훈련을 필요로 함 > Kubernetes를 사용하여 클러스터를 구성하고 자원을 동적으로 확장할 수 있음
- 분산 시스템을 쉽게 관리하고 확장 가능 > 대규모 기계 학습 작업을 효율적으로 처리
- 훈련 중 클러스터에 문제가 생기면 다른 클러스터로 컨테이너를 이동
- 배포 관리
- Kubernetes는 컨테이너화된 애플리케이션의 배포와 관리를 자동화
- 모델 배포를 컨테이너로 추상화하고, Kubernetes 클러스터에 배치함으로써 배포 과정을 단순화하고 일관성을 유지
- 롤링 업데이트, 롤백, 서비스 디스커버리 등과 같은 기능을 제공하여 모델의 신뢰성과 안정성을 보장
- 자원 관리
- 모델 훈련 및 추론 작업에 필요한 CPU, GPU, 메모리 등의 자원을 동적으로 할당하고 관리
- 자동 스케일링 기능을 사용하여 트래픽이나 작업 부하에 따라 자원을 자동으로 조정
- 모니터링과 로깅
- 확장성과 유연성
- If not
- 클러스터를 누군가가 사용 중이다가 다운이 되면 클러스터를 사용하던 사람들은 피해를 봄
- 클러스터를 누군가가 환경 업데이트를 하면 기존에 모델 훈련 방식이 동작하지 않을 수 있음
- 학습 때 마다 그 과정과 결과를 기록하는 것이 중요함
- 저번에 학습이 잘 되었는데, lr이 몇이었지?
- 저번에 썼던 논문, 재연이 안 되네?
- 이 모델에 어떤 데이터셋을 사용했지?
- ML 프로젝트 실험관리 솔루션
- 웹 브라우저를 기반으로 구성되어 있음
- 팀원과 함께 공유할 수 있음
- 실험 결과 시각화
- GPU 사용률 (어떤 모델이 GPU를 많이 점유하고 있는가?)
import random
total_runs = 5
for run in range(total_runs):
# 실험 시작
wandb.init(
project="basic-intro",
name=f"experiment_{run}",
config={
"learning_rate": 0.02,
"architecture": "CNN",
"dataset": "CIFAR-100",
"epochs": 10,
})
epochs = 10
offset = random.random() / 5
for epoch in range(2, epochs):
acc = 1 - 2 ** -epoch - random.random() / epoch - offset
loss = 2 ** -epoch + random.random() / epoch + offset
# log를 남김
wandb.log({"acc": acc, "loss": loss})
# 실험의 결과를 웹 사이트로 링크로 알려준다
wandb.finish()- AutoML: 매일 신경써야 할 일이 줄어듬
- ML이 반복적인 노동의 연속 (lr을 몇으로 해야할까? > 이것을 찾기위해서 많은 과정 필요)
- 이를 자동화하는 것은 파워풀
def train():
import numpy as np
import tensorflow as tf
import wandb
config_defaults = {
'layer1_size': 128,
'layer1_activation': 'relu',
'dropout_rate': 0.2,
'optimizer': 'adam',
'learning_rate': 0.01
}
wandb.init(project='sweep-practice',
config=config_defaults,
magic=True)
config = wandb.config
fashion_mnist = tf.keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
train_images.shape
train_images = train_images / 255.0
test_images = test_images / 255.0
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(config.layer1_size, activation=config.layer1_activation),
tf.keras.layers.Dropout(config.dropout_rate),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
])
if config.optimizer == 'rmsprop':
opt = tf.kears.optimizers.RMSprop(learning_rate=config.learning_rate)
else:
opt = tf.keras.optimizers.Adam(learning_rate=config.learning_rate)
model.compile(optimizer=opt,
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(train_images, train_labels, epochs=5,
validation_data=(test_images, test_labels))
# 여기서 실험할 하이퍼 파라미터를 제공
sweep_config = {
'method': 'grid', # random, bayes
'parameters': {
'layer1_size': {
'values': [64, 96, 128]
},
'layer1_activation':{
'values': ['relu', 'sigmoid']
},
'dropout_rate':{
'values': [0.1,0.2,0.3,0.4,0.5]
},
'optimizer':{
'values': ['adam', 'rmsprop']
},
'learning_rate':{
'values': [0.1,0.01,0.001]
},
}
}
import wandb
sweep_id = wandb.sweep(sweep_config, project='sweep-practice')
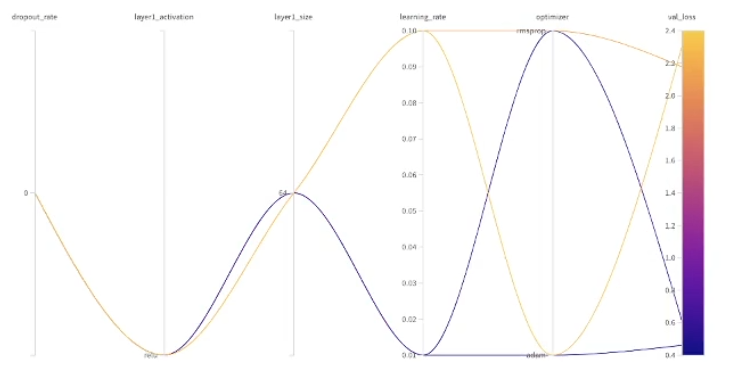
wandb.agent(sweep_id, function=train)하이퍼 파라미터(layer)별 Best Result를 확인할 수 있음


하이퍼 파라미터가 여러 개인 경우, 어떤 하이퍼 파라미터를 선택했을 때 최적의 결과가 나타나는 지 확인할 수 있음
- 문제점
- 리서치 코드를 개인 컴퓨터에 저장
- 복사/붙여넣기로 코드 중복이 많음
- 연구 결과가 재연 불가능
- 전역 변수를 많이 활용함 > 사이드이펙트를 많이 가져옴
- 너무 긴 코드
- 해결 방법
- 라이브러리 구현으로 추상화를 진행할 수 있음 > 코드 중복을 줄임
- 함수와 클래스를 명확하게 구분
- black 패키지를 활용하여 가독성있는 코드 작성에 도움
black main.py
- 타입 힌트
- 함수 input/output 타입 지정
def fn(a:int) -> bool: ...
- mypy: 타입 체크를 통해서 에러를 발생시켜줌
- 함수 input/output 타입 지정
- 지속적으로 퀄리티 컨트롤을 적용하는 프로세스를 실행하는 것
- 요즘 핫한 CI 툴 > Github Actions
- .github/workflow > lint.yml
name: Lint Code Base # git push 시에 실행 on: push jobs: super-lint: # super-lint를 진행할 가상머신 설정 name: Lint Code Base runs-on: ubuntu-latest env: OS: ${{ matrix.os }} PYTHON: '3.10' steps: # ubuntu-latest 머신에 나의 repository를 check-out - name: Checkout code uses: actions/checkout@v2 # Runs the Super-Linter action - name: Lint Code Base uses: github/super-linter@v3 env: DEFAULT_BRANCH: master GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }} VALIDATE_PYTHON_BLACK: true VALIDATE_PYTHON_FLAKE8: true
- PR시, 조건에 맞지 않는 경우에는 아래와 같이 경고를 나타냄

- Unit Test 정의
import unittest from main import helloworld class MainTest(unittest.TestCase): def test_helloworld(self): ret = helloworld() self.assertEqual(ret, "Hello World!") # 테스트 결과의 정답을 설정 if __name__ == "__main__": unittest.main()
- Git Action 추가
name: Coverage Report # git push 시에 실행 on: push jobs: coverage-report: name: Coverage Report runs-on: ubuntu-latest steps: - name: Checkout code uses: actions/checkout@v2 - name: Set up Python 3.7 uses: actions/setup-python@v2 with: architecture: 'x64' - name: Install dependencies run: | python -m pip install --upgrade pip if [ -f requirements.txt ]; then pip install -r requirements.txt; fi # _test.py가 붙은 것을 모두 검사 - name: Generate coverage report run: | coverage run --source=./ -m unittest discover -p "*_test.py" coverage xml # code climate를 연동 # 홈페이지 > repository 추가 > TOKEN을 발급 - name: Upload coverage to code climate env: CODECLIMATE_REPO_TOKEN: 51642184e2902baab3007c428a39a553590c79209aa133eb7fc093e3b021b775 run: | codeclimate-test-reporter
- ML에서 데이터로 인한 장애는 파악하기 어려움
- 데이터가 잘 못되어도 예측은 정상적으로 수행되기 때문에
- 늦게서야 잘못된 예측값을 인지하는 경우가 많음
- 데이터의 특징과 가치를 빠르게 파악할 수 있음
- 해당 패키지를 통해서 기술 통계보기, 스키마 추론, 이상 항목 확인 등이 가능함
- csv에서 feature들의 유형과 빈도들을 확인할 수 있음
- 스키마 환경을 설정하고, 이에 부합하는지 확인할 수 있음 (설정한 feature가 존재하는지 아닌지 확인)
import tfdv
# 데이터 통계량 시각화
train_stats = tfdv.generate_statistics_from_csv(data_location=TRAIN_DATA)
tfdv.visualize_statistics(train_stats)
# 스키마 추론
schema = tfdv.infer_schema(statistics=train_stats)
tfdv.display_schema(schema=schema)
# 스키마 환경 확인
serving_stats = tfdv.generate_statistics_from_csv(SERVING_DATA)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)
tfdv.display_anomalies(serving_anomalies)- 모델 배포 후에 데이터 분포의 변화를 인지하는 것
TFDV는 드리프트 및 스큐를 감지하는 기능 제공
- 스키마 스큐: 학습 및 서빙 데이터가 동일한 스키마를 따르지 않을 때 발생
- 특성 스큐: 모델이 학습하는 특성 값이 서빙 시에 표시되는 특성 값과 다를 때 발생
- 예를 들어 학습 또는 서빙 중 하나에만 일부 전처리를 적용하는 경우
- 분포 스큐: 학습 데이터와 제공 데이터의 분포가 크게 다를 때 발생
- 학습할 때는 이용자가 남성이 많았는데, 후에 여성이 늘어났을 경우
# Add skew comparator for 'payment_type' feature.
payment_type = tfdv.get_feature(schema, 'payment_type')
payment_type.skew_comparator.infinity_norm.threshold = 0.01
# Add drift comparator for 'company' feature.
company=tfdv.get_feature(schema, 'company')
company.drift_comparator.infinity_norm.threshold = 0.001
skew_anomalies = tfdv.validate_statistics(train_stats, schema,
previous_statistics=eval_stats,
serving_statistics=serving_stats)
tfdv.display_anomalies(skew_anomalies)- 전통적인 소프트웨어 개발과 ML 개발은 차이가 있음
- 개발자는 데이터를 통해서 특정 작업을 수행하도록 알고리즘을 학습
- 프로젝트 성공은 데이터의 품질의 양에 크게 의존
- 새로운 환경에서도 새로운 데이터를 보여주면 적응
- 훈련된 ML 모델의 동작을 분석하는 시각화 기반 도구
- 탭을 통해서 모델에 대한 정보를 제공
- Datapoint Editor: 각각의 데이터 포인트를 시각화하여 확인할 수 있음. 피쳐를 변경했을 때 예측 결과의 변화를 확인할 수 있음
- Performance: 피쳐를 슬라이스한 모델의 성능을 확인할 수 있음
- 가장 가까운 특성을 가진 (가까운 Counterfactuals) 레코드를 확인할 수 있음
https://pair-code.github.io/what-if-tool/learn/tutorials/walkthrough/
- AI 모델을 실제 환경에서 운영 및 배포하는 과정을 의미
- 모델을 사용자와 상호작용할 수 있도록 만들어주는 프로세스
- 모델이 실제 데이터에 대해 예측을 수행하고 결과를 생성하는 단계로, 모델이 실제 문제를 해결하고 사용자와 상호 작용하는데 중요한 역할
- 모델의 성능, 신뢰성, 속도 등을 보장
- 사용자 상호 작용
- 모델 배포
- 모델을 서버나 클라우드 환경으로 배포하고, 모델의 API 엔드포인트를 생성하여 클라이언트 애플리케이션과 연결
- 요청 처리
- 클라이언트 애플리케이션으로부터 들어오는 요청을 모델 서버가 받아 처리
- 요청에 따라 입력 데이터를 모델이 이해할 수 있는 형태로 변환하고, 모델에 입력으로 전달
- 출력 생성
- 모델은 입력 데이터를 기반으로 예측을 수행하고, 출력 데이터를 생성
- 주로 사용자에게 제공되거나 다른 시스템과 통합되어 사용
- 응답 전송
- 응답 전송: 모델의 예측 결과를 클라이언트 애플리케이션으로 응답으로 전송
- 주로 JSON 형식이나 다른 표준 데이터 형식으로 전달
- 모델 배포
- 모니터링 및 관리
- 배포된 모델의 성능과 동작을 모니터링하고, 필요한 경우 모델 업데이트나 유지보수 작업을 수행
- 성능 저하나 이상 동작을 감지하면 적절한 조치를 취하여 모델의 품질과 신뢰성을 유지
- 스케일링 (서비스의 사용량이 증가할 경우 모델 서비스를 스케일업하거나 스케일아웃하여 처리 능력을 향상)

- TensorFlow Serving
- 구글에서 개발된 오픈 소스 프레임워크
- TensorFlow 모델을 서빙하기 위한 최적화된 기능을 제공
- TensorfFlow 모델에 한정됨
- 모델 버전 관리, 로드 밸런싱, 스케일링 등을 지원
- Triton Inference Server (formerly known as TensorRT)
- NVIDIA에서 개발한 오픈 소스 프레임워크
- TPU, GPU 가속을 활용하여 모델을 빠르게 서빙할 수 있음
- TensorFlow, PyTorch, ONNX와 같은 다양한 프레임워크에서 모델 지원
- NVIDIA 하드웨어 지원이 필요함
- KFServing (Kubeflow Serving):
- 쿠버네티스 위에서 실행되는 오픈 소스 프레임워크
- 쿠버네티스 기능을 활용하여 모델 배포 및 관리를 쉽게 할 수 있음
- 다양한 모델 형식과 프레임워크를 지원하며, 확장성을 갖춘 모델 서빙 환경을 제공
- BentoML
- 다양한 머신러닝 프레임워크 (PyTorch, TensorFlow, Scikit-learn 등) 지원
- 배포된 모델에 대한 추적, 모니터링, 로깅, 메트릭 수집을 지원
- 높은 수준의 모델 버전 관리 및 관리 도구
- 클라우드 서비스 / Kubernetes와 같은 대규모 클러스터에서 배포 가능
- 학습 곡선이 높음
- AI 모델을 실행할 때, 발생하는 계산과 메모리 사용량을 최소화하고 실행 속도를 향상시키는 기술을 의미
- 모델을 실제 운영 환경에서 효율적으로 실행하기 위해 중요한 역할
- 모델의 배포 및 서빙에 필요한 컴퓨팅 리소스를 줄이고, 사용자 경험을 향상
- 모델 수정
- 모델 크기 축소
- 모델의 파라미터 수를 줄여서 모델의 크기를 축소
- 가중치 규제, 필터 프루닝, 양자화 등을 사용하여 모델 크기를 줄일 수 있음
- 모델 양자화
- 가중치와 활성화 값을 낮은 비트로 표현하여 모델의 정확도를 유지하면서 메모리 사용량과 실행 시간을 줄임
- 레이어 튜닝
- 모델 내의 특정 레이어를 튜닝하여 실행 속도와 메모리 사용량을 개선
- 예를 들어, 컨볼루션 레이어의 필터 크기를 조정하거나, RNN의 셀 크기를 줄일 수 있음
- 모델 크기 축소
- 하드웨어 개선
- 하드웨어 가속기 활용
- GPU나 TPU와 같은 하드웨어 가속기를 활용하여 모델 실행 속도를 향상
- 텐서 컴파일러
- 텐서 컴파일러를 사용하여 모델을 하드웨어에 최적화된 연산으로 변환하여 실행 속도를 향상
- 하드웨어 가속기 활용
- 서빙 방식 개선
- 배치 처리와 병렬화
- 여러 요청을 한 번에 처리하거나, 모델의 연산을 병렬로 처리함으로써 실행 속도를 개선
- 런타임 모니터링
- 모델 실행 중에 리소스 사용량과 성능을 모니터링하여 비효율적인 부분을 찾아내고 개선
- 배치 처리와 병렬화