1_Basic_of_BigData

본 내용은 해당 도서를 참고하여 정리한 내용입니다.
'빅데이터'의 역사에 대해 알아보자
- RDB로는 취급할 수 없을 만큼 대량의 데이터가 쌓임
- RDB는 데이터가 증가함에 따라 소프트웨어, 하드웨어적 비용이 비싸진다.
- 다수의 컴퓨터에서 대량의 데이터 처리
- 초기
MapReduce를 참고하여 제작됨 Java로 개발되어 SQL에 익숙한 분석가가 활용하기 어려웠음 → Hive 도입
Why Hadoop? 🤔
1. 비용 절감. 접근성.
접근성이 뛰어나서 유연한 방식으로 하드웨어를 사용할 수 있음 → 고가의 신뢰도 높은 하드웨어 만을 추구하지 않음 → 비용 절감
기존 DB는 소프트웨어와 하드웨어가 비싸다
2. 빅데이터에 대한 내결함성
기본적으로 HDFS는 파일을 3군데 저장
→ 공간적으로 비효율적이다? 만약 한 데이터 노드에서 데이터를 구성할 수 있다면? 성능적 이득을 볼 수 있음
→ 왜 3개? 내결함성+성능 실험적으로 알맞음
3. 확장성
하드웨어를 추가했을 때, 성능이 리니어하게 증가한다.
4. 읽기 시점 스키마
기존에 쓰기 시점 스키마에서 벗어나, 하둡이나 NoSQL은 데이터를 읽을 때 데이터의 본질을 파악한다.
데이터를 소비자에게 데이터의 성질을 맡기는 시스템. (데이터로 뭘하기 전까진 데이터로 무엇을 할지 정확히 알 수 없다.)
Why Java? 🤔
1. Java의 GC가 가장 성능이 좋음 (빅데이터를 다루기에 메모리 관점 중요)
2. Java가 디버깅이 쉬움
3. Hadoop이 Nutch 프로그램에서 발전 되었는데, 그것이 Java 기반
- RDB에 비해 고속의 읽기, 쓰기가 가능하고, 분산 처리에 뛰어남
- 앱에서 온라인으로 접속하는 DB →
NoSQL DB에 기록하고 Hadoop으로 분산처리하자
- 이전부터 데이터 분석을 위해 도입됨
- 분산 시스템의 발전에 따라 Hadoop과 연결하여 사용
- DW의 데이터 확장성이 좋지 않음
- 데이터 처리는 Hadoop이 진행하고, 비교적 작고 중요한 데이터만 DW에 넣는 식
- 기존의 DW와는 다르게
다수의 분산 시스템을 조합하여확장성이 뛰어난 데이터 처리 구조를 만든다.

- 차례대로 전달해나가는 데이터로 구성된 시스템
- 데이터를 수집하여 무엇을 하고 싶은지에 따라 변화됨
- 데이터 파이프라인의 시작
- 데이터는 여러 장소에서 발생하고 각각 다른 형태를 가짐 (데이터 처리 필요)
- 데이터 처리 방법
- 스트림 처리
- 차례차례로 생성되는 데이터를 끊임없이 보냄 (30분간의 데이터를 집계)
장기적인 데이터 처리에는 적합하지 않음
- 배치 처리
대량의 데이터를 저장하고, 처리하는 데 적합함- 분산 시스템 활용 (4, 5)
- 스트림 처리
- 여러 컴퓨터와 디스크로부터 구성된 스토리지 시스템
- 확장성이 높은 제품을 활용해야함
- Amazon S3, NoSQL DB
- 데이터 분석을 위해 데이터를 가공하여 외부 DB에 저장
MapReduce가 대표적이며, 많은 컴퓨터 자원을 필요로 한다- 빅데이터를 SQL로 집계하기 위한 방법
- 쿼리엔진 도입 (Hive)
- 외부 DW를 이용. ETL과정을 거침.
- 데이터 파이프라인의 동작을 관리하기 위함
- 배치 일정 관리 및 오류 발생 보고를 목적으로 사용됨
대량의 데이터를 장기 보존하는 것에 최적화- 소량의 데이터를 자주 쓰고 읽는 데는 적합하지 않음
- 하루가 끝날 때 정리하여 쓰고, 야간 시간대에 집계하여 보고서 작성
- 데이터 소스의 형태가 모두 다르기 때문에
ETL 프로세스활용 - DW는 중요한 데이터 처리에 사용되기에
과부하를 조심해야함 → 세분화된 니즈에 따라 구성된데이터 마트구축 - DW 중심의 파이프라인에서는 테이블 설계와 ETL 프로세스가 중요
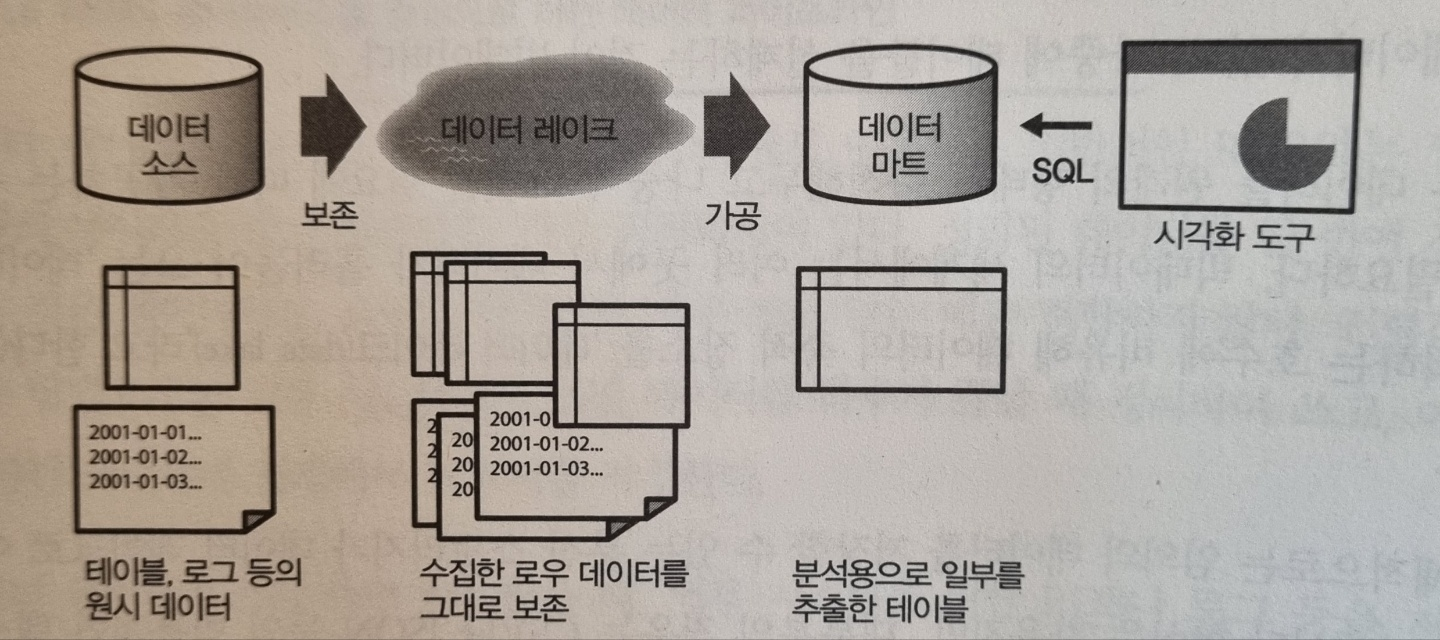
- 모든 데이터를 원래의 형태로 축척하고 나중에 그것을 필요에 따라 가공하는 구조
- 모든 데이터가 DW의 스키마를 가정해서 만들어지지 않음
- 필요한 데이터는
데이터 마트에 정리- Data Lake는 단순 분산 스토리지이기 때문에 데이터를 가공할 수 없음
- MapReduce 등의 분산 데이터 처리 기술이 필요
- ETL
추출, 변환 적재 순서로 데이터를 처리
→ 데이터가 적다면 Python으로 충분
→ 데이터가 크다면 Spark를 고려
→ serverless로 하기 위해서는 aws glue에서 script를 돌림

- ELT
추출, 적재, 변환 순서로 데이터를 처리 (raw 데이터를 보고싶은 요구 상승)
→ 모든 종류의 데이터를 수용하는 데이터 레이크에서 동작 (HDFS 통상적 사용)