- 2024-09-23
+ 2024-09-23
diff --git a/search/search_index.json b/search/search_index.json
index a34293309..5df330dc9 100644
--- a/search/search_index.json
+++ b/search/search_index.json
@@ -1 +1 @@
-{"config":{"lang":["en"],"separator":"[\\s\\-]+","pipeline":["stopWordFilter"]},"docs":[{"location":"","title":"Quick Start","text":""},{"location":"#getting-started-with-kotaemon","title":"Getting Started with Kotaemon","text":"
This page is intended for end users who want to use the kotaemon tool for Question Answering on local documents. If you are a developer who wants contribute to the project, please visit the development page.
An open-source tool for chatting with your documents. Built with both end users and developers in mind.
Source Code | Live Demo
User Guide | Developer Guide | Feedback
Dark Mode | Light Mode
"},{"location":"local_model/","title":"Setup local LLMs & Embedding models","text":""},{"location":"local_model/#setup-local-llms-embedding-models","title":"Setup local LLMs & Embedding models","text":""},{"location":"local_model/#prepare-local-models","title":"Prepare local models","text":""},{"location":"local_model/#note","title":"NOTE","text":"
In the case of using Docker image, please replace http://localhost with http://host.docker.internal to correctly communicate with service on the host machine. See more detail.
"},{"location":"local_model/#ollama-openai-compatible-server-recommended","title":"Ollama OpenAI compatible server (recommended)","text":"
"},{"location":"local_model/#use-local-models-for-rag","title":"Use local models for RAG","text":"
Set default LLM and Embedding model to a local variant.
Set embedding model for the File Collection to a local model (e.g: ollama)
Go to Retrieval settings and choose LLM relevant scoring model as a local model (e.g: ollama). Or, you can choose to disable this feature if your machine cannot handle a lot of parallel LLM requests at the same time.
You are set! Start a new conversation to test your local RAG pipeline.
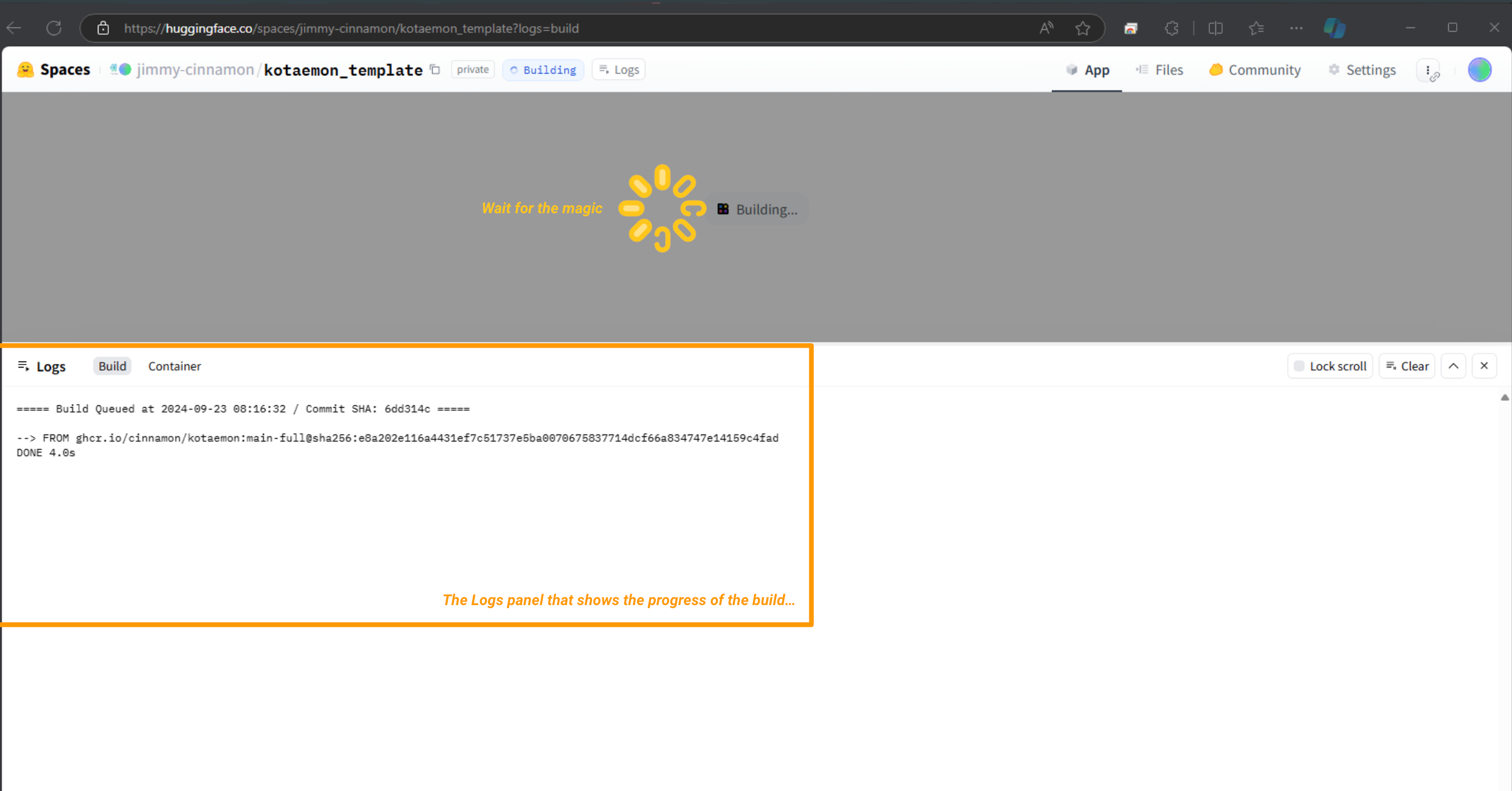
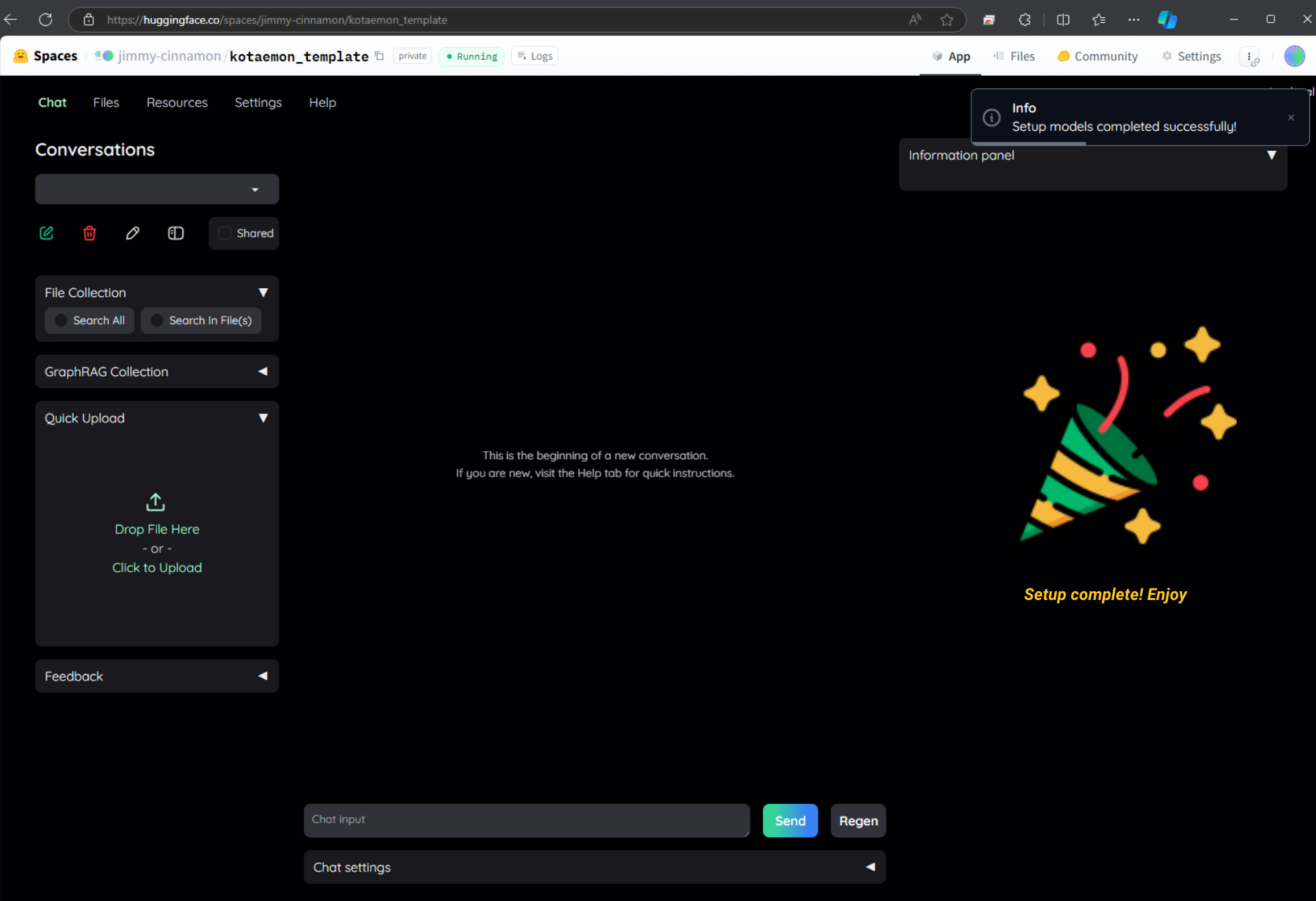
Wait for the build to complete and start up (apprx 10 mins).
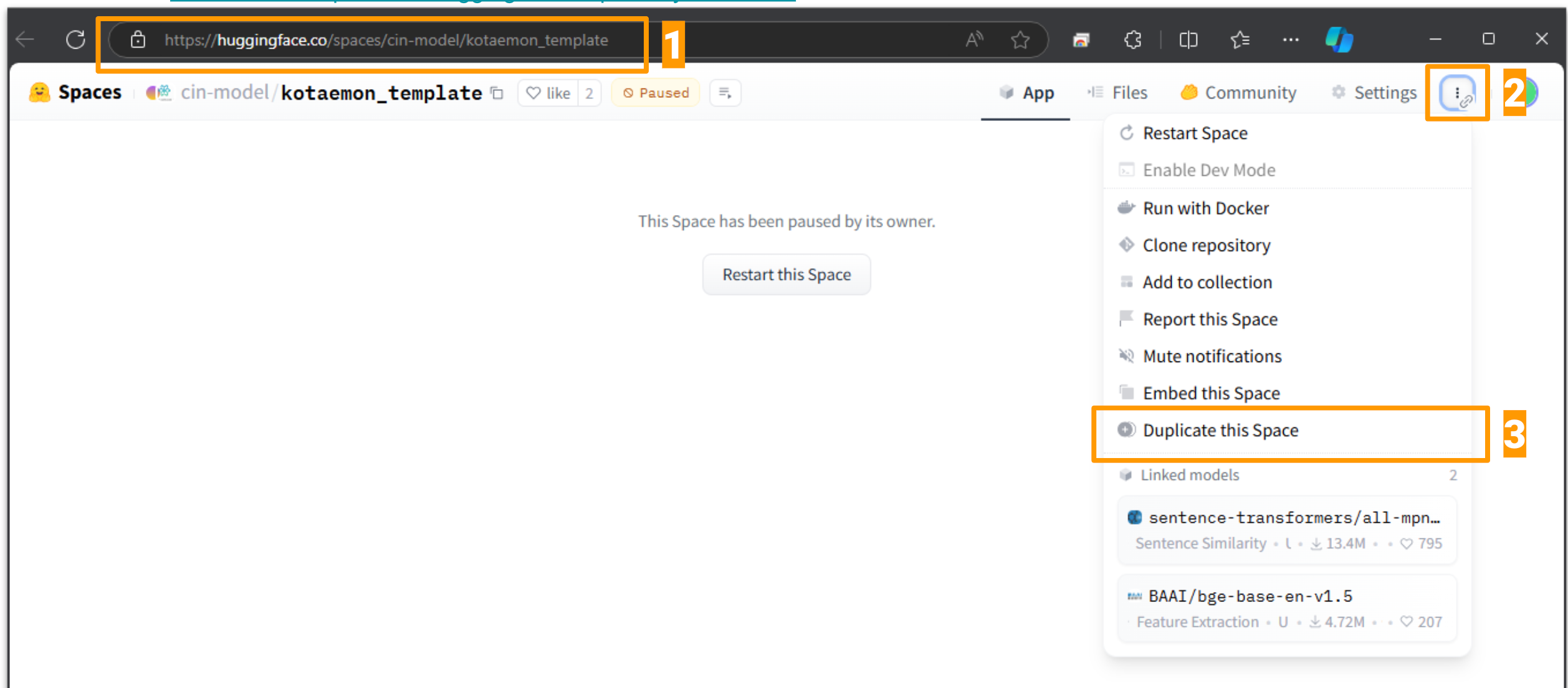
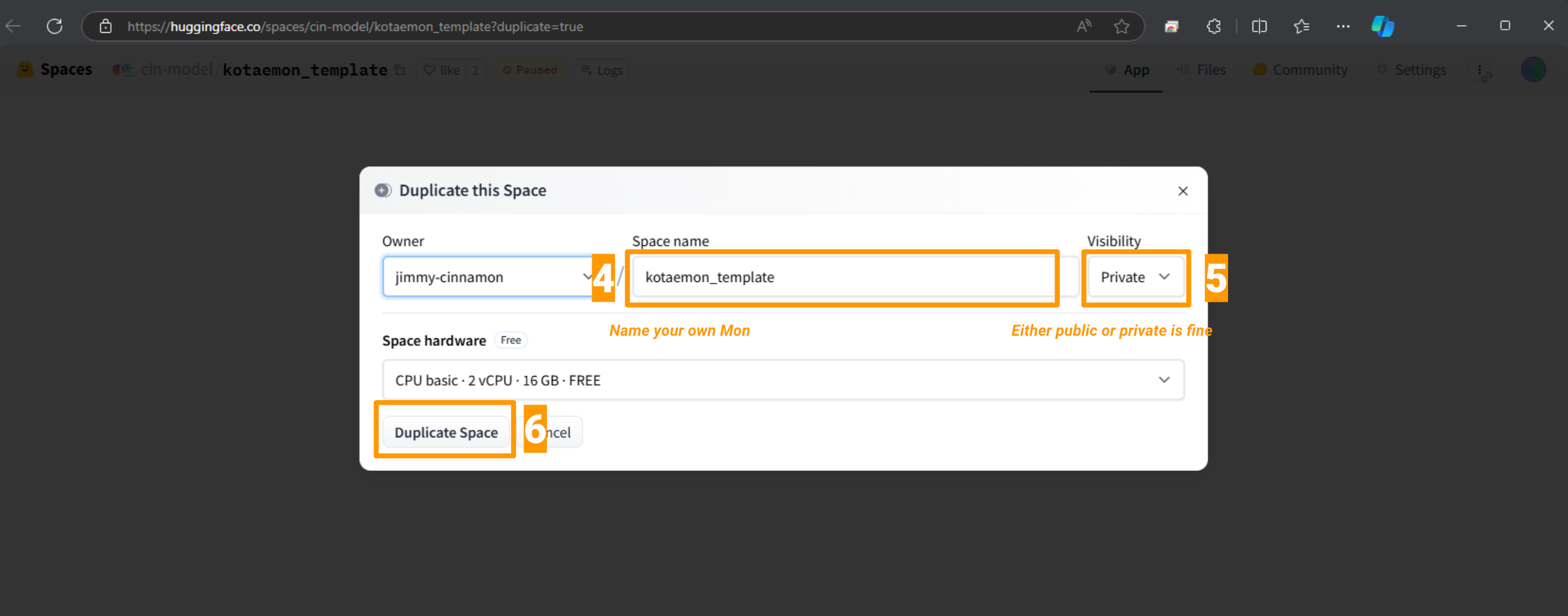
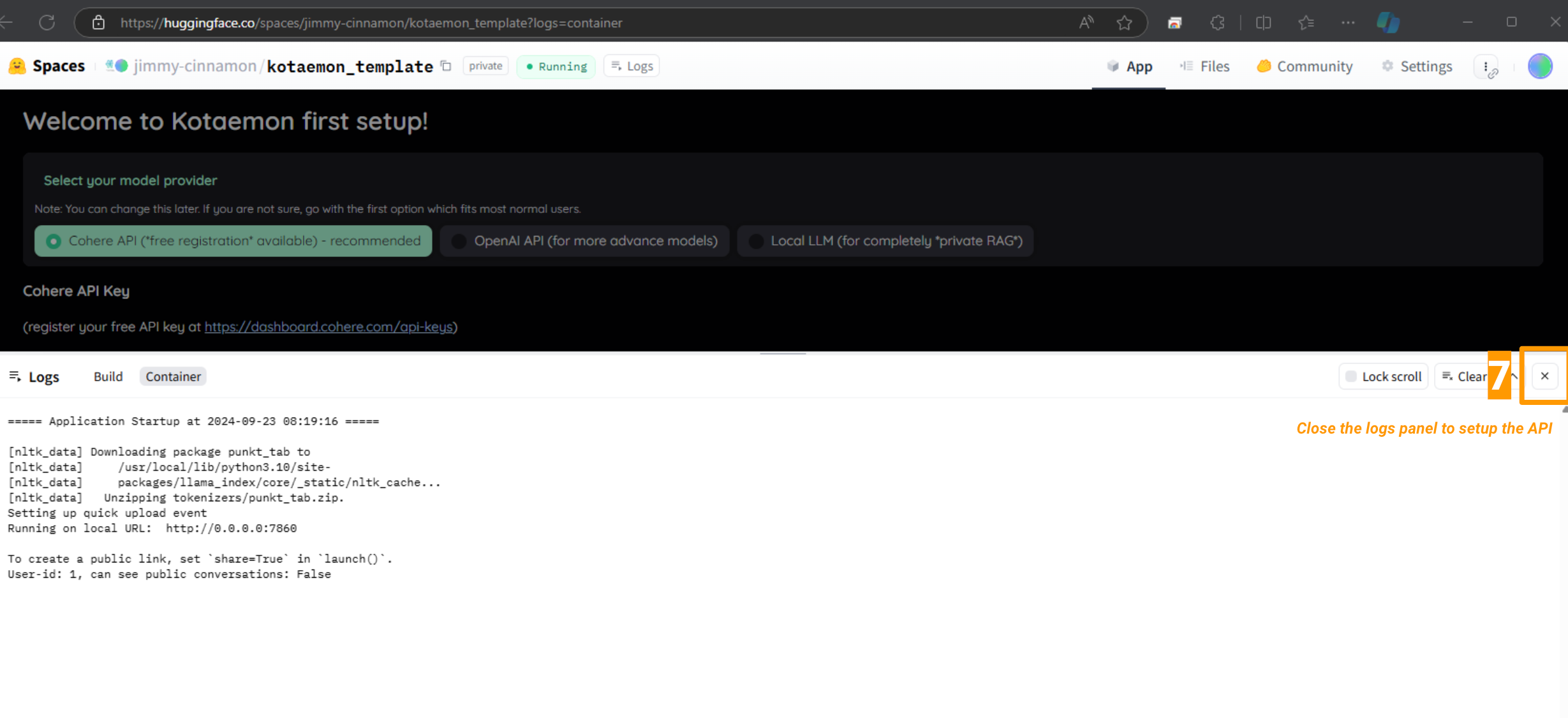
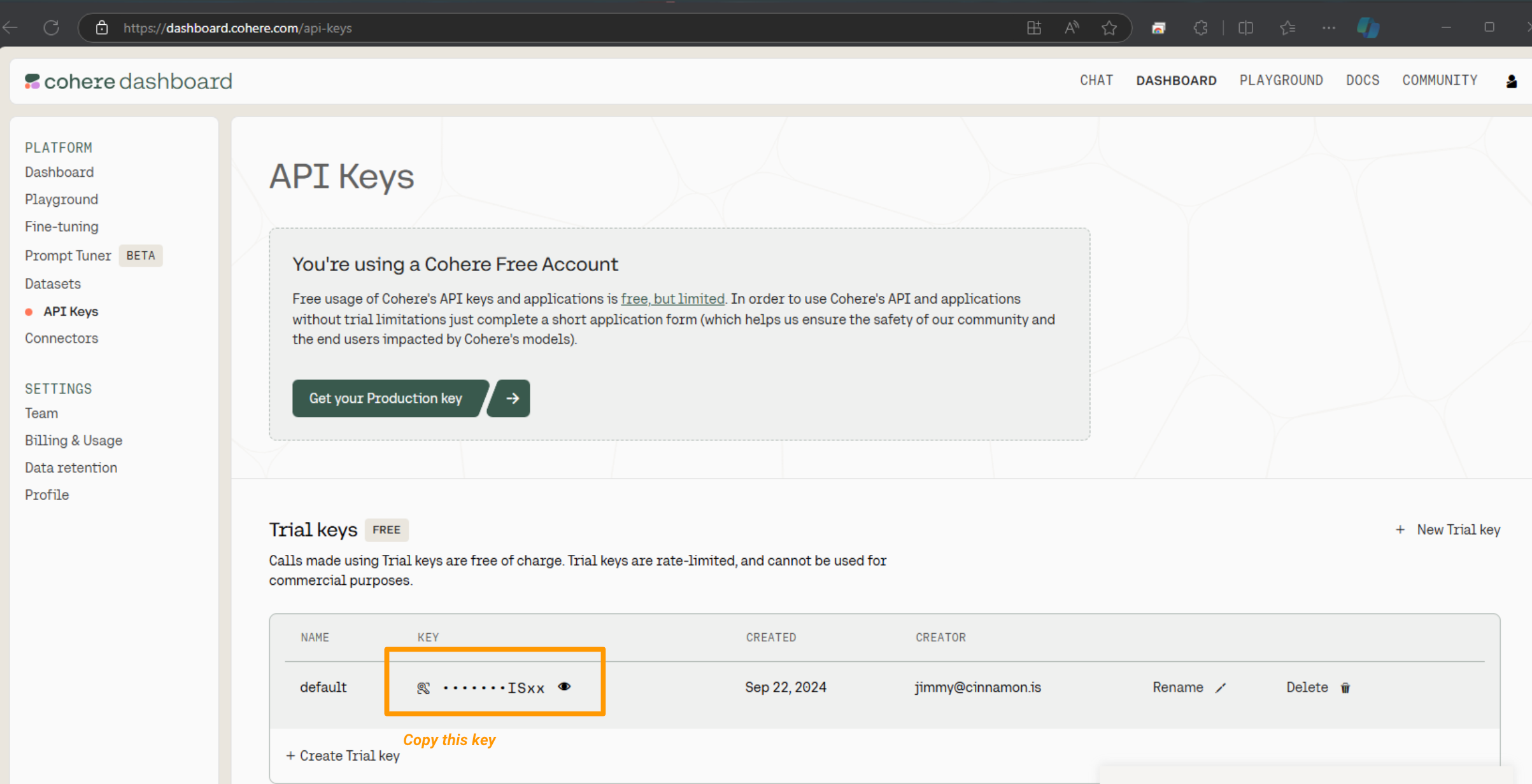
Follow the first setup instructions (and register for Cohere API key if needed)
Complete the setup and use your own private space!
"},{"location":"usage/","title":"Basic Usage","text":""},{"location":"usage/#1-add-your-ai-models","title":"1. Add your AI models","text":"
The tool uses Large Language Model (LLMs) to perform various tasks in a QA pipeline. So, you need to provide the application with access to the LLMs you want to use.
You only need to provide at least one. However, tt is recommended that you include all the LLMs that you have access to, you will be able to switch between them while using the application.
To add a model:
Navigate to the Resources tab.
Select the LLMs sub-tab.
Select the Add sub-tab.
Config the model to add:
Give it a name.
Pick a vendor/provider (e.g. ChatOpenAI).
Provide the specifications.
(Optional) Set the model as default.
Click Add to add the model.
Select Embedding Models sub-tab and repeat the step 3 to 5 to add an embedding model.
(Optional) Configure model via the .env file
Alternatively, you can configure the models via the .env file with the information needed to connect to the LLMs. This file is located in the folder of the application. If you don't see it, you can create one.
In the .env file, set the OPENAI_API_KEY variable with your OpenAI API key in order to enable access to OpenAI's models. There are other variables that can be modified, please feel free to edit them to fit your case. Otherwise, the default parameter should work for most people.
OPENAI_API_BASE=https://api.openai.com/v1\nOPENAI_API_KEY=<your OpenAI API key here>\nOPENAI_CHAT_MODEL=gpt-3.5-turbo\nOPENAI_EMBEDDINGS_MODEL=text-embedding-ada-002\n
For OpenAI models via Azure platform, you need to provide your Azure endpoint and API key. Your might also need to provide your developments' name for the chat model and the embedding model depending on how you set up Azure development.
AZURE_OPENAI_ENDPOINT=\nAZURE_OPENAI_API_KEY=\nOPENAI_API_VERSION=2024-02-15-preview # could be different for you\nAZURE_OPENAI_CHAT_DEPLOYMENT=gpt-35-turbo # change to your deployment name\nAZURE_OPENAI_EMBEDDINGS_DEPLOYMENT=text-embedding-ada-002 # change to your deployment name\n
Privacy. Your documents will be stored and process locally.
Choices. There are a wide range of LLMs in terms of size, domain, language to choose from.
Cost. It's free.
Cons:
Quality. Local models are much smaller and thus have lower generative quality than paid APIs.
Speed. Local models are deployed using your machine so the processing speed is limited by your hardware.
"},{"location":"usage/#find-and-download-a-llm","title":"Find and download a LLM","text":"
You can search and download a LLM to be ran locally from the Hugging Face Hub. Currently, these model formats are supported:
GGUF
You should choose a model whose size is less than your device's memory and should leave about 2 GB. For example, if you have 16 GB of RAM in total, of which 12 GB is available, then you should choose a model that take up at most 10 GB of RAM. Bigger models tend to give better generation but also take more processing time.
Here are some recommendations and their size in memory:
Qwen1.5-1.8B-Chat-GGUF: around 2 GB
"},{"location":"usage/#enable-local-models","title":"Enable local models","text":"
To add a local model to the model pool, set the LOCAL_MODEL variable in the .env file to the path of the model file.
LOCAL_MODEL=<full path to your model file>\n
Here is how to get the full path of your model file:
On Windows 11: right click the file and select Copy as Path.
"},{"location":"usage/#2-upload-your-documents","title":"2. Upload your documents","text":"
In order to do QA on your documents, you need to upload them to the application first. Navigate to the File Index tab and you will see 2 sections:
File upload:
Drag and drop your file to the UI or select it from your file system. Then click Upload and Index.
The application will take some time to process the file and show a message once it is done.
File list:
This section shows the list of files that have been uploaded to the application and allows users to delete them.
"},{"location":"usage/#3-chat-with-your-documents","title":"3. Chat with your documents","text":"
Now navigate back to the Chat tab. The chat tab is divided into 3 regions:
Conversation Settings Panel
Here you can select, create, rename, and delete conversations.
By default, a new conversation is created automatically if no conversation is selected.
Below that you have the file index, where you can choose whether to disable, select all files, or select which files to retrieve references from.
If you choose \"Disabled\", no files will be considered as context during chat.
If you choose \"Search All\", all files will be considered during chat.
If you choose \"Select\", a dropdown will appear for you to select the files to be considered during chat. If no files are selected, then no files will be considered during chat.
Chat Panel
This is where you can chat with the chatbot.
Information Panel
Supporting information such as the retrieved evidence and reference will be displayed here.
Direct citation for the answer produced by the LLM is highlighted.
The confidence score of the answer and relevant scores of evidences are displayed to quickly assess the quality of the answer and retrieved content.
Meaning of the score displayed:
Answer confidence: answer confidence level from the LLM model.
Relevance score: overall relevant score between evidence and user question.
Vectorstore score: relevant score from vector embedding similarity calculation (show full-text search if retrieved from full-text search DB).
LLM relevant score: relevant score from LLM model (which judge relevancy between question and evidence using specific prompt).
Reranking score: relevant score from Cohere reranking model.
Generally, the score quality is LLM relevant score > Reranking score > Vectorscore. By default, overall relevance score is taken directly from LLM relevant score. Evidences are sorted based on their overall relevance score and whether they have citation or not.
This project serves as a functional RAG UI for both end users who want to do QA on their documents and developers who want to build their own RAG pipeline.
For end users:
A clean & minimalistic UI for RAG-based QA.
Supports LLM API providers (OpenAI, AzureOpenAI, Cohere, etc) and local LLMs (via ollama and llama-cpp-python).
Easy installation scripts.
For developers:
A framework for building your own RAG-based document QA pipeline.
Customize and see your RAG pipeline in action with the provided UI (built with Gradio ).
If you use Gradio for development, check out our theme here: kotaemon-gradio-theme.
+----------------------------------------------------------------------------+\n| End users: Those who use apps built with `kotaemon`. |\n| (You use an app like the one in the demo above) |\n| +----------------------------------------------------------------+ |\n| | Developers: Those who built with `kotaemon`. | |\n| | (You have `import kotaemon` somewhere in your project) | |\n| | +----------------------------------------------------+ | |\n| | | Contributors: Those who make `kotaemon` better. | | |\n| | | (You make PR to this repo) | | |\n| | +----------------------------------------------------+ | |\n| +----------------------------------------------------------------+ |\n+----------------------------------------------------------------------------+\n
This repository is under active development. Feedback, issues, and PRs are highly appreciated.
Host your own document QA (RAG) web-UI. Support multi-user login, organize your files in private / public collections, collaborate and share your favorite chat with others.
Organize your LLM & Embedding models. Support both local LLMs & popular API providers (OpenAI, Azure, Ollama, Groq).
Hybrid RAG pipeline. Sane default RAG pipeline with hybrid (full-text & vector) retriever + re-ranking to ensure best retrieval quality.
Multi-modal QA support. Perform Question Answering on multiple documents with figures & tables support. Support multi-modal document parsing (selectable options on UI).
Advance citations with document preview. By default the system will provide detailed citations to ensure the correctness of LLM answers. View your citations (incl. relevant score) directly in the in-browser PDF viewer with highlights. Warning when retrieval pipeline return low relevant articles.
Support complex reasoning methods. Use question decomposition to answer your complex / multi-hop question. Support agent-based reasoning with ReAct, ReWOO and other agents.
Configurable settings UI. You can adjust most important aspects of retrieval & generation process on the UI (incl. prompts).
Extensible. Being built on Gradio, you are free to customize / add any UI elements as you like. Also, we aim to support multiple strategies for document indexing & retrieval. GraphRAG indexing pipeline is provided as an example.
"},{"location":"development/#installation","title":"Installation","text":""},{"location":"development/#for-end-users","title":"For end users","text":"
This document is intended for developers. If you just want to install and use the app as it is, please follow the non-technical User Guide. Use the most recent release .zip to include latest features and bug-fixes.
We support lite & full version of Docker images. With full, the extra packages of unstructured will be installed as well, it can support additional file types (.doc, .docx, ...) but the cost is larger docker image size. For most users, the lite image should work well in most cases.
Currently, two platforms: linux/amd64 and linux/arm64 (for newer Mac) are provided & tested. User can specify the platform by passing --platform in the docker run command. For example:
# To run docker with platform linux/arm64\ndocker run \\\n-e GRADIO_SERVER_NAME=0.0.0.0 \\\n-e GRADIO_SERVER_PORT=7860 \\\n-p 7860:7860 -it --rm \\\n--platform linux/arm64 \\\nghcr.io/cinnamon/kotaemon:main-lite\n
If everything is set up fine, navigate to http://localhost:7860/ to access the web UI.
We use GHCR to store docker images, all images can be found here.
This file provides another way to configure your models and credentials.
Configure model via the .env file
Alternatively, you can configure the models via the .env file with the information needed to connect to the LLMs. This file is located in the folder of the application. If you don't see it, you can create one.
In the .env file, set the OPENAI_API_KEY variable with your OpenAI API key in order to enable access to OpenAI's models. There are other variables that can be modified, please feel free to edit them to fit your case. Otherwise, the default parameter should work for most people.
OPENAI_API_BASE=https://api.openai.com/v1\nOPENAI_API_KEY=<your OpenAI API key here>\nOPENAI_CHAT_MODEL=gpt-3.5-turbo\nOPENAI_EMBEDDINGS_MODEL=text-embedding-ada-002\n
For OpenAI models via Azure platform, you need to provide your Azure endpoint and API key. Your might also need to provide your developments' name for the chat model and the embedding model depending on how you set up Azure development.
Set the model names on web UI and make it as default.
"},{"location":"development/#using-gguf-with-llama-cpp-python","title":"Using GGUF with llama-cpp-python","text":"
You can search and download a LLM to be ran locally from the Hugging Face Hub. Currently, these model formats are supported:
GGUF
You should choose a model whose size is less than your device's memory and should leave about 2 GB. For example, if you have 16 GB of RAM in total, of which 12 GB is available, then you should choose a model that takes up at most 10 GB of RAM. Bigger models tend to give better generation but also take more processing time.
Here are some recommendations and their size in memory:
Qwen1.5-1.8B-Chat-GGUF: around 2 GB
Add a new LlamaCpp model with the provided model name on the web uI.
"},{"location":"development/#adding-your-own-rag-pipeline","title":"Adding your own RAG pipeline","text":""},{"location":"development/#custom-reasoning-pipeline","title":"Custom reasoning pipeline","text":"
First, check the default pipeline implementation in here. You can make quick adjustment to how the default QA pipeline work.
Next, if you feel comfortable adding new pipeline, add new .py implementation in libs/ktem/ktem/reasoning/ and later include it in flowssettings to enable it on the UI.
Or run the installer (one of the scripts/run_* scripts depends on your OS), then you will have all the dependencies installed as a conda environment at install_dir/env.
kotaemon library focuses on the AI building blocks to implement a RAG-based QA application. It consists of base interfaces, core components and a list of utilities:
Base interfaces: kotaemon defines the base interface of a component in a pipeline. A pipeline is also a component. By clearly define this interface, a pipeline of steps can be easily constructed and orchestrated.
Core components: kotaemon implements (or wraps 3rd-party libraries like Langchain, llama-index,... when possible) commonly used components in kotaemon use cases. Some of these components are: LLM, vector store, document store, retriever... For a detailed list and description of these components, please refer to the API Reference section.
List of utilities: kotaemon provides utilities and tools that are usually needed in client project. For example, it provides a prompt engineering UI for AI developers in a project to quickly create a prompt engineering tool for DMs and QALs. It also provides a command to quickly spin up a project code base. For a full list and description of these utilities, please refer to the Utilities section.
[Encouraged] Provide a quick description in the PR, so that:
Reviewers can quickly understand the direction of the PR.
It will be included in the commit message when the PR is merged.
"},{"location":"development/contributing/#environment-caching-on-pr","title":"Environment caching on PR","text":"
To speed up CI, environments are cached based on the version specified in __init__.py.
Since dependencies versions in setup.py are not pinned, you need to pump the version in order to use a new environment. That environment will then be cached and used by your subsequence commits within the PR, until you pump the version again
The new environment created during your PR is cached and will be available to others once the PR is merged.
If you are experimenting with new dependencies and want a fresh environment every time, add [ignore cache] in your commit message. The CI will create a fresh environment to run your commit and then discard it.
If your PR include updated dependencies, the recommended workflow would be:
Doing development as usual.
When you want to run the CI, push a commit with the message containing [ignore cache].
Once the PR is final, pump the version in __init__.py and push a final commit not containing [ignore cache].
"},{"location":"development/create-a-component/","title":"Creating a Component","text":""},{"location":"development/create-a-component/#creating-a-component","title":"Creating a component","text":"
A fundamental concept in kotaemon is \"component\".
Anything that isn't data or data structure is a \"component\". A component can be thought of as a step within a pipeline. It takes in some input, processes it, and returns an output, just the same as a Python function! The output will then become an input for the next component in a pipeline. In fact, a pipeline is just a component. More appropriately, a nested component: a component that makes use of one or more other components in the processing step. So in reality, there isn't a difference between a pipeline and a component! Because of that, in kotaemon, we will consider them the same as \"component\".
To define a component, you will:
Create a class that subclasses from kotaemon.base.BaseComponent
Declare init params with type annotation
Declare nodes (nodes are just other components!) with type annotation
Implement the processing logic in run.
The syntax of a component is as follow:
from kotaemon.base import BaseComponent\nfrom kotaemon.llms import LCAzureChatOpenAI\nfrom kotaemon.parsers import RegexExtractor\n\n\nclass FancyPipeline(BaseComponent):\n param1: str = \"This is param1\"\n param2: int = 10\n param3: float\n\n node1: BaseComponent # this is a node because of BaseComponent type annotation\n node2: LCAzureChatOpenAI # this is also a node because LCAzureChatOpenAI subclasses BaseComponent\n node3: RegexExtractor # this is also a node bceause RegexExtractor subclasses BaseComponent\n\n def run(self, some_text: str):\n prompt = (self.param1 + some_text) * int(self.param2 + self.param3)\n llm_pred = self.node2(prompt).text\n matches = self.node3(llm_pred)\n return matches\n
This way, we can define each operation as a reusable component, and use them to compose larger reusable components!
"},{"location":"development/create-a-component/#benefits-of-component","title":"Benefits of component","text":"
By defining a component as above, we formally encapsulate all the necessary information inside a single class. This introduces several benefits:
Allow tools like promptui to inspect the inner working of a component in order to automatically generate the promptui.
Allow visualizing a pipeline for debugging purpose.
"},{"location":"development/data-components/","title":"Data & Data Structure Components","text":""},{"location":"development/data-components/#data-data-structure-components","title":"Data & Data Structure Components","text":"
MathPixLoader: To use this loader, you need MathPix API key, refer to mathpix docs for more information
OCRLoader: This loader uses lib-table and Flax pipeline to perform OCR and read table structure from PDF file (TODO: add more info about deployment of this module).
Output:
Document: text + metadata to identify whether it is table or not
- \"source\": source file name\n- \"type\": \"table\" or \"text\"\n- \"table_origin\": original table in markdown format (to be feed to LLM or visualize using external tools)\n- \"page_label\": page number in the original PDF document\n
Important: despite the name prompt engineering UI, this tool allows testers to test any kind of parameters that are exposed by developers. Prompt is one kind of param. There can be other type of params that testers can tweak (e.g. top_k, temperature...).
In the development process, developers typically build the pipeline. However, for use cases requiring expertise in prompt creation, non-technical members (testers, domain experts) can be more effective. To facilitate this, kotaemon offers a user-friendly prompt engineering UI that developers integrate into their pipelines. This enables non-technical members to adjust prompts and parameters, run experiments, and export results for optimization.
As of Sept 2023, there are 2 kinds of prompt engineering UI:
Simple pipeline: run one-way from start to finish.
[tech] Spin up prompt engineering UI: $ kotaemon promptui run <path/to/config/file.yml>
[non-tech] Change params, run inference
[non-tech] Export to Excel
[non-tech] Select the set of params that achieve the best output
The prompt engineering UI prominently involves from step 2 to step 7 (step 1 is normally done by the developers, while step 7 happens exclusively in Excel file).
"},{"location":"development/utilities/#step-2-export-pipeline-to-config","title":"Step 2 - Export pipeline to config","text":"
<module.path.pipelineclass> is a dot-separated path to the pipeline. For example, if your pipeline can be accessed with from projectA.pipelines import AnsweringPipeline, then this value is projectA.pipelines.AnswerPipeline.
<path/to/config/file.yml> is the target file path that the config will be exported to. If the config file already exists, and contains information of other pipelines, the config of current pipeline will additionally be added. If it contains information of the current pipeline (in the past), the old information will be replaced.
By default, all params in a pipeline (including nested params) will be export to the configuration file. For params that you do not wish to expose to the UI, you can directly remove them from the config YAML file. You can also annotate those param with ignore_ui=True, and they will be ignored in the config generation process. Example:
Declared as above, and param1 will show up in the config YAML file, while param2 will not.
"},{"location":"development/utilities/#step-3-customize-the-config","title":"Step 3 - Customize the config","text":"
developers can further edit the config file in this step to get the most suitable UI (step 4) with their tasks. The exported config will have this overall schema:
<module.path.pipelineclass1>:\n params: ... (Detail param information to initiate a pipeline. This corresponds to the pipeline init parameters.)\n inputs: ... (Detail the input of the pipeline e.g. a text prompt. This corresponds to the params of `run(...)` method.)\n outputs: ... (Detail the output of the pipeline e.g. prediction, accuracy... This is the output information we wish to see in the UI.)\n logs: ... (Detail what information should show up in the log.)\n
"},{"location":"development/utilities/#input-and-params","title":"Input and params","text":"
The inputs section have the overall schema as follow:
inputs:\n <input-variable-name-1>:\n component: <supported-UI-component>\n params: # this section is optional)\n value: <default-value>\n <input-variable-name-2>: ... # similar to above\nparams:\n <param-variable-name-1>: ... # similar to those in the inputs\n
The list of supported prompt UI and their corresponding gradio UI components:
The outputs are a list of variables that we wish to show in the UI. Since in Python, the function output doesn't have variable name, so output declaration is a little bit different than input and param declaration:
outputs:\n - component: <supported-UI-component>\n step: <name-of-pipeline-step>\n item: <jsonpath way to retrieve the info>\n - ... # similar to above\n
where:
component: the same text string and corresponding Gradio UI as in inputs & params
step: the pipeline step that we wish to look fetch and show output on the UI
item: the jsonpath mechanism to get the targeted variable from the step above
The logs show a list of sheetname and how to retrieve the desired information.
logs:\n <logname>:\n inputs:\n - name: <column name>\n step: <the pipeline step that we would wish to see the input>\n variable: <the variable in the step>\n - ...\n outputs:\n - name: <column name>\n step: <the pipeline step that we would wish to see the output>\n item: <how to retrieve the output of that step>\n
Chat pipeline workflow is different from simple pipeline workflow. In simple pipeline, each Run creates a set of output, input and params for users to compare. In chat pipeline, each Run is not a one-off run, but a long interactive session. Hence, the workflow is as follow:
Set the desired parameters.
Click \"New chat\" to start a chat session with the supplied parameters. This set of parameters will persist until the end of the chat session. During an ongoing chat session, changing the parameters will not take any effect.
Chat and interact with the chat bot on the right panel. You can add any additional input (if any), and they will be supplied to the chatbot.
During chat, the log of the chat will show up in the \"Output\" tabs. This is empty by default, so if you want to show the log here, tell the AI developers to configure the UI settings.
When finishing chat, select your preference in the radio box. Click \"End chat\". This will save the chat log and the preference to disk.
To compare the result of different run, click \"Export\" to get an Excel spreadsheet summary of different run.
"},{"location":"pages/app/customize-flows/","title":"Customize flow logic","text":""},{"location":"pages/app/customize-flows/#add-new-indexing-and-reasoning-pipeline-to-the-application","title":"Add new indexing and reasoning pipeline to the application","text":"
@trducng
At high level, to add new indexing and reasoning pipeline:
You define your indexing or reasoning pipeline as a class from BaseComponent.
You declare that class in the setting files flowsettings.py.
Then when python app.py, the application will dynamically load those pipelines.
The below sections talk in more detail about how the pipelines should be constructed.
"},{"location":"pages/app/customize-flows/#define-a-pipeline-as-a-class","title":"Define a pipeline as a class","text":"
In essence, a pipeline will subclass from kotaemon.base.BaseComponent. Each pipeline has 2 main parts:
This pipeline is simple for demonstration purpose, but we can imagine pipelines with much more arguments, that can take other pipelines as arguments, and have more complicated logic in the run method.
An indexing or reasoning pipeline is just a class subclass from BaseComponent like above.
For more detail on this topic, please refer to Creating a Component
Note: this section is tentative at the moment. We will finalize def run function signature by latest early April.
The indexing pipeline:
def run(\n self,\n file_paths: str | Path | list[str | Path],\n reindex: bool = False,\n **kwargs,\n ):\n \"\"\"Index files to intermediate representation (e.g. vector, database...)\n\n Args:\n file_paths: the list of paths to files\n reindex: if True, files in `file_paths` that already exists in database\n should be reindex.\n \"\"\"\n
The reasoning pipeline:
def run(self, question: str, history: list, **kwargs) -> Document:\n \"\"\"Answer the question\n\n Args:\n question: the user input\n history: the chat history [(user_msg1, bot_msg1), (user_msg2, bot_msg2)...]\n\n Returns:\n kotaemon.base.Document: the final answer\n \"\"\"\n
"},{"location":"pages/app/customize-flows/#register-your-pipeline-to-ktem","title":"Register your pipeline to ktem","text":"
To register your pipelines to ktem, you declare it in the flowsettings.py file. This file locates at the current working directory where you start the ktem. In most use cases, it is this one.
You can register multiple reasoning pipelines to ktem by populating the KH_REASONING list. The user can select which reasoning pipeline to use in their Settings page.
For now, there's only one supported index option for KH_INDEX.
Make sure that your class is discoverable by Python.
"},{"location":"pages/app/customize-flows/#allow-users-to-customize-your-pipeline-in-the-app-settings","title":"Allow users to customize your pipeline in the app settings","text":"
To allow the users to configure your pipeline, you need to declare what you allow the users to configure as a dictionary. ktem will include them into the application settings.
In your pipeline class, add a classmethod get_user_settings that returns a setting dictionary, add a classmethod get_info that returns an info dictionary. Example:
class SoSimple(BaseComponent):\n\n ... # as above\n\n @classmethod\n def get_user_settings(cls) -> dict:\n \"\"\"The settings to the user\"\"\"\n return {\n \"setting_1\": {\n \"name\": \"Human-friendly name\",\n \"value\": \"Default value\",\n \"choices\": [(\"Human-friendly Choice 1\", \"choice1-id\"), (\"HFC 2\", \"choice2-id\")], # optional\n \"component\": \"Which Gradio UI component to render, can be: text, number, checkbox, dropdown, radio, checkboxgroup\"\n },\n \"setting_2\": {\n # follow the same rule as above\n }\n }\n\n @classmethod\n def get_info(cls) -> dict:\n \"\"\"Pipeline information for bookkeeping purpose\"\"\"\n return {\n \"id\": \"a unique id to differentiate this pipeline from other pipeline\",\n \"name\": \"Human-friendly name of the pipeline\",\n \"description\": \"Can be a short description of this pipeline\"\n }\n
Once adding these methods to your pipeline class, ktem will automatically extract and add them to the settings.
"},{"location":"pages/app/customize-flows/#construct-to-pipeline-object","title":"Construct to pipeline object","text":"
Once ktem runs your pipeline, it will call your classmethod get_pipeline with the full user settings and expect to obtain the pipeline object. Within this get_pipeline method, you implement all the necessary logics to initiate the pipeline object. Example:
class SoSimple(BaseComponent):\n ... # as above\n\n @classmethod\n def get_pipeline(self, setting):\n obj = cls(arg1=setting[\"reasoning.id.setting1\"])\n return obj\n
"},{"location":"pages/app/customize-flows/#reasoning-stream-output-to-ui","title":"Reasoning: Stream output to UI","text":"
For fast user experience, you can stream the output directly to UI. This way, user can start observing the output as soon as the LLM model generates the 1st token, rather than having to wait the pipeline finishes to read the whole message.
To stream the output, you need to;
Turn the run function to async.
Pass in the output to a special queue with self.report_output.
async def run(self, question: str, history: list, **kwargs) -> Document:\n for char in \"This is a long messages\":\n self.report_output({\"output\": text.text})\n
The argument to self.report_output is a dictionary, that contains either or all of these 2 keys: \"output\", \"evidence\". The \"output\" string will be streamed to the chat message, and the \"evidence\" string will be streamed to the information panel.
The kotaemon focuses on question and answering over a corpus of data. Below is the gentle introduction about the chat functionality.
Users can upload corpus of files.
Users can converse to the chatbot to ask questions about the corpus of files.
Users can view the reference in the files.
"},{"location":"pages/app/functional-description/","title":"Functional description","text":""},{"location":"pages/app/functional-description/#user-group-tenant-management","title":"User group / tenant management","text":""},{"location":"pages/app/functional-description/#create-new-user-group","title":"Create new user group","text":"
(6 man-days)
Description: each client has a dedicated user group. Each user group has an admin user who can do administrative tasks (e.g. creating user account in that user group...). The workflow for creating new user group is as follow:
Cinnamon accesses the user group management UI.
On \"Create user group\" panel, we supply: a. Client name: e.g. Apple. b. Sub-domain name: e.g. apple. c. Admin email, username & password.
The system will: a. An Aurora Platform deployment with the specified sub-domain. b. Send an email to the admin, with the username & password.
Expectation:
The admin can go to the deployed Aurora Platform.
The admin can login with the specified username & password.
Condition:
When sub-domain name already exists, raise error.
If error sending email to the client, raise the error, and delete the newly-created user-group.
Password rule:
Have at least 8 characters.
Must contain uppercase, lowercase, number and symbols.
"},{"location":"pages/app/functional-description/#delete-user-group","title":"Delete user group","text":"
(2 man-days)
Description: in the tenant management page, we can delete the selected user group. The user flow is as follow:
Cinnamon accesses the user group management UI,
View list of user groups.
Next to target user group, click delete.
Confirm whether to delete.
If Yes, delete the user group. If No, cancel the operation.
Expectation: when a user group is deleted, we expect to delete everything related to the user groups: domain, files, databases, caches, deployments.
"},{"location":"pages/app/functional-description/#user-management","title":"User management","text":""},{"location":"pages/app/functional-description/#create-user-account-for-admin-user","title":"Create user account (for admin user)","text":"
(1 man-day)
Description: the admin user in the client's account can create user account for that user group. To create the new user, the client admin do:
Navigate to \"Admin\" > \"Users\"
In the \"Create user\" panel, supply:
Username
Password
Confirm password
Click \"Create\"
Expectation:
The user can create the account.
The username:
Is case-insensitive (e.g. Moon and moon will be the same)
Can only contains these characters: a-z A-Z 0-9 _ + - .
Has maximum length of 32 characters
The password is subjected to the following rule:
8-character minimum length
Contains at least 1 number
Contains at least 1 lowercase letter
Contains at least 1 uppercase letter
Contains at least 1 special character from the following set, or a non-leading, non-trailing space character: ^ $ * . [ ] { } ( ) ? - \" ! @ # % & / \\ , > < ' : ; | _ ~ + =
"},{"location":"pages/app/functional-description/#delete-user-account-for-admin-user","title":"Delete user account (for admin user)","text":"
Description: the admin user in the client's account can delete user account. Once an user account is deleted, he/she cannot login to Aurora Platform.
The admin user navigates to \"Admin\" > \"Users\".
In the user list panel, next to the username, the admin click on the \"Delete\" button. The Confirmation dialog appears.
If \"Delete\", the user account is deleted. If \"Cancel\", do nothing. The Confirmation dialog disappears.
Expectation:
Once the user is deleted, the following information relating to the user will be deleted:
His/her personal setting.
His/her conversations.
The following information relating to the user will still be retained:
His/her uploaded files.
"},{"location":"pages/app/functional-description/#edit-user-account-for-admin-user","title":"Edit user account (for admin user)","text":"
Description: the admin user can change any information about the user account, including password. To change user information:
The admin user navigates to \"Admin\" > \"Users\".
In the user list panel, next to the username, the admin click on the \"Edit\" button.
The user list disappears, the user detail appears, with the following information show up:
Username: (prefilled the username)
Password: (blank)
Confirm password: (blank)
The admin can edit any of the information, and click \"Save\" or \"Cancel\".
If \"Save\": the information will be updated to the database, or show error per Expectation below.
If \"Cancel\": skip.
If Save success or Cancel, transfer back to the user list UI, where the user information is updated accordingly.
Expectation:
If the \"Password\" & \"Confirm password\" are different from each other, show error: \"Password mismatch\".
If both \"Password\" & *\"Confirm password\" are blank, don't change the user password.
If changing password, the password rule is subjected to the same rule when creating user.
It's possible to change username. If changing username, the target user has to use the new username.
Description: the user can change their password as follow:
User navigates to the Settings > User page.
In the change password section, the user provides these info and click Change:
Current password
New password
Confirm new password
If changing successfully, then the password is changed. Otherwise, show the error on the UI.
Expectation:
If changing password succeeds, next time they logout/login to the system, they can use the new password.
Password rule (Same as normal password rule when creating user)
Errors:
Password does not match.
Violated password rules.
"},{"location":"pages/app/functional-description/#chat","title":"Chat","text":""},{"location":"pages/app/functional-description/#chat-to-the-bot","title":"Chat to the bot","text":"
Description: the Aurora Platform focuses on question and answering over the uploaded data. Each chat has the following components:
Chat message: show the exchange between bots and humans.
Text input + send button: for the user to input the message.
Data source panel: for selecting the files that will scope the context for the bot.
Information panel: showing evidence as the bot answers user's questions.
The chat workflow looks as follow:
[Optional] User select files that they want to scope the context for the bot. If the user doesn't select any files, then all files on Aurora Platform will be the context for the bot.
The user can type multi-line messages, using \"Shift + Enter\" for line-break.
User sends the message (either clicking the Send button or hitting the Enter key).
The bot in the chat conversation will return \"Thinking...\" while it processes.
The information panel on the right begin to show data related to the user message.
The bot begins to generate answer. The \"Thinking...\" placeholder disappears..
Expecatation:
Messages:
User can send multi-line messages, using \"Shift + Enter\" for line-break.
User can thumbs up, thumbs down the AI response. This information is recorded in the database.
User can click on a copy button on the chat message to copy the content to clipboard.
Information panel:
The information panel shows the latest evidence.
The user can click on the message, and the reference for that message will show up on the \"Reference panel\" (feature in-planning).
The user can click on the title to show/hide the content.
The whole information panel can be collapsed.
Chatbot quality:
The user can converse with the bot. The bot answer the user's requests in a natural manner.
The bot message should be streamed to the UI. The bot don't wait to gather alll the text response, then dump all of them at once.
Description: users can jump around between different conversations. They can see the list of all conversations, can select an old converation, and continue the chat under the context of the old conversation. The switching workflow is like this:
Users click on the conversation dropdown. It will show a list of conversations.
Within that dropdown, the user selects one conversation.
The chat messages, information panel, and selected data will show the content in that old chat.
The user can continue chatting as normal under the context of this old chat.
Expectation:
In the conversation drop down list, the conversations are ordered in created date order.
When there is no conversation, the conversation list is empty.
When there is no conversation, the user can still converse with the chat bot. When doing so, it automatically create new conversation.
Description: the user can upload files to the Aurora Platform. The uploaded files will be served as context for our chatbot to refer to when it converses with the user. To upload file, the user:
Navigate to the File tab.
Within the File tab, there is an Upload section.
User can add files to the Upload section through drag & drop, and or by click on the file browser.
User can select some options relating to uploading and indexing. Depending on the project, these options can be different. Nevertheless, they will discuss below.
User click on \"Upload and Index\" button.
The app show notifications when indexing starts and finishes, and when errors happen on the top right corner.
Options:
Force re-index file. When user tries to upload files that already exists on the system:
If this option is True: will re-index those files.
If this option is False: will skip indexing those files.
Condition:
Max number of files: 100 files.
Max number of pages per file: 500 pages
Max file size: 10 MB
"},{"location":"pages/app/functional-description/#list-all-files","title":"List all files","text":"
Description: the user can know which files are on the system by:
Navigate to the File tab.
By default, it will show all the uploaded files, each with the following information: file name, file size, number of pages, uploaded date
The UI also shows total number of pages, and total number of sizes in MB.
The file index stores files in a local folder and index them for retrieval. This file index provides the following infrastructure to support the indexing:
SQL table Source: store the list of files that are indexed by the system
Vector store: contain the embedding of segments of the files
Document store: contain the text of segments of the files. Each text stored in this document store is associated with a vector in the vector store.
SQL table Index: store the relationship between (1) the source and the docstore, and (2) the source and the vector store.
The indexing and retrieval pipelines are encouraged to use the above software infrastructure.
The ktem has default indexing pipeline: ktem.index.file.pipelines.IndexDocumentPipeline.
This default pipeline works as follow:
Input: list of file paths
Output: list of nodes that are indexed into database
Process:
Read files into texts. Different file types has different ways to read texts.
Split text files into smaller segments
Run each segments into embeddings.
Store the embeddings into vector store. Store the texts of each segment into docstore. Store the list of files in Source. Store the linking between Sources and docstore + vectorstore in Index table.
You can customize this default pipeline if your indexing process is close to the default pipeline. You can create your own indexing pipeline if there are too much different logic.
"},{"location":"pages/app/index/file/#customize-the-default-pipeline","title":"Customize the default pipeline","text":"
The default pipeline provides the contact points in flowsettings.py.
FILE_INDEX_PIPELINE_FILE_EXTRACTORS. Supply overriding file extractor, based on file extension. Example: {\".pdf\": \"path.to.PDFReader\", \".xlsx\": \"path.to.ExcelReader\"}
FILE_INDEX_PIPELINE_SPLITTER_CHUNK_SIZE. The expected number of characters of each text segment. Example: 1024.
FILE_INDEX_PIPELINE_SPLITTER_CHUNK_OVERLAP. The expected number of characters that consecutive text segments should overlap with each other. Example: 256.
"},{"location":"pages/app/index/file/#create-your-own-indexing-pipeline","title":"Create your own indexing pipeline","text":"
Your indexing pipeline will subclass BaseFileIndexIndexing.
You should define the following methods:
run(self, file_paths): run the indexing given the pipeline
get_pipeline(cls, user_settings, index_settings): return the fully-initialized pipeline, ready to be used by ktem.
user_settings: is a dictionary contains user settings (e.g. {\"pdf_mode\": True, \"num_retrieval\": 5}). You can declare these settings in the get_user_settings classmethod. ktem will collect these settings into the app Settings page, and will supply these user settings to your get_pipeline method.
index_settings: is a dictionary. Currently it's empty for File Index.
get_user_settings: to declare user settings, return a dictionary.
By subclassing BaseFileIndexIndexing, You will have access to the following resources:
self._Source: the source table
self._Index: the index table
self._VS: the vector store
self._DS: the docstore
Once you have prepared your pipeline, register it in flowsettings.py: FILE_INDEX_PIPELINE = \"<python.path.to.your.pipeline>\".
The ktem has default retrieval pipeline: ktem.index.file.pipelines.DocumentRetrievalPipeline. This pipeline works as follow:
Input: user text query & optionally a list of source file ids
Output: the output segments that match the user text query
Process:
If a list of source file ids is given, get the list of vector ids that associate with those file ids.
Embed the user text query.
Query the vector store. Provide a list of vector ids to limit query scope if the user restrict.
Return the matched text segments
"},{"location":"pages/app/index/file/#create-your-own-retrieval-pipeline","title":"Create your own retrieval pipeline","text":"
Your retrieval pipeline will subclass BaseFileIndexRetriever. The retriever has the same database, vectorstore and docstore accesses like the indexing pipeline.
You should define the following methods:
run(self, query, file_ids): retrieve relevant documents relating to the query. If file_ids is given, you should restrict your search within these file_ids.
get_pipeline(cls, user_settings, index_settings, selected): return the fully-initialized pipeline, ready to be used by ktem.
user_settings: is a dictionary contains user settings (e.g. {\"pdf_mode\": True, \"num_retrieval\": 5}). You can declare these settings in the get_user_settings classmethod. ktem will collect these settings into the app Settings page, and will supply these user settings to your get_pipeline method.
index_settings: is a dictionary. Currently it's empty for File Index.
selected: a list of file ids selected by user. If user doesn't select anything, this variable will be None.
get_user_settings: to declare user settings, return a dictionary.
Once you build the retrieval pipeline class, you can register it in flowsettings.py: FILE_INDEXING_RETRIEVER_PIPELIENS = [\"path.to.retrieval.pipelie\"]. Because there can be multiple parallel pipelines within an index, this variable takes a list of string rather than a string.
"},{"location":"pages/app/index/file/#software-infrastructure","title":"Software infrastructure","text":"Infra Access Schema Ref SQL table Source self._Source - id (int): id of the source (auto)- name (str): the name of the file- path (str): the path of the file- size (int): the file size in bytes- note (dict): allow extra optional information about the file- date_created (datetime): the time the file is created (auto) This is SQLALchemy ORM class. Can consult SQL table Index self._Index - id (int): id of the index entry (auto)- source_id (int): the id of a file in the Source table- target_id: the id of the segment in docstore or vector store- relation_type (str): if the link is \"document\" or \"vector\" This is SQLAlchemy ORM class Vector store self._VS - self._VS.add: add the list of embeddings to the vector store (optionally associate metadata and ids)- self._VS.delete: delete vector entries based on ids- self._VS.query: get embeddings based on embeddings. kotaemon > storages > vectorstores > BaseVectorStore Doc store self._DS - self._DS.add: add the segments to document stores- self._DS.get: get the segments based on id- self._DS.get_all: get all segments- self._DS.delete: delete segments based on id kotaemon > storages > docstores > base > BaseDocumentStore"},{"location":"pages/app/settings/overview/","title":"Settings","text":""},{"location":"pages/app/settings/overview/#overview","title":"Overview","text":"
There are 3 kinds of settings in ktem, geared towards different stakeholders for different use cases:
Developer settings. These settings are meant for very basic app customization, such as database URL, cloud config, logging config, which features to enable... You will be interested in the developer settings if you deploy ktem to your customers, or if you build extension for ktem for developers. These settings are declared inside flowsettings.py.
Admin settings. These settings show up in the Admin page, and are meant to allow admin-level user to customize low level features, such as which credentials to connect to data sources, which keys to use for LLM...
User settings. These settings are meant for run-time users to tweak ktem to their personal needs, such as which output languages the chatbot should generate, which reasoning type to use...
ktem allows developers to extend the index and the reasoning pipeline. In many cases, these components can have settings that should be modified by users at run-time, (e.g. topk, chunksize...). These are the user settings.
ktem allows developers to declare such user settings in their code. Once declared, ktem will render them in a Settings page.
There are 2 places that ktem looks for declared user settings. You can refer to the respective pages.
In the index.
In the reasoning pipeline.
"},{"location":"pages/app/settings/user-settings/#syntax-of-a-settings","title":"Syntax of a settings","text":"
A collection of settings is a dictionary of type dict[str, dict], where the key is a setting id, and the value is the description of the setting.
Agents * Base * Io * Base * Langchain Based * React * Agent * Prompt * Rewoo * Agent * Planner * Prompt * Solver * Tools * Base * Google * Llm * Wikipedia * Utils
Base * Component * Schema
Chatbot * Base * Simple Respondent
CLI
Embeddings * Base * Endpoint Based * Fastembed * Langchain Based * Openai
Indices * Base * Extractors * Doc Parsers * Ingests * Files * Qa * Citation * Text Based * Rankings * Base * Cohere * Llm * Llm Scoring * Llm Trulens * Splitters * Vectorindex
LLMs * Base * Branching * Chats * Base * Endpoint Based * Langchain Based * Llamacpp * Openai * Completions * Base * Langchain Based * Cot * Linear * Prompts * Base * Template
\n# Run with default config file\n$ kh promptui run\n\n\n# Run with username and password supplied\n$ kh promptui run --username admin --password password\n\n\n# Run with username and prompted password\n$ kh promptui run --username admin\n\n# Run and share to promptui\n# kh promptui run --username admin --password password --share --appname hey --port 7861\n
Source code in libs/kotaemon/kotaemon/cli.py
@promptui.command()\n@click.argument(\"run_path\", required=False, default=\"promptui.yml\")\n@click.option(\n \"--share\",\n is_flag=True,\n show_default=True,\n default=False,\n help=\"Share the app through Gradio. Requires --username to enable authentication.\",\n)\n@click.option(\n \"--username\",\n required=False,\n help=(\n \"Username for the user. If not provided, the promptui will not have \"\n \"authentication.\"\n ),\n)\n@click.option(\n \"--password\",\n required=False,\n help=\"Password for the user. If not provided, will be prompted.\",\n)\n@click.option(\n \"--appname\",\n required=False,\n help=\"The share app subdomain. Requires --share and --username\",\n)\n@click.option(\n \"--port\",\n required=False,\n help=\"Port to run the app. If not provided, will $GRADIO_SERVER_PORT (7860)\",\n)\ndef run(run_path, share, username, password, appname, port):\n \"\"\"Run the UI from a config file\n\n Examples:\n\n \\b\n # Run with default config file\n $ kh promptui run\n\n \\b\n # Run with username and password supplied\n $ kh promptui run --username admin --password password\n\n \\b\n # Run with username and prompted password\n $ kh promptui run --username admin\n\n # Run and share to promptui\n # kh promptui run --username admin --password password --share --appname hey \\\n --port 7861\n \"\"\"\n import sys\n\n from kotaemon.contribs.promptui.ui import build_from_dict\n\n sys.path.append(os.getcwd())\n\n check_config_format(run_path)\n demo = build_from_dict(run_path)\n\n params: dict = {}\n if username is not None:\n if password is not None:\n auth = (username, password)\n else:\n auth = (username, click.prompt(\"Password\", hide_input=True))\n params[\"auth\"] = auth\n\n port = int(port) if port else int(os.getenv(\"GRADIO_SERVER_PORT\", \"7860\"))\n params[\"server_port\"] = port\n\n if share:\n if username is None:\n raise ValueError(\n \"Username must be provided to enable authentication for sharing\"\n )\n if appname:\n from kotaemon.contribs.promptui.tunnel import Tunnel\n\n tunnel = Tunnel(\n appname=str(appname), username=str(username), local_port=port\n )\n url = tunnel.run()\n print(f\"App is shared at {url}\")\n else:\n params[\"share\"] = True\n print(\"App is shared at Gradio\")\n\n demo.launch(**params)\n
Important: the value for --template corresponds to the name of the template folder, which is located at https://github.com/Cinnamon/kotaemon/tree/main/templates The default value is \"project-default\", which should work when you are starting a client project.
Source code in libs/kotaemon/kotaemon/cli.py
@main.command()\n@click.option(\n \"--template\",\n default=\"project-default\",\n required=False,\n help=\"Template name\",\n show_default=True,\n)\ndef start_project(template):\n \"\"\"Start a project from a template.\n\n Important: the value for --template corresponds to the name of the template folder,\n which is located at https://github.com/Cinnamon/kotaemon/tree/main/templates\n The default value is \"project-default\", which should work when you are starting a\n client project.\n \"\"\"\n\n print(\"Retrieving template...\")\n os.system(\n \"cookiecutter git@github.com:Cinnamon/kotaemon.git \"\n f\"--directory='templates/{template}'\"\n )\n
Source code in libs/kotaemon/kotaemon/agents/base.py
class BaseAgent(BaseComponent):\n \"\"\"Define base agent interface\"\"\"\n\n name: str = Param(help=\"Name of the agent.\")\n agent_type: AgentType = Param(help=\"Agent type, must be one of AgentType\")\n description: str = Param(\n help=(\n \"Description used to tell the model how/when/why to use the agent. You can\"\n \" provide few-shot examples as a part of the description. This will be\"\n \" input to the prompt of LLM.\"\n )\n )\n llm: Optional[BaseLLM] = Node(\n help=(\n \"LLM to be used for the agent (optional). LLM must implement BaseLLM\"\n \" interface.\"\n )\n )\n prompt_template: Optional[Union[PromptTemplate, dict[str, PromptTemplate]]] = Param(\n help=\"A prompt template or a dict to supply different prompt to the agent\"\n )\n plugins: list[BaseTool] = Param(\n default_callback=lambda _: [],\n help=\"List of plugins / tools to be used in the agent\",\n )\n\n @staticmethod\n def safeguard_run(run_func, *args, **kwargs):\n def wrapper(self, *args, **kwargs):\n try:\n return run_func(self, *args, **kwargs)\n except Exception as e:\n return AgentOutput(\n text=\"\",\n agent_type=self.agent_type,\n status=\"failed\",\n error=str(e),\n )\n\n return wrapper\n\n def add_tools(self, tools: list[BaseTool]) -> None:\n \"\"\"Helper method to add tools and update agent state if needed\"\"\"\n self.plugins.extend(tools)\n\n def run(self, *args, **kwargs) -> AgentOutput | list[AgentOutput]:\n \"\"\"Run the component.\"\"\"\n raise NotImplementedError()\n
Helper method to add tools and update agent state if needed
Source code in libs/kotaemon/kotaemon/agents/base.py
def add_tools(self, tools: list[BaseTool]) -> None:\n \"\"\"Helper method to add tools and update agent state if needed\"\"\"\n self.plugins.extend(tools)\n
required Source code in libs/kotaemon/kotaemon/agents/io/base.py
class AgentFinish(NamedTuple):\n \"\"\"Agent's return value when finishing execution.\n\n Args:\n return_values: The return values of the agent.\n log: The log message.\n \"\"\"\n\n return_values: dict\n log: str\n
required Source code in libs/kotaemon/kotaemon/agents/io/base.py
class AgentOutput(LLMInterface):\n \"\"\"Output from an agent.\n\n Args:\n text: The text output from the agent.\n agent_type: The type of agent.\n status: The status after executing the agent.\n error: The error message if any.\n \"\"\"\n\n model_config = ConfigDict(extra=\"allow\")\n\n text: str\n type: str = \"agent\"\n agent_type: AgentType\n status: Literal[\"thinking\", \"finished\", \"stopped\", \"failed\"]\n error: Optional[str] = None\n intermediate_steps: Optional[list] = None\n
str, optional The title of the panel, defaults to \"Output\".
'Output'stream
bool, optional
False Source code in libs/kotaemon/kotaemon/agents/io/base.py
def panel_print(self, item: Any, title: str = \"Output\", stream: bool = False):\n \"\"\"\n Log a panel output.\n\n Args:\n item : Any\n The item to log.\n title : str, optional\n The title of the panel, defaults to \"Output\".\n stream : bool, optional\n \"\"\"\n if not stream:\n self.log.append(item)\n if check_log():\n self.logger.info(\"-\" * 20)\n self.logger.info(item)\n self.logger.info(\"-\" * 20)\n
Sequential ReactAgent class inherited from BaseAgent. Implementing ReAct agent paradigm https://arxiv.org/pdf/2210.03629.pdf
Source code in libs/kotaemon/kotaemon/agents/react/agent.py
class ReactAgent(BaseAgent):\n \"\"\"\n Sequential ReactAgent class inherited from BaseAgent.\n Implementing ReAct agent paradigm https://arxiv.org/pdf/2210.03629.pdf\n \"\"\"\n\n name: str = \"ReactAgent\"\n agent_type: AgentType = AgentType.react\n description: str = \"ReactAgent for answering multi-step reasoning questions\"\n llm: BaseLLM\n prompt_template: Optional[PromptTemplate] = None\n output_lang: str = \"English\"\n plugins: list[BaseTool] = Param(\n default_callback=lambda _: [], help=\"List of tools to be used in the agent. \"\n )\n examples: dict[str, str | list[str]] = Param(\n default_callback=lambda _: {}, help=\"Examples to be used in the agent. \"\n )\n intermediate_steps: list[tuple[AgentAction | AgentFinish, str]] = Param(\n default_callback=lambda _: [],\n help=\"List of AgentAction and observation (tool) output\",\n )\n max_iterations: int = 5\n strict_decode: bool = False\n max_context_length: int = Param(\n default=3000,\n help=\"Max context length for each tool output.\",\n )\n trim_func: TokenSplitter | None = None\n\n def _compose_plugin_description(self) -> str:\n \"\"\"\n Compose the worker prompt from the workers.\n\n Example:\n toolname1[input]: tool1 description\n toolname2[input]: tool2 description\n \"\"\"\n prompt = \"\"\n try:\n for plugin in self.plugins:\n prompt += f\"{plugin.name}[input]: {plugin.description}\\n\"\n except Exception:\n raise ValueError(\"Worker must have a name and description.\")\n return prompt\n\n def _construct_scratchpad(\n self, intermediate_steps: list[tuple[AgentAction | AgentFinish, str]] = []\n ) -> str:\n \"\"\"Construct the scratchpad that lets the agent continue its thought process.\"\"\"\n thoughts = \"\"\n for action, observation in intermediate_steps:\n thoughts += action.log\n thoughts += f\"\\nObservation: {observation}\\nThought:\"\n return thoughts\n\n def _parse_output(self, text: str) -> Optional[AgentAction | AgentFinish]:\n \"\"\"\n Parse text output from LLM for the next Action or Final Answer\n Using Regex to parse \"Action:\\n Action Input:\\n\" for the next Action\n Using FINAL_ANSWER_ACTION to parse Final Answer\n\n Args:\n text[str]: input text to parse\n \"\"\"\n includes_answer = FINAL_ANSWER_ACTION in text\n regex = (\n r\"Action\\s*\\d*\\s*:[\\s]*(.*?)[\\s]*Action\\s*\\d*\\s*Input\\s*\\d*\\s*:[\\s]*(.*)\"\n )\n action_match = re.search(regex, text, re.DOTALL)\n action_output: Optional[AgentAction | AgentFinish] = None\n if action_match:\n if includes_answer:\n raise Exception(\n \"Parsing LLM output produced both a final answer \"\n f\"and a parse-able action: {text}\"\n )\n action = action_match.group(1).strip()\n action_input = action_match.group(2)\n tool_input = action_input.strip(\" \")\n # ensure if its a well formed SQL query we don't remove any trailing \" chars\n if tool_input.startswith(\"SELECT \") is False:\n tool_input = tool_input.strip('\"')\n\n action_output = AgentAction(action, tool_input, text)\n\n elif includes_answer:\n action_output = AgentFinish(\n {\"output\": text.split(FINAL_ANSWER_ACTION)[-1].strip()}, text\n )\n else:\n if self.strict_decode:\n raise Exception(f\"Could not parse LLM output: `{text}`\")\n else:\n action_output = AgentFinish({\"output\": text}, text)\n\n return action_output\n\n def _compose_prompt(self, instruction) -> str:\n \"\"\"\n Compose the prompt from template, worker description, examples and instruction.\n \"\"\"\n agent_scratchpad = self._construct_scratchpad(self.intermediate_steps)\n tool_description = self._compose_plugin_description()\n tool_names = \", \".join([plugin.name for plugin in self.plugins])\n if self.prompt_template is None:\n from .prompt import zero_shot_react_prompt\n\n self.prompt_template = zero_shot_react_prompt\n return self.prompt_template.populate(\n instruction=instruction,\n agent_scratchpad=agent_scratchpad,\n tool_description=tool_description,\n tool_names=tool_names,\n lang=self.output_lang,\n )\n\n def _format_function_map(self) -> dict[str, BaseTool]:\n \"\"\"Format the function map for the open AI function API.\n\n Return:\n Dict[str, Callable]: The function map.\n \"\"\"\n # Map the function name to the real function object.\n function_map = {}\n for plugin in self.plugins:\n function_map[plugin.name] = plugin\n return function_map\n\n def _trim(self, text: str | Document) -> str:\n \"\"\"\n Trim the text to the maximum token length.\n \"\"\"\n evidence_trim_func = (\n self.trim_func\n if self.trim_func\n else TokenSplitter(\n chunk_size=self.max_context_length,\n chunk_overlap=0,\n separator=\" \",\n tokenizer=partial(\n tiktoken.encoding_for_model(\"gpt-3.5-turbo\").encode,\n allowed_special=set(),\n disallowed_special=\"all\",\n ),\n )\n )\n if isinstance(text, str):\n texts = evidence_trim_func([Document(text=text)])\n elif isinstance(text, Document):\n texts = evidence_trim_func([text])\n else:\n raise ValueError(\"Invalid text type to trim\")\n trim_text = texts[0].text\n logging.info(f\"len (trimmed): {len(trim_text)}\")\n return trim_text\n\n def clear(self):\n \"\"\"\n Clear and reset the agent.\n \"\"\"\n self.intermediate_steps = []\n\n def run(self, instruction, max_iterations=None) -> AgentOutput:\n \"\"\"\n Run the agent with the given instruction.\n\n Args:\n instruction: Instruction to run the agent with.\n max_iterations: Maximum number of iterations\n of reasoning steps, defaults to 10.\n\n Return:\n AgentOutput object.\n \"\"\"\n if not max_iterations:\n max_iterations = self.max_iterations\n assert max_iterations > 0\n\n self.clear()\n logging.info(f\"Running {self.name} with instruction: {instruction}\")\n total_cost = 0.0\n total_token = 0\n status = \"failed\"\n response_text = None\n\n for step_count in range(1, max_iterations + 1):\n prompt = self._compose_prompt(instruction)\n logging.info(f\"Prompt: {prompt}\")\n response = self.llm(\n prompt, stop=[\"Observation:\"]\n ) # could cause bugs if llm doesn't have `stop` as a parameter\n response_text = response.text\n logging.info(f\"Response: {response_text}\")\n action_step = self._parse_output(response_text)\n if action_step is None:\n raise ValueError(\"Invalid action\")\n is_finished_chain = isinstance(action_step, AgentFinish)\n if is_finished_chain:\n result = \"\"\n else:\n assert isinstance(action_step, AgentAction)\n action_name = action_step.tool\n tool_input = action_step.tool_input\n logging.info(f\"Action: {action_name}\")\n logging.info(f\"Tool Input: {tool_input}\")\n result = self._format_function_map()[action_name](tool_input)\n\n # trim the worker output to 1000 tokens, as we are appending\n # all workers' logs and it can exceed the token limit if we\n # don't limit each. Fix this number regarding to the LLM capacity.\n result = self._trim(result)\n logging.info(f\"Result: {result}\")\n\n self.intermediate_steps.append((action_step, result))\n if is_finished_chain:\n logging.info(f\"Finished after {step_count} steps.\")\n status = \"finished\"\n break\n else:\n status = \"stopped\"\n\n return AgentOutput(\n text=response_text,\n agent_type=self.agent_type,\n status=status,\n total_tokens=total_token,\n total_cost=total_cost,\n intermediate_steps=self.intermediate_steps,\n max_iterations=max_iterations,\n )\n\n def stream(self, instruction, max_iterations=None):\n \"\"\"\n Stream the agent with the given instruction.\n\n Args:\n instruction: Instruction to run the agent with.\n max_iterations: Maximum number of iterations\n of reasoning steps, defaults to 10.\n\n Return:\n AgentOutput object.\n \"\"\"\n if not max_iterations:\n max_iterations = self.max_iterations\n assert max_iterations > 0\n\n self.clear()\n logging.info(f\"Running {self.name} with instruction: {instruction}\")\n print(f\"Running {self.name} with instruction: {instruction}\")\n total_cost = 0.0\n total_token = 0\n status = \"failed\"\n response_text = None\n\n for step_count in range(1, max_iterations + 1):\n prompt = self._compose_prompt(instruction)\n logging.info(f\"Prompt: {prompt}\")\n print(f\"Prompt: {prompt}\")\n response = self.llm(\n prompt, stop=[\"Observation:\"]\n ) # TODO: could cause bugs if llm doesn't have `stop` as a parameter\n response_text = response.text\n logging.info(f\"Response: {response_text}\")\n print(f\"Response: {response_text}\")\n action_step = self._parse_output(response_text)\n if action_step is None:\n raise ValueError(\"Invalid action\")\n is_finished_chain = isinstance(action_step, AgentFinish)\n if is_finished_chain:\n result = response_text\n if \"Final Answer:\" in response_text:\n result = response_text.split(\"Final Answer:\")[-1].strip()\n else:\n assert isinstance(action_step, AgentAction)\n action_name = action_step.tool\n tool_input = action_step.tool_input\n logging.info(f\"Action: {action_name}\")\n print(f\"Action: {action_name}\")\n logging.info(f\"Tool Input: {tool_input}\")\n print(f\"Tool Input: {tool_input}\")\n result = self._format_function_map()[action_name](tool_input)\n\n # trim the worker output to 1000 tokens, as we are appending\n # all workers' logs and it can exceed the token limit if we\n # don't limit each. Fix this number regarding to the LLM capacity.\n result = self._trim(result)\n logging.info(f\"Result: {result}\")\n print(f\"Result: {result}\")\n\n self.intermediate_steps.append((action_step, result))\n if is_finished_chain:\n logging.info(f\"Finished after {step_count} steps.\")\n status = \"finished\"\n yield AgentOutput(\n text=result,\n agent_type=self.agent_type,\n status=status,\n intermediate_steps=self.intermediate_steps[-1],\n )\n break\n else:\n yield AgentOutput(\n text=\"\",\n agent_type=self.agent_type,\n status=\"thinking\",\n intermediate_steps=self.intermediate_steps[-1],\n )\n\n else:\n status = \"stopped\"\n yield AgentOutput(\n text=\"\",\n agent_type=self.agent_type,\n status=status,\n intermediate_steps=self.intermediate_steps[-1],\n )\n\n return AgentOutput(\n text=response_text,\n agent_type=self.agent_type,\n status=status,\n total_tokens=total_token,\n total_cost=total_cost,\n intermediate_steps=self.intermediate_steps,\n max_iterations=max_iterations,\n )\n
Maximum number of iterations of reasoning steps, defaults to 10.
None Return
AgentOutput object.
Source code in libs/kotaemon/kotaemon/agents/react/agent.py
def run(self, instruction, max_iterations=None) -> AgentOutput:\n \"\"\"\n Run the agent with the given instruction.\n\n Args:\n instruction: Instruction to run the agent with.\n max_iterations: Maximum number of iterations\n of reasoning steps, defaults to 10.\n\n Return:\n AgentOutput object.\n \"\"\"\n if not max_iterations:\n max_iterations = self.max_iterations\n assert max_iterations > 0\n\n self.clear()\n logging.info(f\"Running {self.name} with instruction: {instruction}\")\n total_cost = 0.0\n total_token = 0\n status = \"failed\"\n response_text = None\n\n for step_count in range(1, max_iterations + 1):\n prompt = self._compose_prompt(instruction)\n logging.info(f\"Prompt: {prompt}\")\n response = self.llm(\n prompt, stop=[\"Observation:\"]\n ) # could cause bugs if llm doesn't have `stop` as a parameter\n response_text = response.text\n logging.info(f\"Response: {response_text}\")\n action_step = self._parse_output(response_text)\n if action_step is None:\n raise ValueError(\"Invalid action\")\n is_finished_chain = isinstance(action_step, AgentFinish)\n if is_finished_chain:\n result = \"\"\n else:\n assert isinstance(action_step, AgentAction)\n action_name = action_step.tool\n tool_input = action_step.tool_input\n logging.info(f\"Action: {action_name}\")\n logging.info(f\"Tool Input: {tool_input}\")\n result = self._format_function_map()[action_name](tool_input)\n\n # trim the worker output to 1000 tokens, as we are appending\n # all workers' logs and it can exceed the token limit if we\n # don't limit each. Fix this number regarding to the LLM capacity.\n result = self._trim(result)\n logging.info(f\"Result: {result}\")\n\n self.intermediate_steps.append((action_step, result))\n if is_finished_chain:\n logging.info(f\"Finished after {step_count} steps.\")\n status = \"finished\"\n break\n else:\n status = \"stopped\"\n\n return AgentOutput(\n text=response_text,\n agent_type=self.agent_type,\n status=status,\n total_tokens=total_token,\n total_cost=total_cost,\n intermediate_steps=self.intermediate_steps,\n max_iterations=max_iterations,\n )\n
Maximum number of iterations of reasoning steps, defaults to 10.
None Return
AgentOutput object.
Source code in libs/kotaemon/kotaemon/agents/react/agent.py
def stream(self, instruction, max_iterations=None):\n \"\"\"\n Stream the agent with the given instruction.\n\n Args:\n instruction: Instruction to run the agent with.\n max_iterations: Maximum number of iterations\n of reasoning steps, defaults to 10.\n\n Return:\n AgentOutput object.\n \"\"\"\n if not max_iterations:\n max_iterations = self.max_iterations\n assert max_iterations > 0\n\n self.clear()\n logging.info(f\"Running {self.name} with instruction: {instruction}\")\n print(f\"Running {self.name} with instruction: {instruction}\")\n total_cost = 0.0\n total_token = 0\n status = \"failed\"\n response_text = None\n\n for step_count in range(1, max_iterations + 1):\n prompt = self._compose_prompt(instruction)\n logging.info(f\"Prompt: {prompt}\")\n print(f\"Prompt: {prompt}\")\n response = self.llm(\n prompt, stop=[\"Observation:\"]\n ) # TODO: could cause bugs if llm doesn't have `stop` as a parameter\n response_text = response.text\n logging.info(f\"Response: {response_text}\")\n print(f\"Response: {response_text}\")\n action_step = self._parse_output(response_text)\n if action_step is None:\n raise ValueError(\"Invalid action\")\n is_finished_chain = isinstance(action_step, AgentFinish)\n if is_finished_chain:\n result = response_text\n if \"Final Answer:\" in response_text:\n result = response_text.split(\"Final Answer:\")[-1].strip()\n else:\n assert isinstance(action_step, AgentAction)\n action_name = action_step.tool\n tool_input = action_step.tool_input\n logging.info(f\"Action: {action_name}\")\n print(f\"Action: {action_name}\")\n logging.info(f\"Tool Input: {tool_input}\")\n print(f\"Tool Input: {tool_input}\")\n result = self._format_function_map()[action_name](tool_input)\n\n # trim the worker output to 1000 tokens, as we are appending\n # all workers' logs and it can exceed the token limit if we\n # don't limit each. Fix this number regarding to the LLM capacity.\n result = self._trim(result)\n logging.info(f\"Result: {result}\")\n print(f\"Result: {result}\")\n\n self.intermediate_steps.append((action_step, result))\n if is_finished_chain:\n logging.info(f\"Finished after {step_count} steps.\")\n status = \"finished\"\n yield AgentOutput(\n text=result,\n agent_type=self.agent_type,\n status=status,\n intermediate_steps=self.intermediate_steps[-1],\n )\n break\n else:\n yield AgentOutput(\n text=\"\",\n agent_type=self.agent_type,\n status=\"thinking\",\n intermediate_steps=self.intermediate_steps[-1],\n )\n\n else:\n status = \"stopped\"\n yield AgentOutput(\n text=\"\",\n agent_type=self.agent_type,\n status=status,\n intermediate_steps=self.intermediate_steps[-1],\n )\n\n return AgentOutput(\n text=response_text,\n agent_type=self.agent_type,\n status=status,\n total_tokens=total_token,\n total_cost=total_cost,\n intermediate_steps=self.intermediate_steps,\n max_iterations=max_iterations,\n )\n
Source code in libs/kotaemon/kotaemon/agents/tools/base.py
class BaseTool(BaseComponent):\n name: str\n \"\"\"The unique name of the tool that clearly communicates its purpose.\"\"\"\n description: str\n \"\"\"Description used to tell the model how/when/why to use the tool.\n You can provide few-shot examples as a part of the description. This will be\n input to the prompt of LLM.\n \"\"\"\n args_schema: Optional[Type[BaseModel]] = None\n \"\"\"Pydantic model class to validate and parse the tool's input arguments.\"\"\"\n verbose: bool = False\n \"\"\"Whether to log the tool's progress.\"\"\"\n handle_tool_error: Optional[\n Union[bool, str, Callable[[ToolException], str]]\n ] = False\n \"\"\"Handle the content of the ToolException thrown.\"\"\"\n\n def _parse_input(\n self,\n tool_input: Union[str, Dict],\n ) -> Union[str, Dict[str, Any]]:\n \"\"\"Convert tool input to pydantic model.\"\"\"\n args_schema = self.args_schema\n if isinstance(tool_input, str):\n if args_schema is not None:\n key_ = next(iter(args_schema.model_fields.keys()))\n args_schema.validate({key_: tool_input})\n return tool_input\n else:\n if args_schema is not None:\n result = args_schema.parse_obj(tool_input)\n return {k: v for k, v in result.dict().items() if k in tool_input}\n return tool_input\n\n def _run_tool(\n self,\n *args: Any,\n **kwargs: Any,\n ) -> Any:\n \"\"\"Call tool.\"\"\"\n raise NotImplementedError(f\"_run_tool is not implemented for {self.name}\")\n\n def _to_args_and_kwargs(self, tool_input: Union[str, Dict]) -> Tuple[Tuple, Dict]:\n # For backwards compatibility, if run_input is a string,\n # pass as a positional argument.\n if isinstance(tool_input, str):\n return (tool_input,), {}\n else:\n return (), tool_input\n\n def _handle_tool_error(self, e: ToolException) -> Any:\n \"\"\"Handle the content of the ToolException thrown.\"\"\"\n observation = None\n if not self.handle_tool_error:\n raise e\n elif isinstance(self.handle_tool_error, bool):\n if e.args:\n observation = e.args[0]\n else:\n observation = \"Tool execution error\"\n elif isinstance(self.handle_tool_error, str):\n observation = self.handle_tool_error\n elif callable(self.handle_tool_error):\n observation = self.handle_tool_error(e)\n else:\n raise ValueError(\n f\"Got unexpected type of `handle_tool_error`. Expected bool, str \"\n f\"or callable. Received: {self.handle_tool_error}\"\n )\n return observation\n\n def to_langchain_format(self) -> LCTool:\n \"\"\"Convert this tool to Langchain format to use with its agent\"\"\"\n return LCTool(name=self.name, description=self.description, func=self.run)\n\n def run(\n self,\n tool_input: Union[str, Dict],\n verbose: Optional[bool] = None,\n **kwargs: Any,\n ) -> Any:\n \"\"\"Run the tool.\"\"\"\n parsed_input = self._parse_input(tool_input)\n # TODO (verbose_): Add logging\n try:\n tool_args, tool_kwargs = self._to_args_and_kwargs(parsed_input)\n call_kwargs = {**kwargs, **tool_kwargs}\n observation = self._run_tool(*tool_args, **call_kwargs)\n except ToolException as e:\n observation = self._handle_tool_error(e)\n return observation\n else:\n return observation\n\n @classmethod\n def from_langchain_format(cls, langchain_tool: LCTool) -> \"BaseTool\":\n \"\"\"Wrapper for Langchain Tool\"\"\"\n new_tool = BaseTool(\n name=langchain_tool.name, description=langchain_tool.description\n )\n new_tool._run_tool = langchain_tool._run # type: ignore\n return new_tool\n
Description used to tell the model how/when/why to use the tool. You can provide few-shot examples as a part of the description. This will be input to the prompt of LLM.
Convert this tool to Langchain format to use with its agent
Source code in libs/kotaemon/kotaemon/agents/tools/base.py
def to_langchain_format(self) -> LCTool:\n \"\"\"Convert this tool to Langchain format to use with its agent\"\"\"\n return LCTool(name=self.name, description=self.description, func=self.run)\n
Wrapper around other BaseComponent to use it as a tool
Parameters:
Name Type Description Default component
BaseComponent-based component to wrap
required postprocessor
Optional postprocessor for the component output
required Source code in libs/kotaemon/kotaemon/agents/tools/base.py
class ComponentTool(BaseTool):\n \"\"\"Wrapper around other BaseComponent to use it as a tool\n\n Args:\n component: BaseComponent-based component to wrap\n postprocessor: Optional postprocessor for the component output\n \"\"\"\n\n component: BaseComponent\n postprocessor: Optional[Callable] = None\n\n def _run_tool(self, *args: Any, **kwargs: Any) -> Any:\n output = self.component(*args, **kwargs)\n if self.postprocessor:\n output = self.postprocessor(output)\n\n return output\n
Tool that adds the capability to query the Wikipedia API.
Source code in libs/kotaemon/kotaemon/agents/tools/wikipedia.py
class WikipediaTool(BaseTool):\n \"\"\"Tool that adds the capability to query the Wikipedia API.\"\"\"\n\n name: str = \"wikipedia\"\n description: str = (\n \"Search engine from Wikipedia, retrieving relevant wiki page. \"\n \"Useful when you need to get holistic knowledge about people, \"\n \"places, companies, historical events, or other subjects. \"\n \"Input should be a search query.\"\n )\n args_schema: Optional[Type[BaseModel]] = WikipediaArgs\n doc_store: Any = None\n\n def _run_tool(self, query: AnyStr) -> AnyStr:\n if not self.doc_store:\n self.doc_store = Wiki()\n tool = self.doc_store\n evidence = tool.search(query)\n return evidence\n
Source code in libs/kotaemon/kotaemon/agents/base.py
class BaseAgent(BaseComponent):\n \"\"\"Define base agent interface\"\"\"\n\n name: str = Param(help=\"Name of the agent.\")\n agent_type: AgentType = Param(help=\"Agent type, must be one of AgentType\")\n description: str = Param(\n help=(\n \"Description used to tell the model how/when/why to use the agent. You can\"\n \" provide few-shot examples as a part of the description. This will be\"\n \" input to the prompt of LLM.\"\n )\n )\n llm: Optional[BaseLLM] = Node(\n help=(\n \"LLM to be used for the agent (optional). LLM must implement BaseLLM\"\n \" interface.\"\n )\n )\n prompt_template: Optional[Union[PromptTemplate, dict[str, PromptTemplate]]] = Param(\n help=\"A prompt template or a dict to supply different prompt to the agent\"\n )\n plugins: list[BaseTool] = Param(\n default_callback=lambda _: [],\n help=\"List of plugins / tools to be used in the agent\",\n )\n\n @staticmethod\n def safeguard_run(run_func, *args, **kwargs):\n def wrapper(self, *args, **kwargs):\n try:\n return run_func(self, *args, **kwargs)\n except Exception as e:\n return AgentOutput(\n text=\"\",\n agent_type=self.agent_type,\n status=\"failed\",\n error=str(e),\n )\n\n return wrapper\n\n def add_tools(self, tools: list[BaseTool]) -> None:\n \"\"\"Helper method to add tools and update agent state if needed\"\"\"\n self.plugins.extend(tools)\n\n def run(self, *args, **kwargs) -> AgentOutput | list[AgentOutput]:\n \"\"\"Run the component.\"\"\"\n raise NotImplementedError()\n
Helper method to add tools and update agent state if needed
Source code in libs/kotaemon/kotaemon/agents/base.py
def add_tools(self, tools: list[BaseTool]) -> None:\n \"\"\"Helper method to add tools and update agent state if needed\"\"\"\n self.plugins.extend(tools)\n
Cost of the provided model name with provided token information
Source code in libs/kotaemon/kotaemon/agents/utils.py
def calculate_cost(model_name: str, prompt_token: int, completion_token: int) -> float:\n \"\"\"\n Calculate the cost of a prompt and completion.\n\n Returns:\n float: Cost of the provided model name with provided token information\n \"\"\"\n # TODO: to be implemented\n return 0.0\n
required Source code in libs/kotaemon/kotaemon/agents/io/base.py
@dataclass\nclass AgentAction:\n \"\"\"Agent's action to take.\n\n Args:\n tool: The tool to invoke.\n tool_input: The input to the tool.\n log: The log message.\n \"\"\"\n\n tool: str\n tool_input: Union[str, dict]\n log: str\n
required Source code in libs/kotaemon/kotaemon/agents/io/base.py
class AgentFinish(NamedTuple):\n \"\"\"Agent's return value when finishing execution.\n\n Args:\n return_values: The return values of the agent.\n log: The log message.\n \"\"\"\n\n return_values: dict\n log: str\n
required Source code in libs/kotaemon/kotaemon/agents/io/base.py
class AgentOutput(LLMInterface):\n \"\"\"Output from an agent.\n\n Args:\n text: The text output from the agent.\n agent_type: The type of agent.\n status: The status after executing the agent.\n error: The error message if any.\n \"\"\"\n\n model_config = ConfigDict(extra=\"allow\")\n\n text: str\n type: str = \"agent\"\n agent_type: AgentType\n status: Literal[\"thinking\", \"finished\", \"stopped\", \"failed\"]\n error: Optional[str] = None\n intermediate_steps: Optional[list] = None\n
str, optional The title of the panel, defaults to \"Output\".
'Output'stream
bool, optional
False Source code in libs/kotaemon/kotaemon/agents/io/base.py
def panel_print(self, item: Any, title: str = \"Output\", stream: bool = False):\n \"\"\"\n Log a panel output.\n\n Args:\n item : Any\n The item to log.\n title : str, optional\n The title of the panel, defaults to \"Output\".\n stream : bool, optional\n \"\"\"\n if not stream:\n self.log.append(item)\n if check_log():\n self.logger.info(\"-\" * 20)\n self.logger.info(item)\n self.logger.info(\"-\" * 20)\n
str, optional The title of the panel, defaults to \"Output\".
'Output'stream
bool, optional
False Source code in libs/kotaemon/kotaemon/agents/io/base.py
def panel_print(self, item: Any, title: str = \"Output\", stream: bool = False):\n \"\"\"\n Log a panel output.\n\n Args:\n item : Any\n The item to log.\n title : str, optional\n The title of the panel, defaults to \"Output\".\n stream : bool, optional\n \"\"\"\n if not stream:\n self.log.append(item)\n if check_log():\n self.logger.info(\"-\" * 20)\n self.logger.info(item)\n self.logger.info(\"-\" * 20)\n
required Source code in libs/kotaemon/kotaemon/agents/io/base.py
@dataclass\nclass AgentAction:\n \"\"\"Agent's action to take.\n\n Args:\n tool: The tool to invoke.\n tool_input: The input to the tool.\n log: The log message.\n \"\"\"\n\n tool: str\n tool_input: Union[str, dict]\n log: str\n
required Source code in libs/kotaemon/kotaemon/agents/io/base.py
class AgentFinish(NamedTuple):\n \"\"\"Agent's return value when finishing execution.\n\n Args:\n return_values: The return values of the agent.\n log: The log message.\n \"\"\"\n\n return_values: dict\n log: str\n
required Source code in libs/kotaemon/kotaemon/agents/io/base.py
class AgentOutput(LLMInterface):\n \"\"\"Output from an agent.\n\n Args:\n text: The text output from the agent.\n agent_type: The type of agent.\n status: The status after executing the agent.\n error: The error message if any.\n \"\"\"\n\n model_config = ConfigDict(extra=\"allow\")\n\n text: str\n type: str = \"agent\"\n agent_type: AgentType\n status: Literal[\"thinking\", \"finished\", \"stopped\", \"failed\"]\n error: Optional[str] = None\n intermediate_steps: Optional[list] = None\n
Checks if logging has been enabled. :return: True if logging has been enabled, False otherwise. :rtype: bool
Source code in libs/kotaemon/kotaemon/agents/io/base.py
def check_log():\n \"\"\"\n Checks if logging has been enabled.\n :return: True if logging has been enabled, False otherwise.\n :rtype: bool\n \"\"\"\n return os.environ.get(\"LOG_PATH\", None) is not None\n
Sequential ReactAgent class inherited from BaseAgent. Implementing ReAct agent paradigm https://arxiv.org/pdf/2210.03629.pdf
Source code in libs/kotaemon/kotaemon/agents/react/agent.py
class ReactAgent(BaseAgent):\n \"\"\"\n Sequential ReactAgent class inherited from BaseAgent.\n Implementing ReAct agent paradigm https://arxiv.org/pdf/2210.03629.pdf\n \"\"\"\n\n name: str = \"ReactAgent\"\n agent_type: AgentType = AgentType.react\n description: str = \"ReactAgent for answering multi-step reasoning questions\"\n llm: BaseLLM\n prompt_template: Optional[PromptTemplate] = None\n output_lang: str = \"English\"\n plugins: list[BaseTool] = Param(\n default_callback=lambda _: [], help=\"List of tools to be used in the agent. \"\n )\n examples: dict[str, str | list[str]] = Param(\n default_callback=lambda _: {}, help=\"Examples to be used in the agent. \"\n )\n intermediate_steps: list[tuple[AgentAction | AgentFinish, str]] = Param(\n default_callback=lambda _: [],\n help=\"List of AgentAction and observation (tool) output\",\n )\n max_iterations: int = 5\n strict_decode: bool = False\n max_context_length: int = Param(\n default=3000,\n help=\"Max context length for each tool output.\",\n )\n trim_func: TokenSplitter | None = None\n\n def _compose_plugin_description(self) -> str:\n \"\"\"\n Compose the worker prompt from the workers.\n\n Example:\n toolname1[input]: tool1 description\n toolname2[input]: tool2 description\n \"\"\"\n prompt = \"\"\n try:\n for plugin in self.plugins:\n prompt += f\"{plugin.name}[input]: {plugin.description}\\n\"\n except Exception:\n raise ValueError(\"Worker must have a name and description.\")\n return prompt\n\n def _construct_scratchpad(\n self, intermediate_steps: list[tuple[AgentAction | AgentFinish, str]] = []\n ) -> str:\n \"\"\"Construct the scratchpad that lets the agent continue its thought process.\"\"\"\n thoughts = \"\"\n for action, observation in intermediate_steps:\n thoughts += action.log\n thoughts += f\"\\nObservation: {observation}\\nThought:\"\n return thoughts\n\n def _parse_output(self, text: str) -> Optional[AgentAction | AgentFinish]:\n \"\"\"\n Parse text output from LLM for the next Action or Final Answer\n Using Regex to parse \"Action:\\n Action Input:\\n\" for the next Action\n Using FINAL_ANSWER_ACTION to parse Final Answer\n\n Args:\n text[str]: input text to parse\n \"\"\"\n includes_answer = FINAL_ANSWER_ACTION in text\n regex = (\n r\"Action\\s*\\d*\\s*:[\\s]*(.*?)[\\s]*Action\\s*\\d*\\s*Input\\s*\\d*\\s*:[\\s]*(.*)\"\n )\n action_match = re.search(regex, text, re.DOTALL)\n action_output: Optional[AgentAction | AgentFinish] = None\n if action_match:\n if includes_answer:\n raise Exception(\n \"Parsing LLM output produced both a final answer \"\n f\"and a parse-able action: {text}\"\n )\n action = action_match.group(1).strip()\n action_input = action_match.group(2)\n tool_input = action_input.strip(\" \")\n # ensure if its a well formed SQL query we don't remove any trailing \" chars\n if tool_input.startswith(\"SELECT \") is False:\n tool_input = tool_input.strip('\"')\n\n action_output = AgentAction(action, tool_input, text)\n\n elif includes_answer:\n action_output = AgentFinish(\n {\"output\": text.split(FINAL_ANSWER_ACTION)[-1].strip()}, text\n )\n else:\n if self.strict_decode:\n raise Exception(f\"Could not parse LLM output: `{text}`\")\n else:\n action_output = AgentFinish({\"output\": text}, text)\n\n return action_output\n\n def _compose_prompt(self, instruction) -> str:\n \"\"\"\n Compose the prompt from template, worker description, examples and instruction.\n \"\"\"\n agent_scratchpad = self._construct_scratchpad(self.intermediate_steps)\n tool_description = self._compose_plugin_description()\n tool_names = \", \".join([plugin.name for plugin in self.plugins])\n if self.prompt_template is None:\n from .prompt import zero_shot_react_prompt\n\n self.prompt_template = zero_shot_react_prompt\n return self.prompt_template.populate(\n instruction=instruction,\n agent_scratchpad=agent_scratchpad,\n tool_description=tool_description,\n tool_names=tool_names,\n lang=self.output_lang,\n )\n\n def _format_function_map(self) -> dict[str, BaseTool]:\n \"\"\"Format the function map for the open AI function API.\n\n Return:\n Dict[str, Callable]: The function map.\n \"\"\"\n # Map the function name to the real function object.\n function_map = {}\n for plugin in self.plugins:\n function_map[plugin.name] = plugin\n return function_map\n\n def _trim(self, text: str | Document) -> str:\n \"\"\"\n Trim the text to the maximum token length.\n \"\"\"\n evidence_trim_func = (\n self.trim_func\n if self.trim_func\n else TokenSplitter(\n chunk_size=self.max_context_length,\n chunk_overlap=0,\n separator=\" \",\n tokenizer=partial(\n tiktoken.encoding_for_model(\"gpt-3.5-turbo\").encode,\n allowed_special=set(),\n disallowed_special=\"all\",\n ),\n )\n )\n if isinstance(text, str):\n texts = evidence_trim_func([Document(text=text)])\n elif isinstance(text, Document):\n texts = evidence_trim_func([text])\n else:\n raise ValueError(\"Invalid text type to trim\")\n trim_text = texts[0].text\n logging.info(f\"len (trimmed): {len(trim_text)}\")\n return trim_text\n\n def clear(self):\n \"\"\"\n Clear and reset the agent.\n \"\"\"\n self.intermediate_steps = []\n\n def run(self, instruction, max_iterations=None) -> AgentOutput:\n \"\"\"\n Run the agent with the given instruction.\n\n Args:\n instruction: Instruction to run the agent with.\n max_iterations: Maximum number of iterations\n of reasoning steps, defaults to 10.\n\n Return:\n AgentOutput object.\n \"\"\"\n if not max_iterations:\n max_iterations = self.max_iterations\n assert max_iterations > 0\n\n self.clear()\n logging.info(f\"Running {self.name} with instruction: {instruction}\")\n total_cost = 0.0\n total_token = 0\n status = \"failed\"\n response_text = None\n\n for step_count in range(1, max_iterations + 1):\n prompt = self._compose_prompt(instruction)\n logging.info(f\"Prompt: {prompt}\")\n response = self.llm(\n prompt, stop=[\"Observation:\"]\n ) # could cause bugs if llm doesn't have `stop` as a parameter\n response_text = response.text\n logging.info(f\"Response: {response_text}\")\n action_step = self._parse_output(response_text)\n if action_step is None:\n raise ValueError(\"Invalid action\")\n is_finished_chain = isinstance(action_step, AgentFinish)\n if is_finished_chain:\n result = \"\"\n else:\n assert isinstance(action_step, AgentAction)\n action_name = action_step.tool\n tool_input = action_step.tool_input\n logging.info(f\"Action: {action_name}\")\n logging.info(f\"Tool Input: {tool_input}\")\n result = self._format_function_map()[action_name](tool_input)\n\n # trim the worker output to 1000 tokens, as we are appending\n # all workers' logs and it can exceed the token limit if we\n # don't limit each. Fix this number regarding to the LLM capacity.\n result = self._trim(result)\n logging.info(f\"Result: {result}\")\n\n self.intermediate_steps.append((action_step, result))\n if is_finished_chain:\n logging.info(f\"Finished after {step_count} steps.\")\n status = \"finished\"\n break\n else:\n status = \"stopped\"\n\n return AgentOutput(\n text=response_text,\n agent_type=self.agent_type,\n status=status,\n total_tokens=total_token,\n total_cost=total_cost,\n intermediate_steps=self.intermediate_steps,\n max_iterations=max_iterations,\n )\n\n def stream(self, instruction, max_iterations=None):\n \"\"\"\n Stream the agent with the given instruction.\n\n Args:\n instruction: Instruction to run the agent with.\n max_iterations: Maximum number of iterations\n of reasoning steps, defaults to 10.\n\n Return:\n AgentOutput object.\n \"\"\"\n if not max_iterations:\n max_iterations = self.max_iterations\n assert max_iterations > 0\n\n self.clear()\n logging.info(f\"Running {self.name} with instruction: {instruction}\")\n print(f\"Running {self.name} with instruction: {instruction}\")\n total_cost = 0.0\n total_token = 0\n status = \"failed\"\n response_text = None\n\n for step_count in range(1, max_iterations + 1):\n prompt = self._compose_prompt(instruction)\n logging.info(f\"Prompt: {prompt}\")\n print(f\"Prompt: {prompt}\")\n response = self.llm(\n prompt, stop=[\"Observation:\"]\n ) # TODO: could cause bugs if llm doesn't have `stop` as a parameter\n response_text = response.text\n logging.info(f\"Response: {response_text}\")\n print(f\"Response: {response_text}\")\n action_step = self._parse_output(response_text)\n if action_step is None:\n raise ValueError(\"Invalid action\")\n is_finished_chain = isinstance(action_step, AgentFinish)\n if is_finished_chain:\n result = response_text\n if \"Final Answer:\" in response_text:\n result = response_text.split(\"Final Answer:\")[-1].strip()\n else:\n assert isinstance(action_step, AgentAction)\n action_name = action_step.tool\n tool_input = action_step.tool_input\n logging.info(f\"Action: {action_name}\")\n print(f\"Action: {action_name}\")\n logging.info(f\"Tool Input: {tool_input}\")\n print(f\"Tool Input: {tool_input}\")\n result = self._format_function_map()[action_name](tool_input)\n\n # trim the worker output to 1000 tokens, as we are appending\n # all workers' logs and it can exceed the token limit if we\n # don't limit each. Fix this number regarding to the LLM capacity.\n result = self._trim(result)\n logging.info(f\"Result: {result}\")\n print(f\"Result: {result}\")\n\n self.intermediate_steps.append((action_step, result))\n if is_finished_chain:\n logging.info(f\"Finished after {step_count} steps.\")\n status = \"finished\"\n yield AgentOutput(\n text=result,\n agent_type=self.agent_type,\n status=status,\n intermediate_steps=self.intermediate_steps[-1],\n )\n break\n else:\n yield AgentOutput(\n text=\"\",\n agent_type=self.agent_type,\n status=\"thinking\",\n intermediate_steps=self.intermediate_steps[-1],\n )\n\n else:\n status = \"stopped\"\n yield AgentOutput(\n text=\"\",\n agent_type=self.agent_type,\n status=status,\n intermediate_steps=self.intermediate_steps[-1],\n )\n\n return AgentOutput(\n text=response_text,\n agent_type=self.agent_type,\n status=status,\n total_tokens=total_token,\n total_cost=total_cost,\n intermediate_steps=self.intermediate_steps,\n max_iterations=max_iterations,\n )\n
Maximum number of iterations of reasoning steps, defaults to 10.
None Return
AgentOutput object.
Source code in libs/kotaemon/kotaemon/agents/react/agent.py
def run(self, instruction, max_iterations=None) -> AgentOutput:\n \"\"\"\n Run the agent with the given instruction.\n\n Args:\n instruction: Instruction to run the agent with.\n max_iterations: Maximum number of iterations\n of reasoning steps, defaults to 10.\n\n Return:\n AgentOutput object.\n \"\"\"\n if not max_iterations:\n max_iterations = self.max_iterations\n assert max_iterations > 0\n\n self.clear()\n logging.info(f\"Running {self.name} with instruction: {instruction}\")\n total_cost = 0.0\n total_token = 0\n status = \"failed\"\n response_text = None\n\n for step_count in range(1, max_iterations + 1):\n prompt = self._compose_prompt(instruction)\n logging.info(f\"Prompt: {prompt}\")\n response = self.llm(\n prompt, stop=[\"Observation:\"]\n ) # could cause bugs if llm doesn't have `stop` as a parameter\n response_text = response.text\n logging.info(f\"Response: {response_text}\")\n action_step = self._parse_output(response_text)\n if action_step is None:\n raise ValueError(\"Invalid action\")\n is_finished_chain = isinstance(action_step, AgentFinish)\n if is_finished_chain:\n result = \"\"\n else:\n assert isinstance(action_step, AgentAction)\n action_name = action_step.tool\n tool_input = action_step.tool_input\n logging.info(f\"Action: {action_name}\")\n logging.info(f\"Tool Input: {tool_input}\")\n result = self._format_function_map()[action_name](tool_input)\n\n # trim the worker output to 1000 tokens, as we are appending\n # all workers' logs and it can exceed the token limit if we\n # don't limit each. Fix this number regarding to the LLM capacity.\n result = self._trim(result)\n logging.info(f\"Result: {result}\")\n\n self.intermediate_steps.append((action_step, result))\n if is_finished_chain:\n logging.info(f\"Finished after {step_count} steps.\")\n status = \"finished\"\n break\n else:\n status = \"stopped\"\n\n return AgentOutput(\n text=response_text,\n agent_type=self.agent_type,\n status=status,\n total_tokens=total_token,\n total_cost=total_cost,\n intermediate_steps=self.intermediate_steps,\n max_iterations=max_iterations,\n )\n
Maximum number of iterations of reasoning steps, defaults to 10.
None Return
AgentOutput object.
Source code in libs/kotaemon/kotaemon/agents/react/agent.py
def stream(self, instruction, max_iterations=None):\n \"\"\"\n Stream the agent with the given instruction.\n\n Args:\n instruction: Instruction to run the agent with.\n max_iterations: Maximum number of iterations\n of reasoning steps, defaults to 10.\n\n Return:\n AgentOutput object.\n \"\"\"\n if not max_iterations:\n max_iterations = self.max_iterations\n assert max_iterations > 0\n\n self.clear()\n logging.info(f\"Running {self.name} with instruction: {instruction}\")\n print(f\"Running {self.name} with instruction: {instruction}\")\n total_cost = 0.0\n total_token = 0\n status = \"failed\"\n response_text = None\n\n for step_count in range(1, max_iterations + 1):\n prompt = self._compose_prompt(instruction)\n logging.info(f\"Prompt: {prompt}\")\n print(f\"Prompt: {prompt}\")\n response = self.llm(\n prompt, stop=[\"Observation:\"]\n ) # TODO: could cause bugs if llm doesn't have `stop` as a parameter\n response_text = response.text\n logging.info(f\"Response: {response_text}\")\n print(f\"Response: {response_text}\")\n action_step = self._parse_output(response_text)\n if action_step is None:\n raise ValueError(\"Invalid action\")\n is_finished_chain = isinstance(action_step, AgentFinish)\n if is_finished_chain:\n result = response_text\n if \"Final Answer:\" in response_text:\n result = response_text.split(\"Final Answer:\")[-1].strip()\n else:\n assert isinstance(action_step, AgentAction)\n action_name = action_step.tool\n tool_input = action_step.tool_input\n logging.info(f\"Action: {action_name}\")\n print(f\"Action: {action_name}\")\n logging.info(f\"Tool Input: {tool_input}\")\n print(f\"Tool Input: {tool_input}\")\n result = self._format_function_map()[action_name](tool_input)\n\n # trim the worker output to 1000 tokens, as we are appending\n # all workers' logs and it can exceed the token limit if we\n # don't limit each. Fix this number regarding to the LLM capacity.\n result = self._trim(result)\n logging.info(f\"Result: {result}\")\n print(f\"Result: {result}\")\n\n self.intermediate_steps.append((action_step, result))\n if is_finished_chain:\n logging.info(f\"Finished after {step_count} steps.\")\n status = \"finished\"\n yield AgentOutput(\n text=result,\n agent_type=self.agent_type,\n status=status,\n intermediate_steps=self.intermediate_steps[-1],\n )\n break\n else:\n yield AgentOutput(\n text=\"\",\n agent_type=self.agent_type,\n status=\"thinking\",\n intermediate_steps=self.intermediate_steps[-1],\n )\n\n else:\n status = \"stopped\"\n yield AgentOutput(\n text=\"\",\n agent_type=self.agent_type,\n status=status,\n intermediate_steps=self.intermediate_steps[-1],\n )\n\n return AgentOutput(\n text=response_text,\n agent_type=self.agent_type,\n status=status,\n total_tokens=total_token,\n total_cost=total_cost,\n intermediate_steps=self.intermediate_steps,\n max_iterations=max_iterations,\n )\n
Sequential ReactAgent class inherited from BaseAgent. Implementing ReAct agent paradigm https://arxiv.org/pdf/2210.03629.pdf
Source code in libs/kotaemon/kotaemon/agents/react/agent.py
class ReactAgent(BaseAgent):\n \"\"\"\n Sequential ReactAgent class inherited from BaseAgent.\n Implementing ReAct agent paradigm https://arxiv.org/pdf/2210.03629.pdf\n \"\"\"\n\n name: str = \"ReactAgent\"\n agent_type: AgentType = AgentType.react\n description: str = \"ReactAgent for answering multi-step reasoning questions\"\n llm: BaseLLM\n prompt_template: Optional[PromptTemplate] = None\n output_lang: str = \"English\"\n plugins: list[BaseTool] = Param(\n default_callback=lambda _: [], help=\"List of tools to be used in the agent. \"\n )\n examples: dict[str, str | list[str]] = Param(\n default_callback=lambda _: {}, help=\"Examples to be used in the agent. \"\n )\n intermediate_steps: list[tuple[AgentAction | AgentFinish, str]] = Param(\n default_callback=lambda _: [],\n help=\"List of AgentAction and observation (tool) output\",\n )\n max_iterations: int = 5\n strict_decode: bool = False\n max_context_length: int = Param(\n default=3000,\n help=\"Max context length for each tool output.\",\n )\n trim_func: TokenSplitter | None = None\n\n def _compose_plugin_description(self) -> str:\n \"\"\"\n Compose the worker prompt from the workers.\n\n Example:\n toolname1[input]: tool1 description\n toolname2[input]: tool2 description\n \"\"\"\n prompt = \"\"\n try:\n for plugin in self.plugins:\n prompt += f\"{plugin.name}[input]: {plugin.description}\\n\"\n except Exception:\n raise ValueError(\"Worker must have a name and description.\")\n return prompt\n\n def _construct_scratchpad(\n self, intermediate_steps: list[tuple[AgentAction | AgentFinish, str]] = []\n ) -> str:\n \"\"\"Construct the scratchpad that lets the agent continue its thought process.\"\"\"\n thoughts = \"\"\n for action, observation in intermediate_steps:\n thoughts += action.log\n thoughts += f\"\\nObservation: {observation}\\nThought:\"\n return thoughts\n\n def _parse_output(self, text: str) -> Optional[AgentAction | AgentFinish]:\n \"\"\"\n Parse text output from LLM for the next Action or Final Answer\n Using Regex to parse \"Action:\\n Action Input:\\n\" for the next Action\n Using FINAL_ANSWER_ACTION to parse Final Answer\n\n Args:\n text[str]: input text to parse\n \"\"\"\n includes_answer = FINAL_ANSWER_ACTION in text\n regex = (\n r\"Action\\s*\\d*\\s*:[\\s]*(.*?)[\\s]*Action\\s*\\d*\\s*Input\\s*\\d*\\s*:[\\s]*(.*)\"\n )\n action_match = re.search(regex, text, re.DOTALL)\n action_output: Optional[AgentAction | AgentFinish] = None\n if action_match:\n if includes_answer:\n raise Exception(\n \"Parsing LLM output produced both a final answer \"\n f\"and a parse-able action: {text}\"\n )\n action = action_match.group(1).strip()\n action_input = action_match.group(2)\n tool_input = action_input.strip(\" \")\n # ensure if its a well formed SQL query we don't remove any trailing \" chars\n if tool_input.startswith(\"SELECT \") is False:\n tool_input = tool_input.strip('\"')\n\n action_output = AgentAction(action, tool_input, text)\n\n elif includes_answer:\n action_output = AgentFinish(\n {\"output\": text.split(FINAL_ANSWER_ACTION)[-1].strip()}, text\n )\n else:\n if self.strict_decode:\n raise Exception(f\"Could not parse LLM output: `{text}`\")\n else:\n action_output = AgentFinish({\"output\": text}, text)\n\n return action_output\n\n def _compose_prompt(self, instruction) -> str:\n \"\"\"\n Compose the prompt from template, worker description, examples and instruction.\n \"\"\"\n agent_scratchpad = self._construct_scratchpad(self.intermediate_steps)\n tool_description = self._compose_plugin_description()\n tool_names = \", \".join([plugin.name for plugin in self.plugins])\n if self.prompt_template is None:\n from .prompt import zero_shot_react_prompt\n\n self.prompt_template = zero_shot_react_prompt\n return self.prompt_template.populate(\n instruction=instruction,\n agent_scratchpad=agent_scratchpad,\n tool_description=tool_description,\n tool_names=tool_names,\n lang=self.output_lang,\n )\n\n def _format_function_map(self) -> dict[str, BaseTool]:\n \"\"\"Format the function map for the open AI function API.\n\n Return:\n Dict[str, Callable]: The function map.\n \"\"\"\n # Map the function name to the real function object.\n function_map = {}\n for plugin in self.plugins:\n function_map[plugin.name] = plugin\n return function_map\n\n def _trim(self, text: str | Document) -> str:\n \"\"\"\n Trim the text to the maximum token length.\n \"\"\"\n evidence_trim_func = (\n self.trim_func\n if self.trim_func\n else TokenSplitter(\n chunk_size=self.max_context_length,\n chunk_overlap=0,\n separator=\" \",\n tokenizer=partial(\n tiktoken.encoding_for_model(\"gpt-3.5-turbo\").encode,\n allowed_special=set(),\n disallowed_special=\"all\",\n ),\n )\n )\n if isinstance(text, str):\n texts = evidence_trim_func([Document(text=text)])\n elif isinstance(text, Document):\n texts = evidence_trim_func([text])\n else:\n raise ValueError(\"Invalid text type to trim\")\n trim_text = texts[0].text\n logging.info(f\"len (trimmed): {len(trim_text)}\")\n return trim_text\n\n def clear(self):\n \"\"\"\n Clear and reset the agent.\n \"\"\"\n self.intermediate_steps = []\n\n def run(self, instruction, max_iterations=None) -> AgentOutput:\n \"\"\"\n Run the agent with the given instruction.\n\n Args:\n instruction: Instruction to run the agent with.\n max_iterations: Maximum number of iterations\n of reasoning steps, defaults to 10.\n\n Return:\n AgentOutput object.\n \"\"\"\n if not max_iterations:\n max_iterations = self.max_iterations\n assert max_iterations > 0\n\n self.clear()\n logging.info(f\"Running {self.name} with instruction: {instruction}\")\n total_cost = 0.0\n total_token = 0\n status = \"failed\"\n response_text = None\n\n for step_count in range(1, max_iterations + 1):\n prompt = self._compose_prompt(instruction)\n logging.info(f\"Prompt: {prompt}\")\n response = self.llm(\n prompt, stop=[\"Observation:\"]\n ) # could cause bugs if llm doesn't have `stop` as a parameter\n response_text = response.text\n logging.info(f\"Response: {response_text}\")\n action_step = self._parse_output(response_text)\n if action_step is None:\n raise ValueError(\"Invalid action\")\n is_finished_chain = isinstance(action_step, AgentFinish)\n if is_finished_chain:\n result = \"\"\n else:\n assert isinstance(action_step, AgentAction)\n action_name = action_step.tool\n tool_input = action_step.tool_input\n logging.info(f\"Action: {action_name}\")\n logging.info(f\"Tool Input: {tool_input}\")\n result = self._format_function_map()[action_name](tool_input)\n\n # trim the worker output to 1000 tokens, as we are appending\n # all workers' logs and it can exceed the token limit if we\n # don't limit each. Fix this number regarding to the LLM capacity.\n result = self._trim(result)\n logging.info(f\"Result: {result}\")\n\n self.intermediate_steps.append((action_step, result))\n if is_finished_chain:\n logging.info(f\"Finished after {step_count} steps.\")\n status = \"finished\"\n break\n else:\n status = \"stopped\"\n\n return AgentOutput(\n text=response_text,\n agent_type=self.agent_type,\n status=status,\n total_tokens=total_token,\n total_cost=total_cost,\n intermediate_steps=self.intermediate_steps,\n max_iterations=max_iterations,\n )\n\n def stream(self, instruction, max_iterations=None):\n \"\"\"\n Stream the agent with the given instruction.\n\n Args:\n instruction: Instruction to run the agent with.\n max_iterations: Maximum number of iterations\n of reasoning steps, defaults to 10.\n\n Return:\n AgentOutput object.\n \"\"\"\n if not max_iterations:\n max_iterations = self.max_iterations\n assert max_iterations > 0\n\n self.clear()\n logging.info(f\"Running {self.name} with instruction: {instruction}\")\n print(f\"Running {self.name} with instruction: {instruction}\")\n total_cost = 0.0\n total_token = 0\n status = \"failed\"\n response_text = None\n\n for step_count in range(1, max_iterations + 1):\n prompt = self._compose_prompt(instruction)\n logging.info(f\"Prompt: {prompt}\")\n print(f\"Prompt: {prompt}\")\n response = self.llm(\n prompt, stop=[\"Observation:\"]\n ) # TODO: could cause bugs if llm doesn't have `stop` as a parameter\n response_text = response.text\n logging.info(f\"Response: {response_text}\")\n print(f\"Response: {response_text}\")\n action_step = self._parse_output(response_text)\n if action_step is None:\n raise ValueError(\"Invalid action\")\n is_finished_chain = isinstance(action_step, AgentFinish)\n if is_finished_chain:\n result = response_text\n if \"Final Answer:\" in response_text:\n result = response_text.split(\"Final Answer:\")[-1].strip()\n else:\n assert isinstance(action_step, AgentAction)\n action_name = action_step.tool\n tool_input = action_step.tool_input\n logging.info(f\"Action: {action_name}\")\n print(f\"Action: {action_name}\")\n logging.info(f\"Tool Input: {tool_input}\")\n print(f\"Tool Input: {tool_input}\")\n result = self._format_function_map()[action_name](tool_input)\n\n # trim the worker output to 1000 tokens, as we are appending\n # all workers' logs and it can exceed the token limit if we\n # don't limit each. Fix this number regarding to the LLM capacity.\n result = self._trim(result)\n logging.info(f\"Result: {result}\")\n print(f\"Result: {result}\")\n\n self.intermediate_steps.append((action_step, result))\n if is_finished_chain:\n logging.info(f\"Finished after {step_count} steps.\")\n status = \"finished\"\n yield AgentOutput(\n text=result,\n agent_type=self.agent_type,\n status=status,\n intermediate_steps=self.intermediate_steps[-1],\n )\n break\n else:\n yield AgentOutput(\n text=\"\",\n agent_type=self.agent_type,\n status=\"thinking\",\n intermediate_steps=self.intermediate_steps[-1],\n )\n\n else:\n status = \"stopped\"\n yield AgentOutput(\n text=\"\",\n agent_type=self.agent_type,\n status=status,\n intermediate_steps=self.intermediate_steps[-1],\n )\n\n return AgentOutput(\n text=response_text,\n agent_type=self.agent_type,\n status=status,\n total_tokens=total_token,\n total_cost=total_cost,\n intermediate_steps=self.intermediate_steps,\n max_iterations=max_iterations,\n )\n
Maximum number of iterations of reasoning steps, defaults to 10.
None Return
AgentOutput object.
Source code in libs/kotaemon/kotaemon/agents/react/agent.py
def run(self, instruction, max_iterations=None) -> AgentOutput:\n \"\"\"\n Run the agent with the given instruction.\n\n Args:\n instruction: Instruction to run the agent with.\n max_iterations: Maximum number of iterations\n of reasoning steps, defaults to 10.\n\n Return:\n AgentOutput object.\n \"\"\"\n if not max_iterations:\n max_iterations = self.max_iterations\n assert max_iterations > 0\n\n self.clear()\n logging.info(f\"Running {self.name} with instruction: {instruction}\")\n total_cost = 0.0\n total_token = 0\n status = \"failed\"\n response_text = None\n\n for step_count in range(1, max_iterations + 1):\n prompt = self._compose_prompt(instruction)\n logging.info(f\"Prompt: {prompt}\")\n response = self.llm(\n prompt, stop=[\"Observation:\"]\n ) # could cause bugs if llm doesn't have `stop` as a parameter\n response_text = response.text\n logging.info(f\"Response: {response_text}\")\n action_step = self._parse_output(response_text)\n if action_step is None:\n raise ValueError(\"Invalid action\")\n is_finished_chain = isinstance(action_step, AgentFinish)\n if is_finished_chain:\n result = \"\"\n else:\n assert isinstance(action_step, AgentAction)\n action_name = action_step.tool\n tool_input = action_step.tool_input\n logging.info(f\"Action: {action_name}\")\n logging.info(f\"Tool Input: {tool_input}\")\n result = self._format_function_map()[action_name](tool_input)\n\n # trim the worker output to 1000 tokens, as we are appending\n # all workers' logs and it can exceed the token limit if we\n # don't limit each. Fix this number regarding to the LLM capacity.\n result = self._trim(result)\n logging.info(f\"Result: {result}\")\n\n self.intermediate_steps.append((action_step, result))\n if is_finished_chain:\n logging.info(f\"Finished after {step_count} steps.\")\n status = \"finished\"\n break\n else:\n status = \"stopped\"\n\n return AgentOutput(\n text=response_text,\n agent_type=self.agent_type,\n status=status,\n total_tokens=total_token,\n total_cost=total_cost,\n intermediate_steps=self.intermediate_steps,\n max_iterations=max_iterations,\n )\n
Maximum number of iterations of reasoning steps, defaults to 10.
None Return
AgentOutput object.
Source code in libs/kotaemon/kotaemon/agents/react/agent.py
def stream(self, instruction, max_iterations=None):\n \"\"\"\n Stream the agent with the given instruction.\n\n Args:\n instruction: Instruction to run the agent with.\n max_iterations: Maximum number of iterations\n of reasoning steps, defaults to 10.\n\n Return:\n AgentOutput object.\n \"\"\"\n if not max_iterations:\n max_iterations = self.max_iterations\n assert max_iterations > 0\n\n self.clear()\n logging.info(f\"Running {self.name} with instruction: {instruction}\")\n print(f\"Running {self.name} with instruction: {instruction}\")\n total_cost = 0.0\n total_token = 0\n status = \"failed\"\n response_text = None\n\n for step_count in range(1, max_iterations + 1):\n prompt = self._compose_prompt(instruction)\n logging.info(f\"Prompt: {prompt}\")\n print(f\"Prompt: {prompt}\")\n response = self.llm(\n prompt, stop=[\"Observation:\"]\n ) # TODO: could cause bugs if llm doesn't have `stop` as a parameter\n response_text = response.text\n logging.info(f\"Response: {response_text}\")\n print(f\"Response: {response_text}\")\n action_step = self._parse_output(response_text)\n if action_step is None:\n raise ValueError(\"Invalid action\")\n is_finished_chain = isinstance(action_step, AgentFinish)\n if is_finished_chain:\n result = response_text\n if \"Final Answer:\" in response_text:\n result = response_text.split(\"Final Answer:\")[-1].strip()\n else:\n assert isinstance(action_step, AgentAction)\n action_name = action_step.tool\n tool_input = action_step.tool_input\n logging.info(f\"Action: {action_name}\")\n print(f\"Action: {action_name}\")\n logging.info(f\"Tool Input: {tool_input}\")\n print(f\"Tool Input: {tool_input}\")\n result = self._format_function_map()[action_name](tool_input)\n\n # trim the worker output to 1000 tokens, as we are appending\n # all workers' logs and it can exceed the token limit if we\n # don't limit each. Fix this number regarding to the LLM capacity.\n result = self._trim(result)\n logging.info(f\"Result: {result}\")\n print(f\"Result: {result}\")\n\n self.intermediate_steps.append((action_step, result))\n if is_finished_chain:\n logging.info(f\"Finished after {step_count} steps.\")\n status = \"finished\"\n yield AgentOutput(\n text=result,\n agent_type=self.agent_type,\n status=status,\n intermediate_steps=self.intermediate_steps[-1],\n )\n break\n else:\n yield AgentOutput(\n text=\"\",\n agent_type=self.agent_type,\n status=\"thinking\",\n intermediate_steps=self.intermediate_steps[-1],\n )\n\n else:\n status = \"stopped\"\n yield AgentOutput(\n text=\"\",\n agent_type=self.agent_type,\n status=status,\n intermediate_steps=self.intermediate_steps[-1],\n )\n\n return AgentOutput(\n text=response_text,\n agent_type=self.agent_type,\n status=status,\n total_tokens=total_token,\n total_cost=total_cost,\n intermediate_steps=self.intermediate_steps,\n max_iterations=max_iterations,\n )\n
Source code in libs/kotaemon/kotaemon/agents/tools/base.py
class BaseTool(BaseComponent):\n name: str\n \"\"\"The unique name of the tool that clearly communicates its purpose.\"\"\"\n description: str\n \"\"\"Description used to tell the model how/when/why to use the tool.\n You can provide few-shot examples as a part of the description. This will be\n input to the prompt of LLM.\n \"\"\"\n args_schema: Optional[Type[BaseModel]] = None\n \"\"\"Pydantic model class to validate and parse the tool's input arguments.\"\"\"\n verbose: bool = False\n \"\"\"Whether to log the tool's progress.\"\"\"\n handle_tool_error: Optional[\n Union[bool, str, Callable[[ToolException], str]]\n ] = False\n \"\"\"Handle the content of the ToolException thrown.\"\"\"\n\n def _parse_input(\n self,\n tool_input: Union[str, Dict],\n ) -> Union[str, Dict[str, Any]]:\n \"\"\"Convert tool input to pydantic model.\"\"\"\n args_schema = self.args_schema\n if isinstance(tool_input, str):\n if args_schema is not None:\n key_ = next(iter(args_schema.model_fields.keys()))\n args_schema.validate({key_: tool_input})\n return tool_input\n else:\n if args_schema is not None:\n result = args_schema.parse_obj(tool_input)\n return {k: v for k, v in result.dict().items() if k in tool_input}\n return tool_input\n\n def _run_tool(\n self,\n *args: Any,\n **kwargs: Any,\n ) -> Any:\n \"\"\"Call tool.\"\"\"\n raise NotImplementedError(f\"_run_tool is not implemented for {self.name}\")\n\n def _to_args_and_kwargs(self, tool_input: Union[str, Dict]) -> Tuple[Tuple, Dict]:\n # For backwards compatibility, if run_input is a string,\n # pass as a positional argument.\n if isinstance(tool_input, str):\n return (tool_input,), {}\n else:\n return (), tool_input\n\n def _handle_tool_error(self, e: ToolException) -> Any:\n \"\"\"Handle the content of the ToolException thrown.\"\"\"\n observation = None\n if not self.handle_tool_error:\n raise e\n elif isinstance(self.handle_tool_error, bool):\n if e.args:\n observation = e.args[0]\n else:\n observation = \"Tool execution error\"\n elif isinstance(self.handle_tool_error, str):\n observation = self.handle_tool_error\n elif callable(self.handle_tool_error):\n observation = self.handle_tool_error(e)\n else:\n raise ValueError(\n f\"Got unexpected type of `handle_tool_error`. Expected bool, str \"\n f\"or callable. Received: {self.handle_tool_error}\"\n )\n return observation\n\n def to_langchain_format(self) -> LCTool:\n \"\"\"Convert this tool to Langchain format to use with its agent\"\"\"\n return LCTool(name=self.name, description=self.description, func=self.run)\n\n def run(\n self,\n tool_input: Union[str, Dict],\n verbose: Optional[bool] = None,\n **kwargs: Any,\n ) -> Any:\n \"\"\"Run the tool.\"\"\"\n parsed_input = self._parse_input(tool_input)\n # TODO (verbose_): Add logging\n try:\n tool_args, tool_kwargs = self._to_args_and_kwargs(parsed_input)\n call_kwargs = {**kwargs, **tool_kwargs}\n observation = self._run_tool(*tool_args, **call_kwargs)\n except ToolException as e:\n observation = self._handle_tool_error(e)\n return observation\n else:\n return observation\n\n @classmethod\n def from_langchain_format(cls, langchain_tool: LCTool) -> \"BaseTool\":\n \"\"\"Wrapper for Langchain Tool\"\"\"\n new_tool = BaseTool(\n name=langchain_tool.name, description=langchain_tool.description\n )\n new_tool._run_tool = langchain_tool._run # type: ignore\n return new_tool\n
Description used to tell the model how/when/why to use the tool. You can provide few-shot examples as a part of the description. This will be input to the prompt of LLM.
Convert this tool to Langchain format to use with its agent
Source code in libs/kotaemon/kotaemon/agents/tools/base.py
def to_langchain_format(self) -> LCTool:\n \"\"\"Convert this tool to Langchain format to use with its agent\"\"\"\n return LCTool(name=self.name, description=self.description, func=self.run)\n
Wrapper around other BaseComponent to use it as a tool
Parameters:
Name Type Description Default component
BaseComponent-based component to wrap
required postprocessor
Optional postprocessor for the component output
required Source code in libs/kotaemon/kotaemon/agents/tools/base.py
class ComponentTool(BaseTool):\n \"\"\"Wrapper around other BaseComponent to use it as a tool\n\n Args:\n component: BaseComponent-based component to wrap\n postprocessor: Optional postprocessor for the component output\n \"\"\"\n\n component: BaseComponent\n postprocessor: Optional[Callable] = None\n\n def _run_tool(self, *args: Any, **kwargs: Any) -> Any:\n output = self.component(*args, **kwargs)\n if self.postprocessor:\n output = self.postprocessor(output)\n\n return output\n
Tool that adds the capability to query the Wikipedia API.
Source code in libs/kotaemon/kotaemon/agents/tools/wikipedia.py
class WikipediaTool(BaseTool):\n \"\"\"Tool that adds the capability to query the Wikipedia API.\"\"\"\n\n name: str = \"wikipedia\"\n description: str = (\n \"Search engine from Wikipedia, retrieving relevant wiki page. \"\n \"Useful when you need to get holistic knowledge about people, \"\n \"places, companies, historical events, or other subjects. \"\n \"Input should be a search query.\"\n )\n args_schema: Optional[Type[BaseModel]] = WikipediaArgs\n doc_store: Any = None\n\n def _run_tool(self, query: AnyStr) -> AnyStr:\n if not self.doc_store:\n self.doc_store = Wiki()\n tool = self.doc_store\n evidence = tool.search(query)\n return evidence\n
An optional exception that tool throws when execution error occurs.
When this exception is thrown, the agent will not stop working, but will handle the exception according to the handle_tool_error variable of the tool, and the processing result will be returned to the agent as observation, and printed in red on the console.
Source code in libs/kotaemon/kotaemon/agents/tools/base.py
class ToolException(Exception):\n \"\"\"An optional exception that tool throws when execution error occurs.\n\n When this exception is thrown, the agent will not stop working,\n but will handle the exception according to the handle_tool_error\n variable of the tool, and the processing result will be returned\n to the agent as observation, and printed in red on the console.\n \"\"\"\n
Source code in libs/kotaemon/kotaemon/agents/tools/base.py
class BaseTool(BaseComponent):\n name: str\n \"\"\"The unique name of the tool that clearly communicates its purpose.\"\"\"\n description: str\n \"\"\"Description used to tell the model how/when/why to use the tool.\n You can provide few-shot examples as a part of the description. This will be\n input to the prompt of LLM.\n \"\"\"\n args_schema: Optional[Type[BaseModel]] = None\n \"\"\"Pydantic model class to validate and parse the tool's input arguments.\"\"\"\n verbose: bool = False\n \"\"\"Whether to log the tool's progress.\"\"\"\n handle_tool_error: Optional[\n Union[bool, str, Callable[[ToolException], str]]\n ] = False\n \"\"\"Handle the content of the ToolException thrown.\"\"\"\n\n def _parse_input(\n self,\n tool_input: Union[str, Dict],\n ) -> Union[str, Dict[str, Any]]:\n \"\"\"Convert tool input to pydantic model.\"\"\"\n args_schema = self.args_schema\n if isinstance(tool_input, str):\n if args_schema is not None:\n key_ = next(iter(args_schema.model_fields.keys()))\n args_schema.validate({key_: tool_input})\n return tool_input\n else:\n if args_schema is not None:\n result = args_schema.parse_obj(tool_input)\n return {k: v for k, v in result.dict().items() if k in tool_input}\n return tool_input\n\n def _run_tool(\n self,\n *args: Any,\n **kwargs: Any,\n ) -> Any:\n \"\"\"Call tool.\"\"\"\n raise NotImplementedError(f\"_run_tool is not implemented for {self.name}\")\n\n def _to_args_and_kwargs(self, tool_input: Union[str, Dict]) -> Tuple[Tuple, Dict]:\n # For backwards compatibility, if run_input is a string,\n # pass as a positional argument.\n if isinstance(tool_input, str):\n return (tool_input,), {}\n else:\n return (), tool_input\n\n def _handle_tool_error(self, e: ToolException) -> Any:\n \"\"\"Handle the content of the ToolException thrown.\"\"\"\n observation = None\n if not self.handle_tool_error:\n raise e\n elif isinstance(self.handle_tool_error, bool):\n if e.args:\n observation = e.args[0]\n else:\n observation = \"Tool execution error\"\n elif isinstance(self.handle_tool_error, str):\n observation = self.handle_tool_error\n elif callable(self.handle_tool_error):\n observation = self.handle_tool_error(e)\n else:\n raise ValueError(\n f\"Got unexpected type of `handle_tool_error`. Expected bool, str \"\n f\"or callable. Received: {self.handle_tool_error}\"\n )\n return observation\n\n def to_langchain_format(self) -> LCTool:\n \"\"\"Convert this tool to Langchain format to use with its agent\"\"\"\n return LCTool(name=self.name, description=self.description, func=self.run)\n\n def run(\n self,\n tool_input: Union[str, Dict],\n verbose: Optional[bool] = None,\n **kwargs: Any,\n ) -> Any:\n \"\"\"Run the tool.\"\"\"\n parsed_input = self._parse_input(tool_input)\n # TODO (verbose_): Add logging\n try:\n tool_args, tool_kwargs = self._to_args_and_kwargs(parsed_input)\n call_kwargs = {**kwargs, **tool_kwargs}\n observation = self._run_tool(*tool_args, **call_kwargs)\n except ToolException as e:\n observation = self._handle_tool_error(e)\n return observation\n else:\n return observation\n\n @classmethod\n def from_langchain_format(cls, langchain_tool: LCTool) -> \"BaseTool\":\n \"\"\"Wrapper for Langchain Tool\"\"\"\n new_tool = BaseTool(\n name=langchain_tool.name, description=langchain_tool.description\n )\n new_tool._run_tool = langchain_tool._run # type: ignore\n return new_tool\n
Description used to tell the model how/when/why to use the tool. You can provide few-shot examples as a part of the description. This will be input to the prompt of LLM.
Convert this tool to Langchain format to use with its agent
Source code in libs/kotaemon/kotaemon/agents/tools/base.py
def to_langchain_format(self) -> LCTool:\n \"\"\"Convert this tool to Langchain format to use with its agent\"\"\"\n return LCTool(name=self.name, description=self.description, func=self.run)\n
Wrapper around other BaseComponent to use it as a tool
Parameters:
Name Type Description Default component
BaseComponent-based component to wrap
required postprocessor
Optional postprocessor for the component output
required Source code in libs/kotaemon/kotaemon/agents/tools/base.py
class ComponentTool(BaseTool):\n \"\"\"Wrapper around other BaseComponent to use it as a tool\n\n Args:\n component: BaseComponent-based component to wrap\n postprocessor: Optional postprocessor for the component output\n \"\"\"\n\n component: BaseComponent\n postprocessor: Optional[Callable] = None\n\n def _run_tool(self, *args: Any, **kwargs: Any) -> Any:\n output = self.component(*args, **kwargs)\n if self.postprocessor:\n output = self.postprocessor(output)\n\n return output\n
Source code in libs/kotaemon/kotaemon/agents/tools/wikipedia.py
class Wiki:\n \"\"\"Wrapper around wikipedia API.\"\"\"\n\n def __init__(self) -> None:\n \"\"\"Check that wikipedia package is installed.\"\"\"\n try:\n import wikipedia # noqa: F401\n except ImportError:\n raise ValueError(\n \"Could not import wikipedia python package. \"\n \"Please install it with `pip install wikipedia`.\"\n )\n\n def search(self, search: str) -> Union[str, Document]:\n \"\"\"Try to search for wiki page.\n\n If page exists, return the page summary, and a PageWithLookups object.\n If page does not exist, return similar entries.\n \"\"\"\n import wikipedia\n\n try:\n page_content = wikipedia.page(search).content\n url = wikipedia.page(search).url\n result: Union[str, Document] = Document(\n text=page_content, metadata={\"page\": url}\n )\n except wikipedia.PageError:\n result = f\"Could not find [{search}]. Similar: {wikipedia.search(search)}\"\n except wikipedia.DisambiguationError:\n result = f\"Could not find [{search}]. Similar: {wikipedia.search(search)}\"\n return result\n
If page exists, return the page summary, and a PageWithLookups object. If page does not exist, return similar entries.
Source code in libs/kotaemon/kotaemon/agents/tools/wikipedia.py
def search(self, search: str) -> Union[str, Document]:\n \"\"\"Try to search for wiki page.\n\n If page exists, return the page summary, and a PageWithLookups object.\n If page does not exist, return similar entries.\n \"\"\"\n import wikipedia\n\n try:\n page_content = wikipedia.page(search).content\n url = wikipedia.page(search).url\n result: Union[str, Document] = Document(\n text=page_content, metadata={\"page\": url}\n )\n except wikipedia.PageError:\n result = f\"Could not find [{search}]. Similar: {wikipedia.search(search)}\"\n except wikipedia.DisambiguationError:\n result = f\"Could not find [{search}]. Similar: {wikipedia.search(search)}\"\n return result\n
Tool that adds the capability to query the Wikipedia API.
Source code in libs/kotaemon/kotaemon/agents/tools/wikipedia.py
class WikipediaTool(BaseTool):\n \"\"\"Tool that adds the capability to query the Wikipedia API.\"\"\"\n\n name: str = \"wikipedia\"\n description: str = (\n \"Search engine from Wikipedia, retrieving relevant wiki page. \"\n \"Useful when you need to get holistic knowledge about people, \"\n \"places, companies, historical events, or other subjects. \"\n \"Input should be a search query.\"\n )\n args_schema: Optional[Type[BaseModel]] = WikipediaArgs\n doc_store: Any = None\n\n def _run_tool(self, query: AnyStr) -> AnyStr:\n if not self.doc_store:\n self.doc_store = Wiki()\n tool = self.doc_store\n evidence = tool.search(query)\n return evidence\n
A component is a class that can be used to compose a pipeline.
Benefits of component
Auto caching, logging
Allow deployment
For each component, the spirit is
Tolerate multiple input types, e.g. str, Document, List[str], List[Document]
Enforce single output type. Hence, the output type of a component should be
as generic as possible.
Source code in libs/kotaemon/kotaemon/base/component.py
class BaseComponent(Function):\n \"\"\"A component is a class that can be used to compose a pipeline.\n\n !!! tip \"Benefits of component\"\n - Auto caching, logging\n - Allow deployment\n\n !!! tip \"For each component, the spirit is\"\n - Tolerate multiple input types, e.g. str, Document, List[str], List[Document]\n - Enforce single output type. Hence, the output type of a component should be\n as generic as possible.\n \"\"\"\n\n inflow = None\n\n def flow(self):\n if self.inflow is None:\n raise ValueError(\"No inflow provided.\")\n\n if not isinstance(self.inflow, BaseComponent):\n raise ValueError(\n f\"inflow must be a BaseComponent, found {type(self.inflow)}\"\n )\n\n return self.__call__(self.inflow.flow())\n\n def set_output_queue(self, queue):\n self._queue = queue\n for name in self._ff_nodes:\n node = getattr(self, name)\n if isinstance(node, BaseComponent):\n node.set_output_queue(queue)\n\n def report_output(self, output: Optional[Document]):\n if self._queue is not None:\n self._queue.put_nowait(output)\n\n def invoke(self, *args, **kwargs) -> Document | list[Document] | None:\n ...\n\n async def ainvoke(self, *args, **kwargs) -> Document | list[Document] | None:\n ...\n\n def stream(self, *args, **kwargs) -> Iterator[Document] | None:\n ...\n\n def astream(self, *args, **kwargs) -> AsyncGenerator[Document, None] | None:\n ...\n\n @abstractmethod\n def run(\n self, *args, **kwargs\n ) -> Document | list[Document] | Iterator[Document] | None | Any:\n \"\"\"Run the component.\"\"\"\n ...\n
Base document class, mostly inherited from Document class from llama-index.
This class accept one positional argument content of an arbitrary type, which will store the raw content of the document. If specified, the class will use content to initialize the base llama_index class.
the channel to show the document. Optional.: - chat: show in chat message - info: show in information panel - index: show in index panel - debug: show in debug panel
Source code in libs/kotaemon/kotaemon/base/schema.py
class Document(BaseDocument):\n \"\"\"\n Base document class, mostly inherited from Document class from llama-index.\n\n This class accept one positional argument `content` of an arbitrary type, which will\n store the raw content of the document. If specified, the class will use\n `content` to initialize the base llama_index class.\n\n Attributes:\n content: raw content of the document, can be anything\n source: id of the source of the Document. Optional.\n channel: the channel to show the document. Optional.:\n - chat: show in chat message\n - info: show in information panel\n - index: show in index panel\n - debug: show in debug panel\n \"\"\"\n\n content: Any = None\n source: Optional[str] = None\n channel: Optional[Literal[\"chat\", \"info\", \"index\", \"debug\", \"plot\"]] = None\n\n def __init__(self, content: Optional[Any] = None, *args, **kwargs):\n if content is None:\n if kwargs.get(\"text\", None) is not None:\n kwargs[\"content\"] = kwargs[\"text\"]\n elif kwargs.get(\"embedding\", None) is not None:\n kwargs[\"content\"] = kwargs[\"embedding\"]\n # default text indicating this document only contains embedding\n kwargs[\"text\"] = \"<EMBEDDING>\"\n elif isinstance(content, Document):\n # TODO: simplify the Document class\n temp_ = content.dict()\n temp_.update(kwargs)\n kwargs = temp_\n else:\n kwargs[\"content\"] = content\n if content:\n kwargs[\"text\"] = str(content)\n else:\n kwargs[\"text\"] = \"\"\n super().__init__(*args, **kwargs)\n\n def __bool__(self):\n return bool(self.content)\n\n @classmethod\n def example(cls) -> \"Document\":\n document = Document(\n text=SAMPLE_TEXT,\n metadata={\"filename\": \"README.md\", \"category\": \"codebase\"},\n )\n return document\n\n def to_haystack_format(self) -> \"HaystackDocument\":\n \"\"\"Convert struct to Haystack document format.\"\"\"\n from haystack.schema import Document as HaystackDocument\n\n metadata = self.metadata or {}\n text = self.text\n return HaystackDocument(content=text, meta=metadata)\n\n def __str__(self):\n return str(self.content)\n
Subclass of Document which must contains embedding
Use this if you want to enforce component's IOs to must contain embedding.
Source code in libs/kotaemon/kotaemon/base/schema.py
class DocumentWithEmbedding(Document):\n \"\"\"Subclass of Document which must contains embedding\n\n Use this if you want to enforce component's IOs to must contain embedding.\n \"\"\"\n\n def __init__(self, embedding: list[float], *args, **kwargs):\n kwargs[\"embedding\"] = embedding\n super().__init__(*args, **kwargs)\n
Subclass of Document with retrieval-related information
Attributes:
Name Type Description scorefloat
score of the document (from 0.0 to 1.0)
retrieval_metadatadict
metadata from the retrieval process, can be used by different components in a retrieved pipeline to communicate with each other
Source code in libs/kotaemon/kotaemon/base/schema.py
class RetrievedDocument(Document):\n \"\"\"Subclass of Document with retrieval-related information\n\n Attributes:\n score (float): score of the document (from 0.0 to 1.0)\n retrieval_metadata (dict): metadata from the retrieval process, can be used\n by different components in a retrieved pipeline to communicate with each\n other\n \"\"\"\n\n score: float = Field(default=0.0)\n retrieval_metadata: dict = Field(default={})\n
A component is a class that can be used to compose a pipeline.
Benefits of component
Auto caching, logging
Allow deployment
For each component, the spirit is
Tolerate multiple input types, e.g. str, Document, List[str], List[Document]
Enforce single output type. Hence, the output type of a component should be
as generic as possible.
Source code in libs/kotaemon/kotaemon/base/component.py
class BaseComponent(Function):\n \"\"\"A component is a class that can be used to compose a pipeline.\n\n !!! tip \"Benefits of component\"\n - Auto caching, logging\n - Allow deployment\n\n !!! tip \"For each component, the spirit is\"\n - Tolerate multiple input types, e.g. str, Document, List[str], List[Document]\n - Enforce single output type. Hence, the output type of a component should be\n as generic as possible.\n \"\"\"\n\n inflow = None\n\n def flow(self):\n if self.inflow is None:\n raise ValueError(\"No inflow provided.\")\n\n if not isinstance(self.inflow, BaseComponent):\n raise ValueError(\n f\"inflow must be a BaseComponent, found {type(self.inflow)}\"\n )\n\n return self.__call__(self.inflow.flow())\n\n def set_output_queue(self, queue):\n self._queue = queue\n for name in self._ff_nodes:\n node = getattr(self, name)\n if isinstance(node, BaseComponent):\n node.set_output_queue(queue)\n\n def report_output(self, output: Optional[Document]):\n if self._queue is not None:\n self._queue.put_nowait(output)\n\n def invoke(self, *args, **kwargs) -> Document | list[Document] | None:\n ...\n\n async def ainvoke(self, *args, **kwargs) -> Document | list[Document] | None:\n ...\n\n def stream(self, *args, **kwargs) -> Iterator[Document] | None:\n ...\n\n def astream(self, *args, **kwargs) -> AsyncGenerator[Document, None] | None:\n ...\n\n @abstractmethod\n def run(\n self, *args, **kwargs\n ) -> Document | list[Document] | Iterator[Document] | None | Any:\n \"\"\"Run the component.\"\"\"\n ...\n
Base document class, mostly inherited from Document class from llama-index.
This class accept one positional argument content of an arbitrary type, which will store the raw content of the document. If specified, the class will use content to initialize the base llama_index class.
the channel to show the document. Optional.: - chat: show in chat message - info: show in information panel - index: show in index panel - debug: show in debug panel
Source code in libs/kotaemon/kotaemon/base/schema.py
class Document(BaseDocument):\n \"\"\"\n Base document class, mostly inherited from Document class from llama-index.\n\n This class accept one positional argument `content` of an arbitrary type, which will\n store the raw content of the document. If specified, the class will use\n `content` to initialize the base llama_index class.\n\n Attributes:\n content: raw content of the document, can be anything\n source: id of the source of the Document. Optional.\n channel: the channel to show the document. Optional.:\n - chat: show in chat message\n - info: show in information panel\n - index: show in index panel\n - debug: show in debug panel\n \"\"\"\n\n content: Any = None\n source: Optional[str] = None\n channel: Optional[Literal[\"chat\", \"info\", \"index\", \"debug\", \"plot\"]] = None\n\n def __init__(self, content: Optional[Any] = None, *args, **kwargs):\n if content is None:\n if kwargs.get(\"text\", None) is not None:\n kwargs[\"content\"] = kwargs[\"text\"]\n elif kwargs.get(\"embedding\", None) is not None:\n kwargs[\"content\"] = kwargs[\"embedding\"]\n # default text indicating this document only contains embedding\n kwargs[\"text\"] = \"<EMBEDDING>\"\n elif isinstance(content, Document):\n # TODO: simplify the Document class\n temp_ = content.dict()\n temp_.update(kwargs)\n kwargs = temp_\n else:\n kwargs[\"content\"] = content\n if content:\n kwargs[\"text\"] = str(content)\n else:\n kwargs[\"text\"] = \"\"\n super().__init__(*args, **kwargs)\n\n def __bool__(self):\n return bool(self.content)\n\n @classmethod\n def example(cls) -> \"Document\":\n document = Document(\n text=SAMPLE_TEXT,\n metadata={\"filename\": \"README.md\", \"category\": \"codebase\"},\n )\n return document\n\n def to_haystack_format(self) -> \"HaystackDocument\":\n \"\"\"Convert struct to Haystack document format.\"\"\"\n from haystack.schema import Document as HaystackDocument\n\n metadata = self.metadata or {}\n text = self.text\n return HaystackDocument(content=text, meta=metadata)\n\n def __str__(self):\n return str(self.content)\n
Subclass of Document which must contains embedding
Use this if you want to enforce component's IOs to must contain embedding.
Source code in libs/kotaemon/kotaemon/base/schema.py
class DocumentWithEmbedding(Document):\n \"\"\"Subclass of Document which must contains embedding\n\n Use this if you want to enforce component's IOs to must contain embedding.\n \"\"\"\n\n def __init__(self, embedding: list[float], *args, **kwargs):\n kwargs[\"embedding\"] = embedding\n super().__init__(*args, **kwargs)\n
Subclass of Document with retrieval-related information
Attributes:
Name Type Description scorefloat
score of the document (from 0.0 to 1.0)
retrieval_metadatadict
metadata from the retrieval process, can be used by different components in a retrieved pipeline to communicate with each other
Source code in libs/kotaemon/kotaemon/base/schema.py
class RetrievedDocument(Document):\n \"\"\"Subclass of Document with retrieval-related information\n\n Attributes:\n score (float): score of the document (from 0.0 to 1.0)\n retrieval_metadata (dict): metadata from the retrieval process, can be used\n by different components in a retrieved pipeline to communicate with each\n other\n \"\"\"\n\n score: float = Field(default=0.0)\n retrieval_metadata: dict = Field(default={})\n
The response to the message. If None, no response is sent.
Source code in libs/kotaemon/kotaemon/chatbot/base.py
def run(self, message: HumanMessage) -> Optional[BaseMessage]:\n \"\"\"Chat, given a message, return a response\n\n Args:\n message: The message to respond to\n\n Returns:\n The response to the message. If None, no response is sent.\n \"\"\"\n user_message = (\n HumanMessage(content=message) if isinstance(message, str) else message\n )\n self.history.append(user_message)\n\n output = self.bot(self.history).text\n output_message = None\n if output is not None:\n output_message = AIMessage(content=output)\n self.history.append(output_message)\n\n return output_message\n
Simple text respondent chatbot that essentially wraps around a chat LLM
Source code in libs/kotaemon/kotaemon/chatbot/simple_respondent.py
class SimpleRespondentChatbot(BaseChatBot):\n \"\"\"Simple text respondent chatbot that essentially wraps around a chat LLM\"\"\"\n\n llm: ChatLLM\n\n def _get_message(self) -> str:\n return self.llm(self.history).text\n
The response to the message. If None, no response is sent.
Source code in libs/kotaemon/kotaemon/chatbot/base.py
def run(self, message: HumanMessage) -> Optional[BaseMessage]:\n \"\"\"Chat, given a message, return a response\n\n Args:\n message: The message to respond to\n\n Returns:\n The response to the message. If None, no response is sent.\n \"\"\"\n user_message = (\n HumanMessage(content=message) if isinstance(message, str) else message\n )\n self.history.append(user_message)\n\n output = self.bot(self.history).text\n output_message = None\n if output is not None:\n output_message = AIMessage(content=output)\n self.history.append(output_message)\n\n return output_message\n
Simple text respondent chatbot that essentially wraps around a chat LLM
Source code in libs/kotaemon/kotaemon/chatbot/simple_respondent.py
class SimpleRespondentChatbot(BaseChatBot):\n \"\"\"Simple text respondent chatbot that essentially wraps around a chat LLM\"\"\"\n\n llm: ChatLLM\n\n def _get_message(self) -> str:\n return self.llm(self.history).text\n
An Embeddings component that uses an OpenAI API compatible endpoint.
Attributes:
Name Type Description endpoint_urlstr
The url of an OpenAI API compatible endpoint.
Source code in libs/kotaemon/kotaemon/embeddings/endpoint_based.py
class EndpointEmbeddings(BaseEmbeddings):\n \"\"\"\n An Embeddings component that uses an OpenAI API compatible endpoint.\n\n Attributes:\n endpoint_url (str): The url of an OpenAI API compatible endpoint.\n \"\"\"\n\n endpoint_url: str\n\n def run(\n self, text: str | list[str] | Document | list[Document]\n ) -> list[DocumentWithEmbedding]:\n \"\"\"\n Generate embeddings from text Args:\n text (str | list[str] | Document | list[Document]): text to generate\n embeddings from\n Returns:\n list[DocumentWithEmbedding]: embeddings\n \"\"\"\n if not isinstance(text, list):\n text = [text]\n\n outputs = []\n\n for item in text:\n response = requests.post(\n self.endpoint_url, json={\"input\": str(item)}\n ).json()\n outputs.append(\n DocumentWithEmbedding(\n text=str(item),\n embedding=response[\"data\"][0][\"embedding\"],\n total_tokens=response[\"usage\"][\"total_tokens\"],\n prompt_tokens=response[\"usage\"][\"prompt_tokens\"],\n )\n )\n\n return outputs\n
Source code in libs/kotaemon/kotaemon/embeddings/openai.py
class OpenAIEmbeddings(BaseOpenAIEmbeddings):\n \"\"\"OpenAI chat model\"\"\"\n\n base_url: Optional[str] = Param(None, help=\"OpenAI base URL\")\n organization: Optional[str] = Param(None, help=\"OpenAI organization\")\n model: str = Param(\n None,\n help=(\n \"ID of the model to use. You can go to [Model overview](https://platform.\"\n \"openai.com/docs/models/overview) to see the available models.\"\n ),\n required=True,\n )\n\n def prepare_client(self, async_version: bool = False):\n \"\"\"Get the OpenAI client\n\n Args:\n async_version (bool): Whether to get the async version of the client\n \"\"\"\n params = {\n \"api_key\": self.api_key,\n \"organization\": self.organization,\n \"base_url\": self.base_url,\n \"timeout\": self.timeout,\n \"max_retries\": self.max_retries_,\n }\n if async_version:\n from openai import AsyncOpenAI\n\n return AsyncOpenAI(**params)\n\n from openai import OpenAI\n\n return OpenAI(**params)\n\n @retry(\n retry=retry_if_not_exception_type(\n (openai.NotFoundError, openai.BadRequestError)\n ),\n wait=wait_random_exponential(min=1, max=40),\n stop=stop_after_attempt(6),\n )\n def openai_response(self, client, **kwargs):\n \"\"\"Get the openai response\"\"\"\n params: dict = {\n \"model\": self.model,\n }\n if self.dimensions:\n params[\"dimensions\"] = self.dimensions\n params.update(kwargs)\n\n return client.embeddings.create(**params)\n
An Embeddings component that uses an OpenAI API compatible endpoint.
Attributes:
Name Type Description endpoint_urlstr
The url of an OpenAI API compatible endpoint.
Source code in libs/kotaemon/kotaemon/embeddings/endpoint_based.py
class EndpointEmbeddings(BaseEmbeddings):\n \"\"\"\n An Embeddings component that uses an OpenAI API compatible endpoint.\n\n Attributes:\n endpoint_url (str): The url of an OpenAI API compatible endpoint.\n \"\"\"\n\n endpoint_url: str\n\n def run(\n self, text: str | list[str] | Document | list[Document]\n ) -> list[DocumentWithEmbedding]:\n \"\"\"\n Generate embeddings from text Args:\n text (str | list[str] | Document | list[Document]): text to generate\n embeddings from\n Returns:\n list[DocumentWithEmbedding]: embeddings\n \"\"\"\n if not isinstance(text, list):\n text = [text]\n\n outputs = []\n\n for item in text:\n response = requests.post(\n self.endpoint_url, json={\"input\": str(item)}\n ).json()\n outputs.append(\n DocumentWithEmbedding(\n text=str(item),\n embedding=response[\"data\"][0][\"embedding\"],\n total_tokens=response[\"usage\"][\"total_tokens\"],\n prompt_tokens=response[\"usage\"][\"prompt_tokens\"],\n )\n )\n\n return outputs\n
Base interface for OpenAI embedding model, using the openai library.
This class exposes the parameters in resources.Chat. To subclass this class:
- Implement the `prepare_client` method to return the OpenAI client\n- Implement the `openai_response` method to return the OpenAI response\n- Implement the params relate to the OpenAI client\n
Source code in libs/kotaemon/kotaemon/embeddings/openai.py
class BaseOpenAIEmbeddings(BaseEmbeddings):\n \"\"\"Base interface for OpenAI embedding model, using the openai library.\n\n This class exposes the parameters in resources.Chat. To subclass this class:\n\n - Implement the `prepare_client` method to return the OpenAI client\n - Implement the `openai_response` method to return the OpenAI response\n - Implement the params relate to the OpenAI client\n \"\"\"\n\n _dependencies = [\"openai\"]\n\n api_key: str = Param(None, help=\"API key\", required=True)\n timeout: Optional[float] = Param(None, help=\"Timeout for the API request.\")\n max_retries: Optional[int] = Param(\n None, help=\"Maximum number of retries for the API request.\"\n )\n\n dimensions: Optional[int] = Param(\n None,\n help=(\n \"The number of dimensions the resulting output embeddings should have. \"\n \"Only supported in `text-embedding-3` and later models.\"\n ),\n )\n context_length: Optional[int] = Param(\n None, help=\"The maximum context length of the embedding model\"\n )\n\n @Param.auto(depends_on=[\"max_retries\"])\n def max_retries_(self):\n if self.max_retries is None:\n from openai._constants import DEFAULT_MAX_RETRIES\n\n return DEFAULT_MAX_RETRIES\n return self.max_retries\n\n def prepare_client(self, async_version: bool = False):\n \"\"\"Get the OpenAI client\n\n Args:\n async_version (bool): Whether to get the async version of the client\n \"\"\"\n raise NotImplementedError\n\n def openai_response(self, client, **kwargs):\n \"\"\"Get the openai response\"\"\"\n raise NotImplementedError\n\n def invoke(\n self, text: str | list[str] | Document | list[Document], *args, **kwargs\n ) -> list[DocumentWithEmbedding]:\n input_doc = self.prepare_input(text)\n client = self.prepare_client(async_version=False)\n\n input_: list[str | list[int]] = []\n splitted_indices = {}\n for idx, text in enumerate(input_doc):\n if self.context_length:\n chunks = split_text_by_chunk_size(text.text or \" \", self.context_length)\n splitted_indices[idx] = (len(input_), len(input_) + len(chunks))\n input_.extend(chunks)\n else:\n splitted_indices[idx] = (len(input_), len(input_) + 1)\n input_.append(text.text)\n\n resp = self.openai_response(client, input=input_, **kwargs).dict()\n output_ = list(sorted(resp[\"data\"], key=lambda x: x[\"index\"]))\n\n output = []\n for idx, doc in enumerate(input_doc):\n embs = output_[splitted_indices[idx][0] : splitted_indices[idx][1]]\n if len(embs) == 1:\n output.append(\n DocumentWithEmbedding(embedding=embs[0][\"embedding\"], content=doc)\n )\n continue\n\n chunk_lens = [\n len(_)\n for _ in input_[splitted_indices[idx][0] : splitted_indices[idx][1]]\n ]\n vs: list[list[float]] = [_[\"embedding\"] for _ in embs]\n emb = np.average(vs, axis=0, weights=chunk_lens)\n emb = emb / np.linalg.norm(emb)\n output.append(DocumentWithEmbedding(embedding=emb.tolist(), content=doc))\n\n return output\n\n async def ainvoke(\n self, text: str | list[str] | Document | list[Document], *args, **kwargs\n ) -> list[DocumentWithEmbedding]:\n input_ = self.prepare_input(text)\n client = self.prepare_client(async_version=True)\n resp = await self.openai_response(\n client, input=[_.text if _.text else \" \" for _ in input_], **kwargs\n ).dict()\n output_ = sorted(resp[\"data\"], key=lambda x: x[\"index\"])\n return [\n DocumentWithEmbedding(embedding=o[\"embedding\"], content=i)\n for i, o in zip(input_, output_)\n ]\n
False Source code in libs/kotaemon/kotaemon/embeddings/openai.py
def prepare_client(self, async_version: bool = False):\n \"\"\"Get the OpenAI client\n\n Args:\n async_version (bool): Whether to get the async version of the client\n \"\"\"\n raise NotImplementedError\n
Source code in libs/kotaemon/kotaemon/embeddings/openai.py
class OpenAIEmbeddings(BaseOpenAIEmbeddings):\n \"\"\"OpenAI chat model\"\"\"\n\n base_url: Optional[str] = Param(None, help=\"OpenAI base URL\")\n organization: Optional[str] = Param(None, help=\"OpenAI organization\")\n model: str = Param(\n None,\n help=(\n \"ID of the model to use. You can go to [Model overview](https://platform.\"\n \"openai.com/docs/models/overview) to see the available models.\"\n ),\n required=True,\n )\n\n def prepare_client(self, async_version: bool = False):\n \"\"\"Get the OpenAI client\n\n Args:\n async_version (bool): Whether to get the async version of the client\n \"\"\"\n params = {\n \"api_key\": self.api_key,\n \"organization\": self.organization,\n \"base_url\": self.base_url,\n \"timeout\": self.timeout,\n \"max_retries\": self.max_retries_,\n }\n if async_version:\n from openai import AsyncOpenAI\n\n return AsyncOpenAI(**params)\n\n from openai import OpenAI\n\n return OpenAI(**params)\n\n @retry(\n retry=retry_if_not_exception_type(\n (openai.NotFoundError, openai.BadRequestError)\n ),\n wait=wait_random_exponential(min=1, max=40),\n stop=stop_after_attempt(6),\n )\n def openai_response(self, client, **kwargs):\n \"\"\"Get the openai response\"\"\"\n params: dict = {\n \"model\": self.model,\n }\n if self.dimensions:\n params[\"dimensions\"] = self.dimensions\n params.update(kwargs)\n\n return client.embeddings.create(**params)\n
Source code in libs/kotaemon/kotaemon/embeddings/openai.py
def split_text_by_chunk_size(text: str, chunk_size: int) -> list[list[int]]:\n \"\"\"Split the text into chunks of a given size\n\n Args:\n text: text to split\n chunk_size: size of each chunk\n\n Returns:\n list of chunks (as tokens)\n \"\"\"\n encoding = tiktoken.get_encoding(\"cl100k_base\")\n tokens = iter(encoding.encode(text))\n result = []\n while chunk := list(islice(tokens, chunk_size)):\n result.append(chunk)\n return result\n
Ingest the document, run through the embedding, and store the embedding in a vector store.
This pipeline supports the following set of inputs
List of documents
List of texts
Source code in libs/kotaemon/kotaemon/indices/vectorindex.py
class VectorIndexing(BaseIndexing):\n \"\"\"Ingest the document, run through the embedding, and store the embedding in a\n vector store.\n\n This pipeline supports the following set of inputs:\n - List of documents\n - List of texts\n \"\"\"\n\n cache_dir: Optional[str] = getattr(flowsettings, \"KH_CHUNKS_OUTPUT_DIR\", None)\n vector_store: BaseVectorStore\n doc_store: Optional[BaseDocumentStore] = None\n embedding: BaseEmbeddings\n count_: int = 0\n\n def to_retrieval_pipeline(self, *args, **kwargs):\n \"\"\"Convert the indexing pipeline to a retrieval pipeline\"\"\"\n return VectorRetrieval(\n vector_store=self.vector_store,\n doc_store=self.doc_store,\n embedding=self.embedding,\n **kwargs,\n )\n\n def to_qa_pipeline(self, *args, **kwargs):\n from .qa import CitationQAPipeline\n\n return TextVectorQA(\n retrieving_pipeline=self.to_retrieval_pipeline(**kwargs),\n qa_pipeline=CitationQAPipeline(**kwargs),\n )\n\n def write_chunk_to_file(self, docs: list[Document]):\n # save the chunks content into markdown format\n if self.cache_dir:\n file_name = Path(docs[0].metadata[\"file_name\"])\n for i in range(len(docs)):\n markdown_content = \"\"\n if \"page_label\" in docs[i].metadata:\n page_label = str(docs[i].metadata[\"page_label\"])\n markdown_content += f\"Page label: {page_label}\"\n if \"file_name\" in docs[i].metadata:\n filename = docs[i].metadata[\"file_name\"]\n markdown_content += f\"\\nFile name: {filename}\"\n if \"section\" in docs[i].metadata:\n section = docs[i].metadata[\"section\"]\n markdown_content += f\"\\nSection: {section}\"\n if \"type\" in docs[i].metadata:\n if docs[i].metadata[\"type\"] == \"image\":\n image_origin = docs[i].metadata[\"image_origin\"]\n image_origin = f'<p><img src=\"{image_origin}\"></p>'\n markdown_content += f\"\\nImage origin: {image_origin}\"\n if docs[i].text:\n markdown_content += f\"\\ntext:\\n{docs[i].text}\"\n\n with open(\n Path(self.cache_dir) / f\"{file_name.stem}_{self.count_+i}.md\",\n \"w\",\n encoding=\"utf-8\",\n ) as f:\n f.write(markdown_content)\n\n def add_to_docstore(self, docs: list[Document]):\n if self.doc_store:\n print(\"Adding documents to doc store\")\n self.doc_store.add(docs)\n\n def add_to_vectorstore(self, docs: list[Document]):\n # in case we want to skip embedding\n if self.vector_store:\n print(f\"Getting embeddings for {len(docs)} nodes\")\n embeddings = self.embedding(docs)\n print(\"Adding embeddings to vector store\")\n self.vector_store.add(\n embeddings=embeddings,\n ids=[t.doc_id for t in docs],\n )\n\n def run(self, text: str | list[str] | Document | list[Document]):\n input_: list[Document] = []\n if not isinstance(text, list):\n text = [text]\n\n for item in cast(list, text):\n if isinstance(item, str):\n input_.append(Document(text=item, id_=str(uuid.uuid4())))\n elif isinstance(item, Document):\n input_.append(item)\n else:\n raise ValueError(\n f\"Invalid input type {type(item)}, should be str or Document\"\n )\n\n self.add_to_vectorstore(input_)\n self.add_to_docstore(input_)\n self.write_chunk_to_file(input_)\n self.count_ += len(input_)\n
Source code in libs/kotaemon/kotaemon/indices/vectorindex.py
class VectorRetrieval(BaseRetrieval):\n \"\"\"Retrieve list of documents from vector store\"\"\"\n\n vector_store: BaseVectorStore\n doc_store: Optional[BaseDocumentStore] = None\n embedding: BaseEmbeddings\n rerankers: Sequence[BaseReranking] = []\n top_k: int = 5\n first_round_top_k_mult: int = 10\n retrieval_mode: str = \"hybrid\" # vector, text, hybrid\n\n def _filter_docs(\n self, documents: list[RetrievedDocument], top_k: int | None = None\n ):\n if top_k:\n documents = documents[:top_k]\n return documents\n\n def run(\n self, text: str | Document, top_k: Optional[int] = None, **kwargs\n ) -> list[RetrievedDocument]:\n \"\"\"Retrieve a list of documents from vector store\n\n Args:\n text: the text to retrieve similar documents\n top_k: number of top similar documents to return\n\n Returns:\n list[RetrievedDocument]: list of retrieved documents\n \"\"\"\n if top_k is None:\n top_k = self.top_k\n\n do_extend = kwargs.pop(\"do_extend\", False)\n thumbnail_count = kwargs.pop(\"thumbnail_count\", 3)\n\n if do_extend:\n top_k_first_round = top_k * self.first_round_top_k_mult\n else:\n top_k_first_round = top_k\n\n if self.doc_store is None:\n raise ValueError(\n \"doc_store is not provided. Please provide a doc_store to \"\n \"retrieve the documents\"\n )\n\n result: list[RetrievedDocument] = []\n # TODO: should declare scope directly in the run params\n scope = kwargs.pop(\"scope\", None)\n emb: list[float]\n\n if self.retrieval_mode == \"vector\":\n emb = self.embedding(text)[0].embedding\n _, scores, ids = self.vector_store.query(\n embedding=emb, top_k=top_k_first_round, **kwargs\n )\n docs = self.doc_store.get(ids)\n result = [\n RetrievedDocument(**doc.to_dict(), score=score)\n for doc, score in zip(docs, scores)\n ]\n elif self.retrieval_mode == \"text\":\n query = text.text if isinstance(text, Document) else text\n docs = self.doc_store.query(query, top_k=top_k_first_round, doc_ids=scope)\n result = [RetrievedDocument(**doc.to_dict(), score=-1.0) for doc in docs]\n elif self.retrieval_mode == \"hybrid\":\n # similarity search section\n emb = self.embedding(text)[0].embedding\n vs_docs: list[RetrievedDocument] = []\n vs_ids: list[str] = []\n vs_scores: list[float] = []\n\n def query_vectorstore():\n nonlocal vs_docs\n nonlocal vs_scores\n nonlocal vs_ids\n\n assert self.doc_store is not None\n _, vs_scores, vs_ids = self.vector_store.query(\n embedding=emb, top_k=top_k_first_round, **kwargs\n )\n if vs_ids:\n vs_docs = self.doc_store.get(vs_ids)\n\n # full-text search section\n ds_docs: list[RetrievedDocument] = []\n\n def query_docstore():\n nonlocal ds_docs\n\n assert self.doc_store is not None\n query = text.text if isinstance(text, Document) else text\n ds_docs = self.doc_store.query(\n query, top_k=top_k_first_round, doc_ids=scope\n )\n\n vs_query_thread = threading.Thread(target=query_vectorstore)\n ds_query_thread = threading.Thread(target=query_docstore)\n\n vs_query_thread.start()\n ds_query_thread.start()\n\n vs_query_thread.join()\n ds_query_thread.join()\n\n result = [\n RetrievedDocument(**doc.to_dict(), score=-1.0)\n for doc in ds_docs\n if doc not in vs_ids\n ]\n result += [\n RetrievedDocument(**doc.to_dict(), score=score)\n for doc, score in zip(vs_docs, vs_scores)\n ]\n print(f\"Got {len(vs_docs)} from vectorstore\")\n print(f\"Got {len(ds_docs)} from docstore\")\n\n # use additional reranker to re-order the document list\n if self.rerankers and text:\n for reranker in self.rerankers:\n # if reranker is LLMReranking, limit the document with top_k items only\n if isinstance(reranker, LLMReranking):\n result = self._filter_docs(result, top_k=top_k)\n result = reranker(documents=result, query=text)\n\n result = self._filter_docs(result, top_k=top_k)\n print(f\"Got raw {len(result)} retrieved documents\")\n\n # add page thumbnails to the result if exists\n thumbnail_doc_ids: set[str] = set()\n # we should copy the text from retrieved text chunk\n # to the thumbnail to get relevant LLM score correctly\n text_thumbnail_docs: dict[str, RetrievedDocument] = {}\n\n non_thumbnail_docs = []\n raw_thumbnail_docs = []\n for doc in result:\n if doc.metadata.get(\"type\") == \"thumbnail\":\n # change type to image to display on UI\n doc.metadata[\"type\"] = \"image\"\n raw_thumbnail_docs.append(doc)\n continue\n if (\n \"thumbnail_doc_id\" in doc.metadata\n and len(thumbnail_doc_ids) < thumbnail_count\n ):\n thumbnail_id = doc.metadata[\"thumbnail_doc_id\"]\n thumbnail_doc_ids.add(thumbnail_id)\n text_thumbnail_docs[thumbnail_id] = doc\n else:\n non_thumbnail_docs.append(doc)\n\n linked_thumbnail_docs = self.doc_store.get(list(thumbnail_doc_ids))\n print(\n \"thumbnail docs\",\n len(linked_thumbnail_docs),\n \"non-thumbnail docs\",\n len(non_thumbnail_docs),\n \"raw-thumbnail docs\",\n len(raw_thumbnail_docs),\n )\n additional_docs = []\n\n for thumbnail_doc in linked_thumbnail_docs:\n text_doc = text_thumbnail_docs[thumbnail_doc.doc_id]\n doc_dict = thumbnail_doc.to_dict()\n doc_dict[\"_id\"] = text_doc.doc_id\n doc_dict[\"content\"] = text_doc.content\n doc_dict[\"metadata\"][\"type\"] = \"image\"\n for key in text_doc.metadata:\n if key not in doc_dict[\"metadata\"]:\n doc_dict[\"metadata\"][key] = text_doc.metadata[key]\n\n additional_docs.append(RetrievedDocument(**doc_dict, score=text_doc.score))\n\n result = additional_docs + non_thumbnail_docs\n\n if not result:\n # return output from raw retrieved thumbnails\n result = self._filter_docs(raw_thumbnail_docs, top_k=thumbnail_count)\n\n return result\n
list[RetrievedDocument]: list of retrieved documents
Source code in libs/kotaemon/kotaemon/indices/vectorindex.py
def run(\n self, text: str | Document, top_k: Optional[int] = None, **kwargs\n) -> list[RetrievedDocument]:\n \"\"\"Retrieve a list of documents from vector store\n\n Args:\n text: the text to retrieve similar documents\n top_k: number of top similar documents to return\n\n Returns:\n list[RetrievedDocument]: list of retrieved documents\n \"\"\"\n if top_k is None:\n top_k = self.top_k\n\n do_extend = kwargs.pop(\"do_extend\", False)\n thumbnail_count = kwargs.pop(\"thumbnail_count\", 3)\n\n if do_extend:\n top_k_first_round = top_k * self.first_round_top_k_mult\n else:\n top_k_first_round = top_k\n\n if self.doc_store is None:\n raise ValueError(\n \"doc_store is not provided. Please provide a doc_store to \"\n \"retrieve the documents\"\n )\n\n result: list[RetrievedDocument] = []\n # TODO: should declare scope directly in the run params\n scope = kwargs.pop(\"scope\", None)\n emb: list[float]\n\n if self.retrieval_mode == \"vector\":\n emb = self.embedding(text)[0].embedding\n _, scores, ids = self.vector_store.query(\n embedding=emb, top_k=top_k_first_round, **kwargs\n )\n docs = self.doc_store.get(ids)\n result = [\n RetrievedDocument(**doc.to_dict(), score=score)\n for doc, score in zip(docs, scores)\n ]\n elif self.retrieval_mode == \"text\":\n query = text.text if isinstance(text, Document) else text\n docs = self.doc_store.query(query, top_k=top_k_first_round, doc_ids=scope)\n result = [RetrievedDocument(**doc.to_dict(), score=-1.0) for doc in docs]\n elif self.retrieval_mode == \"hybrid\":\n # similarity search section\n emb = self.embedding(text)[0].embedding\n vs_docs: list[RetrievedDocument] = []\n vs_ids: list[str] = []\n vs_scores: list[float] = []\n\n def query_vectorstore():\n nonlocal vs_docs\n nonlocal vs_scores\n nonlocal vs_ids\n\n assert self.doc_store is not None\n _, vs_scores, vs_ids = self.vector_store.query(\n embedding=emb, top_k=top_k_first_round, **kwargs\n )\n if vs_ids:\n vs_docs = self.doc_store.get(vs_ids)\n\n # full-text search section\n ds_docs: list[RetrievedDocument] = []\n\n def query_docstore():\n nonlocal ds_docs\n\n assert self.doc_store is not None\n query = text.text if isinstance(text, Document) else text\n ds_docs = self.doc_store.query(\n query, top_k=top_k_first_round, doc_ids=scope\n )\n\n vs_query_thread = threading.Thread(target=query_vectorstore)\n ds_query_thread = threading.Thread(target=query_docstore)\n\n vs_query_thread.start()\n ds_query_thread.start()\n\n vs_query_thread.join()\n ds_query_thread.join()\n\n result = [\n RetrievedDocument(**doc.to_dict(), score=-1.0)\n for doc in ds_docs\n if doc not in vs_ids\n ]\n result += [\n RetrievedDocument(**doc.to_dict(), score=score)\n for doc, score in zip(vs_docs, vs_scores)\n ]\n print(f\"Got {len(vs_docs)} from vectorstore\")\n print(f\"Got {len(ds_docs)} from docstore\")\n\n # use additional reranker to re-order the document list\n if self.rerankers and text:\n for reranker in self.rerankers:\n # if reranker is LLMReranking, limit the document with top_k items only\n if isinstance(reranker, LLMReranking):\n result = self._filter_docs(result, top_k=top_k)\n result = reranker(documents=result, query=text)\n\n result = self._filter_docs(result, top_k=top_k)\n print(f\"Got raw {len(result)} retrieved documents\")\n\n # add page thumbnails to the result if exists\n thumbnail_doc_ids: set[str] = set()\n # we should copy the text from retrieved text chunk\n # to the thumbnail to get relevant LLM score correctly\n text_thumbnail_docs: dict[str, RetrievedDocument] = {}\n\n non_thumbnail_docs = []\n raw_thumbnail_docs = []\n for doc in result:\n if doc.metadata.get(\"type\") == \"thumbnail\":\n # change type to image to display on UI\n doc.metadata[\"type\"] = \"image\"\n raw_thumbnail_docs.append(doc)\n continue\n if (\n \"thumbnail_doc_id\" in doc.metadata\n and len(thumbnail_doc_ids) < thumbnail_count\n ):\n thumbnail_id = doc.metadata[\"thumbnail_doc_id\"]\n thumbnail_doc_ids.add(thumbnail_id)\n text_thumbnail_docs[thumbnail_id] = doc\n else:\n non_thumbnail_docs.append(doc)\n\n linked_thumbnail_docs = self.doc_store.get(list(thumbnail_doc_ids))\n print(\n \"thumbnail docs\",\n len(linked_thumbnail_docs),\n \"non-thumbnail docs\",\n len(non_thumbnail_docs),\n \"raw-thumbnail docs\",\n len(raw_thumbnail_docs),\n )\n additional_docs = []\n\n for thumbnail_doc in linked_thumbnail_docs:\n text_doc = text_thumbnail_docs[thumbnail_doc.doc_id]\n doc_dict = thumbnail_doc.to_dict()\n doc_dict[\"_id\"] = text_doc.doc_id\n doc_dict[\"content\"] = text_doc.content\n doc_dict[\"metadata\"][\"type\"] = \"image\"\n for key in text_doc.metadata:\n if key not in doc_dict[\"metadata\"]:\n doc_dict[\"metadata\"][key] = text_doc.metadata[key]\n\n additional_docs.append(RetrievedDocument(**doc_dict, score=text_doc.score))\n\n result = additional_docs + non_thumbnail_docs\n\n if not result:\n # return output from raw retrieved thumbnails\n result = self._filter_docs(raw_thumbnail_docs, top_k=thumbnail_count)\n\n return result\n
A document transformer transforms a list of documents into another list of documents. Transforming can mean splitting a document into multiple documents, reducing a large list of documents into a smaller list of documents, or adding metadata to each document in a list of documents, etc.
Source code in libs/kotaemon/kotaemon/indices/base.py
class DocTransformer(BaseComponent):\n \"\"\"This is a base class for document transformers\n\n A document transformer transforms a list of documents into another list\n of documents. Transforming can mean splitting a document into multiple documents,\n reducing a large list of documents into a smaller list of documents, or adding\n metadata to each document in a list of documents, etc.\n \"\"\"\n\n @abstractmethod\n def run(\n self,\n documents: list[Document],\n **kwargs,\n ) -> list[Document]:\n ...\n
Allow automatically wrapping a Llama-index component into kotaemon component
Example
class TokenSplitter(LlamaIndexMixin, BaseSplitter): def _get_li_class(self): from llama_index.core.text_splitter import TokenTextSplitter return TokenTextSplitter
To use this mixin, please: 1. Use this class as the 1st parent class, so that Python will prefer to use the attributes and methods of this class whenever possible. 2. Overwrite _get_li_class to return the relevant LlamaIndex component.
Source code in libs/kotaemon/kotaemon/indices/base.py
class LlamaIndexDocTransformerMixin:\n \"\"\"Allow automatically wrapping a Llama-index component into kotaemon component\n\n Example:\n class TokenSplitter(LlamaIndexMixin, BaseSplitter):\n def _get_li_class(self):\n from llama_index.core.text_splitter import TokenTextSplitter\n return TokenTextSplitter\n\n To use this mixin, please:\n 1. Use this class as the 1st parent class, so that Python will prefer to use\n the attributes and methods of this class whenever possible.\n 2. Overwrite `_get_li_class` to return the relevant LlamaIndex component.\n \"\"\"\n\n def _get_li_class(self) -> Type[NodeParser]:\n raise NotImplementedError(\n \"Please return the relevant LlamaIndex class in _get_li_class\"\n )\n\n def __init__(self, **params):\n self._li_cls = self._get_li_class()\n self._obj = self._li_cls(**params)\n self._kwargs = params\n super().__init__()\n\n def __repr__(self):\n kwargs = []\n for key, value_obj in self._kwargs.items():\n value = repr(value_obj)\n kwargs.append(f\"{key}={value}\")\n kwargs_repr = \", \".join(kwargs)\n return f\"{self.__class__.__name__}({kwargs_repr})\"\n\n def __str__(self):\n kwargs = []\n for key, value_obj in self._kwargs.items():\n value = str(value_obj)\n if len(value) > 20:\n value = f\"{value[:15]}...\"\n kwargs.append(f\"{key}={value}\")\n kwargs_repr = \", \".join(kwargs)\n return f\"{self.__class__.__name__}({kwargs_repr})\"\n\n def __setattr__(self, name: str, value: Any) -> None:\n if name.startswith(\"_\") or name in self._protected_keywords():\n return super().__setattr__(name, value)\n\n self._kwargs[name] = value\n return setattr(self._obj, name, value)\n\n def __getattr__(self, name: str) -> Any:\n if name in self._kwargs:\n return self._kwargs[name]\n return getattr(self._obj, name)\n\n def dump(self, *args, **kwargs):\n from theflow.utils.modules import serialize\n\n params = {key: serialize(value) for key, value in self._kwargs.items()}\n return {\n \"__type__\": f\"{self.__module__}.{self.__class__.__qualname__}\",\n **params,\n }\n\n def run(\n self,\n documents: list[Document],\n **kwargs,\n ) -> list[Document]:\n \"\"\"Run Llama-index node parser and convert the output to Document from\n kotaemon\n \"\"\"\n docs = self._obj(documents, **kwargs) # type: ignore\n return [Document.from_dict(doc.to_dict()) for doc in docs]\n
Source code in libs/kotaemon/kotaemon/indices/base.py
class BaseIndexing(BaseComponent):\n \"\"\"Define the base interface for indexing pipeline\"\"\"\n\n def to_retrieval_pipeline(self, **kwargs):\n \"\"\"Convert the indexing pipeline to a retrieval pipeline\"\"\"\n raise NotImplementedError\n\n def to_qa_pipeline(self, **kwargs):\n \"\"\"Convert the indexing pipeline to a QA pipeline\"\"\"\n raise NotImplementedError\n
Source code in libs/kotaemon/kotaemon/indices/base.py
class BaseRetrieval(BaseComponent):\n \"\"\"Define the base interface for retrieval pipeline\"\"\"\n\n @abstractmethod\n def run(self, *args, **kwargs) -> list[RetrievedDocument]:\n ...\n
Ingest the document, run through the embedding, and store the embedding in a vector store.
This pipeline supports the following set of inputs
List of documents
List of texts
Source code in libs/kotaemon/kotaemon/indices/vectorindex.py
class VectorIndexing(BaseIndexing):\n \"\"\"Ingest the document, run through the embedding, and store the embedding in a\n vector store.\n\n This pipeline supports the following set of inputs:\n - List of documents\n - List of texts\n \"\"\"\n\n cache_dir: Optional[str] = getattr(flowsettings, \"KH_CHUNKS_OUTPUT_DIR\", None)\n vector_store: BaseVectorStore\n doc_store: Optional[BaseDocumentStore] = None\n embedding: BaseEmbeddings\n count_: int = 0\n\n def to_retrieval_pipeline(self, *args, **kwargs):\n \"\"\"Convert the indexing pipeline to a retrieval pipeline\"\"\"\n return VectorRetrieval(\n vector_store=self.vector_store,\n doc_store=self.doc_store,\n embedding=self.embedding,\n **kwargs,\n )\n\n def to_qa_pipeline(self, *args, **kwargs):\n from .qa import CitationQAPipeline\n\n return TextVectorQA(\n retrieving_pipeline=self.to_retrieval_pipeline(**kwargs),\n qa_pipeline=CitationQAPipeline(**kwargs),\n )\n\n def write_chunk_to_file(self, docs: list[Document]):\n # save the chunks content into markdown format\n if self.cache_dir:\n file_name = Path(docs[0].metadata[\"file_name\"])\n for i in range(len(docs)):\n markdown_content = \"\"\n if \"page_label\" in docs[i].metadata:\n page_label = str(docs[i].metadata[\"page_label\"])\n markdown_content += f\"Page label: {page_label}\"\n if \"file_name\" in docs[i].metadata:\n filename = docs[i].metadata[\"file_name\"]\n markdown_content += f\"\\nFile name: {filename}\"\n if \"section\" in docs[i].metadata:\n section = docs[i].metadata[\"section\"]\n markdown_content += f\"\\nSection: {section}\"\n if \"type\" in docs[i].metadata:\n if docs[i].metadata[\"type\"] == \"image\":\n image_origin = docs[i].metadata[\"image_origin\"]\n image_origin = f'<p><img src=\"{image_origin}\"></p>'\n markdown_content += f\"\\nImage origin: {image_origin}\"\n if docs[i].text:\n markdown_content += f\"\\ntext:\\n{docs[i].text}\"\n\n with open(\n Path(self.cache_dir) / f\"{file_name.stem}_{self.count_+i}.md\",\n \"w\",\n encoding=\"utf-8\",\n ) as f:\n f.write(markdown_content)\n\n def add_to_docstore(self, docs: list[Document]):\n if self.doc_store:\n print(\"Adding documents to doc store\")\n self.doc_store.add(docs)\n\n def add_to_vectorstore(self, docs: list[Document]):\n # in case we want to skip embedding\n if self.vector_store:\n print(f\"Getting embeddings for {len(docs)} nodes\")\n embeddings = self.embedding(docs)\n print(\"Adding embeddings to vector store\")\n self.vector_store.add(\n embeddings=embeddings,\n ids=[t.doc_id for t in docs],\n )\n\n def run(self, text: str | list[str] | Document | list[Document]):\n input_: list[Document] = []\n if not isinstance(text, list):\n text = [text]\n\n for item in cast(list, text):\n if isinstance(item, str):\n input_.append(Document(text=item, id_=str(uuid.uuid4())))\n elif isinstance(item, Document):\n input_.append(item)\n else:\n raise ValueError(\n f\"Invalid input type {type(item)}, should be str or Document\"\n )\n\n self.add_to_vectorstore(input_)\n self.add_to_docstore(input_)\n self.write_chunk_to_file(input_)\n self.count_ += len(input_)\n
Source code in libs/kotaemon/kotaemon/indices/vectorindex.py
class VectorRetrieval(BaseRetrieval):\n \"\"\"Retrieve list of documents from vector store\"\"\"\n\n vector_store: BaseVectorStore\n doc_store: Optional[BaseDocumentStore] = None\n embedding: BaseEmbeddings\n rerankers: Sequence[BaseReranking] = []\n top_k: int = 5\n first_round_top_k_mult: int = 10\n retrieval_mode: str = \"hybrid\" # vector, text, hybrid\n\n def _filter_docs(\n self, documents: list[RetrievedDocument], top_k: int | None = None\n ):\n if top_k:\n documents = documents[:top_k]\n return documents\n\n def run(\n self, text: str | Document, top_k: Optional[int] = None, **kwargs\n ) -> list[RetrievedDocument]:\n \"\"\"Retrieve a list of documents from vector store\n\n Args:\n text: the text to retrieve similar documents\n top_k: number of top similar documents to return\n\n Returns:\n list[RetrievedDocument]: list of retrieved documents\n \"\"\"\n if top_k is None:\n top_k = self.top_k\n\n do_extend = kwargs.pop(\"do_extend\", False)\n thumbnail_count = kwargs.pop(\"thumbnail_count\", 3)\n\n if do_extend:\n top_k_first_round = top_k * self.first_round_top_k_mult\n else:\n top_k_first_round = top_k\n\n if self.doc_store is None:\n raise ValueError(\n \"doc_store is not provided. Please provide a doc_store to \"\n \"retrieve the documents\"\n )\n\n result: list[RetrievedDocument] = []\n # TODO: should declare scope directly in the run params\n scope = kwargs.pop(\"scope\", None)\n emb: list[float]\n\n if self.retrieval_mode == \"vector\":\n emb = self.embedding(text)[0].embedding\n _, scores, ids = self.vector_store.query(\n embedding=emb, top_k=top_k_first_round, **kwargs\n )\n docs = self.doc_store.get(ids)\n result = [\n RetrievedDocument(**doc.to_dict(), score=score)\n for doc, score in zip(docs, scores)\n ]\n elif self.retrieval_mode == \"text\":\n query = text.text if isinstance(text, Document) else text\n docs = self.doc_store.query(query, top_k=top_k_first_round, doc_ids=scope)\n result = [RetrievedDocument(**doc.to_dict(), score=-1.0) for doc in docs]\n elif self.retrieval_mode == \"hybrid\":\n # similarity search section\n emb = self.embedding(text)[0].embedding\n vs_docs: list[RetrievedDocument] = []\n vs_ids: list[str] = []\n vs_scores: list[float] = []\n\n def query_vectorstore():\n nonlocal vs_docs\n nonlocal vs_scores\n nonlocal vs_ids\n\n assert self.doc_store is not None\n _, vs_scores, vs_ids = self.vector_store.query(\n embedding=emb, top_k=top_k_first_round, **kwargs\n )\n if vs_ids:\n vs_docs = self.doc_store.get(vs_ids)\n\n # full-text search section\n ds_docs: list[RetrievedDocument] = []\n\n def query_docstore():\n nonlocal ds_docs\n\n assert self.doc_store is not None\n query = text.text if isinstance(text, Document) else text\n ds_docs = self.doc_store.query(\n query, top_k=top_k_first_round, doc_ids=scope\n )\n\n vs_query_thread = threading.Thread(target=query_vectorstore)\n ds_query_thread = threading.Thread(target=query_docstore)\n\n vs_query_thread.start()\n ds_query_thread.start()\n\n vs_query_thread.join()\n ds_query_thread.join()\n\n result = [\n RetrievedDocument(**doc.to_dict(), score=-1.0)\n for doc in ds_docs\n if doc not in vs_ids\n ]\n result += [\n RetrievedDocument(**doc.to_dict(), score=score)\n for doc, score in zip(vs_docs, vs_scores)\n ]\n print(f\"Got {len(vs_docs)} from vectorstore\")\n print(f\"Got {len(ds_docs)} from docstore\")\n\n # use additional reranker to re-order the document list\n if self.rerankers and text:\n for reranker in self.rerankers:\n # if reranker is LLMReranking, limit the document with top_k items only\n if isinstance(reranker, LLMReranking):\n result = self._filter_docs(result, top_k=top_k)\n result = reranker(documents=result, query=text)\n\n result = self._filter_docs(result, top_k=top_k)\n print(f\"Got raw {len(result)} retrieved documents\")\n\n # add page thumbnails to the result if exists\n thumbnail_doc_ids: set[str] = set()\n # we should copy the text from retrieved text chunk\n # to the thumbnail to get relevant LLM score correctly\n text_thumbnail_docs: dict[str, RetrievedDocument] = {}\n\n non_thumbnail_docs = []\n raw_thumbnail_docs = []\n for doc in result:\n if doc.metadata.get(\"type\") == \"thumbnail\":\n # change type to image to display on UI\n doc.metadata[\"type\"] = \"image\"\n raw_thumbnail_docs.append(doc)\n continue\n if (\n \"thumbnail_doc_id\" in doc.metadata\n and len(thumbnail_doc_ids) < thumbnail_count\n ):\n thumbnail_id = doc.metadata[\"thumbnail_doc_id\"]\n thumbnail_doc_ids.add(thumbnail_id)\n text_thumbnail_docs[thumbnail_id] = doc\n else:\n non_thumbnail_docs.append(doc)\n\n linked_thumbnail_docs = self.doc_store.get(list(thumbnail_doc_ids))\n print(\n \"thumbnail docs\",\n len(linked_thumbnail_docs),\n \"non-thumbnail docs\",\n len(non_thumbnail_docs),\n \"raw-thumbnail docs\",\n len(raw_thumbnail_docs),\n )\n additional_docs = []\n\n for thumbnail_doc in linked_thumbnail_docs:\n text_doc = text_thumbnail_docs[thumbnail_doc.doc_id]\n doc_dict = thumbnail_doc.to_dict()\n doc_dict[\"_id\"] = text_doc.doc_id\n doc_dict[\"content\"] = text_doc.content\n doc_dict[\"metadata\"][\"type\"] = \"image\"\n for key in text_doc.metadata:\n if key not in doc_dict[\"metadata\"]:\n doc_dict[\"metadata\"][key] = text_doc.metadata[key]\n\n additional_docs.append(RetrievedDocument(**doc_dict, score=text_doc.score))\n\n result = additional_docs + non_thumbnail_docs\n\n if not result:\n # return output from raw retrieved thumbnails\n result = self._filter_docs(raw_thumbnail_docs, top_k=thumbnail_count)\n\n return result\n
list[RetrievedDocument]: list of retrieved documents
Source code in libs/kotaemon/kotaemon/indices/vectorindex.py
def run(\n self, text: str | Document, top_k: Optional[int] = None, **kwargs\n) -> list[RetrievedDocument]:\n \"\"\"Retrieve a list of documents from vector store\n\n Args:\n text: the text to retrieve similar documents\n top_k: number of top similar documents to return\n\n Returns:\n list[RetrievedDocument]: list of retrieved documents\n \"\"\"\n if top_k is None:\n top_k = self.top_k\n\n do_extend = kwargs.pop(\"do_extend\", False)\n thumbnail_count = kwargs.pop(\"thumbnail_count\", 3)\n\n if do_extend:\n top_k_first_round = top_k * self.first_round_top_k_mult\n else:\n top_k_first_round = top_k\n\n if self.doc_store is None:\n raise ValueError(\n \"doc_store is not provided. Please provide a doc_store to \"\n \"retrieve the documents\"\n )\n\n result: list[RetrievedDocument] = []\n # TODO: should declare scope directly in the run params\n scope = kwargs.pop(\"scope\", None)\n emb: list[float]\n\n if self.retrieval_mode == \"vector\":\n emb = self.embedding(text)[0].embedding\n _, scores, ids = self.vector_store.query(\n embedding=emb, top_k=top_k_first_round, **kwargs\n )\n docs = self.doc_store.get(ids)\n result = [\n RetrievedDocument(**doc.to_dict(), score=score)\n for doc, score in zip(docs, scores)\n ]\n elif self.retrieval_mode == \"text\":\n query = text.text if isinstance(text, Document) else text\n docs = self.doc_store.query(query, top_k=top_k_first_round, doc_ids=scope)\n result = [RetrievedDocument(**doc.to_dict(), score=-1.0) for doc in docs]\n elif self.retrieval_mode == \"hybrid\":\n # similarity search section\n emb = self.embedding(text)[0].embedding\n vs_docs: list[RetrievedDocument] = []\n vs_ids: list[str] = []\n vs_scores: list[float] = []\n\n def query_vectorstore():\n nonlocal vs_docs\n nonlocal vs_scores\n nonlocal vs_ids\n\n assert self.doc_store is not None\n _, vs_scores, vs_ids = self.vector_store.query(\n embedding=emb, top_k=top_k_first_round, **kwargs\n )\n if vs_ids:\n vs_docs = self.doc_store.get(vs_ids)\n\n # full-text search section\n ds_docs: list[RetrievedDocument] = []\n\n def query_docstore():\n nonlocal ds_docs\n\n assert self.doc_store is not None\n query = text.text if isinstance(text, Document) else text\n ds_docs = self.doc_store.query(\n query, top_k=top_k_first_round, doc_ids=scope\n )\n\n vs_query_thread = threading.Thread(target=query_vectorstore)\n ds_query_thread = threading.Thread(target=query_docstore)\n\n vs_query_thread.start()\n ds_query_thread.start()\n\n vs_query_thread.join()\n ds_query_thread.join()\n\n result = [\n RetrievedDocument(**doc.to_dict(), score=-1.0)\n for doc in ds_docs\n if doc not in vs_ids\n ]\n result += [\n RetrievedDocument(**doc.to_dict(), score=score)\n for doc, score in zip(vs_docs, vs_scores)\n ]\n print(f\"Got {len(vs_docs)} from vectorstore\")\n print(f\"Got {len(ds_docs)} from docstore\")\n\n # use additional reranker to re-order the document list\n if self.rerankers and text:\n for reranker in self.rerankers:\n # if reranker is LLMReranking, limit the document with top_k items only\n if isinstance(reranker, LLMReranking):\n result = self._filter_docs(result, top_k=top_k)\n result = reranker(documents=result, query=text)\n\n result = self._filter_docs(result, top_k=top_k)\n print(f\"Got raw {len(result)} retrieved documents\")\n\n # add page thumbnails to the result if exists\n thumbnail_doc_ids: set[str] = set()\n # we should copy the text from retrieved text chunk\n # to the thumbnail to get relevant LLM score correctly\n text_thumbnail_docs: dict[str, RetrievedDocument] = {}\n\n non_thumbnail_docs = []\n raw_thumbnail_docs = []\n for doc in result:\n if doc.metadata.get(\"type\") == \"thumbnail\":\n # change type to image to display on UI\n doc.metadata[\"type\"] = \"image\"\n raw_thumbnail_docs.append(doc)\n continue\n if (\n \"thumbnail_doc_id\" in doc.metadata\n and len(thumbnail_doc_ids) < thumbnail_count\n ):\n thumbnail_id = doc.metadata[\"thumbnail_doc_id\"]\n thumbnail_doc_ids.add(thumbnail_id)\n text_thumbnail_docs[thumbnail_id] = doc\n else:\n non_thumbnail_docs.append(doc)\n\n linked_thumbnail_docs = self.doc_store.get(list(thumbnail_doc_ids))\n print(\n \"thumbnail docs\",\n len(linked_thumbnail_docs),\n \"non-thumbnail docs\",\n len(non_thumbnail_docs),\n \"raw-thumbnail docs\",\n len(raw_thumbnail_docs),\n )\n additional_docs = []\n\n for thumbnail_doc in linked_thumbnail_docs:\n text_doc = text_thumbnail_docs[thumbnail_doc.doc_id]\n doc_dict = thumbnail_doc.to_dict()\n doc_dict[\"_id\"] = text_doc.doc_id\n doc_dict[\"content\"] = text_doc.content\n doc_dict[\"metadata\"][\"type\"] = \"image\"\n for key in text_doc.metadata:\n if key not in doc_dict[\"metadata\"]:\n doc_dict[\"metadata\"][key] = text_doc.metadata[key]\n\n additional_docs.append(RetrievedDocument(**doc_dict, score=text_doc.score))\n\n result = additional_docs + non_thumbnail_docs\n\n if not result:\n # return output from raw retrieved thumbnails\n result = self._filter_docs(raw_thumbnail_docs, top_k=thumbnail_count)\n\n return result\n
Ingest common office document types into Document for indexing
Document types
pdf
xlsx, xls
docx, doc
Parameters:
Name Type Description Default pdf_mode
mode for pdf extraction, one of \"normal\", \"mathpix\", \"ocr\" - normal: parse pdf text - mathpix: parse pdf text using mathpix - ocr: parse pdf image using flax
required doc_parsers
list of document parsers to parse the document
required text_splitter
splitter to split the document into text nodes
required override_file_extractors
override file extractors for specific file extensions The default file extractors are stored in KH_DEFAULT_FILE_EXTRACTORS
required Source code in libs/kotaemon/kotaemon/indices/ingests/files.py
class DocumentIngestor(BaseComponent):\n \"\"\"Ingest common office document types into Document for indexing\n\n Document types:\n - pdf\n - xlsx, xls\n - docx, doc\n\n Args:\n pdf_mode: mode for pdf extraction, one of \"normal\", \"mathpix\", \"ocr\"\n - normal: parse pdf text\n - mathpix: parse pdf text using mathpix\n - ocr: parse pdf image using flax\n doc_parsers: list of document parsers to parse the document\n text_splitter: splitter to split the document into text nodes\n override_file_extractors: override file extractors for specific file extensions\n The default file extractors are stored in `KH_DEFAULT_FILE_EXTRACTORS`\n \"\"\"\n\n pdf_mode: str = \"normal\" # \"normal\", \"mathpix\", \"ocr\", \"multimodal\"\n doc_parsers: list[BaseDocParser] = Param(default_callback=lambda _: [])\n text_splitter: BaseSplitter = TokenSplitter.withx(\n chunk_size=1024,\n chunk_overlap=256,\n separator=\"\\n\\n\",\n backup_separators=[\"\\n\", \".\", \" \", \"\\u200B\"],\n )\n override_file_extractors: dict[str, Type[BaseReader]] = {}\n\n def _get_reader(self, input_files: list[str | Path]):\n \"\"\"Get appropriate readers for the input files based on file extension\"\"\"\n file_extractors: dict[str, BaseReader] = {\n ext: reader for ext, reader in KH_DEFAULT_FILE_EXTRACTORS.items()\n }\n for ext, cls in self.override_file_extractors.items():\n file_extractors[ext] = cls()\n\n if self.pdf_mode == \"normal\":\n file_extractors[\".pdf\"] = PDFReader()\n elif self.pdf_mode == \"ocr\":\n file_extractors[\".pdf\"] = OCRReader()\n elif self.pdf_mode == \"multimodal\":\n file_extractors[\".pdf\"] = AdobeReader()\n else:\n file_extractors[\".pdf\"] = MathpixPDFReader()\n\n main_reader = DirectoryReader(\n input_files=input_files,\n file_extractor=file_extractors,\n )\n\n return main_reader\n\n def run(self, file_paths: list[str | Path] | str | Path) -> list[Document]:\n \"\"\"Ingest the file paths into Document\n\n Args:\n file_paths: list of file paths or a single file path\n\n Returns:\n list of parsed Documents\n \"\"\"\n if not isinstance(file_paths, list):\n file_paths = [file_paths]\n\n documents = self._get_reader(input_files=file_paths)()\n print(f\"Read {len(file_paths)} files into {len(documents)} documents.\")\n nodes = self.text_splitter(documents)\n print(f\"Transform {len(documents)} documents into {len(nodes)} nodes.\")\n self.log_progress(\".num_docs\", num_docs=len(nodes))\n\n # document parsers call\n if self.doc_parsers:\n for parser in self.doc_parsers:\n nodes = parser(nodes)\n\n return nodes\n
Name Type Description Default file_pathslist[str | Path] | str | Path
list of file paths or a single file path
required
Returns:
Type Description list[Document]
list of parsed Documents
Source code in libs/kotaemon/kotaemon/indices/ingests/files.py
def run(self, file_paths: list[str | Path] | str | Path) -> list[Document]:\n \"\"\"Ingest the file paths into Document\n\n Args:\n file_paths: list of file paths or a single file path\n\n Returns:\n list of parsed Documents\n \"\"\"\n if not isinstance(file_paths, list):\n file_paths = [file_paths]\n\n documents = self._get_reader(input_files=file_paths)()\n print(f\"Read {len(file_paths)} files into {len(documents)} documents.\")\n nodes = self.text_splitter(documents)\n print(f\"Transform {len(documents)} documents into {len(nodes)} nodes.\")\n self.log_progress(\".num_docs\", num_docs=len(nodes))\n\n # document parsers call\n if self.doc_parsers:\n for parser in self.doc_parsers:\n nodes = parser(nodes)\n\n return nodes\n
Ingest common office document types into Document for indexing
Document types
pdf
xlsx, xls
docx, doc
Parameters:
Name Type Description Default pdf_mode
mode for pdf extraction, one of \"normal\", \"mathpix\", \"ocr\" - normal: parse pdf text - mathpix: parse pdf text using mathpix - ocr: parse pdf image using flax
required doc_parsers
list of document parsers to parse the document
required text_splitter
splitter to split the document into text nodes
required override_file_extractors
override file extractors for specific file extensions The default file extractors are stored in KH_DEFAULT_FILE_EXTRACTORS
required Source code in libs/kotaemon/kotaemon/indices/ingests/files.py
class DocumentIngestor(BaseComponent):\n \"\"\"Ingest common office document types into Document for indexing\n\n Document types:\n - pdf\n - xlsx, xls\n - docx, doc\n\n Args:\n pdf_mode: mode for pdf extraction, one of \"normal\", \"mathpix\", \"ocr\"\n - normal: parse pdf text\n - mathpix: parse pdf text using mathpix\n - ocr: parse pdf image using flax\n doc_parsers: list of document parsers to parse the document\n text_splitter: splitter to split the document into text nodes\n override_file_extractors: override file extractors for specific file extensions\n The default file extractors are stored in `KH_DEFAULT_FILE_EXTRACTORS`\n \"\"\"\n\n pdf_mode: str = \"normal\" # \"normal\", \"mathpix\", \"ocr\", \"multimodal\"\n doc_parsers: list[BaseDocParser] = Param(default_callback=lambda _: [])\n text_splitter: BaseSplitter = TokenSplitter.withx(\n chunk_size=1024,\n chunk_overlap=256,\n separator=\"\\n\\n\",\n backup_separators=[\"\\n\", \".\", \" \", \"\\u200B\"],\n )\n override_file_extractors: dict[str, Type[BaseReader]] = {}\n\n def _get_reader(self, input_files: list[str | Path]):\n \"\"\"Get appropriate readers for the input files based on file extension\"\"\"\n file_extractors: dict[str, BaseReader] = {\n ext: reader for ext, reader in KH_DEFAULT_FILE_EXTRACTORS.items()\n }\n for ext, cls in self.override_file_extractors.items():\n file_extractors[ext] = cls()\n\n if self.pdf_mode == \"normal\":\n file_extractors[\".pdf\"] = PDFReader()\n elif self.pdf_mode == \"ocr\":\n file_extractors[\".pdf\"] = OCRReader()\n elif self.pdf_mode == \"multimodal\":\n file_extractors[\".pdf\"] = AdobeReader()\n else:\n file_extractors[\".pdf\"] = MathpixPDFReader()\n\n main_reader = DirectoryReader(\n input_files=input_files,\n file_extractor=file_extractors,\n )\n\n return main_reader\n\n def run(self, file_paths: list[str | Path] | str | Path) -> list[Document]:\n \"\"\"Ingest the file paths into Document\n\n Args:\n file_paths: list of file paths or a single file path\n\n Returns:\n list of parsed Documents\n \"\"\"\n if not isinstance(file_paths, list):\n file_paths = [file_paths]\n\n documents = self._get_reader(input_files=file_paths)()\n print(f\"Read {len(file_paths)} files into {len(documents)} documents.\")\n nodes = self.text_splitter(documents)\n print(f\"Transform {len(documents)} documents into {len(nodes)} nodes.\")\n self.log_progress(\".num_docs\", num_docs=len(nodes))\n\n # document parsers call\n if self.doc_parsers:\n for parser in self.doc_parsers:\n nodes = parser(nodes)\n\n return nodes\n
Name Type Description Default file_pathslist[str | Path] | str | Path
list of file paths or a single file path
required
Returns:
Type Description list[Document]
list of parsed Documents
Source code in libs/kotaemon/kotaemon/indices/ingests/files.py
def run(self, file_paths: list[str | Path] | str | Path) -> list[Document]:\n \"\"\"Ingest the file paths into Document\n\n Args:\n file_paths: list of file paths or a single file path\n\n Returns:\n list of parsed Documents\n \"\"\"\n if not isinstance(file_paths, list):\n file_paths = [file_paths]\n\n documents = self._get_reader(input_files=file_paths)()\n print(f\"Read {len(file_paths)} files into {len(documents)} documents.\")\n nodes = self.text_splitter(documents)\n print(f\"Transform {len(documents)} documents into {len(nodes)} nodes.\")\n self.log_progress(\".num_docs\", num_docs=len(nodes))\n\n # document parsers call\n if self.doc_parsers:\n for parser in self.doc_parsers:\n nodes = parser(nodes)\n\n return nodes\n
List of evidences (maximum 5) to support the answer.
Source code in libs/kotaemon/kotaemon/indices/qa/citation.py
class CiteEvidence(BaseModel):\n \"\"\"List of evidences (maximum 5) to support the answer.\"\"\"\n\n evidences: List[str] = Field(\n ...,\n description=(\n \"Each source should be a direct quote from the context, \"\n \"as a substring of the original content (max 15 words).\"\n ),\n )\n
Source code in libs/kotaemon/kotaemon/indices/rankings/cohere.py
class CohereReranking(BaseReranking):\n model_name: str = \"rerank-multilingual-v2.0\"\n cohere_api_key: str = config(\"COHERE_API_KEY\", \"\")\n use_key_from_ktem: bool = False\n\n def run(self, documents: list[Document], query: str) -> list[Document]:\n \"\"\"Use Cohere Reranker model to re-order documents\n with their relevance score\"\"\"\n try:\n import cohere\n except ImportError:\n raise ImportError(\n \"Please install Cohere `pip install cohere` to use Cohere Reranking\"\n )\n\n # try to get COHERE_API_KEY from embeddings\n if not self.cohere_api_key and self.use_key_from_ktem:\n try:\n from ktem.embeddings.manager import (\n embedding_models_manager as embeddings,\n )\n\n cohere_model = embeddings.get(\"cohere\")\n ktem_cohere_api_key = cohere_model._kwargs.get( # type: ignore\n \"cohere_api_key\"\n )\n if ktem_cohere_api_key != \"your-key\":\n self.cohere_api_key = ktem_cohere_api_key\n except Exception as e:\n print(\"Cannot get Cohere API key from `ktem`\", e)\n\n if not self.cohere_api_key:\n print(\"Cohere API key not found. Skipping reranking.\")\n return documents\n\n cohere_client = cohere.Client(self.cohere_api_key)\n compressed_docs: list[Document] = []\n\n if not documents: # to avoid empty api call\n return compressed_docs\n\n _docs = [d.content for d in documents]\n response = cohere_client.rerank(\n model=self.model_name, query=query, documents=_docs\n )\n # print(\"Cohere score\", [r.relevance_score for r in response.results])\n for r in response.results:\n doc = documents[r.index]\n doc.metadata[\"cohere_reranking_score\"] = r.relevance_score\n compressed_docs.append(doc)\n\n return compressed_docs\n
Use Cohere Reranker model to re-order documents with their relevance score
Source code in libs/kotaemon/kotaemon/indices/rankings/cohere.py
def run(self, documents: list[Document], query: str) -> list[Document]:\n \"\"\"Use Cohere Reranker model to re-order documents\n with their relevance score\"\"\"\n try:\n import cohere\n except ImportError:\n raise ImportError(\n \"Please install Cohere `pip install cohere` to use Cohere Reranking\"\n )\n\n # try to get COHERE_API_KEY from embeddings\n if not self.cohere_api_key and self.use_key_from_ktem:\n try:\n from ktem.embeddings.manager import (\n embedding_models_manager as embeddings,\n )\n\n cohere_model = embeddings.get(\"cohere\")\n ktem_cohere_api_key = cohere_model._kwargs.get( # type: ignore\n \"cohere_api_key\"\n )\n if ktem_cohere_api_key != \"your-key\":\n self.cohere_api_key = ktem_cohere_api_key\n except Exception as e:\n print(\"Cannot get Cohere API key from `ktem`\", e)\n\n if not self.cohere_api_key:\n print(\"Cohere API key not found. Skipping reranking.\")\n return documents\n\n cohere_client = cohere.Client(self.cohere_api_key)\n compressed_docs: list[Document] = []\n\n if not documents: # to avoid empty api call\n return compressed_docs\n\n _docs = [d.content for d in documents]\n response = cohere_client.rerank(\n model=self.model_name, query=query, documents=_docs\n )\n # print(\"Cohere score\", [r.relevance_score for r in response.results])\n for r in response.results:\n doc = documents[r.index]\n doc.metadata[\"cohere_reranking_score\"] = r.relevance_score\n compressed_docs.append(doc)\n\n return compressed_docs\n
Source code in libs/kotaemon/kotaemon/indices/rankings/llm.py
class LLMReranking(BaseReranking):\n llm: BaseLLM\n prompt_template: PromptTemplate = PromptTemplate(template=RERANK_PROMPT_TEMPLATE)\n top_k: int = 3\n concurrent: bool = True\n\n def run(\n self,\n documents: list[Document],\n query: str,\n ) -> list[Document]:\n \"\"\"Filter down documents based on their relevance to the query.\"\"\"\n filtered_docs = []\n output_parser = BooleanOutputParser()\n\n if self.concurrent:\n with ThreadPoolExecutor() as executor:\n futures = []\n for doc in documents:\n _prompt = self.prompt_template.populate(\n question=query, context=doc.get_content()\n )\n futures.append(executor.submit(lambda: self.llm(_prompt).text))\n\n results = [future.result() for future in futures]\n else:\n results = []\n for doc in documents:\n _prompt = self.prompt_template.populate(\n question=query, context=doc.get_content()\n )\n results.append(self.llm(_prompt).text)\n\n # use Boolean parser to extract relevancy output from LLM\n results = [output_parser.parse(result) for result in results]\n for include_doc, doc in zip(results, documents):\n if include_doc:\n filtered_docs.append(doc)\n\n # prevent returning empty result\n if len(filtered_docs) == 0:\n filtered_docs = documents[: self.top_k]\n\n return filtered_docs\n
Filter down documents based on their relevance to the query.
Source code in libs/kotaemon/kotaemon/indices/rankings/llm.py
def run(\n self,\n documents: list[Document],\n query: str,\n) -> list[Document]:\n \"\"\"Filter down documents based on their relevance to the query.\"\"\"\n filtered_docs = []\n output_parser = BooleanOutputParser()\n\n if self.concurrent:\n with ThreadPoolExecutor() as executor:\n futures = []\n for doc in documents:\n _prompt = self.prompt_template.populate(\n question=query, context=doc.get_content()\n )\n futures.append(executor.submit(lambda: self.llm(_prompt).text))\n\n results = [future.result() for future in futures]\n else:\n results = []\n for doc in documents:\n _prompt = self.prompt_template.populate(\n question=query, context=doc.get_content()\n )\n results.append(self.llm(_prompt).text)\n\n # use Boolean parser to extract relevancy output from LLM\n results = [output_parser.parse(result) for result in results]\n for include_doc, doc in zip(results, documents):\n if include_doc:\n filtered_docs.append(doc)\n\n # prevent returning empty result\n if len(filtered_docs) == 0:\n filtered_docs = documents[: self.top_k]\n\n return filtered_docs\n
Source code in libs/kotaemon/kotaemon/indices/rankings/cohere.py
class CohereReranking(BaseReranking):\n model_name: str = \"rerank-multilingual-v2.0\"\n cohere_api_key: str = config(\"COHERE_API_KEY\", \"\")\n use_key_from_ktem: bool = False\n\n def run(self, documents: list[Document], query: str) -> list[Document]:\n \"\"\"Use Cohere Reranker model to re-order documents\n with their relevance score\"\"\"\n try:\n import cohere\n except ImportError:\n raise ImportError(\n \"Please install Cohere `pip install cohere` to use Cohere Reranking\"\n )\n\n # try to get COHERE_API_KEY from embeddings\n if not self.cohere_api_key and self.use_key_from_ktem:\n try:\n from ktem.embeddings.manager import (\n embedding_models_manager as embeddings,\n )\n\n cohere_model = embeddings.get(\"cohere\")\n ktem_cohere_api_key = cohere_model._kwargs.get( # type: ignore\n \"cohere_api_key\"\n )\n if ktem_cohere_api_key != \"your-key\":\n self.cohere_api_key = ktem_cohere_api_key\n except Exception as e:\n print(\"Cannot get Cohere API key from `ktem`\", e)\n\n if not self.cohere_api_key:\n print(\"Cohere API key not found. Skipping reranking.\")\n return documents\n\n cohere_client = cohere.Client(self.cohere_api_key)\n compressed_docs: list[Document] = []\n\n if not documents: # to avoid empty api call\n return compressed_docs\n\n _docs = [d.content for d in documents]\n response = cohere_client.rerank(\n model=self.model_name, query=query, documents=_docs\n )\n # print(\"Cohere score\", [r.relevance_score for r in response.results])\n for r in response.results:\n doc = documents[r.index]\n doc.metadata[\"cohere_reranking_score\"] = r.relevance_score\n compressed_docs.append(doc)\n\n return compressed_docs\n
Use Cohere Reranker model to re-order documents with their relevance score
Source code in libs/kotaemon/kotaemon/indices/rankings/cohere.py
def run(self, documents: list[Document], query: str) -> list[Document]:\n \"\"\"Use Cohere Reranker model to re-order documents\n with their relevance score\"\"\"\n try:\n import cohere\n except ImportError:\n raise ImportError(\n \"Please install Cohere `pip install cohere` to use Cohere Reranking\"\n )\n\n # try to get COHERE_API_KEY from embeddings\n if not self.cohere_api_key and self.use_key_from_ktem:\n try:\n from ktem.embeddings.manager import (\n embedding_models_manager as embeddings,\n )\n\n cohere_model = embeddings.get(\"cohere\")\n ktem_cohere_api_key = cohere_model._kwargs.get( # type: ignore\n \"cohere_api_key\"\n )\n if ktem_cohere_api_key != \"your-key\":\n self.cohere_api_key = ktem_cohere_api_key\n except Exception as e:\n print(\"Cannot get Cohere API key from `ktem`\", e)\n\n if not self.cohere_api_key:\n print(\"Cohere API key not found. Skipping reranking.\")\n return documents\n\n cohere_client = cohere.Client(self.cohere_api_key)\n compressed_docs: list[Document] = []\n\n if not documents: # to avoid empty api call\n return compressed_docs\n\n _docs = [d.content for d in documents]\n response = cohere_client.rerank(\n model=self.model_name, query=query, documents=_docs\n )\n # print(\"Cohere score\", [r.relevance_score for r in response.results])\n for r in response.results:\n doc = documents[r.index]\n doc.metadata[\"cohere_reranking_score\"] = r.relevance_score\n compressed_docs.append(doc)\n\n return compressed_docs\n
Source code in libs/kotaemon/kotaemon/indices/rankings/llm.py
class LLMReranking(BaseReranking):\n llm: BaseLLM\n prompt_template: PromptTemplate = PromptTemplate(template=RERANK_PROMPT_TEMPLATE)\n top_k: int = 3\n concurrent: bool = True\n\n def run(\n self,\n documents: list[Document],\n query: str,\n ) -> list[Document]:\n \"\"\"Filter down documents based on their relevance to the query.\"\"\"\n filtered_docs = []\n output_parser = BooleanOutputParser()\n\n if self.concurrent:\n with ThreadPoolExecutor() as executor:\n futures = []\n for doc in documents:\n _prompt = self.prompt_template.populate(\n question=query, context=doc.get_content()\n )\n futures.append(executor.submit(lambda: self.llm(_prompt).text))\n\n results = [future.result() for future in futures]\n else:\n results = []\n for doc in documents:\n _prompt = self.prompt_template.populate(\n question=query, context=doc.get_content()\n )\n results.append(self.llm(_prompt).text)\n\n # use Boolean parser to extract relevancy output from LLM\n results = [output_parser.parse(result) for result in results]\n for include_doc, doc in zip(results, documents):\n if include_doc:\n filtered_docs.append(doc)\n\n # prevent returning empty result\n if len(filtered_docs) == 0:\n filtered_docs = documents[: self.top_k]\n\n return filtered_docs\n
Filter down documents based on their relevance to the query.
Source code in libs/kotaemon/kotaemon/indices/rankings/llm.py
def run(\n self,\n documents: list[Document],\n query: str,\n) -> list[Document]:\n \"\"\"Filter down documents based on their relevance to the query.\"\"\"\n filtered_docs = []\n output_parser = BooleanOutputParser()\n\n if self.concurrent:\n with ThreadPoolExecutor() as executor:\n futures = []\n for doc in documents:\n _prompt = self.prompt_template.populate(\n question=query, context=doc.get_content()\n )\n futures.append(executor.submit(lambda: self.llm(_prompt).text))\n\n results = [future.result() for future in futures]\n else:\n results = []\n for doc in documents:\n _prompt = self.prompt_template.populate(\n question=query, context=doc.get_content()\n )\n results.append(self.llm(_prompt).text)\n\n # use Boolean parser to extract relevancy output from LLM\n results = [output_parser.parse(result) for result in results]\n for include_doc, doc in zip(results, documents):\n if include_doc:\n filtered_docs.append(doc)\n\n # prevent returning empty result\n if len(filtered_docs) == 0:\n filtered_docs = documents[: self.top_k]\n\n return filtered_docs\n
Source code in libs/kotaemon/kotaemon/indices/rankings/llm_trulens.py
def validate_rating(rating) -> int:\n \"\"\"Validate a rating is between 0 and 10.\"\"\"\n\n if not 0 <= rating <= 10:\n raise ValueError(\"Rating must be between 0 and 10\")\n\n return rating\n
If the string does not match an integer or matches an integer outside the 0-10 range, raises an error instead. If multiple numbers are found within the expected 0-10 range, the smallest is returned.
Parameters:
Name Type Description Default sstr
String to extract rating from.
required
Returns:
Name Type Description intint
Extracted rating.
Raises:
Type Description ParseError
If no integers between 0 and 10 are found in the string.
Source code in libs/kotaemon/kotaemon/indices/rankings/llm_trulens.py
def re_0_10_rating(s: str) -> int:\n \"\"\"Extract a 0-10 rating from a string.\n\n If the string does not match an integer or matches an integer outside the\n 0-10 range, raises an error instead. If multiple numbers are found within\n the expected 0-10 range, the smallest is returned.\n\n Args:\n s: String to extract rating from.\n\n Returns:\n int: Extracted rating.\n\n Raises:\n ParseError: If no integers between 0 and 10 are found in the string.\n \"\"\"\n\n matches = PATTERN_INTEGER.findall(s)\n if not matches:\n raise AssertionError\n\n vals = set()\n for match in matches:\n try:\n vals.add(validate_rating(int(match)))\n except ValueError:\n pass\n\n if not vals:\n raise AssertionError\n\n # Min to handle cases like \"The rating is 8 out of 10.\"\n return min(vals)\n
A simple gated branching pipeline for executing multiple branches based on a condition.
This class extends the SimpleBranchingPipeline class and adds the ability to execute the branches until a branch returns a non-empty output based on a condition.
Attributes:
Name Type Description branchesList[BaseComponent]
The list of branches to be executed.
Example
from kotaemon.llms import (\n LCAzureChatOpenAI,\n BasePromptComponent,\n GatedLinearPipeline,\n)\nfrom kotaemon.parsers import RegexExtractor\n\ndef identity(x):\n return x\n\npipeline = GatedBranchingPipeline()\nllm = LCAzureChatOpenAI(\n openai_api_base=\"your openai api base\",\n openai_api_key=\"your openai api key\",\n openai_api_version=\"your openai api version\",\n deployment_name=\"dummy-q2-gpt35\",\n temperature=0,\n request_timeout=600,\n)\n\nfor i in range(3):\n pipeline.add_branch(\n GatedLinearPipeline(\n prompt=BasePromptComponent(template=f\"what is {i} in Japanese ?\"),\n condition=RegexExtractor(pattern=f\"{i}\"),\n llm=llm,\n post_processor=identity,\n )\n )\nprint(pipeline(condition_text=\"1\"))\nprint(pipeline(condition_text=\"2\"))\n
Source code in libs/kotaemon/kotaemon/llms/branching.py
class GatedBranchingPipeline(SimpleBranchingPipeline):\n \"\"\"\n A simple gated branching pipeline for executing multiple branches based on a\n condition.\n\n This class extends the SimpleBranchingPipeline class and adds the ability to execute\n the branches until a branch returns a non-empty output based on a condition.\n\n Attributes:\n branches (List[BaseComponent]): The list of branches to be executed.\n\n Example:\n ```python\n from kotaemon.llms import (\n LCAzureChatOpenAI,\n BasePromptComponent,\n GatedLinearPipeline,\n )\n from kotaemon.parsers import RegexExtractor\n\n def identity(x):\n return x\n\n pipeline = GatedBranchingPipeline()\n llm = LCAzureChatOpenAI(\n openai_api_base=\"your openai api base\",\n openai_api_key=\"your openai api key\",\n openai_api_version=\"your openai api version\",\n deployment_name=\"dummy-q2-gpt35\",\n temperature=0,\n request_timeout=600,\n )\n\n for i in range(3):\n pipeline.add_branch(\n GatedLinearPipeline(\n prompt=BasePromptComponent(template=f\"what is {i} in Japanese ?\"),\n condition=RegexExtractor(pattern=f\"{i}\"),\n llm=llm,\n post_processor=identity,\n )\n )\n print(pipeline(condition_text=\"1\"))\n print(pipeline(condition_text=\"2\"))\n ```\n \"\"\"\n\n def run(self, *, condition_text: Optional[str] = None, **prompt_kwargs):\n \"\"\"\n Execute the pipeline by running each branch and return the output of the first\n branch that returns a non-empty output based on the provided condition.\n\n Args:\n condition_text (str): The condition text to evaluate for each branch.\n Default to None.\n **prompt_kwargs: Keyword arguments for the branches.\n\n Returns:\n Union[OutputType, None]: The output of the first branch that satisfies the\n condition, or None if no branch satisfies the condition.\n\n Raises:\n ValueError: If condition_text is None\n \"\"\"\n if condition_text is None:\n raise ValueError(\"`condition_text` must be provided.\")\n\n for i, branch in enumerate(self.branches):\n self._prepare_child(branch, name=f\"branch-{i}\")\n output = branch(condition_text=condition_text, **prompt_kwargs)\n if output:\n return output\n\n return Document(None)\n
Execute the pipeline by running each branch and return the output of the first branch that returns a non-empty output based on the provided condition.
Parameters:
Name Type Description Default condition_textstr
The condition text to evaluate for each branch. Default to None.
None**prompt_kwargs
Keyword arguments for the branches.
{}
Returns:
Type Description
Union[OutputType, None]: The output of the first branch that satisfies the
condition, or None if no branch satisfies the condition.
Raises:
Type Description ValueError
If condition_text is None
Source code in libs/kotaemon/kotaemon/llms/branching.py
def run(self, *, condition_text: Optional[str] = None, **prompt_kwargs):\n \"\"\"\n Execute the pipeline by running each branch and return the output of the first\n branch that returns a non-empty output based on the provided condition.\n\n Args:\n condition_text (str): The condition text to evaluate for each branch.\n Default to None.\n **prompt_kwargs: Keyword arguments for the branches.\n\n Returns:\n Union[OutputType, None]: The output of the first branch that satisfies the\n condition, or None if no branch satisfies the condition.\n\n Raises:\n ValueError: If condition_text is None\n \"\"\"\n if condition_text is None:\n raise ValueError(\"`condition_text` must be provided.\")\n\n for i, branch in enumerate(self.branches):\n self._prepare_child(branch, name=f\"branch-{i}\")\n output = branch(condition_text=condition_text, **prompt_kwargs)\n if output:\n return output\n\n return Document(None)\n
A simple branching pipeline for executing multiple branches.
Attributes:
Name Type Description branchesList[BaseComponent]
The list of branches to be executed.
Example
from kotaemon.llms import (\n LCAzureChatOpenAI,\n BasePromptComponent,\n GatedLinearPipeline,\n)\nfrom kotaemon.parsers import RegexExtractor\n\ndef identity(x):\n return x\n\npipeline = SimpleBranchingPipeline()\nllm = LCAzureChatOpenAI(\n openai_api_base=\"your openai api base\",\n openai_api_key=\"your openai api key\",\n openai_api_version=\"your openai api version\",\n deployment_name=\"dummy-q2-gpt35\",\n temperature=0,\n request_timeout=600,\n)\n\nfor i in range(3):\n pipeline.add_branch(\n GatedLinearPipeline(\n prompt=BasePromptComponent(template=f\"what is {i} in Japanese ?\"),\n condition=RegexExtractor(pattern=f\"{i}\"),\n llm=llm,\n post_processor=identity,\n )\n )\nprint(pipeline(condition_text=\"1\"))\nprint(pipeline(condition_text=\"2\"))\nprint(pipeline(condition_text=\"12\"))\n
Source code in libs/kotaemon/kotaemon/llms/branching.py
class SimpleBranchingPipeline(BaseComponent):\n \"\"\"\n A simple branching pipeline for executing multiple branches.\n\n Attributes:\n branches (List[BaseComponent]): The list of branches to be executed.\n\n Example:\n ```python\n from kotaemon.llms import (\n LCAzureChatOpenAI,\n BasePromptComponent,\n GatedLinearPipeline,\n )\n from kotaemon.parsers import RegexExtractor\n\n def identity(x):\n return x\n\n pipeline = SimpleBranchingPipeline()\n llm = LCAzureChatOpenAI(\n openai_api_base=\"your openai api base\",\n openai_api_key=\"your openai api key\",\n openai_api_version=\"your openai api version\",\n deployment_name=\"dummy-q2-gpt35\",\n temperature=0,\n request_timeout=600,\n )\n\n for i in range(3):\n pipeline.add_branch(\n GatedLinearPipeline(\n prompt=BasePromptComponent(template=f\"what is {i} in Japanese ?\"),\n condition=RegexExtractor(pattern=f\"{i}\"),\n llm=llm,\n post_processor=identity,\n )\n )\n print(pipeline(condition_text=\"1\"))\n print(pipeline(condition_text=\"2\"))\n print(pipeline(condition_text=\"12\"))\n ```\n \"\"\"\n\n branches: List[BaseComponent] = Param(default_callback=lambda *_: [])\n\n def add_branch(self, component: BaseComponent):\n \"\"\"\n Add a new branch to the pipeline.\n\n Args:\n component (BaseComponent): The branch component to be added.\n \"\"\"\n self.branches.append(component)\n\n def run(self, **prompt_kwargs):\n \"\"\"\n Execute the pipeline by running each branch and return the outputs as a list.\n\n Args:\n **prompt_kwargs: Keyword arguments for the branches.\n\n Returns:\n List: The outputs of each branch as a list.\n \"\"\"\n output = []\n for i, branch in enumerate(self.branches):\n self._prepare_child(branch, name=f\"branch-{i}\")\n output.append(branch(**prompt_kwargs))\n\n return output\n
Name Type Description Default componentBaseComponent
The branch component to be added.
required Source code in libs/kotaemon/kotaemon/llms/branching.py
def add_branch(self, component: BaseComponent):\n \"\"\"\n Add a new branch to the pipeline.\n\n Args:\n component (BaseComponent): The branch component to be added.\n \"\"\"\n self.branches.append(component)\n
Execute the pipeline by running each branch and return the outputs as a list.
Parameters:
Name Type Description Default **prompt_kwargs
Keyword arguments for the branches.
{}
Returns:
Name Type Description List
The outputs of each branch as a list.
Source code in libs/kotaemon/kotaemon/llms/branching.py
def run(self, **prompt_kwargs):\n \"\"\"\n Execute the pipeline by running each branch and return the outputs as a list.\n\n Args:\n **prompt_kwargs: Keyword arguments for the branches.\n\n Returns:\n List: The outputs of each branch as a list.\n \"\"\"\n output = []\n for i, branch in enumerate(self.branches):\n self._prepare_child(branch, name=f\"branch-{i}\")\n output.append(branch(**prompt_kwargs))\n\n return output\n
Generate response from messages Args: messages (str | BaseMessage | list[BaseMessage]): history of messages to generate response from **kwargs: additional arguments to pass to the OpenAI API Returns: LLMInterface: generated response
Source code in libs/kotaemon/kotaemon/llms/chats/endpoint_based.py
def run(\n self, messages: str | BaseMessage | list[BaseMessage], **kwargs\n) -> LLMInterface:\n \"\"\"\n Generate response from messages\n Args:\n messages (str | BaseMessage | list[BaseMessage]): history of messages to\n generate response from\n **kwargs: additional arguments to pass to the OpenAI API\n Returns:\n LLMInterface: generated response\n \"\"\"\n if isinstance(messages, str):\n input_ = [HumanMessage(content=messages)]\n elif isinstance(messages, BaseMessage):\n input_ = [messages]\n else:\n input_ = messages\n\n def decide_role(message: BaseMessage):\n if isinstance(message, SystemMessage):\n return \"system\"\n elif isinstance(message, AIMessage):\n return \"assistant\"\n else:\n return \"user\"\n\n request_json = {\n \"messages\": [{\"content\": m.text, \"role\": decide_role(m)} for m in input_]\n }\n\n response = requests.post(self.endpoint_url, json=request_json).json()\n\n content = \"\"\n candidates = []\n if response[\"choices\"]:\n candidates = [\n each[\"message\"][\"content\"]\n for each in response[\"choices\"]\n if each[\"message\"][\"content\"]\n ]\n content = candidates[0]\n\n return LLMInterface(\n content=content,\n candidates=candidates,\n completion_tokens=response[\"usage\"][\"completion_tokens\"],\n total_tokens=response[\"usage\"][\"total_tokens\"],\n prompt_tokens=response[\"usage\"][\"prompt_tokens\"],\n )\n
Source code in libs/kotaemon/kotaemon/llms/chats/llamacpp.py
class LlamaCppChat(ChatLLM):\n \"\"\"Wrapper around the llama-cpp-python's Llama model\"\"\"\n\n model_path: Optional[str] = Param(\n help=\"Path to the model file. This is required to load the model.\",\n )\n repo_id: Optional[str] = Param(\n help=\"Id of a repo on the HuggingFace Hub in the form of `user_name/repo_name`.\"\n )\n filename: Optional[str] = Param(\n help=\"A filename or glob pattern to match the model file in the repo.\"\n )\n chat_format: str = Param(\n help=(\n \"Chat format to use. Please refer to llama_cpp.llama_chat_format for a \"\n \"list of supported formats. If blank, the chat format will be auto-\"\n \"inferred.\"\n ),\n required=True,\n )\n lora_base: Optional[str] = Param(None, help=\"Path to the base Lora model\")\n n_ctx: Optional[int] = Param(512, help=\"Text context, 0 = from model\")\n n_gpu_layers: Optional[int] = Param(\n 0,\n help=\"Number of layers to offload to GPU. If -1, all layers are offloaded\",\n )\n use_mmap: Optional[bool] = Param(\n True,\n help=(),\n )\n vocab_only: Optional[bool] = Param(\n False,\n help=\"If True, only the vocabulary is loaded. This is useful for debugging.\",\n )\n\n _role_mapper: dict[str, str] = {\n \"human\": \"user\",\n \"system\": \"system\",\n \"ai\": \"assistant\",\n }\n\n @Param.auto()\n def client_object(self) -> \"Llama\":\n \"\"\"Get the llama-cpp-python client object\"\"\"\n try:\n from llama_cpp import Llama\n except ImportError:\n raise ImportError(\n \"llama-cpp-python is not installed. \"\n \"Please install it using `pip install llama-cpp-python`\"\n )\n\n errors = []\n if not self.model_path and (not self.repo_id or not self.filename):\n errors.append(\n \"- `model_path` or `repo_id` and `filename` are required to load the\"\n \" model\"\n )\n\n if not self.chat_format:\n errors.append(\n \"- `chat_format` is required to know how to format the chat messages. \"\n \"Please refer to llama_cpp.llama_chat_format for a list of supported \"\n \"formats.\"\n )\n if errors:\n raise ValueError(\"\\n\".join(errors))\n\n if self.model_path:\n return Llama(\n model_path=cast(str, self.model_path),\n chat_format=self.chat_format,\n lora_base=self.lora_base,\n n_ctx=self.n_ctx,\n n_gpu_layers=self.n_gpu_layers,\n use_mmap=self.use_mmap,\n vocab_only=self.vocab_only,\n )\n else:\n return Llama.from_pretrained(\n repo_id=self.repo_id,\n filename=self.filename,\n chat_format=self.chat_format,\n lora_base=self.lora_base,\n n_ctx=self.n_ctx,\n n_gpu_layers=self.n_gpu_layers,\n use_mmap=self.use_mmap,\n vocab_only=self.vocab_only,\n )\n\n def prepare_message(\n self, messages: str | BaseMessage | list[BaseMessage]\n ) -> list[dict]:\n input_: list[BaseMessage] = []\n\n if isinstance(messages, str):\n input_ = [HumanMessage(content=messages)]\n elif isinstance(messages, BaseMessage):\n input_ = [messages]\n else:\n input_ = messages\n\n output_ = [\n {\"role\": self._role_mapper[each.type], \"content\": each.content}\n for each in input_\n ]\n\n return output_\n\n def invoke(\n self, messages: str | BaseMessage | list[BaseMessage], **kwargs\n ) -> LLMInterface:\n\n pred: \"CCCR\" = self.client_object.create_chat_completion(\n messages=self.prepare_message(messages),\n stream=False,\n )\n\n return LLMInterface(\n content=pred[\"choices\"][0][\"message\"][\"content\"] if pred[\"choices\"] else \"\",\n candidates=[\n c[\"message\"][\"content\"]\n for c in pred[\"choices\"]\n if c[\"message\"][\"content\"]\n ],\n completion_tokens=pred[\"usage\"][\"completion_tokens\"],\n total_tokens=pred[\"usage\"][\"total_tokens\"],\n prompt_tokens=pred[\"usage\"][\"prompt_tokens\"],\n )\n\n def stream(\n self, messages: str | BaseMessage | list[BaseMessage], **kwargs\n ) -> Iterator[LLMInterface]:\n pred = self.client_object.create_chat_completion(\n messages=self.prepare_message(messages),\n stream=True,\n )\n for chunk in pred:\n if not chunk[\"choices\"]:\n continue\n\n if \"content\" not in chunk[\"choices\"][0][\"delta\"]:\n continue\n\n yield LLMInterface(content=chunk[\"choices\"][0][\"delta\"][\"content\"])\n
Source code in libs/kotaemon/kotaemon/llms/chats/llamacpp.py
@Param.auto()\ndef client_object(self) -> \"Llama\":\n \"\"\"Get the llama-cpp-python client object\"\"\"\n try:\n from llama_cpp import Llama\n except ImportError:\n raise ImportError(\n \"llama-cpp-python is not installed. \"\n \"Please install it using `pip install llama-cpp-python`\"\n )\n\n errors = []\n if not self.model_path and (not self.repo_id or not self.filename):\n errors.append(\n \"- `model_path` or `repo_id` and `filename` are required to load the\"\n \" model\"\n )\n\n if not self.chat_format:\n errors.append(\n \"- `chat_format` is required to know how to format the chat messages. \"\n \"Please refer to llama_cpp.llama_chat_format for a list of supported \"\n \"formats.\"\n )\n if errors:\n raise ValueError(\"\\n\".join(errors))\n\n if self.model_path:\n return Llama(\n model_path=cast(str, self.model_path),\n chat_format=self.chat_format,\n lora_base=self.lora_base,\n n_ctx=self.n_ctx,\n n_gpu_layers=self.n_gpu_layers,\n use_mmap=self.use_mmap,\n vocab_only=self.vocab_only,\n )\n else:\n return Llama.from_pretrained(\n repo_id=self.repo_id,\n filename=self.filename,\n chat_format=self.chat_format,\n lora_base=self.lora_base,\n n_ctx=self.n_ctx,\n n_gpu_layers=self.n_gpu_layers,\n use_mmap=self.use_mmap,\n vocab_only=self.vocab_only,\n )\n
Perform sequential chain-of-thought with manual pre-defined prompts
This method supports variable number of steps. Each step corresponds to a kotaemon.pipelines.cot.Thought. Please refer that section for Thought's detail. This section is about chaining thought together.
Usage:
Create and run a chain of thought without \"+\" operator:
>>> from kotaemon.pipelines.cot import Thought, ManualSequentialChainOfThought\n>>> llm = LCAzureChatOpenAI(...)\n>>> thought1 = Thought(\n>>> prompt=\"Word {word} in {language} is \",\n>>> post_process=lambda string: {\"translated\": string},\n>>> )\n>>> thought2 = Thought(\n>>> prompt=\"Translate {translated} to Japanese\",\n>>> post_process=lambda string: {\"output\": string},\n>>> )\n>>> thought = ManualSequentialChainOfThought(thoughts=[thought1, thought2], llm=llm)\n>>> thought(word=\"hello\", language=\"French\")\n{'word': 'hello',\n 'language': 'French',\n 'translated': '\"Bonjour\"',\n 'output': '\u3053\u3093\u306b\u3061\u306f (Konnichiwa)'}\n
Create and run a chain of thought without \"+\" operator: Please refer the kotaemon.pipelines.cot.Thought section for examples.
This chain-of-thought optionally takes a termination check callback function. This function will be called after each thought is executed. It takes in a dictionary of all thought outputs so far, and it returns True or False. If True, the chain-of-thought will terminate. If unset, the default callback always returns False.
Source code in libs/kotaemon/kotaemon/llms/cot.py
class ManualSequentialChainOfThought(BaseComponent):\n \"\"\"Perform sequential chain-of-thought with manual pre-defined prompts\n\n This method supports variable number of steps. Each step corresponds to a\n `kotaemon.pipelines.cot.Thought`. Please refer that section for\n Thought's detail. This section is about chaining thought together.\n\n _**Usage:**_\n\n **Create and run a chain of thought without \"+\" operator:**\n\n ```pycon\n >>> from kotaemon.pipelines.cot import Thought, ManualSequentialChainOfThought\n >>> llm = LCAzureChatOpenAI(...)\n >>> thought1 = Thought(\n >>> prompt=\"Word {word} in {language} is \",\n >>> post_process=lambda string: {\"translated\": string},\n >>> )\n >>> thought2 = Thought(\n >>> prompt=\"Translate {translated} to Japanese\",\n >>> post_process=lambda string: {\"output\": string},\n >>> )\n >>> thought = ManualSequentialChainOfThought(thoughts=[thought1, thought2], llm=llm)\n >>> thought(word=\"hello\", language=\"French\")\n {'word': 'hello',\n 'language': 'French',\n 'translated': '\"Bonjour\"',\n 'output': '\u3053\u3093\u306b\u3061\u306f (Konnichiwa)'}\n ```\n\n **Create and run a chain of thought without \"+\" operator:** Please refer the\n `kotaemon.pipelines.cot.Thought` section for examples.\n\n This chain-of-thought optionally takes a termination check callback function.\n This function will be called after each thought is executed. It takes in a\n dictionary of all thought outputs so far, and it returns True or False. If\n True, the chain-of-thought will terminate. If unset, the default callback always\n returns False.\n \"\"\"\n\n thoughts: List[Thought] = Param(\n default_callback=lambda *_: [], help=\"List of Thought\"\n )\n llm: LLM = Param(help=\"The LLM model to use (base of kotaemon.llms.BaseLLM)\")\n terminate: Callable = Param(\n default=lambda _: False,\n help=\"Callback on terminate condition. Default to always return False\",\n )\n\n def run(self, **kwargs) -> Document:\n \"\"\"Run the manual chain of thought\"\"\"\n\n inputs = deepcopy(kwargs)\n for idx, thought in enumerate(self.thoughts):\n if self.llm:\n thought.llm = self.llm\n self._prepare_child(thought, f\"thought{idx}\")\n\n output = thought(**inputs)\n inputs.update(output.content)\n if self.terminate(inputs):\n break\n\n return Document(inputs)\n\n def __add__(self, next_thought: Thought) -> \"ManualSequentialChainOfThought\":\n return ManualSequentialChainOfThought(\n thoughts=self.thoughts + [next_thought], llm=self.llm\n )\n
def run(self, **kwargs) -> Document:\n \"\"\"Run the manual chain of thought\"\"\"\n\n inputs = deepcopy(kwargs)\n for idx, thought in enumerate(self.thoughts):\n if self.llm:\n thought.llm = self.llm\n self._prepare_child(thought, f\"thought{idx}\")\n\n output = thought(**inputs)\n inputs.update(output.content)\n if self.terminate(inputs):\n break\n\n return Document(inputs)\n
Input: **kwargs pairs, where key is the placeholder in the prompt, and value is the value.
Output: an output dictionary
Usage:
Create and run a thought:
>> from kotaemon.pipelines.cot import Thought\n>> thought = Thought(\n prompt=\"How to {action} {object}?\",\n llm=LCAzureChatOpenAI(...),\n post_process=lambda string: {\"tutorial\": string},\n )\n>> output = thought(action=\"install\", object=\"python\")\n>> print(output)\n{'tutorial': 'As an AI language model,...'}\n
Basically, when a thought is run, it will:
Populate the prompt template with the input **kwargs.
Run the LLM model with the populated prompt.
Post-process the LLM output with the post-processor.
This Thought allows chaining sequentially with the + operator. For example:
Under the hood, when the + operator is used, a ManualSequentialChainOfThought is created.
Source code in libs/kotaemon/kotaemon/llms/cot.py
class Thought(BaseComponent):\n \"\"\"A thought in the chain of thought\n\n - Input: `**kwargs` pairs, where key is the placeholder in the prompt, and\n value is the value.\n - Output: an output dictionary\n\n _**Usage:**_\n\n Create and run a thought:\n\n ```python\n >> from kotaemon.pipelines.cot import Thought\n >> thought = Thought(\n prompt=\"How to {action} {object}?\",\n llm=LCAzureChatOpenAI(...),\n post_process=lambda string: {\"tutorial\": string},\n )\n >> output = thought(action=\"install\", object=\"python\")\n >> print(output)\n {'tutorial': 'As an AI language model,...'}\n ```\n\n Basically, when a thought is run, it will:\n\n 1. Populate the prompt template with the input `**kwargs`.\n 2. Run the LLM model with the populated prompt.\n 3. Post-process the LLM output with the post-processor.\n\n This `Thought` allows chaining sequentially with the + operator. For example:\n\n ```python\n >> llm = LCAzureChatOpenAI(...)\n >> thought1 = Thought(\n prompt=\"Word {word} in {language} is \",\n llm=llm,\n post_process=lambda string: {\"translated\": string},\n )\n >> thought2 = Thought(\n prompt=\"Translate {translated} to Japanese\",\n llm=llm,\n post_process=lambda string: {\"output\": string},\n )\n\n >> thought = thought1 + thought2\n >> thought(word=\"hello\", language=\"French\")\n {'word': 'hello',\n 'language': 'French',\n 'translated': '\"Bonjour\"',\n 'output': '\u3053\u3093\u306b\u3061\u306f (Konnichiwa)'}\n ```\n\n Under the hood, when the `+` operator is used, a `ManualSequentialChainOfThought`\n is created.\n \"\"\"\n\n prompt: str = Param(\n help=(\n \"The prompt template string. This prompt template has Python-like variable\"\n \" placeholders, that then will be substituted with real values when this\"\n \" component is executed\"\n )\n )\n llm: LLM = Node(LCAzureChatOpenAI, help=\"The LLM model to execute the input prompt\")\n post_process: Function = Node(\n help=(\n \"The function post-processor that post-processes LLM output prediction .\"\n \"It should take a string as input (this is the LLM output text) and return \"\n \"a dictionary, where the key should\"\n )\n )\n\n @Node.auto(depends_on=\"prompt\")\n def prompt_template(self):\n \"\"\"Automatically wrap around param prompt. Can ignore\"\"\"\n return BasePromptComponent(template=self.prompt)\n\n def run(self, **kwargs) -> Document:\n \"\"\"Run the chain of thought\"\"\"\n prompt = self.prompt_template(**kwargs).text\n response = self.llm(prompt).text\n response = self.post_process(response)\n\n return Document(response)\n\n def get_variables(self) -> List[str]:\n return []\n\n def __add__(self, next_thought: \"Thought\") -> \"ManualSequentialChainOfThought\":\n return ManualSequentialChainOfThought(\n thoughts=[self, next_thought], llm=self.llm\n )\n
A pipeline that extends the SimpleLinearPipeline class and adds a condition attribute.
Attributes:
Name Type Description conditionCallable[[IO_Type], Any]
A callable function that represents the condition.
Usage Example Usage
from kotaemon.llms import LCAzureChatOpenAI, BasePromptComponent\nfrom kotaemon.parsers import RegexExtractor\n\ndef identity(x):\n return x\n\nllm = LCAzureChatOpenAI(\n openai_api_base=\"your openai api base\",\n openai_api_key=\"your openai api key\",\n openai_api_version=\"your openai api version\",\n deployment_name=\"dummy-q2-gpt35\",\n temperature=0,\n request_timeout=600,\n)\n\npipeline = GatedLinearPipeline(\n prompt=BasePromptComponent(template=\"what is {word} in Japanese ?\"),\n condition=RegexExtractor(pattern=\"some pattern\"),\n llm=llm,\n post_processor=identity,\n)\nprint(pipeline(condition_text=\"some pattern\", word=\"lone\"))\nprint(pipeline(condition_text=\"other pattern\", word=\"lone\"))\n
Source code in libs/kotaemon/kotaemon/llms/linear.py
class GatedLinearPipeline(SimpleLinearPipeline):\n \"\"\"\n A pipeline that extends the SimpleLinearPipeline class and adds a condition\n attribute.\n\n Attributes:\n condition (Callable[[IO_Type], Any]): A callable function that represents the\n condition.\n\n Usage:\n ```{.py3 title=\"Example Usage\"}\n from kotaemon.llms import LCAzureChatOpenAI, BasePromptComponent\n from kotaemon.parsers import RegexExtractor\n\n def identity(x):\n return x\n\n llm = LCAzureChatOpenAI(\n openai_api_base=\"your openai api base\",\n openai_api_key=\"your openai api key\",\n openai_api_version=\"your openai api version\",\n deployment_name=\"dummy-q2-gpt35\",\n temperature=0,\n request_timeout=600,\n )\n\n pipeline = GatedLinearPipeline(\n prompt=BasePromptComponent(template=\"what is {word} in Japanese ?\"),\n condition=RegexExtractor(pattern=\"some pattern\"),\n llm=llm,\n post_processor=identity,\n )\n print(pipeline(condition_text=\"some pattern\", word=\"lone\"))\n print(pipeline(condition_text=\"other pattern\", word=\"lone\"))\n ```\n \"\"\"\n\n condition: Callable[[IO_Type], Any]\n\n def run(\n self,\n *,\n condition_text: Optional[str] = None,\n llm_kwargs: Optional[dict] = {},\n post_processor_kwargs: Optional[dict] = {},\n **prompt_kwargs,\n ) -> Document:\n \"\"\"\n Run the pipeline with the given arguments and return the final output as a\n Document object.\n\n Args:\n condition_text (str): The condition text to evaluate. Default to None.\n llm_kwargs (dict): Additional keyword arguments for the language model call.\n post_processor_kwargs (dict): Additional keyword arguments for the\n post-processor.\n **prompt_kwargs: Keyword arguments for populating the prompt.\n\n Returns:\n Document: The final output of the pipeline as a Document object.\n\n Raises:\n ValueError: If condition_text is None\n \"\"\"\n if condition_text is None:\n raise ValueError(\"`condition_text` must be provided\")\n\n if self.condition(condition_text)[0]:\n return super().run(\n llm_kwargs=llm_kwargs,\n post_processor_kwargs=post_processor_kwargs,\n **prompt_kwargs,\n )\n\n return Document(None)\n
Run the pipeline with the given arguments and return the final output as a Document object.
Parameters:
Name Type Description Default condition_textstr
The condition text to evaluate. Default to None.
Nonellm_kwargsdict
Additional keyword arguments for the language model call.
{}post_processor_kwargsdict
Additional keyword arguments for the post-processor.
{}**prompt_kwargs
Keyword arguments for populating the prompt.
{}
Returns:
Name Type Description DocumentDocument
The final output of the pipeline as a Document object.
Raises:
Type Description ValueError
If condition_text is None
Source code in libs/kotaemon/kotaemon/llms/linear.py
def run(\n self,\n *,\n condition_text: Optional[str] = None,\n llm_kwargs: Optional[dict] = {},\n post_processor_kwargs: Optional[dict] = {},\n **prompt_kwargs,\n) -> Document:\n \"\"\"\n Run the pipeline with the given arguments and return the final output as a\n Document object.\n\n Args:\n condition_text (str): The condition text to evaluate. Default to None.\n llm_kwargs (dict): Additional keyword arguments for the language model call.\n post_processor_kwargs (dict): Additional keyword arguments for the\n post-processor.\n **prompt_kwargs: Keyword arguments for populating the prompt.\n\n Returns:\n Document: The final output of the pipeline as a Document object.\n\n Raises:\n ValueError: If condition_text is None\n \"\"\"\n if condition_text is None:\n raise ValueError(\"`condition_text` must be provided\")\n\n if self.condition(condition_text)[0]:\n return super().run(\n llm_kwargs=llm_kwargs,\n post_processor_kwargs=post_processor_kwargs,\n **prompt_kwargs,\n )\n\n return Document(None)\n
from kotaemon.llms import LCAzureChatOpenAI, BasePromptComponent\n\ndef identity(x):\n return x\n\nllm = LCAzureChatOpenAI(\n openai_api_base=\"your openai api base\",\n openai_api_key=\"your openai api key\",\n openai_api_version=\"your openai api version\",\n deployment_name=\"dummy-q2-gpt35\",\n temperature=0,\n request_timeout=600,\n)\n\npipeline = SimpleLinearPipeline(\n prompt=BasePromptComponent(template=\"what is {word} in Japanese ?\"),\n llm=llm,\n post_processor=identity,\n)\nprint(pipeline(word=\"lone\"))\n
Source code in libs/kotaemon/kotaemon/llms/linear.py
class SimpleLinearPipeline(BaseComponent):\n \"\"\"\n A simple pipeline for running a function with a prompt, a language model, and an\n optional post-processor.\n\n Attributes:\n prompt (BasePromptComponent): The prompt component used to generate the initial\n input.\n llm (Union[ChatLLM, LLM]): The language model component used to generate the\n output.\n post_processor (Union[BaseComponent, Callable[[IO_Type], IO_Type]]): An optional\n post-processor component or function.\n\n Example Usage:\n ```python\n from kotaemon.llms import LCAzureChatOpenAI, BasePromptComponent\n\n def identity(x):\n return x\n\n llm = LCAzureChatOpenAI(\n openai_api_base=\"your openai api base\",\n openai_api_key=\"your openai api key\",\n openai_api_version=\"your openai api version\",\n deployment_name=\"dummy-q2-gpt35\",\n temperature=0,\n request_timeout=600,\n )\n\n pipeline = SimpleLinearPipeline(\n prompt=BasePromptComponent(template=\"what is {word} in Japanese ?\"),\n llm=llm,\n post_processor=identity,\n )\n print(pipeline(word=\"lone\"))\n ```\n \"\"\"\n\n prompt: BasePromptComponent\n llm: Union[ChatLLM, LLM]\n post_processor: Union[BaseComponent, Callable[[IO_Type], IO_Type]]\n\n def run(\n self,\n *,\n llm_kwargs: Optional[dict] = {},\n post_processor_kwargs: Optional[dict] = {},\n **prompt_kwargs,\n ):\n \"\"\"\n Run the function with the given arguments and return the final output as a\n Document object.\n\n Args:\n llm_kwargs (dict): Keyword arguments for the llm call.\n post_processor_kwargs (dict): Keyword arguments for the post_processor.\n **prompt_kwargs: Keyword arguments for populating the prompt.\n\n Returns:\n Document: The final output of the function as a Document object.\n \"\"\"\n prompt = self.prompt(**prompt_kwargs)\n llm_output = self.llm(prompt.text, **llm_kwargs)\n if self.post_processor is not None:\n final_output = self.post_processor(llm_output, **post_processor_kwargs)[0]\n else:\n final_output = llm_output\n\n return Document(final_output)\n
Run the function with the given arguments and return the final output as a Document object.
Parameters:
Name Type Description Default llm_kwargsdict
Keyword arguments for the llm call.
{}post_processor_kwargsdict
Keyword arguments for the post_processor.
{}**prompt_kwargs
Keyword arguments for populating the prompt.
{}
Returns:
Name Type Description Document
The final output of the function as a Document object.
Source code in libs/kotaemon/kotaemon/llms/linear.py
def run(\n self,\n *,\n llm_kwargs: Optional[dict] = {},\n post_processor_kwargs: Optional[dict] = {},\n **prompt_kwargs,\n):\n \"\"\"\n Run the function with the given arguments and return the final output as a\n Document object.\n\n Args:\n llm_kwargs (dict): Keyword arguments for the llm call.\n post_processor_kwargs (dict): Keyword arguments for the post_processor.\n **prompt_kwargs: Keyword arguments for populating the prompt.\n\n Returns:\n Document: The final output of the function as a Document object.\n \"\"\"\n prompt = self.prompt(**prompt_kwargs)\n llm_output = self.llm(prompt.text, **llm_kwargs)\n if self.post_processor is not None:\n final_output = self.post_processor(llm_output, **post_processor_kwargs)[0]\n else:\n final_output = llm_output\n\n return Document(final_output)\n
Name Type Description Default templatePromptTemplate
The prompt template.
required **kwargs
Any additional keyword arguments that will be used to populate the given template.
{} Source code in libs/kotaemon/kotaemon/llms/prompts/base.py
class BasePromptComponent(BaseComponent):\n \"\"\"\n Base class for prompt components.\n\n Args:\n template (PromptTemplate): The prompt template.\n **kwargs: Any additional keyword arguments that will be used to populate the\n given template.\n \"\"\"\n\n class Config:\n middleware_switches = {\"theflow.middleware.CachingMiddleware\": False}\n allow_extra = True\n\n template: str | PromptTemplate\n\n @Param.auto(depends_on=\"template\")\n def template__(self):\n return (\n self.template\n if isinstance(self.template, PromptTemplate)\n else PromptTemplate(self.template)\n )\n\n def __init__(self, **kwargs):\n super().__init__(**kwargs)\n self.__set(**kwargs)\n\n def __check_redundant_kwargs(self, **kwargs):\n \"\"\"\n Check for redundant keyword arguments.\n\n Parameters:\n **kwargs (dict): A dictionary of keyword arguments.\n\n Raises:\n ValueError: If any keys provided are not in the template.\n\n Returns:\n None\n \"\"\"\n self.template__.check_redundant_kwargs(**kwargs)\n\n def __check_unset_placeholders(self):\n \"\"\"\n Check if all the placeholders in the template are set.\n\n This function checks if all the expected placeholders in the template are set as\n attributes of the object. If any placeholders are missing, a `ValueError`\n is raised with the names of the missing keys.\n\n Parameters:\n None\n\n Returns:\n None\n \"\"\"\n self.template__.check_missing_kwargs(**self.__dict__)\n\n def __validate_value_type(self, **kwargs):\n \"\"\"\n Validates the value types of the given keyword arguments.\n\n Parameters:\n **kwargs (dict): A dictionary of keyword arguments to be validated.\n\n Raises:\n ValueError: If any of the values in the kwargs dictionary have an\n unsupported type.\n\n Returns:\n None\n \"\"\"\n type_error = []\n for k, v in kwargs.items():\n if k.startswith(\"template\"):\n continue\n if not isinstance(v, (str, int, Document, Callable)): # type: ignore\n type_error.append((k, type(v)))\n\n if type_error:\n raise ValueError(\n \"Type of values must be either int, str, Document, Callable, \"\n f\"found unsupported type for (key, type): {type_error}\"\n )\n\n def __set(self, **kwargs):\n \"\"\"\n Set the values of the attributes in the object based on the provided keyword\n arguments.\n\n Args:\n kwargs (dict): A dictionary with the attribute names as keys and the new\n values as values.\n\n Returns:\n None\n \"\"\"\n self.__check_redundant_kwargs(**kwargs)\n self.__validate_value_type(**kwargs)\n\n self.__dict__.update(kwargs)\n\n def __prepare_value(self):\n \"\"\"\n Generate a dictionary of keyword arguments based on the template's placeholders\n and the current instance's attributes.\n\n Returns:\n dict: A dictionary of keyword arguments.\n \"\"\"\n\n def __prepare(key, value):\n if isinstance(value, str):\n return value\n if isinstance(value, (int, Document)):\n return str(value)\n\n raise ValueError(\n f\"Unsupported type {type(value)} for template value of key {key}\"\n )\n\n kwargs = {}\n for k in self.template__.placeholders:\n v = getattr(self, k)\n\n # if get a callable, execute to get its output\n if isinstance(v, Callable): # type: ignore[arg-type]\n v = v()\n\n if isinstance(v, list):\n v = str([__prepare(k, each) for each in v])\n elif isinstance(v, (str, int, Document)):\n v = __prepare(k, v)\n else:\n raise ValueError(\n f\"Unsupported type {type(v)} for template value of key `{k}`\"\n )\n kwargs[k] = v\n\n return kwargs\n\n def set_value(self, **kwargs):\n \"\"\"\n Similar to `__set` but for external use.\n\n Set the values of the attributes in the object based on the provided keyword\n arguments.\n\n Args:\n kwargs (dict): A dictionary with the attribute names as keys and the new\n values as values.\n\n Returns:\n None\n \"\"\"\n self.__set(**kwargs)\n\n def run(self, **kwargs):\n \"\"\"\n Run the function with the given keyword arguments.\n\n Args:\n **kwargs: The keyword arguments to pass to the function.\n\n Returns:\n The result of calling the `populate` method of the `template` object\n with the given keyword arguments.\n \"\"\"\n self.__set(**kwargs)\n self.__check_unset_placeholders()\n prepared_kwargs = self.__prepare_value()\n\n text = self.template__.populate(**prepared_kwargs)\n return Document(text=text, metadata={\"origin\": \"PromptComponent\"})\n\n def flow(self):\n return self.__call__()\n
Set the values of the attributes in the object based on the provided keyword arguments.
Parameters:
Name Type Description Default kwargsdict
A dictionary with the attribute names as keys and the new values as values.
{}
Returns:
Type Description
None
Source code in libs/kotaemon/kotaemon/llms/prompts/base.py
def set_value(self, **kwargs):\n \"\"\"\n Similar to `__set` but for external use.\n\n Set the values of the attributes in the object based on the provided keyword\n arguments.\n\n Args:\n kwargs (dict): A dictionary with the attribute names as keys and the new\n values as values.\n\n Returns:\n None\n \"\"\"\n self.__set(**kwargs)\n
Run the function with the given keyword arguments.
Parameters:
Name Type Description Default **kwargs
The keyword arguments to pass to the function.
{}
Returns:
Type Description
The result of calling the populate method of the template object
with the given keyword arguments.
Source code in libs/kotaemon/kotaemon/llms/prompts/base.py
def run(self, **kwargs):\n \"\"\"\n Run the function with the given keyword arguments.\n\n Args:\n **kwargs: The keyword arguments to pass to the function.\n\n Returns:\n The result of calling the `populate` method of the `template` object\n with the given keyword arguments.\n \"\"\"\n self.__set(**kwargs)\n self.__check_unset_placeholders()\n prepared_kwargs = self.__prepare_value()\n\n text = self.template__.populate(**prepared_kwargs)\n return Document(text=text, metadata={\"origin\": \"PromptComponent\"})\n
Source code in libs/kotaemon/kotaemon/llms/prompts/template.py
class PromptTemplate:\n \"\"\"\n Base class for prompt templates.\n \"\"\"\n\n def __init__(self, template: str, ignore_invalid=True):\n template = template\n formatter = Formatter()\n parsed_template = list(formatter.parse(template))\n\n placeholders = set()\n for _, key, _, _ in parsed_template:\n if key is None:\n continue\n if not key.isidentifier():\n if ignore_invalid:\n warnings.warn(f\"Ignore invalid placeholder: {key}.\", UserWarning)\n else:\n raise ValueError(\n \"Placeholder name must be a valid Python identifier, found:\"\n f\" {key}.\"\n )\n placeholders.add(key)\n\n self.template = template\n self.placeholders = placeholders\n self.__formatter = formatter\n self.__parsed_template = parsed_template\n\n def check_missing_kwargs(self, **kwargs):\n \"\"\"\n Check if all the placeholders in the template are set.\n\n This function checks if all the expected placeholders in the template are set as\n attributes of the object. If any placeholders are missing, a `ValueError`\n is raised with the names of the missing keys.\n\n Parameters:\n None\n\n Returns:\n None\n \"\"\"\n missing_keys = self.placeholders.difference(kwargs.keys())\n if missing_keys:\n raise ValueError(f\"Missing keys in template: {','.join(missing_keys)}\")\n\n def check_redundant_kwargs(self, **kwargs):\n \"\"\"\n Check if all the placeholders in the template are set.\n\n This function checks if all the expected placeholders in the template are set as\n attributes of the object. If any placeholders are missing, a `ValueError`\n is raised with the names of the missing keys.\n\n Parameters:\n None\n\n Returns:\n None\n \"\"\"\n provided_keys = set(kwargs.keys())\n redundant_keys = provided_keys - self.placeholders\n\n if redundant_keys:\n warnings.warn(\n f\"Keys provided but not in template: {','.join(redundant_keys)}\",\n UserWarning,\n )\n\n def populate(self, **kwargs) -> str:\n \"\"\"\n Strictly populate the template with the given keyword arguments.\n\n Args:\n **kwargs: The keyword arguments to populate the template.\n Each keyword corresponds to a placeholder in the template.\n\n Returns:\n The populated template.\n\n Raises:\n ValueError: If an unknown placeholder is provided.\n \"\"\"\n self.check_missing_kwargs(**kwargs)\n\n return self.partial_populate(**kwargs)\n\n def partial_populate(self, **kwargs):\n \"\"\"\n Partially populate the template with the given keyword arguments.\n\n Args:\n **kwargs: The keyword arguments to populate the template.\n Each keyword corresponds to a placeholder in the template.\n\n Returns:\n str: The populated template.\n \"\"\"\n self.check_redundant_kwargs(**kwargs)\n\n prompt = []\n for literal_text, field_name, format_spec, conversion in self.__parsed_template:\n prompt.append(literal_text)\n\n if field_name is None:\n continue\n\n if field_name not in kwargs:\n if conversion:\n value = f\"{{{field_name}}}!{conversion}:{format_spec}\"\n else:\n value = f\"{{{field_name}:{format_spec}}}\"\n else:\n value = kwargs[field_name]\n if conversion is not None:\n value = self.__formatter.convert_field(value, conversion)\n if format_spec is not None:\n value = self.__formatter.format_field(value, format_spec)\n\n prompt.append(value)\n\n return \"\".join(prompt)\n\n def __add__(self, other):\n \"\"\"\n Create a new PromptTemplate object by concatenating the template of the current\n object with the template of another PromptTemplate object.\n\n Parameters:\n other (PromptTemplate): Another PromptTemplate object.\n\n Returns:\n PromptTemplate: A new PromptTemplate object with the concatenated templates.\n \"\"\"\n return PromptTemplate(self.template + \"\\n\" + other.template)\n
Check if all the placeholders in the template are set.
This function checks if all the expected placeholders in the template are set as attributes of the object. If any placeholders are missing, a ValueError is raised with the names of the missing keys.
Returns:
Type Description
None
Source code in libs/kotaemon/kotaemon/llms/prompts/template.py
def check_missing_kwargs(self, **kwargs):\n \"\"\"\n Check if all the placeholders in the template are set.\n\n This function checks if all the expected placeholders in the template are set as\n attributes of the object. If any placeholders are missing, a `ValueError`\n is raised with the names of the missing keys.\n\n Parameters:\n None\n\n Returns:\n None\n \"\"\"\n missing_keys = self.placeholders.difference(kwargs.keys())\n if missing_keys:\n raise ValueError(f\"Missing keys in template: {','.join(missing_keys)}\")\n
Check if all the placeholders in the template are set.
This function checks if all the expected placeholders in the template are set as attributes of the object. If any placeholders are missing, a ValueError is raised with the names of the missing keys.
Returns:
Type Description
None
Source code in libs/kotaemon/kotaemon/llms/prompts/template.py
def check_redundant_kwargs(self, **kwargs):\n \"\"\"\n Check if all the placeholders in the template are set.\n\n This function checks if all the expected placeholders in the template are set as\n attributes of the object. If any placeholders are missing, a `ValueError`\n is raised with the names of the missing keys.\n\n Parameters:\n None\n\n Returns:\n None\n \"\"\"\n provided_keys = set(kwargs.keys())\n redundant_keys = provided_keys - self.placeholders\n\n if redundant_keys:\n warnings.warn(\n f\"Keys provided but not in template: {','.join(redundant_keys)}\",\n UserWarning,\n )\n
Strictly populate the template with the given keyword arguments.
Parameters:
Name Type Description Default **kwargs
The keyword arguments to populate the template. Each keyword corresponds to a placeholder in the template.
{}
Returns:
Type Description str
The populated template.
Raises:
Type Description ValueError
If an unknown placeholder is provided.
Source code in libs/kotaemon/kotaemon/llms/prompts/template.py
def populate(self, **kwargs) -> str:\n \"\"\"\n Strictly populate the template with the given keyword arguments.\n\n Args:\n **kwargs: The keyword arguments to populate the template.\n Each keyword corresponds to a placeholder in the template.\n\n Returns:\n The populated template.\n\n Raises:\n ValueError: If an unknown placeholder is provided.\n \"\"\"\n self.check_missing_kwargs(**kwargs)\n\n return self.partial_populate(**kwargs)\n
Partially populate the template with the given keyword arguments.
Parameters:
Name Type Description Default **kwargs
The keyword arguments to populate the template. Each keyword corresponds to a placeholder in the template.
{}
Returns:
Name Type Description str
The populated template.
Source code in libs/kotaemon/kotaemon/llms/prompts/template.py
def partial_populate(self, **kwargs):\n \"\"\"\n Partially populate the template with the given keyword arguments.\n\n Args:\n **kwargs: The keyword arguments to populate the template.\n Each keyword corresponds to a placeholder in the template.\n\n Returns:\n str: The populated template.\n \"\"\"\n self.check_redundant_kwargs(**kwargs)\n\n prompt = []\n for literal_text, field_name, format_spec, conversion in self.__parsed_template:\n prompt.append(literal_text)\n\n if field_name is None:\n continue\n\n if field_name not in kwargs:\n if conversion:\n value = f\"{{{field_name}}}!{conversion}:{format_spec}\"\n else:\n value = f\"{{{field_name}:{format_spec}}}\"\n else:\n value = kwargs[field_name]\n if conversion is not None:\n value = self.__formatter.convert_field(value, conversion)\n if format_spec is not None:\n value = self.__formatter.format_field(value, format_spec)\n\n prompt.append(value)\n\n return \"\".join(prompt)\n
A simple branching pipeline for executing multiple branches.
Attributes:
Name Type Description branchesList[BaseComponent]
The list of branches to be executed.
Example
from kotaemon.llms import (\n LCAzureChatOpenAI,\n BasePromptComponent,\n GatedLinearPipeline,\n)\nfrom kotaemon.parsers import RegexExtractor\n\ndef identity(x):\n return x\n\npipeline = SimpleBranchingPipeline()\nllm = LCAzureChatOpenAI(\n openai_api_base=\"your openai api base\",\n openai_api_key=\"your openai api key\",\n openai_api_version=\"your openai api version\",\n deployment_name=\"dummy-q2-gpt35\",\n temperature=0,\n request_timeout=600,\n)\n\nfor i in range(3):\n pipeline.add_branch(\n GatedLinearPipeline(\n prompt=BasePromptComponent(template=f\"what is {i} in Japanese ?\"),\n condition=RegexExtractor(pattern=f\"{i}\"),\n llm=llm,\n post_processor=identity,\n )\n )\nprint(pipeline(condition_text=\"1\"))\nprint(pipeline(condition_text=\"2\"))\nprint(pipeline(condition_text=\"12\"))\n
Source code in libs/kotaemon/kotaemon/llms/branching.py
class SimpleBranchingPipeline(BaseComponent):\n \"\"\"\n A simple branching pipeline for executing multiple branches.\n\n Attributes:\n branches (List[BaseComponent]): The list of branches to be executed.\n\n Example:\n ```python\n from kotaemon.llms import (\n LCAzureChatOpenAI,\n BasePromptComponent,\n GatedLinearPipeline,\n )\n from kotaemon.parsers import RegexExtractor\n\n def identity(x):\n return x\n\n pipeline = SimpleBranchingPipeline()\n llm = LCAzureChatOpenAI(\n openai_api_base=\"your openai api base\",\n openai_api_key=\"your openai api key\",\n openai_api_version=\"your openai api version\",\n deployment_name=\"dummy-q2-gpt35\",\n temperature=0,\n request_timeout=600,\n )\n\n for i in range(3):\n pipeline.add_branch(\n GatedLinearPipeline(\n prompt=BasePromptComponent(template=f\"what is {i} in Japanese ?\"),\n condition=RegexExtractor(pattern=f\"{i}\"),\n llm=llm,\n post_processor=identity,\n )\n )\n print(pipeline(condition_text=\"1\"))\n print(pipeline(condition_text=\"2\"))\n print(pipeline(condition_text=\"12\"))\n ```\n \"\"\"\n\n branches: List[BaseComponent] = Param(default_callback=lambda *_: [])\n\n def add_branch(self, component: BaseComponent):\n \"\"\"\n Add a new branch to the pipeline.\n\n Args:\n component (BaseComponent): The branch component to be added.\n \"\"\"\n self.branches.append(component)\n\n def run(self, **prompt_kwargs):\n \"\"\"\n Execute the pipeline by running each branch and return the outputs as a list.\n\n Args:\n **prompt_kwargs: Keyword arguments for the branches.\n\n Returns:\n List: The outputs of each branch as a list.\n \"\"\"\n output = []\n for i, branch in enumerate(self.branches):\n self._prepare_child(branch, name=f\"branch-{i}\")\n output.append(branch(**prompt_kwargs))\n\n return output\n
Name Type Description Default componentBaseComponent
The branch component to be added.
required Source code in libs/kotaemon/kotaemon/llms/branching.py
def add_branch(self, component: BaseComponent):\n \"\"\"\n Add a new branch to the pipeline.\n\n Args:\n component (BaseComponent): The branch component to be added.\n \"\"\"\n self.branches.append(component)\n
Execute the pipeline by running each branch and return the outputs as a list.
Parameters:
Name Type Description Default **prompt_kwargs
Keyword arguments for the branches.
{}
Returns:
Name Type Description List
The outputs of each branch as a list.
Source code in libs/kotaemon/kotaemon/llms/branching.py
def run(self, **prompt_kwargs):\n \"\"\"\n Execute the pipeline by running each branch and return the outputs as a list.\n\n Args:\n **prompt_kwargs: Keyword arguments for the branches.\n\n Returns:\n List: The outputs of each branch as a list.\n \"\"\"\n output = []\n for i, branch in enumerate(self.branches):\n self._prepare_child(branch, name=f\"branch-{i}\")\n output.append(branch(**prompt_kwargs))\n\n return output\n
A simple gated branching pipeline for executing multiple branches based on a condition.
This class extends the SimpleBranchingPipeline class and adds the ability to execute the branches until a branch returns a non-empty output based on a condition.
Attributes:
Name Type Description branchesList[BaseComponent]
The list of branches to be executed.
Example
from kotaemon.llms import (\n LCAzureChatOpenAI,\n BasePromptComponent,\n GatedLinearPipeline,\n)\nfrom kotaemon.parsers import RegexExtractor\n\ndef identity(x):\n return x\n\npipeline = GatedBranchingPipeline()\nllm = LCAzureChatOpenAI(\n openai_api_base=\"your openai api base\",\n openai_api_key=\"your openai api key\",\n openai_api_version=\"your openai api version\",\n deployment_name=\"dummy-q2-gpt35\",\n temperature=0,\n request_timeout=600,\n)\n\nfor i in range(3):\n pipeline.add_branch(\n GatedLinearPipeline(\n prompt=BasePromptComponent(template=f\"what is {i} in Japanese ?\"),\n condition=RegexExtractor(pattern=f\"{i}\"),\n llm=llm,\n post_processor=identity,\n )\n )\nprint(pipeline(condition_text=\"1\"))\nprint(pipeline(condition_text=\"2\"))\n
Source code in libs/kotaemon/kotaemon/llms/branching.py
class GatedBranchingPipeline(SimpleBranchingPipeline):\n \"\"\"\n A simple gated branching pipeline for executing multiple branches based on a\n condition.\n\n This class extends the SimpleBranchingPipeline class and adds the ability to execute\n the branches until a branch returns a non-empty output based on a condition.\n\n Attributes:\n branches (List[BaseComponent]): The list of branches to be executed.\n\n Example:\n ```python\n from kotaemon.llms import (\n LCAzureChatOpenAI,\n BasePromptComponent,\n GatedLinearPipeline,\n )\n from kotaemon.parsers import RegexExtractor\n\n def identity(x):\n return x\n\n pipeline = GatedBranchingPipeline()\n llm = LCAzureChatOpenAI(\n openai_api_base=\"your openai api base\",\n openai_api_key=\"your openai api key\",\n openai_api_version=\"your openai api version\",\n deployment_name=\"dummy-q2-gpt35\",\n temperature=0,\n request_timeout=600,\n )\n\n for i in range(3):\n pipeline.add_branch(\n GatedLinearPipeline(\n prompt=BasePromptComponent(template=f\"what is {i} in Japanese ?\"),\n condition=RegexExtractor(pattern=f\"{i}\"),\n llm=llm,\n post_processor=identity,\n )\n )\n print(pipeline(condition_text=\"1\"))\n print(pipeline(condition_text=\"2\"))\n ```\n \"\"\"\n\n def run(self, *, condition_text: Optional[str] = None, **prompt_kwargs):\n \"\"\"\n Execute the pipeline by running each branch and return the output of the first\n branch that returns a non-empty output based on the provided condition.\n\n Args:\n condition_text (str): The condition text to evaluate for each branch.\n Default to None.\n **prompt_kwargs: Keyword arguments for the branches.\n\n Returns:\n Union[OutputType, None]: The output of the first branch that satisfies the\n condition, or None if no branch satisfies the condition.\n\n Raises:\n ValueError: If condition_text is None\n \"\"\"\n if condition_text is None:\n raise ValueError(\"`condition_text` must be provided.\")\n\n for i, branch in enumerate(self.branches):\n self._prepare_child(branch, name=f\"branch-{i}\")\n output = branch(condition_text=condition_text, **prompt_kwargs)\n if output:\n return output\n\n return Document(None)\n
Execute the pipeline by running each branch and return the output of the first branch that returns a non-empty output based on the provided condition.
Parameters:
Name Type Description Default condition_textstr
The condition text to evaluate for each branch. Default to None.
None**prompt_kwargs
Keyword arguments for the branches.
{}
Returns:
Type Description
Union[OutputType, None]: The output of the first branch that satisfies the
condition, or None if no branch satisfies the condition.
Raises:
Type Description ValueError
If condition_text is None
Source code in libs/kotaemon/kotaemon/llms/branching.py
def run(self, *, condition_text: Optional[str] = None, **prompt_kwargs):\n \"\"\"\n Execute the pipeline by running each branch and return the output of the first\n branch that returns a non-empty output based on the provided condition.\n\n Args:\n condition_text (str): The condition text to evaluate for each branch.\n Default to None.\n **prompt_kwargs: Keyword arguments for the branches.\n\n Returns:\n Union[OutputType, None]: The output of the first branch that satisfies the\n condition, or None if no branch satisfies the condition.\n\n Raises:\n ValueError: If condition_text is None\n \"\"\"\n if condition_text is None:\n raise ValueError(\"`condition_text` must be provided.\")\n\n for i, branch in enumerate(self.branches):\n self._prepare_child(branch, name=f\"branch-{i}\")\n output = branch(condition_text=condition_text, **prompt_kwargs)\n if output:\n return output\n\n return Document(None)\n
Input: **kwargs pairs, where key is the placeholder in the prompt, and value is the value.
Output: an output dictionary
Usage:
Create and run a thought:
>> from kotaemon.pipelines.cot import Thought\n>> thought = Thought(\n prompt=\"How to {action} {object}?\",\n llm=LCAzureChatOpenAI(...),\n post_process=lambda string: {\"tutorial\": string},\n )\n>> output = thought(action=\"install\", object=\"python\")\n>> print(output)\n{'tutorial': 'As an AI language model,...'}\n
Basically, when a thought is run, it will:
Populate the prompt template with the input **kwargs.
Run the LLM model with the populated prompt.
Post-process the LLM output with the post-processor.
This Thought allows chaining sequentially with the + operator. For example:
Under the hood, when the + operator is used, a ManualSequentialChainOfThought is created.
Source code in libs/kotaemon/kotaemon/llms/cot.py
class Thought(BaseComponent):\n \"\"\"A thought in the chain of thought\n\n - Input: `**kwargs` pairs, where key is the placeholder in the prompt, and\n value is the value.\n - Output: an output dictionary\n\n _**Usage:**_\n\n Create and run a thought:\n\n ```python\n >> from kotaemon.pipelines.cot import Thought\n >> thought = Thought(\n prompt=\"How to {action} {object}?\",\n llm=LCAzureChatOpenAI(...),\n post_process=lambda string: {\"tutorial\": string},\n )\n >> output = thought(action=\"install\", object=\"python\")\n >> print(output)\n {'tutorial': 'As an AI language model,...'}\n ```\n\n Basically, when a thought is run, it will:\n\n 1. Populate the prompt template with the input `**kwargs`.\n 2. Run the LLM model with the populated prompt.\n 3. Post-process the LLM output with the post-processor.\n\n This `Thought` allows chaining sequentially with the + operator. For example:\n\n ```python\n >> llm = LCAzureChatOpenAI(...)\n >> thought1 = Thought(\n prompt=\"Word {word} in {language} is \",\n llm=llm,\n post_process=lambda string: {\"translated\": string},\n )\n >> thought2 = Thought(\n prompt=\"Translate {translated} to Japanese\",\n llm=llm,\n post_process=lambda string: {\"output\": string},\n )\n\n >> thought = thought1 + thought2\n >> thought(word=\"hello\", language=\"French\")\n {'word': 'hello',\n 'language': 'French',\n 'translated': '\"Bonjour\"',\n 'output': '\u3053\u3093\u306b\u3061\u306f (Konnichiwa)'}\n ```\n\n Under the hood, when the `+` operator is used, a `ManualSequentialChainOfThought`\n is created.\n \"\"\"\n\n prompt: str = Param(\n help=(\n \"The prompt template string. This prompt template has Python-like variable\"\n \" placeholders, that then will be substituted with real values when this\"\n \" component is executed\"\n )\n )\n llm: LLM = Node(LCAzureChatOpenAI, help=\"The LLM model to execute the input prompt\")\n post_process: Function = Node(\n help=(\n \"The function post-processor that post-processes LLM output prediction .\"\n \"It should take a string as input (this is the LLM output text) and return \"\n \"a dictionary, where the key should\"\n )\n )\n\n @Node.auto(depends_on=\"prompt\")\n def prompt_template(self):\n \"\"\"Automatically wrap around param prompt. Can ignore\"\"\"\n return BasePromptComponent(template=self.prompt)\n\n def run(self, **kwargs) -> Document:\n \"\"\"Run the chain of thought\"\"\"\n prompt = self.prompt_template(**kwargs).text\n response = self.llm(prompt).text\n response = self.post_process(response)\n\n return Document(response)\n\n def get_variables(self) -> List[str]:\n return []\n\n def __add__(self, next_thought: \"Thought\") -> \"ManualSequentialChainOfThought\":\n return ManualSequentialChainOfThought(\n thoughts=[self, next_thought], llm=self.llm\n )\n
Perform sequential chain-of-thought with manual pre-defined prompts
This method supports variable number of steps. Each step corresponds to a kotaemon.pipelines.cot.Thought. Please refer that section for Thought's detail. This section is about chaining thought together.
Usage:
Create and run a chain of thought without \"+\" operator:
>>> from kotaemon.pipelines.cot import Thought, ManualSequentialChainOfThought\n>>> llm = LCAzureChatOpenAI(...)\n>>> thought1 = Thought(\n>>> prompt=\"Word {word} in {language} is \",\n>>> post_process=lambda string: {\"translated\": string},\n>>> )\n>>> thought2 = Thought(\n>>> prompt=\"Translate {translated} to Japanese\",\n>>> post_process=lambda string: {\"output\": string},\n>>> )\n>>> thought = ManualSequentialChainOfThought(thoughts=[thought1, thought2], llm=llm)\n>>> thought(word=\"hello\", language=\"French\")\n{'word': 'hello',\n 'language': 'French',\n 'translated': '\"Bonjour\"',\n 'output': '\u3053\u3093\u306b\u3061\u306f (Konnichiwa)'}\n
Create and run a chain of thought without \"+\" operator: Please refer the kotaemon.pipelines.cot.Thought section for examples.
This chain-of-thought optionally takes a termination check callback function. This function will be called after each thought is executed. It takes in a dictionary of all thought outputs so far, and it returns True or False. If True, the chain-of-thought will terminate. If unset, the default callback always returns False.
Source code in libs/kotaemon/kotaemon/llms/cot.py
class ManualSequentialChainOfThought(BaseComponent):\n \"\"\"Perform sequential chain-of-thought with manual pre-defined prompts\n\n This method supports variable number of steps. Each step corresponds to a\n `kotaemon.pipelines.cot.Thought`. Please refer that section for\n Thought's detail. This section is about chaining thought together.\n\n _**Usage:**_\n\n **Create and run a chain of thought without \"+\" operator:**\n\n ```pycon\n >>> from kotaemon.pipelines.cot import Thought, ManualSequentialChainOfThought\n >>> llm = LCAzureChatOpenAI(...)\n >>> thought1 = Thought(\n >>> prompt=\"Word {word} in {language} is \",\n >>> post_process=lambda string: {\"translated\": string},\n >>> )\n >>> thought2 = Thought(\n >>> prompt=\"Translate {translated} to Japanese\",\n >>> post_process=lambda string: {\"output\": string},\n >>> )\n >>> thought = ManualSequentialChainOfThought(thoughts=[thought1, thought2], llm=llm)\n >>> thought(word=\"hello\", language=\"French\")\n {'word': 'hello',\n 'language': 'French',\n 'translated': '\"Bonjour\"',\n 'output': '\u3053\u3093\u306b\u3061\u306f (Konnichiwa)'}\n ```\n\n **Create and run a chain of thought without \"+\" operator:** Please refer the\n `kotaemon.pipelines.cot.Thought` section for examples.\n\n This chain-of-thought optionally takes a termination check callback function.\n This function will be called after each thought is executed. It takes in a\n dictionary of all thought outputs so far, and it returns True or False. If\n True, the chain-of-thought will terminate. If unset, the default callback always\n returns False.\n \"\"\"\n\n thoughts: List[Thought] = Param(\n default_callback=lambda *_: [], help=\"List of Thought\"\n )\n llm: LLM = Param(help=\"The LLM model to use (base of kotaemon.llms.BaseLLM)\")\n terminate: Callable = Param(\n default=lambda _: False,\n help=\"Callback on terminate condition. Default to always return False\",\n )\n\n def run(self, **kwargs) -> Document:\n \"\"\"Run the manual chain of thought\"\"\"\n\n inputs = deepcopy(kwargs)\n for idx, thought in enumerate(self.thoughts):\n if self.llm:\n thought.llm = self.llm\n self._prepare_child(thought, f\"thought{idx}\")\n\n output = thought(**inputs)\n inputs.update(output.content)\n if self.terminate(inputs):\n break\n\n return Document(inputs)\n\n def __add__(self, next_thought: Thought) -> \"ManualSequentialChainOfThought\":\n return ManualSequentialChainOfThought(\n thoughts=self.thoughts + [next_thought], llm=self.llm\n )\n
def run(self, **kwargs) -> Document:\n \"\"\"Run the manual chain of thought\"\"\"\n\n inputs = deepcopy(kwargs)\n for idx, thought in enumerate(self.thoughts):\n if self.llm:\n thought.llm = self.llm\n self._prepare_child(thought, f\"thought{idx}\")\n\n output = thought(**inputs)\n inputs.update(output.content)\n if self.terminate(inputs):\n break\n\n return Document(inputs)\n
from kotaemon.llms import LCAzureChatOpenAI, BasePromptComponent\n\ndef identity(x):\n return x\n\nllm = LCAzureChatOpenAI(\n openai_api_base=\"your openai api base\",\n openai_api_key=\"your openai api key\",\n openai_api_version=\"your openai api version\",\n deployment_name=\"dummy-q2-gpt35\",\n temperature=0,\n request_timeout=600,\n)\n\npipeline = SimpleLinearPipeline(\n prompt=BasePromptComponent(template=\"what is {word} in Japanese ?\"),\n llm=llm,\n post_processor=identity,\n)\nprint(pipeline(word=\"lone\"))\n
Source code in libs/kotaemon/kotaemon/llms/linear.py
class SimpleLinearPipeline(BaseComponent):\n \"\"\"\n A simple pipeline for running a function with a prompt, a language model, and an\n optional post-processor.\n\n Attributes:\n prompt (BasePromptComponent): The prompt component used to generate the initial\n input.\n llm (Union[ChatLLM, LLM]): The language model component used to generate the\n output.\n post_processor (Union[BaseComponent, Callable[[IO_Type], IO_Type]]): An optional\n post-processor component or function.\n\n Example Usage:\n ```python\n from kotaemon.llms import LCAzureChatOpenAI, BasePromptComponent\n\n def identity(x):\n return x\n\n llm = LCAzureChatOpenAI(\n openai_api_base=\"your openai api base\",\n openai_api_key=\"your openai api key\",\n openai_api_version=\"your openai api version\",\n deployment_name=\"dummy-q2-gpt35\",\n temperature=0,\n request_timeout=600,\n )\n\n pipeline = SimpleLinearPipeline(\n prompt=BasePromptComponent(template=\"what is {word} in Japanese ?\"),\n llm=llm,\n post_processor=identity,\n )\n print(pipeline(word=\"lone\"))\n ```\n \"\"\"\n\n prompt: BasePromptComponent\n llm: Union[ChatLLM, LLM]\n post_processor: Union[BaseComponent, Callable[[IO_Type], IO_Type]]\n\n def run(\n self,\n *,\n llm_kwargs: Optional[dict] = {},\n post_processor_kwargs: Optional[dict] = {},\n **prompt_kwargs,\n ):\n \"\"\"\n Run the function with the given arguments and return the final output as a\n Document object.\n\n Args:\n llm_kwargs (dict): Keyword arguments for the llm call.\n post_processor_kwargs (dict): Keyword arguments for the post_processor.\n **prompt_kwargs: Keyword arguments for populating the prompt.\n\n Returns:\n Document: The final output of the function as a Document object.\n \"\"\"\n prompt = self.prompt(**prompt_kwargs)\n llm_output = self.llm(prompt.text, **llm_kwargs)\n if self.post_processor is not None:\n final_output = self.post_processor(llm_output, **post_processor_kwargs)[0]\n else:\n final_output = llm_output\n\n return Document(final_output)\n
Run the function with the given arguments and return the final output as a Document object.
Parameters:
Name Type Description Default llm_kwargsdict
Keyword arguments for the llm call.
{}post_processor_kwargsdict
Keyword arguments for the post_processor.
{}**prompt_kwargs
Keyword arguments for populating the prompt.
{}
Returns:
Name Type Description Document
The final output of the function as a Document object.
Source code in libs/kotaemon/kotaemon/llms/linear.py
def run(\n self,\n *,\n llm_kwargs: Optional[dict] = {},\n post_processor_kwargs: Optional[dict] = {},\n **prompt_kwargs,\n):\n \"\"\"\n Run the function with the given arguments and return the final output as a\n Document object.\n\n Args:\n llm_kwargs (dict): Keyword arguments for the llm call.\n post_processor_kwargs (dict): Keyword arguments for the post_processor.\n **prompt_kwargs: Keyword arguments for populating the prompt.\n\n Returns:\n Document: The final output of the function as a Document object.\n \"\"\"\n prompt = self.prompt(**prompt_kwargs)\n llm_output = self.llm(prompt.text, **llm_kwargs)\n if self.post_processor is not None:\n final_output = self.post_processor(llm_output, **post_processor_kwargs)[0]\n else:\n final_output = llm_output\n\n return Document(final_output)\n
A pipeline that extends the SimpleLinearPipeline class and adds a condition attribute.
Attributes:
Name Type Description conditionCallable[[IO_Type], Any]
A callable function that represents the condition.
Usage Example Usage
from kotaemon.llms import LCAzureChatOpenAI, BasePromptComponent\nfrom kotaemon.parsers import RegexExtractor\n\ndef identity(x):\n return x\n\nllm = LCAzureChatOpenAI(\n openai_api_base=\"your openai api base\",\n openai_api_key=\"your openai api key\",\n openai_api_version=\"your openai api version\",\n deployment_name=\"dummy-q2-gpt35\",\n temperature=0,\n request_timeout=600,\n)\n\npipeline = GatedLinearPipeline(\n prompt=BasePromptComponent(template=\"what is {word} in Japanese ?\"),\n condition=RegexExtractor(pattern=\"some pattern\"),\n llm=llm,\n post_processor=identity,\n)\nprint(pipeline(condition_text=\"some pattern\", word=\"lone\"))\nprint(pipeline(condition_text=\"other pattern\", word=\"lone\"))\n
Source code in libs/kotaemon/kotaemon/llms/linear.py
class GatedLinearPipeline(SimpleLinearPipeline):\n \"\"\"\n A pipeline that extends the SimpleLinearPipeline class and adds a condition\n attribute.\n\n Attributes:\n condition (Callable[[IO_Type], Any]): A callable function that represents the\n condition.\n\n Usage:\n ```{.py3 title=\"Example Usage\"}\n from kotaemon.llms import LCAzureChatOpenAI, BasePromptComponent\n from kotaemon.parsers import RegexExtractor\n\n def identity(x):\n return x\n\n llm = LCAzureChatOpenAI(\n openai_api_base=\"your openai api base\",\n openai_api_key=\"your openai api key\",\n openai_api_version=\"your openai api version\",\n deployment_name=\"dummy-q2-gpt35\",\n temperature=0,\n request_timeout=600,\n )\n\n pipeline = GatedLinearPipeline(\n prompt=BasePromptComponent(template=\"what is {word} in Japanese ?\"),\n condition=RegexExtractor(pattern=\"some pattern\"),\n llm=llm,\n post_processor=identity,\n )\n print(pipeline(condition_text=\"some pattern\", word=\"lone\"))\n print(pipeline(condition_text=\"other pattern\", word=\"lone\"))\n ```\n \"\"\"\n\n condition: Callable[[IO_Type], Any]\n\n def run(\n self,\n *,\n condition_text: Optional[str] = None,\n llm_kwargs: Optional[dict] = {},\n post_processor_kwargs: Optional[dict] = {},\n **prompt_kwargs,\n ) -> Document:\n \"\"\"\n Run the pipeline with the given arguments and return the final output as a\n Document object.\n\n Args:\n condition_text (str): The condition text to evaluate. Default to None.\n llm_kwargs (dict): Additional keyword arguments for the language model call.\n post_processor_kwargs (dict): Additional keyword arguments for the\n post-processor.\n **prompt_kwargs: Keyword arguments for populating the prompt.\n\n Returns:\n Document: The final output of the pipeline as a Document object.\n\n Raises:\n ValueError: If condition_text is None\n \"\"\"\n if condition_text is None:\n raise ValueError(\"`condition_text` must be provided\")\n\n if self.condition(condition_text)[0]:\n return super().run(\n llm_kwargs=llm_kwargs,\n post_processor_kwargs=post_processor_kwargs,\n **prompt_kwargs,\n )\n\n return Document(None)\n
Run the pipeline with the given arguments and return the final output as a Document object.
Parameters:
Name Type Description Default condition_textstr
The condition text to evaluate. Default to None.
Nonellm_kwargsdict
Additional keyword arguments for the language model call.
{}post_processor_kwargsdict
Additional keyword arguments for the post-processor.
{}**prompt_kwargs
Keyword arguments for populating the prompt.
{}
Returns:
Name Type Description DocumentDocument
The final output of the pipeline as a Document object.
Raises:
Type Description ValueError
If condition_text is None
Source code in libs/kotaemon/kotaemon/llms/linear.py
def run(\n self,\n *,\n condition_text: Optional[str] = None,\n llm_kwargs: Optional[dict] = {},\n post_processor_kwargs: Optional[dict] = {},\n **prompt_kwargs,\n) -> Document:\n \"\"\"\n Run the pipeline with the given arguments and return the final output as a\n Document object.\n\n Args:\n condition_text (str): The condition text to evaluate. Default to None.\n llm_kwargs (dict): Additional keyword arguments for the language model call.\n post_processor_kwargs (dict): Additional keyword arguments for the\n post-processor.\n **prompt_kwargs: Keyword arguments for populating the prompt.\n\n Returns:\n Document: The final output of the pipeline as a Document object.\n\n Raises:\n ValueError: If condition_text is None\n \"\"\"\n if condition_text is None:\n raise ValueError(\"`condition_text` must be provided\")\n\n if self.condition(condition_text)[0]:\n return super().run(\n llm_kwargs=llm_kwargs,\n post_processor_kwargs=post_processor_kwargs,\n **prompt_kwargs,\n )\n\n return Document(None)\n
Generate response from messages Args: messages (str | BaseMessage | list[BaseMessage]): history of messages to generate response from **kwargs: additional arguments to pass to the OpenAI API Returns: LLMInterface: generated response
Source code in libs/kotaemon/kotaemon/llms/chats/endpoint_based.py
def run(\n self, messages: str | BaseMessage | list[BaseMessage], **kwargs\n) -> LLMInterface:\n \"\"\"\n Generate response from messages\n Args:\n messages (str | BaseMessage | list[BaseMessage]): history of messages to\n generate response from\n **kwargs: additional arguments to pass to the OpenAI API\n Returns:\n LLMInterface: generated response\n \"\"\"\n if isinstance(messages, str):\n input_ = [HumanMessage(content=messages)]\n elif isinstance(messages, BaseMessage):\n input_ = [messages]\n else:\n input_ = messages\n\n def decide_role(message: BaseMessage):\n if isinstance(message, SystemMessage):\n return \"system\"\n elif isinstance(message, AIMessage):\n return \"assistant\"\n else:\n return \"user\"\n\n request_json = {\n \"messages\": [{\"content\": m.text, \"role\": decide_role(m)} for m in input_]\n }\n\n response = requests.post(self.endpoint_url, json=request_json).json()\n\n content = \"\"\n candidates = []\n if response[\"choices\"]:\n candidates = [\n each[\"message\"][\"content\"]\n for each in response[\"choices\"]\n if each[\"message\"][\"content\"]\n ]\n content = candidates[0]\n\n return LLMInterface(\n content=content,\n candidates=candidates,\n completion_tokens=response[\"usage\"][\"completion_tokens\"],\n total_tokens=response[\"usage\"][\"total_tokens\"],\n prompt_tokens=response[\"usage\"][\"prompt_tokens\"],\n )\n
Source code in libs/kotaemon/kotaemon/llms/chats/llamacpp.py
class LlamaCppChat(ChatLLM):\n \"\"\"Wrapper around the llama-cpp-python's Llama model\"\"\"\n\n model_path: Optional[str] = Param(\n help=\"Path to the model file. This is required to load the model.\",\n )\n repo_id: Optional[str] = Param(\n help=\"Id of a repo on the HuggingFace Hub in the form of `user_name/repo_name`.\"\n )\n filename: Optional[str] = Param(\n help=\"A filename or glob pattern to match the model file in the repo.\"\n )\n chat_format: str = Param(\n help=(\n \"Chat format to use. Please refer to llama_cpp.llama_chat_format for a \"\n \"list of supported formats. If blank, the chat format will be auto-\"\n \"inferred.\"\n ),\n required=True,\n )\n lora_base: Optional[str] = Param(None, help=\"Path to the base Lora model\")\n n_ctx: Optional[int] = Param(512, help=\"Text context, 0 = from model\")\n n_gpu_layers: Optional[int] = Param(\n 0,\n help=\"Number of layers to offload to GPU. If -1, all layers are offloaded\",\n )\n use_mmap: Optional[bool] = Param(\n True,\n help=(),\n )\n vocab_only: Optional[bool] = Param(\n False,\n help=\"If True, only the vocabulary is loaded. This is useful for debugging.\",\n )\n\n _role_mapper: dict[str, str] = {\n \"human\": \"user\",\n \"system\": \"system\",\n \"ai\": \"assistant\",\n }\n\n @Param.auto()\n def client_object(self) -> \"Llama\":\n \"\"\"Get the llama-cpp-python client object\"\"\"\n try:\n from llama_cpp import Llama\n except ImportError:\n raise ImportError(\n \"llama-cpp-python is not installed. \"\n \"Please install it using `pip install llama-cpp-python`\"\n )\n\n errors = []\n if not self.model_path and (not self.repo_id or not self.filename):\n errors.append(\n \"- `model_path` or `repo_id` and `filename` are required to load the\"\n \" model\"\n )\n\n if not self.chat_format:\n errors.append(\n \"- `chat_format` is required to know how to format the chat messages. \"\n \"Please refer to llama_cpp.llama_chat_format for a list of supported \"\n \"formats.\"\n )\n if errors:\n raise ValueError(\"\\n\".join(errors))\n\n if self.model_path:\n return Llama(\n model_path=cast(str, self.model_path),\n chat_format=self.chat_format,\n lora_base=self.lora_base,\n n_ctx=self.n_ctx,\n n_gpu_layers=self.n_gpu_layers,\n use_mmap=self.use_mmap,\n vocab_only=self.vocab_only,\n )\n else:\n return Llama.from_pretrained(\n repo_id=self.repo_id,\n filename=self.filename,\n chat_format=self.chat_format,\n lora_base=self.lora_base,\n n_ctx=self.n_ctx,\n n_gpu_layers=self.n_gpu_layers,\n use_mmap=self.use_mmap,\n vocab_only=self.vocab_only,\n )\n\n def prepare_message(\n self, messages: str | BaseMessage | list[BaseMessage]\n ) -> list[dict]:\n input_: list[BaseMessage] = []\n\n if isinstance(messages, str):\n input_ = [HumanMessage(content=messages)]\n elif isinstance(messages, BaseMessage):\n input_ = [messages]\n else:\n input_ = messages\n\n output_ = [\n {\"role\": self._role_mapper[each.type], \"content\": each.content}\n for each in input_\n ]\n\n return output_\n\n def invoke(\n self, messages: str | BaseMessage | list[BaseMessage], **kwargs\n ) -> LLMInterface:\n\n pred: \"CCCR\" = self.client_object.create_chat_completion(\n messages=self.prepare_message(messages),\n stream=False,\n )\n\n return LLMInterface(\n content=pred[\"choices\"][0][\"message\"][\"content\"] if pred[\"choices\"] else \"\",\n candidates=[\n c[\"message\"][\"content\"]\n for c in pred[\"choices\"]\n if c[\"message\"][\"content\"]\n ],\n completion_tokens=pred[\"usage\"][\"completion_tokens\"],\n total_tokens=pred[\"usage\"][\"total_tokens\"],\n prompt_tokens=pred[\"usage\"][\"prompt_tokens\"],\n )\n\n def stream(\n self, messages: str | BaseMessage | list[BaseMessage], **kwargs\n ) -> Iterator[LLMInterface]:\n pred = self.client_object.create_chat_completion(\n messages=self.prepare_message(messages),\n stream=True,\n )\n for chunk in pred:\n if not chunk[\"choices\"]:\n continue\n\n if \"content\" not in chunk[\"choices\"][0][\"delta\"]:\n continue\n\n yield LLMInterface(content=chunk[\"choices\"][0][\"delta\"][\"content\"])\n
Source code in libs/kotaemon/kotaemon/llms/chats/llamacpp.py
@Param.auto()\ndef client_object(self) -> \"Llama\":\n \"\"\"Get the llama-cpp-python client object\"\"\"\n try:\n from llama_cpp import Llama\n except ImportError:\n raise ImportError(\n \"llama-cpp-python is not installed. \"\n \"Please install it using `pip install llama-cpp-python`\"\n )\n\n errors = []\n if not self.model_path and (not self.repo_id or not self.filename):\n errors.append(\n \"- `model_path` or `repo_id` and `filename` are required to load the\"\n \" model\"\n )\n\n if not self.chat_format:\n errors.append(\n \"- `chat_format` is required to know how to format the chat messages. \"\n \"Please refer to llama_cpp.llama_chat_format for a list of supported \"\n \"formats.\"\n )\n if errors:\n raise ValueError(\"\\n\".join(errors))\n\n if self.model_path:\n return Llama(\n model_path=cast(str, self.model_path),\n chat_format=self.chat_format,\n lora_base=self.lora_base,\n n_ctx=self.n_ctx,\n n_gpu_layers=self.n_gpu_layers,\n use_mmap=self.use_mmap,\n vocab_only=self.vocab_only,\n )\n else:\n return Llama.from_pretrained(\n repo_id=self.repo_id,\n filename=self.filename,\n chat_format=self.chat_format,\n lora_base=self.lora_base,\n n_ctx=self.n_ctx,\n n_gpu_layers=self.n_gpu_layers,\n use_mmap=self.use_mmap,\n vocab_only=self.vocab_only,\n )\n
Generate response from messages Args: messages (str | BaseMessage | list[BaseMessage]): history of messages to generate response from **kwargs: additional arguments to pass to the OpenAI API Returns: LLMInterface: generated response
Source code in libs/kotaemon/kotaemon/llms/chats/endpoint_based.py
def run(\n self, messages: str | BaseMessage | list[BaseMessage], **kwargs\n) -> LLMInterface:\n \"\"\"\n Generate response from messages\n Args:\n messages (str | BaseMessage | list[BaseMessage]): history of messages to\n generate response from\n **kwargs: additional arguments to pass to the OpenAI API\n Returns:\n LLMInterface: generated response\n \"\"\"\n if isinstance(messages, str):\n input_ = [HumanMessage(content=messages)]\n elif isinstance(messages, BaseMessage):\n input_ = [messages]\n else:\n input_ = messages\n\n def decide_role(message: BaseMessage):\n if isinstance(message, SystemMessage):\n return \"system\"\n elif isinstance(message, AIMessage):\n return \"assistant\"\n else:\n return \"user\"\n\n request_json = {\n \"messages\": [{\"content\": m.text, \"role\": decide_role(m)} for m in input_]\n }\n\n response = requests.post(self.endpoint_url, json=request_json).json()\n\n content = \"\"\n candidates = []\n if response[\"choices\"]:\n candidates = [\n each[\"message\"][\"content\"]\n for each in response[\"choices\"]\n if each[\"message\"][\"content\"]\n ]\n content = candidates[0]\n\n return LLMInterface(\n content=content,\n candidates=candidates,\n completion_tokens=response[\"usage\"][\"completion_tokens\"],\n total_tokens=response[\"usage\"][\"total_tokens\"],\n prompt_tokens=response[\"usage\"][\"prompt_tokens\"],\n )\n
Source code in libs/kotaemon/kotaemon/llms/chats/llamacpp.py
class LlamaCppChat(ChatLLM):\n \"\"\"Wrapper around the llama-cpp-python's Llama model\"\"\"\n\n model_path: Optional[str] = Param(\n help=\"Path to the model file. This is required to load the model.\",\n )\n repo_id: Optional[str] = Param(\n help=\"Id of a repo on the HuggingFace Hub in the form of `user_name/repo_name`.\"\n )\n filename: Optional[str] = Param(\n help=\"A filename or glob pattern to match the model file in the repo.\"\n )\n chat_format: str = Param(\n help=(\n \"Chat format to use. Please refer to llama_cpp.llama_chat_format for a \"\n \"list of supported formats. If blank, the chat format will be auto-\"\n \"inferred.\"\n ),\n required=True,\n )\n lora_base: Optional[str] = Param(None, help=\"Path to the base Lora model\")\n n_ctx: Optional[int] = Param(512, help=\"Text context, 0 = from model\")\n n_gpu_layers: Optional[int] = Param(\n 0,\n help=\"Number of layers to offload to GPU. If -1, all layers are offloaded\",\n )\n use_mmap: Optional[bool] = Param(\n True,\n help=(),\n )\n vocab_only: Optional[bool] = Param(\n False,\n help=\"If True, only the vocabulary is loaded. This is useful for debugging.\",\n )\n\n _role_mapper: dict[str, str] = {\n \"human\": \"user\",\n \"system\": \"system\",\n \"ai\": \"assistant\",\n }\n\n @Param.auto()\n def client_object(self) -> \"Llama\":\n \"\"\"Get the llama-cpp-python client object\"\"\"\n try:\n from llama_cpp import Llama\n except ImportError:\n raise ImportError(\n \"llama-cpp-python is not installed. \"\n \"Please install it using `pip install llama-cpp-python`\"\n )\n\n errors = []\n if not self.model_path and (not self.repo_id or not self.filename):\n errors.append(\n \"- `model_path` or `repo_id` and `filename` are required to load the\"\n \" model\"\n )\n\n if not self.chat_format:\n errors.append(\n \"- `chat_format` is required to know how to format the chat messages. \"\n \"Please refer to llama_cpp.llama_chat_format for a list of supported \"\n \"formats.\"\n )\n if errors:\n raise ValueError(\"\\n\".join(errors))\n\n if self.model_path:\n return Llama(\n model_path=cast(str, self.model_path),\n chat_format=self.chat_format,\n lora_base=self.lora_base,\n n_ctx=self.n_ctx,\n n_gpu_layers=self.n_gpu_layers,\n use_mmap=self.use_mmap,\n vocab_only=self.vocab_only,\n )\n else:\n return Llama.from_pretrained(\n repo_id=self.repo_id,\n filename=self.filename,\n chat_format=self.chat_format,\n lora_base=self.lora_base,\n n_ctx=self.n_ctx,\n n_gpu_layers=self.n_gpu_layers,\n use_mmap=self.use_mmap,\n vocab_only=self.vocab_only,\n )\n\n def prepare_message(\n self, messages: str | BaseMessage | list[BaseMessage]\n ) -> list[dict]:\n input_: list[BaseMessage] = []\n\n if isinstance(messages, str):\n input_ = [HumanMessage(content=messages)]\n elif isinstance(messages, BaseMessage):\n input_ = [messages]\n else:\n input_ = messages\n\n output_ = [\n {\"role\": self._role_mapper[each.type], \"content\": each.content}\n for each in input_\n ]\n\n return output_\n\n def invoke(\n self, messages: str | BaseMessage | list[BaseMessage], **kwargs\n ) -> LLMInterface:\n\n pred: \"CCCR\" = self.client_object.create_chat_completion(\n messages=self.prepare_message(messages),\n stream=False,\n )\n\n return LLMInterface(\n content=pred[\"choices\"][0][\"message\"][\"content\"] if pred[\"choices\"] else \"\",\n candidates=[\n c[\"message\"][\"content\"]\n for c in pred[\"choices\"]\n if c[\"message\"][\"content\"]\n ],\n completion_tokens=pred[\"usage\"][\"completion_tokens\"],\n total_tokens=pred[\"usage\"][\"total_tokens\"],\n prompt_tokens=pred[\"usage\"][\"prompt_tokens\"],\n )\n\n def stream(\n self, messages: str | BaseMessage | list[BaseMessage], **kwargs\n ) -> Iterator[LLMInterface]:\n pred = self.client_object.create_chat_completion(\n messages=self.prepare_message(messages),\n stream=True,\n )\n for chunk in pred:\n if not chunk[\"choices\"]:\n continue\n\n if \"content\" not in chunk[\"choices\"][0][\"delta\"]:\n continue\n\n yield LLMInterface(content=chunk[\"choices\"][0][\"delta\"][\"content\"])\n
Source code in libs/kotaemon/kotaemon/llms/chats/llamacpp.py
@Param.auto()\ndef client_object(self) -> \"Llama\":\n \"\"\"Get the llama-cpp-python client object\"\"\"\n try:\n from llama_cpp import Llama\n except ImportError:\n raise ImportError(\n \"llama-cpp-python is not installed. \"\n \"Please install it using `pip install llama-cpp-python`\"\n )\n\n errors = []\n if not self.model_path and (not self.repo_id or not self.filename):\n errors.append(\n \"- `model_path` or `repo_id` and `filename` are required to load the\"\n \" model\"\n )\n\n if not self.chat_format:\n errors.append(\n \"- `chat_format` is required to know how to format the chat messages. \"\n \"Please refer to llama_cpp.llama_chat_format for a list of supported \"\n \"formats.\"\n )\n if errors:\n raise ValueError(\"\\n\".join(errors))\n\n if self.model_path:\n return Llama(\n model_path=cast(str, self.model_path),\n chat_format=self.chat_format,\n lora_base=self.lora_base,\n n_ctx=self.n_ctx,\n n_gpu_layers=self.n_gpu_layers,\n use_mmap=self.use_mmap,\n vocab_only=self.vocab_only,\n )\n else:\n return Llama.from_pretrained(\n repo_id=self.repo_id,\n filename=self.filename,\n chat_format=self.chat_format,\n lora_base=self.lora_base,\n n_ctx=self.n_ctx,\n n_gpu_layers=self.n_gpu_layers,\n use_mmap=self.use_mmap,\n vocab_only=self.vocab_only,\n )\n
Base interface for OpenAI chat model, using the openai library
This class exposes the parameters in resources.Chat. To subclass this class:
- Implement the `prepare_client` method to return the OpenAI client\n- Implement the `openai_response` method to return the OpenAI response\n- Implement the params relate to the OpenAI client\n
Source code in libs/kotaemon/kotaemon/llms/chats/openai.py
class BaseChatOpenAI(ChatLLM):\n \"\"\"Base interface for OpenAI chat model, using the openai library\n\n This class exposes the parameters in resources.Chat. To subclass this class:\n\n - Implement the `prepare_client` method to return the OpenAI client\n - Implement the `openai_response` method to return the OpenAI response\n - Implement the params relate to the OpenAI client\n \"\"\"\n\n _dependencies = [\"openai\"]\n _capabilities = [\"chat\", \"text\"] # consider as mixin\n\n api_key: str = Param(help=\"API key\", required=True)\n timeout: Optional[float] = Param(None, help=\"Timeout for the API request\")\n max_retries: Optional[int] = Param(\n None, help=\"Maximum number of retries for the API request\"\n )\n\n temperature: Optional[float] = Param(\n None,\n help=(\n \"Number between 0 and 2 that controls the randomness of the generated \"\n \"tokens. Lower values make the model more deterministic, while higher \"\n \"values make the model more random.\"\n ),\n )\n max_tokens: Optional[int] = Param(\n None,\n help=(\n \"Maximum number of tokens to generate. The total length of input tokens \"\n \"and generated tokens is limited by the model's context length.\"\n ),\n )\n n: int = Param(\n 1,\n help=(\n \"Number of completions to generate. The API will generate n completion \"\n \"for each prompt.\"\n ),\n )\n stop: Optional[str | list[str]] = Param(\n None,\n help=(\n \"Stop sequence. If a stop sequence is detected, generation will stop \"\n \"at that point. If not specified, generation will continue until the \"\n \"maximum token length is reached.\"\n ),\n )\n frequency_penalty: Optional[float] = Param(\n None,\n help=(\n \"Number between -2.0 and 2.0. Positive values penalize new tokens \"\n \"based on their existing frequency in the text so far, decrearsing the \"\n \"model's likelihood of repeating the same text.\"\n ),\n )\n presence_penalty: Optional[float] = Param(\n None,\n help=(\n \"Number between -2.0 and 2.0. Positive values penalize new tokens \"\n \"based on their existing presence in the text so far, decrearsing the \"\n \"model's likelihood of repeating the same text.\"\n ),\n )\n tool_choice: Optional[str] = Param(\n None,\n help=(\n \"Choice of tool to use for the completion. Available choices are: \"\n \"auto, default.\"\n ),\n )\n tools: Optional[list[str]] = Param(\n None,\n help=\"List of tools to use for the completion.\",\n )\n logprobs: Optional[bool] = Param(\n None,\n help=(\n \"Include log probabilities on the logprobs most likely tokens, \"\n \"as well as the chosen token.\"\n ),\n )\n logit_bias: Optional[dict] = Param(\n None,\n help=(\n \"Dictionary of logit bias values to add to the logits of the tokens \"\n \"in the vocabulary.\"\n ),\n )\n top_logprobs: Optional[int] = Param(\n None,\n help=(\n \"An integer between 0 and 5 specifying the number of most likely tokens \"\n \"to return at each token position, each with an associated log \"\n \"probability. `logprobs` must also be set to `true` if this parameter \"\n \"is used.\"\n ),\n )\n top_p: Optional[float] = Param(\n None,\n help=(\n \"An alternative to sampling with temperature, called nucleus sampling, \"\n \"where the model considers the results of the token with top_p \"\n \"probability mass. So 0.1 means that only the tokens comprising the \"\n \"top 10% probability mass are considered.\"\n ),\n )\n\n @Param.auto(depends_on=[\"max_retries\"])\n def max_retries_(self):\n if self.max_retries is None:\n from openai._constants import DEFAULT_MAX_RETRIES\n\n return DEFAULT_MAX_RETRIES\n return self.max_retries\n\n def prepare_message(\n self, messages: str | BaseMessage | list[BaseMessage]\n ) -> list[\"ChatCompletionMessageParam\"]:\n \"\"\"Prepare the message into OpenAI format\n\n Returns:\n list[dict]: List of messages in OpenAI format\n \"\"\"\n input_: list[BaseMessage] = []\n output_: list[\"ChatCompletionMessageParam\"] = []\n\n if isinstance(messages, str):\n input_ = [HumanMessage(content=messages)]\n elif isinstance(messages, BaseMessage):\n input_ = [messages]\n else:\n input_ = messages\n\n for message in input_:\n output_.append(message.to_openai_format())\n\n return output_\n\n def prepare_output(self, resp: dict) -> LLMInterface:\n \"\"\"Convert the OpenAI response into LLMInterface\"\"\"\n additional_kwargs = {}\n if \"tool_calls\" in resp[\"choices\"][0][\"message\"]:\n additional_kwargs[\"tool_calls\"] = resp[\"choices\"][0][\"message\"][\n \"tool_calls\"\n ]\n\n if resp[\"choices\"][0].get(\"logprobs\") is None:\n logprobs = []\n else:\n all_logprobs = resp[\"choices\"][0][\"logprobs\"].get(\"content\")\n logprobs = (\n [logprob[\"logprob\"] for logprob in all_logprobs] if all_logprobs else []\n )\n\n output = LLMInterface(\n candidates=[(_[\"message\"][\"content\"] or \"\") for _ in resp[\"choices\"]],\n content=resp[\"choices\"][0][\"message\"][\"content\"] or \"\",\n total_tokens=resp[\"usage\"][\"total_tokens\"],\n prompt_tokens=resp[\"usage\"][\"prompt_tokens\"],\n completion_tokens=resp[\"usage\"][\"completion_tokens\"],\n additional_kwargs=additional_kwargs,\n messages=[\n AIMessage(content=(_[\"message\"][\"content\"]) or \"\")\n for _ in resp[\"choices\"]\n ],\n logprobs=logprobs,\n )\n\n return output\n\n def prepare_client(self, async_version: bool = False):\n \"\"\"Get the OpenAI client\n\n Args:\n async_version (bool): Whether to get the async version of the client\n \"\"\"\n raise NotImplementedError\n\n def openai_response(self, client, **kwargs):\n \"\"\"Get the openai response\"\"\"\n raise NotImplementedError\n\n def invoke(\n self, messages: str | BaseMessage | list[BaseMessage], *args, **kwargs\n ) -> LLMInterface:\n client = self.prepare_client(async_version=False)\n input_messages = self.prepare_message(messages)\n resp = self.openai_response(\n client, messages=input_messages, stream=False, **kwargs\n ).dict()\n return self.prepare_output(resp)\n\n async def ainvoke(\n self, messages: str | BaseMessage | list[BaseMessage], *args, **kwargs\n ) -> LLMInterface:\n client = self.prepare_client(async_version=True)\n input_messages = self.prepare_message(messages)\n resp = await self.openai_response(\n client, messages=input_messages, stream=False, **kwargs\n ).dict()\n\n return self.prepare_output(resp)\n\n def stream(\n self, messages: str | BaseMessage | list[BaseMessage], *args, **kwargs\n ) -> Iterator[LLMInterface]:\n client = self.prepare_client(async_version=False)\n input_messages = self.prepare_message(messages)\n resp = self.openai_response(\n client, messages=input_messages, stream=True, **kwargs\n )\n\n for c in resp:\n chunk = c.dict()\n if not chunk[\"choices\"]:\n continue\n if chunk[\"choices\"][0][\"delta\"][\"content\"] is not None:\n if chunk[\"choices\"][0].get(\"logprobs\") is None:\n logprobs = []\n else:\n logprobs = [\n logprob[\"logprob\"]\n for logprob in chunk[\"choices\"][0][\"logprobs\"].get(\n \"content\", []\n )\n ]\n\n yield LLMInterface(\n content=chunk[\"choices\"][0][\"delta\"][\"content\"], logprobs=logprobs\n )\n\n async def astream(\n self, messages: str | BaseMessage | list[BaseMessage], *args, **kwargs\n ) -> AsyncGenerator[LLMInterface, None]:\n client = self.prepare_client(async_version=True)\n input_messages = self.prepare_message(messages)\n resp = self.openai_response(\n client, messages=input_messages, stream=True, **kwargs\n )\n\n async for chunk in resp:\n if not chunk.choices:\n continue\n if chunk.choices[0].delta.content is not None:\n yield LLMInterface(content=chunk.choices[0].delta.content)\n
Source code in libs/kotaemon/kotaemon/llms/chats/openai.py
def prepare_output(self, resp: dict) -> LLMInterface:\n \"\"\"Convert the OpenAI response into LLMInterface\"\"\"\n additional_kwargs = {}\n if \"tool_calls\" in resp[\"choices\"][0][\"message\"]:\n additional_kwargs[\"tool_calls\"] = resp[\"choices\"][0][\"message\"][\n \"tool_calls\"\n ]\n\n if resp[\"choices\"][0].get(\"logprobs\") is None:\n logprobs = []\n else:\n all_logprobs = resp[\"choices\"][0][\"logprobs\"].get(\"content\")\n logprobs = (\n [logprob[\"logprob\"] for logprob in all_logprobs] if all_logprobs else []\n )\n\n output = LLMInterface(\n candidates=[(_[\"message\"][\"content\"] or \"\") for _ in resp[\"choices\"]],\n content=resp[\"choices\"][0][\"message\"][\"content\"] or \"\",\n total_tokens=resp[\"usage\"][\"total_tokens\"],\n prompt_tokens=resp[\"usage\"][\"prompt_tokens\"],\n completion_tokens=resp[\"usage\"][\"completion_tokens\"],\n additional_kwargs=additional_kwargs,\n messages=[\n AIMessage(content=(_[\"message\"][\"content\"]) or \"\")\n for _ in resp[\"choices\"]\n ],\n logprobs=logprobs,\n )\n\n return output\n
False Source code in libs/kotaemon/kotaemon/llms/chats/openai.py
def prepare_client(self, async_version: bool = False):\n \"\"\"Get the OpenAI client\n\n Args:\n async_version (bool): Whether to get the async version of the client\n \"\"\"\n raise NotImplementedError\n
Name Type Description Default templatePromptTemplate
The prompt template.
required **kwargs
Any additional keyword arguments that will be used to populate the given template.
{} Source code in libs/kotaemon/kotaemon/llms/prompts/base.py
class BasePromptComponent(BaseComponent):\n \"\"\"\n Base class for prompt components.\n\n Args:\n template (PromptTemplate): The prompt template.\n **kwargs: Any additional keyword arguments that will be used to populate the\n given template.\n \"\"\"\n\n class Config:\n middleware_switches = {\"theflow.middleware.CachingMiddleware\": False}\n allow_extra = True\n\n template: str | PromptTemplate\n\n @Param.auto(depends_on=\"template\")\n def template__(self):\n return (\n self.template\n if isinstance(self.template, PromptTemplate)\n else PromptTemplate(self.template)\n )\n\n def __init__(self, **kwargs):\n super().__init__(**kwargs)\n self.__set(**kwargs)\n\n def __check_redundant_kwargs(self, **kwargs):\n \"\"\"\n Check for redundant keyword arguments.\n\n Parameters:\n **kwargs (dict): A dictionary of keyword arguments.\n\n Raises:\n ValueError: If any keys provided are not in the template.\n\n Returns:\n None\n \"\"\"\n self.template__.check_redundant_kwargs(**kwargs)\n\n def __check_unset_placeholders(self):\n \"\"\"\n Check if all the placeholders in the template are set.\n\n This function checks if all the expected placeholders in the template are set as\n attributes of the object. If any placeholders are missing, a `ValueError`\n is raised with the names of the missing keys.\n\n Parameters:\n None\n\n Returns:\n None\n \"\"\"\n self.template__.check_missing_kwargs(**self.__dict__)\n\n def __validate_value_type(self, **kwargs):\n \"\"\"\n Validates the value types of the given keyword arguments.\n\n Parameters:\n **kwargs (dict): A dictionary of keyword arguments to be validated.\n\n Raises:\n ValueError: If any of the values in the kwargs dictionary have an\n unsupported type.\n\n Returns:\n None\n \"\"\"\n type_error = []\n for k, v in kwargs.items():\n if k.startswith(\"template\"):\n continue\n if not isinstance(v, (str, int, Document, Callable)): # type: ignore\n type_error.append((k, type(v)))\n\n if type_error:\n raise ValueError(\n \"Type of values must be either int, str, Document, Callable, \"\n f\"found unsupported type for (key, type): {type_error}\"\n )\n\n def __set(self, **kwargs):\n \"\"\"\n Set the values of the attributes in the object based on the provided keyword\n arguments.\n\n Args:\n kwargs (dict): A dictionary with the attribute names as keys and the new\n values as values.\n\n Returns:\n None\n \"\"\"\n self.__check_redundant_kwargs(**kwargs)\n self.__validate_value_type(**kwargs)\n\n self.__dict__.update(kwargs)\n\n def __prepare_value(self):\n \"\"\"\n Generate a dictionary of keyword arguments based on the template's placeholders\n and the current instance's attributes.\n\n Returns:\n dict: A dictionary of keyword arguments.\n \"\"\"\n\n def __prepare(key, value):\n if isinstance(value, str):\n return value\n if isinstance(value, (int, Document)):\n return str(value)\n\n raise ValueError(\n f\"Unsupported type {type(value)} for template value of key {key}\"\n )\n\n kwargs = {}\n for k in self.template__.placeholders:\n v = getattr(self, k)\n\n # if get a callable, execute to get its output\n if isinstance(v, Callable): # type: ignore[arg-type]\n v = v()\n\n if isinstance(v, list):\n v = str([__prepare(k, each) for each in v])\n elif isinstance(v, (str, int, Document)):\n v = __prepare(k, v)\n else:\n raise ValueError(\n f\"Unsupported type {type(v)} for template value of key `{k}`\"\n )\n kwargs[k] = v\n\n return kwargs\n\n def set_value(self, **kwargs):\n \"\"\"\n Similar to `__set` but for external use.\n\n Set the values of the attributes in the object based on the provided keyword\n arguments.\n\n Args:\n kwargs (dict): A dictionary with the attribute names as keys and the new\n values as values.\n\n Returns:\n None\n \"\"\"\n self.__set(**kwargs)\n\n def run(self, **kwargs):\n \"\"\"\n Run the function with the given keyword arguments.\n\n Args:\n **kwargs: The keyword arguments to pass to the function.\n\n Returns:\n The result of calling the `populate` method of the `template` object\n with the given keyword arguments.\n \"\"\"\n self.__set(**kwargs)\n self.__check_unset_placeholders()\n prepared_kwargs = self.__prepare_value()\n\n text = self.template__.populate(**prepared_kwargs)\n return Document(text=text, metadata={\"origin\": \"PromptComponent\"})\n\n def flow(self):\n return self.__call__()\n
Set the values of the attributes in the object based on the provided keyword arguments.
Parameters:
Name Type Description Default kwargsdict
A dictionary with the attribute names as keys and the new values as values.
{}
Returns:
Type Description
None
Source code in libs/kotaemon/kotaemon/llms/prompts/base.py
def set_value(self, **kwargs):\n \"\"\"\n Similar to `__set` but for external use.\n\n Set the values of the attributes in the object based on the provided keyword\n arguments.\n\n Args:\n kwargs (dict): A dictionary with the attribute names as keys and the new\n values as values.\n\n Returns:\n None\n \"\"\"\n self.__set(**kwargs)\n
Run the function with the given keyword arguments.
Parameters:
Name Type Description Default **kwargs
The keyword arguments to pass to the function.
{}
Returns:
Type Description
The result of calling the populate method of the template object
with the given keyword arguments.
Source code in libs/kotaemon/kotaemon/llms/prompts/base.py
def run(self, **kwargs):\n \"\"\"\n Run the function with the given keyword arguments.\n\n Args:\n **kwargs: The keyword arguments to pass to the function.\n\n Returns:\n The result of calling the `populate` method of the `template` object\n with the given keyword arguments.\n \"\"\"\n self.__set(**kwargs)\n self.__check_unset_placeholders()\n prepared_kwargs = self.__prepare_value()\n\n text = self.template__.populate(**prepared_kwargs)\n return Document(text=text, metadata={\"origin\": \"PromptComponent\"})\n
Source code in libs/kotaemon/kotaemon/llms/prompts/template.py
class PromptTemplate:\n \"\"\"\n Base class for prompt templates.\n \"\"\"\n\n def __init__(self, template: str, ignore_invalid=True):\n template = template\n formatter = Formatter()\n parsed_template = list(formatter.parse(template))\n\n placeholders = set()\n for _, key, _, _ in parsed_template:\n if key is None:\n continue\n if not key.isidentifier():\n if ignore_invalid:\n warnings.warn(f\"Ignore invalid placeholder: {key}.\", UserWarning)\n else:\n raise ValueError(\n \"Placeholder name must be a valid Python identifier, found:\"\n f\" {key}.\"\n )\n placeholders.add(key)\n\n self.template = template\n self.placeholders = placeholders\n self.__formatter = formatter\n self.__parsed_template = parsed_template\n\n def check_missing_kwargs(self, **kwargs):\n \"\"\"\n Check if all the placeholders in the template are set.\n\n This function checks if all the expected placeholders in the template are set as\n attributes of the object. If any placeholders are missing, a `ValueError`\n is raised with the names of the missing keys.\n\n Parameters:\n None\n\n Returns:\n None\n \"\"\"\n missing_keys = self.placeholders.difference(kwargs.keys())\n if missing_keys:\n raise ValueError(f\"Missing keys in template: {','.join(missing_keys)}\")\n\n def check_redundant_kwargs(self, **kwargs):\n \"\"\"\n Check if all the placeholders in the template are set.\n\n This function checks if all the expected placeholders in the template are set as\n attributes of the object. If any placeholders are missing, a `ValueError`\n is raised with the names of the missing keys.\n\n Parameters:\n None\n\n Returns:\n None\n \"\"\"\n provided_keys = set(kwargs.keys())\n redundant_keys = provided_keys - self.placeholders\n\n if redundant_keys:\n warnings.warn(\n f\"Keys provided but not in template: {','.join(redundant_keys)}\",\n UserWarning,\n )\n\n def populate(self, **kwargs) -> str:\n \"\"\"\n Strictly populate the template with the given keyword arguments.\n\n Args:\n **kwargs: The keyword arguments to populate the template.\n Each keyword corresponds to a placeholder in the template.\n\n Returns:\n The populated template.\n\n Raises:\n ValueError: If an unknown placeholder is provided.\n \"\"\"\n self.check_missing_kwargs(**kwargs)\n\n return self.partial_populate(**kwargs)\n\n def partial_populate(self, **kwargs):\n \"\"\"\n Partially populate the template with the given keyword arguments.\n\n Args:\n **kwargs: The keyword arguments to populate the template.\n Each keyword corresponds to a placeholder in the template.\n\n Returns:\n str: The populated template.\n \"\"\"\n self.check_redundant_kwargs(**kwargs)\n\n prompt = []\n for literal_text, field_name, format_spec, conversion in self.__parsed_template:\n prompt.append(literal_text)\n\n if field_name is None:\n continue\n\n if field_name not in kwargs:\n if conversion:\n value = f\"{{{field_name}}}!{conversion}:{format_spec}\"\n else:\n value = f\"{{{field_name}:{format_spec}}}\"\n else:\n value = kwargs[field_name]\n if conversion is not None:\n value = self.__formatter.convert_field(value, conversion)\n if format_spec is not None:\n value = self.__formatter.format_field(value, format_spec)\n\n prompt.append(value)\n\n return \"\".join(prompt)\n\n def __add__(self, other):\n \"\"\"\n Create a new PromptTemplate object by concatenating the template of the current\n object with the template of another PromptTemplate object.\n\n Parameters:\n other (PromptTemplate): Another PromptTemplate object.\n\n Returns:\n PromptTemplate: A new PromptTemplate object with the concatenated templates.\n \"\"\"\n return PromptTemplate(self.template + \"\\n\" + other.template)\n
Check if all the placeholders in the template are set.
This function checks if all the expected placeholders in the template are set as attributes of the object. If any placeholders are missing, a ValueError is raised with the names of the missing keys.
Returns:
Type Description
None
Source code in libs/kotaemon/kotaemon/llms/prompts/template.py
def check_missing_kwargs(self, **kwargs):\n \"\"\"\n Check if all the placeholders in the template are set.\n\n This function checks if all the expected placeholders in the template are set as\n attributes of the object. If any placeholders are missing, a `ValueError`\n is raised with the names of the missing keys.\n\n Parameters:\n None\n\n Returns:\n None\n \"\"\"\n missing_keys = self.placeholders.difference(kwargs.keys())\n if missing_keys:\n raise ValueError(f\"Missing keys in template: {','.join(missing_keys)}\")\n
Check if all the placeholders in the template are set.
This function checks if all the expected placeholders in the template are set as attributes of the object. If any placeholders are missing, a ValueError is raised with the names of the missing keys.
Returns:
Type Description
None
Source code in libs/kotaemon/kotaemon/llms/prompts/template.py
def check_redundant_kwargs(self, **kwargs):\n \"\"\"\n Check if all the placeholders in the template are set.\n\n This function checks if all the expected placeholders in the template are set as\n attributes of the object. If any placeholders are missing, a `ValueError`\n is raised with the names of the missing keys.\n\n Parameters:\n None\n\n Returns:\n None\n \"\"\"\n provided_keys = set(kwargs.keys())\n redundant_keys = provided_keys - self.placeholders\n\n if redundant_keys:\n warnings.warn(\n f\"Keys provided but not in template: {','.join(redundant_keys)}\",\n UserWarning,\n )\n
Strictly populate the template with the given keyword arguments.
Parameters:
Name Type Description Default **kwargs
The keyword arguments to populate the template. Each keyword corresponds to a placeholder in the template.
{}
Returns:
Type Description str
The populated template.
Raises:
Type Description ValueError
If an unknown placeholder is provided.
Source code in libs/kotaemon/kotaemon/llms/prompts/template.py
def populate(self, **kwargs) -> str:\n \"\"\"\n Strictly populate the template with the given keyword arguments.\n\n Args:\n **kwargs: The keyword arguments to populate the template.\n Each keyword corresponds to a placeholder in the template.\n\n Returns:\n The populated template.\n\n Raises:\n ValueError: If an unknown placeholder is provided.\n \"\"\"\n self.check_missing_kwargs(**kwargs)\n\n return self.partial_populate(**kwargs)\n
Partially populate the template with the given keyword arguments.
Parameters:
Name Type Description Default **kwargs
The keyword arguments to populate the template. Each keyword corresponds to a placeholder in the template.
{}
Returns:
Name Type Description str
The populated template.
Source code in libs/kotaemon/kotaemon/llms/prompts/template.py
def partial_populate(self, **kwargs):\n \"\"\"\n Partially populate the template with the given keyword arguments.\n\n Args:\n **kwargs: The keyword arguments to populate the template.\n Each keyword corresponds to a placeholder in the template.\n\n Returns:\n str: The populated template.\n \"\"\"\n self.check_redundant_kwargs(**kwargs)\n\n prompt = []\n for literal_text, field_name, format_spec, conversion in self.__parsed_template:\n prompt.append(literal_text)\n\n if field_name is None:\n continue\n\n if field_name not in kwargs:\n if conversion:\n value = f\"{{{field_name}}}!{conversion}:{format_spec}\"\n else:\n value = f\"{{{field_name}:{format_spec}}}\"\n else:\n value = kwargs[field_name]\n if conversion is not None:\n value = self.__formatter.convert_field(value, conversion)\n if format_spec is not None:\n value = self.__formatter.format_field(value, format_spec)\n\n prompt.append(value)\n\n return \"\".join(prompt)\n
Name Type Description Default templatePromptTemplate
The prompt template.
required **kwargs
Any additional keyword arguments that will be used to populate the given template.
{} Source code in libs/kotaemon/kotaemon/llms/prompts/base.py
class BasePromptComponent(BaseComponent):\n \"\"\"\n Base class for prompt components.\n\n Args:\n template (PromptTemplate): The prompt template.\n **kwargs: Any additional keyword arguments that will be used to populate the\n given template.\n \"\"\"\n\n class Config:\n middleware_switches = {\"theflow.middleware.CachingMiddleware\": False}\n allow_extra = True\n\n template: str | PromptTemplate\n\n @Param.auto(depends_on=\"template\")\n def template__(self):\n return (\n self.template\n if isinstance(self.template, PromptTemplate)\n else PromptTemplate(self.template)\n )\n\n def __init__(self, **kwargs):\n super().__init__(**kwargs)\n self.__set(**kwargs)\n\n def __check_redundant_kwargs(self, **kwargs):\n \"\"\"\n Check for redundant keyword arguments.\n\n Parameters:\n **kwargs (dict): A dictionary of keyword arguments.\n\n Raises:\n ValueError: If any keys provided are not in the template.\n\n Returns:\n None\n \"\"\"\n self.template__.check_redundant_kwargs(**kwargs)\n\n def __check_unset_placeholders(self):\n \"\"\"\n Check if all the placeholders in the template are set.\n\n This function checks if all the expected placeholders in the template are set as\n attributes of the object. If any placeholders are missing, a `ValueError`\n is raised with the names of the missing keys.\n\n Parameters:\n None\n\n Returns:\n None\n \"\"\"\n self.template__.check_missing_kwargs(**self.__dict__)\n\n def __validate_value_type(self, **kwargs):\n \"\"\"\n Validates the value types of the given keyword arguments.\n\n Parameters:\n **kwargs (dict): A dictionary of keyword arguments to be validated.\n\n Raises:\n ValueError: If any of the values in the kwargs dictionary have an\n unsupported type.\n\n Returns:\n None\n \"\"\"\n type_error = []\n for k, v in kwargs.items():\n if k.startswith(\"template\"):\n continue\n if not isinstance(v, (str, int, Document, Callable)): # type: ignore\n type_error.append((k, type(v)))\n\n if type_error:\n raise ValueError(\n \"Type of values must be either int, str, Document, Callable, \"\n f\"found unsupported type for (key, type): {type_error}\"\n )\n\n def __set(self, **kwargs):\n \"\"\"\n Set the values of the attributes in the object based on the provided keyword\n arguments.\n\n Args:\n kwargs (dict): A dictionary with the attribute names as keys and the new\n values as values.\n\n Returns:\n None\n \"\"\"\n self.__check_redundant_kwargs(**kwargs)\n self.__validate_value_type(**kwargs)\n\n self.__dict__.update(kwargs)\n\n def __prepare_value(self):\n \"\"\"\n Generate a dictionary of keyword arguments based on the template's placeholders\n and the current instance's attributes.\n\n Returns:\n dict: A dictionary of keyword arguments.\n \"\"\"\n\n def __prepare(key, value):\n if isinstance(value, str):\n return value\n if isinstance(value, (int, Document)):\n return str(value)\n\n raise ValueError(\n f\"Unsupported type {type(value)} for template value of key {key}\"\n )\n\n kwargs = {}\n for k in self.template__.placeholders:\n v = getattr(self, k)\n\n # if get a callable, execute to get its output\n if isinstance(v, Callable): # type: ignore[arg-type]\n v = v()\n\n if isinstance(v, list):\n v = str([__prepare(k, each) for each in v])\n elif isinstance(v, (str, int, Document)):\n v = __prepare(k, v)\n else:\n raise ValueError(\n f\"Unsupported type {type(v)} for template value of key `{k}`\"\n )\n kwargs[k] = v\n\n return kwargs\n\n def set_value(self, **kwargs):\n \"\"\"\n Similar to `__set` but for external use.\n\n Set the values of the attributes in the object based on the provided keyword\n arguments.\n\n Args:\n kwargs (dict): A dictionary with the attribute names as keys and the new\n values as values.\n\n Returns:\n None\n \"\"\"\n self.__set(**kwargs)\n\n def run(self, **kwargs):\n \"\"\"\n Run the function with the given keyword arguments.\n\n Args:\n **kwargs: The keyword arguments to pass to the function.\n\n Returns:\n The result of calling the `populate` method of the `template` object\n with the given keyword arguments.\n \"\"\"\n self.__set(**kwargs)\n self.__check_unset_placeholders()\n prepared_kwargs = self.__prepare_value()\n\n text = self.template__.populate(**prepared_kwargs)\n return Document(text=text, metadata={\"origin\": \"PromptComponent\"})\n\n def flow(self):\n return self.__call__()\n
Set the values of the attributes in the object based on the provided keyword arguments.
Parameters:
Name Type Description Default kwargsdict
A dictionary with the attribute names as keys and the new values as values.
{}
Returns:
Type Description
None
Source code in libs/kotaemon/kotaemon/llms/prompts/base.py
def set_value(self, **kwargs):\n \"\"\"\n Similar to `__set` but for external use.\n\n Set the values of the attributes in the object based on the provided keyword\n arguments.\n\n Args:\n kwargs (dict): A dictionary with the attribute names as keys and the new\n values as values.\n\n Returns:\n None\n \"\"\"\n self.__set(**kwargs)\n
Run the function with the given keyword arguments.
Parameters:
Name Type Description Default **kwargs
The keyword arguments to pass to the function.
{}
Returns:
Type Description
The result of calling the populate method of the template object
with the given keyword arguments.
Source code in libs/kotaemon/kotaemon/llms/prompts/base.py
def run(self, **kwargs):\n \"\"\"\n Run the function with the given keyword arguments.\n\n Args:\n **kwargs: The keyword arguments to pass to the function.\n\n Returns:\n The result of calling the `populate` method of the `template` object\n with the given keyword arguments.\n \"\"\"\n self.__set(**kwargs)\n self.__check_unset_placeholders()\n prepared_kwargs = self.__prepare_value()\n\n text = self.template__.populate(**prepared_kwargs)\n return Document(text=text, metadata={\"origin\": \"PromptComponent\"})\n
Source code in libs/kotaemon/kotaemon/llms/prompts/template.py
class PromptTemplate:\n \"\"\"\n Base class for prompt templates.\n \"\"\"\n\n def __init__(self, template: str, ignore_invalid=True):\n template = template\n formatter = Formatter()\n parsed_template = list(formatter.parse(template))\n\n placeholders = set()\n for _, key, _, _ in parsed_template:\n if key is None:\n continue\n if not key.isidentifier():\n if ignore_invalid:\n warnings.warn(f\"Ignore invalid placeholder: {key}.\", UserWarning)\n else:\n raise ValueError(\n \"Placeholder name must be a valid Python identifier, found:\"\n f\" {key}.\"\n )\n placeholders.add(key)\n\n self.template = template\n self.placeholders = placeholders\n self.__formatter = formatter\n self.__parsed_template = parsed_template\n\n def check_missing_kwargs(self, **kwargs):\n \"\"\"\n Check if all the placeholders in the template are set.\n\n This function checks if all the expected placeholders in the template are set as\n attributes of the object. If any placeholders are missing, a `ValueError`\n is raised with the names of the missing keys.\n\n Parameters:\n None\n\n Returns:\n None\n \"\"\"\n missing_keys = self.placeholders.difference(kwargs.keys())\n if missing_keys:\n raise ValueError(f\"Missing keys in template: {','.join(missing_keys)}\")\n\n def check_redundant_kwargs(self, **kwargs):\n \"\"\"\n Check if all the placeholders in the template are set.\n\n This function checks if all the expected placeholders in the template are set as\n attributes of the object. If any placeholders are missing, a `ValueError`\n is raised with the names of the missing keys.\n\n Parameters:\n None\n\n Returns:\n None\n \"\"\"\n provided_keys = set(kwargs.keys())\n redundant_keys = provided_keys - self.placeholders\n\n if redundant_keys:\n warnings.warn(\n f\"Keys provided but not in template: {','.join(redundant_keys)}\",\n UserWarning,\n )\n\n def populate(self, **kwargs) -> str:\n \"\"\"\n Strictly populate the template with the given keyword arguments.\n\n Args:\n **kwargs: The keyword arguments to populate the template.\n Each keyword corresponds to a placeholder in the template.\n\n Returns:\n The populated template.\n\n Raises:\n ValueError: If an unknown placeholder is provided.\n \"\"\"\n self.check_missing_kwargs(**kwargs)\n\n return self.partial_populate(**kwargs)\n\n def partial_populate(self, **kwargs):\n \"\"\"\n Partially populate the template with the given keyword arguments.\n\n Args:\n **kwargs: The keyword arguments to populate the template.\n Each keyword corresponds to a placeholder in the template.\n\n Returns:\n str: The populated template.\n \"\"\"\n self.check_redundant_kwargs(**kwargs)\n\n prompt = []\n for literal_text, field_name, format_spec, conversion in self.__parsed_template:\n prompt.append(literal_text)\n\n if field_name is None:\n continue\n\n if field_name not in kwargs:\n if conversion:\n value = f\"{{{field_name}}}!{conversion}:{format_spec}\"\n else:\n value = f\"{{{field_name}:{format_spec}}}\"\n else:\n value = kwargs[field_name]\n if conversion is not None:\n value = self.__formatter.convert_field(value, conversion)\n if format_spec is not None:\n value = self.__formatter.format_field(value, format_spec)\n\n prompt.append(value)\n\n return \"\".join(prompt)\n\n def __add__(self, other):\n \"\"\"\n Create a new PromptTemplate object by concatenating the template of the current\n object with the template of another PromptTemplate object.\n\n Parameters:\n other (PromptTemplate): Another PromptTemplate object.\n\n Returns:\n PromptTemplate: A new PromptTemplate object with the concatenated templates.\n \"\"\"\n return PromptTemplate(self.template + \"\\n\" + other.template)\n
Check if all the placeholders in the template are set.
This function checks if all the expected placeholders in the template are set as attributes of the object. If any placeholders are missing, a ValueError is raised with the names of the missing keys.
Returns:
Type Description
None
Source code in libs/kotaemon/kotaemon/llms/prompts/template.py
def check_missing_kwargs(self, **kwargs):\n \"\"\"\n Check if all the placeholders in the template are set.\n\n This function checks if all the expected placeholders in the template are set as\n attributes of the object. If any placeholders are missing, a `ValueError`\n is raised with the names of the missing keys.\n\n Parameters:\n None\n\n Returns:\n None\n \"\"\"\n missing_keys = self.placeholders.difference(kwargs.keys())\n if missing_keys:\n raise ValueError(f\"Missing keys in template: {','.join(missing_keys)}\")\n
Check if all the placeholders in the template are set.
This function checks if all the expected placeholders in the template are set as attributes of the object. If any placeholders are missing, a ValueError is raised with the names of the missing keys.
Returns:
Type Description
None
Source code in libs/kotaemon/kotaemon/llms/prompts/template.py
def check_redundant_kwargs(self, **kwargs):\n \"\"\"\n Check if all the placeholders in the template are set.\n\n This function checks if all the expected placeholders in the template are set as\n attributes of the object. If any placeholders are missing, a `ValueError`\n is raised with the names of the missing keys.\n\n Parameters:\n None\n\n Returns:\n None\n \"\"\"\n provided_keys = set(kwargs.keys())\n redundant_keys = provided_keys - self.placeholders\n\n if redundant_keys:\n warnings.warn(\n f\"Keys provided but not in template: {','.join(redundant_keys)}\",\n UserWarning,\n )\n
Strictly populate the template with the given keyword arguments.
Parameters:
Name Type Description Default **kwargs
The keyword arguments to populate the template. Each keyword corresponds to a placeholder in the template.
{}
Returns:
Type Description str
The populated template.
Raises:
Type Description ValueError
If an unknown placeholder is provided.
Source code in libs/kotaemon/kotaemon/llms/prompts/template.py
def populate(self, **kwargs) -> str:\n \"\"\"\n Strictly populate the template with the given keyword arguments.\n\n Args:\n **kwargs: The keyword arguments to populate the template.\n Each keyword corresponds to a placeholder in the template.\n\n Returns:\n The populated template.\n\n Raises:\n ValueError: If an unknown placeholder is provided.\n \"\"\"\n self.check_missing_kwargs(**kwargs)\n\n return self.partial_populate(**kwargs)\n
Partially populate the template with the given keyword arguments.
Parameters:
Name Type Description Default **kwargs
The keyword arguments to populate the template. Each keyword corresponds to a placeholder in the template.
{}
Returns:
Name Type Description str
The populated template.
Source code in libs/kotaemon/kotaemon/llms/prompts/template.py
def partial_populate(self, **kwargs):\n \"\"\"\n Partially populate the template with the given keyword arguments.\n\n Args:\n **kwargs: The keyword arguments to populate the template.\n Each keyword corresponds to a placeholder in the template.\n\n Returns:\n str: The populated template.\n \"\"\"\n self.check_redundant_kwargs(**kwargs)\n\n prompt = []\n for literal_text, field_name, format_spec, conversion in self.__parsed_template:\n prompt.append(literal_text)\n\n if field_name is None:\n continue\n\n if field_name not in kwargs:\n if conversion:\n value = f\"{{{field_name}}}!{conversion}:{format_spec}\"\n else:\n value = f\"{{{field_name}:{format_spec}}}\"\n else:\n value = kwargs[field_name]\n if conversion is not None:\n value = self.__formatter.convert_field(value, conversion)\n if format_spec is not None:\n value = self.__formatter.format_field(value, format_spec)\n\n prompt.append(value)\n\n return \"\".join(prompt)\n
Args: endpoint: URL to the Vision Language Model endpoint. If not provided, will use the default kotaemon.loaders.adobe_loader.DEFAULT_VLM_ENDPOINT
max_figures_to_caption: an int decides how many figured will be captioned.\nThe rest will be ignored (are indexed without captions).\n
Source code in libs/kotaemon/kotaemon/loaders/adobe_loader.py
class AdobeReader(BaseReader):\n \"\"\"Read PDF using the Adobe's PDF Services.\n Be able to extract text, table, and figure with high accuracy\n\n Example:\n ```python\n >> from kotaemon.loaders import AdobeReader\n >> reader = AdobeReader()\n >> documents = reader.load_data(\"path/to/pdf\")\n ```\n Args:\n endpoint: URL to the Vision Language Model endpoint. If not provided,\n will use the default `kotaemon.loaders.adobe_loader.DEFAULT_VLM_ENDPOINT`\n\n max_figures_to_caption: an int decides how many figured will be captioned.\n The rest will be ignored (are indexed without captions).\n \"\"\"\n\n def __init__(\n self,\n vlm_endpoint: Optional[str] = None,\n max_figures_to_caption: int = 100,\n *args: Any,\n **kwargs: Any,\n ) -> None:\n \"\"\"Init params\"\"\"\n super().__init__(*args)\n self.table_regex = r\"/Table(\\[\\d+\\])?$\"\n self.figure_regex = r\"/Figure(\\[\\d+\\])?$\"\n self.vlm_endpoint = vlm_endpoint or DEFAULT_VLM_ENDPOINT\n self.max_figures_to_caption = max_figures_to_caption\n\n def load_data(\n self, file: Path, extra_info: Optional[Dict] = None, **kwargs\n ) -> List[Document]:\n \"\"\"Load data by calling to the Adobe's API\n\n Args:\n file (Path): Path to the PDF file\n\n Returns:\n List[Document]: list of documents extracted from the PDF file,\n includes 3 types: text, table, and image\n\n \"\"\"\n from .utils.adobe import (\n generate_figure_captions,\n load_json,\n parse_figure_paths,\n parse_table_paths,\n request_adobe_service,\n )\n\n filename = file.name\n filepath = str(Path(file).resolve())\n output_path = request_adobe_service(file_path=str(file), output_path=\"\")\n results_path = os.path.join(output_path, \"structuredData.json\")\n\n if not os.path.exists(results_path):\n logger.exception(\"Fail to parse the document.\")\n return []\n\n data = load_json(results_path)\n\n texts = defaultdict(list)\n tables = []\n figures = []\n\n elements = data[\"elements\"]\n for item_id, item in enumerate(elements):\n page_number = item.get(\"Page\", -1) + 1\n item_path = item[\"Path\"]\n item_text = item.get(\"Text\", \"\")\n\n file_paths = [\n Path(output_path) / path for path in item.get(\"filePaths\", [])\n ]\n prev_item = elements[item_id - 1]\n title = prev_item.get(\"Text\", \"\")\n\n if re.search(self.table_regex, item_path):\n table_content = parse_table_paths(file_paths)\n if not table_content:\n continue\n table_caption = (\n table_content.replace(\"|\", \"\").replace(\"---\", \"\")\n + f\"\\n(Table in Page {page_number}. {title})\"\n )\n tables.append((page_number, table_content, table_caption))\n\n elif re.search(self.figure_regex, item_path):\n figure_caption = (\n item_text + f\"\\n(Figure in Page {page_number}. {title})\"\n )\n figure_content = parse_figure_paths(file_paths)\n if not figure_content:\n continue\n figures.append([page_number, figure_content, figure_caption])\n\n else:\n if item_text and \"Table\" not in item_path and \"Figure\" not in item_path:\n texts[page_number].append(item_text)\n\n # get figure caption using GPT-4V\n figure_captions = generate_figure_captions(\n self.vlm_endpoint,\n [item[1] for item in figures],\n self.max_figures_to_caption,\n )\n for item, caption in zip(figures, figure_captions):\n # update figure caption\n item[2] += \" \" + caption\n\n # Wrap elements with Document\n documents = []\n\n # join plain text elements\n for page_number, txts in texts.items():\n documents.append(\n Document(\n text=\"\\n\".join(txts),\n metadata={\n \"page_label\": page_number,\n \"file_name\": filename,\n \"file_path\": filepath,\n },\n )\n )\n\n # table elements\n for page_number, table_content, table_caption in tables:\n documents.append(\n Document(\n text=table_content,\n metadata={\n \"table_origin\": table_content,\n \"type\": \"table\",\n \"page_label\": page_number,\n \"file_name\": filename,\n \"file_path\": filepath,\n },\n metadata_template=\"\",\n metadata_seperator=\"\",\n )\n )\n\n # figure elements\n for page_number, figure_content, figure_caption in figures:\n documents.append(\n Document(\n text=figure_caption,\n metadata={\n \"image_origin\": figure_content,\n \"type\": \"image\",\n \"page_label\": page_number,\n \"file_name\": filename,\n \"file_path\": filepath,\n },\n metadata_template=\"\",\n metadata_seperator=\"\",\n )\n )\n return documents\n
General auto reader for a variety of files. (based on llama-hub)
Source code in libs/kotaemon/kotaemon/loaders/base.py
class AutoReader(BaseReader):\n \"\"\"General auto reader for a variety of files. (based on llama-hub)\"\"\"\n\n def __init__(self, reader_type: Union[str, Type[\"LIBaseReader\"]]) -> None:\n \"\"\"Init reader using string identifier or class name from llama-hub\"\"\"\n\n if isinstance(reader_type, str):\n from llama_index.core import download_loader\n\n self._reader = download_loader(reader_type)()\n else:\n self._reader = reader_type()\n super().__init__()\n\n def load_data(self, file: Union[Path, str], **kwargs: Any) -> List[Document]:\n documents = self._reader.load_data(file=file, **kwargs)\n\n # convert Document to new base class from kotaemon\n converted_documents = [Document.from_dict(doc.to_dict()) for doc in documents]\n return converted_documents\n\n def run(self, file: Union[Path, str], **kwargs: Any) -> List[Document]:\n return self.load_data(file=file, **kwargs)\n
A mapping of file extension to a BaseReader class that specifies how to convert that file to text. If not specified, use default from DEFAULT_FILE_READER_CLS.
A function that takes in a filename and returns a Dict of metadata for the Document. Default is None.
required Source code in libs/kotaemon/kotaemon/loaders/composite_loader.py
class DirectoryReader(LIReaderMixin, BaseReader):\n \"\"\"Wrap around llama-index SimpleDirectoryReader\n\n Args:\n input_dir (str): Path to the directory.\n input_files (List): List of file paths to read\n (Optional; overrides input_dir, exclude)\n exclude (List): glob of python file paths to exclude (Optional)\n exclude_hidden (bool): Whether to exclude hidden files (dotfiles).\n encoding (str): Encoding of the files.\n Default is utf-8.\n errors (str): how encoding and decoding errors are to be handled,\n see https://docs.python.org/3/library/functions.html#open\n recursive (bool): Whether to recursively search in subdirectories.\n False by default.\n filename_as_id (bool): Whether to use the filename as the document id.\n False by default.\n required_exts (Optional[List[str]]): List of required extensions.\n Default is None.\n file_extractor (Optional[Dict[str, BaseReader]]): A mapping of file\n extension to a BaseReader class that specifies how to convert that file\n to text. If not specified, use default from DEFAULT_FILE_READER_CLS.\n num_files_limit (Optional[int]): Maximum number of files to read.\n Default is None.\n file_metadata (Optional[Callable[str, Dict]]): A function that takes\n in a filename and returns a Dict of metadata for the Document.\n Default is None.\n \"\"\"\n\n input_dir: Optional[str] = None\n input_files: Optional[List] = None\n exclude: Optional[List] = None\n exclude_hidden: bool = True\n errors: str = \"ignore\"\n recursive: bool = False\n encoding: str = \"utf-8\"\n filename_as_id: bool = False\n required_exts: Optional[list[str]] = None\n file_extractor: Optional[dict[str, \"LIBaseReader\"]] = None\n num_files_limit: Optional[int] = None\n file_metadata: Optional[Callable[[str], dict]] = None\n\n def _get_wrapped_class(self) -> Type[\"LIBaseReader\"]:\n from llama_index.core import SimpleDirectoryReader\n\n return SimpleDirectoryReader\n
Read Docx files that respect table, using python-docx library
Reader behavior
All paragraphs are extracted as a Document
Each table is extracted as a Document, rendered as a CSV string
The output is a list of Documents, concatenating the above (tables + paragraphs)
Source code in libs/kotaemon/kotaemon/loaders/docx_loader.py
class DocxReader(BaseReader):\n \"\"\"Read Docx files that respect table, using python-docx library\n\n Reader behavior:\n - All paragraphs are extracted as a Document\n - Each table is extracted as a Document, rendered as a CSV string\n - The output is a list of Documents, concatenating the above\n (tables + paragraphs)\n \"\"\"\n\n def __init__(self, *args, **kwargs):\n try:\n import docx # noqa\n except ImportError:\n raise ImportError(\n \"docx is not installed. \"\n \"Please install it using `pip install python-docx`\"\n )\n\n def _load_single_table(self, table) -> List[List[str]]:\n \"\"\"Extract content from tables. Return a list of columns: list[str]\n Some merged cells will share duplicated content.\n \"\"\"\n n_row = len(table.rows)\n n_col = len(table.columns)\n\n arrays = [[\"\" for _ in range(n_row)] for _ in range(n_col)]\n\n for i, row in enumerate(table.rows):\n for j, cell in enumerate(row.cells):\n arrays[j][i] = cell.text\n\n return arrays\n\n def load_data(\n self, file_path: Path, extra_info: Optional[dict] = None, **kwargs\n ) -> List[Document]:\n \"\"\"Load data using Docx reader\n\n Args:\n file_path (Path): Path to .docx file\n\n Returns:\n List[Document]: list of documents extracted from the HTML file\n \"\"\"\n import docx\n\n file_path = Path(file_path).resolve()\n\n doc = docx.Document(str(file_path))\n all_text = \"\\n\".join(\n [unicodedata.normalize(\"NFKC\", p.text) for p in doc.paragraphs]\n )\n pages = [all_text] # 1 page only\n\n tables = []\n for t in doc.tables:\n # return list of columns: list of string\n arrays = self._load_single_table(t)\n\n tables.append(pd.DataFrame({a[0]: a[1:] for a in arrays}))\n\n extra_info = extra_info or {}\n\n # create output Document with metadata from table\n documents = [\n Document(\n text=table.to_csv(\n index=False\n ).strip(), # strip_special_chars_markdown()\n metadata={\n \"table_origin\": table.to_csv(index=False),\n \"type\": \"table\",\n **extra_info,\n },\n metadata_template=\"\",\n metadata_seperator=\"\",\n )\n for table in tables # page_id\n ]\n\n # create Document from non-table text\n documents.extend(\n [\n Document(\n text=non_table_text.strip(),\n metadata={\"page_label\": 1, **extra_info},\n )\n for _, non_table_text in enumerate(pages)\n ]\n )\n\n return documents\n
Parses CSVs using the separator detection from Pandas read_csv function. If special parameters are required, use the pandas_config dict.
Args:
pandas_config (dict): Options for the `pandas.read_excel` function call.\n Refer to https://pandas.pydata.org/docs/reference/api/pandas.read_excel.html\n for more information. Set to empty dict by default,\n this means defaults will be used.\n
Source code in libs/kotaemon/kotaemon/loaders/excel_loader.py
class ExcelReader(BaseReader):\n r\"\"\"Spreadsheet exporter respecting multiple worksheets\n\n Parses CSVs using the separator detection from Pandas `read_csv` function.\n If special parameters are required, use the `pandas_config` dict.\n\n Args:\n\n pandas_config (dict): Options for the `pandas.read_excel` function call.\n Refer to https://pandas.pydata.org/docs/reference/api/pandas.read_excel.html\n for more information. Set to empty dict by default,\n this means defaults will be used.\n\n \"\"\"\n\n def __init__(\n self,\n *args: Any,\n pandas_config: Optional[dict] = None,\n row_joiner: str = \"\\n\",\n col_joiner: str = \" \",\n **kwargs: Any,\n ) -> None:\n \"\"\"Init params.\"\"\"\n super().__init__(*args, **kwargs)\n self._pandas_config = pandas_config or {}\n self._row_joiner = row_joiner if row_joiner else \"\\n\"\n self._col_joiner = col_joiner if col_joiner else \" \"\n\n def load_data(\n self,\n file: Path,\n include_sheetname: bool = True,\n sheet_name: Optional[Union[str, int, list]] = None,\n extra_info: Optional[dict] = None,\n **kwargs,\n ) -> List[Document]:\n \"\"\"Parse file and extract values from a specific column.\n\n Args:\n file (Path): The path to the Excel file to read.\n include_sheetname (bool): Whether to include the sheet name in the output.\n sheet_name (Union[str, int, None]): The specific sheet to read from,\n default is None which reads all sheets.\n\n Returns:\n List[Document]: A list of`Document objects containing the\n values from the specified column in the Excel file.\n \"\"\"\n\n try:\n import pandas as pd\n except ImportError:\n raise ImportError(\n \"install pandas using `pip3 install pandas` to use this loader\"\n )\n\n if sheet_name is not None:\n sheet_name = (\n [sheet_name] if not isinstance(sheet_name, list) else sheet_name\n )\n\n # clean up input\n file = Path(file)\n extra_info = extra_info or {}\n\n dfs = pd.read_excel(file, sheet_name=sheet_name, **self._pandas_config)\n sheet_names = dfs.keys()\n output = []\n\n for idx, key in enumerate(sheet_names):\n dfs[key] = dfs[key].dropna(axis=0, how=\"all\")\n dfs[key] = dfs[key].dropna(axis=0, how=\"all\")\n dfs[key] = dfs[key].astype(\"object\")\n dfs[key].fillna(\"\", inplace=True)\n\n rows = dfs[key].values.astype(str).tolist()\n content = self._row_joiner.join(\n self._col_joiner.join(row).strip() for row in rows\n ).strip()\n if include_sheetname:\n content = f\"(Sheet {key} of file {file.name})\\n{content}\"\n metadata = {\"page_label\": idx + 1, \"sheet_name\": key, **extra_info}\n output.append(Document(text=content, metadata=metadata))\n\n return output\n
Parse file and extract values from a specific column.
Parameters:
Name Type Description Default filePath
The path to the Excel file to read.
required include_sheetnamebool
Whether to include the sheet name in the output.
Truesheet_nameUnion[str, int, None]
The specific sheet to read from, default is None which reads all sheets.
None
Returns:
Type Description List[Document]
List[Document]: A list of`Document objects containing the values from the specified column in the Excel file.
Source code in libs/kotaemon/kotaemon/loaders/excel_loader.py
def load_data(\n self,\n file: Path,\n include_sheetname: bool = True,\n sheet_name: Optional[Union[str, int, list]] = None,\n extra_info: Optional[dict] = None,\n **kwargs,\n) -> List[Document]:\n \"\"\"Parse file and extract values from a specific column.\n\n Args:\n file (Path): The path to the Excel file to read.\n include_sheetname (bool): Whether to include the sheet name in the output.\n sheet_name (Union[str, int, None]): The specific sheet to read from,\n default is None which reads all sheets.\n\n Returns:\n List[Document]: A list of`Document objects containing the\n values from the specified column in the Excel file.\n \"\"\"\n\n try:\n import pandas as pd\n except ImportError:\n raise ImportError(\n \"install pandas using `pip3 install pandas` to use this loader\"\n )\n\n if sheet_name is not None:\n sheet_name = (\n [sheet_name] if not isinstance(sheet_name, list) else sheet_name\n )\n\n # clean up input\n file = Path(file)\n extra_info = extra_info or {}\n\n dfs = pd.read_excel(file, sheet_name=sheet_name, **self._pandas_config)\n sheet_names = dfs.keys()\n output = []\n\n for idx, key in enumerate(sheet_names):\n dfs[key] = dfs[key].dropna(axis=0, how=\"all\")\n dfs[key] = dfs[key].dropna(axis=0, how=\"all\")\n dfs[key] = dfs[key].astype(\"object\")\n dfs[key].fillna(\"\", inplace=True)\n\n rows = dfs[key].values.astype(str).tolist()\n content = self._row_joiner.join(\n self._col_joiner.join(row).strip() for row in rows\n ).strip()\n if include_sheetname:\n content = f\"(Sheet {key} of file {file.name})\\n{content}\"\n metadata = {\"page_label\": idx + 1, \"sheet_name\": key, **extra_info}\n output.append(Document(text=content, metadata=metadata))\n\n return output\n
Parses CSVs using the separator detection from Pandas read_csv function. If special parameters are required, use the pandas_config dict.
Args:
pandas_config (dict): Options for the `pandas.read_excel` function call.\n Refer to https://pandas.pydata.org/docs/reference/api/pandas.read_excel.html\n for more information. Set to empty dict by default,\n this means defaults will be used.\n
Source code in libs/kotaemon/kotaemon/loaders/excel_loader.py
class PandasExcelReader(BaseReader):\n r\"\"\"Pandas-based CSV parser.\n\n Parses CSVs using the separator detection from Pandas `read_csv` function.\n If special parameters are required, use the `pandas_config` dict.\n\n Args:\n\n pandas_config (dict): Options for the `pandas.read_excel` function call.\n Refer to https://pandas.pydata.org/docs/reference/api/pandas.read_excel.html\n for more information. Set to empty dict by default,\n this means defaults will be used.\n\n \"\"\"\n\n def __init__(\n self,\n *args: Any,\n pandas_config: Optional[dict] = None,\n row_joiner: str = \"\\n\",\n col_joiner: str = \" \",\n **kwargs: Any,\n ) -> None:\n \"\"\"Init params.\"\"\"\n super().__init__(*args, **kwargs)\n self._pandas_config = pandas_config or {}\n self._row_joiner = row_joiner if row_joiner else \"\\n\"\n self._col_joiner = col_joiner if col_joiner else \" \"\n\n def load_data(\n self,\n file: Path,\n include_sheetname: bool = False,\n sheet_name: Optional[Union[str, int, list]] = None,\n extra_info: Optional[dict] = None,\n **kwargs,\n ) -> List[Document]:\n \"\"\"Parse file and extract values from a specific column.\n\n Args:\n file (Path): The path to the Excel file to read.\n include_sheetname (bool): Whether to include the sheet name in the output.\n sheet_name (Union[str, int, None]): The specific sheet to read from,\n default is None which reads all sheets.\n\n Returns:\n List[Document]: A list of`Document objects containing the\n values from the specified column in the Excel file.\n \"\"\"\n import itertools\n\n try:\n import pandas as pd\n except ImportError:\n raise ImportError(\n \"install pandas using `pip3 install pandas` to use this loader\"\n )\n\n if sheet_name is not None:\n sheet_name = (\n [sheet_name] if not isinstance(sheet_name, list) else sheet_name\n )\n\n dfs = pd.read_excel(file, sheet_name=sheet_name, **self._pandas_config)\n sheet_names = dfs.keys()\n df_sheets = []\n\n for key in sheet_names:\n sheet = []\n if include_sheetname:\n sheet.append([key])\n dfs[key] = dfs[key].dropna(axis=0, how=\"all\")\n dfs[key] = dfs[key].dropna(axis=0, how=\"all\")\n dfs[key].fillna(\"\", inplace=True)\n sheet.extend(dfs[key].values.astype(str).tolist())\n df_sheets.append(sheet)\n\n text_list = list(\n itertools.chain.from_iterable(df_sheets)\n ) # flatten list of lists\n\n output = [\n Document(\n text=self._row_joiner.join(\n self._col_joiner.join(sublist) for sublist in text_list\n ),\n metadata=extra_info or {},\n )\n ]\n\n return output\n
Parse file and extract values from a specific column.
Parameters:
Name Type Description Default filePath
The path to the Excel file to read.
required include_sheetnamebool
Whether to include the sheet name in the output.
Falsesheet_nameUnion[str, int, None]
The specific sheet to read from, default is None which reads all sheets.
None
Returns:
Type Description List[Document]
List[Document]: A list of`Document objects containing the values from the specified column in the Excel file.
Source code in libs/kotaemon/kotaemon/loaders/excel_loader.py
def load_data(\n self,\n file: Path,\n include_sheetname: bool = False,\n sheet_name: Optional[Union[str, int, list]] = None,\n extra_info: Optional[dict] = None,\n **kwargs,\n) -> List[Document]:\n \"\"\"Parse file and extract values from a specific column.\n\n Args:\n file (Path): The path to the Excel file to read.\n include_sheetname (bool): Whether to include the sheet name in the output.\n sheet_name (Union[str, int, None]): The specific sheet to read from,\n default is None which reads all sheets.\n\n Returns:\n List[Document]: A list of`Document objects containing the\n values from the specified column in the Excel file.\n \"\"\"\n import itertools\n\n try:\n import pandas as pd\n except ImportError:\n raise ImportError(\n \"install pandas using `pip3 install pandas` to use this loader\"\n )\n\n if sheet_name is not None:\n sheet_name = (\n [sheet_name] if not isinstance(sheet_name, list) else sheet_name\n )\n\n dfs = pd.read_excel(file, sheet_name=sheet_name, **self._pandas_config)\n sheet_names = dfs.keys()\n df_sheets = []\n\n for key in sheet_names:\n sheet = []\n if include_sheetname:\n sheet.append([key])\n dfs[key] = dfs[key].dropna(axis=0, how=\"all\")\n dfs[key] = dfs[key].dropna(axis=0, how=\"all\")\n dfs[key].fillna(\"\", inplace=True)\n sheet.extend(dfs[key].values.astype(str).tolist())\n df_sheets.append(sheet)\n\n text_list = list(\n itertools.chain.from_iterable(df_sheets)\n ) # flatten list of lists\n\n output = [\n Document(\n text=self._row_joiner.join(\n self._col_joiner.join(sublist) for sublist in text_list\n ),\n metadata=extra_info or {},\n )\n ]\n\n return output\n
All of the texts will be split by page_break_pattern
Each page is extracted as a Document
The output is a list of Documents
Parameters:
Name Type Description Default page_break_patternstr
Pattern to split the HTML into pages
None Source code in libs/kotaemon/kotaemon/loaders/html_loader.py
class HtmlReader(BaseReader):\n \"\"\"Reader HTML usimg html2text\n\n Reader behavior:\n - HTML is read with html2text.\n - All of the texts will be split by `page_break_pattern`\n - Each page is extracted as a Document\n - The output is a list of Documents\n\n Args:\n page_break_pattern (str): Pattern to split the HTML into pages\n \"\"\"\n\n def __init__(self, page_break_pattern: Optional[str] = None, *args, **kwargs):\n try:\n import html2text # noqa\n except ImportError:\n raise ImportError(\n \"html2text is not installed. \"\n \"Please install it using `pip install html2text`\"\n )\n\n self._page_break_pattern: Optional[str] = page_break_pattern\n super().__init__()\n\n def load_data(\n self, file_path: Path | str, extra_info: Optional[dict] = None, **kwargs\n ) -> list[Document]:\n \"\"\"Load data using Html reader\n\n Args:\n file_path: path to HTML file\n extra_info: extra information passed to this reader during extracting data\n\n Returns:\n list[Document]: list of documents extracted from the HTML file\n \"\"\"\n import html2text\n\n file_path = Path(file_path).resolve()\n\n with file_path.open(\"r\") as f:\n html_text = \"\".join([line[:-1] for line in f.readlines()])\n\n # read HTML\n all_text = html2text.html2text(html_text)\n pages = (\n all_text.split(self._page_break_pattern)\n if self._page_break_pattern\n else [all_text]\n )\n\n extra_info = extra_info or {}\n\n # create Document from non-table text\n documents = [\n Document(\n text=page.strip(),\n metadata={\"page_label\": page_id + 1, **extra_info},\n )\n for page_id, page in enumerate(pages)\n ]\n\n return documents\n
extra information passed to this reader during extracting data
None
Returns:
Type Description list[Document]
list[Document]: list of documents extracted from the HTML file
Source code in libs/kotaemon/kotaemon/loaders/html_loader.py
def load_data(\n self, file_path: Path | str, extra_info: Optional[dict] = None, **kwargs\n) -> list[Document]:\n \"\"\"Load data using Html reader\n\n Args:\n file_path: path to HTML file\n extra_info: extra information passed to this reader during extracting data\n\n Returns:\n list[Document]: list of documents extracted from the HTML file\n \"\"\"\n import html2text\n\n file_path = Path(file_path).resolve()\n\n with file_path.open(\"r\") as f:\n html_text = \"\".join([line[:-1] for line in f.readlines()])\n\n # read HTML\n all_text = html2text.html2text(html_text)\n pages = (\n all_text.split(self._page_break_pattern)\n if self._page_break_pattern\n else [all_text]\n )\n\n extra_info = extra_info or {}\n\n # create Document from non-table text\n documents = [\n Document(\n text=page.strip(),\n metadata={\"page_label\": page_id + 1, **extra_info},\n )\n for page_id, page in enumerate(pages)\n ]\n\n return documents\n
Source code in libs/kotaemon/kotaemon/loaders/html_loader.py
class MhtmlReader(BaseReader):\n \"\"\"Parse `MHTML` files with `BeautifulSoup`.\"\"\"\n\n def __init__(\n self,\n cache_dir: Optional[str] = getattr(\n flowsettings, \"KH_MARKDOWN_OUTPUT_DIR\", None\n ),\n open_encoding: Optional[str] = None,\n bs_kwargs: Optional[dict] = None,\n get_text_separator: str = \"\",\n ) -> None:\n \"\"\"initialize with path, and optionally, file encoding to use, and any kwargs\n to pass to the BeautifulSoup object.\n\n Args:\n cache_dir: Path for markdwon format.\n file_path: Path to file to load.\n open_encoding: The encoding to use when opening the file.\n bs_kwargs: Any kwargs to pass to the BeautifulSoup object.\n get_text_separator: The separator to use when getting the text\n from the soup.\n \"\"\"\n try:\n import bs4 # noqa:F401\n except ImportError:\n raise ImportError(\n \"beautifulsoup4 package not found, please install it with \"\n \"`pip install beautifulsoup4`\"\n )\n\n self.cache_dir = cache_dir\n self.open_encoding = open_encoding\n if bs_kwargs is None:\n bs_kwargs = {\"features\": \"lxml\"}\n self.bs_kwargs = bs_kwargs\n self.get_text_separator = get_text_separator\n\n def load_data(\n self, file_path: Path | str, extra_info: Optional[dict] = None, **kwargs\n ) -> list[Document]:\n \"\"\"Load MHTML document into document objects.\"\"\"\n\n from bs4 import BeautifulSoup\n\n extra_info = extra_info or {}\n metadata: dict = extra_info\n page = []\n file_name = Path(file_path)\n with open(file_path, \"r\", encoding=self.open_encoding) as f:\n message = email.message_from_string(f.read())\n parts = message.get_payload()\n\n if not isinstance(parts, list):\n parts = [message]\n\n for part in parts:\n if part.get_content_type() == \"text/html\":\n html = part.get_payload(decode=True).decode()\n\n soup = BeautifulSoup(html, **self.bs_kwargs)\n text = soup.get_text(self.get_text_separator)\n\n if soup.title:\n title = str(soup.title.string)\n else:\n title = \"\"\n\n metadata = {\n \"source\": str(file_path),\n \"title\": title,\n **extra_info,\n }\n lines = [line for line in text.split(\"\\n\") if line.strip()]\n text = \"\\n\\n\".join(lines)\n if text:\n page.append(text)\n # save the page into markdown format\n print(self.cache_dir)\n if self.cache_dir is not None:\n print(Path(self.cache_dir) / f\"{file_name.stem}.md\")\n with open(Path(self.cache_dir) / f\"{file_name.stem}.md\", \"w\") as f:\n f.write(page[0])\n\n return [Document(text=\"\\n\\n\".join(page), metadata=metadata)]\n
Source code in libs/kotaemon/kotaemon/loaders/html_loader.py
def load_data(\n self, file_path: Path | str, extra_info: Optional[dict] = None, **kwargs\n) -> list[Document]:\n \"\"\"Load MHTML document into document objects.\"\"\"\n\n from bs4 import BeautifulSoup\n\n extra_info = extra_info or {}\n metadata: dict = extra_info\n page = []\n file_name = Path(file_path)\n with open(file_path, \"r\", encoding=self.open_encoding) as f:\n message = email.message_from_string(f.read())\n parts = message.get_payload()\n\n if not isinstance(parts, list):\n parts = [message]\n\n for part in parts:\n if part.get_content_type() == \"text/html\":\n html = part.get_payload(decode=True).decode()\n\n soup = BeautifulSoup(html, **self.bs_kwargs)\n text = soup.get_text(self.get_text_separator)\n\n if soup.title:\n title = str(soup.title.string)\n else:\n title = \"\"\n\n metadata = {\n \"source\": str(file_path),\n \"title\": title,\n **extra_info,\n }\n lines = [line for line in text.split(\"\\n\") if line.strip()]\n text = \"\\n\\n\".join(lines)\n if text:\n page.append(text)\n # save the page into markdown format\n print(self.cache_dir)\n if self.cache_dir is not None:\n print(Path(self.cache_dir) / f\"{file_name.stem}.md\")\n with open(Path(self.cache_dir) / f\"{file_name.stem}.md\", \"w\") as f:\n f.write(page[0])\n\n return [Document(text=\"\\n\\n\".join(page), metadata=metadata)]\n
Source code in libs/kotaemon/kotaemon/loaders/mathpix_loader.py
def wait_for_processing(self, pdf_id: str) -> None:\n \"\"\"Wait for processing to complete.\n\n Args:\n pdf_id: a PDF id.\n\n Returns: None\n \"\"\"\n url = self.url + \"/\" + pdf_id\n for _ in range(0, self.max_wait_time_seconds, 5):\n response = requests.get(url, headers=self._mathpix_headers)\n response_data = response.json()\n status = response_data.get(\"status\", None)\n\n if status == \"completed\":\n return\n elif status == \"error\":\n raise ValueError(\"Unable to retrieve PDF from Mathpix\")\n else:\n print(response_data)\n print(url)\n time.sleep(5)\n raise TimeoutError\n
Name Type Description Default endpointOptional[str]
URL to FullOCR endpoint. If not provided, will look for environment variable OCR_READER_ENDPOINT or use the default knowledgehub.loaders.ocr_loader.DEFAULT_OCR_ENDPOINT (http://127.0.0.1:8000/v2/ai/infer/)
Noneuse_ocr
whether to use OCR to read text (e.g: from images, tables) in the PDF If False, only the table and text within table cells will be extracted.
required Source code in libs/kotaemon/kotaemon/loaders/ocr_loader.py
class ImageReader(BaseReader):\n \"\"\"Read PDF using OCR, with high focus on table extraction\n\n Example:\n ```python\n >> from knowledgehub.loaders import OCRReader\n >> reader = OCRReader()\n >> documents = reader.load_data(\"path/to/pdf\")\n ```\n\n Args:\n endpoint: URL to FullOCR endpoint. If not provided, will look for\n environment variable `OCR_READER_ENDPOINT` or use the default\n `knowledgehub.loaders.ocr_loader.DEFAULT_OCR_ENDPOINT`\n (http://127.0.0.1:8000/v2/ai/infer/)\n use_ocr: whether to use OCR to read text (e.g: from images, tables) in the PDF\n If False, only the table and text within table cells will be extracted.\n \"\"\"\n\n def __init__(self, endpoint: Optional[str] = None):\n \"\"\"Init the OCR reader with OCR endpoint (FullOCR pipeline)\"\"\"\n super().__init__()\n self.ocr_endpoint = endpoint or os.getenv(\n \"OCR_READER_ENDPOINT\", DEFAULT_OCR_ENDPOINT\n )\n\n def load_data(\n self, file_path: Path, extra_info: Optional[dict] = None, **kwargs\n ) -> List[Document]:\n \"\"\"Load data using OCR reader\n\n Args:\n file_path (Path): Path to PDF file\n debug_path (Path): Path to store debug image output\n artifact_path (Path): Path to OCR endpoints artifacts directory\n\n Returns:\n List[Document]: list of documents extracted from the PDF file\n \"\"\"\n file_path = Path(file_path).resolve()\n\n # call the API from FullOCR endpoint\n if \"response_content\" in kwargs:\n # overriding response content if specified\n ocr_results = kwargs[\"response_content\"]\n else:\n # call original API\n resp = tenacious_api_post(\n url=self.ocr_endpoint, file_path=file_path, table_only=False\n )\n ocr_results = resp.json()[\"result\"]\n\n extra_info = extra_info or {}\n result = []\n for ocr_result in ocr_results:\n result.append(\n Document(\n content=ocr_result[\"csv_string\"],\n metadata=extra_info,\n )\n )\n\n return result\n
List[Document]: list of documents extracted from the PDF file
Source code in libs/kotaemon/kotaemon/loaders/ocr_loader.py
def load_data(\n self, file_path: Path, extra_info: Optional[dict] = None, **kwargs\n) -> List[Document]:\n \"\"\"Load data using OCR reader\n\n Args:\n file_path (Path): Path to PDF file\n debug_path (Path): Path to store debug image output\n artifact_path (Path): Path to OCR endpoints artifacts directory\n\n Returns:\n List[Document]: list of documents extracted from the PDF file\n \"\"\"\n file_path = Path(file_path).resolve()\n\n # call the API from FullOCR endpoint\n if \"response_content\" in kwargs:\n # overriding response content if specified\n ocr_results = kwargs[\"response_content\"]\n else:\n # call original API\n resp = tenacious_api_post(\n url=self.ocr_endpoint, file_path=file_path, table_only=False\n )\n ocr_results = resp.json()[\"result\"]\n\n extra_info = extra_info or {}\n result = []\n for ocr_result in ocr_results:\n result.append(\n Document(\n content=ocr_result[\"csv_string\"],\n metadata=extra_info,\n )\n )\n\n return result\n
Name Type Description Default endpointOptional[str]
URL to FullOCR endpoint. If not provided, will look for environment variable OCR_READER_ENDPOINT or use the default kotaemon.loaders.ocr_loader.DEFAULT_OCR_ENDPOINT (http://127.0.0.1:8000/v2/ai/infer/)
Noneuse_ocr
whether to use OCR to read text (e.g: from images, tables) in the PDF If False, only the table and text within table cells will be extracted.
True Source code in libs/kotaemon/kotaemon/loaders/ocr_loader.py
class OCRReader(BaseReader):\n \"\"\"Read PDF using OCR, with high focus on table extraction\n\n Example:\n ```python\n >> from kotaemon.loaders import OCRReader\n >> reader = OCRReader()\n >> documents = reader.load_data(\"path/to/pdf\")\n ```\n\n Args:\n endpoint: URL to FullOCR endpoint. If not provided, will look for\n environment variable `OCR_READER_ENDPOINT` or use the default\n `kotaemon.loaders.ocr_loader.DEFAULT_OCR_ENDPOINT`\n (http://127.0.0.1:8000/v2/ai/infer/)\n use_ocr: whether to use OCR to read text (e.g: from images, tables) in the PDF\n If False, only the table and text within table cells will be extracted.\n \"\"\"\n\n def __init__(self, endpoint: Optional[str] = None, use_ocr=True):\n \"\"\"Init the OCR reader with OCR endpoint (FullOCR pipeline)\"\"\"\n super().__init__()\n self.ocr_endpoint = endpoint or os.getenv(\n \"OCR_READER_ENDPOINT\", DEFAULT_OCR_ENDPOINT\n )\n self.use_ocr = use_ocr\n\n def load_data(\n self, file_path: Path, extra_info: Optional[dict] = None, **kwargs\n ) -> List[Document]:\n \"\"\"Load data using OCR reader\n\n Args:\n file_path (Path): Path to PDF file\n debug_path (Path): Path to store debug image output\n artifact_path (Path): Path to OCR endpoints artifacts directory\n\n Returns:\n List[Document]: list of documents extracted from the PDF file\n \"\"\"\n file_path = Path(file_path).resolve()\n\n # call the API from FullOCR endpoint\n if \"response_content\" in kwargs:\n # overriding response content if specified\n ocr_results = kwargs[\"response_content\"]\n else:\n # call original API\n resp = tenacious_api_post(\n url=self.ocr_endpoint, file_path=file_path, table_only=not self.use_ocr\n )\n ocr_results = resp.json()[\"result\"]\n\n debug_path = kwargs.pop(\"debug_path\", None)\n artifact_path = kwargs.pop(\"artifact_path\", None)\n\n # read PDF through normal reader (unstructured)\n pdf_page_items = read_pdf_unstructured(file_path)\n # merge PDF text output with OCR output\n tables, texts = parse_ocr_output(\n ocr_results,\n pdf_page_items,\n debug_path=debug_path,\n artifact_path=artifact_path,\n )\n extra_info = extra_info or {}\n\n # create output Document with metadata from table\n documents = [\n Document(\n text=strip_special_chars_markdown(table_text),\n metadata={\n \"table_origin\": table_text,\n \"type\": \"table\",\n \"page_label\": page_id + 1,\n **extra_info,\n },\n metadata_template=\"\",\n metadata_seperator=\"\",\n )\n for page_id, table_text in tables\n ]\n # create Document from non-table text\n documents.extend(\n [\n Document(\n text=non_table_text,\n metadata={\"page_label\": page_id + 1, **extra_info},\n )\n for page_id, non_table_text in texts\n ]\n )\n\n return documents\n
General unstructured text reader for a variety of files.
Source code in libs/kotaemon/kotaemon/loaders/unstructured_loader.py
class UnstructuredReader(BaseReader):\n \"\"\"General unstructured text reader for a variety of files.\"\"\"\n\n def __init__(self, *args: Any, **kwargs: Any) -> None:\n \"\"\"Init params.\"\"\"\n super().__init__(*args) # not passing kwargs to parent bc it cannot accept it\n\n self.api = False # we default to local\n if \"url\" in kwargs:\n self.server_url = str(kwargs[\"url\"])\n self.api = True # is url was set, switch to api\n else:\n self.server_url = \"http://localhost:8000\"\n\n if \"api\" in kwargs:\n self.api = kwargs[\"api\"]\n\n self.api_key = \"\"\n if \"api_key\" in kwargs:\n self.api_key = kwargs[\"api_key\"]\n\n \"\"\" Loads data using Unstructured.io\n\n Depending on the construction if url is set or api = True\n it'll parse file using API call, else parse it locally\n additional_metadata is extended by the returned metadata if\n split_documents is True\n\n Returns list of documents\n \"\"\"\n\n def load_data(\n self,\n file: Path,\n extra_info: Optional[Dict] = None,\n split_documents: Optional[bool] = False,\n **kwargs,\n ) -> List[Document]:\n \"\"\"If api is set, parse through api\"\"\"\n file_path_str = str(file)\n if self.api:\n from unstructured.partition.api import partition_via_api\n\n elements = partition_via_api(\n filename=file_path_str,\n api_key=self.api_key,\n api_url=self.server_url + \"/general/v0/general\",\n )\n else:\n \"\"\"Parse file locally\"\"\"\n from unstructured.partition.auto import partition\n\n elements = partition(filename=file_path_str)\n\n \"\"\" Process elements \"\"\"\n docs = []\n file_name = Path(file).name\n file_path = str(Path(file).resolve())\n if split_documents:\n for node in elements:\n metadata = {\"file_name\": file_name, \"file_path\": file_path}\n if hasattr(node, \"metadata\"):\n \"\"\"Load metadata fields\"\"\"\n for field, val in vars(node.metadata).items():\n if field == \"_known_field_names\":\n continue\n # removing coordinates because it does not serialize\n # and dont want to bother with it\n if field == \"coordinates\":\n continue\n # removing bc it might cause interference\n if field == \"parent_id\":\n continue\n metadata[field] = val\n\n if extra_info is not None:\n metadata.update(extra_info)\n\n metadata[\"file_name\"] = file_name\n docs.append(Document(text=node.text, metadata=metadata))\n\n else:\n text_chunks = [\" \".join(str(el).split()) for el in elements]\n metadata = {\"file_name\": file_name, \"file_path\": file_path}\n\n if extra_info is not None:\n metadata.update(extra_info)\n\n # Create a single document by joining all the texts\n docs.append(Document(text=\"\\n\\n\".join(text_chunks), metadata=metadata))\n\n return docs\n
Source code in libs/kotaemon/kotaemon/loaders/unstructured_loader.py
def load_data(\n self,\n file: Path,\n extra_info: Optional[Dict] = None,\n split_documents: Optional[bool] = False,\n **kwargs,\n) -> List[Document]:\n \"\"\"If api is set, parse through api\"\"\"\n file_path_str = str(file)\n if self.api:\n from unstructured.partition.api import partition_via_api\n\n elements = partition_via_api(\n filename=file_path_str,\n api_key=self.api_key,\n api_url=self.server_url + \"/general/v0/general\",\n )\n else:\n \"\"\"Parse file locally\"\"\"\n from unstructured.partition.auto import partition\n\n elements = partition(filename=file_path_str)\n\n \"\"\" Process elements \"\"\"\n docs = []\n file_name = Path(file).name\n file_path = str(Path(file).resolve())\n if split_documents:\n for node in elements:\n metadata = {\"file_name\": file_name, \"file_path\": file_path}\n if hasattr(node, \"metadata\"):\n \"\"\"Load metadata fields\"\"\"\n for field, val in vars(node.metadata).items():\n if field == \"_known_field_names\":\n continue\n # removing coordinates because it does not serialize\n # and dont want to bother with it\n if field == \"coordinates\":\n continue\n # removing bc it might cause interference\n if field == \"parent_id\":\n continue\n metadata[field] = val\n\n if extra_info is not None:\n metadata.update(extra_info)\n\n metadata[\"file_name\"] = file_name\n docs.append(Document(text=node.text, metadata=metadata))\n\n else:\n text_chunks = [\" \".join(str(el).split()) for el in elements]\n metadata = {\"file_name\": file_name, \"file_path\": file_path}\n\n if extra_info is not None:\n metadata.update(extra_info)\n\n # Create a single document by joining all the texts\n docs.append(Document(text=\"\\n\\n\".join(text_chunks), metadata=metadata))\n\n return docs\n
Args: endpoint: URL to the Vision Language Model endpoint. If not provided, will use the default kotaemon.loaders.adobe_loader.DEFAULT_VLM_ENDPOINT
max_figures_to_caption: an int decides how many figured will be captioned.\nThe rest will be ignored (are indexed without captions).\n
Source code in libs/kotaemon/kotaemon/loaders/adobe_loader.py
class AdobeReader(BaseReader):\n \"\"\"Read PDF using the Adobe's PDF Services.\n Be able to extract text, table, and figure with high accuracy\n\n Example:\n ```python\n >> from kotaemon.loaders import AdobeReader\n >> reader = AdobeReader()\n >> documents = reader.load_data(\"path/to/pdf\")\n ```\n Args:\n endpoint: URL to the Vision Language Model endpoint. If not provided,\n will use the default `kotaemon.loaders.adobe_loader.DEFAULT_VLM_ENDPOINT`\n\n max_figures_to_caption: an int decides how many figured will be captioned.\n The rest will be ignored (are indexed without captions).\n \"\"\"\n\n def __init__(\n self,\n vlm_endpoint: Optional[str] = None,\n max_figures_to_caption: int = 100,\n *args: Any,\n **kwargs: Any,\n ) -> None:\n \"\"\"Init params\"\"\"\n super().__init__(*args)\n self.table_regex = r\"/Table(\\[\\d+\\])?$\"\n self.figure_regex = r\"/Figure(\\[\\d+\\])?$\"\n self.vlm_endpoint = vlm_endpoint or DEFAULT_VLM_ENDPOINT\n self.max_figures_to_caption = max_figures_to_caption\n\n def load_data(\n self, file: Path, extra_info: Optional[Dict] = None, **kwargs\n ) -> List[Document]:\n \"\"\"Load data by calling to the Adobe's API\n\n Args:\n file (Path): Path to the PDF file\n\n Returns:\n List[Document]: list of documents extracted from the PDF file,\n includes 3 types: text, table, and image\n\n \"\"\"\n from .utils.adobe import (\n generate_figure_captions,\n load_json,\n parse_figure_paths,\n parse_table_paths,\n request_adobe_service,\n )\n\n filename = file.name\n filepath = str(Path(file).resolve())\n output_path = request_adobe_service(file_path=str(file), output_path=\"\")\n results_path = os.path.join(output_path, \"structuredData.json\")\n\n if not os.path.exists(results_path):\n logger.exception(\"Fail to parse the document.\")\n return []\n\n data = load_json(results_path)\n\n texts = defaultdict(list)\n tables = []\n figures = []\n\n elements = data[\"elements\"]\n for item_id, item in enumerate(elements):\n page_number = item.get(\"Page\", -1) + 1\n item_path = item[\"Path\"]\n item_text = item.get(\"Text\", \"\")\n\n file_paths = [\n Path(output_path) / path for path in item.get(\"filePaths\", [])\n ]\n prev_item = elements[item_id - 1]\n title = prev_item.get(\"Text\", \"\")\n\n if re.search(self.table_regex, item_path):\n table_content = parse_table_paths(file_paths)\n if not table_content:\n continue\n table_caption = (\n table_content.replace(\"|\", \"\").replace(\"---\", \"\")\n + f\"\\n(Table in Page {page_number}. {title})\"\n )\n tables.append((page_number, table_content, table_caption))\n\n elif re.search(self.figure_regex, item_path):\n figure_caption = (\n item_text + f\"\\n(Figure in Page {page_number}. {title})\"\n )\n figure_content = parse_figure_paths(file_paths)\n if not figure_content:\n continue\n figures.append([page_number, figure_content, figure_caption])\n\n else:\n if item_text and \"Table\" not in item_path and \"Figure\" not in item_path:\n texts[page_number].append(item_text)\n\n # get figure caption using GPT-4V\n figure_captions = generate_figure_captions(\n self.vlm_endpoint,\n [item[1] for item in figures],\n self.max_figures_to_caption,\n )\n for item, caption in zip(figures, figure_captions):\n # update figure caption\n item[2] += \" \" + caption\n\n # Wrap elements with Document\n documents = []\n\n # join plain text elements\n for page_number, txts in texts.items():\n documents.append(\n Document(\n text=\"\\n\".join(txts),\n metadata={\n \"page_label\": page_number,\n \"file_name\": filename,\n \"file_path\": filepath,\n },\n )\n )\n\n # table elements\n for page_number, table_content, table_caption in tables:\n documents.append(\n Document(\n text=table_content,\n metadata={\n \"table_origin\": table_content,\n \"type\": \"table\",\n \"page_label\": page_number,\n \"file_name\": filename,\n \"file_path\": filepath,\n },\n metadata_template=\"\",\n metadata_seperator=\"\",\n )\n )\n\n # figure elements\n for page_number, figure_content, figure_caption in figures:\n documents.append(\n Document(\n text=figure_caption,\n metadata={\n \"image_origin\": figure_content,\n \"type\": \"image\",\n \"page_label\": page_number,\n \"file_name\": filename,\n \"file_path\": filepath,\n },\n metadata_template=\"\",\n metadata_seperator=\"\",\n )\n )\n return documents\n
General auto reader for a variety of files. (based on llama-hub)
Source code in libs/kotaemon/kotaemon/loaders/base.py
class AutoReader(BaseReader):\n \"\"\"General auto reader for a variety of files. (based on llama-hub)\"\"\"\n\n def __init__(self, reader_type: Union[str, Type[\"LIBaseReader\"]]) -> None:\n \"\"\"Init reader using string identifier or class name from llama-hub\"\"\"\n\n if isinstance(reader_type, str):\n from llama_index.core import download_loader\n\n self._reader = download_loader(reader_type)()\n else:\n self._reader = reader_type()\n super().__init__()\n\n def load_data(self, file: Union[Path, str], **kwargs: Any) -> List[Document]:\n documents = self._reader.load_data(file=file, **kwargs)\n\n # convert Document to new base class from kotaemon\n converted_documents = [Document.from_dict(doc.to_dict()) for doc in documents]\n return converted_documents\n\n def run(self, file: Union[Path, str], **kwargs: Any) -> List[Document]:\n return self.load_data(file=file, **kwargs)\n
Source code in libs/kotaemon/kotaemon/loaders/base.py
class LIReaderMixin(BaseComponent):\n \"\"\"Base wrapper around llama-index reader\n\n To use the LIBaseReader, you need to implement the _get_wrapped_class method to\n return the relevant llama-index reader class that you want to wrap.\n\n Example:\n\n ```python\n class DirectoryReader(LIBaseReader):\n def _get_wrapped_class(self) -> Type[\"BaseReader\"]:\n from llama_index import SimpleDirectoryReader\n\n return SimpleDirectoryReader\n ```\n \"\"\"\n\n def _get_wrapped_class(self) -> Type[\"LIBaseReader\"]:\n raise NotImplementedError(\n \"Please return the relevant llama-index class in in _get_wrapped_class\"\n )\n\n def __init__(self, *args, **kwargs):\n self._reader_class = self._get_wrapped_class()\n self._reader = self._reader_class(*args, **kwargs)\n super().__init__()\n\n def __setattr__(self, name: str, value: Any) -> None:\n if name.startswith(\"_\"):\n return super().__setattr__(name, value)\n\n return setattr(self._reader, name, value)\n\n def __getattr__(self, name: str) -> Any:\n return getattr(self._reader, name)\n\n def load_data(self, *args, **kwargs: Any) -> List[Document]:\n documents = self._reader.load_data(*args, **kwargs)\n\n # convert Document to new base class from kotaemon\n converted_documents = [Document.from_dict(doc.to_dict()) for doc in documents]\n return converted_documents\n\n def run(self, *args, **kwargs: Any) -> List[Document]:\n return self.load_data(*args, **kwargs)\n
A mapping of file extension to a BaseReader class that specifies how to convert that file to text. If not specified, use default from DEFAULT_FILE_READER_CLS.
A function that takes in a filename and returns a Dict of metadata for the Document. Default is None.
required Source code in libs/kotaemon/kotaemon/loaders/composite_loader.py
class DirectoryReader(LIReaderMixin, BaseReader):\n \"\"\"Wrap around llama-index SimpleDirectoryReader\n\n Args:\n input_dir (str): Path to the directory.\n input_files (List): List of file paths to read\n (Optional; overrides input_dir, exclude)\n exclude (List): glob of python file paths to exclude (Optional)\n exclude_hidden (bool): Whether to exclude hidden files (dotfiles).\n encoding (str): Encoding of the files.\n Default is utf-8.\n errors (str): how encoding and decoding errors are to be handled,\n see https://docs.python.org/3/library/functions.html#open\n recursive (bool): Whether to recursively search in subdirectories.\n False by default.\n filename_as_id (bool): Whether to use the filename as the document id.\n False by default.\n required_exts (Optional[List[str]]): List of required extensions.\n Default is None.\n file_extractor (Optional[Dict[str, BaseReader]]): A mapping of file\n extension to a BaseReader class that specifies how to convert that file\n to text. If not specified, use default from DEFAULT_FILE_READER_CLS.\n num_files_limit (Optional[int]): Maximum number of files to read.\n Default is None.\n file_metadata (Optional[Callable[str, Dict]]): A function that takes\n in a filename and returns a Dict of metadata for the Document.\n Default is None.\n \"\"\"\n\n input_dir: Optional[str] = None\n input_files: Optional[List] = None\n exclude: Optional[List] = None\n exclude_hidden: bool = True\n errors: str = \"ignore\"\n recursive: bool = False\n encoding: str = \"utf-8\"\n filename_as_id: bool = False\n required_exts: Optional[list[str]] = None\n file_extractor: Optional[dict[str, \"LIBaseReader\"]] = None\n num_files_limit: Optional[int] = None\n file_metadata: Optional[Callable[[str], dict]] = None\n\n def _get_wrapped_class(self) -> Type[\"LIBaseReader\"]:\n from llama_index.core import SimpleDirectoryReader\n\n return SimpleDirectoryReader\n
Read Docx files that respect table, using python-docx library
Reader behavior
All paragraphs are extracted as a Document
Each table is extracted as a Document, rendered as a CSV string
The output is a list of Documents, concatenating the above (tables + paragraphs)
Source code in libs/kotaemon/kotaemon/loaders/docx_loader.py
class DocxReader(BaseReader):\n \"\"\"Read Docx files that respect table, using python-docx library\n\n Reader behavior:\n - All paragraphs are extracted as a Document\n - Each table is extracted as a Document, rendered as a CSV string\n - The output is a list of Documents, concatenating the above\n (tables + paragraphs)\n \"\"\"\n\n def __init__(self, *args, **kwargs):\n try:\n import docx # noqa\n except ImportError:\n raise ImportError(\n \"docx is not installed. \"\n \"Please install it using `pip install python-docx`\"\n )\n\n def _load_single_table(self, table) -> List[List[str]]:\n \"\"\"Extract content from tables. Return a list of columns: list[str]\n Some merged cells will share duplicated content.\n \"\"\"\n n_row = len(table.rows)\n n_col = len(table.columns)\n\n arrays = [[\"\" for _ in range(n_row)] for _ in range(n_col)]\n\n for i, row in enumerate(table.rows):\n for j, cell in enumerate(row.cells):\n arrays[j][i] = cell.text\n\n return arrays\n\n def load_data(\n self, file_path: Path, extra_info: Optional[dict] = None, **kwargs\n ) -> List[Document]:\n \"\"\"Load data using Docx reader\n\n Args:\n file_path (Path): Path to .docx file\n\n Returns:\n List[Document]: list of documents extracted from the HTML file\n \"\"\"\n import docx\n\n file_path = Path(file_path).resolve()\n\n doc = docx.Document(str(file_path))\n all_text = \"\\n\".join(\n [unicodedata.normalize(\"NFKC\", p.text) for p in doc.paragraphs]\n )\n pages = [all_text] # 1 page only\n\n tables = []\n for t in doc.tables:\n # return list of columns: list of string\n arrays = self._load_single_table(t)\n\n tables.append(pd.DataFrame({a[0]: a[1:] for a in arrays}))\n\n extra_info = extra_info or {}\n\n # create output Document with metadata from table\n documents = [\n Document(\n text=table.to_csv(\n index=False\n ).strip(), # strip_special_chars_markdown()\n metadata={\n \"table_origin\": table.to_csv(index=False),\n \"type\": \"table\",\n **extra_info,\n },\n metadata_template=\"\",\n metadata_seperator=\"\",\n )\n for table in tables # page_id\n ]\n\n # create Document from non-table text\n documents.extend(\n [\n Document(\n text=non_table_text.strip(),\n metadata={\"page_label\": 1, **extra_info},\n )\n for _, non_table_text in enumerate(pages)\n ]\n )\n\n return documents\n
Parses CSVs using the separator detection from Pandas read_csv function. If special parameters are required, use the pandas_config dict.
Args:
pandas_config (dict): Options for the `pandas.read_excel` function call.\n Refer to https://pandas.pydata.org/docs/reference/api/pandas.read_excel.html\n for more information. Set to empty dict by default,\n this means defaults will be used.\n
Source code in libs/kotaemon/kotaemon/loaders/excel_loader.py
class PandasExcelReader(BaseReader):\n r\"\"\"Pandas-based CSV parser.\n\n Parses CSVs using the separator detection from Pandas `read_csv` function.\n If special parameters are required, use the `pandas_config` dict.\n\n Args:\n\n pandas_config (dict): Options for the `pandas.read_excel` function call.\n Refer to https://pandas.pydata.org/docs/reference/api/pandas.read_excel.html\n for more information. Set to empty dict by default,\n this means defaults will be used.\n\n \"\"\"\n\n def __init__(\n self,\n *args: Any,\n pandas_config: Optional[dict] = None,\n row_joiner: str = \"\\n\",\n col_joiner: str = \" \",\n **kwargs: Any,\n ) -> None:\n \"\"\"Init params.\"\"\"\n super().__init__(*args, **kwargs)\n self._pandas_config = pandas_config or {}\n self._row_joiner = row_joiner if row_joiner else \"\\n\"\n self._col_joiner = col_joiner if col_joiner else \" \"\n\n def load_data(\n self,\n file: Path,\n include_sheetname: bool = False,\n sheet_name: Optional[Union[str, int, list]] = None,\n extra_info: Optional[dict] = None,\n **kwargs,\n ) -> List[Document]:\n \"\"\"Parse file and extract values from a specific column.\n\n Args:\n file (Path): The path to the Excel file to read.\n include_sheetname (bool): Whether to include the sheet name in the output.\n sheet_name (Union[str, int, None]): The specific sheet to read from,\n default is None which reads all sheets.\n\n Returns:\n List[Document]: A list of`Document objects containing the\n values from the specified column in the Excel file.\n \"\"\"\n import itertools\n\n try:\n import pandas as pd\n except ImportError:\n raise ImportError(\n \"install pandas using `pip3 install pandas` to use this loader\"\n )\n\n if sheet_name is not None:\n sheet_name = (\n [sheet_name] if not isinstance(sheet_name, list) else sheet_name\n )\n\n dfs = pd.read_excel(file, sheet_name=sheet_name, **self._pandas_config)\n sheet_names = dfs.keys()\n df_sheets = []\n\n for key in sheet_names:\n sheet = []\n if include_sheetname:\n sheet.append([key])\n dfs[key] = dfs[key].dropna(axis=0, how=\"all\")\n dfs[key] = dfs[key].dropna(axis=0, how=\"all\")\n dfs[key].fillna(\"\", inplace=True)\n sheet.extend(dfs[key].values.astype(str).tolist())\n df_sheets.append(sheet)\n\n text_list = list(\n itertools.chain.from_iterable(df_sheets)\n ) # flatten list of lists\n\n output = [\n Document(\n text=self._row_joiner.join(\n self._col_joiner.join(sublist) for sublist in text_list\n ),\n metadata=extra_info or {},\n )\n ]\n\n return output\n
Parse file and extract values from a specific column.
Parameters:
Name Type Description Default filePath
The path to the Excel file to read.
required include_sheetnamebool
Whether to include the sheet name in the output.
Falsesheet_nameUnion[str, int, None]
The specific sheet to read from, default is None which reads all sheets.
None
Returns:
Type Description List[Document]
List[Document]: A list of`Document objects containing the values from the specified column in the Excel file.
Source code in libs/kotaemon/kotaemon/loaders/excel_loader.py
def load_data(\n self,\n file: Path,\n include_sheetname: bool = False,\n sheet_name: Optional[Union[str, int, list]] = None,\n extra_info: Optional[dict] = None,\n **kwargs,\n) -> List[Document]:\n \"\"\"Parse file and extract values from a specific column.\n\n Args:\n file (Path): The path to the Excel file to read.\n include_sheetname (bool): Whether to include the sheet name in the output.\n sheet_name (Union[str, int, None]): The specific sheet to read from,\n default is None which reads all sheets.\n\n Returns:\n List[Document]: A list of`Document objects containing the\n values from the specified column in the Excel file.\n \"\"\"\n import itertools\n\n try:\n import pandas as pd\n except ImportError:\n raise ImportError(\n \"install pandas using `pip3 install pandas` to use this loader\"\n )\n\n if sheet_name is not None:\n sheet_name = (\n [sheet_name] if not isinstance(sheet_name, list) else sheet_name\n )\n\n dfs = pd.read_excel(file, sheet_name=sheet_name, **self._pandas_config)\n sheet_names = dfs.keys()\n df_sheets = []\n\n for key in sheet_names:\n sheet = []\n if include_sheetname:\n sheet.append([key])\n dfs[key] = dfs[key].dropna(axis=0, how=\"all\")\n dfs[key] = dfs[key].dropna(axis=0, how=\"all\")\n dfs[key].fillna(\"\", inplace=True)\n sheet.extend(dfs[key].values.astype(str).tolist())\n df_sheets.append(sheet)\n\n text_list = list(\n itertools.chain.from_iterable(df_sheets)\n ) # flatten list of lists\n\n output = [\n Document(\n text=self._row_joiner.join(\n self._col_joiner.join(sublist) for sublist in text_list\n ),\n metadata=extra_info or {},\n )\n ]\n\n return output\n
Parses CSVs using the separator detection from Pandas read_csv function. If special parameters are required, use the pandas_config dict.
Args:
pandas_config (dict): Options for the `pandas.read_excel` function call.\n Refer to https://pandas.pydata.org/docs/reference/api/pandas.read_excel.html\n for more information. Set to empty dict by default,\n this means defaults will be used.\n
Source code in libs/kotaemon/kotaemon/loaders/excel_loader.py
class ExcelReader(BaseReader):\n r\"\"\"Spreadsheet exporter respecting multiple worksheets\n\n Parses CSVs using the separator detection from Pandas `read_csv` function.\n If special parameters are required, use the `pandas_config` dict.\n\n Args:\n\n pandas_config (dict): Options for the `pandas.read_excel` function call.\n Refer to https://pandas.pydata.org/docs/reference/api/pandas.read_excel.html\n for more information. Set to empty dict by default,\n this means defaults will be used.\n\n \"\"\"\n\n def __init__(\n self,\n *args: Any,\n pandas_config: Optional[dict] = None,\n row_joiner: str = \"\\n\",\n col_joiner: str = \" \",\n **kwargs: Any,\n ) -> None:\n \"\"\"Init params.\"\"\"\n super().__init__(*args, **kwargs)\n self._pandas_config = pandas_config or {}\n self._row_joiner = row_joiner if row_joiner else \"\\n\"\n self._col_joiner = col_joiner if col_joiner else \" \"\n\n def load_data(\n self,\n file: Path,\n include_sheetname: bool = True,\n sheet_name: Optional[Union[str, int, list]] = None,\n extra_info: Optional[dict] = None,\n **kwargs,\n ) -> List[Document]:\n \"\"\"Parse file and extract values from a specific column.\n\n Args:\n file (Path): The path to the Excel file to read.\n include_sheetname (bool): Whether to include the sheet name in the output.\n sheet_name (Union[str, int, None]): The specific sheet to read from,\n default is None which reads all sheets.\n\n Returns:\n List[Document]: A list of`Document objects containing the\n values from the specified column in the Excel file.\n \"\"\"\n\n try:\n import pandas as pd\n except ImportError:\n raise ImportError(\n \"install pandas using `pip3 install pandas` to use this loader\"\n )\n\n if sheet_name is not None:\n sheet_name = (\n [sheet_name] if not isinstance(sheet_name, list) else sheet_name\n )\n\n # clean up input\n file = Path(file)\n extra_info = extra_info or {}\n\n dfs = pd.read_excel(file, sheet_name=sheet_name, **self._pandas_config)\n sheet_names = dfs.keys()\n output = []\n\n for idx, key in enumerate(sheet_names):\n dfs[key] = dfs[key].dropna(axis=0, how=\"all\")\n dfs[key] = dfs[key].dropna(axis=0, how=\"all\")\n dfs[key] = dfs[key].astype(\"object\")\n dfs[key].fillna(\"\", inplace=True)\n\n rows = dfs[key].values.astype(str).tolist()\n content = self._row_joiner.join(\n self._col_joiner.join(row).strip() for row in rows\n ).strip()\n if include_sheetname:\n content = f\"(Sheet {key} of file {file.name})\\n{content}\"\n metadata = {\"page_label\": idx + 1, \"sheet_name\": key, **extra_info}\n output.append(Document(text=content, metadata=metadata))\n\n return output\n
Parse file and extract values from a specific column.
Parameters:
Name Type Description Default filePath
The path to the Excel file to read.
required include_sheetnamebool
Whether to include the sheet name in the output.
Truesheet_nameUnion[str, int, None]
The specific sheet to read from, default is None which reads all sheets.
None
Returns:
Type Description List[Document]
List[Document]: A list of`Document objects containing the values from the specified column in the Excel file.
Source code in libs/kotaemon/kotaemon/loaders/excel_loader.py
def load_data(\n self,\n file: Path,\n include_sheetname: bool = True,\n sheet_name: Optional[Union[str, int, list]] = None,\n extra_info: Optional[dict] = None,\n **kwargs,\n) -> List[Document]:\n \"\"\"Parse file and extract values from a specific column.\n\n Args:\n file (Path): The path to the Excel file to read.\n include_sheetname (bool): Whether to include the sheet name in the output.\n sheet_name (Union[str, int, None]): The specific sheet to read from,\n default is None which reads all sheets.\n\n Returns:\n List[Document]: A list of`Document objects containing the\n values from the specified column in the Excel file.\n \"\"\"\n\n try:\n import pandas as pd\n except ImportError:\n raise ImportError(\n \"install pandas using `pip3 install pandas` to use this loader\"\n )\n\n if sheet_name is not None:\n sheet_name = (\n [sheet_name] if not isinstance(sheet_name, list) else sheet_name\n )\n\n # clean up input\n file = Path(file)\n extra_info = extra_info or {}\n\n dfs = pd.read_excel(file, sheet_name=sheet_name, **self._pandas_config)\n sheet_names = dfs.keys()\n output = []\n\n for idx, key in enumerate(sheet_names):\n dfs[key] = dfs[key].dropna(axis=0, how=\"all\")\n dfs[key] = dfs[key].dropna(axis=0, how=\"all\")\n dfs[key] = dfs[key].astype(\"object\")\n dfs[key].fillna(\"\", inplace=True)\n\n rows = dfs[key].values.astype(str).tolist()\n content = self._row_joiner.join(\n self._col_joiner.join(row).strip() for row in rows\n ).strip()\n if include_sheetname:\n content = f\"(Sheet {key} of file {file.name})\\n{content}\"\n metadata = {\"page_label\": idx + 1, \"sheet_name\": key, **extra_info}\n output.append(Document(text=content, metadata=metadata))\n\n return output\n
All of the texts will be split by page_break_pattern
Each page is extracted as a Document
The output is a list of Documents
Parameters:
Name Type Description Default page_break_patternstr
Pattern to split the HTML into pages
None Source code in libs/kotaemon/kotaemon/loaders/html_loader.py
class HtmlReader(BaseReader):\n \"\"\"Reader HTML usimg html2text\n\n Reader behavior:\n - HTML is read with html2text.\n - All of the texts will be split by `page_break_pattern`\n - Each page is extracted as a Document\n - The output is a list of Documents\n\n Args:\n page_break_pattern (str): Pattern to split the HTML into pages\n \"\"\"\n\n def __init__(self, page_break_pattern: Optional[str] = None, *args, **kwargs):\n try:\n import html2text # noqa\n except ImportError:\n raise ImportError(\n \"html2text is not installed. \"\n \"Please install it using `pip install html2text`\"\n )\n\n self._page_break_pattern: Optional[str] = page_break_pattern\n super().__init__()\n\n def load_data(\n self, file_path: Path | str, extra_info: Optional[dict] = None, **kwargs\n ) -> list[Document]:\n \"\"\"Load data using Html reader\n\n Args:\n file_path: path to HTML file\n extra_info: extra information passed to this reader during extracting data\n\n Returns:\n list[Document]: list of documents extracted from the HTML file\n \"\"\"\n import html2text\n\n file_path = Path(file_path).resolve()\n\n with file_path.open(\"r\") as f:\n html_text = \"\".join([line[:-1] for line in f.readlines()])\n\n # read HTML\n all_text = html2text.html2text(html_text)\n pages = (\n all_text.split(self._page_break_pattern)\n if self._page_break_pattern\n else [all_text]\n )\n\n extra_info = extra_info or {}\n\n # create Document from non-table text\n documents = [\n Document(\n text=page.strip(),\n metadata={\"page_label\": page_id + 1, **extra_info},\n )\n for page_id, page in enumerate(pages)\n ]\n\n return documents\n
extra information passed to this reader during extracting data
None
Returns:
Type Description list[Document]
list[Document]: list of documents extracted from the HTML file
Source code in libs/kotaemon/kotaemon/loaders/html_loader.py
def load_data(\n self, file_path: Path | str, extra_info: Optional[dict] = None, **kwargs\n) -> list[Document]:\n \"\"\"Load data using Html reader\n\n Args:\n file_path: path to HTML file\n extra_info: extra information passed to this reader during extracting data\n\n Returns:\n list[Document]: list of documents extracted from the HTML file\n \"\"\"\n import html2text\n\n file_path = Path(file_path).resolve()\n\n with file_path.open(\"r\") as f:\n html_text = \"\".join([line[:-1] for line in f.readlines()])\n\n # read HTML\n all_text = html2text.html2text(html_text)\n pages = (\n all_text.split(self._page_break_pattern)\n if self._page_break_pattern\n else [all_text]\n )\n\n extra_info = extra_info or {}\n\n # create Document from non-table text\n documents = [\n Document(\n text=page.strip(),\n metadata={\"page_label\": page_id + 1, **extra_info},\n )\n for page_id, page in enumerate(pages)\n ]\n\n return documents\n
Source code in libs/kotaemon/kotaemon/loaders/html_loader.py
class MhtmlReader(BaseReader):\n \"\"\"Parse `MHTML` files with `BeautifulSoup`.\"\"\"\n\n def __init__(\n self,\n cache_dir: Optional[str] = getattr(\n flowsettings, \"KH_MARKDOWN_OUTPUT_DIR\", None\n ),\n open_encoding: Optional[str] = None,\n bs_kwargs: Optional[dict] = None,\n get_text_separator: str = \"\",\n ) -> None:\n \"\"\"initialize with path, and optionally, file encoding to use, and any kwargs\n to pass to the BeautifulSoup object.\n\n Args:\n cache_dir: Path for markdwon format.\n file_path: Path to file to load.\n open_encoding: The encoding to use when opening the file.\n bs_kwargs: Any kwargs to pass to the BeautifulSoup object.\n get_text_separator: The separator to use when getting the text\n from the soup.\n \"\"\"\n try:\n import bs4 # noqa:F401\n except ImportError:\n raise ImportError(\n \"beautifulsoup4 package not found, please install it with \"\n \"`pip install beautifulsoup4`\"\n )\n\n self.cache_dir = cache_dir\n self.open_encoding = open_encoding\n if bs_kwargs is None:\n bs_kwargs = {\"features\": \"lxml\"}\n self.bs_kwargs = bs_kwargs\n self.get_text_separator = get_text_separator\n\n def load_data(\n self, file_path: Path | str, extra_info: Optional[dict] = None, **kwargs\n ) -> list[Document]:\n \"\"\"Load MHTML document into document objects.\"\"\"\n\n from bs4 import BeautifulSoup\n\n extra_info = extra_info or {}\n metadata: dict = extra_info\n page = []\n file_name = Path(file_path)\n with open(file_path, \"r\", encoding=self.open_encoding) as f:\n message = email.message_from_string(f.read())\n parts = message.get_payload()\n\n if not isinstance(parts, list):\n parts = [message]\n\n for part in parts:\n if part.get_content_type() == \"text/html\":\n html = part.get_payload(decode=True).decode()\n\n soup = BeautifulSoup(html, **self.bs_kwargs)\n text = soup.get_text(self.get_text_separator)\n\n if soup.title:\n title = str(soup.title.string)\n else:\n title = \"\"\n\n metadata = {\n \"source\": str(file_path),\n \"title\": title,\n **extra_info,\n }\n lines = [line for line in text.split(\"\\n\") if line.strip()]\n text = \"\\n\\n\".join(lines)\n if text:\n page.append(text)\n # save the page into markdown format\n print(self.cache_dir)\n if self.cache_dir is not None:\n print(Path(self.cache_dir) / f\"{file_name.stem}.md\")\n with open(Path(self.cache_dir) / f\"{file_name.stem}.md\", \"w\") as f:\n f.write(page[0])\n\n return [Document(text=\"\\n\\n\".join(page), metadata=metadata)]\n
Source code in libs/kotaemon/kotaemon/loaders/html_loader.py
def load_data(\n self, file_path: Path | str, extra_info: Optional[dict] = None, **kwargs\n) -> list[Document]:\n \"\"\"Load MHTML document into document objects.\"\"\"\n\n from bs4 import BeautifulSoup\n\n extra_info = extra_info or {}\n metadata: dict = extra_info\n page = []\n file_name = Path(file_path)\n with open(file_path, \"r\", encoding=self.open_encoding) as f:\n message = email.message_from_string(f.read())\n parts = message.get_payload()\n\n if not isinstance(parts, list):\n parts = [message]\n\n for part in parts:\n if part.get_content_type() == \"text/html\":\n html = part.get_payload(decode=True).decode()\n\n soup = BeautifulSoup(html, **self.bs_kwargs)\n text = soup.get_text(self.get_text_separator)\n\n if soup.title:\n title = str(soup.title.string)\n else:\n title = \"\"\n\n metadata = {\n \"source\": str(file_path),\n \"title\": title,\n **extra_info,\n }\n lines = [line for line in text.split(\"\\n\") if line.strip()]\n text = \"\\n\\n\".join(lines)\n if text:\n page.append(text)\n # save the page into markdown format\n print(self.cache_dir)\n if self.cache_dir is not None:\n print(Path(self.cache_dir) / f\"{file_name.stem}.md\")\n with open(Path(self.cache_dir) / f\"{file_name.stem}.md\", \"w\") as f:\n f.write(page[0])\n\n return [Document(text=\"\\n\\n\".join(page), metadata=metadata)]\n
Source code in libs/kotaemon/kotaemon/loaders/mathpix_loader.py
def wait_for_processing(self, pdf_id: str) -> None:\n \"\"\"Wait for processing to complete.\n\n Args:\n pdf_id: a PDF id.\n\n Returns: None\n \"\"\"\n url = self.url + \"/\" + pdf_id\n for _ in range(0, self.max_wait_time_seconds, 5):\n response = requests.get(url, headers=self._mathpix_headers)\n response_data = response.json()\n status = response_data.get(\"status\", None)\n\n if status == \"completed\":\n return\n elif status == \"error\":\n raise ValueError(\"Unable to retrieve PDF from Mathpix\")\n else:\n print(response_data)\n print(url)\n time.sleep(5)\n raise TimeoutError\n
Name Type Description Default endpointOptional[str]
URL to FullOCR endpoint. If not provided, will look for environment variable OCR_READER_ENDPOINT or use the default kotaemon.loaders.ocr_loader.DEFAULT_OCR_ENDPOINT (http://127.0.0.1:8000/v2/ai/infer/)
Noneuse_ocr
whether to use OCR to read text (e.g: from images, tables) in the PDF If False, only the table and text within table cells will be extracted.
True Source code in libs/kotaemon/kotaemon/loaders/ocr_loader.py
class OCRReader(BaseReader):\n \"\"\"Read PDF using OCR, with high focus on table extraction\n\n Example:\n ```python\n >> from kotaemon.loaders import OCRReader\n >> reader = OCRReader()\n >> documents = reader.load_data(\"path/to/pdf\")\n ```\n\n Args:\n endpoint: URL to FullOCR endpoint. If not provided, will look for\n environment variable `OCR_READER_ENDPOINT` or use the default\n `kotaemon.loaders.ocr_loader.DEFAULT_OCR_ENDPOINT`\n (http://127.0.0.1:8000/v2/ai/infer/)\n use_ocr: whether to use OCR to read text (e.g: from images, tables) in the PDF\n If False, only the table and text within table cells will be extracted.\n \"\"\"\n\n def __init__(self, endpoint: Optional[str] = None, use_ocr=True):\n \"\"\"Init the OCR reader with OCR endpoint (FullOCR pipeline)\"\"\"\n super().__init__()\n self.ocr_endpoint = endpoint or os.getenv(\n \"OCR_READER_ENDPOINT\", DEFAULT_OCR_ENDPOINT\n )\n self.use_ocr = use_ocr\n\n def load_data(\n self, file_path: Path, extra_info: Optional[dict] = None, **kwargs\n ) -> List[Document]:\n \"\"\"Load data using OCR reader\n\n Args:\n file_path (Path): Path to PDF file\n debug_path (Path): Path to store debug image output\n artifact_path (Path): Path to OCR endpoints artifacts directory\n\n Returns:\n List[Document]: list of documents extracted from the PDF file\n \"\"\"\n file_path = Path(file_path).resolve()\n\n # call the API from FullOCR endpoint\n if \"response_content\" in kwargs:\n # overriding response content if specified\n ocr_results = kwargs[\"response_content\"]\n else:\n # call original API\n resp = tenacious_api_post(\n url=self.ocr_endpoint, file_path=file_path, table_only=not self.use_ocr\n )\n ocr_results = resp.json()[\"result\"]\n\n debug_path = kwargs.pop(\"debug_path\", None)\n artifact_path = kwargs.pop(\"artifact_path\", None)\n\n # read PDF through normal reader (unstructured)\n pdf_page_items = read_pdf_unstructured(file_path)\n # merge PDF text output with OCR output\n tables, texts = parse_ocr_output(\n ocr_results,\n pdf_page_items,\n debug_path=debug_path,\n artifact_path=artifact_path,\n )\n extra_info = extra_info or {}\n\n # create output Document with metadata from table\n documents = [\n Document(\n text=strip_special_chars_markdown(table_text),\n metadata={\n \"table_origin\": table_text,\n \"type\": \"table\",\n \"page_label\": page_id + 1,\n **extra_info,\n },\n metadata_template=\"\",\n metadata_seperator=\"\",\n )\n for page_id, table_text in tables\n ]\n # create Document from non-table text\n documents.extend(\n [\n Document(\n text=non_table_text,\n metadata={\"page_label\": page_id + 1, **extra_info},\n )\n for page_id, non_table_text in texts\n ]\n )\n\n return documents\n
Name Type Description Default endpointOptional[str]
URL to FullOCR endpoint. If not provided, will look for environment variable OCR_READER_ENDPOINT or use the default knowledgehub.loaders.ocr_loader.DEFAULT_OCR_ENDPOINT (http://127.0.0.1:8000/v2/ai/infer/)
Noneuse_ocr
whether to use OCR to read text (e.g: from images, tables) in the PDF If False, only the table and text within table cells will be extracted.
required Source code in libs/kotaemon/kotaemon/loaders/ocr_loader.py
class ImageReader(BaseReader):\n \"\"\"Read PDF using OCR, with high focus on table extraction\n\n Example:\n ```python\n >> from knowledgehub.loaders import OCRReader\n >> reader = OCRReader()\n >> documents = reader.load_data(\"path/to/pdf\")\n ```\n\n Args:\n endpoint: URL to FullOCR endpoint. If not provided, will look for\n environment variable `OCR_READER_ENDPOINT` or use the default\n `knowledgehub.loaders.ocr_loader.DEFAULT_OCR_ENDPOINT`\n (http://127.0.0.1:8000/v2/ai/infer/)\n use_ocr: whether to use OCR to read text (e.g: from images, tables) in the PDF\n If False, only the table and text within table cells will be extracted.\n \"\"\"\n\n def __init__(self, endpoint: Optional[str] = None):\n \"\"\"Init the OCR reader with OCR endpoint (FullOCR pipeline)\"\"\"\n super().__init__()\n self.ocr_endpoint = endpoint or os.getenv(\n \"OCR_READER_ENDPOINT\", DEFAULT_OCR_ENDPOINT\n )\n\n def load_data(\n self, file_path: Path, extra_info: Optional[dict] = None, **kwargs\n ) -> List[Document]:\n \"\"\"Load data using OCR reader\n\n Args:\n file_path (Path): Path to PDF file\n debug_path (Path): Path to store debug image output\n artifact_path (Path): Path to OCR endpoints artifacts directory\n\n Returns:\n List[Document]: list of documents extracted from the PDF file\n \"\"\"\n file_path = Path(file_path).resolve()\n\n # call the API from FullOCR endpoint\n if \"response_content\" in kwargs:\n # overriding response content if specified\n ocr_results = kwargs[\"response_content\"]\n else:\n # call original API\n resp = tenacious_api_post(\n url=self.ocr_endpoint, file_path=file_path, table_only=False\n )\n ocr_results = resp.json()[\"result\"]\n\n extra_info = extra_info or {}\n result = []\n for ocr_result in ocr_results:\n result.append(\n Document(\n content=ocr_result[\"csv_string\"],\n metadata=extra_info,\n )\n )\n\n return result\n
List[Document]: list of documents extracted from the PDF file
Source code in libs/kotaemon/kotaemon/loaders/ocr_loader.py
def load_data(\n self, file_path: Path, extra_info: Optional[dict] = None, **kwargs\n) -> List[Document]:\n \"\"\"Load data using OCR reader\n\n Args:\n file_path (Path): Path to PDF file\n debug_path (Path): Path to store debug image output\n artifact_path (Path): Path to OCR endpoints artifacts directory\n\n Returns:\n List[Document]: list of documents extracted from the PDF file\n \"\"\"\n file_path = Path(file_path).resolve()\n\n # call the API from FullOCR endpoint\n if \"response_content\" in kwargs:\n # overriding response content if specified\n ocr_results = kwargs[\"response_content\"]\n else:\n # call original API\n resp = tenacious_api_post(\n url=self.ocr_endpoint, file_path=file_path, table_only=False\n )\n ocr_results = resp.json()[\"result\"]\n\n extra_info = extra_info or {}\n result = []\n for ocr_result in ocr_results:\n result.append(\n Document(\n content=ocr_result[\"csv_string\"],\n metadata=extra_info,\n )\n )\n\n return result\n
General unstructured text reader for a variety of files.
Source code in libs/kotaemon/kotaemon/loaders/unstructured_loader.py
class UnstructuredReader(BaseReader):\n \"\"\"General unstructured text reader for a variety of files.\"\"\"\n\n def __init__(self, *args: Any, **kwargs: Any) -> None:\n \"\"\"Init params.\"\"\"\n super().__init__(*args) # not passing kwargs to parent bc it cannot accept it\n\n self.api = False # we default to local\n if \"url\" in kwargs:\n self.server_url = str(kwargs[\"url\"])\n self.api = True # is url was set, switch to api\n else:\n self.server_url = \"http://localhost:8000\"\n\n if \"api\" in kwargs:\n self.api = kwargs[\"api\"]\n\n self.api_key = \"\"\n if \"api_key\" in kwargs:\n self.api_key = kwargs[\"api_key\"]\n\n \"\"\" Loads data using Unstructured.io\n\n Depending on the construction if url is set or api = True\n it'll parse file using API call, else parse it locally\n additional_metadata is extended by the returned metadata if\n split_documents is True\n\n Returns list of documents\n \"\"\"\n\n def load_data(\n self,\n file: Path,\n extra_info: Optional[Dict] = None,\n split_documents: Optional[bool] = False,\n **kwargs,\n ) -> List[Document]:\n \"\"\"If api is set, parse through api\"\"\"\n file_path_str = str(file)\n if self.api:\n from unstructured.partition.api import partition_via_api\n\n elements = partition_via_api(\n filename=file_path_str,\n api_key=self.api_key,\n api_url=self.server_url + \"/general/v0/general\",\n )\n else:\n \"\"\"Parse file locally\"\"\"\n from unstructured.partition.auto import partition\n\n elements = partition(filename=file_path_str)\n\n \"\"\" Process elements \"\"\"\n docs = []\n file_name = Path(file).name\n file_path = str(Path(file).resolve())\n if split_documents:\n for node in elements:\n metadata = {\"file_name\": file_name, \"file_path\": file_path}\n if hasattr(node, \"metadata\"):\n \"\"\"Load metadata fields\"\"\"\n for field, val in vars(node.metadata).items():\n if field == \"_known_field_names\":\n continue\n # removing coordinates because it does not serialize\n # and dont want to bother with it\n if field == \"coordinates\":\n continue\n # removing bc it might cause interference\n if field == \"parent_id\":\n continue\n metadata[field] = val\n\n if extra_info is not None:\n metadata.update(extra_info)\n\n metadata[\"file_name\"] = file_name\n docs.append(Document(text=node.text, metadata=metadata))\n\n else:\n text_chunks = [\" \".join(str(el).split()) for el in elements]\n metadata = {\"file_name\": file_name, \"file_path\": file_path}\n\n if extra_info is not None:\n metadata.update(extra_info)\n\n # Create a single document by joining all the texts\n docs.append(Document(text=\"\\n\\n\".join(text_chunks), metadata=metadata))\n\n return docs\n
Source code in libs/kotaemon/kotaemon/loaders/unstructured_loader.py
def load_data(\n self,\n file: Path,\n extra_info: Optional[Dict] = None,\n split_documents: Optional[bool] = False,\n **kwargs,\n) -> List[Document]:\n \"\"\"If api is set, parse through api\"\"\"\n file_path_str = str(file)\n if self.api:\n from unstructured.partition.api import partition_via_api\n\n elements = partition_via_api(\n filename=file_path_str,\n api_key=self.api_key,\n api_url=self.server_url + \"/general/v0/general\",\n )\n else:\n \"\"\"Parse file locally\"\"\"\n from unstructured.partition.auto import partition\n\n elements = partition(filename=file_path_str)\n\n \"\"\" Process elements \"\"\"\n docs = []\n file_name = Path(file).name\n file_path = str(Path(file).resolve())\n if split_documents:\n for node in elements:\n metadata = {\"file_name\": file_name, \"file_path\": file_path}\n if hasattr(node, \"metadata\"):\n \"\"\"Load metadata fields\"\"\"\n for field, val in vars(node.metadata).items():\n if field == \"_known_field_names\":\n continue\n # removing coordinates because it does not serialize\n # and dont want to bother with it\n if field == \"coordinates\":\n continue\n # removing bc it might cause interference\n if field == \"parent_id\":\n continue\n metadata[field] = val\n\n if extra_info is not None:\n metadata.update(extra_info)\n\n metadata[\"file_name\"] = file_name\n docs.append(Document(text=node.text, metadata=metadata))\n\n else:\n text_chunks = [\" \".join(str(el).split()) for el in elements]\n metadata = {\"file_name\": file_name, \"file_path\": file_path}\n\n if extra_info is not None:\n metadata.update(extra_info)\n\n # Create a single document by joining all the texts\n docs.append(Document(text=\"\\n\\n\".join(text_chunks), metadata=metadata))\n\n return docs\n
Main function to call the adobe service, and unzip the results. Args: file_path (str): path to the pdf file output_path (str): path to store the results
Returns:
Name Type Description output_pathstr
path to the results
Source code in libs/kotaemon/kotaemon/loaders/utils/adobe.py
def request_adobe_service(file_path: str, output_path: str = \"\") -> str:\n \"\"\"Main function to call the adobe service, and unzip the results.\n Args:\n file_path (str): path to the pdf file\n output_path (str): path to store the results\n\n Returns:\n output_path (str): path to the results\n\n \"\"\"\n try:\n from adobe.pdfservices.operation.auth.credentials import Credentials\n from adobe.pdfservices.operation.exception.exceptions import (\n SdkException,\n ServiceApiException,\n ServiceUsageException,\n )\n from adobe.pdfservices.operation.execution_context import ExecutionContext\n from adobe.pdfservices.operation.io.file_ref import FileRef\n from adobe.pdfservices.operation.pdfops.extract_pdf_operation import (\n ExtractPDFOperation,\n )\n from adobe.pdfservices.operation.pdfops.options.extractpdf.extract_element_type import ( # noqa: E501\n ExtractElementType,\n )\n from adobe.pdfservices.operation.pdfops.options.extractpdf.extract_pdf_options import ( # noqa: E501\n ExtractPDFOptions,\n )\n from adobe.pdfservices.operation.pdfops.options.extractpdf.extract_renditions_element_type import ( # noqa: E501\n ExtractRenditionsElementType,\n )\n except ImportError:\n raise ImportError(\n \"pdfservices-sdk is not installed. \"\n \"Please install it by running `pip install pdfservices-sdk\"\n \"@git+https://github.com/niallcm/pdfservices-python-sdk.git\"\n \"@bump-and-unfreeze-requirements`\"\n )\n\n if not output_path:\n output_path = tempfile.mkdtemp()\n\n try:\n # Initial setup, create credentials instance.\n credentials = (\n Credentials.service_principal_credentials_builder()\n .with_client_id(config(\"PDF_SERVICES_CLIENT_ID\", default=\"\"))\n .with_client_secret(config(\"PDF_SERVICES_CLIENT_SECRET\", default=\"\"))\n .build()\n )\n\n # Create an ExecutionContext using credentials\n # and create a new operation instance.\n execution_context = ExecutionContext.create(credentials)\n extract_pdf_operation = ExtractPDFOperation.create_new()\n\n # Set operation input from a source file.\n source = FileRef.create_from_local_file(file_path)\n extract_pdf_operation.set_input(source)\n\n # Build ExtractPDF options and set them into the operation\n extract_pdf_options: ExtractPDFOptions = (\n ExtractPDFOptions.builder()\n .with_elements_to_extract(\n [ExtractElementType.TEXT, ExtractElementType.TABLES]\n )\n .with_elements_to_extract_renditions(\n [\n ExtractRenditionsElementType.TABLES,\n ExtractRenditionsElementType.FIGURES,\n ]\n )\n .build()\n )\n extract_pdf_operation.set_options(extract_pdf_options)\n\n # Execute the operation.\n result: FileRef = extract_pdf_operation.execute(execution_context)\n\n # Save the result to the specified location.\n zip_file_path = os.path.join(\n output_path, \"ExtractTextTableWithFigureTableRendition.zip\"\n )\n result.save_as(zip_file_path)\n # Open the ZIP file\n with zipfile.ZipFile(zip_file_path, \"r\") as zip_ref:\n # Extract all contents to the destination folder\n zip_ref.extractall(output_path)\n except (ServiceApiException, ServiceUsageException, SdkException):\n logging.exception(\"Exception encountered while executing operation\")\n\n return output_path\n
Convert table from python list representation to markdown format. The input list consists of rows of tables, the first row is the header.
Parameters:
Name Type Description Default table_as_listList[str]
list of table rows Example: [[\"Name\", \"Age\", \"Height\"], [\"Jake\", 20, 5'10], [\"Mary\", 21, 5'7]]
required
Returns: markdown representation of the table
Source code in libs/kotaemon/kotaemon/loaders/utils/adobe.py
def make_markdown_table(table_as_list: List[str]) -> str:\n \"\"\"\n Convert table from python list representation to markdown format.\n The input list consists of rows of tables, the first row is the header.\n\n Args:\n table_as_list: list of table rows\n Example: [[\"Name\", \"Age\", \"Height\"],\n [\"Jake\", 20, 5'10],\n [\"Mary\", 21, 5'7]]\n Returns:\n markdown representation of the table\n \"\"\"\n markdown = \"\\n\" + str(\"| \")\n\n for e in table_as_list[0]:\n to_add = \" \" + str(e) + str(\" |\")\n markdown += to_add\n markdown += \"\\n\"\n\n markdown += \"| \"\n for i in range(len(table_as_list[0])):\n markdown += str(\"--- | \")\n markdown += \"\\n\"\n\n for entry in table_as_list[1:]:\n markdown += str(\"| \")\n for e in entry:\n to_add = str(e) + str(\" | \")\n markdown += to_add\n markdown += \"\\n\"\n\n return markdown + \"\\n\"\n
Source code in libs/kotaemon/kotaemon/loaders/utils/adobe.py
def load_excel(input_path: Union[str | Path]) -> str:\n \"\"\"Load excel file and convert to markdown\"\"\"\n\n df = pd.read_excel(input_path).fillna(\"\")\n # Convert dataframe to a list of rows\n row_list = [df.columns.values.tolist()] + df.values.tolist()\n\n for item_id, item in enumerate(row_list[0]):\n if \"Unnamed\" in item:\n row_list[0][item_id] = \"\"\n\n for row in row_list:\n for item_id, item in enumerate(row):\n row[item_id] = str(item).replace(\"_x000D_\", \" \").replace(\"\\n\", \" \").strip()\n\n markdown_str = make_markdown_table(row_list)\n return markdown_str\n
Read the table stored in an excel file given the file path
Source code in libs/kotaemon/kotaemon/loaders/utils/adobe.py
def parse_table_paths(file_paths: List[Path]) -> str:\n \"\"\"Read the table stored in an excel file given the file path\"\"\"\n\n content = \"\"\n for path in file_paths:\n if path.suffix == \".xlsx\":\n content = load_excel(path)\n break\n return content\n
Read and convert an image to base64 given the image path
Source code in libs/kotaemon/kotaemon/loaders/utils/adobe.py
def parse_figure_paths(file_paths: List[Path]) -> Union[bytes, str]:\n \"\"\"Read and convert an image to base64 given the image path\"\"\"\n\n content = \"\"\n for path in file_paths:\n if path.suffix == \".png\":\n base64_image = encode_image_base64(path)\n content = f\"data:image/png;base64,{base64_image}\" # type: ignore\n break\n return content\n
Source code in libs/kotaemon/kotaemon/loaders/utils/adobe.py
def generate_single_figure_caption(vlm_endpoint: str, figure: str) -> str:\n \"\"\"Summarize a single figure using GPT-4V\"\"\"\n if figure:\n output = generate_gpt4v(\n endpoint=vlm_endpoint,\n prompt=\"Provide a short 2 sentence summary of this image?\",\n images=figure,\n )\n if \"sorry\" in output.lower():\n output = \"\"\n else:\n output = \"\"\n return output\n
Summarize several figures using GPT-4V. Args: vlm_endpoint (str): endpoint to the vision language model service figures (List): list of base64 images max_figures_to_process (int): the maximum number of figures will be summarized, the rest are ignored.
Returns:
Name Type Description resultsList[str]
list of all figure captions and empty strings for
List
ignored figures.
Source code in libs/kotaemon/kotaemon/loaders/utils/adobe.py
def generate_figure_captions(\n vlm_endpoint: str, figures: List, max_figures_to_process: int\n) -> List:\n \"\"\"Summarize several figures using GPT-4V.\n Args:\n vlm_endpoint (str): endpoint to the vision language model service\n figures (List): list of base64 images\n max_figures_to_process (int): the maximum number of figures will be summarized,\n the rest are ignored.\n\n Returns:\n results (List[str]): list of all figure captions and empty strings for\n ignored figures.\n \"\"\"\n to_gen_figures = figures[:max_figures_to_process]\n other_figures = figures[max_figures_to_process:]\n\n with ThreadPoolExecutor() as executor:\n futures = [\n executor.submit(\n lambda: generate_single_figure_caption(vlm_endpoint, figure)\n )\n for figure in to_gen_figures\n ]\n\n results = [future.result() for future in futures]\n return results + [\"\"] * len(other_figures)\n
Source code in libs/kotaemon/kotaemon/loaders/utils/box.py
def points_to_bbox(points: List[Tuple[int, int]]):\n \"\"\"Convert list of points to bounding box\"\"\"\n all_x = [p[0] for p in points]\n all_y = [p[1] for p in points]\n return [min(all_x), min(all_y), max(all_x), max(all_y)]\n
Source code in libs/kotaemon/kotaemon/loaders/utils/box.py
def union_points(points: List[Tuple[int, int]]):\n \"\"\"Return union bounding box of list of points\"\"\"\n all_x = [p[0] for p in points]\n all_y = [p[1] for p in points]\n bbox = (min(all_x), min(all_y), max(all_x), max(all_y))\n return bbox\n
Sort cell list to create the right reading order using their locations
Parameters:
Name Type Description Default linesList[dict]
list of cells to sort
required
Returns:
Type Description
a list of cell lists in the right reading order that contain
no key or start with a key and contain no other key
Source code in libs/kotaemon/kotaemon/loaders/utils/box.py
def sort_funsd_reading_order(lines: List[dict], box_key_name: str = \"box\"):\n \"\"\"Sort cell list to create the right reading order using their locations\n\n Args:\n lines: list of cells to sort\n\n Returns:\n a list of cell lists in the right reading order that contain\n no key or start with a key and contain no other key\n \"\"\"\n sorted_list = []\n\n if len(lines) == 0:\n return lines\n\n while len(lines) > 1:\n topleft_line = lines[0]\n for line in lines[1:]:\n topleft_line_pos = topleft_line[box_key_name]\n topleft_line_center_y = (topleft_line_pos[1] + topleft_line_pos[3]) / 2\n x1, y1, x2, y2 = line[box_key_name]\n box_center_x = (x1 + x2) / 2\n box_center_y = (y1 + y2) / 2\n cell_h = y2 - y1\n if box_center_y <= topleft_line_center_y - cell_h / 2:\n topleft_line = line\n continue\n if (\n box_center_x < topleft_line_pos[2]\n and box_center_y < topleft_line_pos[3]\n ):\n topleft_line = line\n continue\n sorted_list.append(topleft_line)\n lines.remove(topleft_line)\n\n sorted_list.append(lines[0])\n\n return sorted_list\n
Merge PDF and OCR text using IOU overlapping location Args: ocr_list: List of OCR items {\"text\", \"box\", \"location\"} pdf_text_list: List of PDF items {\"text\", \"box\", \"location\"}
Returns:
Type Description
Combined list of PDF text and non-overlap OCR text
Source code in libs/kotaemon/kotaemon/loaders/utils/pdf_ocr.py
def merge_ocr_and_pdf_texts(\n ocr_list: List[dict], pdf_text_list: List[dict], debug_info=None\n):\n \"\"\"Merge PDF and OCR text using IOU overlapping location\n Args:\n ocr_list: List of OCR items {\"text\", \"box\", \"location\"}\n pdf_text_list: List of PDF items {\"text\", \"box\", \"location\"}\n\n Returns:\n Combined list of PDF text and non-overlap OCR text\n \"\"\"\n not_matched_ocr = []\n\n # check for debug info\n if debug_info is not None:\n cv2, debug_im = debug_info\n\n for ocr_item in ocr_list:\n matched = False\n for pdf_item in pdf_text_list:\n if (\n get_rect_iou(ocr_item[\"location\"], pdf_item[\"location\"], iou_type=1)\n > IOU_THRES\n ):\n matched = True\n break\n\n color = (255, 0, 0)\n if not matched:\n ocr_item[\"matched\"] = False\n not_matched_ocr.append(ocr_item)\n color = (0, 255, 255)\n\n if debug_info is not None:\n cv2.rectangle(\n debug_im,\n ocr_item[\"location\"][0],\n ocr_item[\"location\"][2],\n color=color,\n thickness=1,\n )\n\n if debug_info is not None:\n for pdf_item in pdf_text_list:\n cv2.rectangle(\n debug_im,\n pdf_item[\"location\"][0],\n pdf_item[\"location\"][2],\n color=(0, 255, 0),\n thickness=2,\n )\n\n return pdf_text_list + not_matched_ocr\n
Merge table items with OCR text using IOU overlapping location Args: table_list: List of table items \"type\": (\"table\", \"cell\", \"text\"), \"text\", \"box\", \"location\"} ocr_list: List of OCR items {\"text\", \"box\", \"location\"} pdf_list: List of PDF items {\"text\", \"box\", \"location\"}
Returns:
Name Type Description all_table_cells
List of tables, each of table is represented by list of cells with combined text from OCR
not_matched_items
List of PDF text which is not overlapped by table region
Source code in libs/kotaemon/kotaemon/loaders/utils/pdf_ocr.py
def merge_table_cell_and_ocr(\n table_list: List[dict], ocr_list: List[dict], pdf_list: List[dict], debug_info=None\n):\n \"\"\"Merge table items with OCR text using IOU overlapping location\n Args:\n table_list: List of table items\n \"type\": (\"table\", \"cell\", \"text\"), \"text\", \"box\", \"location\"}\n ocr_list: List of OCR items {\"text\", \"box\", \"location\"}\n pdf_list: List of PDF items {\"text\", \"box\", \"location\"}\n\n Returns:\n all_table_cells: List of tables, each of table is represented\n by list of cells with combined text from OCR\n not_matched_items: List of PDF text which is not overlapped by table region\n \"\"\"\n # check for debug info\n if debug_info is not None:\n cv2, debug_im = debug_info\n\n cell_list = [item for item in table_list if item[\"type\"] == \"cell\"]\n table_list = [item for item in table_list if item[\"type\"] == \"table\"]\n\n # sort table by area\n table_list = sorted(table_list, key=lambda item: box_area(item[\"bbox\"]))\n\n all_tables = []\n matched_pdf_ids = []\n matched_cell_ids = []\n\n for table in table_list:\n if debug_info is not None:\n cv2.rectangle(\n debug_im,\n table[\"location\"][0],\n table[\"location\"][2],\n color=[0, 0, 255],\n thickness=5,\n )\n\n cur_table_cells = []\n for cell_id, cell in enumerate(cell_list):\n if cell_id in matched_cell_ids:\n continue\n\n if get_rect_iou(\n table[\"location\"], cell[\"location\"], iou_type=1\n ) > IOU_THRES and box_area(table[\"bbox\"]) > box_area(cell[\"bbox\"]):\n color = [128, 0, 128]\n # cell matched to table\n for item_list, item_type in [(pdf_list, \"pdf\"), (ocr_list, \"ocr\")]:\n cell[\"ocr\"] = []\n for item_id, item in enumerate(item_list):\n if item_type == \"pdf\" and item_id in matched_pdf_ids:\n continue\n if (\n get_rect_iou(item[\"location\"], cell[\"location\"], iou_type=1)\n > IOU_THRES\n ):\n cell[\"ocr\"].append(item)\n if item_type == \"pdf\":\n matched_pdf_ids.append(item_id)\n\n if len(cell[\"ocr\"]) > 0:\n # check if union of matched ocr does\n # not extend over cell boundary,\n # if True, continue to use OCR_list to match\n all_box_points_in_cell = []\n for item in cell[\"ocr\"]:\n all_box_points_in_cell.extend(item[\"location\"])\n union_box = union_points(all_box_points_in_cell)\n cell_okay = (\n box_h(union_box) <= box_h(cell[\"bbox\"]) * PADDING_THRES\n and box_w(union_box) <= box_w(cell[\"bbox\"]) * PADDING_THRES\n )\n else:\n cell_okay = False\n\n if cell_okay:\n if item_type == \"pdf\":\n color = [255, 0, 255]\n break\n\n if debug_info is not None:\n cv2.rectangle(\n debug_im,\n cell[\"location\"][0],\n cell[\"location\"][2],\n color=color,\n thickness=3,\n )\n\n matched_cell_ids.append(cell_id)\n cur_table_cells.append(cell)\n\n all_tables.append(cur_table_cells)\n\n not_matched_items = [\n item for _id, item in enumerate(pdf_list) if _id not in matched_pdf_ids\n ]\n if debug_info is not None:\n for item in not_matched_items:\n cv2.rectangle(\n debug_im,\n item[\"location\"][0],\n item[\"location\"][2],\n color=[128, 128, 128],\n thickness=3,\n )\n\n return all_tables, not_matched_items\n
Main function to combine OCR output and PDF text to form list of table / non-table regions Args: ocr_page_items: List of OCR items by page pdf_page_items: Dict of PDF texts (page number as key) debug_path: If specified, use OpenCV to plot debug image and save to debug_path
Source code in libs/kotaemon/kotaemon/loaders/utils/pdf_ocr.py
def parse_ocr_output(\n ocr_page_items: List[dict],\n pdf_page_items: Dict[int, List[dict]],\n artifact_path: Optional[str] = None,\n debug_path: Optional[str] = None,\n):\n \"\"\"Main function to combine OCR output and PDF text to\n form list of table / non-table regions\n Args:\n ocr_page_items: List of OCR items by page\n pdf_page_items: Dict of PDF texts (page number as key)\n debug_path: If specified, use OpenCV to plot debug image and save to debug_path\n \"\"\"\n all_tables = []\n all_texts = []\n\n for page_id, page in enumerate(ocr_page_items):\n ocr_list = page[\"json\"][\"ocr\"]\n table_list = page[\"json\"][\"table\"]\n page_shape = page[\"image_shape\"]\n pdf_item_list = pdf_page_items[page_id]\n\n # create bbox additional information\n for item in ocr_list:\n item[\"box\"] = points_to_bbox(item[\"location\"])\n\n # re-scale pdf items according to new image size\n for item in pdf_item_list:\n scale_factor = page_shape[0] / item[\"page_shape\"][0]\n item[\"box\"] = scale_box(item[\"box\"], scale_factor=scale_factor)\n item[\"location\"] = scale_points(item[\"location\"], scale_factor=scale_factor)\n\n # if using debug mode, openCV must be installed\n if debug_path and artifact_path is not None:\n try:\n import cv2\n except ImportError:\n raise ImportError(\n \"Please install openCV first to use OCRReader debug mode\"\n )\n image_path = Path(artifact_path) / page[\"image\"]\n image = cv2.imread(str(image_path))\n debug_info = (cv2, image)\n else:\n debug_info = None\n\n new_pdf_list = merge_ocr_and_pdf_texts(\n ocr_list, pdf_item_list, debug_info=debug_info\n )\n\n # sort by reading order\n ocr_list = sort_funsd_reading_order(ocr_list)\n new_pdf_list = sort_funsd_reading_order(new_pdf_list)\n\n all_table_cells, non_table_text_list = merge_table_cell_and_ocr(\n table_list, ocr_list, new_pdf_list, debug_info=debug_info\n )\n\n table_texts = [table_cells_to_markdown(cells) for cells in all_table_cells]\n all_tables.extend([(page_id, text) for text in table_texts])\n all_texts.append(\n (page_id, \" \".join(item[\"text\"] for item in non_table_text_list))\n )\n\n # export debug image to debug_path\n if debug_path:\n cv2.imwrite(str(Path(debug_path) / \"page_{}.png\".format(page_id)), image)\n\n return all_tables, all_texts\n
Check if 2 columns A and B has non-empty content in the same row (to be used with merge_cols)
Parameters:
Name Type Description Default col_aList[str]
column A (list of str)
required col_bList[str]
column B (list of str)
required thresfloat
percentage of overlapping allowed
0.15
Returns: if number of overlapping greater than threshold
Source code in libs/kotaemon/kotaemon/loaders/utils/table.py
def check_col_conflicts(\n col_a: List[str], col_b: List[str], thres: float = 0.15\n) -> bool:\n \"\"\"Check if 2 columns A and B has non-empty content in the same row\n (to be used with merge_cols)\n\n Args:\n col_a: column A (list of str)\n col_b: column B (list of str)\n thres: percentage of overlapping allowed\n Returns:\n if number of overlapping greater than threshold\n \"\"\"\n num_rows = len([cell for cell in col_a if cell])\n assert len(col_a) == len(col_b)\n conflict_count = 0\n for cell_a, cell_b in zip(col_a, col_b):\n if cell_a and cell_b:\n conflict_count += 1\n return conflict_count > num_rows * thres\n
Merge column A and B if they do not have conflict rows
Parameters:
Name Type Description Default col_aList[str]
column A (list of str)
required col_bList[str]
column B (list of str)
required
Returns: merged column
Source code in libs/kotaemon/kotaemon/loaders/utils/table.py
def merge_cols(col_a: List[str], col_b: List[str]) -> List[str]:\n \"\"\"Merge column A and B if they do not have conflict rows\n\n Args:\n col_a: column A (list of str)\n col_b: column B (list of str)\n Returns:\n merged column\n \"\"\"\n for r_id in range(len(col_a)):\n if col_b[r_id]:\n col_a[r_id] = col_a[r_id] + \" \" + col_b[r_id]\n return col_a\n
Add index column as the first column of the table csv_rows
Parameters:
Name Type Description Default csv_rowsList[List[str]]
input table
required
Returns: output table with index column
Source code in libs/kotaemon/kotaemon/loaders/utils/table.py
def add_index_col(csv_rows: List[List[str]]) -> List[List[str]]:\n \"\"\"Add index column as the first column of the table csv_rows\n\n Args:\n csv_rows: input table\n Returns:\n output table with index column\n \"\"\"\n new_csv_rows = [[\"row id\"] + [\"\"] * len(csv_rows[0])]\n for r_id, row in enumerate(csv_rows):\n new_csv_rows.append([str(r_id + 1)] + row)\n return new_csv_rows\n
Compress table csv_rows by merging sparse columns (merge_cols)
Parameters:
Name Type Description Default csv_rowsList[List[str]]
input table
required
Returns: output: compressed table
Source code in libs/kotaemon/kotaemon/loaders/utils/table.py
def compress_csv(csv_rows: List[List[str]]) -> List[List[str]]:\n \"\"\"Compress table csv_rows by merging sparse columns (merge_cols)\n\n Args:\n csv_rows: input table\n Returns:\n output: compressed table\n \"\"\"\n csv_cols = [[r[c_id] for r in csv_rows] for c_id in range(len(csv_rows[0]))]\n to_remove_col_ids = []\n last_c_id = 0\n for c_id in range(1, len(csv_cols)):\n if not check_col_conflicts(csv_cols[last_c_id], csv_cols[c_id]):\n to_remove_col_ids.append(c_id)\n csv_cols[last_c_id] = merge_cols(csv_cols[last_c_id], csv_cols[c_id])\n else:\n last_c_id = c_id\n\n csv_cols = [r for c_id, r in enumerate(csv_cols) if c_id not in to_remove_col_ids]\n csv_rows = [[c[r_id] for c in csv_cols] for r_id in range(len(csv_cols[0]))]\n return csv_rows\n
Get list of text lines belong to table regions specified by table_list
Parameters:
Name Type Description Default ocr_listList[dict]
list of OCR output in Casia format (Flax)
required table_listList[dict]
list of table output in Casia format (Flax)
required
Returns:
Name Type Description _type_
description
Source code in libs/kotaemon/kotaemon/loaders/utils/table.py
def get_table_from_ocr(ocr_list: List[dict], table_list: List[dict]):\n \"\"\"Get list of text lines belong to table regions specified by table_list\n\n Args:\n ocr_list: list of OCR output in Casia format (Flax)\n table_list: list of table output in Casia format (Flax)\n\n Returns:\n _type_: _description_\n \"\"\"\n table_texts = []\n for table in table_list:\n if table[\"type\"] != \"table\":\n continue\n cur_table_texts = []\n for ocr in ocr_list:\n _iou = get_rect_iou(table[\"location\"], ocr[\"location\"], iou_type=1)\n if _iou > 0.8:\n cur_table_texts.append(ocr[\"text\"])\n table_texts.append(cur_table_texts)\n\n return table_texts\n
Source code in libs/kotaemon/kotaemon/loaders/utils/table.py
def make_markdown_table(array: List[List[str]]) -> str:\n \"\"\"Convert table rows in list format to markdown string\n\n Args:\n Python list with rows of table as lists\n First element as header.\n Example Input:\n [[\"Name\", \"Age\", \"Height\"],\n [\"Jake\", 20, 5'10],\n [\"Mary\", 21, 5'7]]\n Returns:\n String to put into a .md file\n \"\"\"\n array = compress_csv(array)\n array = add_index_col(array)\n markdown = \"\\n\" + str(\"| \")\n\n for e in array[0]:\n to_add = \" \" + str(e) + str(\" |\")\n markdown += to_add\n markdown += \"\\n\"\n\n markdown += \"| \"\n for i in range(len(array[0])):\n markdown += str(\"--- | \")\n markdown += \"\\n\"\n\n for entry in array[1:]:\n markdown += str(\"| \")\n for e in entry:\n to_add = str(e) + str(\" | \")\n markdown += to_add\n markdown += \"\\n\"\n\n return markdown + \"\\n\"\n
Extract list of table from FullOCR output (csv_content) with the specified table_texts
Parameters:
Name Type Description Default csv_contentstr
CSV output from FullOCR pipeline
required table_textsList[List[str]]
list of table texts extracted
required
Returns:
Type Description Tuple[List[str], str]
List of tables and non-text content
Source code in libs/kotaemon/kotaemon/loaders/utils/table.py
def extract_tables_from_csv_string(\n csv_content: str, table_texts: List[List[str]]\n) -> Tuple[List[str], str]:\n \"\"\"Extract list of table from FullOCR output\n (csv_content) with the specified table_texts\n\n Args:\n csv_content: CSV output from FullOCR pipeline\n table_texts: list of table texts extracted\n from get_table_from_ocr()\n\n Returns:\n List of tables and non-text content\n \"\"\"\n rows = parse_csv_string_to_list(csv_content)\n used_row_ids = []\n table_csv_list = []\n for table in table_texts:\n cur_rows = []\n for row_id, row in enumerate(rows):\n scores = [\n any(cell in cell_reference for cell in table)\n for cell_reference in row\n if cell_reference\n ]\n score = sum(scores) / len(scores)\n if score > 0.5 and row_id not in used_row_ids:\n used_row_ids.append(row_id)\n cur_rows.append([format_cell(cell) for cell in row])\n if cur_rows:\n table_csv_list.append(make_markdown_table(cur_rows))\n else:\n print(\"table not matched\", table)\n\n non_table_rows = [\n row for row_id, row in enumerate(rows) if row_id not in used_row_ids\n ]\n non_table_text = \"\\n\".join(\n \" \".join(format_cell(cell) for cell in row) for row in non_table_rows\n )\n return table_csv_list, non_table_text\n
Strip special characters from input text in markdown table format
Source code in libs/kotaemon/kotaemon/loaders/utils/table.py
def strip_special_chars_markdown(text: str) -> str:\n \"\"\"Strip special characters from input text in markdown table format\"\"\"\n return text.replace(\"|\", \"\").replace(\":---:\", \"\").replace(\"---\", \"\")\n
Convert markdown text to list of non-table spans and table spans
Parameters:
Name Type Description Default textstr
input markdown text
required
Returns:
Type Description Tuple[List[str], List[str]]
list of table spans and non-table spans
Source code in libs/kotaemon/kotaemon/loaders/utils/table.py
def parse_markdown_text_to_tables(text: str) -> Tuple[List[str], List[str]]:\n \"\"\"Convert markdown text to list of non-table spans and table spans\n\n Args:\n text: input markdown text\n\n Returns:\n list of table spans and non-table spans\n \"\"\"\n # init empty tables and texts list\n tables = []\n texts = []\n\n # split input by line break\n lines = text.split(\"\\n\")\n cur_table = []\n cur_text: List[str] = []\n for line in lines:\n line = line.strip()\n if line.startswith(\"|\"):\n if len(cur_text) > 0:\n texts.append(cur_text)\n cur_text = []\n cur_table.append(line)\n else:\n # add new table to the list\n if len(cur_table) > 0:\n tables.append(cur_table)\n cur_table = []\n cur_text.append(line)\n\n table_texts = [\"\\n\".join(table) for table in tables]\n non_table_texts = [\"\\n\".join(text) for text in texts]\n return table_texts, non_table_texts\n
Convert list of cells with attached text to Markdown table
Source code in libs/kotaemon/kotaemon/loaders/utils/table.py
def table_cells_to_markdown(cells: List[dict]):\n \"\"\"Convert list of cells with attached text to Markdown table\"\"\"\n\n if len(cells) == 0:\n return \"\"\n\n all_row_ids = []\n all_col_ids = []\n for cell in cells:\n all_row_ids.extend(cell[\"rows\"])\n all_col_ids.extend(cell[\"columns\"])\n\n num_rows, num_cols = max(all_row_ids) + 1, max(all_col_ids) + 1\n table_rows = [[\"\" for c in range(num_cols)] for r in range(num_rows)]\n\n # start filling in the grid\n for cell in cells:\n cell_text = \" \".join(item[\"text\"] for item in cell[\"ocr\"])\n start_row_id, end_row_id = cell[\"rows\"]\n start_col_id, end_col_id = cell[\"columns\"]\n span_cell = end_row_id != start_row_id or end_col_id != start_col_id\n\n # do not repeat long text in span cell to prevent context length issue\n if span_cell and len(cell_text.replace(\" \", \"\")) < 20 and start_row_id > 0:\n for row in range(start_row_id, end_row_id + 1):\n for col in range(start_col_id, end_col_id + 1):\n table_rows[row][col] += cell_text + \" \"\n else:\n table_rows[start_row_id][start_col_id] += cell_text + \" \"\n\n return make_markdown_table(table_rows)\n
Simple class for extracting text from a document using a regex pattern.
Parameters:
Name Type Description Default patternList[str]
The regex pattern(s) to use.
required output_mapdict
A mapping from extracted text to the desired output. Defaults to None.
required Source code in libs/kotaemon/kotaemon/parsers/regex_extractor.py
class RegexExtractor(BaseComponent):\n \"\"\"\n Simple class for extracting text from a document using a regex pattern.\n\n Args:\n pattern (List[str]): The regex pattern(s) to use.\n output_map (dict, optional): A mapping from extracted text to the\n desired output. Defaults to None.\n \"\"\"\n\n class Config:\n middleware_switches = {\"theflow.middleware.CachingMiddleware\": False}\n\n pattern: list[str]\n output_map: dict[str, str] | Callable[[str], str] = Param(\n default_callback=lambda *_: {}\n )\n\n def __init__(self, pattern: str | list[str], **kwargs):\n if isinstance(pattern, str):\n pattern = [pattern]\n super().__init__(pattern=pattern, **kwargs)\n\n @staticmethod\n def run_raw_static(pattern: str, text: str) -> list[str]:\n \"\"\"\n Finds all non-overlapping occurrences of a pattern in a string.\n\n Parameters:\n pattern (str): The regular expression pattern to search for.\n text (str): The input string to search in.\n\n Returns:\n List[str]: A list of all non-overlapping occurrences of the pattern in the\n string.\n \"\"\"\n return re.findall(pattern, text)\n\n @staticmethod\n def map_output(text, output_map) -> str:\n \"\"\"\n Maps the given `text` to its corresponding value in the `output_map` dictionary.\n\n Parameters:\n text (str): The input text to be mapped.\n output_map (dict): A dictionary containing mapping of input text to output\n values.\n\n Returns:\n str: The corresponding value from the `output_map` if `text` is found in the\n dictionary, otherwise returns the original `text`.\n \"\"\"\n if not output_map:\n return text\n\n if isinstance(output_map, dict):\n return output_map.get(text, text)\n\n return output_map(text)\n\n def run_raw(self, text: str) -> ExtractorOutput:\n \"\"\"\n Matches the raw text against the pattern and rans the output mapping, returning\n an instance of ExtractorOutput.\n\n Args:\n text (str): The raw text to be processed.\n\n Returns:\n ExtractorOutput: The processed output as a list of ExtractorOutput.\n \"\"\"\n output: list[str] = sum(\n [self.run_raw_static(p, text) for p in self.pattern], []\n )\n output = [self.map_output(text, self.output_map) for text in output]\n\n return ExtractorOutput(\n text=output[0] if output else \"\",\n matches=output,\n metadata={\"origin\": \"RegexExtractor\"},\n )\n\n def run(\n self, text: str | list[str] | Document | list[Document]\n ) -> list[ExtractorOutput]:\n \"\"\"Match the input against a pattern and return the output for each input\n\n Parameters:\n text: contains the input string to be processed\n\n Returns:\n A list contains the output ExtractorOutput for each input\n\n Example:\n ```pycon\n >>> document1 = Document(...)\n >>> document2 = Document(...)\n >>> document_batch = [document1, document2]\n >>> batch_output = self(document_batch)\n >>> print(batch_output)\n [output1_document1, output1_document2]\n ```\n \"\"\"\n # TODO: this conversion seems common\n input_: list[str] = []\n if not isinstance(text, list):\n text = [text]\n\n for item in text:\n if isinstance(item, str):\n input_.append(item)\n elif isinstance(item, Document):\n input_.append(item.text)\n else:\n raise ValueError(\n f\"Invalid input type {type(item)}, should be str or Document\"\n )\n\n output = []\n for each_input in input_:\n output.append(self.run_raw(each_input))\n\n return output\n
Finds all non-overlapping occurrences of a pattern in a string.
Parameters:
Name Type Description Default patternstr
The regular expression pattern to search for.
required textstr
The input string to search in.
required
Returns:
Type Description list[str]
List[str]: A list of all non-overlapping occurrences of the pattern in the string.
Source code in libs/kotaemon/kotaemon/parsers/regex_extractor.py
@staticmethod\ndef run_raw_static(pattern: str, text: str) -> list[str]:\n \"\"\"\n Finds all non-overlapping occurrences of a pattern in a string.\n\n Parameters:\n pattern (str): The regular expression pattern to search for.\n text (str): The input string to search in.\n\n Returns:\n List[str]: A list of all non-overlapping occurrences of the pattern in the\n string.\n \"\"\"\n return re.findall(pattern, text)\n
Maps the given text to its corresponding value in the output_map dictionary.
Parameters:
Name Type Description Default textstr
The input text to be mapped.
required output_mapdict
A dictionary containing mapping of input text to output values.
required
Returns:
Name Type Description strstr
The corresponding value from the output_map if text is found in the dictionary, otherwise returns the original text.
Source code in libs/kotaemon/kotaemon/parsers/regex_extractor.py
@staticmethod\ndef map_output(text, output_map) -> str:\n \"\"\"\n Maps the given `text` to its corresponding value in the `output_map` dictionary.\n\n Parameters:\n text (str): The input text to be mapped.\n output_map (dict): A dictionary containing mapping of input text to output\n values.\n\n Returns:\n str: The corresponding value from the `output_map` if `text` is found in the\n dictionary, otherwise returns the original `text`.\n \"\"\"\n if not output_map:\n return text\n\n if isinstance(output_map, dict):\n return output_map.get(text, text)\n\n return output_map(text)\n
Matches the raw text against the pattern and rans the output mapping, returning an instance of ExtractorOutput.
Parameters:
Name Type Description Default textstr
The raw text to be processed.
required
Returns:
Name Type Description ExtractorOutputExtractorOutput
The processed output as a list of ExtractorOutput.
Source code in libs/kotaemon/kotaemon/parsers/regex_extractor.py
def run_raw(self, text: str) -> ExtractorOutput:\n \"\"\"\n Matches the raw text against the pattern and rans the output mapping, returning\n an instance of ExtractorOutput.\n\n Args:\n text (str): The raw text to be processed.\n\n Returns:\n ExtractorOutput: The processed output as a list of ExtractorOutput.\n \"\"\"\n output: list[str] = sum(\n [self.run_raw_static(p, text) for p in self.pattern], []\n )\n output = [self.map_output(text, self.output_map) for text in output]\n\n return ExtractorOutput(\n text=output[0] if output else \"\",\n matches=output,\n metadata={\"origin\": \"RegexExtractor\"},\n )\n
Source code in libs/kotaemon/kotaemon/parsers/regex_extractor.py
def run(\n self, text: str | list[str] | Document | list[Document]\n) -> list[ExtractorOutput]:\n \"\"\"Match the input against a pattern and return the output for each input\n\n Parameters:\n text: contains the input string to be processed\n\n Returns:\n A list contains the output ExtractorOutput for each input\n\n Example:\n ```pycon\n >>> document1 = Document(...)\n >>> document2 = Document(...)\n >>> document_batch = [document1, document2]\n >>> batch_output = self(document_batch)\n >>> print(batch_output)\n [output1_document1, output1_document2]\n ```\n \"\"\"\n # TODO: this conversion seems common\n input_: list[str] = []\n if not isinstance(text, list):\n text = [text]\n\n for item in text:\n if isinstance(item, str):\n input_.append(item)\n elif isinstance(item, Document):\n input_.append(item.text)\n else:\n raise ValueError(\n f\"Invalid input type {type(item)}, should be str or Document\"\n )\n\n output = []\n for each_input in input_:\n output.append(self.run_raw(each_input))\n\n return output\n
Simple class for extracting text from a document using a regex pattern.
Parameters:
Name Type Description Default patternList[str]
The regex pattern(s) to use.
required output_mapdict
A mapping from extracted text to the desired output. Defaults to None.
required Source code in libs/kotaemon/kotaemon/parsers/regex_extractor.py
class RegexExtractor(BaseComponent):\n \"\"\"\n Simple class for extracting text from a document using a regex pattern.\n\n Args:\n pattern (List[str]): The regex pattern(s) to use.\n output_map (dict, optional): A mapping from extracted text to the\n desired output. Defaults to None.\n \"\"\"\n\n class Config:\n middleware_switches = {\"theflow.middleware.CachingMiddleware\": False}\n\n pattern: list[str]\n output_map: dict[str, str] | Callable[[str], str] = Param(\n default_callback=lambda *_: {}\n )\n\n def __init__(self, pattern: str | list[str], **kwargs):\n if isinstance(pattern, str):\n pattern = [pattern]\n super().__init__(pattern=pattern, **kwargs)\n\n @staticmethod\n def run_raw_static(pattern: str, text: str) -> list[str]:\n \"\"\"\n Finds all non-overlapping occurrences of a pattern in a string.\n\n Parameters:\n pattern (str): The regular expression pattern to search for.\n text (str): The input string to search in.\n\n Returns:\n List[str]: A list of all non-overlapping occurrences of the pattern in the\n string.\n \"\"\"\n return re.findall(pattern, text)\n\n @staticmethod\n def map_output(text, output_map) -> str:\n \"\"\"\n Maps the given `text` to its corresponding value in the `output_map` dictionary.\n\n Parameters:\n text (str): The input text to be mapped.\n output_map (dict): A dictionary containing mapping of input text to output\n values.\n\n Returns:\n str: The corresponding value from the `output_map` if `text` is found in the\n dictionary, otherwise returns the original `text`.\n \"\"\"\n if not output_map:\n return text\n\n if isinstance(output_map, dict):\n return output_map.get(text, text)\n\n return output_map(text)\n\n def run_raw(self, text: str) -> ExtractorOutput:\n \"\"\"\n Matches the raw text against the pattern and rans the output mapping, returning\n an instance of ExtractorOutput.\n\n Args:\n text (str): The raw text to be processed.\n\n Returns:\n ExtractorOutput: The processed output as a list of ExtractorOutput.\n \"\"\"\n output: list[str] = sum(\n [self.run_raw_static(p, text) for p in self.pattern], []\n )\n output = [self.map_output(text, self.output_map) for text in output]\n\n return ExtractorOutput(\n text=output[0] if output else \"\",\n matches=output,\n metadata={\"origin\": \"RegexExtractor\"},\n )\n\n def run(\n self, text: str | list[str] | Document | list[Document]\n ) -> list[ExtractorOutput]:\n \"\"\"Match the input against a pattern and return the output for each input\n\n Parameters:\n text: contains the input string to be processed\n\n Returns:\n A list contains the output ExtractorOutput for each input\n\n Example:\n ```pycon\n >>> document1 = Document(...)\n >>> document2 = Document(...)\n >>> document_batch = [document1, document2]\n >>> batch_output = self(document_batch)\n >>> print(batch_output)\n [output1_document1, output1_document2]\n ```\n \"\"\"\n # TODO: this conversion seems common\n input_: list[str] = []\n if not isinstance(text, list):\n text = [text]\n\n for item in text:\n if isinstance(item, str):\n input_.append(item)\n elif isinstance(item, Document):\n input_.append(item.text)\n else:\n raise ValueError(\n f\"Invalid input type {type(item)}, should be str or Document\"\n )\n\n output = []\n for each_input in input_:\n output.append(self.run_raw(each_input))\n\n return output\n
Finds all non-overlapping occurrences of a pattern in a string.
Parameters:
Name Type Description Default patternstr
The regular expression pattern to search for.
required textstr
The input string to search in.
required
Returns:
Type Description list[str]
List[str]: A list of all non-overlapping occurrences of the pattern in the string.
Source code in libs/kotaemon/kotaemon/parsers/regex_extractor.py
@staticmethod\ndef run_raw_static(pattern: str, text: str) -> list[str]:\n \"\"\"\n Finds all non-overlapping occurrences of a pattern in a string.\n\n Parameters:\n pattern (str): The regular expression pattern to search for.\n text (str): The input string to search in.\n\n Returns:\n List[str]: A list of all non-overlapping occurrences of the pattern in the\n string.\n \"\"\"\n return re.findall(pattern, text)\n
Maps the given text to its corresponding value in the output_map dictionary.
Parameters:
Name Type Description Default textstr
The input text to be mapped.
required output_mapdict
A dictionary containing mapping of input text to output values.
required
Returns:
Name Type Description strstr
The corresponding value from the output_map if text is found in the dictionary, otherwise returns the original text.
Source code in libs/kotaemon/kotaemon/parsers/regex_extractor.py
@staticmethod\ndef map_output(text, output_map) -> str:\n \"\"\"\n Maps the given `text` to its corresponding value in the `output_map` dictionary.\n\n Parameters:\n text (str): The input text to be mapped.\n output_map (dict): A dictionary containing mapping of input text to output\n values.\n\n Returns:\n str: The corresponding value from the `output_map` if `text` is found in the\n dictionary, otherwise returns the original `text`.\n \"\"\"\n if not output_map:\n return text\n\n if isinstance(output_map, dict):\n return output_map.get(text, text)\n\n return output_map(text)\n
Matches the raw text against the pattern and rans the output mapping, returning an instance of ExtractorOutput.
Parameters:
Name Type Description Default textstr
The raw text to be processed.
required
Returns:
Name Type Description ExtractorOutputExtractorOutput
The processed output as a list of ExtractorOutput.
Source code in libs/kotaemon/kotaemon/parsers/regex_extractor.py
def run_raw(self, text: str) -> ExtractorOutput:\n \"\"\"\n Matches the raw text against the pattern and rans the output mapping, returning\n an instance of ExtractorOutput.\n\n Args:\n text (str): The raw text to be processed.\n\n Returns:\n ExtractorOutput: The processed output as a list of ExtractorOutput.\n \"\"\"\n output: list[str] = sum(\n [self.run_raw_static(p, text) for p in self.pattern], []\n )\n output = [self.map_output(text, self.output_map) for text in output]\n\n return ExtractorOutput(\n text=output[0] if output else \"\",\n matches=output,\n metadata={\"origin\": \"RegexExtractor\"},\n )\n
Source code in libs/kotaemon/kotaemon/parsers/regex_extractor.py
def run(\n self, text: str | list[str] | Document | list[Document]\n) -> list[ExtractorOutput]:\n \"\"\"Match the input against a pattern and return the output for each input\n\n Parameters:\n text: contains the input string to be processed\n\n Returns:\n A list contains the output ExtractorOutput for each input\n\n Example:\n ```pycon\n >>> document1 = Document(...)\n >>> document2 = Document(...)\n >>> document_batch = [document1, document2]\n >>> batch_output = self(document_batch)\n >>> print(batch_output)\n [output1_document1, output1_document2]\n ```\n \"\"\"\n # TODO: this conversion seems common\n input_: list[str] = []\n if not isinstance(text, list):\n text = [text]\n\n for item in text:\n if isinstance(item, str):\n input_.append(item)\n elif isinstance(item, Document):\n input_.append(item.text)\n else:\n raise ValueError(\n f\"Invalid input type {type(item)}, should be str or Document\"\n )\n\n output = []\n for each_input in input_:\n output.append(self.run_raw(each_input))\n\n return output\n
A document store is in charged of storing and managing documents
Source code in libs/kotaemon/kotaemon/storages/docstores/base.py
class BaseDocumentStore(ABC):\n \"\"\"A document store is in charged of storing and managing documents\"\"\"\n\n @abstractmethod\n def __init__(self, *args, **kwargs):\n ...\n\n @abstractmethod\n def add(\n self,\n docs: Union[Document, List[Document]],\n ids: Optional[Union[List[str], str]] = None,\n **kwargs,\n ):\n \"\"\"Add document into document store\n\n Args:\n docs: Document or list of documents\n ids: List of ids of the documents. Optional, if not set will use doc.doc_id\n \"\"\"\n ...\n\n @abstractmethod\n def get(self, ids: Union[List[str], str]) -> List[Document]:\n \"\"\"Get document by id\"\"\"\n ...\n\n @abstractmethod\n def get_all(self) -> List[Document]:\n \"\"\"Get all documents\"\"\"\n ...\n\n @abstractmethod\n def count(self) -> int:\n \"\"\"Count number of documents\"\"\"\n ...\n\n @abstractmethod\n def query(\n self, query: str, top_k: int = 10, doc_ids: Optional[list] = None\n ) -> List[Document]:\n \"\"\"Search document store using search query\"\"\"\n ...\n\n @abstractmethod\n def delete(self, ids: Union[List[str], str]):\n \"\"\"Delete document by id\"\"\"\n ...\n\n @abstractmethod\n def drop(self):\n \"\"\"Drop the document store\"\"\"\n ...\n
Name Type Description Default docsUnion[Document, List[Document]]
Document or list of documents
required idsOptional[Union[List[str], str]]
List of ids of the documents. Optional, if not set will use doc.doc_id
None Source code in libs/kotaemon/kotaemon/storages/docstores/base.py
@abstractmethod\ndef add(\n self,\n docs: Union[Document, List[Document]],\n ids: Optional[Union[List[str], str]] = None,\n **kwargs,\n):\n \"\"\"Add document into document store\n\n Args:\n docs: Document or list of documents\n ids: List of ids of the documents. Optional, if not set will use doc.doc_id\n \"\"\"\n ...\n
Name Type Description Default docsUnion[Document, List[Document]]
list of documents to add
required idsOptional[Union[List[str], str]]
specify the ids of documents to add or use existing doc.doc_id
Nonerefresh_indicesbool
request Elasticsearch to update its index (default to True)
True Source code in libs/kotaemon/kotaemon/storages/docstores/elasticsearch.py
def add(\n self,\n docs: Union[Document, List[Document]],\n ids: Optional[Union[List[str], str]] = None,\n refresh_indices: bool = True,\n **kwargs,\n):\n \"\"\"Add document into document store\n\n Args:\n docs: list of documents to add\n ids: specify the ids of documents to add or use existing doc.doc_id\n refresh_indices: request Elasticsearch to update its index (default to True)\n \"\"\"\n if ids and not isinstance(ids, list):\n ids = [ids]\n if not isinstance(docs, list):\n docs = [docs]\n doc_ids = ids if ids else [doc.doc_id for doc in docs]\n\n requests = []\n for doc_id, doc in zip(doc_ids, docs):\n text = doc.text\n metadata = doc.metadata\n request = {\n \"_op_type\": \"index\",\n \"_index\": self.index_name,\n \"content\": text,\n \"metadata\": metadata,\n \"_id\": doc_id,\n }\n requests.append(request)\n\n success, failed = self.es_bulk(self.client, requests)\n print(\"Added/Updated documents to index\", success)\n print(\"Failed documents to index\", failed)\n\n if refresh_indices:\n self.client.indices.refresh(index=self.index_name)\n
Query Elasticsearch store using query format of ES client
Parameters:
Name Type Description Default querydict
Elasticsearch query format
required
Returns:
Type Description List[Document]
List[Document]: List of result documents
Source code in libs/kotaemon/kotaemon/storages/docstores/elasticsearch.py
def query_raw(self, query: dict) -> List[Document]:\n \"\"\"Query Elasticsearch store using query format of ES client\n\n Args:\n query (dict): Elasticsearch query format\n\n Returns:\n List[Document]: List of result documents\n \"\"\"\n res = self.client.search(index=self.index_name, body=query)\n docs = []\n for r in res[\"hits\"][\"hits\"]:\n docs.append(\n Document(\n id_=r[\"_id\"],\n text=r[\"_source\"][\"content\"],\n metadata=r[\"_source\"][\"metadata\"],\n )\n )\n return docs\n
Simple memory document store that store document in a dictionary
Source code in libs/kotaemon/kotaemon/storages/docstores/in_memory.py
class InMemoryDocumentStore(BaseDocumentStore):\n \"\"\"Simple memory document store that store document in a dictionary\"\"\"\n\n def __init__(self):\n self._store = {}\n\n def add(\n self,\n docs: Union[Document, List[Document]],\n ids: Optional[Union[List[str], str]] = None,\n **kwargs,\n ):\n \"\"\"Add document into document store\n\n Args:\n docs: list of documents to add\n ids: specify the ids of documents to add or\n use existing doc.doc_id\n exist_ok: raise error when duplicate doc-id\n found in the docstore (default to False)\n \"\"\"\n exist_ok: bool = kwargs.pop(\"exist_ok\", False)\n\n if ids and not isinstance(ids, list):\n ids = [ids]\n if not isinstance(docs, list):\n docs = [docs]\n doc_ids = ids if ids else [doc.doc_id for doc in docs]\n\n for doc_id, doc in zip(doc_ids, docs):\n if doc_id in self._store and not exist_ok:\n raise ValueError(f\"Document with id {doc_id} already exist\")\n self._store[doc_id] = doc\n\n def get(self, ids: Union[List[str], str]) -> List[Document]:\n \"\"\"Get document by id\"\"\"\n if not isinstance(ids, list):\n ids = [ids]\n\n return [self._store[doc_id] for doc_id in ids]\n\n def get_all(self) -> List[Document]:\n \"\"\"Get all documents\"\"\"\n return list(self._store.values())\n\n def count(self) -> int:\n \"\"\"Count number of documents\"\"\"\n return len(self._store)\n\n def delete(self, ids: Union[List[str], str]):\n \"\"\"Delete document by id\"\"\"\n if not isinstance(ids, list):\n ids = [ids]\n\n for doc_id in ids:\n del self._store[doc_id]\n\n def save(self, path: Union[str, Path]):\n \"\"\"Save document to path\"\"\"\n store = {key: value.to_dict() for key, value in self._store.items()}\n with open(path, \"w\") as f:\n json.dump(store, f)\n\n def load(self, path: Union[str, Path]):\n \"\"\"Load document store from path\"\"\"\n with open(path) as f:\n store = json.load(f)\n # TODO: save and load aren't lossless. A Document-subclass will lose\n # information. Need to edit the `to_dict` and `from_dict` methods in\n # the Document class.\n # For better query support, utilize SQLite as the default document store.\n # Also, for portability, use SQLAlchemy for document store.\n self._store = {key: Document.from_dict(value) for key, value in store.items()}\n\n def query(\n self, query: str, top_k: int = 10, doc_ids: Optional[list] = None\n ) -> List[Document]:\n \"\"\"Perform full-text search on document store\"\"\"\n return []\n\n def __persist_flow__(self):\n return {}\n\n def drop(self):\n \"\"\"Drop the document store\"\"\"\n self._store = {}\n
Name Type Description Default docsUnion[Document, List[Document]]
list of documents to add
required idsOptional[Union[List[str], str]]
specify the ids of documents to add or use existing doc.doc_id
Noneexist_ok
raise error when duplicate doc-id found in the docstore (default to False)
required Source code in libs/kotaemon/kotaemon/storages/docstores/in_memory.py
def add(\n self,\n docs: Union[Document, List[Document]],\n ids: Optional[Union[List[str], str]] = None,\n **kwargs,\n):\n \"\"\"Add document into document store\n\n Args:\n docs: list of documents to add\n ids: specify the ids of documents to add or\n use existing doc.doc_id\n exist_ok: raise error when duplicate doc-id\n found in the docstore (default to False)\n \"\"\"\n exist_ok: bool = kwargs.pop(\"exist_ok\", False)\n\n if ids and not isinstance(ids, list):\n ids = [ids]\n if not isinstance(docs, list):\n docs = [docs]\n doc_ids = ids if ids else [doc.doc_id for doc in docs]\n\n for doc_id, doc in zip(doc_ids, docs):\n if doc_id in self._store and not exist_ok:\n raise ValueError(f\"Document with id {doc_id} already exist\")\n self._store[doc_id] = doc\n
Source code in libs/kotaemon/kotaemon/storages/docstores/in_memory.py
def get(self, ids: Union[List[str], str]) -> List[Document]:\n \"\"\"Get document by id\"\"\"\n if not isinstance(ids, list):\n ids = [ids]\n\n return [self._store[doc_id] for doc_id in ids]\n
Source code in libs/kotaemon/kotaemon/storages/docstores/in_memory.py
def delete(self, ids: Union[List[str], str]):\n \"\"\"Delete document by id\"\"\"\n if not isinstance(ids, list):\n ids = [ids]\n\n for doc_id in ids:\n del self._store[doc_id]\n
Source code in libs/kotaemon/kotaemon/storages/docstores/in_memory.py
def save(self, path: Union[str, Path]):\n \"\"\"Save document to path\"\"\"\n store = {key: value.to_dict() for key, value in self._store.items()}\n with open(path, \"w\") as f:\n json.dump(store, f)\n
Source code in libs/kotaemon/kotaemon/storages/docstores/in_memory.py
def load(self, path: Union[str, Path]):\n \"\"\"Load document store from path\"\"\"\n with open(path) as f:\n store = json.load(f)\n # TODO: save and load aren't lossless. A Document-subclass will lose\n # information. Need to edit the `to_dict` and `from_dict` methods in\n # the Document class.\n # For better query support, utilize SQLite as the default document store.\n # Also, for portability, use SQLAlchemy for document store.\n self._store = {key: Document.from_dict(value) for key, value in store.items()}\n
Improve InMemoryDocumentStore by auto saving whenever the corpus is changed
Source code in libs/kotaemon/kotaemon/storages/docstores/simple_file.py
class SimpleFileDocumentStore(InMemoryDocumentStore):\n \"\"\"Improve InMemoryDocumentStore by auto saving whenever the corpus is changed\"\"\"\n\n def __init__(self, path: str | Path, collection_name: str = \"default\"):\n super().__init__()\n self._path = path\n self._collection_name = collection_name\n\n Path(path).mkdir(parents=True, exist_ok=True)\n self._save_path = Path(path) / f\"{collection_name}.json\"\n if self._save_path.is_file():\n self.load(self._save_path)\n\n def get(self, ids: Union[List[str], str]) -> List[Document]:\n \"\"\"Get document by id\"\"\"\n if not isinstance(ids, list):\n ids = [ids]\n\n for doc_id in ids:\n if doc_id not in self._store:\n self.load(self._save_path)\n break\n\n return [self._store[doc_id] for doc_id in ids]\n\n def add(\n self,\n docs: Union[Document, List[Document]],\n ids: Optional[Union[List[str], str]] = None,\n **kwargs,\n ):\n \"\"\"Add document into document store\n\n Args:\n docs: list of documents to add\n ids: specify the ids of documents to add or\n use existing doc.doc_id\n exist_ok: raise error when duplicate doc-id\n found in the docstore (default to False)\n \"\"\"\n super().add(docs=docs, ids=ids, **kwargs)\n self.save(self._save_path)\n\n def delete(self, ids: Union[List[str], str]):\n \"\"\"Delete document by id\"\"\"\n super().delete(ids=ids)\n self.save(self._save_path)\n\n def drop(self):\n \"\"\"Drop the document store\"\"\"\n super().drop()\n self._save_path.unlink(missing_ok=True)\n\n def __persist_flow__(self):\n from theflow.utils.modules import serialize\n\n return {\n \"path\": serialize(self._path),\n \"collection_name\": self._collection_name,\n }\n
Source code in libs/kotaemon/kotaemon/storages/docstores/simple_file.py
def get(self, ids: Union[List[str], str]) -> List[Document]:\n \"\"\"Get document by id\"\"\"\n if not isinstance(ids, list):\n ids = [ids]\n\n for doc_id in ids:\n if doc_id not in self._store:\n self.load(self._save_path)\n break\n\n return [self._store[doc_id] for doc_id in ids]\n
Name Type Description Default docsUnion[Document, List[Document]]
list of documents to add
required idsOptional[Union[List[str], str]]
specify the ids of documents to add or use existing doc.doc_id
Noneexist_ok
raise error when duplicate doc-id found in the docstore (default to False)
required Source code in libs/kotaemon/kotaemon/storages/docstores/simple_file.py
def add(\n self,\n docs: Union[Document, List[Document]],\n ids: Optional[Union[List[str], str]] = None,\n **kwargs,\n):\n \"\"\"Add document into document store\n\n Args:\n docs: list of documents to add\n ids: specify the ids of documents to add or\n use existing doc.doc_id\n exist_ok: raise error when duplicate doc-id\n found in the docstore (default to False)\n \"\"\"\n super().add(docs=docs, ids=ids, **kwargs)\n self.save(self._save_path)\n
Source code in libs/kotaemon/kotaemon/storages/vectorstores/base.py
class BaseVectorStore(ABC):\n @abstractmethod\n def __init__(self, *args, **kwargs):\n ...\n\n @abstractmethod\n def add(\n self,\n embeddings: list[list[float]] | list[DocumentWithEmbedding],\n metadatas: Optional[list[dict]] = None,\n ids: Optional[list[str]] = None,\n ) -> list[str]:\n \"\"\"Add vector embeddings to vector stores\n\n Args:\n embeddings: List of embeddings\n metadatas: List of metadata of the embeddings\n ids: List of ids of the embeddings\n kwargs: meant for vectorstore-specific parameters\n\n Returns:\n List of ids of the embeddings\n \"\"\"\n ...\n\n @abstractmethod\n def delete(self, ids: list[str], **kwargs):\n \"\"\"Delete vector embeddings from vector stores\n\n Args:\n ids: List of ids of the embeddings to be deleted\n kwargs: meant for vectorstore-specific parameters\n \"\"\"\n ...\n\n @abstractmethod\n def query(\n self,\n embedding: list[float],\n top_k: int = 1,\n ids: Optional[list[str]] = None,\n **kwargs,\n ) -> tuple[list[list[float]], list[float], list[str]]:\n \"\"\"Return the top k most similar vector embeddings\n\n Args:\n embedding: List of embeddings\n top_k: Number of most similar embeddings to return\n ids: List of ids of the embeddings to be queried\n\n Returns:\n the matched embeddings, the similarity scores, and the ids\n \"\"\"\n ...\n\n @abstractmethod\n def drop(self):\n \"\"\"Drop the vector store\"\"\"\n ...\n
Name Type Description Default embeddingslist[list[float]] | list[DocumentWithEmbedding]
List of embeddings
required metadatasOptional[list[dict]]
List of metadata of the embeddings
NoneidsOptional[list[str]]
List of ids of the embeddings
Nonekwargs
meant for vectorstore-specific parameters
required
Returns:
Type Description list[str]
List of ids of the embeddings
Source code in libs/kotaemon/kotaemon/storages/vectorstores/base.py
@abstractmethod\ndef add(\n self,\n embeddings: list[list[float]] | list[DocumentWithEmbedding],\n metadatas: Optional[list[dict]] = None,\n ids: Optional[list[str]] = None,\n) -> list[str]:\n \"\"\"Add vector embeddings to vector stores\n\n Args:\n embeddings: List of embeddings\n metadatas: List of metadata of the embeddings\n ids: List of ids of the embeddings\n kwargs: meant for vectorstore-specific parameters\n\n Returns:\n List of ids of the embeddings\n \"\"\"\n ...\n
{} Source code in libs/kotaemon/kotaemon/storages/vectorstores/base.py
@abstractmethod\ndef delete(self, ids: list[str], **kwargs):\n \"\"\"Delete vector embeddings from vector stores\n\n Args:\n ids: List of ids of the embeddings to be deleted\n kwargs: meant for vectorstore-specific parameters\n \"\"\"\n ...\n
Name Type Description Default embeddinglist[float]
List of embeddings
required top_kint
Number of most similar embeddings to return
1idsOptional[list[str]]
List of ids of the embeddings to be queried
None
Returns:
Type Description tuple[list[list[float]], list[float], list[str]]
the matched embeddings, the similarity scores, and the ids
Source code in libs/kotaemon/kotaemon/storages/vectorstores/base.py
@abstractmethod\ndef query(\n self,\n embedding: list[float],\n top_k: int = 1,\n ids: Optional[list[str]] = None,\n **kwargs,\n) -> tuple[list[list[float]], list[float], list[str]]:\n \"\"\"Return the top k most similar vector embeddings\n\n Args:\n embedding: List of embeddings\n top_k: Number of most similar embeddings to return\n ids: List of ids of the embeddings to be queried\n\n Returns:\n the matched embeddings, the similarity scores, and the ids\n \"\"\"\n ...\n
{} Source code in libs/kotaemon/kotaemon/storages/vectorstores/chroma.py
def delete(self, ids: List[str], **kwargs):\n \"\"\"Delete vector embeddings from vector stores\n\n Args:\n ids: List of ids of the embeddings to be deleted\n kwargs: meant for vectorstore-specific parameters\n \"\"\"\n self._client.client.delete(ids=ids)\n
None Source code in libs/kotaemon/kotaemon/storages/vectorstores/in_memory.py
def save(\n self,\n save_path: str,\n fs: Optional[fsspec.AbstractFileSystem] = None,\n **kwargs,\n):\n\n \"\"\"save a simpleVectorStore to a dictionary.\n\n Args:\n save_path: Path of saving vector to disk.\n fs: An abstract super-class for pythonic file-systems\n \"\"\"\n self._client.persist(persist_path=save_path, fs=fs)\n
{} Source code in libs/kotaemon/kotaemon/storages/vectorstores/lancedb.py
def delete(self, ids: List[str], **kwargs):\n \"\"\"Delete vector embeddings from vector stores\n\n Args:\n ids: List of ids of the embeddings to be deleted\n kwargs: meant for vectorstore-specific parameters\n \"\"\"\n self._client.delete_nodes(ids)\n
{} Source code in libs/kotaemon/kotaemon/storages/vectorstores/qdrant.py
def delete(self, ids: List[str], **kwargs):\n \"\"\"Delete vector embeddings from vector stores\n\n Args:\n ids: List of ids of the embeddings to be deleted\n kwargs: meant for vectorstore-specific parameters\n \"\"\"\n from qdrant_client import models\n\n self._client.client.delete(\n collection_name=self._collection_name,\n points_selector=models.PointIdsList(\n points=ids,\n ),\n **kwargs,\n )\n
A document store is in charged of storing and managing documents
Source code in libs/kotaemon/kotaemon/storages/docstores/base.py
class BaseDocumentStore(ABC):\n \"\"\"A document store is in charged of storing and managing documents\"\"\"\n\n @abstractmethod\n def __init__(self, *args, **kwargs):\n ...\n\n @abstractmethod\n def add(\n self,\n docs: Union[Document, List[Document]],\n ids: Optional[Union[List[str], str]] = None,\n **kwargs,\n ):\n \"\"\"Add document into document store\n\n Args:\n docs: Document or list of documents\n ids: List of ids of the documents. Optional, if not set will use doc.doc_id\n \"\"\"\n ...\n\n @abstractmethod\n def get(self, ids: Union[List[str], str]) -> List[Document]:\n \"\"\"Get document by id\"\"\"\n ...\n\n @abstractmethod\n def get_all(self) -> List[Document]:\n \"\"\"Get all documents\"\"\"\n ...\n\n @abstractmethod\n def count(self) -> int:\n \"\"\"Count number of documents\"\"\"\n ...\n\n @abstractmethod\n def query(\n self, query: str, top_k: int = 10, doc_ids: Optional[list] = None\n ) -> List[Document]:\n \"\"\"Search document store using search query\"\"\"\n ...\n\n @abstractmethod\n def delete(self, ids: Union[List[str], str]):\n \"\"\"Delete document by id\"\"\"\n ...\n\n @abstractmethod\n def drop(self):\n \"\"\"Drop the document store\"\"\"\n ...\n
Name Type Description Default docsUnion[Document, List[Document]]
Document or list of documents
required idsOptional[Union[List[str], str]]
List of ids of the documents. Optional, if not set will use doc.doc_id
None Source code in libs/kotaemon/kotaemon/storages/docstores/base.py
@abstractmethod\ndef add(\n self,\n docs: Union[Document, List[Document]],\n ids: Optional[Union[List[str], str]] = None,\n **kwargs,\n):\n \"\"\"Add document into document store\n\n Args:\n docs: Document or list of documents\n ids: List of ids of the documents. Optional, if not set will use doc.doc_id\n \"\"\"\n ...\n
Name Type Description Default docsUnion[Document, List[Document]]
list of documents to add
required idsOptional[Union[List[str], str]]
specify the ids of documents to add or use existing doc.doc_id
Nonerefresh_indicesbool
request Elasticsearch to update its index (default to True)
True Source code in libs/kotaemon/kotaemon/storages/docstores/elasticsearch.py
def add(\n self,\n docs: Union[Document, List[Document]],\n ids: Optional[Union[List[str], str]] = None,\n refresh_indices: bool = True,\n **kwargs,\n):\n \"\"\"Add document into document store\n\n Args:\n docs: list of documents to add\n ids: specify the ids of documents to add or use existing doc.doc_id\n refresh_indices: request Elasticsearch to update its index (default to True)\n \"\"\"\n if ids and not isinstance(ids, list):\n ids = [ids]\n if not isinstance(docs, list):\n docs = [docs]\n doc_ids = ids if ids else [doc.doc_id for doc in docs]\n\n requests = []\n for doc_id, doc in zip(doc_ids, docs):\n text = doc.text\n metadata = doc.metadata\n request = {\n \"_op_type\": \"index\",\n \"_index\": self.index_name,\n \"content\": text,\n \"metadata\": metadata,\n \"_id\": doc_id,\n }\n requests.append(request)\n\n success, failed = self.es_bulk(self.client, requests)\n print(\"Added/Updated documents to index\", success)\n print(\"Failed documents to index\", failed)\n\n if refresh_indices:\n self.client.indices.refresh(index=self.index_name)\n
Query Elasticsearch store using query format of ES client
Parameters:
Name Type Description Default querydict
Elasticsearch query format
required
Returns:
Type Description List[Document]
List[Document]: List of result documents
Source code in libs/kotaemon/kotaemon/storages/docstores/elasticsearch.py
def query_raw(self, query: dict) -> List[Document]:\n \"\"\"Query Elasticsearch store using query format of ES client\n\n Args:\n query (dict): Elasticsearch query format\n\n Returns:\n List[Document]: List of result documents\n \"\"\"\n res = self.client.search(index=self.index_name, body=query)\n docs = []\n for r in res[\"hits\"][\"hits\"]:\n docs.append(\n Document(\n id_=r[\"_id\"],\n text=r[\"_source\"][\"content\"],\n metadata=r[\"_source\"][\"metadata\"],\n )\n )\n return docs\n
Simple memory document store that store document in a dictionary
Source code in libs/kotaemon/kotaemon/storages/docstores/in_memory.py
class InMemoryDocumentStore(BaseDocumentStore):\n \"\"\"Simple memory document store that store document in a dictionary\"\"\"\n\n def __init__(self):\n self._store = {}\n\n def add(\n self,\n docs: Union[Document, List[Document]],\n ids: Optional[Union[List[str], str]] = None,\n **kwargs,\n ):\n \"\"\"Add document into document store\n\n Args:\n docs: list of documents to add\n ids: specify the ids of documents to add or\n use existing doc.doc_id\n exist_ok: raise error when duplicate doc-id\n found in the docstore (default to False)\n \"\"\"\n exist_ok: bool = kwargs.pop(\"exist_ok\", False)\n\n if ids and not isinstance(ids, list):\n ids = [ids]\n if not isinstance(docs, list):\n docs = [docs]\n doc_ids = ids if ids else [doc.doc_id for doc in docs]\n\n for doc_id, doc in zip(doc_ids, docs):\n if doc_id in self._store and not exist_ok:\n raise ValueError(f\"Document with id {doc_id} already exist\")\n self._store[doc_id] = doc\n\n def get(self, ids: Union[List[str], str]) -> List[Document]:\n \"\"\"Get document by id\"\"\"\n if not isinstance(ids, list):\n ids = [ids]\n\n return [self._store[doc_id] for doc_id in ids]\n\n def get_all(self) -> List[Document]:\n \"\"\"Get all documents\"\"\"\n return list(self._store.values())\n\n def count(self) -> int:\n \"\"\"Count number of documents\"\"\"\n return len(self._store)\n\n def delete(self, ids: Union[List[str], str]):\n \"\"\"Delete document by id\"\"\"\n if not isinstance(ids, list):\n ids = [ids]\n\n for doc_id in ids:\n del self._store[doc_id]\n\n def save(self, path: Union[str, Path]):\n \"\"\"Save document to path\"\"\"\n store = {key: value.to_dict() for key, value in self._store.items()}\n with open(path, \"w\") as f:\n json.dump(store, f)\n\n def load(self, path: Union[str, Path]):\n \"\"\"Load document store from path\"\"\"\n with open(path) as f:\n store = json.load(f)\n # TODO: save and load aren't lossless. A Document-subclass will lose\n # information. Need to edit the `to_dict` and `from_dict` methods in\n # the Document class.\n # For better query support, utilize SQLite as the default document store.\n # Also, for portability, use SQLAlchemy for document store.\n self._store = {key: Document.from_dict(value) for key, value in store.items()}\n\n def query(\n self, query: str, top_k: int = 10, doc_ids: Optional[list] = None\n ) -> List[Document]:\n \"\"\"Perform full-text search on document store\"\"\"\n return []\n\n def __persist_flow__(self):\n return {}\n\n def drop(self):\n \"\"\"Drop the document store\"\"\"\n self._store = {}\n
Name Type Description Default docsUnion[Document, List[Document]]
list of documents to add
required idsOptional[Union[List[str], str]]
specify the ids of documents to add or use existing doc.doc_id
Noneexist_ok
raise error when duplicate doc-id found in the docstore (default to False)
required Source code in libs/kotaemon/kotaemon/storages/docstores/in_memory.py
def add(\n self,\n docs: Union[Document, List[Document]],\n ids: Optional[Union[List[str], str]] = None,\n **kwargs,\n):\n \"\"\"Add document into document store\n\n Args:\n docs: list of documents to add\n ids: specify the ids of documents to add or\n use existing doc.doc_id\n exist_ok: raise error when duplicate doc-id\n found in the docstore (default to False)\n \"\"\"\n exist_ok: bool = kwargs.pop(\"exist_ok\", False)\n\n if ids and not isinstance(ids, list):\n ids = [ids]\n if not isinstance(docs, list):\n docs = [docs]\n doc_ids = ids if ids else [doc.doc_id for doc in docs]\n\n for doc_id, doc in zip(doc_ids, docs):\n if doc_id in self._store and not exist_ok:\n raise ValueError(f\"Document with id {doc_id} already exist\")\n self._store[doc_id] = doc\n
Source code in libs/kotaemon/kotaemon/storages/docstores/in_memory.py
def get(self, ids: Union[List[str], str]) -> List[Document]:\n \"\"\"Get document by id\"\"\"\n if not isinstance(ids, list):\n ids = [ids]\n\n return [self._store[doc_id] for doc_id in ids]\n
Source code in libs/kotaemon/kotaemon/storages/docstores/in_memory.py
def delete(self, ids: Union[List[str], str]):\n \"\"\"Delete document by id\"\"\"\n if not isinstance(ids, list):\n ids = [ids]\n\n for doc_id in ids:\n del self._store[doc_id]\n
Source code in libs/kotaemon/kotaemon/storages/docstores/in_memory.py
def save(self, path: Union[str, Path]):\n \"\"\"Save document to path\"\"\"\n store = {key: value.to_dict() for key, value in self._store.items()}\n with open(path, \"w\") as f:\n json.dump(store, f)\n
Source code in libs/kotaemon/kotaemon/storages/docstores/in_memory.py
def load(self, path: Union[str, Path]):\n \"\"\"Load document store from path\"\"\"\n with open(path) as f:\n store = json.load(f)\n # TODO: save and load aren't lossless. A Document-subclass will lose\n # information. Need to edit the `to_dict` and `from_dict` methods in\n # the Document class.\n # For better query support, utilize SQLite as the default document store.\n # Also, for portability, use SQLAlchemy for document store.\n self._store = {key: Document.from_dict(value) for key, value in store.items()}\n
Improve InMemoryDocumentStore by auto saving whenever the corpus is changed
Source code in libs/kotaemon/kotaemon/storages/docstores/simple_file.py
class SimpleFileDocumentStore(InMemoryDocumentStore):\n \"\"\"Improve InMemoryDocumentStore by auto saving whenever the corpus is changed\"\"\"\n\n def __init__(self, path: str | Path, collection_name: str = \"default\"):\n super().__init__()\n self._path = path\n self._collection_name = collection_name\n\n Path(path).mkdir(parents=True, exist_ok=True)\n self._save_path = Path(path) / f\"{collection_name}.json\"\n if self._save_path.is_file():\n self.load(self._save_path)\n\n def get(self, ids: Union[List[str], str]) -> List[Document]:\n \"\"\"Get document by id\"\"\"\n if not isinstance(ids, list):\n ids = [ids]\n\n for doc_id in ids:\n if doc_id not in self._store:\n self.load(self._save_path)\n break\n\n return [self._store[doc_id] for doc_id in ids]\n\n def add(\n self,\n docs: Union[Document, List[Document]],\n ids: Optional[Union[List[str], str]] = None,\n **kwargs,\n ):\n \"\"\"Add document into document store\n\n Args:\n docs: list of documents to add\n ids: specify the ids of documents to add or\n use existing doc.doc_id\n exist_ok: raise error when duplicate doc-id\n found in the docstore (default to False)\n \"\"\"\n super().add(docs=docs, ids=ids, **kwargs)\n self.save(self._save_path)\n\n def delete(self, ids: Union[List[str], str]):\n \"\"\"Delete document by id\"\"\"\n super().delete(ids=ids)\n self.save(self._save_path)\n\n def drop(self):\n \"\"\"Drop the document store\"\"\"\n super().drop()\n self._save_path.unlink(missing_ok=True)\n\n def __persist_flow__(self):\n from theflow.utils.modules import serialize\n\n return {\n \"path\": serialize(self._path),\n \"collection_name\": self._collection_name,\n }\n
Source code in libs/kotaemon/kotaemon/storages/docstores/simple_file.py
def get(self, ids: Union[List[str], str]) -> List[Document]:\n \"\"\"Get document by id\"\"\"\n if not isinstance(ids, list):\n ids = [ids]\n\n for doc_id in ids:\n if doc_id not in self._store:\n self.load(self._save_path)\n break\n\n return [self._store[doc_id] for doc_id in ids]\n
Name Type Description Default docsUnion[Document, List[Document]]
list of documents to add
required idsOptional[Union[List[str], str]]
specify the ids of documents to add or use existing doc.doc_id
Noneexist_ok
raise error when duplicate doc-id found in the docstore (default to False)
required Source code in libs/kotaemon/kotaemon/storages/docstores/simple_file.py
def add(\n self,\n docs: Union[Document, List[Document]],\n ids: Optional[Union[List[str], str]] = None,\n **kwargs,\n):\n \"\"\"Add document into document store\n\n Args:\n docs: list of documents to add\n ids: specify the ids of documents to add or\n use existing doc.doc_id\n exist_ok: raise error when duplicate doc-id\n found in the docstore (default to False)\n \"\"\"\n super().add(docs=docs, ids=ids, **kwargs)\n self.save(self._save_path)\n
A document store is in charged of storing and managing documents
Source code in libs/kotaemon/kotaemon/storages/docstores/base.py
class BaseDocumentStore(ABC):\n \"\"\"A document store is in charged of storing and managing documents\"\"\"\n\n @abstractmethod\n def __init__(self, *args, **kwargs):\n ...\n\n @abstractmethod\n def add(\n self,\n docs: Union[Document, List[Document]],\n ids: Optional[Union[List[str], str]] = None,\n **kwargs,\n ):\n \"\"\"Add document into document store\n\n Args:\n docs: Document or list of documents\n ids: List of ids of the documents. Optional, if not set will use doc.doc_id\n \"\"\"\n ...\n\n @abstractmethod\n def get(self, ids: Union[List[str], str]) -> List[Document]:\n \"\"\"Get document by id\"\"\"\n ...\n\n @abstractmethod\n def get_all(self) -> List[Document]:\n \"\"\"Get all documents\"\"\"\n ...\n\n @abstractmethod\n def count(self) -> int:\n \"\"\"Count number of documents\"\"\"\n ...\n\n @abstractmethod\n def query(\n self, query: str, top_k: int = 10, doc_ids: Optional[list] = None\n ) -> List[Document]:\n \"\"\"Search document store using search query\"\"\"\n ...\n\n @abstractmethod\n def delete(self, ids: Union[List[str], str]):\n \"\"\"Delete document by id\"\"\"\n ...\n\n @abstractmethod\n def drop(self):\n \"\"\"Drop the document store\"\"\"\n ...\n
Name Type Description Default docsUnion[Document, List[Document]]
Document or list of documents
required idsOptional[Union[List[str], str]]
List of ids of the documents. Optional, if not set will use doc.doc_id
None Source code in libs/kotaemon/kotaemon/storages/docstores/base.py
@abstractmethod\ndef add(\n self,\n docs: Union[Document, List[Document]],\n ids: Optional[Union[List[str], str]] = None,\n **kwargs,\n):\n \"\"\"Add document into document store\n\n Args:\n docs: Document or list of documents\n ids: List of ids of the documents. Optional, if not set will use doc.doc_id\n \"\"\"\n ...\n
Name Type Description Default docsUnion[Document, List[Document]]
list of documents to add
required idsOptional[Union[List[str], str]]
specify the ids of documents to add or use existing doc.doc_id
Nonerefresh_indicesbool
request Elasticsearch to update its index (default to True)
True Source code in libs/kotaemon/kotaemon/storages/docstores/elasticsearch.py
def add(\n self,\n docs: Union[Document, List[Document]],\n ids: Optional[Union[List[str], str]] = None,\n refresh_indices: bool = True,\n **kwargs,\n):\n \"\"\"Add document into document store\n\n Args:\n docs: list of documents to add\n ids: specify the ids of documents to add or use existing doc.doc_id\n refresh_indices: request Elasticsearch to update its index (default to True)\n \"\"\"\n if ids and not isinstance(ids, list):\n ids = [ids]\n if not isinstance(docs, list):\n docs = [docs]\n doc_ids = ids if ids else [doc.doc_id for doc in docs]\n\n requests = []\n for doc_id, doc in zip(doc_ids, docs):\n text = doc.text\n metadata = doc.metadata\n request = {\n \"_op_type\": \"index\",\n \"_index\": self.index_name,\n \"content\": text,\n \"metadata\": metadata,\n \"_id\": doc_id,\n }\n requests.append(request)\n\n success, failed = self.es_bulk(self.client, requests)\n print(\"Added/Updated documents to index\", success)\n print(\"Failed documents to index\", failed)\n\n if refresh_indices:\n self.client.indices.refresh(index=self.index_name)\n
Query Elasticsearch store using query format of ES client
Parameters:
Name Type Description Default querydict
Elasticsearch query format
required
Returns:
Type Description List[Document]
List[Document]: List of result documents
Source code in libs/kotaemon/kotaemon/storages/docstores/elasticsearch.py
def query_raw(self, query: dict) -> List[Document]:\n \"\"\"Query Elasticsearch store using query format of ES client\n\n Args:\n query (dict): Elasticsearch query format\n\n Returns:\n List[Document]: List of result documents\n \"\"\"\n res = self.client.search(index=self.index_name, body=query)\n docs = []\n for r in res[\"hits\"][\"hits\"]:\n docs.append(\n Document(\n id_=r[\"_id\"],\n text=r[\"_source\"][\"content\"],\n metadata=r[\"_source\"][\"metadata\"],\n )\n )\n return docs\n
Simple memory document store that store document in a dictionary
Source code in libs/kotaemon/kotaemon/storages/docstores/in_memory.py
class InMemoryDocumentStore(BaseDocumentStore):\n \"\"\"Simple memory document store that store document in a dictionary\"\"\"\n\n def __init__(self):\n self._store = {}\n\n def add(\n self,\n docs: Union[Document, List[Document]],\n ids: Optional[Union[List[str], str]] = None,\n **kwargs,\n ):\n \"\"\"Add document into document store\n\n Args:\n docs: list of documents to add\n ids: specify the ids of documents to add or\n use existing doc.doc_id\n exist_ok: raise error when duplicate doc-id\n found in the docstore (default to False)\n \"\"\"\n exist_ok: bool = kwargs.pop(\"exist_ok\", False)\n\n if ids and not isinstance(ids, list):\n ids = [ids]\n if not isinstance(docs, list):\n docs = [docs]\n doc_ids = ids if ids else [doc.doc_id for doc in docs]\n\n for doc_id, doc in zip(doc_ids, docs):\n if doc_id in self._store and not exist_ok:\n raise ValueError(f\"Document with id {doc_id} already exist\")\n self._store[doc_id] = doc\n\n def get(self, ids: Union[List[str], str]) -> List[Document]:\n \"\"\"Get document by id\"\"\"\n if not isinstance(ids, list):\n ids = [ids]\n\n return [self._store[doc_id] for doc_id in ids]\n\n def get_all(self) -> List[Document]:\n \"\"\"Get all documents\"\"\"\n return list(self._store.values())\n\n def count(self) -> int:\n \"\"\"Count number of documents\"\"\"\n return len(self._store)\n\n def delete(self, ids: Union[List[str], str]):\n \"\"\"Delete document by id\"\"\"\n if not isinstance(ids, list):\n ids = [ids]\n\n for doc_id in ids:\n del self._store[doc_id]\n\n def save(self, path: Union[str, Path]):\n \"\"\"Save document to path\"\"\"\n store = {key: value.to_dict() for key, value in self._store.items()}\n with open(path, \"w\") as f:\n json.dump(store, f)\n\n def load(self, path: Union[str, Path]):\n \"\"\"Load document store from path\"\"\"\n with open(path) as f:\n store = json.load(f)\n # TODO: save and load aren't lossless. A Document-subclass will lose\n # information. Need to edit the `to_dict` and `from_dict` methods in\n # the Document class.\n # For better query support, utilize SQLite as the default document store.\n # Also, for portability, use SQLAlchemy for document store.\n self._store = {key: Document.from_dict(value) for key, value in store.items()}\n\n def query(\n self, query: str, top_k: int = 10, doc_ids: Optional[list] = None\n ) -> List[Document]:\n \"\"\"Perform full-text search on document store\"\"\"\n return []\n\n def __persist_flow__(self):\n return {}\n\n def drop(self):\n \"\"\"Drop the document store\"\"\"\n self._store = {}\n
Name Type Description Default docsUnion[Document, List[Document]]
list of documents to add
required idsOptional[Union[List[str], str]]
specify the ids of documents to add or use existing doc.doc_id
Noneexist_ok
raise error when duplicate doc-id found in the docstore (default to False)
required Source code in libs/kotaemon/kotaemon/storages/docstores/in_memory.py
def add(\n self,\n docs: Union[Document, List[Document]],\n ids: Optional[Union[List[str], str]] = None,\n **kwargs,\n):\n \"\"\"Add document into document store\n\n Args:\n docs: list of documents to add\n ids: specify the ids of documents to add or\n use existing doc.doc_id\n exist_ok: raise error when duplicate doc-id\n found in the docstore (default to False)\n \"\"\"\n exist_ok: bool = kwargs.pop(\"exist_ok\", False)\n\n if ids and not isinstance(ids, list):\n ids = [ids]\n if not isinstance(docs, list):\n docs = [docs]\n doc_ids = ids if ids else [doc.doc_id for doc in docs]\n\n for doc_id, doc in zip(doc_ids, docs):\n if doc_id in self._store and not exist_ok:\n raise ValueError(f\"Document with id {doc_id} already exist\")\n self._store[doc_id] = doc\n
Source code in libs/kotaemon/kotaemon/storages/docstores/in_memory.py
def get(self, ids: Union[List[str], str]) -> List[Document]:\n \"\"\"Get document by id\"\"\"\n if not isinstance(ids, list):\n ids = [ids]\n\n return [self._store[doc_id] for doc_id in ids]\n
Source code in libs/kotaemon/kotaemon/storages/docstores/in_memory.py
def delete(self, ids: Union[List[str], str]):\n \"\"\"Delete document by id\"\"\"\n if not isinstance(ids, list):\n ids = [ids]\n\n for doc_id in ids:\n del self._store[doc_id]\n
Source code in libs/kotaemon/kotaemon/storages/docstores/in_memory.py
def save(self, path: Union[str, Path]):\n \"\"\"Save document to path\"\"\"\n store = {key: value.to_dict() for key, value in self._store.items()}\n with open(path, \"w\") as f:\n json.dump(store, f)\n
Source code in libs/kotaemon/kotaemon/storages/docstores/in_memory.py
def load(self, path: Union[str, Path]):\n \"\"\"Load document store from path\"\"\"\n with open(path) as f:\n store = json.load(f)\n # TODO: save and load aren't lossless. A Document-subclass will lose\n # information. Need to edit the `to_dict` and `from_dict` methods in\n # the Document class.\n # For better query support, utilize SQLite as the default document store.\n # Also, for portability, use SQLAlchemy for document store.\n self._store = {key: Document.from_dict(value) for key, value in store.items()}\n
Improve InMemoryDocumentStore by auto saving whenever the corpus is changed
Source code in libs/kotaemon/kotaemon/storages/docstores/simple_file.py
class SimpleFileDocumentStore(InMemoryDocumentStore):\n \"\"\"Improve InMemoryDocumentStore by auto saving whenever the corpus is changed\"\"\"\n\n def __init__(self, path: str | Path, collection_name: str = \"default\"):\n super().__init__()\n self._path = path\n self._collection_name = collection_name\n\n Path(path).mkdir(parents=True, exist_ok=True)\n self._save_path = Path(path) / f\"{collection_name}.json\"\n if self._save_path.is_file():\n self.load(self._save_path)\n\n def get(self, ids: Union[List[str], str]) -> List[Document]:\n \"\"\"Get document by id\"\"\"\n if not isinstance(ids, list):\n ids = [ids]\n\n for doc_id in ids:\n if doc_id not in self._store:\n self.load(self._save_path)\n break\n\n return [self._store[doc_id] for doc_id in ids]\n\n def add(\n self,\n docs: Union[Document, List[Document]],\n ids: Optional[Union[List[str], str]] = None,\n **kwargs,\n ):\n \"\"\"Add document into document store\n\n Args:\n docs: list of documents to add\n ids: specify the ids of documents to add or\n use existing doc.doc_id\n exist_ok: raise error when duplicate doc-id\n found in the docstore (default to False)\n \"\"\"\n super().add(docs=docs, ids=ids, **kwargs)\n self.save(self._save_path)\n\n def delete(self, ids: Union[List[str], str]):\n \"\"\"Delete document by id\"\"\"\n super().delete(ids=ids)\n self.save(self._save_path)\n\n def drop(self):\n \"\"\"Drop the document store\"\"\"\n super().drop()\n self._save_path.unlink(missing_ok=True)\n\n def __persist_flow__(self):\n from theflow.utils.modules import serialize\n\n return {\n \"path\": serialize(self._path),\n \"collection_name\": self._collection_name,\n }\n
Source code in libs/kotaemon/kotaemon/storages/docstores/simple_file.py
def get(self, ids: Union[List[str], str]) -> List[Document]:\n \"\"\"Get document by id\"\"\"\n if not isinstance(ids, list):\n ids = [ids]\n\n for doc_id in ids:\n if doc_id not in self._store:\n self.load(self._save_path)\n break\n\n return [self._store[doc_id] for doc_id in ids]\n
Name Type Description Default docsUnion[Document, List[Document]]
list of documents to add
required idsOptional[Union[List[str], str]]
specify the ids of documents to add or use existing doc.doc_id
Noneexist_ok
raise error when duplicate doc-id found in the docstore (default to False)
required Source code in libs/kotaemon/kotaemon/storages/docstores/simple_file.py
def add(\n self,\n docs: Union[Document, List[Document]],\n ids: Optional[Union[List[str], str]] = None,\n **kwargs,\n):\n \"\"\"Add document into document store\n\n Args:\n docs: list of documents to add\n ids: specify the ids of documents to add or\n use existing doc.doc_id\n exist_ok: raise error when duplicate doc-id\n found in the docstore (default to False)\n \"\"\"\n super().add(docs=docs, ids=ids, **kwargs)\n self.save(self._save_path)\n
Source code in libs/kotaemon/kotaemon/storages/vectorstores/base.py
class BaseVectorStore(ABC):\n @abstractmethod\n def __init__(self, *args, **kwargs):\n ...\n\n @abstractmethod\n def add(\n self,\n embeddings: list[list[float]] | list[DocumentWithEmbedding],\n metadatas: Optional[list[dict]] = None,\n ids: Optional[list[str]] = None,\n ) -> list[str]:\n \"\"\"Add vector embeddings to vector stores\n\n Args:\n embeddings: List of embeddings\n metadatas: List of metadata of the embeddings\n ids: List of ids of the embeddings\n kwargs: meant for vectorstore-specific parameters\n\n Returns:\n List of ids of the embeddings\n \"\"\"\n ...\n\n @abstractmethod\n def delete(self, ids: list[str], **kwargs):\n \"\"\"Delete vector embeddings from vector stores\n\n Args:\n ids: List of ids of the embeddings to be deleted\n kwargs: meant for vectorstore-specific parameters\n \"\"\"\n ...\n\n @abstractmethod\n def query(\n self,\n embedding: list[float],\n top_k: int = 1,\n ids: Optional[list[str]] = None,\n **kwargs,\n ) -> tuple[list[list[float]], list[float], list[str]]:\n \"\"\"Return the top k most similar vector embeddings\n\n Args:\n embedding: List of embeddings\n top_k: Number of most similar embeddings to return\n ids: List of ids of the embeddings to be queried\n\n Returns:\n the matched embeddings, the similarity scores, and the ids\n \"\"\"\n ...\n\n @abstractmethod\n def drop(self):\n \"\"\"Drop the vector store\"\"\"\n ...\n
Name Type Description Default embeddingslist[list[float]] | list[DocumentWithEmbedding]
List of embeddings
required metadatasOptional[list[dict]]
List of metadata of the embeddings
NoneidsOptional[list[str]]
List of ids of the embeddings
Nonekwargs
meant for vectorstore-specific parameters
required
Returns:
Type Description list[str]
List of ids of the embeddings
Source code in libs/kotaemon/kotaemon/storages/vectorstores/base.py
@abstractmethod\ndef add(\n self,\n embeddings: list[list[float]] | list[DocumentWithEmbedding],\n metadatas: Optional[list[dict]] = None,\n ids: Optional[list[str]] = None,\n) -> list[str]:\n \"\"\"Add vector embeddings to vector stores\n\n Args:\n embeddings: List of embeddings\n metadatas: List of metadata of the embeddings\n ids: List of ids of the embeddings\n kwargs: meant for vectorstore-specific parameters\n\n Returns:\n List of ids of the embeddings\n \"\"\"\n ...\n
{} Source code in libs/kotaemon/kotaemon/storages/vectorstores/base.py
@abstractmethod\ndef delete(self, ids: list[str], **kwargs):\n \"\"\"Delete vector embeddings from vector stores\n\n Args:\n ids: List of ids of the embeddings to be deleted\n kwargs: meant for vectorstore-specific parameters\n \"\"\"\n ...\n
Name Type Description Default embeddinglist[float]
List of embeddings
required top_kint
Number of most similar embeddings to return
1idsOptional[list[str]]
List of ids of the embeddings to be queried
None
Returns:
Type Description tuple[list[list[float]], list[float], list[str]]
the matched embeddings, the similarity scores, and the ids
Source code in libs/kotaemon/kotaemon/storages/vectorstores/base.py
@abstractmethod\ndef query(\n self,\n embedding: list[float],\n top_k: int = 1,\n ids: Optional[list[str]] = None,\n **kwargs,\n) -> tuple[list[list[float]], list[float], list[str]]:\n \"\"\"Return the top k most similar vector embeddings\n\n Args:\n embedding: List of embeddings\n top_k: Number of most similar embeddings to return\n ids: List of ids of the embeddings to be queried\n\n Returns:\n the matched embeddings, the similarity scores, and the ids\n \"\"\"\n ...\n
{} Source code in libs/kotaemon/kotaemon/storages/vectorstores/chroma.py
def delete(self, ids: List[str], **kwargs):\n \"\"\"Delete vector embeddings from vector stores\n\n Args:\n ids: List of ids of the embeddings to be deleted\n kwargs: meant for vectorstore-specific parameters\n \"\"\"\n self._client.client.delete(ids=ids)\n
None Source code in libs/kotaemon/kotaemon/storages/vectorstores/in_memory.py
def save(\n self,\n save_path: str,\n fs: Optional[fsspec.AbstractFileSystem] = None,\n **kwargs,\n):\n\n \"\"\"save a simpleVectorStore to a dictionary.\n\n Args:\n save_path: Path of saving vector to disk.\n fs: An abstract super-class for pythonic file-systems\n \"\"\"\n self._client.persist(persist_path=save_path, fs=fs)\n
{} Source code in libs/kotaemon/kotaemon/storages/vectorstores/lancedb.py
def delete(self, ids: List[str], **kwargs):\n \"\"\"Delete vector embeddings from vector stores\n\n Args:\n ids: List of ids of the embeddings to be deleted\n kwargs: meant for vectorstore-specific parameters\n \"\"\"\n self._client.delete_nodes(ids)\n
{} Source code in libs/kotaemon/kotaemon/storages/vectorstores/qdrant.py
def delete(self, ids: List[str], **kwargs):\n \"\"\"Delete vector embeddings from vector stores\n\n Args:\n ids: List of ids of the embeddings to be deleted\n kwargs: meant for vectorstore-specific parameters\n \"\"\"\n from qdrant_client import models\n\n self._client.client.delete(\n collection_name=self._collection_name,\n points_selector=models.PointIdsList(\n points=ids,\n ),\n **kwargs,\n )\n
Source code in libs/kotaemon/kotaemon/storages/vectorstores/base.py
class BaseVectorStore(ABC):\n @abstractmethod\n def __init__(self, *args, **kwargs):\n ...\n\n @abstractmethod\n def add(\n self,\n embeddings: list[list[float]] | list[DocumentWithEmbedding],\n metadatas: Optional[list[dict]] = None,\n ids: Optional[list[str]] = None,\n ) -> list[str]:\n \"\"\"Add vector embeddings to vector stores\n\n Args:\n embeddings: List of embeddings\n metadatas: List of metadata of the embeddings\n ids: List of ids of the embeddings\n kwargs: meant for vectorstore-specific parameters\n\n Returns:\n List of ids of the embeddings\n \"\"\"\n ...\n\n @abstractmethod\n def delete(self, ids: list[str], **kwargs):\n \"\"\"Delete vector embeddings from vector stores\n\n Args:\n ids: List of ids of the embeddings to be deleted\n kwargs: meant for vectorstore-specific parameters\n \"\"\"\n ...\n\n @abstractmethod\n def query(\n self,\n embedding: list[float],\n top_k: int = 1,\n ids: Optional[list[str]] = None,\n **kwargs,\n ) -> tuple[list[list[float]], list[float], list[str]]:\n \"\"\"Return the top k most similar vector embeddings\n\n Args:\n embedding: List of embeddings\n top_k: Number of most similar embeddings to return\n ids: List of ids of the embeddings to be queried\n\n Returns:\n the matched embeddings, the similarity scores, and the ids\n \"\"\"\n ...\n\n @abstractmethod\n def drop(self):\n \"\"\"Drop the vector store\"\"\"\n ...\n
Name Type Description Default embeddingslist[list[float]] | list[DocumentWithEmbedding]
List of embeddings
required metadatasOptional[list[dict]]
List of metadata of the embeddings
NoneidsOptional[list[str]]
List of ids of the embeddings
Nonekwargs
meant for vectorstore-specific parameters
required
Returns:
Type Description list[str]
List of ids of the embeddings
Source code in libs/kotaemon/kotaemon/storages/vectorstores/base.py
@abstractmethod\ndef add(\n self,\n embeddings: list[list[float]] | list[DocumentWithEmbedding],\n metadatas: Optional[list[dict]] = None,\n ids: Optional[list[str]] = None,\n) -> list[str]:\n \"\"\"Add vector embeddings to vector stores\n\n Args:\n embeddings: List of embeddings\n metadatas: List of metadata of the embeddings\n ids: List of ids of the embeddings\n kwargs: meant for vectorstore-specific parameters\n\n Returns:\n List of ids of the embeddings\n \"\"\"\n ...\n
{} Source code in libs/kotaemon/kotaemon/storages/vectorstores/base.py
@abstractmethod\ndef delete(self, ids: list[str], **kwargs):\n \"\"\"Delete vector embeddings from vector stores\n\n Args:\n ids: List of ids of the embeddings to be deleted\n kwargs: meant for vectorstore-specific parameters\n \"\"\"\n ...\n
Name Type Description Default embeddinglist[float]
List of embeddings
required top_kint
Number of most similar embeddings to return
1idsOptional[list[str]]
List of ids of the embeddings to be queried
None
Returns:
Type Description tuple[list[list[float]], list[float], list[str]]
the matched embeddings, the similarity scores, and the ids
Source code in libs/kotaemon/kotaemon/storages/vectorstores/base.py
@abstractmethod\ndef query(\n self,\n embedding: list[float],\n top_k: int = 1,\n ids: Optional[list[str]] = None,\n **kwargs,\n) -> tuple[list[list[float]], list[float], list[str]]:\n \"\"\"Return the top k most similar vector embeddings\n\n Args:\n embedding: List of embeddings\n top_k: Number of most similar embeddings to return\n ids: List of ids of the embeddings to be queried\n\n Returns:\n the matched embeddings, the similarity scores, and the ids\n \"\"\"\n ...\n
Source code in libs/kotaemon/kotaemon/storages/vectorstores/base.py
class LlamaIndexVectorStore(BaseVectorStore):\n \"\"\"Mixin for LlamaIndex based vectorstores\"\"\"\n\n _li_class: type[LIVectorStore | BasePydanticVectorStore] | None\n\n def _get_li_class(self):\n raise NotImplementedError(\n \"Please return the relevant LlamaIndex class in in _get_li_class\"\n )\n\n def __init__(self, *args, **kwargs):\n # get li_class from the method if not set\n if not self._li_class:\n LIClass = self._get_li_class()\n else:\n LIClass = self._li_class\n\n from dataclasses import fields\n\n self._client = LIClass(*args, **kwargs)\n\n self._vsq_kwargs = {_.name for _ in fields(VectorStoreQuery)}\n for key in [\"query_embedding\", \"similarity_top_k\", \"node_ids\"]:\n if key in self._vsq_kwargs:\n self._vsq_kwargs.remove(key)\n\n def __setattr__(self, name: str, value: Any) -> None:\n if name.startswith(\"_\"):\n return super().__setattr__(name, value)\n\n return setattr(self._client, name, value)\n\n def __getattr__(self, name: str) -> Any:\n if name == \"_li_class\":\n return super().__getattribute__(name)\n\n return getattr(self._client, name)\n\n def add(\n self,\n embeddings: list[list[float]] | list[DocumentWithEmbedding],\n metadatas: Optional[list[dict]] = None,\n ids: Optional[list[str]] = None,\n ):\n if isinstance(embeddings[0], list):\n nodes: list[DocumentWithEmbedding] = [\n DocumentWithEmbedding(embedding=embedding) for embedding in embeddings\n ]\n else:\n nodes = embeddings # type: ignore\n if metadatas is not None:\n for node, metadata in zip(nodes, metadatas):\n node.metadata = metadata\n if ids is not None:\n for node, id in zip(nodes, ids):\n node.id_ = id\n node.relationships = {\n NodeRelationship.SOURCE: RelatedNodeInfo(node_id=id)\n }\n\n return self._client.add(nodes=nodes)\n\n def delete(self, ids: list[str], **kwargs):\n for id_ in ids:\n self._client.delete(ref_doc_id=id_, **kwargs)\n\n def query(\n self,\n embedding: list[float],\n top_k: int = 1,\n ids: Optional[list[str]] = None,\n **kwargs,\n ) -> tuple[list[list[float]], list[float], list[str]]:\n \"\"\"Return the top k most similar vector embeddings\n\n Args:\n embedding: List of embeddings\n top_k: Number of most similar embeddings to return\n ids: List of ids of the embeddings to be queried\n kwargs: extra query parameters. Depending on the name, these parameters\n will be used when constructing the VectorStoreQuery object or when\n performing querying of the underlying vector store.\n\n Returns:\n the matched embeddings, the similarity scores, and the ids\n \"\"\"\n vsq_kwargs = {}\n vs_kwargs = {}\n for kwkey, kwvalue in kwargs.items():\n if kwkey in self._vsq_kwargs:\n vsq_kwargs[kwkey] = kwvalue\n else:\n vs_kwargs[kwkey] = kwvalue\n\n output = self._client.query(\n query=VectorStoreQuery(\n query_embedding=embedding,\n similarity_top_k=top_k,\n node_ids=ids,\n **vsq_kwargs,\n ),\n **vs_kwargs,\n )\n\n embeddings = []\n if output.nodes:\n for node in output.nodes:\n embeddings.append(node.embedding)\n similarities = output.similarities if output.similarities else []\n out_ids = output.ids if output.ids else []\n\n return embeddings, similarities, out_ids\n
Name Type Description Default embeddinglist[float]
List of embeddings
required top_kint
Number of most similar embeddings to return
1idsOptional[list[str]]
List of ids of the embeddings to be queried
Nonekwargs
extra query parameters. Depending on the name, these parameters will be used when constructing the VectorStoreQuery object or when performing querying of the underlying vector store.
{}
Returns:
Type Description tuple[list[list[float]], list[float], list[str]]
the matched embeddings, the similarity scores, and the ids
Source code in libs/kotaemon/kotaemon/storages/vectorstores/base.py
def query(\n self,\n embedding: list[float],\n top_k: int = 1,\n ids: Optional[list[str]] = None,\n **kwargs,\n) -> tuple[list[list[float]], list[float], list[str]]:\n \"\"\"Return the top k most similar vector embeddings\n\n Args:\n embedding: List of embeddings\n top_k: Number of most similar embeddings to return\n ids: List of ids of the embeddings to be queried\n kwargs: extra query parameters. Depending on the name, these parameters\n will be used when constructing the VectorStoreQuery object or when\n performing querying of the underlying vector store.\n\n Returns:\n the matched embeddings, the similarity scores, and the ids\n \"\"\"\n vsq_kwargs = {}\n vs_kwargs = {}\n for kwkey, kwvalue in kwargs.items():\n if kwkey in self._vsq_kwargs:\n vsq_kwargs[kwkey] = kwvalue\n else:\n vs_kwargs[kwkey] = kwvalue\n\n output = self._client.query(\n query=VectorStoreQuery(\n query_embedding=embedding,\n similarity_top_k=top_k,\n node_ids=ids,\n **vsq_kwargs,\n ),\n **vs_kwargs,\n )\n\n embeddings = []\n if output.nodes:\n for node in output.nodes:\n embeddings.append(node.embedding)\n similarities = output.similarities if output.similarities else []\n out_ids = output.ids if output.ids else []\n\n return embeddings, similarities, out_ids\n
{} Source code in libs/kotaemon/kotaemon/storages/vectorstores/chroma.py
def delete(self, ids: List[str], **kwargs):\n \"\"\"Delete vector embeddings from vector stores\n\n Args:\n ids: List of ids of the embeddings to be deleted\n kwargs: meant for vectorstore-specific parameters\n \"\"\"\n self._client.client.delete(ids=ids)\n
None Source code in libs/kotaemon/kotaemon/storages/vectorstores/in_memory.py
def save(\n self,\n save_path: str,\n fs: Optional[fsspec.AbstractFileSystem] = None,\n **kwargs,\n):\n\n \"\"\"save a simpleVectorStore to a dictionary.\n\n Args:\n save_path: Path of saving vector to disk.\n fs: An abstract super-class for pythonic file-systems\n \"\"\"\n self._client.persist(persist_path=save_path, fs=fs)\n
{} Source code in libs/kotaemon/kotaemon/storages/vectorstores/lancedb.py
def delete(self, ids: List[str], **kwargs):\n \"\"\"Delete vector embeddings from vector stores\n\n Args:\n ids: List of ids of the embeddings to be deleted\n kwargs: meant for vectorstore-specific parameters\n \"\"\"\n self._client.delete_nodes(ids)\n
{} Source code in libs/kotaemon/kotaemon/storages/vectorstores/qdrant.py
def delete(self, ids: List[str], **kwargs):\n \"\"\"Delete vector embeddings from vector stores\n\n Args:\n ids: List of ids of the embeddings to be deleted\n kwargs: meant for vectorstore-specific parameters\n \"\"\"\n from qdrant_client import models\n\n self._client.client.delete(\n collection_name=self._collection_name,\n points_selector=models.PointIdsList(\n points=ids,\n ),\n **kwargs,\n )\n
"}]}
\ No newline at end of file
+{"config":{"lang":["en"],"separator":"[\\s\\-]+","pipeline":["stopWordFilter"]},"docs":[{"location":"","title":"Quick Start","text":""},{"location":"#getting-started-with-kotaemon","title":"Getting Started with Kotaemon","text":"
This page is intended for end users who want to use the kotaemon tool for Question Answering on local documents. If you are a developer who wants contribute to the project, please visit the development page.
An open-source tool for chatting with your documents. Built with both end users and developers in mind.
Source Code | Live Demo
User Guide | Developer Guide | Feedback
Dark Mode | Light Mode
"},{"location":"local_model/","title":"Setup local LLMs & Embedding models","text":""},{"location":"local_model/#setup-local-llms-embedding-models","title":"Setup local LLMs & Embedding models","text":""},{"location":"local_model/#prepare-local-models","title":"Prepare local models","text":""},{"location":"local_model/#note","title":"NOTE","text":"
In the case of using Docker image, please replace http://localhost with http://host.docker.internal to correctly communicate with service on the host machine. See more detail.
"},{"location":"local_model/#ollama-openai-compatible-server-recommended","title":"Ollama OpenAI compatible server (recommended)","text":"
"},{"location":"local_model/#use-local-models-for-rag","title":"Use local models for RAG","text":"
Set default LLM and Embedding model to a local variant.
Set embedding model for the File Collection to a local model (e.g: ollama)
Go to Retrieval settings and choose LLM relevant scoring model as a local model (e.g: ollama). Or, you can choose to disable this feature if your machine cannot handle a lot of parallel LLM requests at the same time.
You are set! Start a new conversation to test your local RAG pipeline.
Wait for the build to complete and start up (apprx 10 mins).
Follow the first setup instructions (and register for Cohere API key if needed)\\
Complete the setup and use your own private space!
"},{"location":"usage/","title":"Basic Usage","text":""},{"location":"usage/#1-add-your-ai-models","title":"1. Add your AI models","text":"
The tool uses Large Language Model (LLMs) to perform various tasks in a QA pipeline. So, you need to provide the application with access to the LLMs you want to use.
You only need to provide at least one. However, tt is recommended that you include all the LLMs that you have access to, you will be able to switch between them while using the application.
To add a model:
Navigate to the Resources tab.
Select the LLMs sub-tab.
Select the Add sub-tab.
Config the model to add:
Give it a name.
Pick a vendor/provider (e.g. ChatOpenAI).
Provide the specifications.
(Optional) Set the model as default.
Click Add to add the model.
Select Embedding Models sub-tab and repeat the step 3 to 5 to add an embedding model.
(Optional) Configure model via the .env file
Alternatively, you can configure the models via the .env file with the information needed to connect to the LLMs. This file is located in the folder of the application. If you don't see it, you can create one.
In the .env file, set the OPENAI_API_KEY variable with your OpenAI API key in order to enable access to OpenAI's models. There are other variables that can be modified, please feel free to edit them to fit your case. Otherwise, the default parameter should work for most people.
OPENAI_API_BASE=https://api.openai.com/v1\nOPENAI_API_KEY=<your OpenAI API key here>\nOPENAI_CHAT_MODEL=gpt-3.5-turbo\nOPENAI_EMBEDDINGS_MODEL=text-embedding-ada-002\n
For OpenAI models via Azure platform, you need to provide your Azure endpoint and API key. Your might also need to provide your developments' name for the chat model and the embedding model depending on how you set up Azure development.
AZURE_OPENAI_ENDPOINT=\nAZURE_OPENAI_API_KEY=\nOPENAI_API_VERSION=2024-02-15-preview # could be different for you\nAZURE_OPENAI_CHAT_DEPLOYMENT=gpt-35-turbo # change to your deployment name\nAZURE_OPENAI_EMBEDDINGS_DEPLOYMENT=text-embedding-ada-002 # change to your deployment name\n
Privacy. Your documents will be stored and process locally.
Choices. There are a wide range of LLMs in terms of size, domain, language to choose from.
Cost. It's free.
Cons:
Quality. Local models are much smaller and thus have lower generative quality than paid APIs.
Speed. Local models are deployed using your machine so the processing speed is limited by your hardware.
"},{"location":"usage/#find-and-download-a-llm","title":"Find and download a LLM","text":"
You can search and download a LLM to be ran locally from the Hugging Face Hub. Currently, these model formats are supported:
GGUF
You should choose a model whose size is less than your device's memory and should leave about 2 GB. For example, if you have 16 GB of RAM in total, of which 12 GB is available, then you should choose a model that take up at most 10 GB of RAM. Bigger models tend to give better generation but also take more processing time.
Here are some recommendations and their size in memory:
Qwen1.5-1.8B-Chat-GGUF: around 2 GB
"},{"location":"usage/#enable-local-models","title":"Enable local models","text":"
To add a local model to the model pool, set the LOCAL_MODEL variable in the .env file to the path of the model file.
LOCAL_MODEL=<full path to your model file>\n
Here is how to get the full path of your model file:
On Windows 11: right click the file and select Copy as Path.
"},{"location":"usage/#2-upload-your-documents","title":"2. Upload your documents","text":"
In order to do QA on your documents, you need to upload them to the application first. Navigate to the File Index tab and you will see 2 sections:
File upload:
Drag and drop your file to the UI or select it from your file system. Then click Upload and Index.
The application will take some time to process the file and show a message once it is done.
File list:
This section shows the list of files that have been uploaded to the application and allows users to delete them.
"},{"location":"usage/#3-chat-with-your-documents","title":"3. Chat with your documents","text":"
Now navigate back to the Chat tab. The chat tab is divided into 3 regions:
Conversation Settings Panel
Here you can select, create, rename, and delete conversations.
By default, a new conversation is created automatically if no conversation is selected.
Below that you have the file index, where you can choose whether to disable, select all files, or select which files to retrieve references from.
If you choose \"Disabled\", no files will be considered as context during chat.
If you choose \"Search All\", all files will be considered during chat.
If you choose \"Select\", a dropdown will appear for you to select the files to be considered during chat. If no files are selected, then no files will be considered during chat.
Chat Panel
This is where you can chat with the chatbot.
Information Panel
Supporting information such as the retrieved evidence and reference will be displayed here.
Direct citation for the answer produced by the LLM is highlighted.
The confidence score of the answer and relevant scores of evidences are displayed to quickly assess the quality of the answer and retrieved content.
Meaning of the score displayed:
Answer confidence: answer confidence level from the LLM model.
Relevance score: overall relevant score between evidence and user question.
Vectorstore score: relevant score from vector embedding similarity calculation (show full-text search if retrieved from full-text search DB).
LLM relevant score: relevant score from LLM model (which judge relevancy between question and evidence using specific prompt).
Reranking score: relevant score from Cohere reranking model.
Generally, the score quality is LLM relevant score > Reranking score > Vectorscore. By default, overall relevance score is taken directly from LLM relevant score. Evidences are sorted based on their overall relevance score and whether they have citation or not.
This project serves as a functional RAG UI for both end users who want to do QA on their documents and developers who want to build their own RAG pipeline.
For end users:
A clean & minimalistic UI for RAG-based QA.
Supports LLM API providers (OpenAI, AzureOpenAI, Cohere, etc) and local LLMs (via ollama and llama-cpp-python).
Easy installation scripts.
For developers:
A framework for building your own RAG-based document QA pipeline.
Customize and see your RAG pipeline in action with the provided UI (built with Gradio ).
If you use Gradio for development, check out our theme here: kotaemon-gradio-theme.
+----------------------------------------------------------------------------+\n| End users: Those who use apps built with `kotaemon`. |\n| (You use an app like the one in the demo above) |\n| +----------------------------------------------------------------+ |\n| | Developers: Those who built with `kotaemon`. | |\n| | (You have `import kotaemon` somewhere in your project) | |\n| | +----------------------------------------------------+ | |\n| | | Contributors: Those who make `kotaemon` better. | | |\n| | | (You make PR to this repo) | | |\n| | +----------------------------------------------------+ | |\n| +----------------------------------------------------------------+ |\n+----------------------------------------------------------------------------+\n
This repository is under active development. Feedback, issues, and PRs are highly appreciated.
Host your own document QA (RAG) web-UI. Support multi-user login, organize your files in private / public collections, collaborate and share your favorite chat with others.
Organize your LLM & Embedding models. Support both local LLMs & popular API providers (OpenAI, Azure, Ollama, Groq).
Hybrid RAG pipeline. Sane default RAG pipeline with hybrid (full-text & vector) retriever + re-ranking to ensure best retrieval quality.
Multi-modal QA support. Perform Question Answering on multiple documents with figures & tables support. Support multi-modal document parsing (selectable options on UI).
Advance citations with document preview. By default the system will provide detailed citations to ensure the correctness of LLM answers. View your citations (incl. relevant score) directly in the in-browser PDF viewer with highlights. Warning when retrieval pipeline return low relevant articles.
Support complex reasoning methods. Use question decomposition to answer your complex / multi-hop question. Support agent-based reasoning with ReAct, ReWOO and other agents.
Configurable settings UI. You can adjust most important aspects of retrieval & generation process on the UI (incl. prompts).
Extensible. Being built on Gradio, you are free to customize / add any UI elements as you like. Also, we aim to support multiple strategies for document indexing & retrieval. GraphRAG indexing pipeline is provided as an example.
"},{"location":"development/#installation","title":"Installation","text":""},{"location":"development/#for-end-users","title":"For end users","text":"
This document is intended for developers. If you just want to install and use the app as it is, please follow the non-technical User Guide. Use the most recent release .zip to include latest features and bug-fixes.
We support lite & full version of Docker images. With full, the extra packages of unstructured will be installed as well, it can support additional file types (.doc, .docx, ...) but the cost is larger docker image size. For most users, the lite image should work well in most cases.
Currently, two platforms: linux/amd64 and linux/arm64 (for newer Mac) are provided & tested. User can specify the platform by passing --platform in the docker run command. For example:
# To run docker with platform linux/arm64\ndocker run \\\n-e GRADIO_SERVER_NAME=0.0.0.0 \\\n-e GRADIO_SERVER_PORT=7860 \\\n-p 7860:7860 -it --rm \\\n--platform linux/arm64 \\\nghcr.io/cinnamon/kotaemon:main-lite\n
If everything is set up fine, navigate to http://localhost:7860/ to access the web UI.
We use GHCR to store docker images, all images can be found here.
This file provides another way to configure your models and credentials.
Configure model via the .env file
Alternatively, you can configure the models via the .env file with the information needed to connect to the LLMs. This file is located in the folder of the application. If you don't see it, you can create one.
In the .env file, set the OPENAI_API_KEY variable with your OpenAI API key in order to enable access to OpenAI's models. There are other variables that can be modified, please feel free to edit them to fit your case. Otherwise, the default parameter should work for most people.
OPENAI_API_BASE=https://api.openai.com/v1\nOPENAI_API_KEY=<your OpenAI API key here>\nOPENAI_CHAT_MODEL=gpt-3.5-turbo\nOPENAI_EMBEDDINGS_MODEL=text-embedding-ada-002\n
For OpenAI models via Azure platform, you need to provide your Azure endpoint and API key. Your might also need to provide your developments' name for the chat model and the embedding model depending on how you set up Azure development.
Set the model names on web UI and make it as default.
"},{"location":"development/#using-gguf-with-llama-cpp-python","title":"Using GGUF with llama-cpp-python","text":"
You can search and download a LLM to be ran locally from the Hugging Face Hub. Currently, these model formats are supported:
GGUF
You should choose a model whose size is less than your device's memory and should leave about 2 GB. For example, if you have 16 GB of RAM in total, of which 12 GB is available, then you should choose a model that takes up at most 10 GB of RAM. Bigger models tend to give better generation but also take more processing time.
Here are some recommendations and their size in memory:
Qwen1.5-1.8B-Chat-GGUF: around 2 GB
Add a new LlamaCpp model with the provided model name on the web uI.
"},{"location":"development/#adding-your-own-rag-pipeline","title":"Adding your own RAG pipeline","text":""},{"location":"development/#custom-reasoning-pipeline","title":"Custom reasoning pipeline","text":"
First, check the default pipeline implementation in here. You can make quick adjustment to how the default QA pipeline work.
Next, if you feel comfortable adding new pipeline, add new .py implementation in libs/ktem/ktem/reasoning/ and later include it in flowssettings to enable it on the UI.
Or run the installer (one of the scripts/run_* scripts depends on your OS), then you will have all the dependencies installed as a conda environment at install_dir/env.
kotaemon library focuses on the AI building blocks to implement a RAG-based QA application. It consists of base interfaces, core components and a list of utilities:
Base interfaces: kotaemon defines the base interface of a component in a pipeline. A pipeline is also a component. By clearly define this interface, a pipeline of steps can be easily constructed and orchestrated.
Core components: kotaemon implements (or wraps 3rd-party libraries like Langchain, llama-index,... when possible) commonly used components in kotaemon use cases. Some of these components are: LLM, vector store, document store, retriever... For a detailed list and description of these components, please refer to the API Reference section.
List of utilities: kotaemon provides utilities and tools that are usually needed in client project. For example, it provides a prompt engineering UI for AI developers in a project to quickly create a prompt engineering tool for DMs and QALs. It also provides a command to quickly spin up a project code base. For a full list and description of these utilities, please refer to the Utilities section.
[Encouraged] Provide a quick description in the PR, so that:
Reviewers can quickly understand the direction of the PR.
It will be included in the commit message when the PR is merged.
"},{"location":"development/contributing/#environment-caching-on-pr","title":"Environment caching on PR","text":"
To speed up CI, environments are cached based on the version specified in __init__.py.
Since dependencies versions in setup.py are not pinned, you need to pump the version in order to use a new environment. That environment will then be cached and used by your subsequence commits within the PR, until you pump the version again
The new environment created during your PR is cached and will be available to others once the PR is merged.
If you are experimenting with new dependencies and want a fresh environment every time, add [ignore cache] in your commit message. The CI will create a fresh environment to run your commit and then discard it.
If your PR include updated dependencies, the recommended workflow would be:
Doing development as usual.
When you want to run the CI, push a commit with the message containing [ignore cache].
Once the PR is final, pump the version in __init__.py and push a final commit not containing [ignore cache].
"},{"location":"development/create-a-component/","title":"Creating a Component","text":""},{"location":"development/create-a-component/#creating-a-component","title":"Creating a component","text":"
A fundamental concept in kotaemon is \"component\".
Anything that isn't data or data structure is a \"component\". A component can be thought of as a step within a pipeline. It takes in some input, processes it, and returns an output, just the same as a Python function! The output will then become an input for the next component in a pipeline. In fact, a pipeline is just a component. More appropriately, a nested component: a component that makes use of one or more other components in the processing step. So in reality, there isn't a difference between a pipeline and a component! Because of that, in kotaemon, we will consider them the same as \"component\".
To define a component, you will:
Create a class that subclasses from kotaemon.base.BaseComponent
Declare init params with type annotation
Declare nodes (nodes are just other components!) with type annotation
Implement the processing logic in run.
The syntax of a component is as follow:
from kotaemon.base import BaseComponent\nfrom kotaemon.llms import LCAzureChatOpenAI\nfrom kotaemon.parsers import RegexExtractor\n\n\nclass FancyPipeline(BaseComponent):\n param1: str = \"This is param1\"\n param2: int = 10\n param3: float\n\n node1: BaseComponent # this is a node because of BaseComponent type annotation\n node2: LCAzureChatOpenAI # this is also a node because LCAzureChatOpenAI subclasses BaseComponent\n node3: RegexExtractor # this is also a node bceause RegexExtractor subclasses BaseComponent\n\n def run(self, some_text: str):\n prompt = (self.param1 + some_text) * int(self.param2 + self.param3)\n llm_pred = self.node2(prompt).text\n matches = self.node3(llm_pred)\n return matches\n
This way, we can define each operation as a reusable component, and use them to compose larger reusable components!
"},{"location":"development/create-a-component/#benefits-of-component","title":"Benefits of component","text":"
By defining a component as above, we formally encapsulate all the necessary information inside a single class. This introduces several benefits:
Allow tools like promptui to inspect the inner working of a component in order to automatically generate the promptui.
Allow visualizing a pipeline for debugging purpose.
"},{"location":"development/data-components/","title":"Data & Data Structure Components","text":""},{"location":"development/data-components/#data-data-structure-components","title":"Data & Data Structure Components","text":"
MathPixLoader: To use this loader, you need MathPix API key, refer to mathpix docs for more information
OCRLoader: This loader uses lib-table and Flax pipeline to perform OCR and read table structure from PDF file (TODO: add more info about deployment of this module).
Output:
Document: text + metadata to identify whether it is table or not
- \"source\": source file name\n- \"type\": \"table\" or \"text\"\n- \"table_origin\": original table in markdown format (to be feed to LLM or visualize using external tools)\n- \"page_label\": page number in the original PDF document\n
Important: despite the name prompt engineering UI, this tool allows testers to test any kind of parameters that are exposed by developers. Prompt is one kind of param. There can be other type of params that testers can tweak (e.g. top_k, temperature...).
In the development process, developers typically build the pipeline. However, for use cases requiring expertise in prompt creation, non-technical members (testers, domain experts) can be more effective. To facilitate this, kotaemon offers a user-friendly prompt engineering UI that developers integrate into their pipelines. This enables non-technical members to adjust prompts and parameters, run experiments, and export results for optimization.
As of Sept 2023, there are 2 kinds of prompt engineering UI:
Simple pipeline: run one-way from start to finish.
[tech] Spin up prompt engineering UI: $ kotaemon promptui run <path/to/config/file.yml>
[non-tech] Change params, run inference
[non-tech] Export to Excel
[non-tech] Select the set of params that achieve the best output
The prompt engineering UI prominently involves from step 2 to step 7 (step 1 is normally done by the developers, while step 7 happens exclusively in Excel file).
"},{"location":"development/utilities/#step-2-export-pipeline-to-config","title":"Step 2 - Export pipeline to config","text":"
<module.path.pipelineclass> is a dot-separated path to the pipeline. For example, if your pipeline can be accessed with from projectA.pipelines import AnsweringPipeline, then this value is projectA.pipelines.AnswerPipeline.
<path/to/config/file.yml> is the target file path that the config will be exported to. If the config file already exists, and contains information of other pipelines, the config of current pipeline will additionally be added. If it contains information of the current pipeline (in the past), the old information will be replaced.
By default, all params in a pipeline (including nested params) will be export to the configuration file. For params that you do not wish to expose to the UI, you can directly remove them from the config YAML file. You can also annotate those param with ignore_ui=True, and they will be ignored in the config generation process. Example:
Declared as above, and param1 will show up in the config YAML file, while param2 will not.
"},{"location":"development/utilities/#step-3-customize-the-config","title":"Step 3 - Customize the config","text":"
developers can further edit the config file in this step to get the most suitable UI (step 4) with their tasks. The exported config will have this overall schema:
<module.path.pipelineclass1>:\n params: ... (Detail param information to initiate a pipeline. This corresponds to the pipeline init parameters.)\n inputs: ... (Detail the input of the pipeline e.g. a text prompt. This corresponds to the params of `run(...)` method.)\n outputs: ... (Detail the output of the pipeline e.g. prediction, accuracy... This is the output information we wish to see in the UI.)\n logs: ... (Detail what information should show up in the log.)\n
"},{"location":"development/utilities/#input-and-params","title":"Input and params","text":"
The inputs section have the overall schema as follow:
inputs:\n <input-variable-name-1>:\n component: <supported-UI-component>\n params: # this section is optional)\n value: <default-value>\n <input-variable-name-2>: ... # similar to above\nparams:\n <param-variable-name-1>: ... # similar to those in the inputs\n
The list of supported prompt UI and their corresponding gradio UI components:
The outputs are a list of variables that we wish to show in the UI. Since in Python, the function output doesn't have variable name, so output declaration is a little bit different than input and param declaration:
outputs:\n - component: <supported-UI-component>\n step: <name-of-pipeline-step>\n item: <jsonpath way to retrieve the info>\n - ... # similar to above\n
where:
component: the same text string and corresponding Gradio UI as in inputs & params
step: the pipeline step that we wish to look fetch and show output on the UI
item: the jsonpath mechanism to get the targeted variable from the step above
The logs show a list of sheetname and how to retrieve the desired information.
logs:\n <logname>:\n inputs:\n - name: <column name>\n step: <the pipeline step that we would wish to see the input>\n variable: <the variable in the step>\n - ...\n outputs:\n - name: <column name>\n step: <the pipeline step that we would wish to see the output>\n item: <how to retrieve the output of that step>\n
Chat pipeline workflow is different from simple pipeline workflow. In simple pipeline, each Run creates a set of output, input and params for users to compare. In chat pipeline, each Run is not a one-off run, but a long interactive session. Hence, the workflow is as follow:
Set the desired parameters.
Click \"New chat\" to start a chat session with the supplied parameters. This set of parameters will persist until the end of the chat session. During an ongoing chat session, changing the parameters will not take any effect.
Chat and interact with the chat bot on the right panel. You can add any additional input (if any), and they will be supplied to the chatbot.
During chat, the log of the chat will show up in the \"Output\" tabs. This is empty by default, so if you want to show the log here, tell the AI developers to configure the UI settings.
When finishing chat, select your preference in the radio box. Click \"End chat\". This will save the chat log and the preference to disk.
To compare the result of different run, click \"Export\" to get an Excel spreadsheet summary of different run.
"},{"location":"pages/app/customize-flows/","title":"Customize flow logic","text":""},{"location":"pages/app/customize-flows/#add-new-indexing-and-reasoning-pipeline-to-the-application","title":"Add new indexing and reasoning pipeline to the application","text":"
@trducng
At high level, to add new indexing and reasoning pipeline:
You define your indexing or reasoning pipeline as a class from BaseComponent.
You declare that class in the setting files flowsettings.py.
Then when python app.py, the application will dynamically load those pipelines.
The below sections talk in more detail about how the pipelines should be constructed.
"},{"location":"pages/app/customize-flows/#define-a-pipeline-as-a-class","title":"Define a pipeline as a class","text":"
In essence, a pipeline will subclass from kotaemon.base.BaseComponent. Each pipeline has 2 main parts:
This pipeline is simple for demonstration purpose, but we can imagine pipelines with much more arguments, that can take other pipelines as arguments, and have more complicated logic in the run method.
An indexing or reasoning pipeline is just a class subclass from BaseComponent like above.
For more detail on this topic, please refer to Creating a Component
Note: this section is tentative at the moment. We will finalize def run function signature by latest early April.
The indexing pipeline:
def run(\n self,\n file_paths: str | Path | list[str | Path],\n reindex: bool = False,\n **kwargs,\n ):\n \"\"\"Index files to intermediate representation (e.g. vector, database...)\n\n Args:\n file_paths: the list of paths to files\n reindex: if True, files in `file_paths` that already exists in database\n should be reindex.\n \"\"\"\n
The reasoning pipeline:
def run(self, question: str, history: list, **kwargs) -> Document:\n \"\"\"Answer the question\n\n Args:\n question: the user input\n history: the chat history [(user_msg1, bot_msg1), (user_msg2, bot_msg2)...]\n\n Returns:\n kotaemon.base.Document: the final answer\n \"\"\"\n
"},{"location":"pages/app/customize-flows/#register-your-pipeline-to-ktem","title":"Register your pipeline to ktem","text":"
To register your pipelines to ktem, you declare it in the flowsettings.py file. This file locates at the current working directory where you start the ktem. In most use cases, it is this one.
You can register multiple reasoning pipelines to ktem by populating the KH_REASONING list. The user can select which reasoning pipeline to use in their Settings page.
For now, there's only one supported index option for KH_INDEX.
Make sure that your class is discoverable by Python.
"},{"location":"pages/app/customize-flows/#allow-users-to-customize-your-pipeline-in-the-app-settings","title":"Allow users to customize your pipeline in the app settings","text":"
To allow the users to configure your pipeline, you need to declare what you allow the users to configure as a dictionary. ktem will include them into the application settings.
In your pipeline class, add a classmethod get_user_settings that returns a setting dictionary, add a classmethod get_info that returns an info dictionary. Example:
class SoSimple(BaseComponent):\n\n ... # as above\n\n @classmethod\n def get_user_settings(cls) -> dict:\n \"\"\"The settings to the user\"\"\"\n return {\n \"setting_1\": {\n \"name\": \"Human-friendly name\",\n \"value\": \"Default value\",\n \"choices\": [(\"Human-friendly Choice 1\", \"choice1-id\"), (\"HFC 2\", \"choice2-id\")], # optional\n \"component\": \"Which Gradio UI component to render, can be: text, number, checkbox, dropdown, radio, checkboxgroup\"\n },\n \"setting_2\": {\n # follow the same rule as above\n }\n }\n\n @classmethod\n def get_info(cls) -> dict:\n \"\"\"Pipeline information for bookkeeping purpose\"\"\"\n return {\n \"id\": \"a unique id to differentiate this pipeline from other pipeline\",\n \"name\": \"Human-friendly name of the pipeline\",\n \"description\": \"Can be a short description of this pipeline\"\n }\n
Once adding these methods to your pipeline class, ktem will automatically extract and add them to the settings.
"},{"location":"pages/app/customize-flows/#construct-to-pipeline-object","title":"Construct to pipeline object","text":"
Once ktem runs your pipeline, it will call your classmethod get_pipeline with the full user settings and expect to obtain the pipeline object. Within this get_pipeline method, you implement all the necessary logics to initiate the pipeline object. Example:
class SoSimple(BaseComponent):\n ... # as above\n\n @classmethod\n def get_pipeline(self, setting):\n obj = cls(arg1=setting[\"reasoning.id.setting1\"])\n return obj\n
"},{"location":"pages/app/customize-flows/#reasoning-stream-output-to-ui","title":"Reasoning: Stream output to UI","text":"
For fast user experience, you can stream the output directly to UI. This way, user can start observing the output as soon as the LLM model generates the 1st token, rather than having to wait the pipeline finishes to read the whole message.
To stream the output, you need to;
Turn the run function to async.
Pass in the output to a special queue with self.report_output.
async def run(self, question: str, history: list, **kwargs) -> Document:\n for char in \"This is a long messages\":\n self.report_output({\"output\": text.text})\n
The argument to self.report_output is a dictionary, that contains either or all of these 2 keys: \"output\", \"evidence\". The \"output\" string will be streamed to the chat message, and the \"evidence\" string will be streamed to the information panel.
The kotaemon focuses on question and answering over a corpus of data. Below is the gentle introduction about the chat functionality.
Users can upload corpus of files.
Users can converse to the chatbot to ask questions about the corpus of files.
Users can view the reference in the files.
"},{"location":"pages/app/functional-description/","title":"Functional description","text":""},{"location":"pages/app/functional-description/#user-group-tenant-management","title":"User group / tenant management","text":""},{"location":"pages/app/functional-description/#create-new-user-group","title":"Create new user group","text":"
(6 man-days)
Description: each client has a dedicated user group. Each user group has an admin user who can do administrative tasks (e.g. creating user account in that user group...). The workflow for creating new user group is as follow:
Cinnamon accesses the user group management UI.
On \"Create user group\" panel, we supply: a. Client name: e.g. Apple. b. Sub-domain name: e.g. apple. c. Admin email, username & password.
The system will: a. An Aurora Platform deployment with the specified sub-domain. b. Send an email to the admin, with the username & password.
Expectation:
The admin can go to the deployed Aurora Platform.
The admin can login with the specified username & password.
Condition:
When sub-domain name already exists, raise error.
If error sending email to the client, raise the error, and delete the newly-created user-group.
Password rule:
Have at least 8 characters.
Must contain uppercase, lowercase, number and symbols.
"},{"location":"pages/app/functional-description/#delete-user-group","title":"Delete user group","text":"
(2 man-days)
Description: in the tenant management page, we can delete the selected user group. The user flow is as follow:
Cinnamon accesses the user group management UI,
View list of user groups.
Next to target user group, click delete.
Confirm whether to delete.
If Yes, delete the user group. If No, cancel the operation.
Expectation: when a user group is deleted, we expect to delete everything related to the user groups: domain, files, databases, caches, deployments.
"},{"location":"pages/app/functional-description/#user-management","title":"User management","text":""},{"location":"pages/app/functional-description/#create-user-account-for-admin-user","title":"Create user account (for admin user)","text":"
(1 man-day)
Description: the admin user in the client's account can create user account for that user group. To create the new user, the client admin do:
Navigate to \"Admin\" > \"Users\"
In the \"Create user\" panel, supply:
Username
Password
Confirm password
Click \"Create\"
Expectation:
The user can create the account.
The username:
Is case-insensitive (e.g. Moon and moon will be the same)
Can only contains these characters: a-z A-Z 0-9 _ + - .
Has maximum length of 32 characters
The password is subjected to the following rule:
8-character minimum length
Contains at least 1 number
Contains at least 1 lowercase letter
Contains at least 1 uppercase letter
Contains at least 1 special character from the following set, or a non-leading, non-trailing space character: ^ $ * . [ ] { } ( ) ? - \" ! @ # % & / \\ , > < ' : ; | _ ~ + =
"},{"location":"pages/app/functional-description/#delete-user-account-for-admin-user","title":"Delete user account (for admin user)","text":"
Description: the admin user in the client's account can delete user account. Once an user account is deleted, he/she cannot login to Aurora Platform.
The admin user navigates to \"Admin\" > \"Users\".
In the user list panel, next to the username, the admin click on the \"Delete\" button. The Confirmation dialog appears.
If \"Delete\", the user account is deleted. If \"Cancel\", do nothing. The Confirmation dialog disappears.
Expectation:
Once the user is deleted, the following information relating to the user will be deleted:
His/her personal setting.
His/her conversations.
The following information relating to the user will still be retained:
His/her uploaded files.
"},{"location":"pages/app/functional-description/#edit-user-account-for-admin-user","title":"Edit user account (for admin user)","text":"
Description: the admin user can change any information about the user account, including password. To change user information:
The admin user navigates to \"Admin\" > \"Users\".
In the user list panel, next to the username, the admin click on the \"Edit\" button.
The user list disappears, the user detail appears, with the following information show up:
Username: (prefilled the username)
Password: (blank)
Confirm password: (blank)
The admin can edit any of the information, and click \"Save\" or \"Cancel\".
If \"Save\": the information will be updated to the database, or show error per Expectation below.
If \"Cancel\": skip.
If Save success or Cancel, transfer back to the user list UI, where the user information is updated accordingly.
Expectation:
If the \"Password\" & \"Confirm password\" are different from each other, show error: \"Password mismatch\".
If both \"Password\" & *\"Confirm password\" are blank, don't change the user password.
If changing password, the password rule is subjected to the same rule when creating user.
It's possible to change username. If changing username, the target user has to use the new username.
Description: the user can change their password as follow:
User navigates to the Settings > User page.
In the change password section, the user provides these info and click Change:
Current password
New password
Confirm new password
If changing successfully, then the password is changed. Otherwise, show the error on the UI.
Expectation:
If changing password succeeds, next time they logout/login to the system, they can use the new password.
Password rule (Same as normal password rule when creating user)
Errors:
Password does not match.
Violated password rules.
"},{"location":"pages/app/functional-description/#chat","title":"Chat","text":""},{"location":"pages/app/functional-description/#chat-to-the-bot","title":"Chat to the bot","text":"
Description: the Aurora Platform focuses on question and answering over the uploaded data. Each chat has the following components:
Chat message: show the exchange between bots and humans.
Text input + send button: for the user to input the message.
Data source panel: for selecting the files that will scope the context for the bot.
Information panel: showing evidence as the bot answers user's questions.
The chat workflow looks as follow:
[Optional] User select files that they want to scope the context for the bot. If the user doesn't select any files, then all files on Aurora Platform will be the context for the bot.
The user can type multi-line messages, using \"Shift + Enter\" for line-break.
User sends the message (either clicking the Send button or hitting the Enter key).
The bot in the chat conversation will return \"Thinking...\" while it processes.
The information panel on the right begin to show data related to the user message.
The bot begins to generate answer. The \"Thinking...\" placeholder disappears..
Expecatation:
Messages:
User can send multi-line messages, using \"Shift + Enter\" for line-break.
User can thumbs up, thumbs down the AI response. This information is recorded in the database.
User can click on a copy button on the chat message to copy the content to clipboard.
Information panel:
The information panel shows the latest evidence.
The user can click on the message, and the reference for that message will show up on the \"Reference panel\" (feature in-planning).
The user can click on the title to show/hide the content.
The whole information panel can be collapsed.
Chatbot quality:
The user can converse with the bot. The bot answer the user's requests in a natural manner.
The bot message should be streamed to the UI. The bot don't wait to gather alll the text response, then dump all of them at once.
Description: users can jump around between different conversations. They can see the list of all conversations, can select an old converation, and continue the chat under the context of the old conversation. The switching workflow is like this:
Users click on the conversation dropdown. It will show a list of conversations.
Within that dropdown, the user selects one conversation.
The chat messages, information panel, and selected data will show the content in that old chat.
The user can continue chatting as normal under the context of this old chat.
Expectation:
In the conversation drop down list, the conversations are ordered in created date order.
When there is no conversation, the conversation list is empty.
When there is no conversation, the user can still converse with the chat bot. When doing so, it automatically create new conversation.
Description: the user can upload files to the Aurora Platform. The uploaded files will be served as context for our chatbot to refer to when it converses with the user. To upload file, the user:
Navigate to the File tab.
Within the File tab, there is an Upload section.
User can add files to the Upload section through drag & drop, and or by click on the file browser.
User can select some options relating to uploading and indexing. Depending on the project, these options can be different. Nevertheless, they will discuss below.
User click on \"Upload and Index\" button.
The app show notifications when indexing starts and finishes, and when errors happen on the top right corner.
Options:
Force re-index file. When user tries to upload files that already exists on the system:
If this option is True: will re-index those files.
If this option is False: will skip indexing those files.
Condition:
Max number of files: 100 files.
Max number of pages per file: 500 pages
Max file size: 10 MB
"},{"location":"pages/app/functional-description/#list-all-files","title":"List all files","text":"
Description: the user can know which files are on the system by:
Navigate to the File tab.
By default, it will show all the uploaded files, each with the following information: file name, file size, number of pages, uploaded date
The UI also shows total number of pages, and total number of sizes in MB.
The file index stores files in a local folder and index them for retrieval. This file index provides the following infrastructure to support the indexing:
SQL table Source: store the list of files that are indexed by the system
Vector store: contain the embedding of segments of the files
Document store: contain the text of segments of the files. Each text stored in this document store is associated with a vector in the vector store.
SQL table Index: store the relationship between (1) the source and the docstore, and (2) the source and the vector store.
The indexing and retrieval pipelines are encouraged to use the above software infrastructure.
The ktem has default indexing pipeline: ktem.index.file.pipelines.IndexDocumentPipeline.
This default pipeline works as follow:
Input: list of file paths
Output: list of nodes that are indexed into database
Process:
Read files into texts. Different file types has different ways to read texts.
Split text files into smaller segments
Run each segments into embeddings.
Store the embeddings into vector store. Store the texts of each segment into docstore. Store the list of files in Source. Store the linking between Sources and docstore + vectorstore in Index table.
You can customize this default pipeline if your indexing process is close to the default pipeline. You can create your own indexing pipeline if there are too much different logic.
"},{"location":"pages/app/index/file/#customize-the-default-pipeline","title":"Customize the default pipeline","text":"
The default pipeline provides the contact points in flowsettings.py.
FILE_INDEX_PIPELINE_FILE_EXTRACTORS. Supply overriding file extractor, based on file extension. Example: {\".pdf\": \"path.to.PDFReader\", \".xlsx\": \"path.to.ExcelReader\"}
FILE_INDEX_PIPELINE_SPLITTER_CHUNK_SIZE. The expected number of characters of each text segment. Example: 1024.
FILE_INDEX_PIPELINE_SPLITTER_CHUNK_OVERLAP. The expected number of characters that consecutive text segments should overlap with each other. Example: 256.
"},{"location":"pages/app/index/file/#create-your-own-indexing-pipeline","title":"Create your own indexing pipeline","text":"
Your indexing pipeline will subclass BaseFileIndexIndexing.
You should define the following methods:
run(self, file_paths): run the indexing given the pipeline
get_pipeline(cls, user_settings, index_settings): return the fully-initialized pipeline, ready to be used by ktem.
user_settings: is a dictionary contains user settings (e.g. {\"pdf_mode\": True, \"num_retrieval\": 5}). You can declare these settings in the get_user_settings classmethod. ktem will collect these settings into the app Settings page, and will supply these user settings to your get_pipeline method.
index_settings: is a dictionary. Currently it's empty for File Index.
get_user_settings: to declare user settings, return a dictionary.
By subclassing BaseFileIndexIndexing, You will have access to the following resources:
self._Source: the source table
self._Index: the index table
self._VS: the vector store
self._DS: the docstore
Once you have prepared your pipeline, register it in flowsettings.py: FILE_INDEX_PIPELINE = \"<python.path.to.your.pipeline>\".
The ktem has default retrieval pipeline: ktem.index.file.pipelines.DocumentRetrievalPipeline. This pipeline works as follow:
Input: user text query & optionally a list of source file ids
Output: the output segments that match the user text query
Process:
If a list of source file ids is given, get the list of vector ids that associate with those file ids.
Embed the user text query.
Query the vector store. Provide a list of vector ids to limit query scope if the user restrict.
Return the matched text segments
"},{"location":"pages/app/index/file/#create-your-own-retrieval-pipeline","title":"Create your own retrieval pipeline","text":"
Your retrieval pipeline will subclass BaseFileIndexRetriever. The retriever has the same database, vectorstore and docstore accesses like the indexing pipeline.
You should define the following methods:
run(self, query, file_ids): retrieve relevant documents relating to the query. If file_ids is given, you should restrict your search within these file_ids.
get_pipeline(cls, user_settings, index_settings, selected): return the fully-initialized pipeline, ready to be used by ktem.
user_settings: is a dictionary contains user settings (e.g. {\"pdf_mode\": True, \"num_retrieval\": 5}). You can declare these settings in the get_user_settings classmethod. ktem will collect these settings into the app Settings page, and will supply these user settings to your get_pipeline method.
index_settings: is a dictionary. Currently it's empty for File Index.
selected: a list of file ids selected by user. If user doesn't select anything, this variable will be None.
get_user_settings: to declare user settings, return a dictionary.
Once you build the retrieval pipeline class, you can register it in flowsettings.py: FILE_INDEXING_RETRIEVER_PIPELIENS = [\"path.to.retrieval.pipelie\"]. Because there can be multiple parallel pipelines within an index, this variable takes a list of string rather than a string.
"},{"location":"pages/app/index/file/#software-infrastructure","title":"Software infrastructure","text":"Infra Access Schema Ref SQL table Source self._Source - id (int): id of the source (auto)- name (str): the name of the file- path (str): the path of the file- size (int): the file size in bytes- note (dict): allow extra optional information about the file- date_created (datetime): the time the file is created (auto) This is SQLALchemy ORM class. Can consult SQL table Index self._Index - id (int): id of the index entry (auto)- source_id (int): the id of a file in the Source table- target_id: the id of the segment in docstore or vector store- relation_type (str): if the link is \"document\" or \"vector\" This is SQLAlchemy ORM class Vector store self._VS - self._VS.add: add the list of embeddings to the vector store (optionally associate metadata and ids)- self._VS.delete: delete vector entries based on ids- self._VS.query: get embeddings based on embeddings. kotaemon > storages > vectorstores > BaseVectorStore Doc store self._DS - self._DS.add: add the segments to document stores- self._DS.get: get the segments based on id- self._DS.get_all: get all segments- self._DS.delete: delete segments based on id kotaemon > storages > docstores > base > BaseDocumentStore"},{"location":"pages/app/settings/overview/","title":"Settings","text":""},{"location":"pages/app/settings/overview/#overview","title":"Overview","text":"
There are 3 kinds of settings in ktem, geared towards different stakeholders for different use cases:
Developer settings. These settings are meant for very basic app customization, such as database URL, cloud config, logging config, which features to enable... You will be interested in the developer settings if you deploy ktem to your customers, or if you build extension for ktem for developers. These settings are declared inside flowsettings.py.
Admin settings. These settings show up in the Admin page, and are meant to allow admin-level user to customize low level features, such as which credentials to connect to data sources, which keys to use for LLM...
User settings. These settings are meant for run-time users to tweak ktem to their personal needs, such as which output languages the chatbot should generate, which reasoning type to use...
ktem allows developers to extend the index and the reasoning pipeline. In many cases, these components can have settings that should be modified by users at run-time, (e.g. topk, chunksize...). These are the user settings.
ktem allows developers to declare such user settings in their code. Once declared, ktem will render them in a Settings page.
There are 2 places that ktem looks for declared user settings. You can refer to the respective pages.
In the index.
In the reasoning pipeline.
"},{"location":"pages/app/settings/user-settings/#syntax-of-a-settings","title":"Syntax of a settings","text":"
A collection of settings is a dictionary of type dict[str, dict], where the key is a setting id, and the value is the description of the setting.
Agents * Base * Io * Base * Langchain Based * React * Agent * Prompt * Rewoo * Agent * Planner * Prompt * Solver * Tools * Base * Google * Llm * Wikipedia * Utils
Base * Component * Schema
Chatbot * Base * Simple Respondent
CLI
Embeddings * Base * Endpoint Based * Fastembed * Langchain Based * Openai
Indices * Base * Extractors * Doc Parsers * Ingests * Files * Qa * Citation * Text Based * Rankings * Base * Cohere * Llm * Llm Scoring * Llm Trulens * Splitters * Vectorindex
LLMs * Base * Branching * Chats * Base * Endpoint Based * Langchain Based * Llamacpp * Openai * Completions * Base * Langchain Based * Cot * Linear * Prompts * Base * Template
\n# Run with default config file\n$ kh promptui run\n\n\n# Run with username and password supplied\n$ kh promptui run --username admin --password password\n\n\n# Run with username and prompted password\n$ kh promptui run --username admin\n\n# Run and share to promptui\n# kh promptui run --username admin --password password --share --appname hey --port 7861\n
Source code in libs/kotaemon/kotaemon/cli.py
@promptui.command()\n@click.argument(\"run_path\", required=False, default=\"promptui.yml\")\n@click.option(\n \"--share\",\n is_flag=True,\n show_default=True,\n default=False,\n help=\"Share the app through Gradio. Requires --username to enable authentication.\",\n)\n@click.option(\n \"--username\",\n required=False,\n help=(\n \"Username for the user. If not provided, the promptui will not have \"\n \"authentication.\"\n ),\n)\n@click.option(\n \"--password\",\n required=False,\n help=\"Password for the user. If not provided, will be prompted.\",\n)\n@click.option(\n \"--appname\",\n required=False,\n help=\"The share app subdomain. Requires --share and --username\",\n)\n@click.option(\n \"--port\",\n required=False,\n help=\"Port to run the app. If not provided, will $GRADIO_SERVER_PORT (7860)\",\n)\ndef run(run_path, share, username, password, appname, port):\n \"\"\"Run the UI from a config file\n\n Examples:\n\n \\b\n # Run with default config file\n $ kh promptui run\n\n \\b\n # Run with username and password supplied\n $ kh promptui run --username admin --password password\n\n \\b\n # Run with username and prompted password\n $ kh promptui run --username admin\n\n # Run and share to promptui\n # kh promptui run --username admin --password password --share --appname hey \\\n --port 7861\n \"\"\"\n import sys\n\n from kotaemon.contribs.promptui.ui import build_from_dict\n\n sys.path.append(os.getcwd())\n\n check_config_format(run_path)\n demo = build_from_dict(run_path)\n\n params: dict = {}\n if username is not None:\n if password is not None:\n auth = (username, password)\n else:\n auth = (username, click.prompt(\"Password\", hide_input=True))\n params[\"auth\"] = auth\n\n port = int(port) if port else int(os.getenv(\"GRADIO_SERVER_PORT\", \"7860\"))\n params[\"server_port\"] = port\n\n if share:\n if username is None:\n raise ValueError(\n \"Username must be provided to enable authentication for sharing\"\n )\n if appname:\n from kotaemon.contribs.promptui.tunnel import Tunnel\n\n tunnel = Tunnel(\n appname=str(appname), username=str(username), local_port=port\n )\n url = tunnel.run()\n print(f\"App is shared at {url}\")\n else:\n params[\"share\"] = True\n print(\"App is shared at Gradio\")\n\n demo.launch(**params)\n
Important: the value for --template corresponds to the name of the template folder, which is located at https://github.com/Cinnamon/kotaemon/tree/main/templates The default value is \"project-default\", which should work when you are starting a client project.
Source code in libs/kotaemon/kotaemon/cli.py
@main.command()\n@click.option(\n \"--template\",\n default=\"project-default\",\n required=False,\n help=\"Template name\",\n show_default=True,\n)\ndef start_project(template):\n \"\"\"Start a project from a template.\n\n Important: the value for --template corresponds to the name of the template folder,\n which is located at https://github.com/Cinnamon/kotaemon/tree/main/templates\n The default value is \"project-default\", which should work when you are starting a\n client project.\n \"\"\"\n\n print(\"Retrieving template...\")\n os.system(\n \"cookiecutter git@github.com:Cinnamon/kotaemon.git \"\n f\"--directory='templates/{template}'\"\n )\n
Source code in libs/kotaemon/kotaemon/agents/base.py
class BaseAgent(BaseComponent):\n \"\"\"Define base agent interface\"\"\"\n\n name: str = Param(help=\"Name of the agent.\")\n agent_type: AgentType = Param(help=\"Agent type, must be one of AgentType\")\n description: str = Param(\n help=(\n \"Description used to tell the model how/when/why to use the agent. You can\"\n \" provide few-shot examples as a part of the description. This will be\"\n \" input to the prompt of LLM.\"\n )\n )\n llm: Optional[BaseLLM] = Node(\n help=(\n \"LLM to be used for the agent (optional). LLM must implement BaseLLM\"\n \" interface.\"\n )\n )\n prompt_template: Optional[Union[PromptTemplate, dict[str, PromptTemplate]]] = Param(\n help=\"A prompt template or a dict to supply different prompt to the agent\"\n )\n plugins: list[BaseTool] = Param(\n default_callback=lambda _: [],\n help=\"List of plugins / tools to be used in the agent\",\n )\n\n @staticmethod\n def safeguard_run(run_func, *args, **kwargs):\n def wrapper(self, *args, **kwargs):\n try:\n return run_func(self, *args, **kwargs)\n except Exception as e:\n return AgentOutput(\n text=\"\",\n agent_type=self.agent_type,\n status=\"failed\",\n error=str(e),\n )\n\n return wrapper\n\n def add_tools(self, tools: list[BaseTool]) -> None:\n \"\"\"Helper method to add tools and update agent state if needed\"\"\"\n self.plugins.extend(tools)\n\n def run(self, *args, **kwargs) -> AgentOutput | list[AgentOutput]:\n \"\"\"Run the component.\"\"\"\n raise NotImplementedError()\n
Helper method to add tools and update agent state if needed
Source code in libs/kotaemon/kotaemon/agents/base.py
def add_tools(self, tools: list[BaseTool]) -> None:\n \"\"\"Helper method to add tools and update agent state if needed\"\"\"\n self.plugins.extend(tools)\n
required Source code in libs/kotaemon/kotaemon/agents/io/base.py
class AgentFinish(NamedTuple):\n \"\"\"Agent's return value when finishing execution.\n\n Args:\n return_values: The return values of the agent.\n log: The log message.\n \"\"\"\n\n return_values: dict\n log: str\n
required Source code in libs/kotaemon/kotaemon/agents/io/base.py
class AgentOutput(LLMInterface):\n \"\"\"Output from an agent.\n\n Args:\n text: The text output from the agent.\n agent_type: The type of agent.\n status: The status after executing the agent.\n error: The error message if any.\n \"\"\"\n\n model_config = ConfigDict(extra=\"allow\")\n\n text: str\n type: str = \"agent\"\n agent_type: AgentType\n status: Literal[\"thinking\", \"finished\", \"stopped\", \"failed\"]\n error: Optional[str] = None\n intermediate_steps: Optional[list] = None\n
str, optional The title of the panel, defaults to \"Output\".
'Output'stream
bool, optional
False Source code in libs/kotaemon/kotaemon/agents/io/base.py
def panel_print(self, item: Any, title: str = \"Output\", stream: bool = False):\n \"\"\"\n Log a panel output.\n\n Args:\n item : Any\n The item to log.\n title : str, optional\n The title of the panel, defaults to \"Output\".\n stream : bool, optional\n \"\"\"\n if not stream:\n self.log.append(item)\n if check_log():\n self.logger.info(\"-\" * 20)\n self.logger.info(item)\n self.logger.info(\"-\" * 20)\n
Sequential ReactAgent class inherited from BaseAgent. Implementing ReAct agent paradigm https://arxiv.org/pdf/2210.03629.pdf
Source code in libs/kotaemon/kotaemon/agents/react/agent.py
class ReactAgent(BaseAgent):\n \"\"\"\n Sequential ReactAgent class inherited from BaseAgent.\n Implementing ReAct agent paradigm https://arxiv.org/pdf/2210.03629.pdf\n \"\"\"\n\n name: str = \"ReactAgent\"\n agent_type: AgentType = AgentType.react\n description: str = \"ReactAgent for answering multi-step reasoning questions\"\n llm: BaseLLM\n prompt_template: Optional[PromptTemplate] = None\n output_lang: str = \"English\"\n plugins: list[BaseTool] = Param(\n default_callback=lambda _: [], help=\"List of tools to be used in the agent. \"\n )\n examples: dict[str, str | list[str]] = Param(\n default_callback=lambda _: {}, help=\"Examples to be used in the agent. \"\n )\n intermediate_steps: list[tuple[AgentAction | AgentFinish, str]] = Param(\n default_callback=lambda _: [],\n help=\"List of AgentAction and observation (tool) output\",\n )\n max_iterations: int = 5\n strict_decode: bool = False\n max_context_length: int = Param(\n default=3000,\n help=\"Max context length for each tool output.\",\n )\n trim_func: TokenSplitter | None = None\n\n def _compose_plugin_description(self) -> str:\n \"\"\"\n Compose the worker prompt from the workers.\n\n Example:\n toolname1[input]: tool1 description\n toolname2[input]: tool2 description\n \"\"\"\n prompt = \"\"\n try:\n for plugin in self.plugins:\n prompt += f\"{plugin.name}[input]: {plugin.description}\\n\"\n except Exception:\n raise ValueError(\"Worker must have a name and description.\")\n return prompt\n\n def _construct_scratchpad(\n self, intermediate_steps: list[tuple[AgentAction | AgentFinish, str]] = []\n ) -> str:\n \"\"\"Construct the scratchpad that lets the agent continue its thought process.\"\"\"\n thoughts = \"\"\n for action, observation in intermediate_steps:\n thoughts += action.log\n thoughts += f\"\\nObservation: {observation}\\nThought:\"\n return thoughts\n\n def _parse_output(self, text: str) -> Optional[AgentAction | AgentFinish]:\n \"\"\"\n Parse text output from LLM for the next Action or Final Answer\n Using Regex to parse \"Action:\\n Action Input:\\n\" for the next Action\n Using FINAL_ANSWER_ACTION to parse Final Answer\n\n Args:\n text[str]: input text to parse\n \"\"\"\n includes_answer = FINAL_ANSWER_ACTION in text\n regex = (\n r\"Action\\s*\\d*\\s*:[\\s]*(.*?)[\\s]*Action\\s*\\d*\\s*Input\\s*\\d*\\s*:[\\s]*(.*)\"\n )\n action_match = re.search(regex, text, re.DOTALL)\n action_output: Optional[AgentAction | AgentFinish] = None\n if action_match:\n if includes_answer:\n raise Exception(\n \"Parsing LLM output produced both a final answer \"\n f\"and a parse-able action: {text}\"\n )\n action = action_match.group(1).strip()\n action_input = action_match.group(2)\n tool_input = action_input.strip(\" \")\n # ensure if its a well formed SQL query we don't remove any trailing \" chars\n if tool_input.startswith(\"SELECT \") is False:\n tool_input = tool_input.strip('\"')\n\n action_output = AgentAction(action, tool_input, text)\n\n elif includes_answer:\n action_output = AgentFinish(\n {\"output\": text.split(FINAL_ANSWER_ACTION)[-1].strip()}, text\n )\n else:\n if self.strict_decode:\n raise Exception(f\"Could not parse LLM output: `{text}`\")\n else:\n action_output = AgentFinish({\"output\": text}, text)\n\n return action_output\n\n def _compose_prompt(self, instruction) -> str:\n \"\"\"\n Compose the prompt from template, worker description, examples and instruction.\n \"\"\"\n agent_scratchpad = self._construct_scratchpad(self.intermediate_steps)\n tool_description = self._compose_plugin_description()\n tool_names = \", \".join([plugin.name for plugin in self.plugins])\n if self.prompt_template is None:\n from .prompt import zero_shot_react_prompt\n\n self.prompt_template = zero_shot_react_prompt\n return self.prompt_template.populate(\n instruction=instruction,\n agent_scratchpad=agent_scratchpad,\n tool_description=tool_description,\n tool_names=tool_names,\n lang=self.output_lang,\n )\n\n def _format_function_map(self) -> dict[str, BaseTool]:\n \"\"\"Format the function map for the open AI function API.\n\n Return:\n Dict[str, Callable]: The function map.\n \"\"\"\n # Map the function name to the real function object.\n function_map = {}\n for plugin in self.plugins:\n function_map[plugin.name] = plugin\n return function_map\n\n def _trim(self, text: str | Document) -> str:\n \"\"\"\n Trim the text to the maximum token length.\n \"\"\"\n evidence_trim_func = (\n self.trim_func\n if self.trim_func\n else TokenSplitter(\n chunk_size=self.max_context_length,\n chunk_overlap=0,\n separator=\" \",\n tokenizer=partial(\n tiktoken.encoding_for_model(\"gpt-3.5-turbo\").encode,\n allowed_special=set(),\n disallowed_special=\"all\",\n ),\n )\n )\n if isinstance(text, str):\n texts = evidence_trim_func([Document(text=text)])\n elif isinstance(text, Document):\n texts = evidence_trim_func([text])\n else:\n raise ValueError(\"Invalid text type to trim\")\n trim_text = texts[0].text\n logging.info(f\"len (trimmed): {len(trim_text)}\")\n return trim_text\n\n def clear(self):\n \"\"\"\n Clear and reset the agent.\n \"\"\"\n self.intermediate_steps = []\n\n def run(self, instruction, max_iterations=None) -> AgentOutput:\n \"\"\"\n Run the agent with the given instruction.\n\n Args:\n instruction: Instruction to run the agent with.\n max_iterations: Maximum number of iterations\n of reasoning steps, defaults to 10.\n\n Return:\n AgentOutput object.\n \"\"\"\n if not max_iterations:\n max_iterations = self.max_iterations\n assert max_iterations > 0\n\n self.clear()\n logging.info(f\"Running {self.name} with instruction: {instruction}\")\n total_cost = 0.0\n total_token = 0\n status = \"failed\"\n response_text = None\n\n for step_count in range(1, max_iterations + 1):\n prompt = self._compose_prompt(instruction)\n logging.info(f\"Prompt: {prompt}\")\n response = self.llm(\n prompt, stop=[\"Observation:\"]\n ) # could cause bugs if llm doesn't have `stop` as a parameter\n response_text = response.text\n logging.info(f\"Response: {response_text}\")\n action_step = self._parse_output(response_text)\n if action_step is None:\n raise ValueError(\"Invalid action\")\n is_finished_chain = isinstance(action_step, AgentFinish)\n if is_finished_chain:\n result = \"\"\n else:\n assert isinstance(action_step, AgentAction)\n action_name = action_step.tool\n tool_input = action_step.tool_input\n logging.info(f\"Action: {action_name}\")\n logging.info(f\"Tool Input: {tool_input}\")\n result = self._format_function_map()[action_name](tool_input)\n\n # trim the worker output to 1000 tokens, as we are appending\n # all workers' logs and it can exceed the token limit if we\n # don't limit each. Fix this number regarding to the LLM capacity.\n result = self._trim(result)\n logging.info(f\"Result: {result}\")\n\n self.intermediate_steps.append((action_step, result))\n if is_finished_chain:\n logging.info(f\"Finished after {step_count} steps.\")\n status = \"finished\"\n break\n else:\n status = \"stopped\"\n\n return AgentOutput(\n text=response_text,\n agent_type=self.agent_type,\n status=status,\n total_tokens=total_token,\n total_cost=total_cost,\n intermediate_steps=self.intermediate_steps,\n max_iterations=max_iterations,\n )\n\n def stream(self, instruction, max_iterations=None):\n \"\"\"\n Stream the agent with the given instruction.\n\n Args:\n instruction: Instruction to run the agent with.\n max_iterations: Maximum number of iterations\n of reasoning steps, defaults to 10.\n\n Return:\n AgentOutput object.\n \"\"\"\n if not max_iterations:\n max_iterations = self.max_iterations\n assert max_iterations > 0\n\n self.clear()\n logging.info(f\"Running {self.name} with instruction: {instruction}\")\n print(f\"Running {self.name} with instruction: {instruction}\")\n total_cost = 0.0\n total_token = 0\n status = \"failed\"\n response_text = None\n\n for step_count in range(1, max_iterations + 1):\n prompt = self._compose_prompt(instruction)\n logging.info(f\"Prompt: {prompt}\")\n print(f\"Prompt: {prompt}\")\n response = self.llm(\n prompt, stop=[\"Observation:\"]\n ) # TODO: could cause bugs if llm doesn't have `stop` as a parameter\n response_text = response.text\n logging.info(f\"Response: {response_text}\")\n print(f\"Response: {response_text}\")\n action_step = self._parse_output(response_text)\n if action_step is None:\n raise ValueError(\"Invalid action\")\n is_finished_chain = isinstance(action_step, AgentFinish)\n if is_finished_chain:\n result = response_text\n if \"Final Answer:\" in response_text:\n result = response_text.split(\"Final Answer:\")[-1].strip()\n else:\n assert isinstance(action_step, AgentAction)\n action_name = action_step.tool\n tool_input = action_step.tool_input\n logging.info(f\"Action: {action_name}\")\n print(f\"Action: {action_name}\")\n logging.info(f\"Tool Input: {tool_input}\")\n print(f\"Tool Input: {tool_input}\")\n result = self._format_function_map()[action_name](tool_input)\n\n # trim the worker output to 1000 tokens, as we are appending\n # all workers' logs and it can exceed the token limit if we\n # don't limit each. Fix this number regarding to the LLM capacity.\n result = self._trim(result)\n logging.info(f\"Result: {result}\")\n print(f\"Result: {result}\")\n\n self.intermediate_steps.append((action_step, result))\n if is_finished_chain:\n logging.info(f\"Finished after {step_count} steps.\")\n status = \"finished\"\n yield AgentOutput(\n text=result,\n agent_type=self.agent_type,\n status=status,\n intermediate_steps=self.intermediate_steps[-1],\n )\n break\n else:\n yield AgentOutput(\n text=\"\",\n agent_type=self.agent_type,\n status=\"thinking\",\n intermediate_steps=self.intermediate_steps[-1],\n )\n\n else:\n status = \"stopped\"\n yield AgentOutput(\n text=\"\",\n agent_type=self.agent_type,\n status=status,\n intermediate_steps=self.intermediate_steps[-1],\n )\n\n return AgentOutput(\n text=response_text,\n agent_type=self.agent_type,\n status=status,\n total_tokens=total_token,\n total_cost=total_cost,\n intermediate_steps=self.intermediate_steps,\n max_iterations=max_iterations,\n )\n
Maximum number of iterations of reasoning steps, defaults to 10.
None Return
AgentOutput object.
Source code in libs/kotaemon/kotaemon/agents/react/agent.py
def run(self, instruction, max_iterations=None) -> AgentOutput:\n \"\"\"\n Run the agent with the given instruction.\n\n Args:\n instruction: Instruction to run the agent with.\n max_iterations: Maximum number of iterations\n of reasoning steps, defaults to 10.\n\n Return:\n AgentOutput object.\n \"\"\"\n if not max_iterations:\n max_iterations = self.max_iterations\n assert max_iterations > 0\n\n self.clear()\n logging.info(f\"Running {self.name} with instruction: {instruction}\")\n total_cost = 0.0\n total_token = 0\n status = \"failed\"\n response_text = None\n\n for step_count in range(1, max_iterations + 1):\n prompt = self._compose_prompt(instruction)\n logging.info(f\"Prompt: {prompt}\")\n response = self.llm(\n prompt, stop=[\"Observation:\"]\n ) # could cause bugs if llm doesn't have `stop` as a parameter\n response_text = response.text\n logging.info(f\"Response: {response_text}\")\n action_step = self._parse_output(response_text)\n if action_step is None:\n raise ValueError(\"Invalid action\")\n is_finished_chain = isinstance(action_step, AgentFinish)\n if is_finished_chain:\n result = \"\"\n else:\n assert isinstance(action_step, AgentAction)\n action_name = action_step.tool\n tool_input = action_step.tool_input\n logging.info(f\"Action: {action_name}\")\n logging.info(f\"Tool Input: {tool_input}\")\n result = self._format_function_map()[action_name](tool_input)\n\n # trim the worker output to 1000 tokens, as we are appending\n # all workers' logs and it can exceed the token limit if we\n # don't limit each. Fix this number regarding to the LLM capacity.\n result = self._trim(result)\n logging.info(f\"Result: {result}\")\n\n self.intermediate_steps.append((action_step, result))\n if is_finished_chain:\n logging.info(f\"Finished after {step_count} steps.\")\n status = \"finished\"\n break\n else:\n status = \"stopped\"\n\n return AgentOutput(\n text=response_text,\n agent_type=self.agent_type,\n status=status,\n total_tokens=total_token,\n total_cost=total_cost,\n intermediate_steps=self.intermediate_steps,\n max_iterations=max_iterations,\n )\n
Maximum number of iterations of reasoning steps, defaults to 10.
None Return
AgentOutput object.
Source code in libs/kotaemon/kotaemon/agents/react/agent.py
def stream(self, instruction, max_iterations=None):\n \"\"\"\n Stream the agent with the given instruction.\n\n Args:\n instruction: Instruction to run the agent with.\n max_iterations: Maximum number of iterations\n of reasoning steps, defaults to 10.\n\n Return:\n AgentOutput object.\n \"\"\"\n if not max_iterations:\n max_iterations = self.max_iterations\n assert max_iterations > 0\n\n self.clear()\n logging.info(f\"Running {self.name} with instruction: {instruction}\")\n print(f\"Running {self.name} with instruction: {instruction}\")\n total_cost = 0.0\n total_token = 0\n status = \"failed\"\n response_text = None\n\n for step_count in range(1, max_iterations + 1):\n prompt = self._compose_prompt(instruction)\n logging.info(f\"Prompt: {prompt}\")\n print(f\"Prompt: {prompt}\")\n response = self.llm(\n prompt, stop=[\"Observation:\"]\n ) # TODO: could cause bugs if llm doesn't have `stop` as a parameter\n response_text = response.text\n logging.info(f\"Response: {response_text}\")\n print(f\"Response: {response_text}\")\n action_step = self._parse_output(response_text)\n if action_step is None:\n raise ValueError(\"Invalid action\")\n is_finished_chain = isinstance(action_step, AgentFinish)\n if is_finished_chain:\n result = response_text\n if \"Final Answer:\" in response_text:\n result = response_text.split(\"Final Answer:\")[-1].strip()\n else:\n assert isinstance(action_step, AgentAction)\n action_name = action_step.tool\n tool_input = action_step.tool_input\n logging.info(f\"Action: {action_name}\")\n print(f\"Action: {action_name}\")\n logging.info(f\"Tool Input: {tool_input}\")\n print(f\"Tool Input: {tool_input}\")\n result = self._format_function_map()[action_name](tool_input)\n\n # trim the worker output to 1000 tokens, as we are appending\n # all workers' logs and it can exceed the token limit if we\n # don't limit each. Fix this number regarding to the LLM capacity.\n result = self._trim(result)\n logging.info(f\"Result: {result}\")\n print(f\"Result: {result}\")\n\n self.intermediate_steps.append((action_step, result))\n if is_finished_chain:\n logging.info(f\"Finished after {step_count} steps.\")\n status = \"finished\"\n yield AgentOutput(\n text=result,\n agent_type=self.agent_type,\n status=status,\n intermediate_steps=self.intermediate_steps[-1],\n )\n break\n else:\n yield AgentOutput(\n text=\"\",\n agent_type=self.agent_type,\n status=\"thinking\",\n intermediate_steps=self.intermediate_steps[-1],\n )\n\n else:\n status = \"stopped\"\n yield AgentOutput(\n text=\"\",\n agent_type=self.agent_type,\n status=status,\n intermediate_steps=self.intermediate_steps[-1],\n )\n\n return AgentOutput(\n text=response_text,\n agent_type=self.agent_type,\n status=status,\n total_tokens=total_token,\n total_cost=total_cost,\n intermediate_steps=self.intermediate_steps,\n max_iterations=max_iterations,\n )\n
Source code in libs/kotaemon/kotaemon/agents/tools/base.py
class BaseTool(BaseComponent):\n name: str\n \"\"\"The unique name of the tool that clearly communicates its purpose.\"\"\"\n description: str\n \"\"\"Description used to tell the model how/when/why to use the tool.\n You can provide few-shot examples as a part of the description. This will be\n input to the prompt of LLM.\n \"\"\"\n args_schema: Optional[Type[BaseModel]] = None\n \"\"\"Pydantic model class to validate and parse the tool's input arguments.\"\"\"\n verbose: bool = False\n \"\"\"Whether to log the tool's progress.\"\"\"\n handle_tool_error: Optional[\n Union[bool, str, Callable[[ToolException], str]]\n ] = False\n \"\"\"Handle the content of the ToolException thrown.\"\"\"\n\n def _parse_input(\n self,\n tool_input: Union[str, Dict],\n ) -> Union[str, Dict[str, Any]]:\n \"\"\"Convert tool input to pydantic model.\"\"\"\n args_schema = self.args_schema\n if isinstance(tool_input, str):\n if args_schema is not None:\n key_ = next(iter(args_schema.model_fields.keys()))\n args_schema.validate({key_: tool_input})\n return tool_input\n else:\n if args_schema is not None:\n result = args_schema.parse_obj(tool_input)\n return {k: v for k, v in result.dict().items() if k in tool_input}\n return tool_input\n\n def _run_tool(\n self,\n *args: Any,\n **kwargs: Any,\n ) -> Any:\n \"\"\"Call tool.\"\"\"\n raise NotImplementedError(f\"_run_tool is not implemented for {self.name}\")\n\n def _to_args_and_kwargs(self, tool_input: Union[str, Dict]) -> Tuple[Tuple, Dict]:\n # For backwards compatibility, if run_input is a string,\n # pass as a positional argument.\n if isinstance(tool_input, str):\n return (tool_input,), {}\n else:\n return (), tool_input\n\n def _handle_tool_error(self, e: ToolException) -> Any:\n \"\"\"Handle the content of the ToolException thrown.\"\"\"\n observation = None\n if not self.handle_tool_error:\n raise e\n elif isinstance(self.handle_tool_error, bool):\n if e.args:\n observation = e.args[0]\n else:\n observation = \"Tool execution error\"\n elif isinstance(self.handle_tool_error, str):\n observation = self.handle_tool_error\n elif callable(self.handle_tool_error):\n observation = self.handle_tool_error(e)\n else:\n raise ValueError(\n f\"Got unexpected type of `handle_tool_error`. Expected bool, str \"\n f\"or callable. Received: {self.handle_tool_error}\"\n )\n return observation\n\n def to_langchain_format(self) -> LCTool:\n \"\"\"Convert this tool to Langchain format to use with its agent\"\"\"\n return LCTool(name=self.name, description=self.description, func=self.run)\n\n def run(\n self,\n tool_input: Union[str, Dict],\n verbose: Optional[bool] = None,\n **kwargs: Any,\n ) -> Any:\n \"\"\"Run the tool.\"\"\"\n parsed_input = self._parse_input(tool_input)\n # TODO (verbose_): Add logging\n try:\n tool_args, tool_kwargs = self._to_args_and_kwargs(parsed_input)\n call_kwargs = {**kwargs, **tool_kwargs}\n observation = self._run_tool(*tool_args, **call_kwargs)\n except ToolException as e:\n observation = self._handle_tool_error(e)\n return observation\n else:\n return observation\n\n @classmethod\n def from_langchain_format(cls, langchain_tool: LCTool) -> \"BaseTool\":\n \"\"\"Wrapper for Langchain Tool\"\"\"\n new_tool = BaseTool(\n name=langchain_tool.name, description=langchain_tool.description\n )\n new_tool._run_tool = langchain_tool._run # type: ignore\n return new_tool\n
Description used to tell the model how/when/why to use the tool. You can provide few-shot examples as a part of the description. This will be input to the prompt of LLM.
Convert this tool to Langchain format to use with its agent
Source code in libs/kotaemon/kotaemon/agents/tools/base.py
def to_langchain_format(self) -> LCTool:\n \"\"\"Convert this tool to Langchain format to use with its agent\"\"\"\n return LCTool(name=self.name, description=self.description, func=self.run)\n
Wrapper around other BaseComponent to use it as a tool
Parameters:
Name Type Description Default component
BaseComponent-based component to wrap
required postprocessor
Optional postprocessor for the component output
required Source code in libs/kotaemon/kotaemon/agents/tools/base.py
class ComponentTool(BaseTool):\n \"\"\"Wrapper around other BaseComponent to use it as a tool\n\n Args:\n component: BaseComponent-based component to wrap\n postprocessor: Optional postprocessor for the component output\n \"\"\"\n\n component: BaseComponent\n postprocessor: Optional[Callable] = None\n\n def _run_tool(self, *args: Any, **kwargs: Any) -> Any:\n output = self.component(*args, **kwargs)\n if self.postprocessor:\n output = self.postprocessor(output)\n\n return output\n
Tool that adds the capability to query the Wikipedia API.
Source code in libs/kotaemon/kotaemon/agents/tools/wikipedia.py
class WikipediaTool(BaseTool):\n \"\"\"Tool that adds the capability to query the Wikipedia API.\"\"\"\n\n name: str = \"wikipedia\"\n description: str = (\n \"Search engine from Wikipedia, retrieving relevant wiki page. \"\n \"Useful when you need to get holistic knowledge about people, \"\n \"places, companies, historical events, or other subjects. \"\n \"Input should be a search query.\"\n )\n args_schema: Optional[Type[BaseModel]] = WikipediaArgs\n doc_store: Any = None\n\n def _run_tool(self, query: AnyStr) -> AnyStr:\n if not self.doc_store:\n self.doc_store = Wiki()\n tool = self.doc_store\n evidence = tool.search(query)\n return evidence\n
Source code in libs/kotaemon/kotaemon/agents/base.py
class BaseAgent(BaseComponent):\n \"\"\"Define base agent interface\"\"\"\n\n name: str = Param(help=\"Name of the agent.\")\n agent_type: AgentType = Param(help=\"Agent type, must be one of AgentType\")\n description: str = Param(\n help=(\n \"Description used to tell the model how/when/why to use the agent. You can\"\n \" provide few-shot examples as a part of the description. This will be\"\n \" input to the prompt of LLM.\"\n )\n )\n llm: Optional[BaseLLM] = Node(\n help=(\n \"LLM to be used for the agent (optional). LLM must implement BaseLLM\"\n \" interface.\"\n )\n )\n prompt_template: Optional[Union[PromptTemplate, dict[str, PromptTemplate]]] = Param(\n help=\"A prompt template or a dict to supply different prompt to the agent\"\n )\n plugins: list[BaseTool] = Param(\n default_callback=lambda _: [],\n help=\"List of plugins / tools to be used in the agent\",\n )\n\n @staticmethod\n def safeguard_run(run_func, *args, **kwargs):\n def wrapper(self, *args, **kwargs):\n try:\n return run_func(self, *args, **kwargs)\n except Exception as e:\n return AgentOutput(\n text=\"\",\n agent_type=self.agent_type,\n status=\"failed\",\n error=str(e),\n )\n\n return wrapper\n\n def add_tools(self, tools: list[BaseTool]) -> None:\n \"\"\"Helper method to add tools and update agent state if needed\"\"\"\n self.plugins.extend(tools)\n\n def run(self, *args, **kwargs) -> AgentOutput | list[AgentOutput]:\n \"\"\"Run the component.\"\"\"\n raise NotImplementedError()\n
Helper method to add tools and update agent state if needed
Source code in libs/kotaemon/kotaemon/agents/base.py
def add_tools(self, tools: list[BaseTool]) -> None:\n \"\"\"Helper method to add tools and update agent state if needed\"\"\"\n self.plugins.extend(tools)\n
Cost of the provided model name with provided token information
Source code in libs/kotaemon/kotaemon/agents/utils.py
def calculate_cost(model_name: str, prompt_token: int, completion_token: int) -> float:\n \"\"\"\n Calculate the cost of a prompt and completion.\n\n Returns:\n float: Cost of the provided model name with provided token information\n \"\"\"\n # TODO: to be implemented\n return 0.0\n
required Source code in libs/kotaemon/kotaemon/agents/io/base.py
@dataclass\nclass AgentAction:\n \"\"\"Agent's action to take.\n\n Args:\n tool: The tool to invoke.\n tool_input: The input to the tool.\n log: The log message.\n \"\"\"\n\n tool: str\n tool_input: Union[str, dict]\n log: str\n
required Source code in libs/kotaemon/kotaemon/agents/io/base.py
class AgentFinish(NamedTuple):\n \"\"\"Agent's return value when finishing execution.\n\n Args:\n return_values: The return values of the agent.\n log: The log message.\n \"\"\"\n\n return_values: dict\n log: str\n
required Source code in libs/kotaemon/kotaemon/agents/io/base.py
class AgentOutput(LLMInterface):\n \"\"\"Output from an agent.\n\n Args:\n text: The text output from the agent.\n agent_type: The type of agent.\n status: The status after executing the agent.\n error: The error message if any.\n \"\"\"\n\n model_config = ConfigDict(extra=\"allow\")\n\n text: str\n type: str = \"agent\"\n agent_type: AgentType\n status: Literal[\"thinking\", \"finished\", \"stopped\", \"failed\"]\n error: Optional[str] = None\n intermediate_steps: Optional[list] = None\n
str, optional The title of the panel, defaults to \"Output\".
'Output'stream
bool, optional
False Source code in libs/kotaemon/kotaemon/agents/io/base.py
def panel_print(self, item: Any, title: str = \"Output\", stream: bool = False):\n \"\"\"\n Log a panel output.\n\n Args:\n item : Any\n The item to log.\n title : str, optional\n The title of the panel, defaults to \"Output\".\n stream : bool, optional\n \"\"\"\n if not stream:\n self.log.append(item)\n if check_log():\n self.logger.info(\"-\" * 20)\n self.logger.info(item)\n self.logger.info(\"-\" * 20)\n
str, optional The title of the panel, defaults to \"Output\".
'Output'stream
bool, optional
False Source code in libs/kotaemon/kotaemon/agents/io/base.py
def panel_print(self, item: Any, title: str = \"Output\", stream: bool = False):\n \"\"\"\n Log a panel output.\n\n Args:\n item : Any\n The item to log.\n title : str, optional\n The title of the panel, defaults to \"Output\".\n stream : bool, optional\n \"\"\"\n if not stream:\n self.log.append(item)\n if check_log():\n self.logger.info(\"-\" * 20)\n self.logger.info(item)\n self.logger.info(\"-\" * 20)\n
required Source code in libs/kotaemon/kotaemon/agents/io/base.py
@dataclass\nclass AgentAction:\n \"\"\"Agent's action to take.\n\n Args:\n tool: The tool to invoke.\n tool_input: The input to the tool.\n log: The log message.\n \"\"\"\n\n tool: str\n tool_input: Union[str, dict]\n log: str\n
required Source code in libs/kotaemon/kotaemon/agents/io/base.py
class AgentFinish(NamedTuple):\n \"\"\"Agent's return value when finishing execution.\n\n Args:\n return_values: The return values of the agent.\n log: The log message.\n \"\"\"\n\n return_values: dict\n log: str\n
required Source code in libs/kotaemon/kotaemon/agents/io/base.py
class AgentOutput(LLMInterface):\n \"\"\"Output from an agent.\n\n Args:\n text: The text output from the agent.\n agent_type: The type of agent.\n status: The status after executing the agent.\n error: The error message if any.\n \"\"\"\n\n model_config = ConfigDict(extra=\"allow\")\n\n text: str\n type: str = \"agent\"\n agent_type: AgentType\n status: Literal[\"thinking\", \"finished\", \"stopped\", \"failed\"]\n error: Optional[str] = None\n intermediate_steps: Optional[list] = None\n
Checks if logging has been enabled. :return: True if logging has been enabled, False otherwise. :rtype: bool
Source code in libs/kotaemon/kotaemon/agents/io/base.py
def check_log():\n \"\"\"\n Checks if logging has been enabled.\n :return: True if logging has been enabled, False otherwise.\n :rtype: bool\n \"\"\"\n return os.environ.get(\"LOG_PATH\", None) is not None\n
Sequential ReactAgent class inherited from BaseAgent. Implementing ReAct agent paradigm https://arxiv.org/pdf/2210.03629.pdf
Source code in libs/kotaemon/kotaemon/agents/react/agent.py
class ReactAgent(BaseAgent):\n \"\"\"\n Sequential ReactAgent class inherited from BaseAgent.\n Implementing ReAct agent paradigm https://arxiv.org/pdf/2210.03629.pdf\n \"\"\"\n\n name: str = \"ReactAgent\"\n agent_type: AgentType = AgentType.react\n description: str = \"ReactAgent for answering multi-step reasoning questions\"\n llm: BaseLLM\n prompt_template: Optional[PromptTemplate] = None\n output_lang: str = \"English\"\n plugins: list[BaseTool] = Param(\n default_callback=lambda _: [], help=\"List of tools to be used in the agent. \"\n )\n examples: dict[str, str | list[str]] = Param(\n default_callback=lambda _: {}, help=\"Examples to be used in the agent. \"\n )\n intermediate_steps: list[tuple[AgentAction | AgentFinish, str]] = Param(\n default_callback=lambda _: [],\n help=\"List of AgentAction and observation (tool) output\",\n )\n max_iterations: int = 5\n strict_decode: bool = False\n max_context_length: int = Param(\n default=3000,\n help=\"Max context length for each tool output.\",\n )\n trim_func: TokenSplitter | None = None\n\n def _compose_plugin_description(self) -> str:\n \"\"\"\n Compose the worker prompt from the workers.\n\n Example:\n toolname1[input]: tool1 description\n toolname2[input]: tool2 description\n \"\"\"\n prompt = \"\"\n try:\n for plugin in self.plugins:\n prompt += f\"{plugin.name}[input]: {plugin.description}\\n\"\n except Exception:\n raise ValueError(\"Worker must have a name and description.\")\n return prompt\n\n def _construct_scratchpad(\n self, intermediate_steps: list[tuple[AgentAction | AgentFinish, str]] = []\n ) -> str:\n \"\"\"Construct the scratchpad that lets the agent continue its thought process.\"\"\"\n thoughts = \"\"\n for action, observation in intermediate_steps:\n thoughts += action.log\n thoughts += f\"\\nObservation: {observation}\\nThought:\"\n return thoughts\n\n def _parse_output(self, text: str) -> Optional[AgentAction | AgentFinish]:\n \"\"\"\n Parse text output from LLM for the next Action or Final Answer\n Using Regex to parse \"Action:\\n Action Input:\\n\" for the next Action\n Using FINAL_ANSWER_ACTION to parse Final Answer\n\n Args:\n text[str]: input text to parse\n \"\"\"\n includes_answer = FINAL_ANSWER_ACTION in text\n regex = (\n r\"Action\\s*\\d*\\s*:[\\s]*(.*?)[\\s]*Action\\s*\\d*\\s*Input\\s*\\d*\\s*:[\\s]*(.*)\"\n )\n action_match = re.search(regex, text, re.DOTALL)\n action_output: Optional[AgentAction | AgentFinish] = None\n if action_match:\n if includes_answer:\n raise Exception(\n \"Parsing LLM output produced both a final answer \"\n f\"and a parse-able action: {text}\"\n )\n action = action_match.group(1).strip()\n action_input = action_match.group(2)\n tool_input = action_input.strip(\" \")\n # ensure if its a well formed SQL query we don't remove any trailing \" chars\n if tool_input.startswith(\"SELECT \") is False:\n tool_input = tool_input.strip('\"')\n\n action_output = AgentAction(action, tool_input, text)\n\n elif includes_answer:\n action_output = AgentFinish(\n {\"output\": text.split(FINAL_ANSWER_ACTION)[-1].strip()}, text\n )\n else:\n if self.strict_decode:\n raise Exception(f\"Could not parse LLM output: `{text}`\")\n else:\n action_output = AgentFinish({\"output\": text}, text)\n\n return action_output\n\n def _compose_prompt(self, instruction) -> str:\n \"\"\"\n Compose the prompt from template, worker description, examples and instruction.\n \"\"\"\n agent_scratchpad = self._construct_scratchpad(self.intermediate_steps)\n tool_description = self._compose_plugin_description()\n tool_names = \", \".join([plugin.name for plugin in self.plugins])\n if self.prompt_template is None:\n from .prompt import zero_shot_react_prompt\n\n self.prompt_template = zero_shot_react_prompt\n return self.prompt_template.populate(\n instruction=instruction,\n agent_scratchpad=agent_scratchpad,\n tool_description=tool_description,\n tool_names=tool_names,\n lang=self.output_lang,\n )\n\n def _format_function_map(self) -> dict[str, BaseTool]:\n \"\"\"Format the function map for the open AI function API.\n\n Return:\n Dict[str, Callable]: The function map.\n \"\"\"\n # Map the function name to the real function object.\n function_map = {}\n for plugin in self.plugins:\n function_map[plugin.name] = plugin\n return function_map\n\n def _trim(self, text: str | Document) -> str:\n \"\"\"\n Trim the text to the maximum token length.\n \"\"\"\n evidence_trim_func = (\n self.trim_func\n if self.trim_func\n else TokenSplitter(\n chunk_size=self.max_context_length,\n chunk_overlap=0,\n separator=\" \",\n tokenizer=partial(\n tiktoken.encoding_for_model(\"gpt-3.5-turbo\").encode,\n allowed_special=set(),\n disallowed_special=\"all\",\n ),\n )\n )\n if isinstance(text, str):\n texts = evidence_trim_func([Document(text=text)])\n elif isinstance(text, Document):\n texts = evidence_trim_func([text])\n else:\n raise ValueError(\"Invalid text type to trim\")\n trim_text = texts[0].text\n logging.info(f\"len (trimmed): {len(trim_text)}\")\n return trim_text\n\n def clear(self):\n \"\"\"\n Clear and reset the agent.\n \"\"\"\n self.intermediate_steps = []\n\n def run(self, instruction, max_iterations=None) -> AgentOutput:\n \"\"\"\n Run the agent with the given instruction.\n\n Args:\n instruction: Instruction to run the agent with.\n max_iterations: Maximum number of iterations\n of reasoning steps, defaults to 10.\n\n Return:\n AgentOutput object.\n \"\"\"\n if not max_iterations:\n max_iterations = self.max_iterations\n assert max_iterations > 0\n\n self.clear()\n logging.info(f\"Running {self.name} with instruction: {instruction}\")\n total_cost = 0.0\n total_token = 0\n status = \"failed\"\n response_text = None\n\n for step_count in range(1, max_iterations + 1):\n prompt = self._compose_prompt(instruction)\n logging.info(f\"Prompt: {prompt}\")\n response = self.llm(\n prompt, stop=[\"Observation:\"]\n ) # could cause bugs if llm doesn't have `stop` as a parameter\n response_text = response.text\n logging.info(f\"Response: {response_text}\")\n action_step = self._parse_output(response_text)\n if action_step is None:\n raise ValueError(\"Invalid action\")\n is_finished_chain = isinstance(action_step, AgentFinish)\n if is_finished_chain:\n result = \"\"\n else:\n assert isinstance(action_step, AgentAction)\n action_name = action_step.tool\n tool_input = action_step.tool_input\n logging.info(f\"Action: {action_name}\")\n logging.info(f\"Tool Input: {tool_input}\")\n result = self._format_function_map()[action_name](tool_input)\n\n # trim the worker output to 1000 tokens, as we are appending\n # all workers' logs and it can exceed the token limit if we\n # don't limit each. Fix this number regarding to the LLM capacity.\n result = self._trim(result)\n logging.info(f\"Result: {result}\")\n\n self.intermediate_steps.append((action_step, result))\n if is_finished_chain:\n logging.info(f\"Finished after {step_count} steps.\")\n status = \"finished\"\n break\n else:\n status = \"stopped\"\n\n return AgentOutput(\n text=response_text,\n agent_type=self.agent_type,\n status=status,\n total_tokens=total_token,\n total_cost=total_cost,\n intermediate_steps=self.intermediate_steps,\n max_iterations=max_iterations,\n )\n\n def stream(self, instruction, max_iterations=None):\n \"\"\"\n Stream the agent with the given instruction.\n\n Args:\n instruction: Instruction to run the agent with.\n max_iterations: Maximum number of iterations\n of reasoning steps, defaults to 10.\n\n Return:\n AgentOutput object.\n \"\"\"\n if not max_iterations:\n max_iterations = self.max_iterations\n assert max_iterations > 0\n\n self.clear()\n logging.info(f\"Running {self.name} with instruction: {instruction}\")\n print(f\"Running {self.name} with instruction: {instruction}\")\n total_cost = 0.0\n total_token = 0\n status = \"failed\"\n response_text = None\n\n for step_count in range(1, max_iterations + 1):\n prompt = self._compose_prompt(instruction)\n logging.info(f\"Prompt: {prompt}\")\n print(f\"Prompt: {prompt}\")\n response = self.llm(\n prompt, stop=[\"Observation:\"]\n ) # TODO: could cause bugs if llm doesn't have `stop` as a parameter\n response_text = response.text\n logging.info(f\"Response: {response_text}\")\n print(f\"Response: {response_text}\")\n action_step = self._parse_output(response_text)\n if action_step is None:\n raise ValueError(\"Invalid action\")\n is_finished_chain = isinstance(action_step, AgentFinish)\n if is_finished_chain:\n result = response_text\n if \"Final Answer:\" in response_text:\n result = response_text.split(\"Final Answer:\")[-1].strip()\n else:\n assert isinstance(action_step, AgentAction)\n action_name = action_step.tool\n tool_input = action_step.tool_input\n logging.info(f\"Action: {action_name}\")\n print(f\"Action: {action_name}\")\n logging.info(f\"Tool Input: {tool_input}\")\n print(f\"Tool Input: {tool_input}\")\n result = self._format_function_map()[action_name](tool_input)\n\n # trim the worker output to 1000 tokens, as we are appending\n # all workers' logs and it can exceed the token limit if we\n # don't limit each. Fix this number regarding to the LLM capacity.\n result = self._trim(result)\n logging.info(f\"Result: {result}\")\n print(f\"Result: {result}\")\n\n self.intermediate_steps.append((action_step, result))\n if is_finished_chain:\n logging.info(f\"Finished after {step_count} steps.\")\n status = \"finished\"\n yield AgentOutput(\n text=result,\n agent_type=self.agent_type,\n status=status,\n intermediate_steps=self.intermediate_steps[-1],\n )\n break\n else:\n yield AgentOutput(\n text=\"\",\n agent_type=self.agent_type,\n status=\"thinking\",\n intermediate_steps=self.intermediate_steps[-1],\n )\n\n else:\n status = \"stopped\"\n yield AgentOutput(\n text=\"\",\n agent_type=self.agent_type,\n status=status,\n intermediate_steps=self.intermediate_steps[-1],\n )\n\n return AgentOutput(\n text=response_text,\n agent_type=self.agent_type,\n status=status,\n total_tokens=total_token,\n total_cost=total_cost,\n intermediate_steps=self.intermediate_steps,\n max_iterations=max_iterations,\n )\n
Maximum number of iterations of reasoning steps, defaults to 10.
None Return
AgentOutput object.
Source code in libs/kotaemon/kotaemon/agents/react/agent.py
def run(self, instruction, max_iterations=None) -> AgentOutput:\n \"\"\"\n Run the agent with the given instruction.\n\n Args:\n instruction: Instruction to run the agent with.\n max_iterations: Maximum number of iterations\n of reasoning steps, defaults to 10.\n\n Return:\n AgentOutput object.\n \"\"\"\n if not max_iterations:\n max_iterations = self.max_iterations\n assert max_iterations > 0\n\n self.clear()\n logging.info(f\"Running {self.name} with instruction: {instruction}\")\n total_cost = 0.0\n total_token = 0\n status = \"failed\"\n response_text = None\n\n for step_count in range(1, max_iterations + 1):\n prompt = self._compose_prompt(instruction)\n logging.info(f\"Prompt: {prompt}\")\n response = self.llm(\n prompt, stop=[\"Observation:\"]\n ) # could cause bugs if llm doesn't have `stop` as a parameter\n response_text = response.text\n logging.info(f\"Response: {response_text}\")\n action_step = self._parse_output(response_text)\n if action_step is None:\n raise ValueError(\"Invalid action\")\n is_finished_chain = isinstance(action_step, AgentFinish)\n if is_finished_chain:\n result = \"\"\n else:\n assert isinstance(action_step, AgentAction)\n action_name = action_step.tool\n tool_input = action_step.tool_input\n logging.info(f\"Action: {action_name}\")\n logging.info(f\"Tool Input: {tool_input}\")\n result = self._format_function_map()[action_name](tool_input)\n\n # trim the worker output to 1000 tokens, as we are appending\n # all workers' logs and it can exceed the token limit if we\n # don't limit each. Fix this number regarding to the LLM capacity.\n result = self._trim(result)\n logging.info(f\"Result: {result}\")\n\n self.intermediate_steps.append((action_step, result))\n if is_finished_chain:\n logging.info(f\"Finished after {step_count} steps.\")\n status = \"finished\"\n break\n else:\n status = \"stopped\"\n\n return AgentOutput(\n text=response_text,\n agent_type=self.agent_type,\n status=status,\n total_tokens=total_token,\n total_cost=total_cost,\n intermediate_steps=self.intermediate_steps,\n max_iterations=max_iterations,\n )\n
Maximum number of iterations of reasoning steps, defaults to 10.
None Return
AgentOutput object.
Source code in libs/kotaemon/kotaemon/agents/react/agent.py
def stream(self, instruction, max_iterations=None):\n \"\"\"\n Stream the agent with the given instruction.\n\n Args:\n instruction: Instruction to run the agent with.\n max_iterations: Maximum number of iterations\n of reasoning steps, defaults to 10.\n\n Return:\n AgentOutput object.\n \"\"\"\n if not max_iterations:\n max_iterations = self.max_iterations\n assert max_iterations > 0\n\n self.clear()\n logging.info(f\"Running {self.name} with instruction: {instruction}\")\n print(f\"Running {self.name} with instruction: {instruction}\")\n total_cost = 0.0\n total_token = 0\n status = \"failed\"\n response_text = None\n\n for step_count in range(1, max_iterations + 1):\n prompt = self._compose_prompt(instruction)\n logging.info(f\"Prompt: {prompt}\")\n print(f\"Prompt: {prompt}\")\n response = self.llm(\n prompt, stop=[\"Observation:\"]\n ) # TODO: could cause bugs if llm doesn't have `stop` as a parameter\n response_text = response.text\n logging.info(f\"Response: {response_text}\")\n print(f\"Response: {response_text}\")\n action_step = self._parse_output(response_text)\n if action_step is None:\n raise ValueError(\"Invalid action\")\n is_finished_chain = isinstance(action_step, AgentFinish)\n if is_finished_chain:\n result = response_text\n if \"Final Answer:\" in response_text:\n result = response_text.split(\"Final Answer:\")[-1].strip()\n else:\n assert isinstance(action_step, AgentAction)\n action_name = action_step.tool\n tool_input = action_step.tool_input\n logging.info(f\"Action: {action_name}\")\n print(f\"Action: {action_name}\")\n logging.info(f\"Tool Input: {tool_input}\")\n print(f\"Tool Input: {tool_input}\")\n result = self._format_function_map()[action_name](tool_input)\n\n # trim the worker output to 1000 tokens, as we are appending\n # all workers' logs and it can exceed the token limit if we\n # don't limit each. Fix this number regarding to the LLM capacity.\n result = self._trim(result)\n logging.info(f\"Result: {result}\")\n print(f\"Result: {result}\")\n\n self.intermediate_steps.append((action_step, result))\n if is_finished_chain:\n logging.info(f\"Finished after {step_count} steps.\")\n status = \"finished\"\n yield AgentOutput(\n text=result,\n agent_type=self.agent_type,\n status=status,\n intermediate_steps=self.intermediate_steps[-1],\n )\n break\n else:\n yield AgentOutput(\n text=\"\",\n agent_type=self.agent_type,\n status=\"thinking\",\n intermediate_steps=self.intermediate_steps[-1],\n )\n\n else:\n status = \"stopped\"\n yield AgentOutput(\n text=\"\",\n agent_type=self.agent_type,\n status=status,\n intermediate_steps=self.intermediate_steps[-1],\n )\n\n return AgentOutput(\n text=response_text,\n agent_type=self.agent_type,\n status=status,\n total_tokens=total_token,\n total_cost=total_cost,\n intermediate_steps=self.intermediate_steps,\n max_iterations=max_iterations,\n )\n
Sequential ReactAgent class inherited from BaseAgent. Implementing ReAct agent paradigm https://arxiv.org/pdf/2210.03629.pdf
Source code in libs/kotaemon/kotaemon/agents/react/agent.py
class ReactAgent(BaseAgent):\n \"\"\"\n Sequential ReactAgent class inherited from BaseAgent.\n Implementing ReAct agent paradigm https://arxiv.org/pdf/2210.03629.pdf\n \"\"\"\n\n name: str = \"ReactAgent\"\n agent_type: AgentType = AgentType.react\n description: str = \"ReactAgent for answering multi-step reasoning questions\"\n llm: BaseLLM\n prompt_template: Optional[PromptTemplate] = None\n output_lang: str = \"English\"\n plugins: list[BaseTool] = Param(\n default_callback=lambda _: [], help=\"List of tools to be used in the agent. \"\n )\n examples: dict[str, str | list[str]] = Param(\n default_callback=lambda _: {}, help=\"Examples to be used in the agent. \"\n )\n intermediate_steps: list[tuple[AgentAction | AgentFinish, str]] = Param(\n default_callback=lambda _: [],\n help=\"List of AgentAction and observation (tool) output\",\n )\n max_iterations: int = 5\n strict_decode: bool = False\n max_context_length: int = Param(\n default=3000,\n help=\"Max context length for each tool output.\",\n )\n trim_func: TokenSplitter | None = None\n\n def _compose_plugin_description(self) -> str:\n \"\"\"\n Compose the worker prompt from the workers.\n\n Example:\n toolname1[input]: tool1 description\n toolname2[input]: tool2 description\n \"\"\"\n prompt = \"\"\n try:\n for plugin in self.plugins:\n prompt += f\"{plugin.name}[input]: {plugin.description}\\n\"\n except Exception:\n raise ValueError(\"Worker must have a name and description.\")\n return prompt\n\n def _construct_scratchpad(\n self, intermediate_steps: list[tuple[AgentAction | AgentFinish, str]] = []\n ) -> str:\n \"\"\"Construct the scratchpad that lets the agent continue its thought process.\"\"\"\n thoughts = \"\"\n for action, observation in intermediate_steps:\n thoughts += action.log\n thoughts += f\"\\nObservation: {observation}\\nThought:\"\n return thoughts\n\n def _parse_output(self, text: str) -> Optional[AgentAction | AgentFinish]:\n \"\"\"\n Parse text output from LLM for the next Action or Final Answer\n Using Regex to parse \"Action:\\n Action Input:\\n\" for the next Action\n Using FINAL_ANSWER_ACTION to parse Final Answer\n\n Args:\n text[str]: input text to parse\n \"\"\"\n includes_answer = FINAL_ANSWER_ACTION in text\n regex = (\n r\"Action\\s*\\d*\\s*:[\\s]*(.*?)[\\s]*Action\\s*\\d*\\s*Input\\s*\\d*\\s*:[\\s]*(.*)\"\n )\n action_match = re.search(regex, text, re.DOTALL)\n action_output: Optional[AgentAction | AgentFinish] = None\n if action_match:\n if includes_answer:\n raise Exception(\n \"Parsing LLM output produced both a final answer \"\n f\"and a parse-able action: {text}\"\n )\n action = action_match.group(1).strip()\n action_input = action_match.group(2)\n tool_input = action_input.strip(\" \")\n # ensure if its a well formed SQL query we don't remove any trailing \" chars\n if tool_input.startswith(\"SELECT \") is False:\n tool_input = tool_input.strip('\"')\n\n action_output = AgentAction(action, tool_input, text)\n\n elif includes_answer:\n action_output = AgentFinish(\n {\"output\": text.split(FINAL_ANSWER_ACTION)[-1].strip()}, text\n )\n else:\n if self.strict_decode:\n raise Exception(f\"Could not parse LLM output: `{text}`\")\n else:\n action_output = AgentFinish({\"output\": text}, text)\n\n return action_output\n\n def _compose_prompt(self, instruction) -> str:\n \"\"\"\n Compose the prompt from template, worker description, examples and instruction.\n \"\"\"\n agent_scratchpad = self._construct_scratchpad(self.intermediate_steps)\n tool_description = self._compose_plugin_description()\n tool_names = \", \".join([plugin.name for plugin in self.plugins])\n if self.prompt_template is None:\n from .prompt import zero_shot_react_prompt\n\n self.prompt_template = zero_shot_react_prompt\n return self.prompt_template.populate(\n instruction=instruction,\n agent_scratchpad=agent_scratchpad,\n tool_description=tool_description,\n tool_names=tool_names,\n lang=self.output_lang,\n )\n\n def _format_function_map(self) -> dict[str, BaseTool]:\n \"\"\"Format the function map for the open AI function API.\n\n Return:\n Dict[str, Callable]: The function map.\n \"\"\"\n # Map the function name to the real function object.\n function_map = {}\n for plugin in self.plugins:\n function_map[plugin.name] = plugin\n return function_map\n\n def _trim(self, text: str | Document) -> str:\n \"\"\"\n Trim the text to the maximum token length.\n \"\"\"\n evidence_trim_func = (\n self.trim_func\n if self.trim_func\n else TokenSplitter(\n chunk_size=self.max_context_length,\n chunk_overlap=0,\n separator=\" \",\n tokenizer=partial(\n tiktoken.encoding_for_model(\"gpt-3.5-turbo\").encode,\n allowed_special=set(),\n disallowed_special=\"all\",\n ),\n )\n )\n if isinstance(text, str):\n texts = evidence_trim_func([Document(text=text)])\n elif isinstance(text, Document):\n texts = evidence_trim_func([text])\n else:\n raise ValueError(\"Invalid text type to trim\")\n trim_text = texts[0].text\n logging.info(f\"len (trimmed): {len(trim_text)}\")\n return trim_text\n\n def clear(self):\n \"\"\"\n Clear and reset the agent.\n \"\"\"\n self.intermediate_steps = []\n\n def run(self, instruction, max_iterations=None) -> AgentOutput:\n \"\"\"\n Run the agent with the given instruction.\n\n Args:\n instruction: Instruction to run the agent with.\n max_iterations: Maximum number of iterations\n of reasoning steps, defaults to 10.\n\n Return:\n AgentOutput object.\n \"\"\"\n if not max_iterations:\n max_iterations = self.max_iterations\n assert max_iterations > 0\n\n self.clear()\n logging.info(f\"Running {self.name} with instruction: {instruction}\")\n total_cost = 0.0\n total_token = 0\n status = \"failed\"\n response_text = None\n\n for step_count in range(1, max_iterations + 1):\n prompt = self._compose_prompt(instruction)\n logging.info(f\"Prompt: {prompt}\")\n response = self.llm(\n prompt, stop=[\"Observation:\"]\n ) # could cause bugs if llm doesn't have `stop` as a parameter\n response_text = response.text\n logging.info(f\"Response: {response_text}\")\n action_step = self._parse_output(response_text)\n if action_step is None:\n raise ValueError(\"Invalid action\")\n is_finished_chain = isinstance(action_step, AgentFinish)\n if is_finished_chain:\n result = \"\"\n else:\n assert isinstance(action_step, AgentAction)\n action_name = action_step.tool\n tool_input = action_step.tool_input\n logging.info(f\"Action: {action_name}\")\n logging.info(f\"Tool Input: {tool_input}\")\n result = self._format_function_map()[action_name](tool_input)\n\n # trim the worker output to 1000 tokens, as we are appending\n # all workers' logs and it can exceed the token limit if we\n # don't limit each. Fix this number regarding to the LLM capacity.\n result = self._trim(result)\n logging.info(f\"Result: {result}\")\n\n self.intermediate_steps.append((action_step, result))\n if is_finished_chain:\n logging.info(f\"Finished after {step_count} steps.\")\n status = \"finished\"\n break\n else:\n status = \"stopped\"\n\n return AgentOutput(\n text=response_text,\n agent_type=self.agent_type,\n status=status,\n total_tokens=total_token,\n total_cost=total_cost,\n intermediate_steps=self.intermediate_steps,\n max_iterations=max_iterations,\n )\n\n def stream(self, instruction, max_iterations=None):\n \"\"\"\n Stream the agent with the given instruction.\n\n Args:\n instruction: Instruction to run the agent with.\n max_iterations: Maximum number of iterations\n of reasoning steps, defaults to 10.\n\n Return:\n AgentOutput object.\n \"\"\"\n if not max_iterations:\n max_iterations = self.max_iterations\n assert max_iterations > 0\n\n self.clear()\n logging.info(f\"Running {self.name} with instruction: {instruction}\")\n print(f\"Running {self.name} with instruction: {instruction}\")\n total_cost = 0.0\n total_token = 0\n status = \"failed\"\n response_text = None\n\n for step_count in range(1, max_iterations + 1):\n prompt = self._compose_prompt(instruction)\n logging.info(f\"Prompt: {prompt}\")\n print(f\"Prompt: {prompt}\")\n response = self.llm(\n prompt, stop=[\"Observation:\"]\n ) # TODO: could cause bugs if llm doesn't have `stop` as a parameter\n response_text = response.text\n logging.info(f\"Response: {response_text}\")\n print(f\"Response: {response_text}\")\n action_step = self._parse_output(response_text)\n if action_step is None:\n raise ValueError(\"Invalid action\")\n is_finished_chain = isinstance(action_step, AgentFinish)\n if is_finished_chain:\n result = response_text\n if \"Final Answer:\" in response_text:\n result = response_text.split(\"Final Answer:\")[-1].strip()\n else:\n assert isinstance(action_step, AgentAction)\n action_name = action_step.tool\n tool_input = action_step.tool_input\n logging.info(f\"Action: {action_name}\")\n print(f\"Action: {action_name}\")\n logging.info(f\"Tool Input: {tool_input}\")\n print(f\"Tool Input: {tool_input}\")\n result = self._format_function_map()[action_name](tool_input)\n\n # trim the worker output to 1000 tokens, as we are appending\n # all workers' logs and it can exceed the token limit if we\n # don't limit each. Fix this number regarding to the LLM capacity.\n result = self._trim(result)\n logging.info(f\"Result: {result}\")\n print(f\"Result: {result}\")\n\n self.intermediate_steps.append((action_step, result))\n if is_finished_chain:\n logging.info(f\"Finished after {step_count} steps.\")\n status = \"finished\"\n yield AgentOutput(\n text=result,\n agent_type=self.agent_type,\n status=status,\n intermediate_steps=self.intermediate_steps[-1],\n )\n break\n else:\n yield AgentOutput(\n text=\"\",\n agent_type=self.agent_type,\n status=\"thinking\",\n intermediate_steps=self.intermediate_steps[-1],\n )\n\n else:\n status = \"stopped\"\n yield AgentOutput(\n text=\"\",\n agent_type=self.agent_type,\n status=status,\n intermediate_steps=self.intermediate_steps[-1],\n )\n\n return AgentOutput(\n text=response_text,\n agent_type=self.agent_type,\n status=status,\n total_tokens=total_token,\n total_cost=total_cost,\n intermediate_steps=self.intermediate_steps,\n max_iterations=max_iterations,\n )\n
Maximum number of iterations of reasoning steps, defaults to 10.
None Return
AgentOutput object.
Source code in libs/kotaemon/kotaemon/agents/react/agent.py
def run(self, instruction, max_iterations=None) -> AgentOutput:\n \"\"\"\n Run the agent with the given instruction.\n\n Args:\n instruction: Instruction to run the agent with.\n max_iterations: Maximum number of iterations\n of reasoning steps, defaults to 10.\n\n Return:\n AgentOutput object.\n \"\"\"\n if not max_iterations:\n max_iterations = self.max_iterations\n assert max_iterations > 0\n\n self.clear()\n logging.info(f\"Running {self.name} with instruction: {instruction}\")\n total_cost = 0.0\n total_token = 0\n status = \"failed\"\n response_text = None\n\n for step_count in range(1, max_iterations + 1):\n prompt = self._compose_prompt(instruction)\n logging.info(f\"Prompt: {prompt}\")\n response = self.llm(\n prompt, stop=[\"Observation:\"]\n ) # could cause bugs if llm doesn't have `stop` as a parameter\n response_text = response.text\n logging.info(f\"Response: {response_text}\")\n action_step = self._parse_output(response_text)\n if action_step is None:\n raise ValueError(\"Invalid action\")\n is_finished_chain = isinstance(action_step, AgentFinish)\n if is_finished_chain:\n result = \"\"\n else:\n assert isinstance(action_step, AgentAction)\n action_name = action_step.tool\n tool_input = action_step.tool_input\n logging.info(f\"Action: {action_name}\")\n logging.info(f\"Tool Input: {tool_input}\")\n result = self._format_function_map()[action_name](tool_input)\n\n # trim the worker output to 1000 tokens, as we are appending\n # all workers' logs and it can exceed the token limit if we\n # don't limit each. Fix this number regarding to the LLM capacity.\n result = self._trim(result)\n logging.info(f\"Result: {result}\")\n\n self.intermediate_steps.append((action_step, result))\n if is_finished_chain:\n logging.info(f\"Finished after {step_count} steps.\")\n status = \"finished\"\n break\n else:\n status = \"stopped\"\n\n return AgentOutput(\n text=response_text,\n agent_type=self.agent_type,\n status=status,\n total_tokens=total_token,\n total_cost=total_cost,\n intermediate_steps=self.intermediate_steps,\n max_iterations=max_iterations,\n )\n
Maximum number of iterations of reasoning steps, defaults to 10.
None Return
AgentOutput object.
Source code in libs/kotaemon/kotaemon/agents/react/agent.py
def stream(self, instruction, max_iterations=None):\n \"\"\"\n Stream the agent with the given instruction.\n\n Args:\n instruction: Instruction to run the agent with.\n max_iterations: Maximum number of iterations\n of reasoning steps, defaults to 10.\n\n Return:\n AgentOutput object.\n \"\"\"\n if not max_iterations:\n max_iterations = self.max_iterations\n assert max_iterations > 0\n\n self.clear()\n logging.info(f\"Running {self.name} with instruction: {instruction}\")\n print(f\"Running {self.name} with instruction: {instruction}\")\n total_cost = 0.0\n total_token = 0\n status = \"failed\"\n response_text = None\n\n for step_count in range(1, max_iterations + 1):\n prompt = self._compose_prompt(instruction)\n logging.info(f\"Prompt: {prompt}\")\n print(f\"Prompt: {prompt}\")\n response = self.llm(\n prompt, stop=[\"Observation:\"]\n ) # TODO: could cause bugs if llm doesn't have `stop` as a parameter\n response_text = response.text\n logging.info(f\"Response: {response_text}\")\n print(f\"Response: {response_text}\")\n action_step = self._parse_output(response_text)\n if action_step is None:\n raise ValueError(\"Invalid action\")\n is_finished_chain = isinstance(action_step, AgentFinish)\n if is_finished_chain:\n result = response_text\n if \"Final Answer:\" in response_text:\n result = response_text.split(\"Final Answer:\")[-1].strip()\n else:\n assert isinstance(action_step, AgentAction)\n action_name = action_step.tool\n tool_input = action_step.tool_input\n logging.info(f\"Action: {action_name}\")\n print(f\"Action: {action_name}\")\n logging.info(f\"Tool Input: {tool_input}\")\n print(f\"Tool Input: {tool_input}\")\n result = self._format_function_map()[action_name](tool_input)\n\n # trim the worker output to 1000 tokens, as we are appending\n # all workers' logs and it can exceed the token limit if we\n # don't limit each. Fix this number regarding to the LLM capacity.\n result = self._trim(result)\n logging.info(f\"Result: {result}\")\n print(f\"Result: {result}\")\n\n self.intermediate_steps.append((action_step, result))\n if is_finished_chain:\n logging.info(f\"Finished after {step_count} steps.\")\n status = \"finished\"\n yield AgentOutput(\n text=result,\n agent_type=self.agent_type,\n status=status,\n intermediate_steps=self.intermediate_steps[-1],\n )\n break\n else:\n yield AgentOutput(\n text=\"\",\n agent_type=self.agent_type,\n status=\"thinking\",\n intermediate_steps=self.intermediate_steps[-1],\n )\n\n else:\n status = \"stopped\"\n yield AgentOutput(\n text=\"\",\n agent_type=self.agent_type,\n status=status,\n intermediate_steps=self.intermediate_steps[-1],\n )\n\n return AgentOutput(\n text=response_text,\n agent_type=self.agent_type,\n status=status,\n total_tokens=total_token,\n total_cost=total_cost,\n intermediate_steps=self.intermediate_steps,\n max_iterations=max_iterations,\n )\n
Source code in libs/kotaemon/kotaemon/agents/tools/base.py
class BaseTool(BaseComponent):\n name: str\n \"\"\"The unique name of the tool that clearly communicates its purpose.\"\"\"\n description: str\n \"\"\"Description used to tell the model how/when/why to use the tool.\n You can provide few-shot examples as a part of the description. This will be\n input to the prompt of LLM.\n \"\"\"\n args_schema: Optional[Type[BaseModel]] = None\n \"\"\"Pydantic model class to validate and parse the tool's input arguments.\"\"\"\n verbose: bool = False\n \"\"\"Whether to log the tool's progress.\"\"\"\n handle_tool_error: Optional[\n Union[bool, str, Callable[[ToolException], str]]\n ] = False\n \"\"\"Handle the content of the ToolException thrown.\"\"\"\n\n def _parse_input(\n self,\n tool_input: Union[str, Dict],\n ) -> Union[str, Dict[str, Any]]:\n \"\"\"Convert tool input to pydantic model.\"\"\"\n args_schema = self.args_schema\n if isinstance(tool_input, str):\n if args_schema is not None:\n key_ = next(iter(args_schema.model_fields.keys()))\n args_schema.validate({key_: tool_input})\n return tool_input\n else:\n if args_schema is not None:\n result = args_schema.parse_obj(tool_input)\n return {k: v for k, v in result.dict().items() if k in tool_input}\n return tool_input\n\n def _run_tool(\n self,\n *args: Any,\n **kwargs: Any,\n ) -> Any:\n \"\"\"Call tool.\"\"\"\n raise NotImplementedError(f\"_run_tool is not implemented for {self.name}\")\n\n def _to_args_and_kwargs(self, tool_input: Union[str, Dict]) -> Tuple[Tuple, Dict]:\n # For backwards compatibility, if run_input is a string,\n # pass as a positional argument.\n if isinstance(tool_input, str):\n return (tool_input,), {}\n else:\n return (), tool_input\n\n def _handle_tool_error(self, e: ToolException) -> Any:\n \"\"\"Handle the content of the ToolException thrown.\"\"\"\n observation = None\n if not self.handle_tool_error:\n raise e\n elif isinstance(self.handle_tool_error, bool):\n if e.args:\n observation = e.args[0]\n else:\n observation = \"Tool execution error\"\n elif isinstance(self.handle_tool_error, str):\n observation = self.handle_tool_error\n elif callable(self.handle_tool_error):\n observation = self.handle_tool_error(e)\n else:\n raise ValueError(\n f\"Got unexpected type of `handle_tool_error`. Expected bool, str \"\n f\"or callable. Received: {self.handle_tool_error}\"\n )\n return observation\n\n def to_langchain_format(self) -> LCTool:\n \"\"\"Convert this tool to Langchain format to use with its agent\"\"\"\n return LCTool(name=self.name, description=self.description, func=self.run)\n\n def run(\n self,\n tool_input: Union[str, Dict],\n verbose: Optional[bool] = None,\n **kwargs: Any,\n ) -> Any:\n \"\"\"Run the tool.\"\"\"\n parsed_input = self._parse_input(tool_input)\n # TODO (verbose_): Add logging\n try:\n tool_args, tool_kwargs = self._to_args_and_kwargs(parsed_input)\n call_kwargs = {**kwargs, **tool_kwargs}\n observation = self._run_tool(*tool_args, **call_kwargs)\n except ToolException as e:\n observation = self._handle_tool_error(e)\n return observation\n else:\n return observation\n\n @classmethod\n def from_langchain_format(cls, langchain_tool: LCTool) -> \"BaseTool\":\n \"\"\"Wrapper for Langchain Tool\"\"\"\n new_tool = BaseTool(\n name=langchain_tool.name, description=langchain_tool.description\n )\n new_tool._run_tool = langchain_tool._run # type: ignore\n return new_tool\n
Description used to tell the model how/when/why to use the tool. You can provide few-shot examples as a part of the description. This will be input to the prompt of LLM.
Convert this tool to Langchain format to use with its agent
Source code in libs/kotaemon/kotaemon/agents/tools/base.py
def to_langchain_format(self) -> LCTool:\n \"\"\"Convert this tool to Langchain format to use with its agent\"\"\"\n return LCTool(name=self.name, description=self.description, func=self.run)\n
Wrapper around other BaseComponent to use it as a tool
Parameters:
Name Type Description Default component
BaseComponent-based component to wrap
required postprocessor
Optional postprocessor for the component output
required Source code in libs/kotaemon/kotaemon/agents/tools/base.py
class ComponentTool(BaseTool):\n \"\"\"Wrapper around other BaseComponent to use it as a tool\n\n Args:\n component: BaseComponent-based component to wrap\n postprocessor: Optional postprocessor for the component output\n \"\"\"\n\n component: BaseComponent\n postprocessor: Optional[Callable] = None\n\n def _run_tool(self, *args: Any, **kwargs: Any) -> Any:\n output = self.component(*args, **kwargs)\n if self.postprocessor:\n output = self.postprocessor(output)\n\n return output\n
Tool that adds the capability to query the Wikipedia API.
Source code in libs/kotaemon/kotaemon/agents/tools/wikipedia.py
class WikipediaTool(BaseTool):\n \"\"\"Tool that adds the capability to query the Wikipedia API.\"\"\"\n\n name: str = \"wikipedia\"\n description: str = (\n \"Search engine from Wikipedia, retrieving relevant wiki page. \"\n \"Useful when you need to get holistic knowledge about people, \"\n \"places, companies, historical events, or other subjects. \"\n \"Input should be a search query.\"\n )\n args_schema: Optional[Type[BaseModel]] = WikipediaArgs\n doc_store: Any = None\n\n def _run_tool(self, query: AnyStr) -> AnyStr:\n if not self.doc_store:\n self.doc_store = Wiki()\n tool = self.doc_store\n evidence = tool.search(query)\n return evidence\n
An optional exception that tool throws when execution error occurs.
When this exception is thrown, the agent will not stop working, but will handle the exception according to the handle_tool_error variable of the tool, and the processing result will be returned to the agent as observation, and printed in red on the console.
Source code in libs/kotaemon/kotaemon/agents/tools/base.py
class ToolException(Exception):\n \"\"\"An optional exception that tool throws when execution error occurs.\n\n When this exception is thrown, the agent will not stop working,\n but will handle the exception according to the handle_tool_error\n variable of the tool, and the processing result will be returned\n to the agent as observation, and printed in red on the console.\n \"\"\"\n
Source code in libs/kotaemon/kotaemon/agents/tools/base.py
class BaseTool(BaseComponent):\n name: str\n \"\"\"The unique name of the tool that clearly communicates its purpose.\"\"\"\n description: str\n \"\"\"Description used to tell the model how/when/why to use the tool.\n You can provide few-shot examples as a part of the description. This will be\n input to the prompt of LLM.\n \"\"\"\n args_schema: Optional[Type[BaseModel]] = None\n \"\"\"Pydantic model class to validate and parse the tool's input arguments.\"\"\"\n verbose: bool = False\n \"\"\"Whether to log the tool's progress.\"\"\"\n handle_tool_error: Optional[\n Union[bool, str, Callable[[ToolException], str]]\n ] = False\n \"\"\"Handle the content of the ToolException thrown.\"\"\"\n\n def _parse_input(\n self,\n tool_input: Union[str, Dict],\n ) -> Union[str, Dict[str, Any]]:\n \"\"\"Convert tool input to pydantic model.\"\"\"\n args_schema = self.args_schema\n if isinstance(tool_input, str):\n if args_schema is not None:\n key_ = next(iter(args_schema.model_fields.keys()))\n args_schema.validate({key_: tool_input})\n return tool_input\n else:\n if args_schema is not None:\n result = args_schema.parse_obj(tool_input)\n return {k: v for k, v in result.dict().items() if k in tool_input}\n return tool_input\n\n def _run_tool(\n self,\n *args: Any,\n **kwargs: Any,\n ) -> Any:\n \"\"\"Call tool.\"\"\"\n raise NotImplementedError(f\"_run_tool is not implemented for {self.name}\")\n\n def _to_args_and_kwargs(self, tool_input: Union[str, Dict]) -> Tuple[Tuple, Dict]:\n # For backwards compatibility, if run_input is a string,\n # pass as a positional argument.\n if isinstance(tool_input, str):\n return (tool_input,), {}\n else:\n return (), tool_input\n\n def _handle_tool_error(self, e: ToolException) -> Any:\n \"\"\"Handle the content of the ToolException thrown.\"\"\"\n observation = None\n if not self.handle_tool_error:\n raise e\n elif isinstance(self.handle_tool_error, bool):\n if e.args:\n observation = e.args[0]\n else:\n observation = \"Tool execution error\"\n elif isinstance(self.handle_tool_error, str):\n observation = self.handle_tool_error\n elif callable(self.handle_tool_error):\n observation = self.handle_tool_error(e)\n else:\n raise ValueError(\n f\"Got unexpected type of `handle_tool_error`. Expected bool, str \"\n f\"or callable. Received: {self.handle_tool_error}\"\n )\n return observation\n\n def to_langchain_format(self) -> LCTool:\n \"\"\"Convert this tool to Langchain format to use with its agent\"\"\"\n return LCTool(name=self.name, description=self.description, func=self.run)\n\n def run(\n self,\n tool_input: Union[str, Dict],\n verbose: Optional[bool] = None,\n **kwargs: Any,\n ) -> Any:\n \"\"\"Run the tool.\"\"\"\n parsed_input = self._parse_input(tool_input)\n # TODO (verbose_): Add logging\n try:\n tool_args, tool_kwargs = self._to_args_and_kwargs(parsed_input)\n call_kwargs = {**kwargs, **tool_kwargs}\n observation = self._run_tool(*tool_args, **call_kwargs)\n except ToolException as e:\n observation = self._handle_tool_error(e)\n return observation\n else:\n return observation\n\n @classmethod\n def from_langchain_format(cls, langchain_tool: LCTool) -> \"BaseTool\":\n \"\"\"Wrapper for Langchain Tool\"\"\"\n new_tool = BaseTool(\n name=langchain_tool.name, description=langchain_tool.description\n )\n new_tool._run_tool = langchain_tool._run # type: ignore\n return new_tool\n
Description used to tell the model how/when/why to use the tool. You can provide few-shot examples as a part of the description. This will be input to the prompt of LLM.
Convert this tool to Langchain format to use with its agent
Source code in libs/kotaemon/kotaemon/agents/tools/base.py
def to_langchain_format(self) -> LCTool:\n \"\"\"Convert this tool to Langchain format to use with its agent\"\"\"\n return LCTool(name=self.name, description=self.description, func=self.run)\n
Wrapper around other BaseComponent to use it as a tool
Parameters:
Name Type Description Default component
BaseComponent-based component to wrap
required postprocessor
Optional postprocessor for the component output
required Source code in libs/kotaemon/kotaemon/agents/tools/base.py
class ComponentTool(BaseTool):\n \"\"\"Wrapper around other BaseComponent to use it as a tool\n\n Args:\n component: BaseComponent-based component to wrap\n postprocessor: Optional postprocessor for the component output\n \"\"\"\n\n component: BaseComponent\n postprocessor: Optional[Callable] = None\n\n def _run_tool(self, *args: Any, **kwargs: Any) -> Any:\n output = self.component(*args, **kwargs)\n if self.postprocessor:\n output = self.postprocessor(output)\n\n return output\n
Source code in libs/kotaemon/kotaemon/agents/tools/wikipedia.py
class Wiki:\n \"\"\"Wrapper around wikipedia API.\"\"\"\n\n def __init__(self) -> None:\n \"\"\"Check that wikipedia package is installed.\"\"\"\n try:\n import wikipedia # noqa: F401\n except ImportError:\n raise ValueError(\n \"Could not import wikipedia python package. \"\n \"Please install it with `pip install wikipedia`.\"\n )\n\n def search(self, search: str) -> Union[str, Document]:\n \"\"\"Try to search for wiki page.\n\n If page exists, return the page summary, and a PageWithLookups object.\n If page does not exist, return similar entries.\n \"\"\"\n import wikipedia\n\n try:\n page_content = wikipedia.page(search).content\n url = wikipedia.page(search).url\n result: Union[str, Document] = Document(\n text=page_content, metadata={\"page\": url}\n )\n except wikipedia.PageError:\n result = f\"Could not find [{search}]. Similar: {wikipedia.search(search)}\"\n except wikipedia.DisambiguationError:\n result = f\"Could not find [{search}]. Similar: {wikipedia.search(search)}\"\n return result\n
If page exists, return the page summary, and a PageWithLookups object. If page does not exist, return similar entries.
Source code in libs/kotaemon/kotaemon/agents/tools/wikipedia.py
def search(self, search: str) -> Union[str, Document]:\n \"\"\"Try to search for wiki page.\n\n If page exists, return the page summary, and a PageWithLookups object.\n If page does not exist, return similar entries.\n \"\"\"\n import wikipedia\n\n try:\n page_content = wikipedia.page(search).content\n url = wikipedia.page(search).url\n result: Union[str, Document] = Document(\n text=page_content, metadata={\"page\": url}\n )\n except wikipedia.PageError:\n result = f\"Could not find [{search}]. Similar: {wikipedia.search(search)}\"\n except wikipedia.DisambiguationError:\n result = f\"Could not find [{search}]. Similar: {wikipedia.search(search)}\"\n return result\n
Tool that adds the capability to query the Wikipedia API.
Source code in libs/kotaemon/kotaemon/agents/tools/wikipedia.py
class WikipediaTool(BaseTool):\n \"\"\"Tool that adds the capability to query the Wikipedia API.\"\"\"\n\n name: str = \"wikipedia\"\n description: str = (\n \"Search engine from Wikipedia, retrieving relevant wiki page. \"\n \"Useful when you need to get holistic knowledge about people, \"\n \"places, companies, historical events, or other subjects. \"\n \"Input should be a search query.\"\n )\n args_schema: Optional[Type[BaseModel]] = WikipediaArgs\n doc_store: Any = None\n\n def _run_tool(self, query: AnyStr) -> AnyStr:\n if not self.doc_store:\n self.doc_store = Wiki()\n tool = self.doc_store\n evidence = tool.search(query)\n return evidence\n
A component is a class that can be used to compose a pipeline.
Benefits of component
Auto caching, logging
Allow deployment
For each component, the spirit is
Tolerate multiple input types, e.g. str, Document, List[str], List[Document]
Enforce single output type. Hence, the output type of a component should be
as generic as possible.
Source code in libs/kotaemon/kotaemon/base/component.py
class BaseComponent(Function):\n \"\"\"A component is a class that can be used to compose a pipeline.\n\n !!! tip \"Benefits of component\"\n - Auto caching, logging\n - Allow deployment\n\n !!! tip \"For each component, the spirit is\"\n - Tolerate multiple input types, e.g. str, Document, List[str], List[Document]\n - Enforce single output type. Hence, the output type of a component should be\n as generic as possible.\n \"\"\"\n\n inflow = None\n\n def flow(self):\n if self.inflow is None:\n raise ValueError(\"No inflow provided.\")\n\n if not isinstance(self.inflow, BaseComponent):\n raise ValueError(\n f\"inflow must be a BaseComponent, found {type(self.inflow)}\"\n )\n\n return self.__call__(self.inflow.flow())\n\n def set_output_queue(self, queue):\n self._queue = queue\n for name in self._ff_nodes:\n node = getattr(self, name)\n if isinstance(node, BaseComponent):\n node.set_output_queue(queue)\n\n def report_output(self, output: Optional[Document]):\n if self._queue is not None:\n self._queue.put_nowait(output)\n\n def invoke(self, *args, **kwargs) -> Document | list[Document] | None:\n ...\n\n async def ainvoke(self, *args, **kwargs) -> Document | list[Document] | None:\n ...\n\n def stream(self, *args, **kwargs) -> Iterator[Document] | None:\n ...\n\n def astream(self, *args, **kwargs) -> AsyncGenerator[Document, None] | None:\n ...\n\n @abstractmethod\n def run(\n self, *args, **kwargs\n ) -> Document | list[Document] | Iterator[Document] | None | Any:\n \"\"\"Run the component.\"\"\"\n ...\n
Base document class, mostly inherited from Document class from llama-index.
This class accept one positional argument content of an arbitrary type, which will store the raw content of the document. If specified, the class will use content to initialize the base llama_index class.
the channel to show the document. Optional.: - chat: show in chat message - info: show in information panel - index: show in index panel - debug: show in debug panel
Source code in libs/kotaemon/kotaemon/base/schema.py
class Document(BaseDocument):\n \"\"\"\n Base document class, mostly inherited from Document class from llama-index.\n\n This class accept one positional argument `content` of an arbitrary type, which will\n store the raw content of the document. If specified, the class will use\n `content` to initialize the base llama_index class.\n\n Attributes:\n content: raw content of the document, can be anything\n source: id of the source of the Document. Optional.\n channel: the channel to show the document. Optional.:\n - chat: show in chat message\n - info: show in information panel\n - index: show in index panel\n - debug: show in debug panel\n \"\"\"\n\n content: Any = None\n source: Optional[str] = None\n channel: Optional[Literal[\"chat\", \"info\", \"index\", \"debug\", \"plot\"]] = None\n\n def __init__(self, content: Optional[Any] = None, *args, **kwargs):\n if content is None:\n if kwargs.get(\"text\", None) is not None:\n kwargs[\"content\"] = kwargs[\"text\"]\n elif kwargs.get(\"embedding\", None) is not None:\n kwargs[\"content\"] = kwargs[\"embedding\"]\n # default text indicating this document only contains embedding\n kwargs[\"text\"] = \"<EMBEDDING>\"\n elif isinstance(content, Document):\n # TODO: simplify the Document class\n temp_ = content.dict()\n temp_.update(kwargs)\n kwargs = temp_\n else:\n kwargs[\"content\"] = content\n if content:\n kwargs[\"text\"] = str(content)\n else:\n kwargs[\"text\"] = \"\"\n super().__init__(*args, **kwargs)\n\n def __bool__(self):\n return bool(self.content)\n\n @classmethod\n def example(cls) -> \"Document\":\n document = Document(\n text=SAMPLE_TEXT,\n metadata={\"filename\": \"README.md\", \"category\": \"codebase\"},\n )\n return document\n\n def to_haystack_format(self) -> \"HaystackDocument\":\n \"\"\"Convert struct to Haystack document format.\"\"\"\n from haystack.schema import Document as HaystackDocument\n\n metadata = self.metadata or {}\n text = self.text\n return HaystackDocument(content=text, meta=metadata)\n\n def __str__(self):\n return str(self.content)\n
Subclass of Document which must contains embedding
Use this if you want to enforce component's IOs to must contain embedding.
Source code in libs/kotaemon/kotaemon/base/schema.py
class DocumentWithEmbedding(Document):\n \"\"\"Subclass of Document which must contains embedding\n\n Use this if you want to enforce component's IOs to must contain embedding.\n \"\"\"\n\n def __init__(self, embedding: list[float], *args, **kwargs):\n kwargs[\"embedding\"] = embedding\n super().__init__(*args, **kwargs)\n
Subclass of Document with retrieval-related information
Attributes:
Name Type Description scorefloat
score of the document (from 0.0 to 1.0)
retrieval_metadatadict
metadata from the retrieval process, can be used by different components in a retrieved pipeline to communicate with each other
Source code in libs/kotaemon/kotaemon/base/schema.py
class RetrievedDocument(Document):\n \"\"\"Subclass of Document with retrieval-related information\n\n Attributes:\n score (float): score of the document (from 0.0 to 1.0)\n retrieval_metadata (dict): metadata from the retrieval process, can be used\n by different components in a retrieved pipeline to communicate with each\n other\n \"\"\"\n\n score: float = Field(default=0.0)\n retrieval_metadata: dict = Field(default={})\n
A component is a class that can be used to compose a pipeline.
Benefits of component
Auto caching, logging
Allow deployment
For each component, the spirit is
Tolerate multiple input types, e.g. str, Document, List[str], List[Document]
Enforce single output type. Hence, the output type of a component should be
as generic as possible.
Source code in libs/kotaemon/kotaemon/base/component.py
class BaseComponent(Function):\n \"\"\"A component is a class that can be used to compose a pipeline.\n\n !!! tip \"Benefits of component\"\n - Auto caching, logging\n - Allow deployment\n\n !!! tip \"For each component, the spirit is\"\n - Tolerate multiple input types, e.g. str, Document, List[str], List[Document]\n - Enforce single output type. Hence, the output type of a component should be\n as generic as possible.\n \"\"\"\n\n inflow = None\n\n def flow(self):\n if self.inflow is None:\n raise ValueError(\"No inflow provided.\")\n\n if not isinstance(self.inflow, BaseComponent):\n raise ValueError(\n f\"inflow must be a BaseComponent, found {type(self.inflow)}\"\n )\n\n return self.__call__(self.inflow.flow())\n\n def set_output_queue(self, queue):\n self._queue = queue\n for name in self._ff_nodes:\n node = getattr(self, name)\n if isinstance(node, BaseComponent):\n node.set_output_queue(queue)\n\n def report_output(self, output: Optional[Document]):\n if self._queue is not None:\n self._queue.put_nowait(output)\n\n def invoke(self, *args, **kwargs) -> Document | list[Document] | None:\n ...\n\n async def ainvoke(self, *args, **kwargs) -> Document | list[Document] | None:\n ...\n\n def stream(self, *args, **kwargs) -> Iterator[Document] | None:\n ...\n\n def astream(self, *args, **kwargs) -> AsyncGenerator[Document, None] | None:\n ...\n\n @abstractmethod\n def run(\n self, *args, **kwargs\n ) -> Document | list[Document] | Iterator[Document] | None | Any:\n \"\"\"Run the component.\"\"\"\n ...\n
Base document class, mostly inherited from Document class from llama-index.
This class accept one positional argument content of an arbitrary type, which will store the raw content of the document. If specified, the class will use content to initialize the base llama_index class.
the channel to show the document. Optional.: - chat: show in chat message - info: show in information panel - index: show in index panel - debug: show in debug panel
Source code in libs/kotaemon/kotaemon/base/schema.py
class Document(BaseDocument):\n \"\"\"\n Base document class, mostly inherited from Document class from llama-index.\n\n This class accept one positional argument `content` of an arbitrary type, which will\n store the raw content of the document. If specified, the class will use\n `content` to initialize the base llama_index class.\n\n Attributes:\n content: raw content of the document, can be anything\n source: id of the source of the Document. Optional.\n channel: the channel to show the document. Optional.:\n - chat: show in chat message\n - info: show in information panel\n - index: show in index panel\n - debug: show in debug panel\n \"\"\"\n\n content: Any = None\n source: Optional[str] = None\n channel: Optional[Literal[\"chat\", \"info\", \"index\", \"debug\", \"plot\"]] = None\n\n def __init__(self, content: Optional[Any] = None, *args, **kwargs):\n if content is None:\n if kwargs.get(\"text\", None) is not None:\n kwargs[\"content\"] = kwargs[\"text\"]\n elif kwargs.get(\"embedding\", None) is not None:\n kwargs[\"content\"] = kwargs[\"embedding\"]\n # default text indicating this document only contains embedding\n kwargs[\"text\"] = \"<EMBEDDING>\"\n elif isinstance(content, Document):\n # TODO: simplify the Document class\n temp_ = content.dict()\n temp_.update(kwargs)\n kwargs = temp_\n else:\n kwargs[\"content\"] = content\n if content:\n kwargs[\"text\"] = str(content)\n else:\n kwargs[\"text\"] = \"\"\n super().__init__(*args, **kwargs)\n\n def __bool__(self):\n return bool(self.content)\n\n @classmethod\n def example(cls) -> \"Document\":\n document = Document(\n text=SAMPLE_TEXT,\n metadata={\"filename\": \"README.md\", \"category\": \"codebase\"},\n )\n return document\n\n def to_haystack_format(self) -> \"HaystackDocument\":\n \"\"\"Convert struct to Haystack document format.\"\"\"\n from haystack.schema import Document as HaystackDocument\n\n metadata = self.metadata or {}\n text = self.text\n return HaystackDocument(content=text, meta=metadata)\n\n def __str__(self):\n return str(self.content)\n
Subclass of Document which must contains embedding
Use this if you want to enforce component's IOs to must contain embedding.
Source code in libs/kotaemon/kotaemon/base/schema.py
class DocumentWithEmbedding(Document):\n \"\"\"Subclass of Document which must contains embedding\n\n Use this if you want to enforce component's IOs to must contain embedding.\n \"\"\"\n\n def __init__(self, embedding: list[float], *args, **kwargs):\n kwargs[\"embedding\"] = embedding\n super().__init__(*args, **kwargs)\n
Subclass of Document with retrieval-related information
Attributes:
Name Type Description scorefloat
score of the document (from 0.0 to 1.0)
retrieval_metadatadict
metadata from the retrieval process, can be used by different components in a retrieved pipeline to communicate with each other
Source code in libs/kotaemon/kotaemon/base/schema.py
class RetrievedDocument(Document):\n \"\"\"Subclass of Document with retrieval-related information\n\n Attributes:\n score (float): score of the document (from 0.0 to 1.0)\n retrieval_metadata (dict): metadata from the retrieval process, can be used\n by different components in a retrieved pipeline to communicate with each\n other\n \"\"\"\n\n score: float = Field(default=0.0)\n retrieval_metadata: dict = Field(default={})\n
The response to the message. If None, no response is sent.
Source code in libs/kotaemon/kotaemon/chatbot/base.py
def run(self, message: HumanMessage) -> Optional[BaseMessage]:\n \"\"\"Chat, given a message, return a response\n\n Args:\n message: The message to respond to\n\n Returns:\n The response to the message. If None, no response is sent.\n \"\"\"\n user_message = (\n HumanMessage(content=message) if isinstance(message, str) else message\n )\n self.history.append(user_message)\n\n output = self.bot(self.history).text\n output_message = None\n if output is not None:\n output_message = AIMessage(content=output)\n self.history.append(output_message)\n\n return output_message\n
Simple text respondent chatbot that essentially wraps around a chat LLM
Source code in libs/kotaemon/kotaemon/chatbot/simple_respondent.py
class SimpleRespondentChatbot(BaseChatBot):\n \"\"\"Simple text respondent chatbot that essentially wraps around a chat LLM\"\"\"\n\n llm: ChatLLM\n\n def _get_message(self) -> str:\n return self.llm(self.history).text\n
The response to the message. If None, no response is sent.
Source code in libs/kotaemon/kotaemon/chatbot/base.py
def run(self, message: HumanMessage) -> Optional[BaseMessage]:\n \"\"\"Chat, given a message, return a response\n\n Args:\n message: The message to respond to\n\n Returns:\n The response to the message. If None, no response is sent.\n \"\"\"\n user_message = (\n HumanMessage(content=message) if isinstance(message, str) else message\n )\n self.history.append(user_message)\n\n output = self.bot(self.history).text\n output_message = None\n if output is not None:\n output_message = AIMessage(content=output)\n self.history.append(output_message)\n\n return output_message\n
Simple text respondent chatbot that essentially wraps around a chat LLM
Source code in libs/kotaemon/kotaemon/chatbot/simple_respondent.py
class SimpleRespondentChatbot(BaseChatBot):\n \"\"\"Simple text respondent chatbot that essentially wraps around a chat LLM\"\"\"\n\n llm: ChatLLM\n\n def _get_message(self) -> str:\n return self.llm(self.history).text\n
An Embeddings component that uses an OpenAI API compatible endpoint.
Attributes:
Name Type Description endpoint_urlstr
The url of an OpenAI API compatible endpoint.
Source code in libs/kotaemon/kotaemon/embeddings/endpoint_based.py
class EndpointEmbeddings(BaseEmbeddings):\n \"\"\"\n An Embeddings component that uses an OpenAI API compatible endpoint.\n\n Attributes:\n endpoint_url (str): The url of an OpenAI API compatible endpoint.\n \"\"\"\n\n endpoint_url: str\n\n def run(\n self, text: str | list[str] | Document | list[Document]\n ) -> list[DocumentWithEmbedding]:\n \"\"\"\n Generate embeddings from text Args:\n text (str | list[str] | Document | list[Document]): text to generate\n embeddings from\n Returns:\n list[DocumentWithEmbedding]: embeddings\n \"\"\"\n if not isinstance(text, list):\n text = [text]\n\n outputs = []\n\n for item in text:\n response = requests.post(\n self.endpoint_url, json={\"input\": str(item)}\n ).json()\n outputs.append(\n DocumentWithEmbedding(\n text=str(item),\n embedding=response[\"data\"][0][\"embedding\"],\n total_tokens=response[\"usage\"][\"total_tokens\"],\n prompt_tokens=response[\"usage\"][\"prompt_tokens\"],\n )\n )\n\n return outputs\n
Source code in libs/kotaemon/kotaemon/embeddings/openai.py
class OpenAIEmbeddings(BaseOpenAIEmbeddings):\n \"\"\"OpenAI chat model\"\"\"\n\n base_url: Optional[str] = Param(None, help=\"OpenAI base URL\")\n organization: Optional[str] = Param(None, help=\"OpenAI organization\")\n model: str = Param(\n None,\n help=(\n \"ID of the model to use. You can go to [Model overview](https://platform.\"\n \"openai.com/docs/models/overview) to see the available models.\"\n ),\n required=True,\n )\n\n def prepare_client(self, async_version: bool = False):\n \"\"\"Get the OpenAI client\n\n Args:\n async_version (bool): Whether to get the async version of the client\n \"\"\"\n params = {\n \"api_key\": self.api_key,\n \"organization\": self.organization,\n \"base_url\": self.base_url,\n \"timeout\": self.timeout,\n \"max_retries\": self.max_retries_,\n }\n if async_version:\n from openai import AsyncOpenAI\n\n return AsyncOpenAI(**params)\n\n from openai import OpenAI\n\n return OpenAI(**params)\n\n @retry(\n retry=retry_if_not_exception_type(\n (openai.NotFoundError, openai.BadRequestError)\n ),\n wait=wait_random_exponential(min=1, max=40),\n stop=stop_after_attempt(6),\n )\n def openai_response(self, client, **kwargs):\n \"\"\"Get the openai response\"\"\"\n params: dict = {\n \"model\": self.model,\n }\n if self.dimensions:\n params[\"dimensions\"] = self.dimensions\n params.update(kwargs)\n\n return client.embeddings.create(**params)\n
An Embeddings component that uses an OpenAI API compatible endpoint.
Attributes:
Name Type Description endpoint_urlstr
The url of an OpenAI API compatible endpoint.
Source code in libs/kotaemon/kotaemon/embeddings/endpoint_based.py
class EndpointEmbeddings(BaseEmbeddings):\n \"\"\"\n An Embeddings component that uses an OpenAI API compatible endpoint.\n\n Attributes:\n endpoint_url (str): The url of an OpenAI API compatible endpoint.\n \"\"\"\n\n endpoint_url: str\n\n def run(\n self, text: str | list[str] | Document | list[Document]\n ) -> list[DocumentWithEmbedding]:\n \"\"\"\n Generate embeddings from text Args:\n text (str | list[str] | Document | list[Document]): text to generate\n embeddings from\n Returns:\n list[DocumentWithEmbedding]: embeddings\n \"\"\"\n if not isinstance(text, list):\n text = [text]\n\n outputs = []\n\n for item in text:\n response = requests.post(\n self.endpoint_url, json={\"input\": str(item)}\n ).json()\n outputs.append(\n DocumentWithEmbedding(\n text=str(item),\n embedding=response[\"data\"][0][\"embedding\"],\n total_tokens=response[\"usage\"][\"total_tokens\"],\n prompt_tokens=response[\"usage\"][\"prompt_tokens\"],\n )\n )\n\n return outputs\n
Base interface for OpenAI embedding model, using the openai library.
This class exposes the parameters in resources.Chat. To subclass this class:
- Implement the `prepare_client` method to return the OpenAI client\n- Implement the `openai_response` method to return the OpenAI response\n- Implement the params relate to the OpenAI client\n
Source code in libs/kotaemon/kotaemon/embeddings/openai.py
class BaseOpenAIEmbeddings(BaseEmbeddings):\n \"\"\"Base interface for OpenAI embedding model, using the openai library.\n\n This class exposes the parameters in resources.Chat. To subclass this class:\n\n - Implement the `prepare_client` method to return the OpenAI client\n - Implement the `openai_response` method to return the OpenAI response\n - Implement the params relate to the OpenAI client\n \"\"\"\n\n _dependencies = [\"openai\"]\n\n api_key: str = Param(None, help=\"API key\", required=True)\n timeout: Optional[float] = Param(None, help=\"Timeout for the API request.\")\n max_retries: Optional[int] = Param(\n None, help=\"Maximum number of retries for the API request.\"\n )\n\n dimensions: Optional[int] = Param(\n None,\n help=(\n \"The number of dimensions the resulting output embeddings should have. \"\n \"Only supported in `text-embedding-3` and later models.\"\n ),\n )\n context_length: Optional[int] = Param(\n None, help=\"The maximum context length of the embedding model\"\n )\n\n @Param.auto(depends_on=[\"max_retries\"])\n def max_retries_(self):\n if self.max_retries is None:\n from openai._constants import DEFAULT_MAX_RETRIES\n\n return DEFAULT_MAX_RETRIES\n return self.max_retries\n\n def prepare_client(self, async_version: bool = False):\n \"\"\"Get the OpenAI client\n\n Args:\n async_version (bool): Whether to get the async version of the client\n \"\"\"\n raise NotImplementedError\n\n def openai_response(self, client, **kwargs):\n \"\"\"Get the openai response\"\"\"\n raise NotImplementedError\n\n def invoke(\n self, text: str | list[str] | Document | list[Document], *args, **kwargs\n ) -> list[DocumentWithEmbedding]:\n input_doc = self.prepare_input(text)\n client = self.prepare_client(async_version=False)\n\n input_: list[str | list[int]] = []\n splitted_indices = {}\n for idx, text in enumerate(input_doc):\n if self.context_length:\n chunks = split_text_by_chunk_size(text.text or \" \", self.context_length)\n splitted_indices[idx] = (len(input_), len(input_) + len(chunks))\n input_.extend(chunks)\n else:\n splitted_indices[idx] = (len(input_), len(input_) + 1)\n input_.append(text.text)\n\n resp = self.openai_response(client, input=input_, **kwargs).dict()\n output_ = list(sorted(resp[\"data\"], key=lambda x: x[\"index\"]))\n\n output = []\n for idx, doc in enumerate(input_doc):\n embs = output_[splitted_indices[idx][0] : splitted_indices[idx][1]]\n if len(embs) == 1:\n output.append(\n DocumentWithEmbedding(embedding=embs[0][\"embedding\"], content=doc)\n )\n continue\n\n chunk_lens = [\n len(_)\n for _ in input_[splitted_indices[idx][0] : splitted_indices[idx][1]]\n ]\n vs: list[list[float]] = [_[\"embedding\"] for _ in embs]\n emb = np.average(vs, axis=0, weights=chunk_lens)\n emb = emb / np.linalg.norm(emb)\n output.append(DocumentWithEmbedding(embedding=emb.tolist(), content=doc))\n\n return output\n\n async def ainvoke(\n self, text: str | list[str] | Document | list[Document], *args, **kwargs\n ) -> list[DocumentWithEmbedding]:\n input_ = self.prepare_input(text)\n client = self.prepare_client(async_version=True)\n resp = await self.openai_response(\n client, input=[_.text if _.text else \" \" for _ in input_], **kwargs\n ).dict()\n output_ = sorted(resp[\"data\"], key=lambda x: x[\"index\"])\n return [\n DocumentWithEmbedding(embedding=o[\"embedding\"], content=i)\n for i, o in zip(input_, output_)\n ]\n
False Source code in libs/kotaemon/kotaemon/embeddings/openai.py
def prepare_client(self, async_version: bool = False):\n \"\"\"Get the OpenAI client\n\n Args:\n async_version (bool): Whether to get the async version of the client\n \"\"\"\n raise NotImplementedError\n
Source code in libs/kotaemon/kotaemon/embeddings/openai.py
class OpenAIEmbeddings(BaseOpenAIEmbeddings):\n \"\"\"OpenAI chat model\"\"\"\n\n base_url: Optional[str] = Param(None, help=\"OpenAI base URL\")\n organization: Optional[str] = Param(None, help=\"OpenAI organization\")\n model: str = Param(\n None,\n help=(\n \"ID of the model to use. You can go to [Model overview](https://platform.\"\n \"openai.com/docs/models/overview) to see the available models.\"\n ),\n required=True,\n )\n\n def prepare_client(self, async_version: bool = False):\n \"\"\"Get the OpenAI client\n\n Args:\n async_version (bool): Whether to get the async version of the client\n \"\"\"\n params = {\n \"api_key\": self.api_key,\n \"organization\": self.organization,\n \"base_url\": self.base_url,\n \"timeout\": self.timeout,\n \"max_retries\": self.max_retries_,\n }\n if async_version:\n from openai import AsyncOpenAI\n\n return AsyncOpenAI(**params)\n\n from openai import OpenAI\n\n return OpenAI(**params)\n\n @retry(\n retry=retry_if_not_exception_type(\n (openai.NotFoundError, openai.BadRequestError)\n ),\n wait=wait_random_exponential(min=1, max=40),\n stop=stop_after_attempt(6),\n )\n def openai_response(self, client, **kwargs):\n \"\"\"Get the openai response\"\"\"\n params: dict = {\n \"model\": self.model,\n }\n if self.dimensions:\n params[\"dimensions\"] = self.dimensions\n params.update(kwargs)\n\n return client.embeddings.create(**params)\n
Source code in libs/kotaemon/kotaemon/embeddings/openai.py
def split_text_by_chunk_size(text: str, chunk_size: int) -> list[list[int]]:\n \"\"\"Split the text into chunks of a given size\n\n Args:\n text: text to split\n chunk_size: size of each chunk\n\n Returns:\n list of chunks (as tokens)\n \"\"\"\n encoding = tiktoken.get_encoding(\"cl100k_base\")\n tokens = iter(encoding.encode(text))\n result = []\n while chunk := list(islice(tokens, chunk_size)):\n result.append(chunk)\n return result\n
Ingest the document, run through the embedding, and store the embedding in a vector store.
This pipeline supports the following set of inputs
List of documents
List of texts
Source code in libs/kotaemon/kotaemon/indices/vectorindex.py
class VectorIndexing(BaseIndexing):\n \"\"\"Ingest the document, run through the embedding, and store the embedding in a\n vector store.\n\n This pipeline supports the following set of inputs:\n - List of documents\n - List of texts\n \"\"\"\n\n cache_dir: Optional[str] = getattr(flowsettings, \"KH_CHUNKS_OUTPUT_DIR\", None)\n vector_store: BaseVectorStore\n doc_store: Optional[BaseDocumentStore] = None\n embedding: BaseEmbeddings\n count_: int = 0\n\n def to_retrieval_pipeline(self, *args, **kwargs):\n \"\"\"Convert the indexing pipeline to a retrieval pipeline\"\"\"\n return VectorRetrieval(\n vector_store=self.vector_store,\n doc_store=self.doc_store,\n embedding=self.embedding,\n **kwargs,\n )\n\n def to_qa_pipeline(self, *args, **kwargs):\n from .qa import CitationQAPipeline\n\n return TextVectorQA(\n retrieving_pipeline=self.to_retrieval_pipeline(**kwargs),\n qa_pipeline=CitationQAPipeline(**kwargs),\n )\n\n def write_chunk_to_file(self, docs: list[Document]):\n # save the chunks content into markdown format\n if self.cache_dir:\n file_name = Path(docs[0].metadata[\"file_name\"])\n for i in range(len(docs)):\n markdown_content = \"\"\n if \"page_label\" in docs[i].metadata:\n page_label = str(docs[i].metadata[\"page_label\"])\n markdown_content += f\"Page label: {page_label}\"\n if \"file_name\" in docs[i].metadata:\n filename = docs[i].metadata[\"file_name\"]\n markdown_content += f\"\\nFile name: {filename}\"\n if \"section\" in docs[i].metadata:\n section = docs[i].metadata[\"section\"]\n markdown_content += f\"\\nSection: {section}\"\n if \"type\" in docs[i].metadata:\n if docs[i].metadata[\"type\"] == \"image\":\n image_origin = docs[i].metadata[\"image_origin\"]\n image_origin = f'<p><img src=\"{image_origin}\"></p>'\n markdown_content += f\"\\nImage origin: {image_origin}\"\n if docs[i].text:\n markdown_content += f\"\\ntext:\\n{docs[i].text}\"\n\n with open(\n Path(self.cache_dir) / f\"{file_name.stem}_{self.count_+i}.md\",\n \"w\",\n encoding=\"utf-8\",\n ) as f:\n f.write(markdown_content)\n\n def add_to_docstore(self, docs: list[Document]):\n if self.doc_store:\n print(\"Adding documents to doc store\")\n self.doc_store.add(docs)\n\n def add_to_vectorstore(self, docs: list[Document]):\n # in case we want to skip embedding\n if self.vector_store:\n print(f\"Getting embeddings for {len(docs)} nodes\")\n embeddings = self.embedding(docs)\n print(\"Adding embeddings to vector store\")\n self.vector_store.add(\n embeddings=embeddings,\n ids=[t.doc_id for t in docs],\n )\n\n def run(self, text: str | list[str] | Document | list[Document]):\n input_: list[Document] = []\n if not isinstance(text, list):\n text = [text]\n\n for item in cast(list, text):\n if isinstance(item, str):\n input_.append(Document(text=item, id_=str(uuid.uuid4())))\n elif isinstance(item, Document):\n input_.append(item)\n else:\n raise ValueError(\n f\"Invalid input type {type(item)}, should be str or Document\"\n )\n\n self.add_to_vectorstore(input_)\n self.add_to_docstore(input_)\n self.write_chunk_to_file(input_)\n self.count_ += len(input_)\n
Source code in libs/kotaemon/kotaemon/indices/vectorindex.py
class VectorRetrieval(BaseRetrieval):\n \"\"\"Retrieve list of documents from vector store\"\"\"\n\n vector_store: BaseVectorStore\n doc_store: Optional[BaseDocumentStore] = None\n embedding: BaseEmbeddings\n rerankers: Sequence[BaseReranking] = []\n top_k: int = 5\n first_round_top_k_mult: int = 10\n retrieval_mode: str = \"hybrid\" # vector, text, hybrid\n\n def _filter_docs(\n self, documents: list[RetrievedDocument], top_k: int | None = None\n ):\n if top_k:\n documents = documents[:top_k]\n return documents\n\n def run(\n self, text: str | Document, top_k: Optional[int] = None, **kwargs\n ) -> list[RetrievedDocument]:\n \"\"\"Retrieve a list of documents from vector store\n\n Args:\n text: the text to retrieve similar documents\n top_k: number of top similar documents to return\n\n Returns:\n list[RetrievedDocument]: list of retrieved documents\n \"\"\"\n if top_k is None:\n top_k = self.top_k\n\n do_extend = kwargs.pop(\"do_extend\", False)\n thumbnail_count = kwargs.pop(\"thumbnail_count\", 3)\n\n if do_extend:\n top_k_first_round = top_k * self.first_round_top_k_mult\n else:\n top_k_first_round = top_k\n\n if self.doc_store is None:\n raise ValueError(\n \"doc_store is not provided. Please provide a doc_store to \"\n \"retrieve the documents\"\n )\n\n result: list[RetrievedDocument] = []\n # TODO: should declare scope directly in the run params\n scope = kwargs.pop(\"scope\", None)\n emb: list[float]\n\n if self.retrieval_mode == \"vector\":\n emb = self.embedding(text)[0].embedding\n _, scores, ids = self.vector_store.query(\n embedding=emb, top_k=top_k_first_round, **kwargs\n )\n docs = self.doc_store.get(ids)\n result = [\n RetrievedDocument(**doc.to_dict(), score=score)\n for doc, score in zip(docs, scores)\n ]\n elif self.retrieval_mode == \"text\":\n query = text.text if isinstance(text, Document) else text\n docs = self.doc_store.query(query, top_k=top_k_first_round, doc_ids=scope)\n result = [RetrievedDocument(**doc.to_dict(), score=-1.0) for doc in docs]\n elif self.retrieval_mode == \"hybrid\":\n # similarity search section\n emb = self.embedding(text)[0].embedding\n vs_docs: list[RetrievedDocument] = []\n vs_ids: list[str] = []\n vs_scores: list[float] = []\n\n def query_vectorstore():\n nonlocal vs_docs\n nonlocal vs_scores\n nonlocal vs_ids\n\n assert self.doc_store is not None\n _, vs_scores, vs_ids = self.vector_store.query(\n embedding=emb, top_k=top_k_first_round, **kwargs\n )\n if vs_ids:\n vs_docs = self.doc_store.get(vs_ids)\n\n # full-text search section\n ds_docs: list[RetrievedDocument] = []\n\n def query_docstore():\n nonlocal ds_docs\n\n assert self.doc_store is not None\n query = text.text if isinstance(text, Document) else text\n ds_docs = self.doc_store.query(\n query, top_k=top_k_first_round, doc_ids=scope\n )\n\n vs_query_thread = threading.Thread(target=query_vectorstore)\n ds_query_thread = threading.Thread(target=query_docstore)\n\n vs_query_thread.start()\n ds_query_thread.start()\n\n vs_query_thread.join()\n ds_query_thread.join()\n\n result = [\n RetrievedDocument(**doc.to_dict(), score=-1.0)\n for doc in ds_docs\n if doc not in vs_ids\n ]\n result += [\n RetrievedDocument(**doc.to_dict(), score=score)\n for doc, score in zip(vs_docs, vs_scores)\n ]\n print(f\"Got {len(vs_docs)} from vectorstore\")\n print(f\"Got {len(ds_docs)} from docstore\")\n\n # use additional reranker to re-order the document list\n if self.rerankers and text:\n for reranker in self.rerankers:\n # if reranker is LLMReranking, limit the document with top_k items only\n if isinstance(reranker, LLMReranking):\n result = self._filter_docs(result, top_k=top_k)\n result = reranker(documents=result, query=text)\n\n result = self._filter_docs(result, top_k=top_k)\n print(f\"Got raw {len(result)} retrieved documents\")\n\n # add page thumbnails to the result if exists\n thumbnail_doc_ids: set[str] = set()\n # we should copy the text from retrieved text chunk\n # to the thumbnail to get relevant LLM score correctly\n text_thumbnail_docs: dict[str, RetrievedDocument] = {}\n\n non_thumbnail_docs = []\n raw_thumbnail_docs = []\n for doc in result:\n if doc.metadata.get(\"type\") == \"thumbnail\":\n # change type to image to display on UI\n doc.metadata[\"type\"] = \"image\"\n raw_thumbnail_docs.append(doc)\n continue\n if (\n \"thumbnail_doc_id\" in doc.metadata\n and len(thumbnail_doc_ids) < thumbnail_count\n ):\n thumbnail_id = doc.metadata[\"thumbnail_doc_id\"]\n thumbnail_doc_ids.add(thumbnail_id)\n text_thumbnail_docs[thumbnail_id] = doc\n else:\n non_thumbnail_docs.append(doc)\n\n linked_thumbnail_docs = self.doc_store.get(list(thumbnail_doc_ids))\n print(\n \"thumbnail docs\",\n len(linked_thumbnail_docs),\n \"non-thumbnail docs\",\n len(non_thumbnail_docs),\n \"raw-thumbnail docs\",\n len(raw_thumbnail_docs),\n )\n additional_docs = []\n\n for thumbnail_doc in linked_thumbnail_docs:\n text_doc = text_thumbnail_docs[thumbnail_doc.doc_id]\n doc_dict = thumbnail_doc.to_dict()\n doc_dict[\"_id\"] = text_doc.doc_id\n doc_dict[\"content\"] = text_doc.content\n doc_dict[\"metadata\"][\"type\"] = \"image\"\n for key in text_doc.metadata:\n if key not in doc_dict[\"metadata\"]:\n doc_dict[\"metadata\"][key] = text_doc.metadata[key]\n\n additional_docs.append(RetrievedDocument(**doc_dict, score=text_doc.score))\n\n result = additional_docs + non_thumbnail_docs\n\n if not result:\n # return output from raw retrieved thumbnails\n result = self._filter_docs(raw_thumbnail_docs, top_k=thumbnail_count)\n\n return result\n
list[RetrievedDocument]: list of retrieved documents
Source code in libs/kotaemon/kotaemon/indices/vectorindex.py
def run(\n self, text: str | Document, top_k: Optional[int] = None, **kwargs\n) -> list[RetrievedDocument]:\n \"\"\"Retrieve a list of documents from vector store\n\n Args:\n text: the text to retrieve similar documents\n top_k: number of top similar documents to return\n\n Returns:\n list[RetrievedDocument]: list of retrieved documents\n \"\"\"\n if top_k is None:\n top_k = self.top_k\n\n do_extend = kwargs.pop(\"do_extend\", False)\n thumbnail_count = kwargs.pop(\"thumbnail_count\", 3)\n\n if do_extend:\n top_k_first_round = top_k * self.first_round_top_k_mult\n else:\n top_k_first_round = top_k\n\n if self.doc_store is None:\n raise ValueError(\n \"doc_store is not provided. Please provide a doc_store to \"\n \"retrieve the documents\"\n )\n\n result: list[RetrievedDocument] = []\n # TODO: should declare scope directly in the run params\n scope = kwargs.pop(\"scope\", None)\n emb: list[float]\n\n if self.retrieval_mode == \"vector\":\n emb = self.embedding(text)[0].embedding\n _, scores, ids = self.vector_store.query(\n embedding=emb, top_k=top_k_first_round, **kwargs\n )\n docs = self.doc_store.get(ids)\n result = [\n RetrievedDocument(**doc.to_dict(), score=score)\n for doc, score in zip(docs, scores)\n ]\n elif self.retrieval_mode == \"text\":\n query = text.text if isinstance(text, Document) else text\n docs = self.doc_store.query(query, top_k=top_k_first_round, doc_ids=scope)\n result = [RetrievedDocument(**doc.to_dict(), score=-1.0) for doc in docs]\n elif self.retrieval_mode == \"hybrid\":\n # similarity search section\n emb = self.embedding(text)[0].embedding\n vs_docs: list[RetrievedDocument] = []\n vs_ids: list[str] = []\n vs_scores: list[float] = []\n\n def query_vectorstore():\n nonlocal vs_docs\n nonlocal vs_scores\n nonlocal vs_ids\n\n assert self.doc_store is not None\n _, vs_scores, vs_ids = self.vector_store.query(\n embedding=emb, top_k=top_k_first_round, **kwargs\n )\n if vs_ids:\n vs_docs = self.doc_store.get(vs_ids)\n\n # full-text search section\n ds_docs: list[RetrievedDocument] = []\n\n def query_docstore():\n nonlocal ds_docs\n\n assert self.doc_store is not None\n query = text.text if isinstance(text, Document) else text\n ds_docs = self.doc_store.query(\n query, top_k=top_k_first_round, doc_ids=scope\n )\n\n vs_query_thread = threading.Thread(target=query_vectorstore)\n ds_query_thread = threading.Thread(target=query_docstore)\n\n vs_query_thread.start()\n ds_query_thread.start()\n\n vs_query_thread.join()\n ds_query_thread.join()\n\n result = [\n RetrievedDocument(**doc.to_dict(), score=-1.0)\n for doc in ds_docs\n if doc not in vs_ids\n ]\n result += [\n RetrievedDocument(**doc.to_dict(), score=score)\n for doc, score in zip(vs_docs, vs_scores)\n ]\n print(f\"Got {len(vs_docs)} from vectorstore\")\n print(f\"Got {len(ds_docs)} from docstore\")\n\n # use additional reranker to re-order the document list\n if self.rerankers and text:\n for reranker in self.rerankers:\n # if reranker is LLMReranking, limit the document with top_k items only\n if isinstance(reranker, LLMReranking):\n result = self._filter_docs(result, top_k=top_k)\n result = reranker(documents=result, query=text)\n\n result = self._filter_docs(result, top_k=top_k)\n print(f\"Got raw {len(result)} retrieved documents\")\n\n # add page thumbnails to the result if exists\n thumbnail_doc_ids: set[str] = set()\n # we should copy the text from retrieved text chunk\n # to the thumbnail to get relevant LLM score correctly\n text_thumbnail_docs: dict[str, RetrievedDocument] = {}\n\n non_thumbnail_docs = []\n raw_thumbnail_docs = []\n for doc in result:\n if doc.metadata.get(\"type\") == \"thumbnail\":\n # change type to image to display on UI\n doc.metadata[\"type\"] = \"image\"\n raw_thumbnail_docs.append(doc)\n continue\n if (\n \"thumbnail_doc_id\" in doc.metadata\n and len(thumbnail_doc_ids) < thumbnail_count\n ):\n thumbnail_id = doc.metadata[\"thumbnail_doc_id\"]\n thumbnail_doc_ids.add(thumbnail_id)\n text_thumbnail_docs[thumbnail_id] = doc\n else:\n non_thumbnail_docs.append(doc)\n\n linked_thumbnail_docs = self.doc_store.get(list(thumbnail_doc_ids))\n print(\n \"thumbnail docs\",\n len(linked_thumbnail_docs),\n \"non-thumbnail docs\",\n len(non_thumbnail_docs),\n \"raw-thumbnail docs\",\n len(raw_thumbnail_docs),\n )\n additional_docs = []\n\n for thumbnail_doc in linked_thumbnail_docs:\n text_doc = text_thumbnail_docs[thumbnail_doc.doc_id]\n doc_dict = thumbnail_doc.to_dict()\n doc_dict[\"_id\"] = text_doc.doc_id\n doc_dict[\"content\"] = text_doc.content\n doc_dict[\"metadata\"][\"type\"] = \"image\"\n for key in text_doc.metadata:\n if key not in doc_dict[\"metadata\"]:\n doc_dict[\"metadata\"][key] = text_doc.metadata[key]\n\n additional_docs.append(RetrievedDocument(**doc_dict, score=text_doc.score))\n\n result = additional_docs + non_thumbnail_docs\n\n if not result:\n # return output from raw retrieved thumbnails\n result = self._filter_docs(raw_thumbnail_docs, top_k=thumbnail_count)\n\n return result\n
A document transformer transforms a list of documents into another list of documents. Transforming can mean splitting a document into multiple documents, reducing a large list of documents into a smaller list of documents, or adding metadata to each document in a list of documents, etc.
Source code in libs/kotaemon/kotaemon/indices/base.py
class DocTransformer(BaseComponent):\n \"\"\"This is a base class for document transformers\n\n A document transformer transforms a list of documents into another list\n of documents. Transforming can mean splitting a document into multiple documents,\n reducing a large list of documents into a smaller list of documents, or adding\n metadata to each document in a list of documents, etc.\n \"\"\"\n\n @abstractmethod\n def run(\n self,\n documents: list[Document],\n **kwargs,\n ) -> list[Document]:\n ...\n
Allow automatically wrapping a Llama-index component into kotaemon component
Example
class TokenSplitter(LlamaIndexMixin, BaseSplitter): def _get_li_class(self): from llama_index.core.text_splitter import TokenTextSplitter return TokenTextSplitter
To use this mixin, please: 1. Use this class as the 1st parent class, so that Python will prefer to use the attributes and methods of this class whenever possible. 2. Overwrite _get_li_class to return the relevant LlamaIndex component.
Source code in libs/kotaemon/kotaemon/indices/base.py
class LlamaIndexDocTransformerMixin:\n \"\"\"Allow automatically wrapping a Llama-index component into kotaemon component\n\n Example:\n class TokenSplitter(LlamaIndexMixin, BaseSplitter):\n def _get_li_class(self):\n from llama_index.core.text_splitter import TokenTextSplitter\n return TokenTextSplitter\n\n To use this mixin, please:\n 1. Use this class as the 1st parent class, so that Python will prefer to use\n the attributes and methods of this class whenever possible.\n 2. Overwrite `_get_li_class` to return the relevant LlamaIndex component.\n \"\"\"\n\n def _get_li_class(self) -> Type[NodeParser]:\n raise NotImplementedError(\n \"Please return the relevant LlamaIndex class in _get_li_class\"\n )\n\n def __init__(self, **params):\n self._li_cls = self._get_li_class()\n self._obj = self._li_cls(**params)\n self._kwargs = params\n super().__init__()\n\n def __repr__(self):\n kwargs = []\n for key, value_obj in self._kwargs.items():\n value = repr(value_obj)\n kwargs.append(f\"{key}={value}\")\n kwargs_repr = \", \".join(kwargs)\n return f\"{self.__class__.__name__}({kwargs_repr})\"\n\n def __str__(self):\n kwargs = []\n for key, value_obj in self._kwargs.items():\n value = str(value_obj)\n if len(value) > 20:\n value = f\"{value[:15]}...\"\n kwargs.append(f\"{key}={value}\")\n kwargs_repr = \", \".join(kwargs)\n return f\"{self.__class__.__name__}({kwargs_repr})\"\n\n def __setattr__(self, name: str, value: Any) -> None:\n if name.startswith(\"_\") or name in self._protected_keywords():\n return super().__setattr__(name, value)\n\n self._kwargs[name] = value\n return setattr(self._obj, name, value)\n\n def __getattr__(self, name: str) -> Any:\n if name in self._kwargs:\n return self._kwargs[name]\n return getattr(self._obj, name)\n\n def dump(self, *args, **kwargs):\n from theflow.utils.modules import serialize\n\n params = {key: serialize(value) for key, value in self._kwargs.items()}\n return {\n \"__type__\": f\"{self.__module__}.{self.__class__.__qualname__}\",\n **params,\n }\n\n def run(\n self,\n documents: list[Document],\n **kwargs,\n ) -> list[Document]:\n \"\"\"Run Llama-index node parser and convert the output to Document from\n kotaemon\n \"\"\"\n docs = self._obj(documents, **kwargs) # type: ignore\n return [Document.from_dict(doc.to_dict()) for doc in docs]\n
Source code in libs/kotaemon/kotaemon/indices/base.py
class BaseIndexing(BaseComponent):\n \"\"\"Define the base interface for indexing pipeline\"\"\"\n\n def to_retrieval_pipeline(self, **kwargs):\n \"\"\"Convert the indexing pipeline to a retrieval pipeline\"\"\"\n raise NotImplementedError\n\n def to_qa_pipeline(self, **kwargs):\n \"\"\"Convert the indexing pipeline to a QA pipeline\"\"\"\n raise NotImplementedError\n
Source code in libs/kotaemon/kotaemon/indices/base.py
class BaseRetrieval(BaseComponent):\n \"\"\"Define the base interface for retrieval pipeline\"\"\"\n\n @abstractmethod\n def run(self, *args, **kwargs) -> list[RetrievedDocument]:\n ...\n
Ingest the document, run through the embedding, and store the embedding in a vector store.
This pipeline supports the following set of inputs
List of documents
List of texts
Source code in libs/kotaemon/kotaemon/indices/vectorindex.py
class VectorIndexing(BaseIndexing):\n \"\"\"Ingest the document, run through the embedding, and store the embedding in a\n vector store.\n\n This pipeline supports the following set of inputs:\n - List of documents\n - List of texts\n \"\"\"\n\n cache_dir: Optional[str] = getattr(flowsettings, \"KH_CHUNKS_OUTPUT_DIR\", None)\n vector_store: BaseVectorStore\n doc_store: Optional[BaseDocumentStore] = None\n embedding: BaseEmbeddings\n count_: int = 0\n\n def to_retrieval_pipeline(self, *args, **kwargs):\n \"\"\"Convert the indexing pipeline to a retrieval pipeline\"\"\"\n return VectorRetrieval(\n vector_store=self.vector_store,\n doc_store=self.doc_store,\n embedding=self.embedding,\n **kwargs,\n )\n\n def to_qa_pipeline(self, *args, **kwargs):\n from .qa import CitationQAPipeline\n\n return TextVectorQA(\n retrieving_pipeline=self.to_retrieval_pipeline(**kwargs),\n qa_pipeline=CitationQAPipeline(**kwargs),\n )\n\n def write_chunk_to_file(self, docs: list[Document]):\n # save the chunks content into markdown format\n if self.cache_dir:\n file_name = Path(docs[0].metadata[\"file_name\"])\n for i in range(len(docs)):\n markdown_content = \"\"\n if \"page_label\" in docs[i].metadata:\n page_label = str(docs[i].metadata[\"page_label\"])\n markdown_content += f\"Page label: {page_label}\"\n if \"file_name\" in docs[i].metadata:\n filename = docs[i].metadata[\"file_name\"]\n markdown_content += f\"\\nFile name: {filename}\"\n if \"section\" in docs[i].metadata:\n section = docs[i].metadata[\"section\"]\n markdown_content += f\"\\nSection: {section}\"\n if \"type\" in docs[i].metadata:\n if docs[i].metadata[\"type\"] == \"image\":\n image_origin = docs[i].metadata[\"image_origin\"]\n image_origin = f'<p><img src=\"{image_origin}\"></p>'\n markdown_content += f\"\\nImage origin: {image_origin}\"\n if docs[i].text:\n markdown_content += f\"\\ntext:\\n{docs[i].text}\"\n\n with open(\n Path(self.cache_dir) / f\"{file_name.stem}_{self.count_+i}.md\",\n \"w\",\n encoding=\"utf-8\",\n ) as f:\n f.write(markdown_content)\n\n def add_to_docstore(self, docs: list[Document]):\n if self.doc_store:\n print(\"Adding documents to doc store\")\n self.doc_store.add(docs)\n\n def add_to_vectorstore(self, docs: list[Document]):\n # in case we want to skip embedding\n if self.vector_store:\n print(f\"Getting embeddings for {len(docs)} nodes\")\n embeddings = self.embedding(docs)\n print(\"Adding embeddings to vector store\")\n self.vector_store.add(\n embeddings=embeddings,\n ids=[t.doc_id for t in docs],\n )\n\n def run(self, text: str | list[str] | Document | list[Document]):\n input_: list[Document] = []\n if not isinstance(text, list):\n text = [text]\n\n for item in cast(list, text):\n if isinstance(item, str):\n input_.append(Document(text=item, id_=str(uuid.uuid4())))\n elif isinstance(item, Document):\n input_.append(item)\n else:\n raise ValueError(\n f\"Invalid input type {type(item)}, should be str or Document\"\n )\n\n self.add_to_vectorstore(input_)\n self.add_to_docstore(input_)\n self.write_chunk_to_file(input_)\n self.count_ += len(input_)\n
Source code in libs/kotaemon/kotaemon/indices/vectorindex.py
class VectorRetrieval(BaseRetrieval):\n \"\"\"Retrieve list of documents from vector store\"\"\"\n\n vector_store: BaseVectorStore\n doc_store: Optional[BaseDocumentStore] = None\n embedding: BaseEmbeddings\n rerankers: Sequence[BaseReranking] = []\n top_k: int = 5\n first_round_top_k_mult: int = 10\n retrieval_mode: str = \"hybrid\" # vector, text, hybrid\n\n def _filter_docs(\n self, documents: list[RetrievedDocument], top_k: int | None = None\n ):\n if top_k:\n documents = documents[:top_k]\n return documents\n\n def run(\n self, text: str | Document, top_k: Optional[int] = None, **kwargs\n ) -> list[RetrievedDocument]:\n \"\"\"Retrieve a list of documents from vector store\n\n Args:\n text: the text to retrieve similar documents\n top_k: number of top similar documents to return\n\n Returns:\n list[RetrievedDocument]: list of retrieved documents\n \"\"\"\n if top_k is None:\n top_k = self.top_k\n\n do_extend = kwargs.pop(\"do_extend\", False)\n thumbnail_count = kwargs.pop(\"thumbnail_count\", 3)\n\n if do_extend:\n top_k_first_round = top_k * self.first_round_top_k_mult\n else:\n top_k_first_round = top_k\n\n if self.doc_store is None:\n raise ValueError(\n \"doc_store is not provided. Please provide a doc_store to \"\n \"retrieve the documents\"\n )\n\n result: list[RetrievedDocument] = []\n # TODO: should declare scope directly in the run params\n scope = kwargs.pop(\"scope\", None)\n emb: list[float]\n\n if self.retrieval_mode == \"vector\":\n emb = self.embedding(text)[0].embedding\n _, scores, ids = self.vector_store.query(\n embedding=emb, top_k=top_k_first_round, **kwargs\n )\n docs = self.doc_store.get(ids)\n result = [\n RetrievedDocument(**doc.to_dict(), score=score)\n for doc, score in zip(docs, scores)\n ]\n elif self.retrieval_mode == \"text\":\n query = text.text if isinstance(text, Document) else text\n docs = self.doc_store.query(query, top_k=top_k_first_round, doc_ids=scope)\n result = [RetrievedDocument(**doc.to_dict(), score=-1.0) for doc in docs]\n elif self.retrieval_mode == \"hybrid\":\n # similarity search section\n emb = self.embedding(text)[0].embedding\n vs_docs: list[RetrievedDocument] = []\n vs_ids: list[str] = []\n vs_scores: list[float] = []\n\n def query_vectorstore():\n nonlocal vs_docs\n nonlocal vs_scores\n nonlocal vs_ids\n\n assert self.doc_store is not None\n _, vs_scores, vs_ids = self.vector_store.query(\n embedding=emb, top_k=top_k_first_round, **kwargs\n )\n if vs_ids:\n vs_docs = self.doc_store.get(vs_ids)\n\n # full-text search section\n ds_docs: list[RetrievedDocument] = []\n\n def query_docstore():\n nonlocal ds_docs\n\n assert self.doc_store is not None\n query = text.text if isinstance(text, Document) else text\n ds_docs = self.doc_store.query(\n query, top_k=top_k_first_round, doc_ids=scope\n )\n\n vs_query_thread = threading.Thread(target=query_vectorstore)\n ds_query_thread = threading.Thread(target=query_docstore)\n\n vs_query_thread.start()\n ds_query_thread.start()\n\n vs_query_thread.join()\n ds_query_thread.join()\n\n result = [\n RetrievedDocument(**doc.to_dict(), score=-1.0)\n for doc in ds_docs\n if doc not in vs_ids\n ]\n result += [\n RetrievedDocument(**doc.to_dict(), score=score)\n for doc, score in zip(vs_docs, vs_scores)\n ]\n print(f\"Got {len(vs_docs)} from vectorstore\")\n print(f\"Got {len(ds_docs)} from docstore\")\n\n # use additional reranker to re-order the document list\n if self.rerankers and text:\n for reranker in self.rerankers:\n # if reranker is LLMReranking, limit the document with top_k items only\n if isinstance(reranker, LLMReranking):\n result = self._filter_docs(result, top_k=top_k)\n result = reranker(documents=result, query=text)\n\n result = self._filter_docs(result, top_k=top_k)\n print(f\"Got raw {len(result)} retrieved documents\")\n\n # add page thumbnails to the result if exists\n thumbnail_doc_ids: set[str] = set()\n # we should copy the text from retrieved text chunk\n # to the thumbnail to get relevant LLM score correctly\n text_thumbnail_docs: dict[str, RetrievedDocument] = {}\n\n non_thumbnail_docs = []\n raw_thumbnail_docs = []\n for doc in result:\n if doc.metadata.get(\"type\") == \"thumbnail\":\n # change type to image to display on UI\n doc.metadata[\"type\"] = \"image\"\n raw_thumbnail_docs.append(doc)\n continue\n if (\n \"thumbnail_doc_id\" in doc.metadata\n and len(thumbnail_doc_ids) < thumbnail_count\n ):\n thumbnail_id = doc.metadata[\"thumbnail_doc_id\"]\n thumbnail_doc_ids.add(thumbnail_id)\n text_thumbnail_docs[thumbnail_id] = doc\n else:\n non_thumbnail_docs.append(doc)\n\n linked_thumbnail_docs = self.doc_store.get(list(thumbnail_doc_ids))\n print(\n \"thumbnail docs\",\n len(linked_thumbnail_docs),\n \"non-thumbnail docs\",\n len(non_thumbnail_docs),\n \"raw-thumbnail docs\",\n len(raw_thumbnail_docs),\n )\n additional_docs = []\n\n for thumbnail_doc in linked_thumbnail_docs:\n text_doc = text_thumbnail_docs[thumbnail_doc.doc_id]\n doc_dict = thumbnail_doc.to_dict()\n doc_dict[\"_id\"] = text_doc.doc_id\n doc_dict[\"content\"] = text_doc.content\n doc_dict[\"metadata\"][\"type\"] = \"image\"\n for key in text_doc.metadata:\n if key not in doc_dict[\"metadata\"]:\n doc_dict[\"metadata\"][key] = text_doc.metadata[key]\n\n additional_docs.append(RetrievedDocument(**doc_dict, score=text_doc.score))\n\n result = additional_docs + non_thumbnail_docs\n\n if not result:\n # return output from raw retrieved thumbnails\n result = self._filter_docs(raw_thumbnail_docs, top_k=thumbnail_count)\n\n return result\n
list[RetrievedDocument]: list of retrieved documents
Source code in libs/kotaemon/kotaemon/indices/vectorindex.py
def run(\n self, text: str | Document, top_k: Optional[int] = None, **kwargs\n) -> list[RetrievedDocument]:\n \"\"\"Retrieve a list of documents from vector store\n\n Args:\n text: the text to retrieve similar documents\n top_k: number of top similar documents to return\n\n Returns:\n list[RetrievedDocument]: list of retrieved documents\n \"\"\"\n if top_k is None:\n top_k = self.top_k\n\n do_extend = kwargs.pop(\"do_extend\", False)\n thumbnail_count = kwargs.pop(\"thumbnail_count\", 3)\n\n if do_extend:\n top_k_first_round = top_k * self.first_round_top_k_mult\n else:\n top_k_first_round = top_k\n\n if self.doc_store is None:\n raise ValueError(\n \"doc_store is not provided. Please provide a doc_store to \"\n \"retrieve the documents\"\n )\n\n result: list[RetrievedDocument] = []\n # TODO: should declare scope directly in the run params\n scope = kwargs.pop(\"scope\", None)\n emb: list[float]\n\n if self.retrieval_mode == \"vector\":\n emb = self.embedding(text)[0].embedding\n _, scores, ids = self.vector_store.query(\n embedding=emb, top_k=top_k_first_round, **kwargs\n )\n docs = self.doc_store.get(ids)\n result = [\n RetrievedDocument(**doc.to_dict(), score=score)\n for doc, score in zip(docs, scores)\n ]\n elif self.retrieval_mode == \"text\":\n query = text.text if isinstance(text, Document) else text\n docs = self.doc_store.query(query, top_k=top_k_first_round, doc_ids=scope)\n result = [RetrievedDocument(**doc.to_dict(), score=-1.0) for doc in docs]\n elif self.retrieval_mode == \"hybrid\":\n # similarity search section\n emb = self.embedding(text)[0].embedding\n vs_docs: list[RetrievedDocument] = []\n vs_ids: list[str] = []\n vs_scores: list[float] = []\n\n def query_vectorstore():\n nonlocal vs_docs\n nonlocal vs_scores\n nonlocal vs_ids\n\n assert self.doc_store is not None\n _, vs_scores, vs_ids = self.vector_store.query(\n embedding=emb, top_k=top_k_first_round, **kwargs\n )\n if vs_ids:\n vs_docs = self.doc_store.get(vs_ids)\n\n # full-text search section\n ds_docs: list[RetrievedDocument] = []\n\n def query_docstore():\n nonlocal ds_docs\n\n assert self.doc_store is not None\n query = text.text if isinstance(text, Document) else text\n ds_docs = self.doc_store.query(\n query, top_k=top_k_first_round, doc_ids=scope\n )\n\n vs_query_thread = threading.Thread(target=query_vectorstore)\n ds_query_thread = threading.Thread(target=query_docstore)\n\n vs_query_thread.start()\n ds_query_thread.start()\n\n vs_query_thread.join()\n ds_query_thread.join()\n\n result = [\n RetrievedDocument(**doc.to_dict(), score=-1.0)\n for doc in ds_docs\n if doc not in vs_ids\n ]\n result += [\n RetrievedDocument(**doc.to_dict(), score=score)\n for doc, score in zip(vs_docs, vs_scores)\n ]\n print(f\"Got {len(vs_docs)} from vectorstore\")\n print(f\"Got {len(ds_docs)} from docstore\")\n\n # use additional reranker to re-order the document list\n if self.rerankers and text:\n for reranker in self.rerankers:\n # if reranker is LLMReranking, limit the document with top_k items only\n if isinstance(reranker, LLMReranking):\n result = self._filter_docs(result, top_k=top_k)\n result = reranker(documents=result, query=text)\n\n result = self._filter_docs(result, top_k=top_k)\n print(f\"Got raw {len(result)} retrieved documents\")\n\n # add page thumbnails to the result if exists\n thumbnail_doc_ids: set[str] = set()\n # we should copy the text from retrieved text chunk\n # to the thumbnail to get relevant LLM score correctly\n text_thumbnail_docs: dict[str, RetrievedDocument] = {}\n\n non_thumbnail_docs = []\n raw_thumbnail_docs = []\n for doc in result:\n if doc.metadata.get(\"type\") == \"thumbnail\":\n # change type to image to display on UI\n doc.metadata[\"type\"] = \"image\"\n raw_thumbnail_docs.append(doc)\n continue\n if (\n \"thumbnail_doc_id\" in doc.metadata\n and len(thumbnail_doc_ids) < thumbnail_count\n ):\n thumbnail_id = doc.metadata[\"thumbnail_doc_id\"]\n thumbnail_doc_ids.add(thumbnail_id)\n text_thumbnail_docs[thumbnail_id] = doc\n else:\n non_thumbnail_docs.append(doc)\n\n linked_thumbnail_docs = self.doc_store.get(list(thumbnail_doc_ids))\n print(\n \"thumbnail docs\",\n len(linked_thumbnail_docs),\n \"non-thumbnail docs\",\n len(non_thumbnail_docs),\n \"raw-thumbnail docs\",\n len(raw_thumbnail_docs),\n )\n additional_docs = []\n\n for thumbnail_doc in linked_thumbnail_docs:\n text_doc = text_thumbnail_docs[thumbnail_doc.doc_id]\n doc_dict = thumbnail_doc.to_dict()\n doc_dict[\"_id\"] = text_doc.doc_id\n doc_dict[\"content\"] = text_doc.content\n doc_dict[\"metadata\"][\"type\"] = \"image\"\n for key in text_doc.metadata:\n if key not in doc_dict[\"metadata\"]:\n doc_dict[\"metadata\"][key] = text_doc.metadata[key]\n\n additional_docs.append(RetrievedDocument(**doc_dict, score=text_doc.score))\n\n result = additional_docs + non_thumbnail_docs\n\n if not result:\n # return output from raw retrieved thumbnails\n result = self._filter_docs(raw_thumbnail_docs, top_k=thumbnail_count)\n\n return result\n
Ingest common office document types into Document for indexing
Document types
pdf
xlsx, xls
docx, doc
Parameters:
Name Type Description Default pdf_mode
mode for pdf extraction, one of \"normal\", \"mathpix\", \"ocr\" - normal: parse pdf text - mathpix: parse pdf text using mathpix - ocr: parse pdf image using flax
required doc_parsers
list of document parsers to parse the document
required text_splitter
splitter to split the document into text nodes
required override_file_extractors
override file extractors for specific file extensions The default file extractors are stored in KH_DEFAULT_FILE_EXTRACTORS
required Source code in libs/kotaemon/kotaemon/indices/ingests/files.py
class DocumentIngestor(BaseComponent):\n \"\"\"Ingest common office document types into Document for indexing\n\n Document types:\n - pdf\n - xlsx, xls\n - docx, doc\n\n Args:\n pdf_mode: mode for pdf extraction, one of \"normal\", \"mathpix\", \"ocr\"\n - normal: parse pdf text\n - mathpix: parse pdf text using mathpix\n - ocr: parse pdf image using flax\n doc_parsers: list of document parsers to parse the document\n text_splitter: splitter to split the document into text nodes\n override_file_extractors: override file extractors for specific file extensions\n The default file extractors are stored in `KH_DEFAULT_FILE_EXTRACTORS`\n \"\"\"\n\n pdf_mode: str = \"normal\" # \"normal\", \"mathpix\", \"ocr\", \"multimodal\"\n doc_parsers: list[BaseDocParser] = Param(default_callback=lambda _: [])\n text_splitter: BaseSplitter = TokenSplitter.withx(\n chunk_size=1024,\n chunk_overlap=256,\n separator=\"\\n\\n\",\n backup_separators=[\"\\n\", \".\", \" \", \"\\u200B\"],\n )\n override_file_extractors: dict[str, Type[BaseReader]] = {}\n\n def _get_reader(self, input_files: list[str | Path]):\n \"\"\"Get appropriate readers for the input files based on file extension\"\"\"\n file_extractors: dict[str, BaseReader] = {\n ext: reader for ext, reader in KH_DEFAULT_FILE_EXTRACTORS.items()\n }\n for ext, cls in self.override_file_extractors.items():\n file_extractors[ext] = cls()\n\n if self.pdf_mode == \"normal\":\n file_extractors[\".pdf\"] = PDFReader()\n elif self.pdf_mode == \"ocr\":\n file_extractors[\".pdf\"] = OCRReader()\n elif self.pdf_mode == \"multimodal\":\n file_extractors[\".pdf\"] = AdobeReader()\n else:\n file_extractors[\".pdf\"] = MathpixPDFReader()\n\n main_reader = DirectoryReader(\n input_files=input_files,\n file_extractor=file_extractors,\n )\n\n return main_reader\n\n def run(self, file_paths: list[str | Path] | str | Path) -> list[Document]:\n \"\"\"Ingest the file paths into Document\n\n Args:\n file_paths: list of file paths or a single file path\n\n Returns:\n list of parsed Documents\n \"\"\"\n if not isinstance(file_paths, list):\n file_paths = [file_paths]\n\n documents = self._get_reader(input_files=file_paths)()\n print(f\"Read {len(file_paths)} files into {len(documents)} documents.\")\n nodes = self.text_splitter(documents)\n print(f\"Transform {len(documents)} documents into {len(nodes)} nodes.\")\n self.log_progress(\".num_docs\", num_docs=len(nodes))\n\n # document parsers call\n if self.doc_parsers:\n for parser in self.doc_parsers:\n nodes = parser(nodes)\n\n return nodes\n
Name Type Description Default file_pathslist[str | Path] | str | Path
list of file paths or a single file path
required
Returns:
Type Description list[Document]
list of parsed Documents
Source code in libs/kotaemon/kotaemon/indices/ingests/files.py
def run(self, file_paths: list[str | Path] | str | Path) -> list[Document]:\n \"\"\"Ingest the file paths into Document\n\n Args:\n file_paths: list of file paths or a single file path\n\n Returns:\n list of parsed Documents\n \"\"\"\n if not isinstance(file_paths, list):\n file_paths = [file_paths]\n\n documents = self._get_reader(input_files=file_paths)()\n print(f\"Read {len(file_paths)} files into {len(documents)} documents.\")\n nodes = self.text_splitter(documents)\n print(f\"Transform {len(documents)} documents into {len(nodes)} nodes.\")\n self.log_progress(\".num_docs\", num_docs=len(nodes))\n\n # document parsers call\n if self.doc_parsers:\n for parser in self.doc_parsers:\n nodes = parser(nodes)\n\n return nodes\n
Ingest common office document types into Document for indexing
Document types
pdf
xlsx, xls
docx, doc
Parameters:
Name Type Description Default pdf_mode
mode for pdf extraction, one of \"normal\", \"mathpix\", \"ocr\" - normal: parse pdf text - mathpix: parse pdf text using mathpix - ocr: parse pdf image using flax
required doc_parsers
list of document parsers to parse the document
required text_splitter
splitter to split the document into text nodes
required override_file_extractors
override file extractors for specific file extensions The default file extractors are stored in KH_DEFAULT_FILE_EXTRACTORS
required Source code in libs/kotaemon/kotaemon/indices/ingests/files.py
class DocumentIngestor(BaseComponent):\n \"\"\"Ingest common office document types into Document for indexing\n\n Document types:\n - pdf\n - xlsx, xls\n - docx, doc\n\n Args:\n pdf_mode: mode for pdf extraction, one of \"normal\", \"mathpix\", \"ocr\"\n - normal: parse pdf text\n - mathpix: parse pdf text using mathpix\n - ocr: parse pdf image using flax\n doc_parsers: list of document parsers to parse the document\n text_splitter: splitter to split the document into text nodes\n override_file_extractors: override file extractors for specific file extensions\n The default file extractors are stored in `KH_DEFAULT_FILE_EXTRACTORS`\n \"\"\"\n\n pdf_mode: str = \"normal\" # \"normal\", \"mathpix\", \"ocr\", \"multimodal\"\n doc_parsers: list[BaseDocParser] = Param(default_callback=lambda _: [])\n text_splitter: BaseSplitter = TokenSplitter.withx(\n chunk_size=1024,\n chunk_overlap=256,\n separator=\"\\n\\n\",\n backup_separators=[\"\\n\", \".\", \" \", \"\\u200B\"],\n )\n override_file_extractors: dict[str, Type[BaseReader]] = {}\n\n def _get_reader(self, input_files: list[str | Path]):\n \"\"\"Get appropriate readers for the input files based on file extension\"\"\"\n file_extractors: dict[str, BaseReader] = {\n ext: reader for ext, reader in KH_DEFAULT_FILE_EXTRACTORS.items()\n }\n for ext, cls in self.override_file_extractors.items():\n file_extractors[ext] = cls()\n\n if self.pdf_mode == \"normal\":\n file_extractors[\".pdf\"] = PDFReader()\n elif self.pdf_mode == \"ocr\":\n file_extractors[\".pdf\"] = OCRReader()\n elif self.pdf_mode == \"multimodal\":\n file_extractors[\".pdf\"] = AdobeReader()\n else:\n file_extractors[\".pdf\"] = MathpixPDFReader()\n\n main_reader = DirectoryReader(\n input_files=input_files,\n file_extractor=file_extractors,\n )\n\n return main_reader\n\n def run(self, file_paths: list[str | Path] | str | Path) -> list[Document]:\n \"\"\"Ingest the file paths into Document\n\n Args:\n file_paths: list of file paths or a single file path\n\n Returns:\n list of parsed Documents\n \"\"\"\n if not isinstance(file_paths, list):\n file_paths = [file_paths]\n\n documents = self._get_reader(input_files=file_paths)()\n print(f\"Read {len(file_paths)} files into {len(documents)} documents.\")\n nodes = self.text_splitter(documents)\n print(f\"Transform {len(documents)} documents into {len(nodes)} nodes.\")\n self.log_progress(\".num_docs\", num_docs=len(nodes))\n\n # document parsers call\n if self.doc_parsers:\n for parser in self.doc_parsers:\n nodes = parser(nodes)\n\n return nodes\n
Name Type Description Default file_pathslist[str | Path] | str | Path
list of file paths or a single file path
required
Returns:
Type Description list[Document]
list of parsed Documents
Source code in libs/kotaemon/kotaemon/indices/ingests/files.py
def run(self, file_paths: list[str | Path] | str | Path) -> list[Document]:\n \"\"\"Ingest the file paths into Document\n\n Args:\n file_paths: list of file paths or a single file path\n\n Returns:\n list of parsed Documents\n \"\"\"\n if not isinstance(file_paths, list):\n file_paths = [file_paths]\n\n documents = self._get_reader(input_files=file_paths)()\n print(f\"Read {len(file_paths)} files into {len(documents)} documents.\")\n nodes = self.text_splitter(documents)\n print(f\"Transform {len(documents)} documents into {len(nodes)} nodes.\")\n self.log_progress(\".num_docs\", num_docs=len(nodes))\n\n # document parsers call\n if self.doc_parsers:\n for parser in self.doc_parsers:\n nodes = parser(nodes)\n\n return nodes\n
List of evidences (maximum 5) to support the answer.
Source code in libs/kotaemon/kotaemon/indices/qa/citation.py
class CiteEvidence(BaseModel):\n \"\"\"List of evidences (maximum 5) to support the answer.\"\"\"\n\n evidences: List[str] = Field(\n ...,\n description=(\n \"Each source should be a direct quote from the context, \"\n \"as a substring of the original content (max 15 words).\"\n ),\n )\n
Source code in libs/kotaemon/kotaemon/indices/rankings/cohere.py
class CohereReranking(BaseReranking):\n model_name: str = \"rerank-multilingual-v2.0\"\n cohere_api_key: str = config(\"COHERE_API_KEY\", \"\")\n use_key_from_ktem: bool = False\n\n def run(self, documents: list[Document], query: str) -> list[Document]:\n \"\"\"Use Cohere Reranker model to re-order documents\n with their relevance score\"\"\"\n try:\n import cohere\n except ImportError:\n raise ImportError(\n \"Please install Cohere `pip install cohere` to use Cohere Reranking\"\n )\n\n # try to get COHERE_API_KEY from embeddings\n if not self.cohere_api_key and self.use_key_from_ktem:\n try:\n from ktem.embeddings.manager import (\n embedding_models_manager as embeddings,\n )\n\n cohere_model = embeddings.get(\"cohere\")\n ktem_cohere_api_key = cohere_model._kwargs.get( # type: ignore\n \"cohere_api_key\"\n )\n if ktem_cohere_api_key != \"your-key\":\n self.cohere_api_key = ktem_cohere_api_key\n except Exception as e:\n print(\"Cannot get Cohere API key from `ktem`\", e)\n\n if not self.cohere_api_key:\n print(\"Cohere API key not found. Skipping reranking.\")\n return documents\n\n cohere_client = cohere.Client(self.cohere_api_key)\n compressed_docs: list[Document] = []\n\n if not documents: # to avoid empty api call\n return compressed_docs\n\n _docs = [d.content for d in documents]\n response = cohere_client.rerank(\n model=self.model_name, query=query, documents=_docs\n )\n # print(\"Cohere score\", [r.relevance_score for r in response.results])\n for r in response.results:\n doc = documents[r.index]\n doc.metadata[\"cohere_reranking_score\"] = r.relevance_score\n compressed_docs.append(doc)\n\n return compressed_docs\n
Use Cohere Reranker model to re-order documents with their relevance score
Source code in libs/kotaemon/kotaemon/indices/rankings/cohere.py
def run(self, documents: list[Document], query: str) -> list[Document]:\n \"\"\"Use Cohere Reranker model to re-order documents\n with their relevance score\"\"\"\n try:\n import cohere\n except ImportError:\n raise ImportError(\n \"Please install Cohere `pip install cohere` to use Cohere Reranking\"\n )\n\n # try to get COHERE_API_KEY from embeddings\n if not self.cohere_api_key and self.use_key_from_ktem:\n try:\n from ktem.embeddings.manager import (\n embedding_models_manager as embeddings,\n )\n\n cohere_model = embeddings.get(\"cohere\")\n ktem_cohere_api_key = cohere_model._kwargs.get( # type: ignore\n \"cohere_api_key\"\n )\n if ktem_cohere_api_key != \"your-key\":\n self.cohere_api_key = ktem_cohere_api_key\n except Exception as e:\n print(\"Cannot get Cohere API key from `ktem`\", e)\n\n if not self.cohere_api_key:\n print(\"Cohere API key not found. Skipping reranking.\")\n return documents\n\n cohere_client = cohere.Client(self.cohere_api_key)\n compressed_docs: list[Document] = []\n\n if not documents: # to avoid empty api call\n return compressed_docs\n\n _docs = [d.content for d in documents]\n response = cohere_client.rerank(\n model=self.model_name, query=query, documents=_docs\n )\n # print(\"Cohere score\", [r.relevance_score for r in response.results])\n for r in response.results:\n doc = documents[r.index]\n doc.metadata[\"cohere_reranking_score\"] = r.relevance_score\n compressed_docs.append(doc)\n\n return compressed_docs\n
Source code in libs/kotaemon/kotaemon/indices/rankings/llm.py
class LLMReranking(BaseReranking):\n llm: BaseLLM\n prompt_template: PromptTemplate = PromptTemplate(template=RERANK_PROMPT_TEMPLATE)\n top_k: int = 3\n concurrent: bool = True\n\n def run(\n self,\n documents: list[Document],\n query: str,\n ) -> list[Document]:\n \"\"\"Filter down documents based on their relevance to the query.\"\"\"\n filtered_docs = []\n output_parser = BooleanOutputParser()\n\n if self.concurrent:\n with ThreadPoolExecutor() as executor:\n futures = []\n for doc in documents:\n _prompt = self.prompt_template.populate(\n question=query, context=doc.get_content()\n )\n futures.append(executor.submit(lambda: self.llm(_prompt).text))\n\n results = [future.result() for future in futures]\n else:\n results = []\n for doc in documents:\n _prompt = self.prompt_template.populate(\n question=query, context=doc.get_content()\n )\n results.append(self.llm(_prompt).text)\n\n # use Boolean parser to extract relevancy output from LLM\n results = [output_parser.parse(result) for result in results]\n for include_doc, doc in zip(results, documents):\n if include_doc:\n filtered_docs.append(doc)\n\n # prevent returning empty result\n if len(filtered_docs) == 0:\n filtered_docs = documents[: self.top_k]\n\n return filtered_docs\n
Filter down documents based on their relevance to the query.
Source code in libs/kotaemon/kotaemon/indices/rankings/llm.py
def run(\n self,\n documents: list[Document],\n query: str,\n) -> list[Document]:\n \"\"\"Filter down documents based on their relevance to the query.\"\"\"\n filtered_docs = []\n output_parser = BooleanOutputParser()\n\n if self.concurrent:\n with ThreadPoolExecutor() as executor:\n futures = []\n for doc in documents:\n _prompt = self.prompt_template.populate(\n question=query, context=doc.get_content()\n )\n futures.append(executor.submit(lambda: self.llm(_prompt).text))\n\n results = [future.result() for future in futures]\n else:\n results = []\n for doc in documents:\n _prompt = self.prompt_template.populate(\n question=query, context=doc.get_content()\n )\n results.append(self.llm(_prompt).text)\n\n # use Boolean parser to extract relevancy output from LLM\n results = [output_parser.parse(result) for result in results]\n for include_doc, doc in zip(results, documents):\n if include_doc:\n filtered_docs.append(doc)\n\n # prevent returning empty result\n if len(filtered_docs) == 0:\n filtered_docs = documents[: self.top_k]\n\n return filtered_docs\n
Source code in libs/kotaemon/kotaemon/indices/rankings/cohere.py
class CohereReranking(BaseReranking):\n model_name: str = \"rerank-multilingual-v2.0\"\n cohere_api_key: str = config(\"COHERE_API_KEY\", \"\")\n use_key_from_ktem: bool = False\n\n def run(self, documents: list[Document], query: str) -> list[Document]:\n \"\"\"Use Cohere Reranker model to re-order documents\n with their relevance score\"\"\"\n try:\n import cohere\n except ImportError:\n raise ImportError(\n \"Please install Cohere `pip install cohere` to use Cohere Reranking\"\n )\n\n # try to get COHERE_API_KEY from embeddings\n if not self.cohere_api_key and self.use_key_from_ktem:\n try:\n from ktem.embeddings.manager import (\n embedding_models_manager as embeddings,\n )\n\n cohere_model = embeddings.get(\"cohere\")\n ktem_cohere_api_key = cohere_model._kwargs.get( # type: ignore\n \"cohere_api_key\"\n )\n if ktem_cohere_api_key != \"your-key\":\n self.cohere_api_key = ktem_cohere_api_key\n except Exception as e:\n print(\"Cannot get Cohere API key from `ktem`\", e)\n\n if not self.cohere_api_key:\n print(\"Cohere API key not found. Skipping reranking.\")\n return documents\n\n cohere_client = cohere.Client(self.cohere_api_key)\n compressed_docs: list[Document] = []\n\n if not documents: # to avoid empty api call\n return compressed_docs\n\n _docs = [d.content for d in documents]\n response = cohere_client.rerank(\n model=self.model_name, query=query, documents=_docs\n )\n # print(\"Cohere score\", [r.relevance_score for r in response.results])\n for r in response.results:\n doc = documents[r.index]\n doc.metadata[\"cohere_reranking_score\"] = r.relevance_score\n compressed_docs.append(doc)\n\n return compressed_docs\n
Use Cohere Reranker model to re-order documents with their relevance score
Source code in libs/kotaemon/kotaemon/indices/rankings/cohere.py
def run(self, documents: list[Document], query: str) -> list[Document]:\n \"\"\"Use Cohere Reranker model to re-order documents\n with their relevance score\"\"\"\n try:\n import cohere\n except ImportError:\n raise ImportError(\n \"Please install Cohere `pip install cohere` to use Cohere Reranking\"\n )\n\n # try to get COHERE_API_KEY from embeddings\n if not self.cohere_api_key and self.use_key_from_ktem:\n try:\n from ktem.embeddings.manager import (\n embedding_models_manager as embeddings,\n )\n\n cohere_model = embeddings.get(\"cohere\")\n ktem_cohere_api_key = cohere_model._kwargs.get( # type: ignore\n \"cohere_api_key\"\n )\n if ktem_cohere_api_key != \"your-key\":\n self.cohere_api_key = ktem_cohere_api_key\n except Exception as e:\n print(\"Cannot get Cohere API key from `ktem`\", e)\n\n if not self.cohere_api_key:\n print(\"Cohere API key not found. Skipping reranking.\")\n return documents\n\n cohere_client = cohere.Client(self.cohere_api_key)\n compressed_docs: list[Document] = []\n\n if not documents: # to avoid empty api call\n return compressed_docs\n\n _docs = [d.content for d in documents]\n response = cohere_client.rerank(\n model=self.model_name, query=query, documents=_docs\n )\n # print(\"Cohere score\", [r.relevance_score for r in response.results])\n for r in response.results:\n doc = documents[r.index]\n doc.metadata[\"cohere_reranking_score\"] = r.relevance_score\n compressed_docs.append(doc)\n\n return compressed_docs\n
Source code in libs/kotaemon/kotaemon/indices/rankings/llm.py
class LLMReranking(BaseReranking):\n llm: BaseLLM\n prompt_template: PromptTemplate = PromptTemplate(template=RERANK_PROMPT_TEMPLATE)\n top_k: int = 3\n concurrent: bool = True\n\n def run(\n self,\n documents: list[Document],\n query: str,\n ) -> list[Document]:\n \"\"\"Filter down documents based on their relevance to the query.\"\"\"\n filtered_docs = []\n output_parser = BooleanOutputParser()\n\n if self.concurrent:\n with ThreadPoolExecutor() as executor:\n futures = []\n for doc in documents:\n _prompt = self.prompt_template.populate(\n question=query, context=doc.get_content()\n )\n futures.append(executor.submit(lambda: self.llm(_prompt).text))\n\n results = [future.result() for future in futures]\n else:\n results = []\n for doc in documents:\n _prompt = self.prompt_template.populate(\n question=query, context=doc.get_content()\n )\n results.append(self.llm(_prompt).text)\n\n # use Boolean parser to extract relevancy output from LLM\n results = [output_parser.parse(result) for result in results]\n for include_doc, doc in zip(results, documents):\n if include_doc:\n filtered_docs.append(doc)\n\n # prevent returning empty result\n if len(filtered_docs) == 0:\n filtered_docs = documents[: self.top_k]\n\n return filtered_docs\n
Filter down documents based on their relevance to the query.
Source code in libs/kotaemon/kotaemon/indices/rankings/llm.py
def run(\n self,\n documents: list[Document],\n query: str,\n) -> list[Document]:\n \"\"\"Filter down documents based on their relevance to the query.\"\"\"\n filtered_docs = []\n output_parser = BooleanOutputParser()\n\n if self.concurrent:\n with ThreadPoolExecutor() as executor:\n futures = []\n for doc in documents:\n _prompt = self.prompt_template.populate(\n question=query, context=doc.get_content()\n )\n futures.append(executor.submit(lambda: self.llm(_prompt).text))\n\n results = [future.result() for future in futures]\n else:\n results = []\n for doc in documents:\n _prompt = self.prompt_template.populate(\n question=query, context=doc.get_content()\n )\n results.append(self.llm(_prompt).text)\n\n # use Boolean parser to extract relevancy output from LLM\n results = [output_parser.parse(result) for result in results]\n for include_doc, doc in zip(results, documents):\n if include_doc:\n filtered_docs.append(doc)\n\n # prevent returning empty result\n if len(filtered_docs) == 0:\n filtered_docs = documents[: self.top_k]\n\n return filtered_docs\n
Source code in libs/kotaemon/kotaemon/indices/rankings/llm_trulens.py
def validate_rating(rating) -> int:\n \"\"\"Validate a rating is between 0 and 10.\"\"\"\n\n if not 0 <= rating <= 10:\n raise ValueError(\"Rating must be between 0 and 10\")\n\n return rating\n
If the string does not match an integer or matches an integer outside the 0-10 range, raises an error instead. If multiple numbers are found within the expected 0-10 range, the smallest is returned.
Parameters:
Name Type Description Default sstr
String to extract rating from.
required
Returns:
Name Type Description intint
Extracted rating.
Raises:
Type Description ParseError
If no integers between 0 and 10 are found in the string.
Source code in libs/kotaemon/kotaemon/indices/rankings/llm_trulens.py
def re_0_10_rating(s: str) -> int:\n \"\"\"Extract a 0-10 rating from a string.\n\n If the string does not match an integer or matches an integer outside the\n 0-10 range, raises an error instead. If multiple numbers are found within\n the expected 0-10 range, the smallest is returned.\n\n Args:\n s: String to extract rating from.\n\n Returns:\n int: Extracted rating.\n\n Raises:\n ParseError: If no integers between 0 and 10 are found in the string.\n \"\"\"\n\n matches = PATTERN_INTEGER.findall(s)\n if not matches:\n raise AssertionError\n\n vals = set()\n for match in matches:\n try:\n vals.add(validate_rating(int(match)))\n except ValueError:\n pass\n\n if not vals:\n raise AssertionError\n\n # Min to handle cases like \"The rating is 8 out of 10.\"\n return min(vals)\n
A simple gated branching pipeline for executing multiple branches based on a condition.
This class extends the SimpleBranchingPipeline class and adds the ability to execute the branches until a branch returns a non-empty output based on a condition.
Attributes:
Name Type Description branchesList[BaseComponent]
The list of branches to be executed.
Example
from kotaemon.llms import (\n LCAzureChatOpenAI,\n BasePromptComponent,\n GatedLinearPipeline,\n)\nfrom kotaemon.parsers import RegexExtractor\n\ndef identity(x):\n return x\n\npipeline = GatedBranchingPipeline()\nllm = LCAzureChatOpenAI(\n openai_api_base=\"your openai api base\",\n openai_api_key=\"your openai api key\",\n openai_api_version=\"your openai api version\",\n deployment_name=\"dummy-q2-gpt35\",\n temperature=0,\n request_timeout=600,\n)\n\nfor i in range(3):\n pipeline.add_branch(\n GatedLinearPipeline(\n prompt=BasePromptComponent(template=f\"what is {i} in Japanese ?\"),\n condition=RegexExtractor(pattern=f\"{i}\"),\n llm=llm,\n post_processor=identity,\n )\n )\nprint(pipeline(condition_text=\"1\"))\nprint(pipeline(condition_text=\"2\"))\n
Source code in libs/kotaemon/kotaemon/llms/branching.py
class GatedBranchingPipeline(SimpleBranchingPipeline):\n \"\"\"\n A simple gated branching pipeline for executing multiple branches based on a\n condition.\n\n This class extends the SimpleBranchingPipeline class and adds the ability to execute\n the branches until a branch returns a non-empty output based on a condition.\n\n Attributes:\n branches (List[BaseComponent]): The list of branches to be executed.\n\n Example:\n ```python\n from kotaemon.llms import (\n LCAzureChatOpenAI,\n BasePromptComponent,\n GatedLinearPipeline,\n )\n from kotaemon.parsers import RegexExtractor\n\n def identity(x):\n return x\n\n pipeline = GatedBranchingPipeline()\n llm = LCAzureChatOpenAI(\n openai_api_base=\"your openai api base\",\n openai_api_key=\"your openai api key\",\n openai_api_version=\"your openai api version\",\n deployment_name=\"dummy-q2-gpt35\",\n temperature=0,\n request_timeout=600,\n )\n\n for i in range(3):\n pipeline.add_branch(\n GatedLinearPipeline(\n prompt=BasePromptComponent(template=f\"what is {i} in Japanese ?\"),\n condition=RegexExtractor(pattern=f\"{i}\"),\n llm=llm,\n post_processor=identity,\n )\n )\n print(pipeline(condition_text=\"1\"))\n print(pipeline(condition_text=\"2\"))\n ```\n \"\"\"\n\n def run(self, *, condition_text: Optional[str] = None, **prompt_kwargs):\n \"\"\"\n Execute the pipeline by running each branch and return the output of the first\n branch that returns a non-empty output based on the provided condition.\n\n Args:\n condition_text (str): The condition text to evaluate for each branch.\n Default to None.\n **prompt_kwargs: Keyword arguments for the branches.\n\n Returns:\n Union[OutputType, None]: The output of the first branch that satisfies the\n condition, or None if no branch satisfies the condition.\n\n Raises:\n ValueError: If condition_text is None\n \"\"\"\n if condition_text is None:\n raise ValueError(\"`condition_text` must be provided.\")\n\n for i, branch in enumerate(self.branches):\n self._prepare_child(branch, name=f\"branch-{i}\")\n output = branch(condition_text=condition_text, **prompt_kwargs)\n if output:\n return output\n\n return Document(None)\n
Execute the pipeline by running each branch and return the output of the first branch that returns a non-empty output based on the provided condition.
Parameters:
Name Type Description Default condition_textstr
The condition text to evaluate for each branch. Default to None.
None**prompt_kwargs
Keyword arguments for the branches.
{}
Returns:
Type Description
Union[OutputType, None]: The output of the first branch that satisfies the
condition, or None if no branch satisfies the condition.
Raises:
Type Description ValueError
If condition_text is None
Source code in libs/kotaemon/kotaemon/llms/branching.py
def run(self, *, condition_text: Optional[str] = None, **prompt_kwargs):\n \"\"\"\n Execute the pipeline by running each branch and return the output of the first\n branch that returns a non-empty output based on the provided condition.\n\n Args:\n condition_text (str): The condition text to evaluate for each branch.\n Default to None.\n **prompt_kwargs: Keyword arguments for the branches.\n\n Returns:\n Union[OutputType, None]: The output of the first branch that satisfies the\n condition, or None if no branch satisfies the condition.\n\n Raises:\n ValueError: If condition_text is None\n \"\"\"\n if condition_text is None:\n raise ValueError(\"`condition_text` must be provided.\")\n\n for i, branch in enumerate(self.branches):\n self._prepare_child(branch, name=f\"branch-{i}\")\n output = branch(condition_text=condition_text, **prompt_kwargs)\n if output:\n return output\n\n return Document(None)\n
A simple branching pipeline for executing multiple branches.
Attributes:
Name Type Description branchesList[BaseComponent]
The list of branches to be executed.
Example
from kotaemon.llms import (\n LCAzureChatOpenAI,\n BasePromptComponent,\n GatedLinearPipeline,\n)\nfrom kotaemon.parsers import RegexExtractor\n\ndef identity(x):\n return x\n\npipeline = SimpleBranchingPipeline()\nllm = LCAzureChatOpenAI(\n openai_api_base=\"your openai api base\",\n openai_api_key=\"your openai api key\",\n openai_api_version=\"your openai api version\",\n deployment_name=\"dummy-q2-gpt35\",\n temperature=0,\n request_timeout=600,\n)\n\nfor i in range(3):\n pipeline.add_branch(\n GatedLinearPipeline(\n prompt=BasePromptComponent(template=f\"what is {i} in Japanese ?\"),\n condition=RegexExtractor(pattern=f\"{i}\"),\n llm=llm,\n post_processor=identity,\n )\n )\nprint(pipeline(condition_text=\"1\"))\nprint(pipeline(condition_text=\"2\"))\nprint(pipeline(condition_text=\"12\"))\n
Source code in libs/kotaemon/kotaemon/llms/branching.py
class SimpleBranchingPipeline(BaseComponent):\n \"\"\"\n A simple branching pipeline for executing multiple branches.\n\n Attributes:\n branches (List[BaseComponent]): The list of branches to be executed.\n\n Example:\n ```python\n from kotaemon.llms import (\n LCAzureChatOpenAI,\n BasePromptComponent,\n GatedLinearPipeline,\n )\n from kotaemon.parsers import RegexExtractor\n\n def identity(x):\n return x\n\n pipeline = SimpleBranchingPipeline()\n llm = LCAzureChatOpenAI(\n openai_api_base=\"your openai api base\",\n openai_api_key=\"your openai api key\",\n openai_api_version=\"your openai api version\",\n deployment_name=\"dummy-q2-gpt35\",\n temperature=0,\n request_timeout=600,\n )\n\n for i in range(3):\n pipeline.add_branch(\n GatedLinearPipeline(\n prompt=BasePromptComponent(template=f\"what is {i} in Japanese ?\"),\n condition=RegexExtractor(pattern=f\"{i}\"),\n llm=llm,\n post_processor=identity,\n )\n )\n print(pipeline(condition_text=\"1\"))\n print(pipeline(condition_text=\"2\"))\n print(pipeline(condition_text=\"12\"))\n ```\n \"\"\"\n\n branches: List[BaseComponent] = Param(default_callback=lambda *_: [])\n\n def add_branch(self, component: BaseComponent):\n \"\"\"\n Add a new branch to the pipeline.\n\n Args:\n component (BaseComponent): The branch component to be added.\n \"\"\"\n self.branches.append(component)\n\n def run(self, **prompt_kwargs):\n \"\"\"\n Execute the pipeline by running each branch and return the outputs as a list.\n\n Args:\n **prompt_kwargs: Keyword arguments for the branches.\n\n Returns:\n List: The outputs of each branch as a list.\n \"\"\"\n output = []\n for i, branch in enumerate(self.branches):\n self._prepare_child(branch, name=f\"branch-{i}\")\n output.append(branch(**prompt_kwargs))\n\n return output\n
Name Type Description Default componentBaseComponent
The branch component to be added.
required Source code in libs/kotaemon/kotaemon/llms/branching.py
def add_branch(self, component: BaseComponent):\n \"\"\"\n Add a new branch to the pipeline.\n\n Args:\n component (BaseComponent): The branch component to be added.\n \"\"\"\n self.branches.append(component)\n
Execute the pipeline by running each branch and return the outputs as a list.
Parameters:
Name Type Description Default **prompt_kwargs
Keyword arguments for the branches.
{}
Returns:
Name Type Description List
The outputs of each branch as a list.
Source code in libs/kotaemon/kotaemon/llms/branching.py
def run(self, **prompt_kwargs):\n \"\"\"\n Execute the pipeline by running each branch and return the outputs as a list.\n\n Args:\n **prompt_kwargs: Keyword arguments for the branches.\n\n Returns:\n List: The outputs of each branch as a list.\n \"\"\"\n output = []\n for i, branch in enumerate(self.branches):\n self._prepare_child(branch, name=f\"branch-{i}\")\n output.append(branch(**prompt_kwargs))\n\n return output\n
Generate response from messages Args: messages (str | BaseMessage | list[BaseMessage]): history of messages to generate response from **kwargs: additional arguments to pass to the OpenAI API Returns: LLMInterface: generated response
Source code in libs/kotaemon/kotaemon/llms/chats/endpoint_based.py
def run(\n self, messages: str | BaseMessage | list[BaseMessage], **kwargs\n) -> LLMInterface:\n \"\"\"\n Generate response from messages\n Args:\n messages (str | BaseMessage | list[BaseMessage]): history of messages to\n generate response from\n **kwargs: additional arguments to pass to the OpenAI API\n Returns:\n LLMInterface: generated response\n \"\"\"\n if isinstance(messages, str):\n input_ = [HumanMessage(content=messages)]\n elif isinstance(messages, BaseMessage):\n input_ = [messages]\n else:\n input_ = messages\n\n def decide_role(message: BaseMessage):\n if isinstance(message, SystemMessage):\n return \"system\"\n elif isinstance(message, AIMessage):\n return \"assistant\"\n else:\n return \"user\"\n\n request_json = {\n \"messages\": [{\"content\": m.text, \"role\": decide_role(m)} for m in input_]\n }\n\n response = requests.post(self.endpoint_url, json=request_json).json()\n\n content = \"\"\n candidates = []\n if response[\"choices\"]:\n candidates = [\n each[\"message\"][\"content\"]\n for each in response[\"choices\"]\n if each[\"message\"][\"content\"]\n ]\n content = candidates[0]\n\n return LLMInterface(\n content=content,\n candidates=candidates,\n completion_tokens=response[\"usage\"][\"completion_tokens\"],\n total_tokens=response[\"usage\"][\"total_tokens\"],\n prompt_tokens=response[\"usage\"][\"prompt_tokens\"],\n )\n
Source code in libs/kotaemon/kotaemon/llms/chats/llamacpp.py
class LlamaCppChat(ChatLLM):\n \"\"\"Wrapper around the llama-cpp-python's Llama model\"\"\"\n\n model_path: Optional[str] = Param(\n help=\"Path to the model file. This is required to load the model.\",\n )\n repo_id: Optional[str] = Param(\n help=\"Id of a repo on the HuggingFace Hub in the form of `user_name/repo_name`.\"\n )\n filename: Optional[str] = Param(\n help=\"A filename or glob pattern to match the model file in the repo.\"\n )\n chat_format: str = Param(\n help=(\n \"Chat format to use. Please refer to llama_cpp.llama_chat_format for a \"\n \"list of supported formats. If blank, the chat format will be auto-\"\n \"inferred.\"\n ),\n required=True,\n )\n lora_base: Optional[str] = Param(None, help=\"Path to the base Lora model\")\n n_ctx: Optional[int] = Param(512, help=\"Text context, 0 = from model\")\n n_gpu_layers: Optional[int] = Param(\n 0,\n help=\"Number of layers to offload to GPU. If -1, all layers are offloaded\",\n )\n use_mmap: Optional[bool] = Param(\n True,\n help=(),\n )\n vocab_only: Optional[bool] = Param(\n False,\n help=\"If True, only the vocabulary is loaded. This is useful for debugging.\",\n )\n\n _role_mapper: dict[str, str] = {\n \"human\": \"user\",\n \"system\": \"system\",\n \"ai\": \"assistant\",\n }\n\n @Param.auto()\n def client_object(self) -> \"Llama\":\n \"\"\"Get the llama-cpp-python client object\"\"\"\n try:\n from llama_cpp import Llama\n except ImportError:\n raise ImportError(\n \"llama-cpp-python is not installed. \"\n \"Please install it using `pip install llama-cpp-python`\"\n )\n\n errors = []\n if not self.model_path and (not self.repo_id or not self.filename):\n errors.append(\n \"- `model_path` or `repo_id` and `filename` are required to load the\"\n \" model\"\n )\n\n if not self.chat_format:\n errors.append(\n \"- `chat_format` is required to know how to format the chat messages. \"\n \"Please refer to llama_cpp.llama_chat_format for a list of supported \"\n \"formats.\"\n )\n if errors:\n raise ValueError(\"\\n\".join(errors))\n\n if self.model_path:\n return Llama(\n model_path=cast(str, self.model_path),\n chat_format=self.chat_format,\n lora_base=self.lora_base,\n n_ctx=self.n_ctx,\n n_gpu_layers=self.n_gpu_layers,\n use_mmap=self.use_mmap,\n vocab_only=self.vocab_only,\n )\n else:\n return Llama.from_pretrained(\n repo_id=self.repo_id,\n filename=self.filename,\n chat_format=self.chat_format,\n lora_base=self.lora_base,\n n_ctx=self.n_ctx,\n n_gpu_layers=self.n_gpu_layers,\n use_mmap=self.use_mmap,\n vocab_only=self.vocab_only,\n )\n\n def prepare_message(\n self, messages: str | BaseMessage | list[BaseMessage]\n ) -> list[dict]:\n input_: list[BaseMessage] = []\n\n if isinstance(messages, str):\n input_ = [HumanMessage(content=messages)]\n elif isinstance(messages, BaseMessage):\n input_ = [messages]\n else:\n input_ = messages\n\n output_ = [\n {\"role\": self._role_mapper[each.type], \"content\": each.content}\n for each in input_\n ]\n\n return output_\n\n def invoke(\n self, messages: str | BaseMessage | list[BaseMessage], **kwargs\n ) -> LLMInterface:\n\n pred: \"CCCR\" = self.client_object.create_chat_completion(\n messages=self.prepare_message(messages),\n stream=False,\n )\n\n return LLMInterface(\n content=pred[\"choices\"][0][\"message\"][\"content\"] if pred[\"choices\"] else \"\",\n candidates=[\n c[\"message\"][\"content\"]\n for c in pred[\"choices\"]\n if c[\"message\"][\"content\"]\n ],\n completion_tokens=pred[\"usage\"][\"completion_tokens\"],\n total_tokens=pred[\"usage\"][\"total_tokens\"],\n prompt_tokens=pred[\"usage\"][\"prompt_tokens\"],\n )\n\n def stream(\n self, messages: str | BaseMessage | list[BaseMessage], **kwargs\n ) -> Iterator[LLMInterface]:\n pred = self.client_object.create_chat_completion(\n messages=self.prepare_message(messages),\n stream=True,\n )\n for chunk in pred:\n if not chunk[\"choices\"]:\n continue\n\n if \"content\" not in chunk[\"choices\"][0][\"delta\"]:\n continue\n\n yield LLMInterface(content=chunk[\"choices\"][0][\"delta\"][\"content\"])\n
Source code in libs/kotaemon/kotaemon/llms/chats/llamacpp.py
@Param.auto()\ndef client_object(self) -> \"Llama\":\n \"\"\"Get the llama-cpp-python client object\"\"\"\n try:\n from llama_cpp import Llama\n except ImportError:\n raise ImportError(\n \"llama-cpp-python is not installed. \"\n \"Please install it using `pip install llama-cpp-python`\"\n )\n\n errors = []\n if not self.model_path and (not self.repo_id or not self.filename):\n errors.append(\n \"- `model_path` or `repo_id` and `filename` are required to load the\"\n \" model\"\n )\n\n if not self.chat_format:\n errors.append(\n \"- `chat_format` is required to know how to format the chat messages. \"\n \"Please refer to llama_cpp.llama_chat_format for a list of supported \"\n \"formats.\"\n )\n if errors:\n raise ValueError(\"\\n\".join(errors))\n\n if self.model_path:\n return Llama(\n model_path=cast(str, self.model_path),\n chat_format=self.chat_format,\n lora_base=self.lora_base,\n n_ctx=self.n_ctx,\n n_gpu_layers=self.n_gpu_layers,\n use_mmap=self.use_mmap,\n vocab_only=self.vocab_only,\n )\n else:\n return Llama.from_pretrained(\n repo_id=self.repo_id,\n filename=self.filename,\n chat_format=self.chat_format,\n lora_base=self.lora_base,\n n_ctx=self.n_ctx,\n n_gpu_layers=self.n_gpu_layers,\n use_mmap=self.use_mmap,\n vocab_only=self.vocab_only,\n )\n
Perform sequential chain-of-thought with manual pre-defined prompts
This method supports variable number of steps. Each step corresponds to a kotaemon.pipelines.cot.Thought. Please refer that section for Thought's detail. This section is about chaining thought together.
Usage:
Create and run a chain of thought without \"+\" operator:
>>> from kotaemon.pipelines.cot import Thought, ManualSequentialChainOfThought\n>>> llm = LCAzureChatOpenAI(...)\n>>> thought1 = Thought(\n>>> prompt=\"Word {word} in {language} is \",\n>>> post_process=lambda string: {\"translated\": string},\n>>> )\n>>> thought2 = Thought(\n>>> prompt=\"Translate {translated} to Japanese\",\n>>> post_process=lambda string: {\"output\": string},\n>>> )\n>>> thought = ManualSequentialChainOfThought(thoughts=[thought1, thought2], llm=llm)\n>>> thought(word=\"hello\", language=\"French\")\n{'word': 'hello',\n 'language': 'French',\n 'translated': '\"Bonjour\"',\n 'output': '\u3053\u3093\u306b\u3061\u306f (Konnichiwa)'}\n
Create and run a chain of thought without \"+\" operator: Please refer the kotaemon.pipelines.cot.Thought section for examples.
This chain-of-thought optionally takes a termination check callback function. This function will be called after each thought is executed. It takes in a dictionary of all thought outputs so far, and it returns True or False. If True, the chain-of-thought will terminate. If unset, the default callback always returns False.
Source code in libs/kotaemon/kotaemon/llms/cot.py
class ManualSequentialChainOfThought(BaseComponent):\n \"\"\"Perform sequential chain-of-thought with manual pre-defined prompts\n\n This method supports variable number of steps. Each step corresponds to a\n `kotaemon.pipelines.cot.Thought`. Please refer that section for\n Thought's detail. This section is about chaining thought together.\n\n _**Usage:**_\n\n **Create and run a chain of thought without \"+\" operator:**\n\n ```pycon\n >>> from kotaemon.pipelines.cot import Thought, ManualSequentialChainOfThought\n >>> llm = LCAzureChatOpenAI(...)\n >>> thought1 = Thought(\n >>> prompt=\"Word {word} in {language} is \",\n >>> post_process=lambda string: {\"translated\": string},\n >>> )\n >>> thought2 = Thought(\n >>> prompt=\"Translate {translated} to Japanese\",\n >>> post_process=lambda string: {\"output\": string},\n >>> )\n >>> thought = ManualSequentialChainOfThought(thoughts=[thought1, thought2], llm=llm)\n >>> thought(word=\"hello\", language=\"French\")\n {'word': 'hello',\n 'language': 'French',\n 'translated': '\"Bonjour\"',\n 'output': '\u3053\u3093\u306b\u3061\u306f (Konnichiwa)'}\n ```\n\n **Create and run a chain of thought without \"+\" operator:** Please refer the\n `kotaemon.pipelines.cot.Thought` section for examples.\n\n This chain-of-thought optionally takes a termination check callback function.\n This function will be called after each thought is executed. It takes in a\n dictionary of all thought outputs so far, and it returns True or False. If\n True, the chain-of-thought will terminate. If unset, the default callback always\n returns False.\n \"\"\"\n\n thoughts: List[Thought] = Param(\n default_callback=lambda *_: [], help=\"List of Thought\"\n )\n llm: LLM = Param(help=\"The LLM model to use (base of kotaemon.llms.BaseLLM)\")\n terminate: Callable = Param(\n default=lambda _: False,\n help=\"Callback on terminate condition. Default to always return False\",\n )\n\n def run(self, **kwargs) -> Document:\n \"\"\"Run the manual chain of thought\"\"\"\n\n inputs = deepcopy(kwargs)\n for idx, thought in enumerate(self.thoughts):\n if self.llm:\n thought.llm = self.llm\n self._prepare_child(thought, f\"thought{idx}\")\n\n output = thought(**inputs)\n inputs.update(output.content)\n if self.terminate(inputs):\n break\n\n return Document(inputs)\n\n def __add__(self, next_thought: Thought) -> \"ManualSequentialChainOfThought\":\n return ManualSequentialChainOfThought(\n thoughts=self.thoughts + [next_thought], llm=self.llm\n )\n
def run(self, **kwargs) -> Document:\n \"\"\"Run the manual chain of thought\"\"\"\n\n inputs = deepcopy(kwargs)\n for idx, thought in enumerate(self.thoughts):\n if self.llm:\n thought.llm = self.llm\n self._prepare_child(thought, f\"thought{idx}\")\n\n output = thought(**inputs)\n inputs.update(output.content)\n if self.terminate(inputs):\n break\n\n return Document(inputs)\n
Input: **kwargs pairs, where key is the placeholder in the prompt, and value is the value.
Output: an output dictionary
Usage:
Create and run a thought:
>> from kotaemon.pipelines.cot import Thought\n>> thought = Thought(\n prompt=\"How to {action} {object}?\",\n llm=LCAzureChatOpenAI(...),\n post_process=lambda string: {\"tutorial\": string},\n )\n>> output = thought(action=\"install\", object=\"python\")\n>> print(output)\n{'tutorial': 'As an AI language model,...'}\n
Basically, when a thought is run, it will:
Populate the prompt template with the input **kwargs.
Run the LLM model with the populated prompt.
Post-process the LLM output with the post-processor.
This Thought allows chaining sequentially with the + operator. For example:
Under the hood, when the + operator is used, a ManualSequentialChainOfThought is created.
Source code in libs/kotaemon/kotaemon/llms/cot.py
class Thought(BaseComponent):\n \"\"\"A thought in the chain of thought\n\n - Input: `**kwargs` pairs, where key is the placeholder in the prompt, and\n value is the value.\n - Output: an output dictionary\n\n _**Usage:**_\n\n Create and run a thought:\n\n ```python\n >> from kotaemon.pipelines.cot import Thought\n >> thought = Thought(\n prompt=\"How to {action} {object}?\",\n llm=LCAzureChatOpenAI(...),\n post_process=lambda string: {\"tutorial\": string},\n )\n >> output = thought(action=\"install\", object=\"python\")\n >> print(output)\n {'tutorial': 'As an AI language model,...'}\n ```\n\n Basically, when a thought is run, it will:\n\n 1. Populate the prompt template with the input `**kwargs`.\n 2. Run the LLM model with the populated prompt.\n 3. Post-process the LLM output with the post-processor.\n\n This `Thought` allows chaining sequentially with the + operator. For example:\n\n ```python\n >> llm = LCAzureChatOpenAI(...)\n >> thought1 = Thought(\n prompt=\"Word {word} in {language} is \",\n llm=llm,\n post_process=lambda string: {\"translated\": string},\n )\n >> thought2 = Thought(\n prompt=\"Translate {translated} to Japanese\",\n llm=llm,\n post_process=lambda string: {\"output\": string},\n )\n\n >> thought = thought1 + thought2\n >> thought(word=\"hello\", language=\"French\")\n {'word': 'hello',\n 'language': 'French',\n 'translated': '\"Bonjour\"',\n 'output': '\u3053\u3093\u306b\u3061\u306f (Konnichiwa)'}\n ```\n\n Under the hood, when the `+` operator is used, a `ManualSequentialChainOfThought`\n is created.\n \"\"\"\n\n prompt: str = Param(\n help=(\n \"The prompt template string. This prompt template has Python-like variable\"\n \" placeholders, that then will be substituted with real values when this\"\n \" component is executed\"\n )\n )\n llm: LLM = Node(LCAzureChatOpenAI, help=\"The LLM model to execute the input prompt\")\n post_process: Function = Node(\n help=(\n \"The function post-processor that post-processes LLM output prediction .\"\n \"It should take a string as input (this is the LLM output text) and return \"\n \"a dictionary, where the key should\"\n )\n )\n\n @Node.auto(depends_on=\"prompt\")\n def prompt_template(self):\n \"\"\"Automatically wrap around param prompt. Can ignore\"\"\"\n return BasePromptComponent(template=self.prompt)\n\n def run(self, **kwargs) -> Document:\n \"\"\"Run the chain of thought\"\"\"\n prompt = self.prompt_template(**kwargs).text\n response = self.llm(prompt).text\n response = self.post_process(response)\n\n return Document(response)\n\n def get_variables(self) -> List[str]:\n return []\n\n def __add__(self, next_thought: \"Thought\") -> \"ManualSequentialChainOfThought\":\n return ManualSequentialChainOfThought(\n thoughts=[self, next_thought], llm=self.llm\n )\n
A pipeline that extends the SimpleLinearPipeline class and adds a condition attribute.
Attributes:
Name Type Description conditionCallable[[IO_Type], Any]
A callable function that represents the condition.
Usage Example Usage
from kotaemon.llms import LCAzureChatOpenAI, BasePromptComponent\nfrom kotaemon.parsers import RegexExtractor\n\ndef identity(x):\n return x\n\nllm = LCAzureChatOpenAI(\n openai_api_base=\"your openai api base\",\n openai_api_key=\"your openai api key\",\n openai_api_version=\"your openai api version\",\n deployment_name=\"dummy-q2-gpt35\",\n temperature=0,\n request_timeout=600,\n)\n\npipeline = GatedLinearPipeline(\n prompt=BasePromptComponent(template=\"what is {word} in Japanese ?\"),\n condition=RegexExtractor(pattern=\"some pattern\"),\n llm=llm,\n post_processor=identity,\n)\nprint(pipeline(condition_text=\"some pattern\", word=\"lone\"))\nprint(pipeline(condition_text=\"other pattern\", word=\"lone\"))\n
Source code in libs/kotaemon/kotaemon/llms/linear.py
class GatedLinearPipeline(SimpleLinearPipeline):\n \"\"\"\n A pipeline that extends the SimpleLinearPipeline class and adds a condition\n attribute.\n\n Attributes:\n condition (Callable[[IO_Type], Any]): A callable function that represents the\n condition.\n\n Usage:\n ```{.py3 title=\"Example Usage\"}\n from kotaemon.llms import LCAzureChatOpenAI, BasePromptComponent\n from kotaemon.parsers import RegexExtractor\n\n def identity(x):\n return x\n\n llm = LCAzureChatOpenAI(\n openai_api_base=\"your openai api base\",\n openai_api_key=\"your openai api key\",\n openai_api_version=\"your openai api version\",\n deployment_name=\"dummy-q2-gpt35\",\n temperature=0,\n request_timeout=600,\n )\n\n pipeline = GatedLinearPipeline(\n prompt=BasePromptComponent(template=\"what is {word} in Japanese ?\"),\n condition=RegexExtractor(pattern=\"some pattern\"),\n llm=llm,\n post_processor=identity,\n )\n print(pipeline(condition_text=\"some pattern\", word=\"lone\"))\n print(pipeline(condition_text=\"other pattern\", word=\"lone\"))\n ```\n \"\"\"\n\n condition: Callable[[IO_Type], Any]\n\n def run(\n self,\n *,\n condition_text: Optional[str] = None,\n llm_kwargs: Optional[dict] = {},\n post_processor_kwargs: Optional[dict] = {},\n **prompt_kwargs,\n ) -> Document:\n \"\"\"\n Run the pipeline with the given arguments and return the final output as a\n Document object.\n\n Args:\n condition_text (str): The condition text to evaluate. Default to None.\n llm_kwargs (dict): Additional keyword arguments for the language model call.\n post_processor_kwargs (dict): Additional keyword arguments for the\n post-processor.\n **prompt_kwargs: Keyword arguments for populating the prompt.\n\n Returns:\n Document: The final output of the pipeline as a Document object.\n\n Raises:\n ValueError: If condition_text is None\n \"\"\"\n if condition_text is None:\n raise ValueError(\"`condition_text` must be provided\")\n\n if self.condition(condition_text)[0]:\n return super().run(\n llm_kwargs=llm_kwargs,\n post_processor_kwargs=post_processor_kwargs,\n **prompt_kwargs,\n )\n\n return Document(None)\n
Run the pipeline with the given arguments and return the final output as a Document object.
Parameters:
Name Type Description Default condition_textstr
The condition text to evaluate. Default to None.
Nonellm_kwargsdict
Additional keyword arguments for the language model call.
{}post_processor_kwargsdict
Additional keyword arguments for the post-processor.
{}**prompt_kwargs
Keyword arguments for populating the prompt.
{}
Returns:
Name Type Description DocumentDocument
The final output of the pipeline as a Document object.
Raises:
Type Description ValueError
If condition_text is None
Source code in libs/kotaemon/kotaemon/llms/linear.py
def run(\n self,\n *,\n condition_text: Optional[str] = None,\n llm_kwargs: Optional[dict] = {},\n post_processor_kwargs: Optional[dict] = {},\n **prompt_kwargs,\n) -> Document:\n \"\"\"\n Run the pipeline with the given arguments and return the final output as a\n Document object.\n\n Args:\n condition_text (str): The condition text to evaluate. Default to None.\n llm_kwargs (dict): Additional keyword arguments for the language model call.\n post_processor_kwargs (dict): Additional keyword arguments for the\n post-processor.\n **prompt_kwargs: Keyword arguments for populating the prompt.\n\n Returns:\n Document: The final output of the pipeline as a Document object.\n\n Raises:\n ValueError: If condition_text is None\n \"\"\"\n if condition_text is None:\n raise ValueError(\"`condition_text` must be provided\")\n\n if self.condition(condition_text)[0]:\n return super().run(\n llm_kwargs=llm_kwargs,\n post_processor_kwargs=post_processor_kwargs,\n **prompt_kwargs,\n )\n\n return Document(None)\n
from kotaemon.llms import LCAzureChatOpenAI, BasePromptComponent\n\ndef identity(x):\n return x\n\nllm = LCAzureChatOpenAI(\n openai_api_base=\"your openai api base\",\n openai_api_key=\"your openai api key\",\n openai_api_version=\"your openai api version\",\n deployment_name=\"dummy-q2-gpt35\",\n temperature=0,\n request_timeout=600,\n)\n\npipeline = SimpleLinearPipeline(\n prompt=BasePromptComponent(template=\"what is {word} in Japanese ?\"),\n llm=llm,\n post_processor=identity,\n)\nprint(pipeline(word=\"lone\"))\n
Source code in libs/kotaemon/kotaemon/llms/linear.py
class SimpleLinearPipeline(BaseComponent):\n \"\"\"\n A simple pipeline for running a function with a prompt, a language model, and an\n optional post-processor.\n\n Attributes:\n prompt (BasePromptComponent): The prompt component used to generate the initial\n input.\n llm (Union[ChatLLM, LLM]): The language model component used to generate the\n output.\n post_processor (Union[BaseComponent, Callable[[IO_Type], IO_Type]]): An optional\n post-processor component or function.\n\n Example Usage:\n ```python\n from kotaemon.llms import LCAzureChatOpenAI, BasePromptComponent\n\n def identity(x):\n return x\n\n llm = LCAzureChatOpenAI(\n openai_api_base=\"your openai api base\",\n openai_api_key=\"your openai api key\",\n openai_api_version=\"your openai api version\",\n deployment_name=\"dummy-q2-gpt35\",\n temperature=0,\n request_timeout=600,\n )\n\n pipeline = SimpleLinearPipeline(\n prompt=BasePromptComponent(template=\"what is {word} in Japanese ?\"),\n llm=llm,\n post_processor=identity,\n )\n print(pipeline(word=\"lone\"))\n ```\n \"\"\"\n\n prompt: BasePromptComponent\n llm: Union[ChatLLM, LLM]\n post_processor: Union[BaseComponent, Callable[[IO_Type], IO_Type]]\n\n def run(\n self,\n *,\n llm_kwargs: Optional[dict] = {},\n post_processor_kwargs: Optional[dict] = {},\n **prompt_kwargs,\n ):\n \"\"\"\n Run the function with the given arguments and return the final output as a\n Document object.\n\n Args:\n llm_kwargs (dict): Keyword arguments for the llm call.\n post_processor_kwargs (dict): Keyword arguments for the post_processor.\n **prompt_kwargs: Keyword arguments for populating the prompt.\n\n Returns:\n Document: The final output of the function as a Document object.\n \"\"\"\n prompt = self.prompt(**prompt_kwargs)\n llm_output = self.llm(prompt.text, **llm_kwargs)\n if self.post_processor is not None:\n final_output = self.post_processor(llm_output, **post_processor_kwargs)[0]\n else:\n final_output = llm_output\n\n return Document(final_output)\n
Run the function with the given arguments and return the final output as a Document object.
Parameters:
Name Type Description Default llm_kwargsdict
Keyword arguments for the llm call.
{}post_processor_kwargsdict
Keyword arguments for the post_processor.
{}**prompt_kwargs
Keyword arguments for populating the prompt.
{}
Returns:
Name Type Description Document
The final output of the function as a Document object.
Source code in libs/kotaemon/kotaemon/llms/linear.py
def run(\n self,\n *,\n llm_kwargs: Optional[dict] = {},\n post_processor_kwargs: Optional[dict] = {},\n **prompt_kwargs,\n):\n \"\"\"\n Run the function with the given arguments and return the final output as a\n Document object.\n\n Args:\n llm_kwargs (dict): Keyword arguments for the llm call.\n post_processor_kwargs (dict): Keyword arguments for the post_processor.\n **prompt_kwargs: Keyword arguments for populating the prompt.\n\n Returns:\n Document: The final output of the function as a Document object.\n \"\"\"\n prompt = self.prompt(**prompt_kwargs)\n llm_output = self.llm(prompt.text, **llm_kwargs)\n if self.post_processor is not None:\n final_output = self.post_processor(llm_output, **post_processor_kwargs)[0]\n else:\n final_output = llm_output\n\n return Document(final_output)\n
Name Type Description Default templatePromptTemplate
The prompt template.
required **kwargs
Any additional keyword arguments that will be used to populate the given template.
{} Source code in libs/kotaemon/kotaemon/llms/prompts/base.py
class BasePromptComponent(BaseComponent):\n \"\"\"\n Base class for prompt components.\n\n Args:\n template (PromptTemplate): The prompt template.\n **kwargs: Any additional keyword arguments that will be used to populate the\n given template.\n \"\"\"\n\n class Config:\n middleware_switches = {\"theflow.middleware.CachingMiddleware\": False}\n allow_extra = True\n\n template: str | PromptTemplate\n\n @Param.auto(depends_on=\"template\")\n def template__(self):\n return (\n self.template\n if isinstance(self.template, PromptTemplate)\n else PromptTemplate(self.template)\n )\n\n def __init__(self, **kwargs):\n super().__init__(**kwargs)\n self.__set(**kwargs)\n\n def __check_redundant_kwargs(self, **kwargs):\n \"\"\"\n Check for redundant keyword arguments.\n\n Parameters:\n **kwargs (dict): A dictionary of keyword arguments.\n\n Raises:\n ValueError: If any keys provided are not in the template.\n\n Returns:\n None\n \"\"\"\n self.template__.check_redundant_kwargs(**kwargs)\n\n def __check_unset_placeholders(self):\n \"\"\"\n Check if all the placeholders in the template are set.\n\n This function checks if all the expected placeholders in the template are set as\n attributes of the object. If any placeholders are missing, a `ValueError`\n is raised with the names of the missing keys.\n\n Parameters:\n None\n\n Returns:\n None\n \"\"\"\n self.template__.check_missing_kwargs(**self.__dict__)\n\n def __validate_value_type(self, **kwargs):\n \"\"\"\n Validates the value types of the given keyword arguments.\n\n Parameters:\n **kwargs (dict): A dictionary of keyword arguments to be validated.\n\n Raises:\n ValueError: If any of the values in the kwargs dictionary have an\n unsupported type.\n\n Returns:\n None\n \"\"\"\n type_error = []\n for k, v in kwargs.items():\n if k.startswith(\"template\"):\n continue\n if not isinstance(v, (str, int, Document, Callable)): # type: ignore\n type_error.append((k, type(v)))\n\n if type_error:\n raise ValueError(\n \"Type of values must be either int, str, Document, Callable, \"\n f\"found unsupported type for (key, type): {type_error}\"\n )\n\n def __set(self, **kwargs):\n \"\"\"\n Set the values of the attributes in the object based on the provided keyword\n arguments.\n\n Args:\n kwargs (dict): A dictionary with the attribute names as keys and the new\n values as values.\n\n Returns:\n None\n \"\"\"\n self.__check_redundant_kwargs(**kwargs)\n self.__validate_value_type(**kwargs)\n\n self.__dict__.update(kwargs)\n\n def __prepare_value(self):\n \"\"\"\n Generate a dictionary of keyword arguments based on the template's placeholders\n and the current instance's attributes.\n\n Returns:\n dict: A dictionary of keyword arguments.\n \"\"\"\n\n def __prepare(key, value):\n if isinstance(value, str):\n return value\n if isinstance(value, (int, Document)):\n return str(value)\n\n raise ValueError(\n f\"Unsupported type {type(value)} for template value of key {key}\"\n )\n\n kwargs = {}\n for k in self.template__.placeholders:\n v = getattr(self, k)\n\n # if get a callable, execute to get its output\n if isinstance(v, Callable): # type: ignore[arg-type]\n v = v()\n\n if isinstance(v, list):\n v = str([__prepare(k, each) for each in v])\n elif isinstance(v, (str, int, Document)):\n v = __prepare(k, v)\n else:\n raise ValueError(\n f\"Unsupported type {type(v)} for template value of key `{k}`\"\n )\n kwargs[k] = v\n\n return kwargs\n\n def set_value(self, **kwargs):\n \"\"\"\n Similar to `__set` but for external use.\n\n Set the values of the attributes in the object based on the provided keyword\n arguments.\n\n Args:\n kwargs (dict): A dictionary with the attribute names as keys and the new\n values as values.\n\n Returns:\n None\n \"\"\"\n self.__set(**kwargs)\n\n def run(self, **kwargs):\n \"\"\"\n Run the function with the given keyword arguments.\n\n Args:\n **kwargs: The keyword arguments to pass to the function.\n\n Returns:\n The result of calling the `populate` method of the `template` object\n with the given keyword arguments.\n \"\"\"\n self.__set(**kwargs)\n self.__check_unset_placeholders()\n prepared_kwargs = self.__prepare_value()\n\n text = self.template__.populate(**prepared_kwargs)\n return Document(text=text, metadata={\"origin\": \"PromptComponent\"})\n\n def flow(self):\n return self.__call__()\n
Set the values of the attributes in the object based on the provided keyword arguments.
Parameters:
Name Type Description Default kwargsdict
A dictionary with the attribute names as keys and the new values as values.
{}
Returns:
Type Description
None
Source code in libs/kotaemon/kotaemon/llms/prompts/base.py
def set_value(self, **kwargs):\n \"\"\"\n Similar to `__set` but for external use.\n\n Set the values of the attributes in the object based on the provided keyword\n arguments.\n\n Args:\n kwargs (dict): A dictionary with the attribute names as keys and the new\n values as values.\n\n Returns:\n None\n \"\"\"\n self.__set(**kwargs)\n
Run the function with the given keyword arguments.
Parameters:
Name Type Description Default **kwargs
The keyword arguments to pass to the function.
{}
Returns:
Type Description
The result of calling the populate method of the template object
with the given keyword arguments.
Source code in libs/kotaemon/kotaemon/llms/prompts/base.py
def run(self, **kwargs):\n \"\"\"\n Run the function with the given keyword arguments.\n\n Args:\n **kwargs: The keyword arguments to pass to the function.\n\n Returns:\n The result of calling the `populate` method of the `template` object\n with the given keyword arguments.\n \"\"\"\n self.__set(**kwargs)\n self.__check_unset_placeholders()\n prepared_kwargs = self.__prepare_value()\n\n text = self.template__.populate(**prepared_kwargs)\n return Document(text=text, metadata={\"origin\": \"PromptComponent\"})\n
Source code in libs/kotaemon/kotaemon/llms/prompts/template.py
class PromptTemplate:\n \"\"\"\n Base class for prompt templates.\n \"\"\"\n\n def __init__(self, template: str, ignore_invalid=True):\n template = template\n formatter = Formatter()\n parsed_template = list(formatter.parse(template))\n\n placeholders = set()\n for _, key, _, _ in parsed_template:\n if key is None:\n continue\n if not key.isidentifier():\n if ignore_invalid:\n warnings.warn(f\"Ignore invalid placeholder: {key}.\", UserWarning)\n else:\n raise ValueError(\n \"Placeholder name must be a valid Python identifier, found:\"\n f\" {key}.\"\n )\n placeholders.add(key)\n\n self.template = template\n self.placeholders = placeholders\n self.__formatter = formatter\n self.__parsed_template = parsed_template\n\n def check_missing_kwargs(self, **kwargs):\n \"\"\"\n Check if all the placeholders in the template are set.\n\n This function checks if all the expected placeholders in the template are set as\n attributes of the object. If any placeholders are missing, a `ValueError`\n is raised with the names of the missing keys.\n\n Parameters:\n None\n\n Returns:\n None\n \"\"\"\n missing_keys = self.placeholders.difference(kwargs.keys())\n if missing_keys:\n raise ValueError(f\"Missing keys in template: {','.join(missing_keys)}\")\n\n def check_redundant_kwargs(self, **kwargs):\n \"\"\"\n Check if all the placeholders in the template are set.\n\n This function checks if all the expected placeholders in the template are set as\n attributes of the object. If any placeholders are missing, a `ValueError`\n is raised with the names of the missing keys.\n\n Parameters:\n None\n\n Returns:\n None\n \"\"\"\n provided_keys = set(kwargs.keys())\n redundant_keys = provided_keys - self.placeholders\n\n if redundant_keys:\n warnings.warn(\n f\"Keys provided but not in template: {','.join(redundant_keys)}\",\n UserWarning,\n )\n\n def populate(self, **kwargs) -> str:\n \"\"\"\n Strictly populate the template with the given keyword arguments.\n\n Args:\n **kwargs: The keyword arguments to populate the template.\n Each keyword corresponds to a placeholder in the template.\n\n Returns:\n The populated template.\n\n Raises:\n ValueError: If an unknown placeholder is provided.\n \"\"\"\n self.check_missing_kwargs(**kwargs)\n\n return self.partial_populate(**kwargs)\n\n def partial_populate(self, **kwargs):\n \"\"\"\n Partially populate the template with the given keyword arguments.\n\n Args:\n **kwargs: The keyword arguments to populate the template.\n Each keyword corresponds to a placeholder in the template.\n\n Returns:\n str: The populated template.\n \"\"\"\n self.check_redundant_kwargs(**kwargs)\n\n prompt = []\n for literal_text, field_name, format_spec, conversion in self.__parsed_template:\n prompt.append(literal_text)\n\n if field_name is None:\n continue\n\n if field_name not in kwargs:\n if conversion:\n value = f\"{{{field_name}}}!{conversion}:{format_spec}\"\n else:\n value = f\"{{{field_name}:{format_spec}}}\"\n else:\n value = kwargs[field_name]\n if conversion is not None:\n value = self.__formatter.convert_field(value, conversion)\n if format_spec is not None:\n value = self.__formatter.format_field(value, format_spec)\n\n prompt.append(value)\n\n return \"\".join(prompt)\n\n def __add__(self, other):\n \"\"\"\n Create a new PromptTemplate object by concatenating the template of the current\n object with the template of another PromptTemplate object.\n\n Parameters:\n other (PromptTemplate): Another PromptTemplate object.\n\n Returns:\n PromptTemplate: A new PromptTemplate object with the concatenated templates.\n \"\"\"\n return PromptTemplate(self.template + \"\\n\" + other.template)\n
Check if all the placeholders in the template are set.
This function checks if all the expected placeholders in the template are set as attributes of the object. If any placeholders are missing, a ValueError is raised with the names of the missing keys.
Returns:
Type Description
None
Source code in libs/kotaemon/kotaemon/llms/prompts/template.py
def check_missing_kwargs(self, **kwargs):\n \"\"\"\n Check if all the placeholders in the template are set.\n\n This function checks if all the expected placeholders in the template are set as\n attributes of the object. If any placeholders are missing, a `ValueError`\n is raised with the names of the missing keys.\n\n Parameters:\n None\n\n Returns:\n None\n \"\"\"\n missing_keys = self.placeholders.difference(kwargs.keys())\n if missing_keys:\n raise ValueError(f\"Missing keys in template: {','.join(missing_keys)}\")\n
Check if all the placeholders in the template are set.
This function checks if all the expected placeholders in the template are set as attributes of the object. If any placeholders are missing, a ValueError is raised with the names of the missing keys.
Returns:
Type Description
None
Source code in libs/kotaemon/kotaemon/llms/prompts/template.py
def check_redundant_kwargs(self, **kwargs):\n \"\"\"\n Check if all the placeholders in the template are set.\n\n This function checks if all the expected placeholders in the template are set as\n attributes of the object. If any placeholders are missing, a `ValueError`\n is raised with the names of the missing keys.\n\n Parameters:\n None\n\n Returns:\n None\n \"\"\"\n provided_keys = set(kwargs.keys())\n redundant_keys = provided_keys - self.placeholders\n\n if redundant_keys:\n warnings.warn(\n f\"Keys provided but not in template: {','.join(redundant_keys)}\",\n UserWarning,\n )\n
Strictly populate the template with the given keyword arguments.
Parameters:
Name Type Description Default **kwargs
The keyword arguments to populate the template. Each keyword corresponds to a placeholder in the template.
{}
Returns:
Type Description str
The populated template.
Raises:
Type Description ValueError
If an unknown placeholder is provided.
Source code in libs/kotaemon/kotaemon/llms/prompts/template.py
def populate(self, **kwargs) -> str:\n \"\"\"\n Strictly populate the template with the given keyword arguments.\n\n Args:\n **kwargs: The keyword arguments to populate the template.\n Each keyword corresponds to a placeholder in the template.\n\n Returns:\n The populated template.\n\n Raises:\n ValueError: If an unknown placeholder is provided.\n \"\"\"\n self.check_missing_kwargs(**kwargs)\n\n return self.partial_populate(**kwargs)\n
Partially populate the template with the given keyword arguments.
Parameters:
Name Type Description Default **kwargs
The keyword arguments to populate the template. Each keyword corresponds to a placeholder in the template.
{}
Returns:
Name Type Description str
The populated template.
Source code in libs/kotaemon/kotaemon/llms/prompts/template.py
def partial_populate(self, **kwargs):\n \"\"\"\n Partially populate the template with the given keyword arguments.\n\n Args:\n **kwargs: The keyword arguments to populate the template.\n Each keyword corresponds to a placeholder in the template.\n\n Returns:\n str: The populated template.\n \"\"\"\n self.check_redundant_kwargs(**kwargs)\n\n prompt = []\n for literal_text, field_name, format_spec, conversion in self.__parsed_template:\n prompt.append(literal_text)\n\n if field_name is None:\n continue\n\n if field_name not in kwargs:\n if conversion:\n value = f\"{{{field_name}}}!{conversion}:{format_spec}\"\n else:\n value = f\"{{{field_name}:{format_spec}}}\"\n else:\n value = kwargs[field_name]\n if conversion is not None:\n value = self.__formatter.convert_field(value, conversion)\n if format_spec is not None:\n value = self.__formatter.format_field(value, format_spec)\n\n prompt.append(value)\n\n return \"\".join(prompt)\n
A simple branching pipeline for executing multiple branches.
Attributes:
Name Type Description branchesList[BaseComponent]
The list of branches to be executed.
Example
from kotaemon.llms import (\n LCAzureChatOpenAI,\n BasePromptComponent,\n GatedLinearPipeline,\n)\nfrom kotaemon.parsers import RegexExtractor\n\ndef identity(x):\n return x\n\npipeline = SimpleBranchingPipeline()\nllm = LCAzureChatOpenAI(\n openai_api_base=\"your openai api base\",\n openai_api_key=\"your openai api key\",\n openai_api_version=\"your openai api version\",\n deployment_name=\"dummy-q2-gpt35\",\n temperature=0,\n request_timeout=600,\n)\n\nfor i in range(3):\n pipeline.add_branch(\n GatedLinearPipeline(\n prompt=BasePromptComponent(template=f\"what is {i} in Japanese ?\"),\n condition=RegexExtractor(pattern=f\"{i}\"),\n llm=llm,\n post_processor=identity,\n )\n )\nprint(pipeline(condition_text=\"1\"))\nprint(pipeline(condition_text=\"2\"))\nprint(pipeline(condition_text=\"12\"))\n
Source code in libs/kotaemon/kotaemon/llms/branching.py
class SimpleBranchingPipeline(BaseComponent):\n \"\"\"\n A simple branching pipeline for executing multiple branches.\n\n Attributes:\n branches (List[BaseComponent]): The list of branches to be executed.\n\n Example:\n ```python\n from kotaemon.llms import (\n LCAzureChatOpenAI,\n BasePromptComponent,\n GatedLinearPipeline,\n )\n from kotaemon.parsers import RegexExtractor\n\n def identity(x):\n return x\n\n pipeline = SimpleBranchingPipeline()\n llm = LCAzureChatOpenAI(\n openai_api_base=\"your openai api base\",\n openai_api_key=\"your openai api key\",\n openai_api_version=\"your openai api version\",\n deployment_name=\"dummy-q2-gpt35\",\n temperature=0,\n request_timeout=600,\n )\n\n for i in range(3):\n pipeline.add_branch(\n GatedLinearPipeline(\n prompt=BasePromptComponent(template=f\"what is {i} in Japanese ?\"),\n condition=RegexExtractor(pattern=f\"{i}\"),\n llm=llm,\n post_processor=identity,\n )\n )\n print(pipeline(condition_text=\"1\"))\n print(pipeline(condition_text=\"2\"))\n print(pipeline(condition_text=\"12\"))\n ```\n \"\"\"\n\n branches: List[BaseComponent] = Param(default_callback=lambda *_: [])\n\n def add_branch(self, component: BaseComponent):\n \"\"\"\n Add a new branch to the pipeline.\n\n Args:\n component (BaseComponent): The branch component to be added.\n \"\"\"\n self.branches.append(component)\n\n def run(self, **prompt_kwargs):\n \"\"\"\n Execute the pipeline by running each branch and return the outputs as a list.\n\n Args:\n **prompt_kwargs: Keyword arguments for the branches.\n\n Returns:\n List: The outputs of each branch as a list.\n \"\"\"\n output = []\n for i, branch in enumerate(self.branches):\n self._prepare_child(branch, name=f\"branch-{i}\")\n output.append(branch(**prompt_kwargs))\n\n return output\n
Name Type Description Default componentBaseComponent
The branch component to be added.
required Source code in libs/kotaemon/kotaemon/llms/branching.py
def add_branch(self, component: BaseComponent):\n \"\"\"\n Add a new branch to the pipeline.\n\n Args:\n component (BaseComponent): The branch component to be added.\n \"\"\"\n self.branches.append(component)\n
Execute the pipeline by running each branch and return the outputs as a list.
Parameters:
Name Type Description Default **prompt_kwargs
Keyword arguments for the branches.
{}
Returns:
Name Type Description List
The outputs of each branch as a list.
Source code in libs/kotaemon/kotaemon/llms/branching.py
def run(self, **prompt_kwargs):\n \"\"\"\n Execute the pipeline by running each branch and return the outputs as a list.\n\n Args:\n **prompt_kwargs: Keyword arguments for the branches.\n\n Returns:\n List: The outputs of each branch as a list.\n \"\"\"\n output = []\n for i, branch in enumerate(self.branches):\n self._prepare_child(branch, name=f\"branch-{i}\")\n output.append(branch(**prompt_kwargs))\n\n return output\n
A simple gated branching pipeline for executing multiple branches based on a condition.
This class extends the SimpleBranchingPipeline class and adds the ability to execute the branches until a branch returns a non-empty output based on a condition.
Attributes:
Name Type Description branchesList[BaseComponent]
The list of branches to be executed.
Example
from kotaemon.llms import (\n LCAzureChatOpenAI,\n BasePromptComponent,\n GatedLinearPipeline,\n)\nfrom kotaemon.parsers import RegexExtractor\n\ndef identity(x):\n return x\n\npipeline = GatedBranchingPipeline()\nllm = LCAzureChatOpenAI(\n openai_api_base=\"your openai api base\",\n openai_api_key=\"your openai api key\",\n openai_api_version=\"your openai api version\",\n deployment_name=\"dummy-q2-gpt35\",\n temperature=0,\n request_timeout=600,\n)\n\nfor i in range(3):\n pipeline.add_branch(\n GatedLinearPipeline(\n prompt=BasePromptComponent(template=f\"what is {i} in Japanese ?\"),\n condition=RegexExtractor(pattern=f\"{i}\"),\n llm=llm,\n post_processor=identity,\n )\n )\nprint(pipeline(condition_text=\"1\"))\nprint(pipeline(condition_text=\"2\"))\n
Source code in libs/kotaemon/kotaemon/llms/branching.py
class GatedBranchingPipeline(SimpleBranchingPipeline):\n \"\"\"\n A simple gated branching pipeline for executing multiple branches based on a\n condition.\n\n This class extends the SimpleBranchingPipeline class and adds the ability to execute\n the branches until a branch returns a non-empty output based on a condition.\n\n Attributes:\n branches (List[BaseComponent]): The list of branches to be executed.\n\n Example:\n ```python\n from kotaemon.llms import (\n LCAzureChatOpenAI,\n BasePromptComponent,\n GatedLinearPipeline,\n )\n from kotaemon.parsers import RegexExtractor\n\n def identity(x):\n return x\n\n pipeline = GatedBranchingPipeline()\n llm = LCAzureChatOpenAI(\n openai_api_base=\"your openai api base\",\n openai_api_key=\"your openai api key\",\n openai_api_version=\"your openai api version\",\n deployment_name=\"dummy-q2-gpt35\",\n temperature=0,\n request_timeout=600,\n )\n\n for i in range(3):\n pipeline.add_branch(\n GatedLinearPipeline(\n prompt=BasePromptComponent(template=f\"what is {i} in Japanese ?\"),\n condition=RegexExtractor(pattern=f\"{i}\"),\n llm=llm,\n post_processor=identity,\n )\n )\n print(pipeline(condition_text=\"1\"))\n print(pipeline(condition_text=\"2\"))\n ```\n \"\"\"\n\n def run(self, *, condition_text: Optional[str] = None, **prompt_kwargs):\n \"\"\"\n Execute the pipeline by running each branch and return the output of the first\n branch that returns a non-empty output based on the provided condition.\n\n Args:\n condition_text (str): The condition text to evaluate for each branch.\n Default to None.\n **prompt_kwargs: Keyword arguments for the branches.\n\n Returns:\n Union[OutputType, None]: The output of the first branch that satisfies the\n condition, or None if no branch satisfies the condition.\n\n Raises:\n ValueError: If condition_text is None\n \"\"\"\n if condition_text is None:\n raise ValueError(\"`condition_text` must be provided.\")\n\n for i, branch in enumerate(self.branches):\n self._prepare_child(branch, name=f\"branch-{i}\")\n output = branch(condition_text=condition_text, **prompt_kwargs)\n if output:\n return output\n\n return Document(None)\n
Execute the pipeline by running each branch and return the output of the first branch that returns a non-empty output based on the provided condition.
Parameters:
Name Type Description Default condition_textstr
The condition text to evaluate for each branch. Default to None.
None**prompt_kwargs
Keyword arguments for the branches.
{}
Returns:
Type Description
Union[OutputType, None]: The output of the first branch that satisfies the
condition, or None if no branch satisfies the condition.
Raises:
Type Description ValueError
If condition_text is None
Source code in libs/kotaemon/kotaemon/llms/branching.py
def run(self, *, condition_text: Optional[str] = None, **prompt_kwargs):\n \"\"\"\n Execute the pipeline by running each branch and return the output of the first\n branch that returns a non-empty output based on the provided condition.\n\n Args:\n condition_text (str): The condition text to evaluate for each branch.\n Default to None.\n **prompt_kwargs: Keyword arguments for the branches.\n\n Returns:\n Union[OutputType, None]: The output of the first branch that satisfies the\n condition, or None if no branch satisfies the condition.\n\n Raises:\n ValueError: If condition_text is None\n \"\"\"\n if condition_text is None:\n raise ValueError(\"`condition_text` must be provided.\")\n\n for i, branch in enumerate(self.branches):\n self._prepare_child(branch, name=f\"branch-{i}\")\n output = branch(condition_text=condition_text, **prompt_kwargs)\n if output:\n return output\n\n return Document(None)\n
Input: **kwargs pairs, where key is the placeholder in the prompt, and value is the value.
Output: an output dictionary
Usage:
Create and run a thought:
>> from kotaemon.pipelines.cot import Thought\n>> thought = Thought(\n prompt=\"How to {action} {object}?\",\n llm=LCAzureChatOpenAI(...),\n post_process=lambda string: {\"tutorial\": string},\n )\n>> output = thought(action=\"install\", object=\"python\")\n>> print(output)\n{'tutorial': 'As an AI language model,...'}\n
Basically, when a thought is run, it will:
Populate the prompt template with the input **kwargs.
Run the LLM model with the populated prompt.
Post-process the LLM output with the post-processor.
This Thought allows chaining sequentially with the + operator. For example:
Under the hood, when the + operator is used, a ManualSequentialChainOfThought is created.
Source code in libs/kotaemon/kotaemon/llms/cot.py
class Thought(BaseComponent):\n \"\"\"A thought in the chain of thought\n\n - Input: `**kwargs` pairs, where key is the placeholder in the prompt, and\n value is the value.\n - Output: an output dictionary\n\n _**Usage:**_\n\n Create and run a thought:\n\n ```python\n >> from kotaemon.pipelines.cot import Thought\n >> thought = Thought(\n prompt=\"How to {action} {object}?\",\n llm=LCAzureChatOpenAI(...),\n post_process=lambda string: {\"tutorial\": string},\n )\n >> output = thought(action=\"install\", object=\"python\")\n >> print(output)\n {'tutorial': 'As an AI language model,...'}\n ```\n\n Basically, when a thought is run, it will:\n\n 1. Populate the prompt template with the input `**kwargs`.\n 2. Run the LLM model with the populated prompt.\n 3. Post-process the LLM output with the post-processor.\n\n This `Thought` allows chaining sequentially with the + operator. For example:\n\n ```python\n >> llm = LCAzureChatOpenAI(...)\n >> thought1 = Thought(\n prompt=\"Word {word} in {language} is \",\n llm=llm,\n post_process=lambda string: {\"translated\": string},\n )\n >> thought2 = Thought(\n prompt=\"Translate {translated} to Japanese\",\n llm=llm,\n post_process=lambda string: {\"output\": string},\n )\n\n >> thought = thought1 + thought2\n >> thought(word=\"hello\", language=\"French\")\n {'word': 'hello',\n 'language': 'French',\n 'translated': '\"Bonjour\"',\n 'output': '\u3053\u3093\u306b\u3061\u306f (Konnichiwa)'}\n ```\n\n Under the hood, when the `+` operator is used, a `ManualSequentialChainOfThought`\n is created.\n \"\"\"\n\n prompt: str = Param(\n help=(\n \"The prompt template string. This prompt template has Python-like variable\"\n \" placeholders, that then will be substituted with real values when this\"\n \" component is executed\"\n )\n )\n llm: LLM = Node(LCAzureChatOpenAI, help=\"The LLM model to execute the input prompt\")\n post_process: Function = Node(\n help=(\n \"The function post-processor that post-processes LLM output prediction .\"\n \"It should take a string as input (this is the LLM output text) and return \"\n \"a dictionary, where the key should\"\n )\n )\n\n @Node.auto(depends_on=\"prompt\")\n def prompt_template(self):\n \"\"\"Automatically wrap around param prompt. Can ignore\"\"\"\n return BasePromptComponent(template=self.prompt)\n\n def run(self, **kwargs) -> Document:\n \"\"\"Run the chain of thought\"\"\"\n prompt = self.prompt_template(**kwargs).text\n response = self.llm(prompt).text\n response = self.post_process(response)\n\n return Document(response)\n\n def get_variables(self) -> List[str]:\n return []\n\n def __add__(self, next_thought: \"Thought\") -> \"ManualSequentialChainOfThought\":\n return ManualSequentialChainOfThought(\n thoughts=[self, next_thought], llm=self.llm\n )\n
Perform sequential chain-of-thought with manual pre-defined prompts
This method supports variable number of steps. Each step corresponds to a kotaemon.pipelines.cot.Thought. Please refer that section for Thought's detail. This section is about chaining thought together.
Usage:
Create and run a chain of thought without \"+\" operator:
>>> from kotaemon.pipelines.cot import Thought, ManualSequentialChainOfThought\n>>> llm = LCAzureChatOpenAI(...)\n>>> thought1 = Thought(\n>>> prompt=\"Word {word} in {language} is \",\n>>> post_process=lambda string: {\"translated\": string},\n>>> )\n>>> thought2 = Thought(\n>>> prompt=\"Translate {translated} to Japanese\",\n>>> post_process=lambda string: {\"output\": string},\n>>> )\n>>> thought = ManualSequentialChainOfThought(thoughts=[thought1, thought2], llm=llm)\n>>> thought(word=\"hello\", language=\"French\")\n{'word': 'hello',\n 'language': 'French',\n 'translated': '\"Bonjour\"',\n 'output': '\u3053\u3093\u306b\u3061\u306f (Konnichiwa)'}\n
Create and run a chain of thought without \"+\" operator: Please refer the kotaemon.pipelines.cot.Thought section for examples.
This chain-of-thought optionally takes a termination check callback function. This function will be called after each thought is executed. It takes in a dictionary of all thought outputs so far, and it returns True or False. If True, the chain-of-thought will terminate. If unset, the default callback always returns False.
Source code in libs/kotaemon/kotaemon/llms/cot.py
class ManualSequentialChainOfThought(BaseComponent):\n \"\"\"Perform sequential chain-of-thought with manual pre-defined prompts\n\n This method supports variable number of steps. Each step corresponds to a\n `kotaemon.pipelines.cot.Thought`. Please refer that section for\n Thought's detail. This section is about chaining thought together.\n\n _**Usage:**_\n\n **Create and run a chain of thought without \"+\" operator:**\n\n ```pycon\n >>> from kotaemon.pipelines.cot import Thought, ManualSequentialChainOfThought\n >>> llm = LCAzureChatOpenAI(...)\n >>> thought1 = Thought(\n >>> prompt=\"Word {word} in {language} is \",\n >>> post_process=lambda string: {\"translated\": string},\n >>> )\n >>> thought2 = Thought(\n >>> prompt=\"Translate {translated} to Japanese\",\n >>> post_process=lambda string: {\"output\": string},\n >>> )\n >>> thought = ManualSequentialChainOfThought(thoughts=[thought1, thought2], llm=llm)\n >>> thought(word=\"hello\", language=\"French\")\n {'word': 'hello',\n 'language': 'French',\n 'translated': '\"Bonjour\"',\n 'output': '\u3053\u3093\u306b\u3061\u306f (Konnichiwa)'}\n ```\n\n **Create and run a chain of thought without \"+\" operator:** Please refer the\n `kotaemon.pipelines.cot.Thought` section for examples.\n\n This chain-of-thought optionally takes a termination check callback function.\n This function will be called after each thought is executed. It takes in a\n dictionary of all thought outputs so far, and it returns True or False. If\n True, the chain-of-thought will terminate. If unset, the default callback always\n returns False.\n \"\"\"\n\n thoughts: List[Thought] = Param(\n default_callback=lambda *_: [], help=\"List of Thought\"\n )\n llm: LLM = Param(help=\"The LLM model to use (base of kotaemon.llms.BaseLLM)\")\n terminate: Callable = Param(\n default=lambda _: False,\n help=\"Callback on terminate condition. Default to always return False\",\n )\n\n def run(self, **kwargs) -> Document:\n \"\"\"Run the manual chain of thought\"\"\"\n\n inputs = deepcopy(kwargs)\n for idx, thought in enumerate(self.thoughts):\n if self.llm:\n thought.llm = self.llm\n self._prepare_child(thought, f\"thought{idx}\")\n\n output = thought(**inputs)\n inputs.update(output.content)\n if self.terminate(inputs):\n break\n\n return Document(inputs)\n\n def __add__(self, next_thought: Thought) -> \"ManualSequentialChainOfThought\":\n return ManualSequentialChainOfThought(\n thoughts=self.thoughts + [next_thought], llm=self.llm\n )\n
def run(self, **kwargs) -> Document:\n \"\"\"Run the manual chain of thought\"\"\"\n\n inputs = deepcopy(kwargs)\n for idx, thought in enumerate(self.thoughts):\n if self.llm:\n thought.llm = self.llm\n self._prepare_child(thought, f\"thought{idx}\")\n\n output = thought(**inputs)\n inputs.update(output.content)\n if self.terminate(inputs):\n break\n\n return Document(inputs)\n
from kotaemon.llms import LCAzureChatOpenAI, BasePromptComponent\n\ndef identity(x):\n return x\n\nllm = LCAzureChatOpenAI(\n openai_api_base=\"your openai api base\",\n openai_api_key=\"your openai api key\",\n openai_api_version=\"your openai api version\",\n deployment_name=\"dummy-q2-gpt35\",\n temperature=0,\n request_timeout=600,\n)\n\npipeline = SimpleLinearPipeline(\n prompt=BasePromptComponent(template=\"what is {word} in Japanese ?\"),\n llm=llm,\n post_processor=identity,\n)\nprint(pipeline(word=\"lone\"))\n
Source code in libs/kotaemon/kotaemon/llms/linear.py
class SimpleLinearPipeline(BaseComponent):\n \"\"\"\n A simple pipeline for running a function with a prompt, a language model, and an\n optional post-processor.\n\n Attributes:\n prompt (BasePromptComponent): The prompt component used to generate the initial\n input.\n llm (Union[ChatLLM, LLM]): The language model component used to generate the\n output.\n post_processor (Union[BaseComponent, Callable[[IO_Type], IO_Type]]): An optional\n post-processor component or function.\n\n Example Usage:\n ```python\n from kotaemon.llms import LCAzureChatOpenAI, BasePromptComponent\n\n def identity(x):\n return x\n\n llm = LCAzureChatOpenAI(\n openai_api_base=\"your openai api base\",\n openai_api_key=\"your openai api key\",\n openai_api_version=\"your openai api version\",\n deployment_name=\"dummy-q2-gpt35\",\n temperature=0,\n request_timeout=600,\n )\n\n pipeline = SimpleLinearPipeline(\n prompt=BasePromptComponent(template=\"what is {word} in Japanese ?\"),\n llm=llm,\n post_processor=identity,\n )\n print(pipeline(word=\"lone\"))\n ```\n \"\"\"\n\n prompt: BasePromptComponent\n llm: Union[ChatLLM, LLM]\n post_processor: Union[BaseComponent, Callable[[IO_Type], IO_Type]]\n\n def run(\n self,\n *,\n llm_kwargs: Optional[dict] = {},\n post_processor_kwargs: Optional[dict] = {},\n **prompt_kwargs,\n ):\n \"\"\"\n Run the function with the given arguments and return the final output as a\n Document object.\n\n Args:\n llm_kwargs (dict): Keyword arguments for the llm call.\n post_processor_kwargs (dict): Keyword arguments for the post_processor.\n **prompt_kwargs: Keyword arguments for populating the prompt.\n\n Returns:\n Document: The final output of the function as a Document object.\n \"\"\"\n prompt = self.prompt(**prompt_kwargs)\n llm_output = self.llm(prompt.text, **llm_kwargs)\n if self.post_processor is not None:\n final_output = self.post_processor(llm_output, **post_processor_kwargs)[0]\n else:\n final_output = llm_output\n\n return Document(final_output)\n
Run the function with the given arguments and return the final output as a Document object.
Parameters:
Name Type Description Default llm_kwargsdict
Keyword arguments for the llm call.
{}post_processor_kwargsdict
Keyword arguments for the post_processor.
{}**prompt_kwargs
Keyword arguments for populating the prompt.
{}
Returns:
Name Type Description Document
The final output of the function as a Document object.
Source code in libs/kotaemon/kotaemon/llms/linear.py
def run(\n self,\n *,\n llm_kwargs: Optional[dict] = {},\n post_processor_kwargs: Optional[dict] = {},\n **prompt_kwargs,\n):\n \"\"\"\n Run the function with the given arguments and return the final output as a\n Document object.\n\n Args:\n llm_kwargs (dict): Keyword arguments for the llm call.\n post_processor_kwargs (dict): Keyword arguments for the post_processor.\n **prompt_kwargs: Keyword arguments for populating the prompt.\n\n Returns:\n Document: The final output of the function as a Document object.\n \"\"\"\n prompt = self.prompt(**prompt_kwargs)\n llm_output = self.llm(prompt.text, **llm_kwargs)\n if self.post_processor is not None:\n final_output = self.post_processor(llm_output, **post_processor_kwargs)[0]\n else:\n final_output = llm_output\n\n return Document(final_output)\n
A pipeline that extends the SimpleLinearPipeline class and adds a condition attribute.
Attributes:
Name Type Description conditionCallable[[IO_Type], Any]
A callable function that represents the condition.
Usage Example Usage
from kotaemon.llms import LCAzureChatOpenAI, BasePromptComponent\nfrom kotaemon.parsers import RegexExtractor\n\ndef identity(x):\n return x\n\nllm = LCAzureChatOpenAI(\n openai_api_base=\"your openai api base\",\n openai_api_key=\"your openai api key\",\n openai_api_version=\"your openai api version\",\n deployment_name=\"dummy-q2-gpt35\",\n temperature=0,\n request_timeout=600,\n)\n\npipeline = GatedLinearPipeline(\n prompt=BasePromptComponent(template=\"what is {word} in Japanese ?\"),\n condition=RegexExtractor(pattern=\"some pattern\"),\n llm=llm,\n post_processor=identity,\n)\nprint(pipeline(condition_text=\"some pattern\", word=\"lone\"))\nprint(pipeline(condition_text=\"other pattern\", word=\"lone\"))\n
Source code in libs/kotaemon/kotaemon/llms/linear.py
class GatedLinearPipeline(SimpleLinearPipeline):\n \"\"\"\n A pipeline that extends the SimpleLinearPipeline class and adds a condition\n attribute.\n\n Attributes:\n condition (Callable[[IO_Type], Any]): A callable function that represents the\n condition.\n\n Usage:\n ```{.py3 title=\"Example Usage\"}\n from kotaemon.llms import LCAzureChatOpenAI, BasePromptComponent\n from kotaemon.parsers import RegexExtractor\n\n def identity(x):\n return x\n\n llm = LCAzureChatOpenAI(\n openai_api_base=\"your openai api base\",\n openai_api_key=\"your openai api key\",\n openai_api_version=\"your openai api version\",\n deployment_name=\"dummy-q2-gpt35\",\n temperature=0,\n request_timeout=600,\n )\n\n pipeline = GatedLinearPipeline(\n prompt=BasePromptComponent(template=\"what is {word} in Japanese ?\"),\n condition=RegexExtractor(pattern=\"some pattern\"),\n llm=llm,\n post_processor=identity,\n )\n print(pipeline(condition_text=\"some pattern\", word=\"lone\"))\n print(pipeline(condition_text=\"other pattern\", word=\"lone\"))\n ```\n \"\"\"\n\n condition: Callable[[IO_Type], Any]\n\n def run(\n self,\n *,\n condition_text: Optional[str] = None,\n llm_kwargs: Optional[dict] = {},\n post_processor_kwargs: Optional[dict] = {},\n **prompt_kwargs,\n ) -> Document:\n \"\"\"\n Run the pipeline with the given arguments and return the final output as a\n Document object.\n\n Args:\n condition_text (str): The condition text to evaluate. Default to None.\n llm_kwargs (dict): Additional keyword arguments for the language model call.\n post_processor_kwargs (dict): Additional keyword arguments for the\n post-processor.\n **prompt_kwargs: Keyword arguments for populating the prompt.\n\n Returns:\n Document: The final output of the pipeline as a Document object.\n\n Raises:\n ValueError: If condition_text is None\n \"\"\"\n if condition_text is None:\n raise ValueError(\"`condition_text` must be provided\")\n\n if self.condition(condition_text)[0]:\n return super().run(\n llm_kwargs=llm_kwargs,\n post_processor_kwargs=post_processor_kwargs,\n **prompt_kwargs,\n )\n\n return Document(None)\n
Run the pipeline with the given arguments and return the final output as a Document object.
Parameters:
Name Type Description Default condition_textstr
The condition text to evaluate. Default to None.
Nonellm_kwargsdict
Additional keyword arguments for the language model call.
{}post_processor_kwargsdict
Additional keyword arguments for the post-processor.
{}**prompt_kwargs
Keyword arguments for populating the prompt.
{}
Returns:
Name Type Description DocumentDocument
The final output of the pipeline as a Document object.
Raises:
Type Description ValueError
If condition_text is None
Source code in libs/kotaemon/kotaemon/llms/linear.py
def run(\n self,\n *,\n condition_text: Optional[str] = None,\n llm_kwargs: Optional[dict] = {},\n post_processor_kwargs: Optional[dict] = {},\n **prompt_kwargs,\n) -> Document:\n \"\"\"\n Run the pipeline with the given arguments and return the final output as a\n Document object.\n\n Args:\n condition_text (str): The condition text to evaluate. Default to None.\n llm_kwargs (dict): Additional keyword arguments for the language model call.\n post_processor_kwargs (dict): Additional keyword arguments for the\n post-processor.\n **prompt_kwargs: Keyword arguments for populating the prompt.\n\n Returns:\n Document: The final output of the pipeline as a Document object.\n\n Raises:\n ValueError: If condition_text is None\n \"\"\"\n if condition_text is None:\n raise ValueError(\"`condition_text` must be provided\")\n\n if self.condition(condition_text)[0]:\n return super().run(\n llm_kwargs=llm_kwargs,\n post_processor_kwargs=post_processor_kwargs,\n **prompt_kwargs,\n )\n\n return Document(None)\n
Generate response from messages Args: messages (str | BaseMessage | list[BaseMessage]): history of messages to generate response from **kwargs: additional arguments to pass to the OpenAI API Returns: LLMInterface: generated response
Source code in libs/kotaemon/kotaemon/llms/chats/endpoint_based.py
def run(\n self, messages: str | BaseMessage | list[BaseMessage], **kwargs\n) -> LLMInterface:\n \"\"\"\n Generate response from messages\n Args:\n messages (str | BaseMessage | list[BaseMessage]): history of messages to\n generate response from\n **kwargs: additional arguments to pass to the OpenAI API\n Returns:\n LLMInterface: generated response\n \"\"\"\n if isinstance(messages, str):\n input_ = [HumanMessage(content=messages)]\n elif isinstance(messages, BaseMessage):\n input_ = [messages]\n else:\n input_ = messages\n\n def decide_role(message: BaseMessage):\n if isinstance(message, SystemMessage):\n return \"system\"\n elif isinstance(message, AIMessage):\n return \"assistant\"\n else:\n return \"user\"\n\n request_json = {\n \"messages\": [{\"content\": m.text, \"role\": decide_role(m)} for m in input_]\n }\n\n response = requests.post(self.endpoint_url, json=request_json).json()\n\n content = \"\"\n candidates = []\n if response[\"choices\"]:\n candidates = [\n each[\"message\"][\"content\"]\n for each in response[\"choices\"]\n if each[\"message\"][\"content\"]\n ]\n content = candidates[0]\n\n return LLMInterface(\n content=content,\n candidates=candidates,\n completion_tokens=response[\"usage\"][\"completion_tokens\"],\n total_tokens=response[\"usage\"][\"total_tokens\"],\n prompt_tokens=response[\"usage\"][\"prompt_tokens\"],\n )\n
Source code in libs/kotaemon/kotaemon/llms/chats/llamacpp.py
class LlamaCppChat(ChatLLM):\n \"\"\"Wrapper around the llama-cpp-python's Llama model\"\"\"\n\n model_path: Optional[str] = Param(\n help=\"Path to the model file. This is required to load the model.\",\n )\n repo_id: Optional[str] = Param(\n help=\"Id of a repo on the HuggingFace Hub in the form of `user_name/repo_name`.\"\n )\n filename: Optional[str] = Param(\n help=\"A filename or glob pattern to match the model file in the repo.\"\n )\n chat_format: str = Param(\n help=(\n \"Chat format to use. Please refer to llama_cpp.llama_chat_format for a \"\n \"list of supported formats. If blank, the chat format will be auto-\"\n \"inferred.\"\n ),\n required=True,\n )\n lora_base: Optional[str] = Param(None, help=\"Path to the base Lora model\")\n n_ctx: Optional[int] = Param(512, help=\"Text context, 0 = from model\")\n n_gpu_layers: Optional[int] = Param(\n 0,\n help=\"Number of layers to offload to GPU. If -1, all layers are offloaded\",\n )\n use_mmap: Optional[bool] = Param(\n True,\n help=(),\n )\n vocab_only: Optional[bool] = Param(\n False,\n help=\"If True, only the vocabulary is loaded. This is useful for debugging.\",\n )\n\n _role_mapper: dict[str, str] = {\n \"human\": \"user\",\n \"system\": \"system\",\n \"ai\": \"assistant\",\n }\n\n @Param.auto()\n def client_object(self) -> \"Llama\":\n \"\"\"Get the llama-cpp-python client object\"\"\"\n try:\n from llama_cpp import Llama\n except ImportError:\n raise ImportError(\n \"llama-cpp-python is not installed. \"\n \"Please install it using `pip install llama-cpp-python`\"\n )\n\n errors = []\n if not self.model_path and (not self.repo_id or not self.filename):\n errors.append(\n \"- `model_path` or `repo_id` and `filename` are required to load the\"\n \" model\"\n )\n\n if not self.chat_format:\n errors.append(\n \"- `chat_format` is required to know how to format the chat messages. \"\n \"Please refer to llama_cpp.llama_chat_format for a list of supported \"\n \"formats.\"\n )\n if errors:\n raise ValueError(\"\\n\".join(errors))\n\n if self.model_path:\n return Llama(\n model_path=cast(str, self.model_path),\n chat_format=self.chat_format,\n lora_base=self.lora_base,\n n_ctx=self.n_ctx,\n n_gpu_layers=self.n_gpu_layers,\n use_mmap=self.use_mmap,\n vocab_only=self.vocab_only,\n )\n else:\n return Llama.from_pretrained(\n repo_id=self.repo_id,\n filename=self.filename,\n chat_format=self.chat_format,\n lora_base=self.lora_base,\n n_ctx=self.n_ctx,\n n_gpu_layers=self.n_gpu_layers,\n use_mmap=self.use_mmap,\n vocab_only=self.vocab_only,\n )\n\n def prepare_message(\n self, messages: str | BaseMessage | list[BaseMessage]\n ) -> list[dict]:\n input_: list[BaseMessage] = []\n\n if isinstance(messages, str):\n input_ = [HumanMessage(content=messages)]\n elif isinstance(messages, BaseMessage):\n input_ = [messages]\n else:\n input_ = messages\n\n output_ = [\n {\"role\": self._role_mapper[each.type], \"content\": each.content}\n for each in input_\n ]\n\n return output_\n\n def invoke(\n self, messages: str | BaseMessage | list[BaseMessage], **kwargs\n ) -> LLMInterface:\n\n pred: \"CCCR\" = self.client_object.create_chat_completion(\n messages=self.prepare_message(messages),\n stream=False,\n )\n\n return LLMInterface(\n content=pred[\"choices\"][0][\"message\"][\"content\"] if pred[\"choices\"] else \"\",\n candidates=[\n c[\"message\"][\"content\"]\n for c in pred[\"choices\"]\n if c[\"message\"][\"content\"]\n ],\n completion_tokens=pred[\"usage\"][\"completion_tokens\"],\n total_tokens=pred[\"usage\"][\"total_tokens\"],\n prompt_tokens=pred[\"usage\"][\"prompt_tokens\"],\n )\n\n def stream(\n self, messages: str | BaseMessage | list[BaseMessage], **kwargs\n ) -> Iterator[LLMInterface]:\n pred = self.client_object.create_chat_completion(\n messages=self.prepare_message(messages),\n stream=True,\n )\n for chunk in pred:\n if not chunk[\"choices\"]:\n continue\n\n if \"content\" not in chunk[\"choices\"][0][\"delta\"]:\n continue\n\n yield LLMInterface(content=chunk[\"choices\"][0][\"delta\"][\"content\"])\n
Source code in libs/kotaemon/kotaemon/llms/chats/llamacpp.py
@Param.auto()\ndef client_object(self) -> \"Llama\":\n \"\"\"Get the llama-cpp-python client object\"\"\"\n try:\n from llama_cpp import Llama\n except ImportError:\n raise ImportError(\n \"llama-cpp-python is not installed. \"\n \"Please install it using `pip install llama-cpp-python`\"\n )\n\n errors = []\n if not self.model_path and (not self.repo_id or not self.filename):\n errors.append(\n \"- `model_path` or `repo_id` and `filename` are required to load the\"\n \" model\"\n )\n\n if not self.chat_format:\n errors.append(\n \"- `chat_format` is required to know how to format the chat messages. \"\n \"Please refer to llama_cpp.llama_chat_format for a list of supported \"\n \"formats.\"\n )\n if errors:\n raise ValueError(\"\\n\".join(errors))\n\n if self.model_path:\n return Llama(\n model_path=cast(str, self.model_path),\n chat_format=self.chat_format,\n lora_base=self.lora_base,\n n_ctx=self.n_ctx,\n n_gpu_layers=self.n_gpu_layers,\n use_mmap=self.use_mmap,\n vocab_only=self.vocab_only,\n )\n else:\n return Llama.from_pretrained(\n repo_id=self.repo_id,\n filename=self.filename,\n chat_format=self.chat_format,\n lora_base=self.lora_base,\n n_ctx=self.n_ctx,\n n_gpu_layers=self.n_gpu_layers,\n use_mmap=self.use_mmap,\n vocab_only=self.vocab_only,\n )\n
Generate response from messages Args: messages (str | BaseMessage | list[BaseMessage]): history of messages to generate response from **kwargs: additional arguments to pass to the OpenAI API Returns: LLMInterface: generated response
Source code in libs/kotaemon/kotaemon/llms/chats/endpoint_based.py
def run(\n self, messages: str | BaseMessage | list[BaseMessage], **kwargs\n) -> LLMInterface:\n \"\"\"\n Generate response from messages\n Args:\n messages (str | BaseMessage | list[BaseMessage]): history of messages to\n generate response from\n **kwargs: additional arguments to pass to the OpenAI API\n Returns:\n LLMInterface: generated response\n \"\"\"\n if isinstance(messages, str):\n input_ = [HumanMessage(content=messages)]\n elif isinstance(messages, BaseMessage):\n input_ = [messages]\n else:\n input_ = messages\n\n def decide_role(message: BaseMessage):\n if isinstance(message, SystemMessage):\n return \"system\"\n elif isinstance(message, AIMessage):\n return \"assistant\"\n else:\n return \"user\"\n\n request_json = {\n \"messages\": [{\"content\": m.text, \"role\": decide_role(m)} for m in input_]\n }\n\n response = requests.post(self.endpoint_url, json=request_json).json()\n\n content = \"\"\n candidates = []\n if response[\"choices\"]:\n candidates = [\n each[\"message\"][\"content\"]\n for each in response[\"choices\"]\n if each[\"message\"][\"content\"]\n ]\n content = candidates[0]\n\n return LLMInterface(\n content=content,\n candidates=candidates,\n completion_tokens=response[\"usage\"][\"completion_tokens\"],\n total_tokens=response[\"usage\"][\"total_tokens\"],\n prompt_tokens=response[\"usage\"][\"prompt_tokens\"],\n )\n
Source code in libs/kotaemon/kotaemon/llms/chats/llamacpp.py
class LlamaCppChat(ChatLLM):\n \"\"\"Wrapper around the llama-cpp-python's Llama model\"\"\"\n\n model_path: Optional[str] = Param(\n help=\"Path to the model file. This is required to load the model.\",\n )\n repo_id: Optional[str] = Param(\n help=\"Id of a repo on the HuggingFace Hub in the form of `user_name/repo_name`.\"\n )\n filename: Optional[str] = Param(\n help=\"A filename or glob pattern to match the model file in the repo.\"\n )\n chat_format: str = Param(\n help=(\n \"Chat format to use. Please refer to llama_cpp.llama_chat_format for a \"\n \"list of supported formats. If blank, the chat format will be auto-\"\n \"inferred.\"\n ),\n required=True,\n )\n lora_base: Optional[str] = Param(None, help=\"Path to the base Lora model\")\n n_ctx: Optional[int] = Param(512, help=\"Text context, 0 = from model\")\n n_gpu_layers: Optional[int] = Param(\n 0,\n help=\"Number of layers to offload to GPU. If -1, all layers are offloaded\",\n )\n use_mmap: Optional[bool] = Param(\n True,\n help=(),\n )\n vocab_only: Optional[bool] = Param(\n False,\n help=\"If True, only the vocabulary is loaded. This is useful for debugging.\",\n )\n\n _role_mapper: dict[str, str] = {\n \"human\": \"user\",\n \"system\": \"system\",\n \"ai\": \"assistant\",\n }\n\n @Param.auto()\n def client_object(self) -> \"Llama\":\n \"\"\"Get the llama-cpp-python client object\"\"\"\n try:\n from llama_cpp import Llama\n except ImportError:\n raise ImportError(\n \"llama-cpp-python is not installed. \"\n \"Please install it using `pip install llama-cpp-python`\"\n )\n\n errors = []\n if not self.model_path and (not self.repo_id or not self.filename):\n errors.append(\n \"- `model_path` or `repo_id` and `filename` are required to load the\"\n \" model\"\n )\n\n if not self.chat_format:\n errors.append(\n \"- `chat_format` is required to know how to format the chat messages. \"\n \"Please refer to llama_cpp.llama_chat_format for a list of supported \"\n \"formats.\"\n )\n if errors:\n raise ValueError(\"\\n\".join(errors))\n\n if self.model_path:\n return Llama(\n model_path=cast(str, self.model_path),\n chat_format=self.chat_format,\n lora_base=self.lora_base,\n n_ctx=self.n_ctx,\n n_gpu_layers=self.n_gpu_layers,\n use_mmap=self.use_mmap,\n vocab_only=self.vocab_only,\n )\n else:\n return Llama.from_pretrained(\n repo_id=self.repo_id,\n filename=self.filename,\n chat_format=self.chat_format,\n lora_base=self.lora_base,\n n_ctx=self.n_ctx,\n n_gpu_layers=self.n_gpu_layers,\n use_mmap=self.use_mmap,\n vocab_only=self.vocab_only,\n )\n\n def prepare_message(\n self, messages: str | BaseMessage | list[BaseMessage]\n ) -> list[dict]:\n input_: list[BaseMessage] = []\n\n if isinstance(messages, str):\n input_ = [HumanMessage(content=messages)]\n elif isinstance(messages, BaseMessage):\n input_ = [messages]\n else:\n input_ = messages\n\n output_ = [\n {\"role\": self._role_mapper[each.type], \"content\": each.content}\n for each in input_\n ]\n\n return output_\n\n def invoke(\n self, messages: str | BaseMessage | list[BaseMessage], **kwargs\n ) -> LLMInterface:\n\n pred: \"CCCR\" = self.client_object.create_chat_completion(\n messages=self.prepare_message(messages),\n stream=False,\n )\n\n return LLMInterface(\n content=pred[\"choices\"][0][\"message\"][\"content\"] if pred[\"choices\"] else \"\",\n candidates=[\n c[\"message\"][\"content\"]\n for c in pred[\"choices\"]\n if c[\"message\"][\"content\"]\n ],\n completion_tokens=pred[\"usage\"][\"completion_tokens\"],\n total_tokens=pred[\"usage\"][\"total_tokens\"],\n prompt_tokens=pred[\"usage\"][\"prompt_tokens\"],\n )\n\n def stream(\n self, messages: str | BaseMessage | list[BaseMessage], **kwargs\n ) -> Iterator[LLMInterface]:\n pred = self.client_object.create_chat_completion(\n messages=self.prepare_message(messages),\n stream=True,\n )\n for chunk in pred:\n if not chunk[\"choices\"]:\n continue\n\n if \"content\" not in chunk[\"choices\"][0][\"delta\"]:\n continue\n\n yield LLMInterface(content=chunk[\"choices\"][0][\"delta\"][\"content\"])\n
Source code in libs/kotaemon/kotaemon/llms/chats/llamacpp.py
@Param.auto()\ndef client_object(self) -> \"Llama\":\n \"\"\"Get the llama-cpp-python client object\"\"\"\n try:\n from llama_cpp import Llama\n except ImportError:\n raise ImportError(\n \"llama-cpp-python is not installed. \"\n \"Please install it using `pip install llama-cpp-python`\"\n )\n\n errors = []\n if not self.model_path and (not self.repo_id or not self.filename):\n errors.append(\n \"- `model_path` or `repo_id` and `filename` are required to load the\"\n \" model\"\n )\n\n if not self.chat_format:\n errors.append(\n \"- `chat_format` is required to know how to format the chat messages. \"\n \"Please refer to llama_cpp.llama_chat_format for a list of supported \"\n \"formats.\"\n )\n if errors:\n raise ValueError(\"\\n\".join(errors))\n\n if self.model_path:\n return Llama(\n model_path=cast(str, self.model_path),\n chat_format=self.chat_format,\n lora_base=self.lora_base,\n n_ctx=self.n_ctx,\n n_gpu_layers=self.n_gpu_layers,\n use_mmap=self.use_mmap,\n vocab_only=self.vocab_only,\n )\n else:\n return Llama.from_pretrained(\n repo_id=self.repo_id,\n filename=self.filename,\n chat_format=self.chat_format,\n lora_base=self.lora_base,\n n_ctx=self.n_ctx,\n n_gpu_layers=self.n_gpu_layers,\n use_mmap=self.use_mmap,\n vocab_only=self.vocab_only,\n )\n
Base interface for OpenAI chat model, using the openai library
This class exposes the parameters in resources.Chat. To subclass this class:
- Implement the `prepare_client` method to return the OpenAI client\n- Implement the `openai_response` method to return the OpenAI response\n- Implement the params relate to the OpenAI client\n
Source code in libs/kotaemon/kotaemon/llms/chats/openai.py
class BaseChatOpenAI(ChatLLM):\n \"\"\"Base interface for OpenAI chat model, using the openai library\n\n This class exposes the parameters in resources.Chat. To subclass this class:\n\n - Implement the `prepare_client` method to return the OpenAI client\n - Implement the `openai_response` method to return the OpenAI response\n - Implement the params relate to the OpenAI client\n \"\"\"\n\n _dependencies = [\"openai\"]\n _capabilities = [\"chat\", \"text\"] # consider as mixin\n\n api_key: str = Param(help=\"API key\", required=True)\n timeout: Optional[float] = Param(None, help=\"Timeout for the API request\")\n max_retries: Optional[int] = Param(\n None, help=\"Maximum number of retries for the API request\"\n )\n\n temperature: Optional[float] = Param(\n None,\n help=(\n \"Number between 0 and 2 that controls the randomness of the generated \"\n \"tokens. Lower values make the model more deterministic, while higher \"\n \"values make the model more random.\"\n ),\n )\n max_tokens: Optional[int] = Param(\n None,\n help=(\n \"Maximum number of tokens to generate. The total length of input tokens \"\n \"and generated tokens is limited by the model's context length.\"\n ),\n )\n n: int = Param(\n 1,\n help=(\n \"Number of completions to generate. The API will generate n completion \"\n \"for each prompt.\"\n ),\n )\n stop: Optional[str | list[str]] = Param(\n None,\n help=(\n \"Stop sequence. If a stop sequence is detected, generation will stop \"\n \"at that point. If not specified, generation will continue until the \"\n \"maximum token length is reached.\"\n ),\n )\n frequency_penalty: Optional[float] = Param(\n None,\n help=(\n \"Number between -2.0 and 2.0. Positive values penalize new tokens \"\n \"based on their existing frequency in the text so far, decrearsing the \"\n \"model's likelihood of repeating the same text.\"\n ),\n )\n presence_penalty: Optional[float] = Param(\n None,\n help=(\n \"Number between -2.0 and 2.0. Positive values penalize new tokens \"\n \"based on their existing presence in the text so far, decrearsing the \"\n \"model's likelihood of repeating the same text.\"\n ),\n )\n tool_choice: Optional[str] = Param(\n None,\n help=(\n \"Choice of tool to use for the completion. Available choices are: \"\n \"auto, default.\"\n ),\n )\n tools: Optional[list[str]] = Param(\n None,\n help=\"List of tools to use for the completion.\",\n )\n logprobs: Optional[bool] = Param(\n None,\n help=(\n \"Include log probabilities on the logprobs most likely tokens, \"\n \"as well as the chosen token.\"\n ),\n )\n logit_bias: Optional[dict] = Param(\n None,\n help=(\n \"Dictionary of logit bias values to add to the logits of the tokens \"\n \"in the vocabulary.\"\n ),\n )\n top_logprobs: Optional[int] = Param(\n None,\n help=(\n \"An integer between 0 and 5 specifying the number of most likely tokens \"\n \"to return at each token position, each with an associated log \"\n \"probability. `logprobs` must also be set to `true` if this parameter \"\n \"is used.\"\n ),\n )\n top_p: Optional[float] = Param(\n None,\n help=(\n \"An alternative to sampling with temperature, called nucleus sampling, \"\n \"where the model considers the results of the token with top_p \"\n \"probability mass. So 0.1 means that only the tokens comprising the \"\n \"top 10% probability mass are considered.\"\n ),\n )\n\n @Param.auto(depends_on=[\"max_retries\"])\n def max_retries_(self):\n if self.max_retries is None:\n from openai._constants import DEFAULT_MAX_RETRIES\n\n return DEFAULT_MAX_RETRIES\n return self.max_retries\n\n def prepare_message(\n self, messages: str | BaseMessage | list[BaseMessage]\n ) -> list[\"ChatCompletionMessageParam\"]:\n \"\"\"Prepare the message into OpenAI format\n\n Returns:\n list[dict]: List of messages in OpenAI format\n \"\"\"\n input_: list[BaseMessage] = []\n output_: list[\"ChatCompletionMessageParam\"] = []\n\n if isinstance(messages, str):\n input_ = [HumanMessage(content=messages)]\n elif isinstance(messages, BaseMessage):\n input_ = [messages]\n else:\n input_ = messages\n\n for message in input_:\n output_.append(message.to_openai_format())\n\n return output_\n\n def prepare_output(self, resp: dict) -> LLMInterface:\n \"\"\"Convert the OpenAI response into LLMInterface\"\"\"\n additional_kwargs = {}\n if \"tool_calls\" in resp[\"choices\"][0][\"message\"]:\n additional_kwargs[\"tool_calls\"] = resp[\"choices\"][0][\"message\"][\n \"tool_calls\"\n ]\n\n if resp[\"choices\"][0].get(\"logprobs\") is None:\n logprobs = []\n else:\n all_logprobs = resp[\"choices\"][0][\"logprobs\"].get(\"content\")\n logprobs = (\n [logprob[\"logprob\"] for logprob in all_logprobs] if all_logprobs else []\n )\n\n output = LLMInterface(\n candidates=[(_[\"message\"][\"content\"] or \"\") for _ in resp[\"choices\"]],\n content=resp[\"choices\"][0][\"message\"][\"content\"] or \"\",\n total_tokens=resp[\"usage\"][\"total_tokens\"],\n prompt_tokens=resp[\"usage\"][\"prompt_tokens\"],\n completion_tokens=resp[\"usage\"][\"completion_tokens\"],\n additional_kwargs=additional_kwargs,\n messages=[\n AIMessage(content=(_[\"message\"][\"content\"]) or \"\")\n for _ in resp[\"choices\"]\n ],\n logprobs=logprobs,\n )\n\n return output\n\n def prepare_client(self, async_version: bool = False):\n \"\"\"Get the OpenAI client\n\n Args:\n async_version (bool): Whether to get the async version of the client\n \"\"\"\n raise NotImplementedError\n\n def openai_response(self, client, **kwargs):\n \"\"\"Get the openai response\"\"\"\n raise NotImplementedError\n\n def invoke(\n self, messages: str | BaseMessage | list[BaseMessage], *args, **kwargs\n ) -> LLMInterface:\n client = self.prepare_client(async_version=False)\n input_messages = self.prepare_message(messages)\n resp = self.openai_response(\n client, messages=input_messages, stream=False, **kwargs\n ).dict()\n return self.prepare_output(resp)\n\n async def ainvoke(\n self, messages: str | BaseMessage | list[BaseMessage], *args, **kwargs\n ) -> LLMInterface:\n client = self.prepare_client(async_version=True)\n input_messages = self.prepare_message(messages)\n resp = await self.openai_response(\n client, messages=input_messages, stream=False, **kwargs\n ).dict()\n\n return self.prepare_output(resp)\n\n def stream(\n self, messages: str | BaseMessage | list[BaseMessage], *args, **kwargs\n ) -> Iterator[LLMInterface]:\n client = self.prepare_client(async_version=False)\n input_messages = self.prepare_message(messages)\n resp = self.openai_response(\n client, messages=input_messages, stream=True, **kwargs\n )\n\n for c in resp:\n chunk = c.dict()\n if not chunk[\"choices\"]:\n continue\n if chunk[\"choices\"][0][\"delta\"][\"content\"] is not None:\n if chunk[\"choices\"][0].get(\"logprobs\") is None:\n logprobs = []\n else:\n logprobs = [\n logprob[\"logprob\"]\n for logprob in chunk[\"choices\"][0][\"logprobs\"].get(\n \"content\", []\n )\n ]\n\n yield LLMInterface(\n content=chunk[\"choices\"][0][\"delta\"][\"content\"], logprobs=logprobs\n )\n\n async def astream(\n self, messages: str | BaseMessage | list[BaseMessage], *args, **kwargs\n ) -> AsyncGenerator[LLMInterface, None]:\n client = self.prepare_client(async_version=True)\n input_messages = self.prepare_message(messages)\n resp = self.openai_response(\n client, messages=input_messages, stream=True, **kwargs\n )\n\n async for chunk in resp:\n if not chunk.choices:\n continue\n if chunk.choices[0].delta.content is not None:\n yield LLMInterface(content=chunk.choices[0].delta.content)\n
Source code in libs/kotaemon/kotaemon/llms/chats/openai.py
def prepare_output(self, resp: dict) -> LLMInterface:\n \"\"\"Convert the OpenAI response into LLMInterface\"\"\"\n additional_kwargs = {}\n if \"tool_calls\" in resp[\"choices\"][0][\"message\"]:\n additional_kwargs[\"tool_calls\"] = resp[\"choices\"][0][\"message\"][\n \"tool_calls\"\n ]\n\n if resp[\"choices\"][0].get(\"logprobs\") is None:\n logprobs = []\n else:\n all_logprobs = resp[\"choices\"][0][\"logprobs\"].get(\"content\")\n logprobs = (\n [logprob[\"logprob\"] for logprob in all_logprobs] if all_logprobs else []\n )\n\n output = LLMInterface(\n candidates=[(_[\"message\"][\"content\"] or \"\") for _ in resp[\"choices\"]],\n content=resp[\"choices\"][0][\"message\"][\"content\"] or \"\",\n total_tokens=resp[\"usage\"][\"total_tokens\"],\n prompt_tokens=resp[\"usage\"][\"prompt_tokens\"],\n completion_tokens=resp[\"usage\"][\"completion_tokens\"],\n additional_kwargs=additional_kwargs,\n messages=[\n AIMessage(content=(_[\"message\"][\"content\"]) or \"\")\n for _ in resp[\"choices\"]\n ],\n logprobs=logprobs,\n )\n\n return output\n
False Source code in libs/kotaemon/kotaemon/llms/chats/openai.py
def prepare_client(self, async_version: bool = False):\n \"\"\"Get the OpenAI client\n\n Args:\n async_version (bool): Whether to get the async version of the client\n \"\"\"\n raise NotImplementedError\n
Name Type Description Default templatePromptTemplate
The prompt template.
required **kwargs
Any additional keyword arguments that will be used to populate the given template.
{} Source code in libs/kotaemon/kotaemon/llms/prompts/base.py
class BasePromptComponent(BaseComponent):\n \"\"\"\n Base class for prompt components.\n\n Args:\n template (PromptTemplate): The prompt template.\n **kwargs: Any additional keyword arguments that will be used to populate the\n given template.\n \"\"\"\n\n class Config:\n middleware_switches = {\"theflow.middleware.CachingMiddleware\": False}\n allow_extra = True\n\n template: str | PromptTemplate\n\n @Param.auto(depends_on=\"template\")\n def template__(self):\n return (\n self.template\n if isinstance(self.template, PromptTemplate)\n else PromptTemplate(self.template)\n )\n\n def __init__(self, **kwargs):\n super().__init__(**kwargs)\n self.__set(**kwargs)\n\n def __check_redundant_kwargs(self, **kwargs):\n \"\"\"\n Check for redundant keyword arguments.\n\n Parameters:\n **kwargs (dict): A dictionary of keyword arguments.\n\n Raises:\n ValueError: If any keys provided are not in the template.\n\n Returns:\n None\n \"\"\"\n self.template__.check_redundant_kwargs(**kwargs)\n\n def __check_unset_placeholders(self):\n \"\"\"\n Check if all the placeholders in the template are set.\n\n This function checks if all the expected placeholders in the template are set as\n attributes of the object. If any placeholders are missing, a `ValueError`\n is raised with the names of the missing keys.\n\n Parameters:\n None\n\n Returns:\n None\n \"\"\"\n self.template__.check_missing_kwargs(**self.__dict__)\n\n def __validate_value_type(self, **kwargs):\n \"\"\"\n Validates the value types of the given keyword arguments.\n\n Parameters:\n **kwargs (dict): A dictionary of keyword arguments to be validated.\n\n Raises:\n ValueError: If any of the values in the kwargs dictionary have an\n unsupported type.\n\n Returns:\n None\n \"\"\"\n type_error = []\n for k, v in kwargs.items():\n if k.startswith(\"template\"):\n continue\n if not isinstance(v, (str, int, Document, Callable)): # type: ignore\n type_error.append((k, type(v)))\n\n if type_error:\n raise ValueError(\n \"Type of values must be either int, str, Document, Callable, \"\n f\"found unsupported type for (key, type): {type_error}\"\n )\n\n def __set(self, **kwargs):\n \"\"\"\n Set the values of the attributes in the object based on the provided keyword\n arguments.\n\n Args:\n kwargs (dict): A dictionary with the attribute names as keys and the new\n values as values.\n\n Returns:\n None\n \"\"\"\n self.__check_redundant_kwargs(**kwargs)\n self.__validate_value_type(**kwargs)\n\n self.__dict__.update(kwargs)\n\n def __prepare_value(self):\n \"\"\"\n Generate a dictionary of keyword arguments based on the template's placeholders\n and the current instance's attributes.\n\n Returns:\n dict: A dictionary of keyword arguments.\n \"\"\"\n\n def __prepare(key, value):\n if isinstance(value, str):\n return value\n if isinstance(value, (int, Document)):\n return str(value)\n\n raise ValueError(\n f\"Unsupported type {type(value)} for template value of key {key}\"\n )\n\n kwargs = {}\n for k in self.template__.placeholders:\n v = getattr(self, k)\n\n # if get a callable, execute to get its output\n if isinstance(v, Callable): # type: ignore[arg-type]\n v = v()\n\n if isinstance(v, list):\n v = str([__prepare(k, each) for each in v])\n elif isinstance(v, (str, int, Document)):\n v = __prepare(k, v)\n else:\n raise ValueError(\n f\"Unsupported type {type(v)} for template value of key `{k}`\"\n )\n kwargs[k] = v\n\n return kwargs\n\n def set_value(self, **kwargs):\n \"\"\"\n Similar to `__set` but for external use.\n\n Set the values of the attributes in the object based on the provided keyword\n arguments.\n\n Args:\n kwargs (dict): A dictionary with the attribute names as keys and the new\n values as values.\n\n Returns:\n None\n \"\"\"\n self.__set(**kwargs)\n\n def run(self, **kwargs):\n \"\"\"\n Run the function with the given keyword arguments.\n\n Args:\n **kwargs: The keyword arguments to pass to the function.\n\n Returns:\n The result of calling the `populate` method of the `template` object\n with the given keyword arguments.\n \"\"\"\n self.__set(**kwargs)\n self.__check_unset_placeholders()\n prepared_kwargs = self.__prepare_value()\n\n text = self.template__.populate(**prepared_kwargs)\n return Document(text=text, metadata={\"origin\": \"PromptComponent\"})\n\n def flow(self):\n return self.__call__()\n
Set the values of the attributes in the object based on the provided keyword arguments.
Parameters:
Name Type Description Default kwargsdict
A dictionary with the attribute names as keys and the new values as values.
{}
Returns:
Type Description
None
Source code in libs/kotaemon/kotaemon/llms/prompts/base.py
def set_value(self, **kwargs):\n \"\"\"\n Similar to `__set` but for external use.\n\n Set the values of the attributes in the object based on the provided keyword\n arguments.\n\n Args:\n kwargs (dict): A dictionary with the attribute names as keys and the new\n values as values.\n\n Returns:\n None\n \"\"\"\n self.__set(**kwargs)\n
Run the function with the given keyword arguments.
Parameters:
Name Type Description Default **kwargs
The keyword arguments to pass to the function.
{}
Returns:
Type Description
The result of calling the populate method of the template object
with the given keyword arguments.
Source code in libs/kotaemon/kotaemon/llms/prompts/base.py
def run(self, **kwargs):\n \"\"\"\n Run the function with the given keyword arguments.\n\n Args:\n **kwargs: The keyword arguments to pass to the function.\n\n Returns:\n The result of calling the `populate` method of the `template` object\n with the given keyword arguments.\n \"\"\"\n self.__set(**kwargs)\n self.__check_unset_placeholders()\n prepared_kwargs = self.__prepare_value()\n\n text = self.template__.populate(**prepared_kwargs)\n return Document(text=text, metadata={\"origin\": \"PromptComponent\"})\n
Source code in libs/kotaemon/kotaemon/llms/prompts/template.py
class PromptTemplate:\n \"\"\"\n Base class for prompt templates.\n \"\"\"\n\n def __init__(self, template: str, ignore_invalid=True):\n template = template\n formatter = Formatter()\n parsed_template = list(formatter.parse(template))\n\n placeholders = set()\n for _, key, _, _ in parsed_template:\n if key is None:\n continue\n if not key.isidentifier():\n if ignore_invalid:\n warnings.warn(f\"Ignore invalid placeholder: {key}.\", UserWarning)\n else:\n raise ValueError(\n \"Placeholder name must be a valid Python identifier, found:\"\n f\" {key}.\"\n )\n placeholders.add(key)\n\n self.template = template\n self.placeholders = placeholders\n self.__formatter = formatter\n self.__parsed_template = parsed_template\n\n def check_missing_kwargs(self, **kwargs):\n \"\"\"\n Check if all the placeholders in the template are set.\n\n This function checks if all the expected placeholders in the template are set as\n attributes of the object. If any placeholders are missing, a `ValueError`\n is raised with the names of the missing keys.\n\n Parameters:\n None\n\n Returns:\n None\n \"\"\"\n missing_keys = self.placeholders.difference(kwargs.keys())\n if missing_keys:\n raise ValueError(f\"Missing keys in template: {','.join(missing_keys)}\")\n\n def check_redundant_kwargs(self, **kwargs):\n \"\"\"\n Check if all the placeholders in the template are set.\n\n This function checks if all the expected placeholders in the template are set as\n attributes of the object. If any placeholders are missing, a `ValueError`\n is raised with the names of the missing keys.\n\n Parameters:\n None\n\n Returns:\n None\n \"\"\"\n provided_keys = set(kwargs.keys())\n redundant_keys = provided_keys - self.placeholders\n\n if redundant_keys:\n warnings.warn(\n f\"Keys provided but not in template: {','.join(redundant_keys)}\",\n UserWarning,\n )\n\n def populate(self, **kwargs) -> str:\n \"\"\"\n Strictly populate the template with the given keyword arguments.\n\n Args:\n **kwargs: The keyword arguments to populate the template.\n Each keyword corresponds to a placeholder in the template.\n\n Returns:\n The populated template.\n\n Raises:\n ValueError: If an unknown placeholder is provided.\n \"\"\"\n self.check_missing_kwargs(**kwargs)\n\n return self.partial_populate(**kwargs)\n\n def partial_populate(self, **kwargs):\n \"\"\"\n Partially populate the template with the given keyword arguments.\n\n Args:\n **kwargs: The keyword arguments to populate the template.\n Each keyword corresponds to a placeholder in the template.\n\n Returns:\n str: The populated template.\n \"\"\"\n self.check_redundant_kwargs(**kwargs)\n\n prompt = []\n for literal_text, field_name, format_spec, conversion in self.__parsed_template:\n prompt.append(literal_text)\n\n if field_name is None:\n continue\n\n if field_name not in kwargs:\n if conversion:\n value = f\"{{{field_name}}}!{conversion}:{format_spec}\"\n else:\n value = f\"{{{field_name}:{format_spec}}}\"\n else:\n value = kwargs[field_name]\n if conversion is not None:\n value = self.__formatter.convert_field(value, conversion)\n if format_spec is not None:\n value = self.__formatter.format_field(value, format_spec)\n\n prompt.append(value)\n\n return \"\".join(prompt)\n\n def __add__(self, other):\n \"\"\"\n Create a new PromptTemplate object by concatenating the template of the current\n object with the template of another PromptTemplate object.\n\n Parameters:\n other (PromptTemplate): Another PromptTemplate object.\n\n Returns:\n PromptTemplate: A new PromptTemplate object with the concatenated templates.\n \"\"\"\n return PromptTemplate(self.template + \"\\n\" + other.template)\n
Check if all the placeholders in the template are set.
This function checks if all the expected placeholders in the template are set as attributes of the object. If any placeholders are missing, a ValueError is raised with the names of the missing keys.
Returns:
Type Description
None
Source code in libs/kotaemon/kotaemon/llms/prompts/template.py
def check_missing_kwargs(self, **kwargs):\n \"\"\"\n Check if all the placeholders in the template are set.\n\n This function checks if all the expected placeholders in the template are set as\n attributes of the object. If any placeholders are missing, a `ValueError`\n is raised with the names of the missing keys.\n\n Parameters:\n None\n\n Returns:\n None\n \"\"\"\n missing_keys = self.placeholders.difference(kwargs.keys())\n if missing_keys:\n raise ValueError(f\"Missing keys in template: {','.join(missing_keys)}\")\n
Check if all the placeholders in the template are set.
This function checks if all the expected placeholders in the template are set as attributes of the object. If any placeholders are missing, a ValueError is raised with the names of the missing keys.
Returns:
Type Description
None
Source code in libs/kotaemon/kotaemon/llms/prompts/template.py
def check_redundant_kwargs(self, **kwargs):\n \"\"\"\n Check if all the placeholders in the template are set.\n\n This function checks if all the expected placeholders in the template are set as\n attributes of the object. If any placeholders are missing, a `ValueError`\n is raised with the names of the missing keys.\n\n Parameters:\n None\n\n Returns:\n None\n \"\"\"\n provided_keys = set(kwargs.keys())\n redundant_keys = provided_keys - self.placeholders\n\n if redundant_keys:\n warnings.warn(\n f\"Keys provided but not in template: {','.join(redundant_keys)}\",\n UserWarning,\n )\n
Strictly populate the template with the given keyword arguments.
Parameters:
Name Type Description Default **kwargs
The keyword arguments to populate the template. Each keyword corresponds to a placeholder in the template.
{}
Returns:
Type Description str
The populated template.
Raises:
Type Description ValueError
If an unknown placeholder is provided.
Source code in libs/kotaemon/kotaemon/llms/prompts/template.py
def populate(self, **kwargs) -> str:\n \"\"\"\n Strictly populate the template with the given keyword arguments.\n\n Args:\n **kwargs: The keyword arguments to populate the template.\n Each keyword corresponds to a placeholder in the template.\n\n Returns:\n The populated template.\n\n Raises:\n ValueError: If an unknown placeholder is provided.\n \"\"\"\n self.check_missing_kwargs(**kwargs)\n\n return self.partial_populate(**kwargs)\n
Partially populate the template with the given keyword arguments.
Parameters:
Name Type Description Default **kwargs
The keyword arguments to populate the template. Each keyword corresponds to a placeholder in the template.
{}
Returns:
Name Type Description str
The populated template.
Source code in libs/kotaemon/kotaemon/llms/prompts/template.py
def partial_populate(self, **kwargs):\n \"\"\"\n Partially populate the template with the given keyword arguments.\n\n Args:\n **kwargs: The keyword arguments to populate the template.\n Each keyword corresponds to a placeholder in the template.\n\n Returns:\n str: The populated template.\n \"\"\"\n self.check_redundant_kwargs(**kwargs)\n\n prompt = []\n for literal_text, field_name, format_spec, conversion in self.__parsed_template:\n prompt.append(literal_text)\n\n if field_name is None:\n continue\n\n if field_name not in kwargs:\n if conversion:\n value = f\"{{{field_name}}}!{conversion}:{format_spec}\"\n else:\n value = f\"{{{field_name}:{format_spec}}}\"\n else:\n value = kwargs[field_name]\n if conversion is not None:\n value = self.__formatter.convert_field(value, conversion)\n if format_spec is not None:\n value = self.__formatter.format_field(value, format_spec)\n\n prompt.append(value)\n\n return \"\".join(prompt)\n
Name Type Description Default templatePromptTemplate
The prompt template.
required **kwargs
Any additional keyword arguments that will be used to populate the given template.
{} Source code in libs/kotaemon/kotaemon/llms/prompts/base.py
class BasePromptComponent(BaseComponent):\n \"\"\"\n Base class for prompt components.\n\n Args:\n template (PromptTemplate): The prompt template.\n **kwargs: Any additional keyword arguments that will be used to populate the\n given template.\n \"\"\"\n\n class Config:\n middleware_switches = {\"theflow.middleware.CachingMiddleware\": False}\n allow_extra = True\n\n template: str | PromptTemplate\n\n @Param.auto(depends_on=\"template\")\n def template__(self):\n return (\n self.template\n if isinstance(self.template, PromptTemplate)\n else PromptTemplate(self.template)\n )\n\n def __init__(self, **kwargs):\n super().__init__(**kwargs)\n self.__set(**kwargs)\n\n def __check_redundant_kwargs(self, **kwargs):\n \"\"\"\n Check for redundant keyword arguments.\n\n Parameters:\n **kwargs (dict): A dictionary of keyword arguments.\n\n Raises:\n ValueError: If any keys provided are not in the template.\n\n Returns:\n None\n \"\"\"\n self.template__.check_redundant_kwargs(**kwargs)\n\n def __check_unset_placeholders(self):\n \"\"\"\n Check if all the placeholders in the template are set.\n\n This function checks if all the expected placeholders in the template are set as\n attributes of the object. If any placeholders are missing, a `ValueError`\n is raised with the names of the missing keys.\n\n Parameters:\n None\n\n Returns:\n None\n \"\"\"\n self.template__.check_missing_kwargs(**self.__dict__)\n\n def __validate_value_type(self, **kwargs):\n \"\"\"\n Validates the value types of the given keyword arguments.\n\n Parameters:\n **kwargs (dict): A dictionary of keyword arguments to be validated.\n\n Raises:\n ValueError: If any of the values in the kwargs dictionary have an\n unsupported type.\n\n Returns:\n None\n \"\"\"\n type_error = []\n for k, v in kwargs.items():\n if k.startswith(\"template\"):\n continue\n if not isinstance(v, (str, int, Document, Callable)): # type: ignore\n type_error.append((k, type(v)))\n\n if type_error:\n raise ValueError(\n \"Type of values must be either int, str, Document, Callable, \"\n f\"found unsupported type for (key, type): {type_error}\"\n )\n\n def __set(self, **kwargs):\n \"\"\"\n Set the values of the attributes in the object based on the provided keyword\n arguments.\n\n Args:\n kwargs (dict): A dictionary with the attribute names as keys and the new\n values as values.\n\n Returns:\n None\n \"\"\"\n self.__check_redundant_kwargs(**kwargs)\n self.__validate_value_type(**kwargs)\n\n self.__dict__.update(kwargs)\n\n def __prepare_value(self):\n \"\"\"\n Generate a dictionary of keyword arguments based on the template's placeholders\n and the current instance's attributes.\n\n Returns:\n dict: A dictionary of keyword arguments.\n \"\"\"\n\n def __prepare(key, value):\n if isinstance(value, str):\n return value\n if isinstance(value, (int, Document)):\n return str(value)\n\n raise ValueError(\n f\"Unsupported type {type(value)} for template value of key {key}\"\n )\n\n kwargs = {}\n for k in self.template__.placeholders:\n v = getattr(self, k)\n\n # if get a callable, execute to get its output\n if isinstance(v, Callable): # type: ignore[arg-type]\n v = v()\n\n if isinstance(v, list):\n v = str([__prepare(k, each) for each in v])\n elif isinstance(v, (str, int, Document)):\n v = __prepare(k, v)\n else:\n raise ValueError(\n f\"Unsupported type {type(v)} for template value of key `{k}`\"\n )\n kwargs[k] = v\n\n return kwargs\n\n def set_value(self, **kwargs):\n \"\"\"\n Similar to `__set` but for external use.\n\n Set the values of the attributes in the object based on the provided keyword\n arguments.\n\n Args:\n kwargs (dict): A dictionary with the attribute names as keys and the new\n values as values.\n\n Returns:\n None\n \"\"\"\n self.__set(**kwargs)\n\n def run(self, **kwargs):\n \"\"\"\n Run the function with the given keyword arguments.\n\n Args:\n **kwargs: The keyword arguments to pass to the function.\n\n Returns:\n The result of calling the `populate` method of the `template` object\n with the given keyword arguments.\n \"\"\"\n self.__set(**kwargs)\n self.__check_unset_placeholders()\n prepared_kwargs = self.__prepare_value()\n\n text = self.template__.populate(**prepared_kwargs)\n return Document(text=text, metadata={\"origin\": \"PromptComponent\"})\n\n def flow(self):\n return self.__call__()\n
Set the values of the attributes in the object based on the provided keyword arguments.
Parameters:
Name Type Description Default kwargsdict
A dictionary with the attribute names as keys and the new values as values.
{}
Returns:
Type Description
None
Source code in libs/kotaemon/kotaemon/llms/prompts/base.py
def set_value(self, **kwargs):\n \"\"\"\n Similar to `__set` but for external use.\n\n Set the values of the attributes in the object based on the provided keyword\n arguments.\n\n Args:\n kwargs (dict): A dictionary with the attribute names as keys and the new\n values as values.\n\n Returns:\n None\n \"\"\"\n self.__set(**kwargs)\n
Run the function with the given keyword arguments.
Parameters:
Name Type Description Default **kwargs
The keyword arguments to pass to the function.
{}
Returns:
Type Description
The result of calling the populate method of the template object
with the given keyword arguments.
Source code in libs/kotaemon/kotaemon/llms/prompts/base.py
def run(self, **kwargs):\n \"\"\"\n Run the function with the given keyword arguments.\n\n Args:\n **kwargs: The keyword arguments to pass to the function.\n\n Returns:\n The result of calling the `populate` method of the `template` object\n with the given keyword arguments.\n \"\"\"\n self.__set(**kwargs)\n self.__check_unset_placeholders()\n prepared_kwargs = self.__prepare_value()\n\n text = self.template__.populate(**prepared_kwargs)\n return Document(text=text, metadata={\"origin\": \"PromptComponent\"})\n
Source code in libs/kotaemon/kotaemon/llms/prompts/template.py
class PromptTemplate:\n \"\"\"\n Base class for prompt templates.\n \"\"\"\n\n def __init__(self, template: str, ignore_invalid=True):\n template = template\n formatter = Formatter()\n parsed_template = list(formatter.parse(template))\n\n placeholders = set()\n for _, key, _, _ in parsed_template:\n if key is None:\n continue\n if not key.isidentifier():\n if ignore_invalid:\n warnings.warn(f\"Ignore invalid placeholder: {key}.\", UserWarning)\n else:\n raise ValueError(\n \"Placeholder name must be a valid Python identifier, found:\"\n f\" {key}.\"\n )\n placeholders.add(key)\n\n self.template = template\n self.placeholders = placeholders\n self.__formatter = formatter\n self.__parsed_template = parsed_template\n\n def check_missing_kwargs(self, **kwargs):\n \"\"\"\n Check if all the placeholders in the template are set.\n\n This function checks if all the expected placeholders in the template are set as\n attributes of the object. If any placeholders are missing, a `ValueError`\n is raised with the names of the missing keys.\n\n Parameters:\n None\n\n Returns:\n None\n \"\"\"\n missing_keys = self.placeholders.difference(kwargs.keys())\n if missing_keys:\n raise ValueError(f\"Missing keys in template: {','.join(missing_keys)}\")\n\n def check_redundant_kwargs(self, **kwargs):\n \"\"\"\n Check if all the placeholders in the template are set.\n\n This function checks if all the expected placeholders in the template are set as\n attributes of the object. If any placeholders are missing, a `ValueError`\n is raised with the names of the missing keys.\n\n Parameters:\n None\n\n Returns:\n None\n \"\"\"\n provided_keys = set(kwargs.keys())\n redundant_keys = provided_keys - self.placeholders\n\n if redundant_keys:\n warnings.warn(\n f\"Keys provided but not in template: {','.join(redundant_keys)}\",\n UserWarning,\n )\n\n def populate(self, **kwargs) -> str:\n \"\"\"\n Strictly populate the template with the given keyword arguments.\n\n Args:\n **kwargs: The keyword arguments to populate the template.\n Each keyword corresponds to a placeholder in the template.\n\n Returns:\n The populated template.\n\n Raises:\n ValueError: If an unknown placeholder is provided.\n \"\"\"\n self.check_missing_kwargs(**kwargs)\n\n return self.partial_populate(**kwargs)\n\n def partial_populate(self, **kwargs):\n \"\"\"\n Partially populate the template with the given keyword arguments.\n\n Args:\n **kwargs: The keyword arguments to populate the template.\n Each keyword corresponds to a placeholder in the template.\n\n Returns:\n str: The populated template.\n \"\"\"\n self.check_redundant_kwargs(**kwargs)\n\n prompt = []\n for literal_text, field_name, format_spec, conversion in self.__parsed_template:\n prompt.append(literal_text)\n\n if field_name is None:\n continue\n\n if field_name not in kwargs:\n if conversion:\n value = f\"{{{field_name}}}!{conversion}:{format_spec}\"\n else:\n value = f\"{{{field_name}:{format_spec}}}\"\n else:\n value = kwargs[field_name]\n if conversion is not None:\n value = self.__formatter.convert_field(value, conversion)\n if format_spec is not None:\n value = self.__formatter.format_field(value, format_spec)\n\n prompt.append(value)\n\n return \"\".join(prompt)\n\n def __add__(self, other):\n \"\"\"\n Create a new PromptTemplate object by concatenating the template of the current\n object with the template of another PromptTemplate object.\n\n Parameters:\n other (PromptTemplate): Another PromptTemplate object.\n\n Returns:\n PromptTemplate: A new PromptTemplate object with the concatenated templates.\n \"\"\"\n return PromptTemplate(self.template + \"\\n\" + other.template)\n
Check if all the placeholders in the template are set.
This function checks if all the expected placeholders in the template are set as attributes of the object. If any placeholders are missing, a ValueError is raised with the names of the missing keys.
Returns:
Type Description
None
Source code in libs/kotaemon/kotaemon/llms/prompts/template.py
def check_missing_kwargs(self, **kwargs):\n \"\"\"\n Check if all the placeholders in the template are set.\n\n This function checks if all the expected placeholders in the template are set as\n attributes of the object. If any placeholders are missing, a `ValueError`\n is raised with the names of the missing keys.\n\n Parameters:\n None\n\n Returns:\n None\n \"\"\"\n missing_keys = self.placeholders.difference(kwargs.keys())\n if missing_keys:\n raise ValueError(f\"Missing keys in template: {','.join(missing_keys)}\")\n
Check if all the placeholders in the template are set.
This function checks if all the expected placeholders in the template are set as attributes of the object. If any placeholders are missing, a ValueError is raised with the names of the missing keys.
Returns:
Type Description
None
Source code in libs/kotaemon/kotaemon/llms/prompts/template.py
def check_redundant_kwargs(self, **kwargs):\n \"\"\"\n Check if all the placeholders in the template are set.\n\n This function checks if all the expected placeholders in the template are set as\n attributes of the object. If any placeholders are missing, a `ValueError`\n is raised with the names of the missing keys.\n\n Parameters:\n None\n\n Returns:\n None\n \"\"\"\n provided_keys = set(kwargs.keys())\n redundant_keys = provided_keys - self.placeholders\n\n if redundant_keys:\n warnings.warn(\n f\"Keys provided but not in template: {','.join(redundant_keys)}\",\n UserWarning,\n )\n
Strictly populate the template with the given keyword arguments.
Parameters:
Name Type Description Default **kwargs
The keyword arguments to populate the template. Each keyword corresponds to a placeholder in the template.
{}
Returns:
Type Description str
The populated template.
Raises:
Type Description ValueError
If an unknown placeholder is provided.
Source code in libs/kotaemon/kotaemon/llms/prompts/template.py
def populate(self, **kwargs) -> str:\n \"\"\"\n Strictly populate the template with the given keyword arguments.\n\n Args:\n **kwargs: The keyword arguments to populate the template.\n Each keyword corresponds to a placeholder in the template.\n\n Returns:\n The populated template.\n\n Raises:\n ValueError: If an unknown placeholder is provided.\n \"\"\"\n self.check_missing_kwargs(**kwargs)\n\n return self.partial_populate(**kwargs)\n
Partially populate the template with the given keyword arguments.
Parameters:
Name Type Description Default **kwargs
The keyword arguments to populate the template. Each keyword corresponds to a placeholder in the template.
{}
Returns:
Name Type Description str
The populated template.
Source code in libs/kotaemon/kotaemon/llms/prompts/template.py
def partial_populate(self, **kwargs):\n \"\"\"\n Partially populate the template with the given keyword arguments.\n\n Args:\n **kwargs: The keyword arguments to populate the template.\n Each keyword corresponds to a placeholder in the template.\n\n Returns:\n str: The populated template.\n \"\"\"\n self.check_redundant_kwargs(**kwargs)\n\n prompt = []\n for literal_text, field_name, format_spec, conversion in self.__parsed_template:\n prompt.append(literal_text)\n\n if field_name is None:\n continue\n\n if field_name not in kwargs:\n if conversion:\n value = f\"{{{field_name}}}!{conversion}:{format_spec}\"\n else:\n value = f\"{{{field_name}:{format_spec}}}\"\n else:\n value = kwargs[field_name]\n if conversion is not None:\n value = self.__formatter.convert_field(value, conversion)\n if format_spec is not None:\n value = self.__formatter.format_field(value, format_spec)\n\n prompt.append(value)\n\n return \"\".join(prompt)\n
Args: endpoint: URL to the Vision Language Model endpoint. If not provided, will use the default kotaemon.loaders.adobe_loader.DEFAULT_VLM_ENDPOINT
max_figures_to_caption: an int decides how many figured will be captioned.\nThe rest will be ignored (are indexed without captions).\n
Source code in libs/kotaemon/kotaemon/loaders/adobe_loader.py
class AdobeReader(BaseReader):\n \"\"\"Read PDF using the Adobe's PDF Services.\n Be able to extract text, table, and figure with high accuracy\n\n Example:\n ```python\n >> from kotaemon.loaders import AdobeReader\n >> reader = AdobeReader()\n >> documents = reader.load_data(\"path/to/pdf\")\n ```\n Args:\n endpoint: URL to the Vision Language Model endpoint. If not provided,\n will use the default `kotaemon.loaders.adobe_loader.DEFAULT_VLM_ENDPOINT`\n\n max_figures_to_caption: an int decides how many figured will be captioned.\n The rest will be ignored (are indexed without captions).\n \"\"\"\n\n def __init__(\n self,\n vlm_endpoint: Optional[str] = None,\n max_figures_to_caption: int = 100,\n *args: Any,\n **kwargs: Any,\n ) -> None:\n \"\"\"Init params\"\"\"\n super().__init__(*args)\n self.table_regex = r\"/Table(\\[\\d+\\])?$\"\n self.figure_regex = r\"/Figure(\\[\\d+\\])?$\"\n self.vlm_endpoint = vlm_endpoint or DEFAULT_VLM_ENDPOINT\n self.max_figures_to_caption = max_figures_to_caption\n\n def load_data(\n self, file: Path, extra_info: Optional[Dict] = None, **kwargs\n ) -> List[Document]:\n \"\"\"Load data by calling to the Adobe's API\n\n Args:\n file (Path): Path to the PDF file\n\n Returns:\n List[Document]: list of documents extracted from the PDF file,\n includes 3 types: text, table, and image\n\n \"\"\"\n from .utils.adobe import (\n generate_figure_captions,\n load_json,\n parse_figure_paths,\n parse_table_paths,\n request_adobe_service,\n )\n\n filename = file.name\n filepath = str(Path(file).resolve())\n output_path = request_adobe_service(file_path=str(file), output_path=\"\")\n results_path = os.path.join(output_path, \"structuredData.json\")\n\n if not os.path.exists(results_path):\n logger.exception(\"Fail to parse the document.\")\n return []\n\n data = load_json(results_path)\n\n texts = defaultdict(list)\n tables = []\n figures = []\n\n elements = data[\"elements\"]\n for item_id, item in enumerate(elements):\n page_number = item.get(\"Page\", -1) + 1\n item_path = item[\"Path\"]\n item_text = item.get(\"Text\", \"\")\n\n file_paths = [\n Path(output_path) / path for path in item.get(\"filePaths\", [])\n ]\n prev_item = elements[item_id - 1]\n title = prev_item.get(\"Text\", \"\")\n\n if re.search(self.table_regex, item_path):\n table_content = parse_table_paths(file_paths)\n if not table_content:\n continue\n table_caption = (\n table_content.replace(\"|\", \"\").replace(\"---\", \"\")\n + f\"\\n(Table in Page {page_number}. {title})\"\n )\n tables.append((page_number, table_content, table_caption))\n\n elif re.search(self.figure_regex, item_path):\n figure_caption = (\n item_text + f\"\\n(Figure in Page {page_number}. {title})\"\n )\n figure_content = parse_figure_paths(file_paths)\n if not figure_content:\n continue\n figures.append([page_number, figure_content, figure_caption])\n\n else:\n if item_text and \"Table\" not in item_path and \"Figure\" not in item_path:\n texts[page_number].append(item_text)\n\n # get figure caption using GPT-4V\n figure_captions = generate_figure_captions(\n self.vlm_endpoint,\n [item[1] for item in figures],\n self.max_figures_to_caption,\n )\n for item, caption in zip(figures, figure_captions):\n # update figure caption\n item[2] += \" \" + caption\n\n # Wrap elements with Document\n documents = []\n\n # join plain text elements\n for page_number, txts in texts.items():\n documents.append(\n Document(\n text=\"\\n\".join(txts),\n metadata={\n \"page_label\": page_number,\n \"file_name\": filename,\n \"file_path\": filepath,\n },\n )\n )\n\n # table elements\n for page_number, table_content, table_caption in tables:\n documents.append(\n Document(\n text=table_content,\n metadata={\n \"table_origin\": table_content,\n \"type\": \"table\",\n \"page_label\": page_number,\n \"file_name\": filename,\n \"file_path\": filepath,\n },\n metadata_template=\"\",\n metadata_seperator=\"\",\n )\n )\n\n # figure elements\n for page_number, figure_content, figure_caption in figures:\n documents.append(\n Document(\n text=figure_caption,\n metadata={\n \"image_origin\": figure_content,\n \"type\": \"image\",\n \"page_label\": page_number,\n \"file_name\": filename,\n \"file_path\": filepath,\n },\n metadata_template=\"\",\n metadata_seperator=\"\",\n )\n )\n return documents\n
General auto reader for a variety of files. (based on llama-hub)
Source code in libs/kotaemon/kotaemon/loaders/base.py
class AutoReader(BaseReader):\n \"\"\"General auto reader for a variety of files. (based on llama-hub)\"\"\"\n\n def __init__(self, reader_type: Union[str, Type[\"LIBaseReader\"]]) -> None:\n \"\"\"Init reader using string identifier or class name from llama-hub\"\"\"\n\n if isinstance(reader_type, str):\n from llama_index.core import download_loader\n\n self._reader = download_loader(reader_type)()\n else:\n self._reader = reader_type()\n super().__init__()\n\n def load_data(self, file: Union[Path, str], **kwargs: Any) -> List[Document]:\n documents = self._reader.load_data(file=file, **kwargs)\n\n # convert Document to new base class from kotaemon\n converted_documents = [Document.from_dict(doc.to_dict()) for doc in documents]\n return converted_documents\n\n def run(self, file: Union[Path, str], **kwargs: Any) -> List[Document]:\n return self.load_data(file=file, **kwargs)\n
A mapping of file extension to a BaseReader class that specifies how to convert that file to text. If not specified, use default from DEFAULT_FILE_READER_CLS.
A function that takes in a filename and returns a Dict of metadata for the Document. Default is None.
required Source code in libs/kotaemon/kotaemon/loaders/composite_loader.py
class DirectoryReader(LIReaderMixin, BaseReader):\n \"\"\"Wrap around llama-index SimpleDirectoryReader\n\n Args:\n input_dir (str): Path to the directory.\n input_files (List): List of file paths to read\n (Optional; overrides input_dir, exclude)\n exclude (List): glob of python file paths to exclude (Optional)\n exclude_hidden (bool): Whether to exclude hidden files (dotfiles).\n encoding (str): Encoding of the files.\n Default is utf-8.\n errors (str): how encoding and decoding errors are to be handled,\n see https://docs.python.org/3/library/functions.html#open\n recursive (bool): Whether to recursively search in subdirectories.\n False by default.\n filename_as_id (bool): Whether to use the filename as the document id.\n False by default.\n required_exts (Optional[List[str]]): List of required extensions.\n Default is None.\n file_extractor (Optional[Dict[str, BaseReader]]): A mapping of file\n extension to a BaseReader class that specifies how to convert that file\n to text. If not specified, use default from DEFAULT_FILE_READER_CLS.\n num_files_limit (Optional[int]): Maximum number of files to read.\n Default is None.\n file_metadata (Optional[Callable[str, Dict]]): A function that takes\n in a filename and returns a Dict of metadata for the Document.\n Default is None.\n \"\"\"\n\n input_dir: Optional[str] = None\n input_files: Optional[List] = None\n exclude: Optional[List] = None\n exclude_hidden: bool = True\n errors: str = \"ignore\"\n recursive: bool = False\n encoding: str = \"utf-8\"\n filename_as_id: bool = False\n required_exts: Optional[list[str]] = None\n file_extractor: Optional[dict[str, \"LIBaseReader\"]] = None\n num_files_limit: Optional[int] = None\n file_metadata: Optional[Callable[[str], dict]] = None\n\n def _get_wrapped_class(self) -> Type[\"LIBaseReader\"]:\n from llama_index.core import SimpleDirectoryReader\n\n return SimpleDirectoryReader\n
Read Docx files that respect table, using python-docx library
Reader behavior
All paragraphs are extracted as a Document
Each table is extracted as a Document, rendered as a CSV string
The output is a list of Documents, concatenating the above (tables + paragraphs)
Source code in libs/kotaemon/kotaemon/loaders/docx_loader.py
class DocxReader(BaseReader):\n \"\"\"Read Docx files that respect table, using python-docx library\n\n Reader behavior:\n - All paragraphs are extracted as a Document\n - Each table is extracted as a Document, rendered as a CSV string\n - The output is a list of Documents, concatenating the above\n (tables + paragraphs)\n \"\"\"\n\n def __init__(self, *args, **kwargs):\n try:\n import docx # noqa\n except ImportError:\n raise ImportError(\n \"docx is not installed. \"\n \"Please install it using `pip install python-docx`\"\n )\n\n def _load_single_table(self, table) -> List[List[str]]:\n \"\"\"Extract content from tables. Return a list of columns: list[str]\n Some merged cells will share duplicated content.\n \"\"\"\n n_row = len(table.rows)\n n_col = len(table.columns)\n\n arrays = [[\"\" for _ in range(n_row)] for _ in range(n_col)]\n\n for i, row in enumerate(table.rows):\n for j, cell in enumerate(row.cells):\n arrays[j][i] = cell.text\n\n return arrays\n\n def load_data(\n self, file_path: Path, extra_info: Optional[dict] = None, **kwargs\n ) -> List[Document]:\n \"\"\"Load data using Docx reader\n\n Args:\n file_path (Path): Path to .docx file\n\n Returns:\n List[Document]: list of documents extracted from the HTML file\n \"\"\"\n import docx\n\n file_path = Path(file_path).resolve()\n\n doc = docx.Document(str(file_path))\n all_text = \"\\n\".join(\n [unicodedata.normalize(\"NFKC\", p.text) for p in doc.paragraphs]\n )\n pages = [all_text] # 1 page only\n\n tables = []\n for t in doc.tables:\n # return list of columns: list of string\n arrays = self._load_single_table(t)\n\n tables.append(pd.DataFrame({a[0]: a[1:] for a in arrays}))\n\n extra_info = extra_info or {}\n\n # create output Document with metadata from table\n documents = [\n Document(\n text=table.to_csv(\n index=False\n ).strip(), # strip_special_chars_markdown()\n metadata={\n \"table_origin\": table.to_csv(index=False),\n \"type\": \"table\",\n **extra_info,\n },\n metadata_template=\"\",\n metadata_seperator=\"\",\n )\n for table in tables # page_id\n ]\n\n # create Document from non-table text\n documents.extend(\n [\n Document(\n text=non_table_text.strip(),\n metadata={\"page_label\": 1, **extra_info},\n )\n for _, non_table_text in enumerate(pages)\n ]\n )\n\n return documents\n
Parses CSVs using the separator detection from Pandas read_csv function. If special parameters are required, use the pandas_config dict.
Args:
pandas_config (dict): Options for the `pandas.read_excel` function call.\n Refer to https://pandas.pydata.org/docs/reference/api/pandas.read_excel.html\n for more information. Set to empty dict by default,\n this means defaults will be used.\n
Source code in libs/kotaemon/kotaemon/loaders/excel_loader.py
class ExcelReader(BaseReader):\n r\"\"\"Spreadsheet exporter respecting multiple worksheets\n\n Parses CSVs using the separator detection from Pandas `read_csv` function.\n If special parameters are required, use the `pandas_config` dict.\n\n Args:\n\n pandas_config (dict): Options for the `pandas.read_excel` function call.\n Refer to https://pandas.pydata.org/docs/reference/api/pandas.read_excel.html\n for more information. Set to empty dict by default,\n this means defaults will be used.\n\n \"\"\"\n\n def __init__(\n self,\n *args: Any,\n pandas_config: Optional[dict] = None,\n row_joiner: str = \"\\n\",\n col_joiner: str = \" \",\n **kwargs: Any,\n ) -> None:\n \"\"\"Init params.\"\"\"\n super().__init__(*args, **kwargs)\n self._pandas_config = pandas_config or {}\n self._row_joiner = row_joiner if row_joiner else \"\\n\"\n self._col_joiner = col_joiner if col_joiner else \" \"\n\n def load_data(\n self,\n file: Path,\n include_sheetname: bool = True,\n sheet_name: Optional[Union[str, int, list]] = None,\n extra_info: Optional[dict] = None,\n **kwargs,\n ) -> List[Document]:\n \"\"\"Parse file and extract values from a specific column.\n\n Args:\n file (Path): The path to the Excel file to read.\n include_sheetname (bool): Whether to include the sheet name in the output.\n sheet_name (Union[str, int, None]): The specific sheet to read from,\n default is None which reads all sheets.\n\n Returns:\n List[Document]: A list of`Document objects containing the\n values from the specified column in the Excel file.\n \"\"\"\n\n try:\n import pandas as pd\n except ImportError:\n raise ImportError(\n \"install pandas using `pip3 install pandas` to use this loader\"\n )\n\n if sheet_name is not None:\n sheet_name = (\n [sheet_name] if not isinstance(sheet_name, list) else sheet_name\n )\n\n # clean up input\n file = Path(file)\n extra_info = extra_info or {}\n\n dfs = pd.read_excel(file, sheet_name=sheet_name, **self._pandas_config)\n sheet_names = dfs.keys()\n output = []\n\n for idx, key in enumerate(sheet_names):\n dfs[key] = dfs[key].dropna(axis=0, how=\"all\")\n dfs[key] = dfs[key].dropna(axis=0, how=\"all\")\n dfs[key] = dfs[key].astype(\"object\")\n dfs[key].fillna(\"\", inplace=True)\n\n rows = dfs[key].values.astype(str).tolist()\n content = self._row_joiner.join(\n self._col_joiner.join(row).strip() for row in rows\n ).strip()\n if include_sheetname:\n content = f\"(Sheet {key} of file {file.name})\\n{content}\"\n metadata = {\"page_label\": idx + 1, \"sheet_name\": key, **extra_info}\n output.append(Document(text=content, metadata=metadata))\n\n return output\n
Parse file and extract values from a specific column.
Parameters:
Name Type Description Default filePath
The path to the Excel file to read.
required include_sheetnamebool
Whether to include the sheet name in the output.
Truesheet_nameUnion[str, int, None]
The specific sheet to read from, default is None which reads all sheets.
None
Returns:
Type Description List[Document]
List[Document]: A list of`Document objects containing the values from the specified column in the Excel file.
Source code in libs/kotaemon/kotaemon/loaders/excel_loader.py
def load_data(\n self,\n file: Path,\n include_sheetname: bool = True,\n sheet_name: Optional[Union[str, int, list]] = None,\n extra_info: Optional[dict] = None,\n **kwargs,\n) -> List[Document]:\n \"\"\"Parse file and extract values from a specific column.\n\n Args:\n file (Path): The path to the Excel file to read.\n include_sheetname (bool): Whether to include the sheet name in the output.\n sheet_name (Union[str, int, None]): The specific sheet to read from,\n default is None which reads all sheets.\n\n Returns:\n List[Document]: A list of`Document objects containing the\n values from the specified column in the Excel file.\n \"\"\"\n\n try:\n import pandas as pd\n except ImportError:\n raise ImportError(\n \"install pandas using `pip3 install pandas` to use this loader\"\n )\n\n if sheet_name is not None:\n sheet_name = (\n [sheet_name] if not isinstance(sheet_name, list) else sheet_name\n )\n\n # clean up input\n file = Path(file)\n extra_info = extra_info or {}\n\n dfs = pd.read_excel(file, sheet_name=sheet_name, **self._pandas_config)\n sheet_names = dfs.keys()\n output = []\n\n for idx, key in enumerate(sheet_names):\n dfs[key] = dfs[key].dropna(axis=0, how=\"all\")\n dfs[key] = dfs[key].dropna(axis=0, how=\"all\")\n dfs[key] = dfs[key].astype(\"object\")\n dfs[key].fillna(\"\", inplace=True)\n\n rows = dfs[key].values.astype(str).tolist()\n content = self._row_joiner.join(\n self._col_joiner.join(row).strip() for row in rows\n ).strip()\n if include_sheetname:\n content = f\"(Sheet {key} of file {file.name})\\n{content}\"\n metadata = {\"page_label\": idx + 1, \"sheet_name\": key, **extra_info}\n output.append(Document(text=content, metadata=metadata))\n\n return output\n
Parses CSVs using the separator detection from Pandas read_csv function. If special parameters are required, use the pandas_config dict.
Args:
pandas_config (dict): Options for the `pandas.read_excel` function call.\n Refer to https://pandas.pydata.org/docs/reference/api/pandas.read_excel.html\n for more information. Set to empty dict by default,\n this means defaults will be used.\n
Source code in libs/kotaemon/kotaemon/loaders/excel_loader.py
class PandasExcelReader(BaseReader):\n r\"\"\"Pandas-based CSV parser.\n\n Parses CSVs using the separator detection from Pandas `read_csv` function.\n If special parameters are required, use the `pandas_config` dict.\n\n Args:\n\n pandas_config (dict): Options for the `pandas.read_excel` function call.\n Refer to https://pandas.pydata.org/docs/reference/api/pandas.read_excel.html\n for more information. Set to empty dict by default,\n this means defaults will be used.\n\n \"\"\"\n\n def __init__(\n self,\n *args: Any,\n pandas_config: Optional[dict] = None,\n row_joiner: str = \"\\n\",\n col_joiner: str = \" \",\n **kwargs: Any,\n ) -> None:\n \"\"\"Init params.\"\"\"\n super().__init__(*args, **kwargs)\n self._pandas_config = pandas_config or {}\n self._row_joiner = row_joiner if row_joiner else \"\\n\"\n self._col_joiner = col_joiner if col_joiner else \" \"\n\n def load_data(\n self,\n file: Path,\n include_sheetname: bool = False,\n sheet_name: Optional[Union[str, int, list]] = None,\n extra_info: Optional[dict] = None,\n **kwargs,\n ) -> List[Document]:\n \"\"\"Parse file and extract values from a specific column.\n\n Args:\n file (Path): The path to the Excel file to read.\n include_sheetname (bool): Whether to include the sheet name in the output.\n sheet_name (Union[str, int, None]): The specific sheet to read from,\n default is None which reads all sheets.\n\n Returns:\n List[Document]: A list of`Document objects containing the\n values from the specified column in the Excel file.\n \"\"\"\n import itertools\n\n try:\n import pandas as pd\n except ImportError:\n raise ImportError(\n \"install pandas using `pip3 install pandas` to use this loader\"\n )\n\n if sheet_name is not None:\n sheet_name = (\n [sheet_name] if not isinstance(sheet_name, list) else sheet_name\n )\n\n dfs = pd.read_excel(file, sheet_name=sheet_name, **self._pandas_config)\n sheet_names = dfs.keys()\n df_sheets = []\n\n for key in sheet_names:\n sheet = []\n if include_sheetname:\n sheet.append([key])\n dfs[key] = dfs[key].dropna(axis=0, how=\"all\")\n dfs[key] = dfs[key].dropna(axis=0, how=\"all\")\n dfs[key].fillna(\"\", inplace=True)\n sheet.extend(dfs[key].values.astype(str).tolist())\n df_sheets.append(sheet)\n\n text_list = list(\n itertools.chain.from_iterable(df_sheets)\n ) # flatten list of lists\n\n output = [\n Document(\n text=self._row_joiner.join(\n self._col_joiner.join(sublist) for sublist in text_list\n ),\n metadata=extra_info or {},\n )\n ]\n\n return output\n
Parse file and extract values from a specific column.
Parameters:
Name Type Description Default filePath
The path to the Excel file to read.
required include_sheetnamebool
Whether to include the sheet name in the output.
Falsesheet_nameUnion[str, int, None]
The specific sheet to read from, default is None which reads all sheets.
None
Returns:
Type Description List[Document]
List[Document]: A list of`Document objects containing the values from the specified column in the Excel file.
Source code in libs/kotaemon/kotaemon/loaders/excel_loader.py
def load_data(\n self,\n file: Path,\n include_sheetname: bool = False,\n sheet_name: Optional[Union[str, int, list]] = None,\n extra_info: Optional[dict] = None,\n **kwargs,\n) -> List[Document]:\n \"\"\"Parse file and extract values from a specific column.\n\n Args:\n file (Path): The path to the Excel file to read.\n include_sheetname (bool): Whether to include the sheet name in the output.\n sheet_name (Union[str, int, None]): The specific sheet to read from,\n default is None which reads all sheets.\n\n Returns:\n List[Document]: A list of`Document objects containing the\n values from the specified column in the Excel file.\n \"\"\"\n import itertools\n\n try:\n import pandas as pd\n except ImportError:\n raise ImportError(\n \"install pandas using `pip3 install pandas` to use this loader\"\n )\n\n if sheet_name is not None:\n sheet_name = (\n [sheet_name] if not isinstance(sheet_name, list) else sheet_name\n )\n\n dfs = pd.read_excel(file, sheet_name=sheet_name, **self._pandas_config)\n sheet_names = dfs.keys()\n df_sheets = []\n\n for key in sheet_names:\n sheet = []\n if include_sheetname:\n sheet.append([key])\n dfs[key] = dfs[key].dropna(axis=0, how=\"all\")\n dfs[key] = dfs[key].dropna(axis=0, how=\"all\")\n dfs[key].fillna(\"\", inplace=True)\n sheet.extend(dfs[key].values.astype(str).tolist())\n df_sheets.append(sheet)\n\n text_list = list(\n itertools.chain.from_iterable(df_sheets)\n ) # flatten list of lists\n\n output = [\n Document(\n text=self._row_joiner.join(\n self._col_joiner.join(sublist) for sublist in text_list\n ),\n metadata=extra_info or {},\n )\n ]\n\n return output\n
All of the texts will be split by page_break_pattern
Each page is extracted as a Document
The output is a list of Documents
Parameters:
Name Type Description Default page_break_patternstr
Pattern to split the HTML into pages
None Source code in libs/kotaemon/kotaemon/loaders/html_loader.py
class HtmlReader(BaseReader):\n \"\"\"Reader HTML usimg html2text\n\n Reader behavior:\n - HTML is read with html2text.\n - All of the texts will be split by `page_break_pattern`\n - Each page is extracted as a Document\n - The output is a list of Documents\n\n Args:\n page_break_pattern (str): Pattern to split the HTML into pages\n \"\"\"\n\n def __init__(self, page_break_pattern: Optional[str] = None, *args, **kwargs):\n try:\n import html2text # noqa\n except ImportError:\n raise ImportError(\n \"html2text is not installed. \"\n \"Please install it using `pip install html2text`\"\n )\n\n self._page_break_pattern: Optional[str] = page_break_pattern\n super().__init__()\n\n def load_data(\n self, file_path: Path | str, extra_info: Optional[dict] = None, **kwargs\n ) -> list[Document]:\n \"\"\"Load data using Html reader\n\n Args:\n file_path: path to HTML file\n extra_info: extra information passed to this reader during extracting data\n\n Returns:\n list[Document]: list of documents extracted from the HTML file\n \"\"\"\n import html2text\n\n file_path = Path(file_path).resolve()\n\n with file_path.open(\"r\") as f:\n html_text = \"\".join([line[:-1] for line in f.readlines()])\n\n # read HTML\n all_text = html2text.html2text(html_text)\n pages = (\n all_text.split(self._page_break_pattern)\n if self._page_break_pattern\n else [all_text]\n )\n\n extra_info = extra_info or {}\n\n # create Document from non-table text\n documents = [\n Document(\n text=page.strip(),\n metadata={\"page_label\": page_id + 1, **extra_info},\n )\n for page_id, page in enumerate(pages)\n ]\n\n return documents\n
extra information passed to this reader during extracting data
None
Returns:
Type Description list[Document]
list[Document]: list of documents extracted from the HTML file
Source code in libs/kotaemon/kotaemon/loaders/html_loader.py
def load_data(\n self, file_path: Path | str, extra_info: Optional[dict] = None, **kwargs\n) -> list[Document]:\n \"\"\"Load data using Html reader\n\n Args:\n file_path: path to HTML file\n extra_info: extra information passed to this reader during extracting data\n\n Returns:\n list[Document]: list of documents extracted from the HTML file\n \"\"\"\n import html2text\n\n file_path = Path(file_path).resolve()\n\n with file_path.open(\"r\") as f:\n html_text = \"\".join([line[:-1] for line in f.readlines()])\n\n # read HTML\n all_text = html2text.html2text(html_text)\n pages = (\n all_text.split(self._page_break_pattern)\n if self._page_break_pattern\n else [all_text]\n )\n\n extra_info = extra_info or {}\n\n # create Document from non-table text\n documents = [\n Document(\n text=page.strip(),\n metadata={\"page_label\": page_id + 1, **extra_info},\n )\n for page_id, page in enumerate(pages)\n ]\n\n return documents\n
Source code in libs/kotaemon/kotaemon/loaders/html_loader.py
class MhtmlReader(BaseReader):\n \"\"\"Parse `MHTML` files with `BeautifulSoup`.\"\"\"\n\n def __init__(\n self,\n cache_dir: Optional[str] = getattr(\n flowsettings, \"KH_MARKDOWN_OUTPUT_DIR\", None\n ),\n open_encoding: Optional[str] = None,\n bs_kwargs: Optional[dict] = None,\n get_text_separator: str = \"\",\n ) -> None:\n \"\"\"initialize with path, and optionally, file encoding to use, and any kwargs\n to pass to the BeautifulSoup object.\n\n Args:\n cache_dir: Path for markdwon format.\n file_path: Path to file to load.\n open_encoding: The encoding to use when opening the file.\n bs_kwargs: Any kwargs to pass to the BeautifulSoup object.\n get_text_separator: The separator to use when getting the text\n from the soup.\n \"\"\"\n try:\n import bs4 # noqa:F401\n except ImportError:\n raise ImportError(\n \"beautifulsoup4 package not found, please install it with \"\n \"`pip install beautifulsoup4`\"\n )\n\n self.cache_dir = cache_dir\n self.open_encoding = open_encoding\n if bs_kwargs is None:\n bs_kwargs = {\"features\": \"lxml\"}\n self.bs_kwargs = bs_kwargs\n self.get_text_separator = get_text_separator\n\n def load_data(\n self, file_path: Path | str, extra_info: Optional[dict] = None, **kwargs\n ) -> list[Document]:\n \"\"\"Load MHTML document into document objects.\"\"\"\n\n from bs4 import BeautifulSoup\n\n extra_info = extra_info or {}\n metadata: dict = extra_info\n page = []\n file_name = Path(file_path)\n with open(file_path, \"r\", encoding=self.open_encoding) as f:\n message = email.message_from_string(f.read())\n parts = message.get_payload()\n\n if not isinstance(parts, list):\n parts = [message]\n\n for part in parts:\n if part.get_content_type() == \"text/html\":\n html = part.get_payload(decode=True).decode()\n\n soup = BeautifulSoup(html, **self.bs_kwargs)\n text = soup.get_text(self.get_text_separator)\n\n if soup.title:\n title = str(soup.title.string)\n else:\n title = \"\"\n\n metadata = {\n \"source\": str(file_path),\n \"title\": title,\n **extra_info,\n }\n lines = [line for line in text.split(\"\\n\") if line.strip()]\n text = \"\\n\\n\".join(lines)\n if text:\n page.append(text)\n # save the page into markdown format\n print(self.cache_dir)\n if self.cache_dir is not None:\n print(Path(self.cache_dir) / f\"{file_name.stem}.md\")\n with open(Path(self.cache_dir) / f\"{file_name.stem}.md\", \"w\") as f:\n f.write(page[0])\n\n return [Document(text=\"\\n\\n\".join(page), metadata=metadata)]\n
Source code in libs/kotaemon/kotaemon/loaders/html_loader.py
def load_data(\n self, file_path: Path | str, extra_info: Optional[dict] = None, **kwargs\n) -> list[Document]:\n \"\"\"Load MHTML document into document objects.\"\"\"\n\n from bs4 import BeautifulSoup\n\n extra_info = extra_info or {}\n metadata: dict = extra_info\n page = []\n file_name = Path(file_path)\n with open(file_path, \"r\", encoding=self.open_encoding) as f:\n message = email.message_from_string(f.read())\n parts = message.get_payload()\n\n if not isinstance(parts, list):\n parts = [message]\n\n for part in parts:\n if part.get_content_type() == \"text/html\":\n html = part.get_payload(decode=True).decode()\n\n soup = BeautifulSoup(html, **self.bs_kwargs)\n text = soup.get_text(self.get_text_separator)\n\n if soup.title:\n title = str(soup.title.string)\n else:\n title = \"\"\n\n metadata = {\n \"source\": str(file_path),\n \"title\": title,\n **extra_info,\n }\n lines = [line for line in text.split(\"\\n\") if line.strip()]\n text = \"\\n\\n\".join(lines)\n if text:\n page.append(text)\n # save the page into markdown format\n print(self.cache_dir)\n if self.cache_dir is not None:\n print(Path(self.cache_dir) / f\"{file_name.stem}.md\")\n with open(Path(self.cache_dir) / f\"{file_name.stem}.md\", \"w\") as f:\n f.write(page[0])\n\n return [Document(text=\"\\n\\n\".join(page), metadata=metadata)]\n
Source code in libs/kotaemon/kotaemon/loaders/mathpix_loader.py
def wait_for_processing(self, pdf_id: str) -> None:\n \"\"\"Wait for processing to complete.\n\n Args:\n pdf_id: a PDF id.\n\n Returns: None\n \"\"\"\n url = self.url + \"/\" + pdf_id\n for _ in range(0, self.max_wait_time_seconds, 5):\n response = requests.get(url, headers=self._mathpix_headers)\n response_data = response.json()\n status = response_data.get(\"status\", None)\n\n if status == \"completed\":\n return\n elif status == \"error\":\n raise ValueError(\"Unable to retrieve PDF from Mathpix\")\n else:\n print(response_data)\n print(url)\n time.sleep(5)\n raise TimeoutError\n
Name Type Description Default endpointOptional[str]
URL to FullOCR endpoint. If not provided, will look for environment variable OCR_READER_ENDPOINT or use the default knowledgehub.loaders.ocr_loader.DEFAULT_OCR_ENDPOINT (http://127.0.0.1:8000/v2/ai/infer/)
Noneuse_ocr
whether to use OCR to read text (e.g: from images, tables) in the PDF If False, only the table and text within table cells will be extracted.
required Source code in libs/kotaemon/kotaemon/loaders/ocr_loader.py
class ImageReader(BaseReader):\n \"\"\"Read PDF using OCR, with high focus on table extraction\n\n Example:\n ```python\n >> from knowledgehub.loaders import OCRReader\n >> reader = OCRReader()\n >> documents = reader.load_data(\"path/to/pdf\")\n ```\n\n Args:\n endpoint: URL to FullOCR endpoint. If not provided, will look for\n environment variable `OCR_READER_ENDPOINT` or use the default\n `knowledgehub.loaders.ocr_loader.DEFAULT_OCR_ENDPOINT`\n (http://127.0.0.1:8000/v2/ai/infer/)\n use_ocr: whether to use OCR to read text (e.g: from images, tables) in the PDF\n If False, only the table and text within table cells will be extracted.\n \"\"\"\n\n def __init__(self, endpoint: Optional[str] = None):\n \"\"\"Init the OCR reader with OCR endpoint (FullOCR pipeline)\"\"\"\n super().__init__()\n self.ocr_endpoint = endpoint or os.getenv(\n \"OCR_READER_ENDPOINT\", DEFAULT_OCR_ENDPOINT\n )\n\n def load_data(\n self, file_path: Path, extra_info: Optional[dict] = None, **kwargs\n ) -> List[Document]:\n \"\"\"Load data using OCR reader\n\n Args:\n file_path (Path): Path to PDF file\n debug_path (Path): Path to store debug image output\n artifact_path (Path): Path to OCR endpoints artifacts directory\n\n Returns:\n List[Document]: list of documents extracted from the PDF file\n \"\"\"\n file_path = Path(file_path).resolve()\n\n # call the API from FullOCR endpoint\n if \"response_content\" in kwargs:\n # overriding response content if specified\n ocr_results = kwargs[\"response_content\"]\n else:\n # call original API\n resp = tenacious_api_post(\n url=self.ocr_endpoint, file_path=file_path, table_only=False\n )\n ocr_results = resp.json()[\"result\"]\n\n extra_info = extra_info or {}\n result = []\n for ocr_result in ocr_results:\n result.append(\n Document(\n content=ocr_result[\"csv_string\"],\n metadata=extra_info,\n )\n )\n\n return result\n
List[Document]: list of documents extracted from the PDF file
Source code in libs/kotaemon/kotaemon/loaders/ocr_loader.py
def load_data(\n self, file_path: Path, extra_info: Optional[dict] = None, **kwargs\n) -> List[Document]:\n \"\"\"Load data using OCR reader\n\n Args:\n file_path (Path): Path to PDF file\n debug_path (Path): Path to store debug image output\n artifact_path (Path): Path to OCR endpoints artifacts directory\n\n Returns:\n List[Document]: list of documents extracted from the PDF file\n \"\"\"\n file_path = Path(file_path).resolve()\n\n # call the API from FullOCR endpoint\n if \"response_content\" in kwargs:\n # overriding response content if specified\n ocr_results = kwargs[\"response_content\"]\n else:\n # call original API\n resp = tenacious_api_post(\n url=self.ocr_endpoint, file_path=file_path, table_only=False\n )\n ocr_results = resp.json()[\"result\"]\n\n extra_info = extra_info or {}\n result = []\n for ocr_result in ocr_results:\n result.append(\n Document(\n content=ocr_result[\"csv_string\"],\n metadata=extra_info,\n )\n )\n\n return result\n
Name Type Description Default endpointOptional[str]
URL to FullOCR endpoint. If not provided, will look for environment variable OCR_READER_ENDPOINT or use the default kotaemon.loaders.ocr_loader.DEFAULT_OCR_ENDPOINT (http://127.0.0.1:8000/v2/ai/infer/)
Noneuse_ocr
whether to use OCR to read text (e.g: from images, tables) in the PDF If False, only the table and text within table cells will be extracted.
True Source code in libs/kotaemon/kotaemon/loaders/ocr_loader.py
class OCRReader(BaseReader):\n \"\"\"Read PDF using OCR, with high focus on table extraction\n\n Example:\n ```python\n >> from kotaemon.loaders import OCRReader\n >> reader = OCRReader()\n >> documents = reader.load_data(\"path/to/pdf\")\n ```\n\n Args:\n endpoint: URL to FullOCR endpoint. If not provided, will look for\n environment variable `OCR_READER_ENDPOINT` or use the default\n `kotaemon.loaders.ocr_loader.DEFAULT_OCR_ENDPOINT`\n (http://127.0.0.1:8000/v2/ai/infer/)\n use_ocr: whether to use OCR to read text (e.g: from images, tables) in the PDF\n If False, only the table and text within table cells will be extracted.\n \"\"\"\n\n def __init__(self, endpoint: Optional[str] = None, use_ocr=True):\n \"\"\"Init the OCR reader with OCR endpoint (FullOCR pipeline)\"\"\"\n super().__init__()\n self.ocr_endpoint = endpoint or os.getenv(\n \"OCR_READER_ENDPOINT\", DEFAULT_OCR_ENDPOINT\n )\n self.use_ocr = use_ocr\n\n def load_data(\n self, file_path: Path, extra_info: Optional[dict] = None, **kwargs\n ) -> List[Document]:\n \"\"\"Load data using OCR reader\n\n Args:\n file_path (Path): Path to PDF file\n debug_path (Path): Path to store debug image output\n artifact_path (Path): Path to OCR endpoints artifacts directory\n\n Returns:\n List[Document]: list of documents extracted from the PDF file\n \"\"\"\n file_path = Path(file_path).resolve()\n\n # call the API from FullOCR endpoint\n if \"response_content\" in kwargs:\n # overriding response content if specified\n ocr_results = kwargs[\"response_content\"]\n else:\n # call original API\n resp = tenacious_api_post(\n url=self.ocr_endpoint, file_path=file_path, table_only=not self.use_ocr\n )\n ocr_results = resp.json()[\"result\"]\n\n debug_path = kwargs.pop(\"debug_path\", None)\n artifact_path = kwargs.pop(\"artifact_path\", None)\n\n # read PDF through normal reader (unstructured)\n pdf_page_items = read_pdf_unstructured(file_path)\n # merge PDF text output with OCR output\n tables, texts = parse_ocr_output(\n ocr_results,\n pdf_page_items,\n debug_path=debug_path,\n artifact_path=artifact_path,\n )\n extra_info = extra_info or {}\n\n # create output Document with metadata from table\n documents = [\n Document(\n text=strip_special_chars_markdown(table_text),\n metadata={\n \"table_origin\": table_text,\n \"type\": \"table\",\n \"page_label\": page_id + 1,\n **extra_info,\n },\n metadata_template=\"\",\n metadata_seperator=\"\",\n )\n for page_id, table_text in tables\n ]\n # create Document from non-table text\n documents.extend(\n [\n Document(\n text=non_table_text,\n metadata={\"page_label\": page_id + 1, **extra_info},\n )\n for page_id, non_table_text in texts\n ]\n )\n\n return documents\n
General unstructured text reader for a variety of files.
Source code in libs/kotaemon/kotaemon/loaders/unstructured_loader.py
class UnstructuredReader(BaseReader):\n \"\"\"General unstructured text reader for a variety of files.\"\"\"\n\n def __init__(self, *args: Any, **kwargs: Any) -> None:\n \"\"\"Init params.\"\"\"\n super().__init__(*args) # not passing kwargs to parent bc it cannot accept it\n\n self.api = False # we default to local\n if \"url\" in kwargs:\n self.server_url = str(kwargs[\"url\"])\n self.api = True # is url was set, switch to api\n else:\n self.server_url = \"http://localhost:8000\"\n\n if \"api\" in kwargs:\n self.api = kwargs[\"api\"]\n\n self.api_key = \"\"\n if \"api_key\" in kwargs:\n self.api_key = kwargs[\"api_key\"]\n\n \"\"\" Loads data using Unstructured.io\n\n Depending on the construction if url is set or api = True\n it'll parse file using API call, else parse it locally\n additional_metadata is extended by the returned metadata if\n split_documents is True\n\n Returns list of documents\n \"\"\"\n\n def load_data(\n self,\n file: Path,\n extra_info: Optional[Dict] = None,\n split_documents: Optional[bool] = False,\n **kwargs,\n ) -> List[Document]:\n \"\"\"If api is set, parse through api\"\"\"\n file_path_str = str(file)\n if self.api:\n from unstructured.partition.api import partition_via_api\n\n elements = partition_via_api(\n filename=file_path_str,\n api_key=self.api_key,\n api_url=self.server_url + \"/general/v0/general\",\n )\n else:\n \"\"\"Parse file locally\"\"\"\n from unstructured.partition.auto import partition\n\n elements = partition(filename=file_path_str)\n\n \"\"\" Process elements \"\"\"\n docs = []\n file_name = Path(file).name\n file_path = str(Path(file).resolve())\n if split_documents:\n for node in elements:\n metadata = {\"file_name\": file_name, \"file_path\": file_path}\n if hasattr(node, \"metadata\"):\n \"\"\"Load metadata fields\"\"\"\n for field, val in vars(node.metadata).items():\n if field == \"_known_field_names\":\n continue\n # removing coordinates because it does not serialize\n # and dont want to bother with it\n if field == \"coordinates\":\n continue\n # removing bc it might cause interference\n if field == \"parent_id\":\n continue\n metadata[field] = val\n\n if extra_info is not None:\n metadata.update(extra_info)\n\n metadata[\"file_name\"] = file_name\n docs.append(Document(text=node.text, metadata=metadata))\n\n else:\n text_chunks = [\" \".join(str(el).split()) for el in elements]\n metadata = {\"file_name\": file_name, \"file_path\": file_path}\n\n if extra_info is not None:\n metadata.update(extra_info)\n\n # Create a single document by joining all the texts\n docs.append(Document(text=\"\\n\\n\".join(text_chunks), metadata=metadata))\n\n return docs\n
Source code in libs/kotaemon/kotaemon/loaders/unstructured_loader.py
def load_data(\n self,\n file: Path,\n extra_info: Optional[Dict] = None,\n split_documents: Optional[bool] = False,\n **kwargs,\n) -> List[Document]:\n \"\"\"If api is set, parse through api\"\"\"\n file_path_str = str(file)\n if self.api:\n from unstructured.partition.api import partition_via_api\n\n elements = partition_via_api(\n filename=file_path_str,\n api_key=self.api_key,\n api_url=self.server_url + \"/general/v0/general\",\n )\n else:\n \"\"\"Parse file locally\"\"\"\n from unstructured.partition.auto import partition\n\n elements = partition(filename=file_path_str)\n\n \"\"\" Process elements \"\"\"\n docs = []\n file_name = Path(file).name\n file_path = str(Path(file).resolve())\n if split_documents:\n for node in elements:\n metadata = {\"file_name\": file_name, \"file_path\": file_path}\n if hasattr(node, \"metadata\"):\n \"\"\"Load metadata fields\"\"\"\n for field, val in vars(node.metadata).items():\n if field == \"_known_field_names\":\n continue\n # removing coordinates because it does not serialize\n # and dont want to bother with it\n if field == \"coordinates\":\n continue\n # removing bc it might cause interference\n if field == \"parent_id\":\n continue\n metadata[field] = val\n\n if extra_info is not None:\n metadata.update(extra_info)\n\n metadata[\"file_name\"] = file_name\n docs.append(Document(text=node.text, metadata=metadata))\n\n else:\n text_chunks = [\" \".join(str(el).split()) for el in elements]\n metadata = {\"file_name\": file_name, \"file_path\": file_path}\n\n if extra_info is not None:\n metadata.update(extra_info)\n\n # Create a single document by joining all the texts\n docs.append(Document(text=\"\\n\\n\".join(text_chunks), metadata=metadata))\n\n return docs\n
Args: endpoint: URL to the Vision Language Model endpoint. If not provided, will use the default kotaemon.loaders.adobe_loader.DEFAULT_VLM_ENDPOINT
max_figures_to_caption: an int decides how many figured will be captioned.\nThe rest will be ignored (are indexed without captions).\n
Source code in libs/kotaemon/kotaemon/loaders/adobe_loader.py
class AdobeReader(BaseReader):\n \"\"\"Read PDF using the Adobe's PDF Services.\n Be able to extract text, table, and figure with high accuracy\n\n Example:\n ```python\n >> from kotaemon.loaders import AdobeReader\n >> reader = AdobeReader()\n >> documents = reader.load_data(\"path/to/pdf\")\n ```\n Args:\n endpoint: URL to the Vision Language Model endpoint. If not provided,\n will use the default `kotaemon.loaders.adobe_loader.DEFAULT_VLM_ENDPOINT`\n\n max_figures_to_caption: an int decides how many figured will be captioned.\n The rest will be ignored (are indexed without captions).\n \"\"\"\n\n def __init__(\n self,\n vlm_endpoint: Optional[str] = None,\n max_figures_to_caption: int = 100,\n *args: Any,\n **kwargs: Any,\n ) -> None:\n \"\"\"Init params\"\"\"\n super().__init__(*args)\n self.table_regex = r\"/Table(\\[\\d+\\])?$\"\n self.figure_regex = r\"/Figure(\\[\\d+\\])?$\"\n self.vlm_endpoint = vlm_endpoint or DEFAULT_VLM_ENDPOINT\n self.max_figures_to_caption = max_figures_to_caption\n\n def load_data(\n self, file: Path, extra_info: Optional[Dict] = None, **kwargs\n ) -> List[Document]:\n \"\"\"Load data by calling to the Adobe's API\n\n Args:\n file (Path): Path to the PDF file\n\n Returns:\n List[Document]: list of documents extracted from the PDF file,\n includes 3 types: text, table, and image\n\n \"\"\"\n from .utils.adobe import (\n generate_figure_captions,\n load_json,\n parse_figure_paths,\n parse_table_paths,\n request_adobe_service,\n )\n\n filename = file.name\n filepath = str(Path(file).resolve())\n output_path = request_adobe_service(file_path=str(file), output_path=\"\")\n results_path = os.path.join(output_path, \"structuredData.json\")\n\n if not os.path.exists(results_path):\n logger.exception(\"Fail to parse the document.\")\n return []\n\n data = load_json(results_path)\n\n texts = defaultdict(list)\n tables = []\n figures = []\n\n elements = data[\"elements\"]\n for item_id, item in enumerate(elements):\n page_number = item.get(\"Page\", -1) + 1\n item_path = item[\"Path\"]\n item_text = item.get(\"Text\", \"\")\n\n file_paths = [\n Path(output_path) / path for path in item.get(\"filePaths\", [])\n ]\n prev_item = elements[item_id - 1]\n title = prev_item.get(\"Text\", \"\")\n\n if re.search(self.table_regex, item_path):\n table_content = parse_table_paths(file_paths)\n if not table_content:\n continue\n table_caption = (\n table_content.replace(\"|\", \"\").replace(\"---\", \"\")\n + f\"\\n(Table in Page {page_number}. {title})\"\n )\n tables.append((page_number, table_content, table_caption))\n\n elif re.search(self.figure_regex, item_path):\n figure_caption = (\n item_text + f\"\\n(Figure in Page {page_number}. {title})\"\n )\n figure_content = parse_figure_paths(file_paths)\n if not figure_content:\n continue\n figures.append([page_number, figure_content, figure_caption])\n\n else:\n if item_text and \"Table\" not in item_path and \"Figure\" not in item_path:\n texts[page_number].append(item_text)\n\n # get figure caption using GPT-4V\n figure_captions = generate_figure_captions(\n self.vlm_endpoint,\n [item[1] for item in figures],\n self.max_figures_to_caption,\n )\n for item, caption in zip(figures, figure_captions):\n # update figure caption\n item[2] += \" \" + caption\n\n # Wrap elements with Document\n documents = []\n\n # join plain text elements\n for page_number, txts in texts.items():\n documents.append(\n Document(\n text=\"\\n\".join(txts),\n metadata={\n \"page_label\": page_number,\n \"file_name\": filename,\n \"file_path\": filepath,\n },\n )\n )\n\n # table elements\n for page_number, table_content, table_caption in tables:\n documents.append(\n Document(\n text=table_content,\n metadata={\n \"table_origin\": table_content,\n \"type\": \"table\",\n \"page_label\": page_number,\n \"file_name\": filename,\n \"file_path\": filepath,\n },\n metadata_template=\"\",\n metadata_seperator=\"\",\n )\n )\n\n # figure elements\n for page_number, figure_content, figure_caption in figures:\n documents.append(\n Document(\n text=figure_caption,\n metadata={\n \"image_origin\": figure_content,\n \"type\": \"image\",\n \"page_label\": page_number,\n \"file_name\": filename,\n \"file_path\": filepath,\n },\n metadata_template=\"\",\n metadata_seperator=\"\",\n )\n )\n return documents\n
General auto reader for a variety of files. (based on llama-hub)
Source code in libs/kotaemon/kotaemon/loaders/base.py
class AutoReader(BaseReader):\n \"\"\"General auto reader for a variety of files. (based on llama-hub)\"\"\"\n\n def __init__(self, reader_type: Union[str, Type[\"LIBaseReader\"]]) -> None:\n \"\"\"Init reader using string identifier or class name from llama-hub\"\"\"\n\n if isinstance(reader_type, str):\n from llama_index.core import download_loader\n\n self._reader = download_loader(reader_type)()\n else:\n self._reader = reader_type()\n super().__init__()\n\n def load_data(self, file: Union[Path, str], **kwargs: Any) -> List[Document]:\n documents = self._reader.load_data(file=file, **kwargs)\n\n # convert Document to new base class from kotaemon\n converted_documents = [Document.from_dict(doc.to_dict()) for doc in documents]\n return converted_documents\n\n def run(self, file: Union[Path, str], **kwargs: Any) -> List[Document]:\n return self.load_data(file=file, **kwargs)\n
Source code in libs/kotaemon/kotaemon/loaders/base.py
class LIReaderMixin(BaseComponent):\n \"\"\"Base wrapper around llama-index reader\n\n To use the LIBaseReader, you need to implement the _get_wrapped_class method to\n return the relevant llama-index reader class that you want to wrap.\n\n Example:\n\n ```python\n class DirectoryReader(LIBaseReader):\n def _get_wrapped_class(self) -> Type[\"BaseReader\"]:\n from llama_index import SimpleDirectoryReader\n\n return SimpleDirectoryReader\n ```\n \"\"\"\n\n def _get_wrapped_class(self) -> Type[\"LIBaseReader\"]:\n raise NotImplementedError(\n \"Please return the relevant llama-index class in in _get_wrapped_class\"\n )\n\n def __init__(self, *args, **kwargs):\n self._reader_class = self._get_wrapped_class()\n self._reader = self._reader_class(*args, **kwargs)\n super().__init__()\n\n def __setattr__(self, name: str, value: Any) -> None:\n if name.startswith(\"_\"):\n return super().__setattr__(name, value)\n\n return setattr(self._reader, name, value)\n\n def __getattr__(self, name: str) -> Any:\n return getattr(self._reader, name)\n\n def load_data(self, *args, **kwargs: Any) -> List[Document]:\n documents = self._reader.load_data(*args, **kwargs)\n\n # convert Document to new base class from kotaemon\n converted_documents = [Document.from_dict(doc.to_dict()) for doc in documents]\n return converted_documents\n\n def run(self, *args, **kwargs: Any) -> List[Document]:\n return self.load_data(*args, **kwargs)\n
A mapping of file extension to a BaseReader class that specifies how to convert that file to text. If not specified, use default from DEFAULT_FILE_READER_CLS.
A function that takes in a filename and returns a Dict of metadata for the Document. Default is None.
required Source code in libs/kotaemon/kotaemon/loaders/composite_loader.py
class DirectoryReader(LIReaderMixin, BaseReader):\n \"\"\"Wrap around llama-index SimpleDirectoryReader\n\n Args:\n input_dir (str): Path to the directory.\n input_files (List): List of file paths to read\n (Optional; overrides input_dir, exclude)\n exclude (List): glob of python file paths to exclude (Optional)\n exclude_hidden (bool): Whether to exclude hidden files (dotfiles).\n encoding (str): Encoding of the files.\n Default is utf-8.\n errors (str): how encoding and decoding errors are to be handled,\n see https://docs.python.org/3/library/functions.html#open\n recursive (bool): Whether to recursively search in subdirectories.\n False by default.\n filename_as_id (bool): Whether to use the filename as the document id.\n False by default.\n required_exts (Optional[List[str]]): List of required extensions.\n Default is None.\n file_extractor (Optional[Dict[str, BaseReader]]): A mapping of file\n extension to a BaseReader class that specifies how to convert that file\n to text. If not specified, use default from DEFAULT_FILE_READER_CLS.\n num_files_limit (Optional[int]): Maximum number of files to read.\n Default is None.\n file_metadata (Optional[Callable[str, Dict]]): A function that takes\n in a filename and returns a Dict of metadata for the Document.\n Default is None.\n \"\"\"\n\n input_dir: Optional[str] = None\n input_files: Optional[List] = None\n exclude: Optional[List] = None\n exclude_hidden: bool = True\n errors: str = \"ignore\"\n recursive: bool = False\n encoding: str = \"utf-8\"\n filename_as_id: bool = False\n required_exts: Optional[list[str]] = None\n file_extractor: Optional[dict[str, \"LIBaseReader\"]] = None\n num_files_limit: Optional[int] = None\n file_metadata: Optional[Callable[[str], dict]] = None\n\n def _get_wrapped_class(self) -> Type[\"LIBaseReader\"]:\n from llama_index.core import SimpleDirectoryReader\n\n return SimpleDirectoryReader\n
Read Docx files that respect table, using python-docx library
Reader behavior
All paragraphs are extracted as a Document
Each table is extracted as a Document, rendered as a CSV string
The output is a list of Documents, concatenating the above (tables + paragraphs)
Source code in libs/kotaemon/kotaemon/loaders/docx_loader.py
class DocxReader(BaseReader):\n \"\"\"Read Docx files that respect table, using python-docx library\n\n Reader behavior:\n - All paragraphs are extracted as a Document\n - Each table is extracted as a Document, rendered as a CSV string\n - The output is a list of Documents, concatenating the above\n (tables + paragraphs)\n \"\"\"\n\n def __init__(self, *args, **kwargs):\n try:\n import docx # noqa\n except ImportError:\n raise ImportError(\n \"docx is not installed. \"\n \"Please install it using `pip install python-docx`\"\n )\n\n def _load_single_table(self, table) -> List[List[str]]:\n \"\"\"Extract content from tables. Return a list of columns: list[str]\n Some merged cells will share duplicated content.\n \"\"\"\n n_row = len(table.rows)\n n_col = len(table.columns)\n\n arrays = [[\"\" for _ in range(n_row)] for _ in range(n_col)]\n\n for i, row in enumerate(table.rows):\n for j, cell in enumerate(row.cells):\n arrays[j][i] = cell.text\n\n return arrays\n\n def load_data(\n self, file_path: Path, extra_info: Optional[dict] = None, **kwargs\n ) -> List[Document]:\n \"\"\"Load data using Docx reader\n\n Args:\n file_path (Path): Path to .docx file\n\n Returns:\n List[Document]: list of documents extracted from the HTML file\n \"\"\"\n import docx\n\n file_path = Path(file_path).resolve()\n\n doc = docx.Document(str(file_path))\n all_text = \"\\n\".join(\n [unicodedata.normalize(\"NFKC\", p.text) for p in doc.paragraphs]\n )\n pages = [all_text] # 1 page only\n\n tables = []\n for t in doc.tables:\n # return list of columns: list of string\n arrays = self._load_single_table(t)\n\n tables.append(pd.DataFrame({a[0]: a[1:] for a in arrays}))\n\n extra_info = extra_info or {}\n\n # create output Document with metadata from table\n documents = [\n Document(\n text=table.to_csv(\n index=False\n ).strip(), # strip_special_chars_markdown()\n metadata={\n \"table_origin\": table.to_csv(index=False),\n \"type\": \"table\",\n **extra_info,\n },\n metadata_template=\"\",\n metadata_seperator=\"\",\n )\n for table in tables # page_id\n ]\n\n # create Document from non-table text\n documents.extend(\n [\n Document(\n text=non_table_text.strip(),\n metadata={\"page_label\": 1, **extra_info},\n )\n for _, non_table_text in enumerate(pages)\n ]\n )\n\n return documents\n
Parses CSVs using the separator detection from Pandas read_csv function. If special parameters are required, use the pandas_config dict.
Args:
pandas_config (dict): Options for the `pandas.read_excel` function call.\n Refer to https://pandas.pydata.org/docs/reference/api/pandas.read_excel.html\n for more information. Set to empty dict by default,\n this means defaults will be used.\n
Source code in libs/kotaemon/kotaemon/loaders/excel_loader.py
class PandasExcelReader(BaseReader):\n r\"\"\"Pandas-based CSV parser.\n\n Parses CSVs using the separator detection from Pandas `read_csv` function.\n If special parameters are required, use the `pandas_config` dict.\n\n Args:\n\n pandas_config (dict): Options for the `pandas.read_excel` function call.\n Refer to https://pandas.pydata.org/docs/reference/api/pandas.read_excel.html\n for more information. Set to empty dict by default,\n this means defaults will be used.\n\n \"\"\"\n\n def __init__(\n self,\n *args: Any,\n pandas_config: Optional[dict] = None,\n row_joiner: str = \"\\n\",\n col_joiner: str = \" \",\n **kwargs: Any,\n ) -> None:\n \"\"\"Init params.\"\"\"\n super().__init__(*args, **kwargs)\n self._pandas_config = pandas_config or {}\n self._row_joiner = row_joiner if row_joiner else \"\\n\"\n self._col_joiner = col_joiner if col_joiner else \" \"\n\n def load_data(\n self,\n file: Path,\n include_sheetname: bool = False,\n sheet_name: Optional[Union[str, int, list]] = None,\n extra_info: Optional[dict] = None,\n **kwargs,\n ) -> List[Document]:\n \"\"\"Parse file and extract values from a specific column.\n\n Args:\n file (Path): The path to the Excel file to read.\n include_sheetname (bool): Whether to include the sheet name in the output.\n sheet_name (Union[str, int, None]): The specific sheet to read from,\n default is None which reads all sheets.\n\n Returns:\n List[Document]: A list of`Document objects containing the\n values from the specified column in the Excel file.\n \"\"\"\n import itertools\n\n try:\n import pandas as pd\n except ImportError:\n raise ImportError(\n \"install pandas using `pip3 install pandas` to use this loader\"\n )\n\n if sheet_name is not None:\n sheet_name = (\n [sheet_name] if not isinstance(sheet_name, list) else sheet_name\n )\n\n dfs = pd.read_excel(file, sheet_name=sheet_name, **self._pandas_config)\n sheet_names = dfs.keys()\n df_sheets = []\n\n for key in sheet_names:\n sheet = []\n if include_sheetname:\n sheet.append([key])\n dfs[key] = dfs[key].dropna(axis=0, how=\"all\")\n dfs[key] = dfs[key].dropna(axis=0, how=\"all\")\n dfs[key].fillna(\"\", inplace=True)\n sheet.extend(dfs[key].values.astype(str).tolist())\n df_sheets.append(sheet)\n\n text_list = list(\n itertools.chain.from_iterable(df_sheets)\n ) # flatten list of lists\n\n output = [\n Document(\n text=self._row_joiner.join(\n self._col_joiner.join(sublist) for sublist in text_list\n ),\n metadata=extra_info or {},\n )\n ]\n\n return output\n
Parse file and extract values from a specific column.
Parameters:
Name Type Description Default filePath
The path to the Excel file to read.
required include_sheetnamebool
Whether to include the sheet name in the output.
Falsesheet_nameUnion[str, int, None]
The specific sheet to read from, default is None which reads all sheets.
None
Returns:
Type Description List[Document]
List[Document]: A list of`Document objects containing the values from the specified column in the Excel file.
Source code in libs/kotaemon/kotaemon/loaders/excel_loader.py
def load_data(\n self,\n file: Path,\n include_sheetname: bool = False,\n sheet_name: Optional[Union[str, int, list]] = None,\n extra_info: Optional[dict] = None,\n **kwargs,\n) -> List[Document]:\n \"\"\"Parse file and extract values from a specific column.\n\n Args:\n file (Path): The path to the Excel file to read.\n include_sheetname (bool): Whether to include the sheet name in the output.\n sheet_name (Union[str, int, None]): The specific sheet to read from,\n default is None which reads all sheets.\n\n Returns:\n List[Document]: A list of`Document objects containing the\n values from the specified column in the Excel file.\n \"\"\"\n import itertools\n\n try:\n import pandas as pd\n except ImportError:\n raise ImportError(\n \"install pandas using `pip3 install pandas` to use this loader\"\n )\n\n if sheet_name is not None:\n sheet_name = (\n [sheet_name] if not isinstance(sheet_name, list) else sheet_name\n )\n\n dfs = pd.read_excel(file, sheet_name=sheet_name, **self._pandas_config)\n sheet_names = dfs.keys()\n df_sheets = []\n\n for key in sheet_names:\n sheet = []\n if include_sheetname:\n sheet.append([key])\n dfs[key] = dfs[key].dropna(axis=0, how=\"all\")\n dfs[key] = dfs[key].dropna(axis=0, how=\"all\")\n dfs[key].fillna(\"\", inplace=True)\n sheet.extend(dfs[key].values.astype(str).tolist())\n df_sheets.append(sheet)\n\n text_list = list(\n itertools.chain.from_iterable(df_sheets)\n ) # flatten list of lists\n\n output = [\n Document(\n text=self._row_joiner.join(\n self._col_joiner.join(sublist) for sublist in text_list\n ),\n metadata=extra_info or {},\n )\n ]\n\n return output\n
Parses CSVs using the separator detection from Pandas read_csv function. If special parameters are required, use the pandas_config dict.
Args:
pandas_config (dict): Options for the `pandas.read_excel` function call.\n Refer to https://pandas.pydata.org/docs/reference/api/pandas.read_excel.html\n for more information. Set to empty dict by default,\n this means defaults will be used.\n
Source code in libs/kotaemon/kotaemon/loaders/excel_loader.py
class ExcelReader(BaseReader):\n r\"\"\"Spreadsheet exporter respecting multiple worksheets\n\n Parses CSVs using the separator detection from Pandas `read_csv` function.\n If special parameters are required, use the `pandas_config` dict.\n\n Args:\n\n pandas_config (dict): Options for the `pandas.read_excel` function call.\n Refer to https://pandas.pydata.org/docs/reference/api/pandas.read_excel.html\n for more information. Set to empty dict by default,\n this means defaults will be used.\n\n \"\"\"\n\n def __init__(\n self,\n *args: Any,\n pandas_config: Optional[dict] = None,\n row_joiner: str = \"\\n\",\n col_joiner: str = \" \",\n **kwargs: Any,\n ) -> None:\n \"\"\"Init params.\"\"\"\n super().__init__(*args, **kwargs)\n self._pandas_config = pandas_config or {}\n self._row_joiner = row_joiner if row_joiner else \"\\n\"\n self._col_joiner = col_joiner if col_joiner else \" \"\n\n def load_data(\n self,\n file: Path,\n include_sheetname: bool = True,\n sheet_name: Optional[Union[str, int, list]] = None,\n extra_info: Optional[dict] = None,\n **kwargs,\n ) -> List[Document]:\n \"\"\"Parse file and extract values from a specific column.\n\n Args:\n file (Path): The path to the Excel file to read.\n include_sheetname (bool): Whether to include the sheet name in the output.\n sheet_name (Union[str, int, None]): The specific sheet to read from,\n default is None which reads all sheets.\n\n Returns:\n List[Document]: A list of`Document objects containing the\n values from the specified column in the Excel file.\n \"\"\"\n\n try:\n import pandas as pd\n except ImportError:\n raise ImportError(\n \"install pandas using `pip3 install pandas` to use this loader\"\n )\n\n if sheet_name is not None:\n sheet_name = (\n [sheet_name] if not isinstance(sheet_name, list) else sheet_name\n )\n\n # clean up input\n file = Path(file)\n extra_info = extra_info or {}\n\n dfs = pd.read_excel(file, sheet_name=sheet_name, **self._pandas_config)\n sheet_names = dfs.keys()\n output = []\n\n for idx, key in enumerate(sheet_names):\n dfs[key] = dfs[key].dropna(axis=0, how=\"all\")\n dfs[key] = dfs[key].dropna(axis=0, how=\"all\")\n dfs[key] = dfs[key].astype(\"object\")\n dfs[key].fillna(\"\", inplace=True)\n\n rows = dfs[key].values.astype(str).tolist()\n content = self._row_joiner.join(\n self._col_joiner.join(row).strip() for row in rows\n ).strip()\n if include_sheetname:\n content = f\"(Sheet {key} of file {file.name})\\n{content}\"\n metadata = {\"page_label\": idx + 1, \"sheet_name\": key, **extra_info}\n output.append(Document(text=content, metadata=metadata))\n\n return output\n
Parse file and extract values from a specific column.
Parameters:
Name Type Description Default filePath
The path to the Excel file to read.
required include_sheetnamebool
Whether to include the sheet name in the output.
Truesheet_nameUnion[str, int, None]
The specific sheet to read from, default is None which reads all sheets.
None
Returns:
Type Description List[Document]
List[Document]: A list of`Document objects containing the values from the specified column in the Excel file.
Source code in libs/kotaemon/kotaemon/loaders/excel_loader.py
def load_data(\n self,\n file: Path,\n include_sheetname: bool = True,\n sheet_name: Optional[Union[str, int, list]] = None,\n extra_info: Optional[dict] = None,\n **kwargs,\n) -> List[Document]:\n \"\"\"Parse file and extract values from a specific column.\n\n Args:\n file (Path): The path to the Excel file to read.\n include_sheetname (bool): Whether to include the sheet name in the output.\n sheet_name (Union[str, int, None]): The specific sheet to read from,\n default is None which reads all sheets.\n\n Returns:\n List[Document]: A list of`Document objects containing the\n values from the specified column in the Excel file.\n \"\"\"\n\n try:\n import pandas as pd\n except ImportError:\n raise ImportError(\n \"install pandas using `pip3 install pandas` to use this loader\"\n )\n\n if sheet_name is not None:\n sheet_name = (\n [sheet_name] if not isinstance(sheet_name, list) else sheet_name\n )\n\n # clean up input\n file = Path(file)\n extra_info = extra_info or {}\n\n dfs = pd.read_excel(file, sheet_name=sheet_name, **self._pandas_config)\n sheet_names = dfs.keys()\n output = []\n\n for idx, key in enumerate(sheet_names):\n dfs[key] = dfs[key].dropna(axis=0, how=\"all\")\n dfs[key] = dfs[key].dropna(axis=0, how=\"all\")\n dfs[key] = dfs[key].astype(\"object\")\n dfs[key].fillna(\"\", inplace=True)\n\n rows = dfs[key].values.astype(str).tolist()\n content = self._row_joiner.join(\n self._col_joiner.join(row).strip() for row in rows\n ).strip()\n if include_sheetname:\n content = f\"(Sheet {key} of file {file.name})\\n{content}\"\n metadata = {\"page_label\": idx + 1, \"sheet_name\": key, **extra_info}\n output.append(Document(text=content, metadata=metadata))\n\n return output\n
All of the texts will be split by page_break_pattern
Each page is extracted as a Document
The output is a list of Documents
Parameters:
Name Type Description Default page_break_patternstr
Pattern to split the HTML into pages
None Source code in libs/kotaemon/kotaemon/loaders/html_loader.py
class HtmlReader(BaseReader):\n \"\"\"Reader HTML usimg html2text\n\n Reader behavior:\n - HTML is read with html2text.\n - All of the texts will be split by `page_break_pattern`\n - Each page is extracted as a Document\n - The output is a list of Documents\n\n Args:\n page_break_pattern (str): Pattern to split the HTML into pages\n \"\"\"\n\n def __init__(self, page_break_pattern: Optional[str] = None, *args, **kwargs):\n try:\n import html2text # noqa\n except ImportError:\n raise ImportError(\n \"html2text is not installed. \"\n \"Please install it using `pip install html2text`\"\n )\n\n self._page_break_pattern: Optional[str] = page_break_pattern\n super().__init__()\n\n def load_data(\n self, file_path: Path | str, extra_info: Optional[dict] = None, **kwargs\n ) -> list[Document]:\n \"\"\"Load data using Html reader\n\n Args:\n file_path: path to HTML file\n extra_info: extra information passed to this reader during extracting data\n\n Returns:\n list[Document]: list of documents extracted from the HTML file\n \"\"\"\n import html2text\n\n file_path = Path(file_path).resolve()\n\n with file_path.open(\"r\") as f:\n html_text = \"\".join([line[:-1] for line in f.readlines()])\n\n # read HTML\n all_text = html2text.html2text(html_text)\n pages = (\n all_text.split(self._page_break_pattern)\n if self._page_break_pattern\n else [all_text]\n )\n\n extra_info = extra_info or {}\n\n # create Document from non-table text\n documents = [\n Document(\n text=page.strip(),\n metadata={\"page_label\": page_id + 1, **extra_info},\n )\n for page_id, page in enumerate(pages)\n ]\n\n return documents\n
extra information passed to this reader during extracting data
None
Returns:
Type Description list[Document]
list[Document]: list of documents extracted from the HTML file
Source code in libs/kotaemon/kotaemon/loaders/html_loader.py
def load_data(\n self, file_path: Path | str, extra_info: Optional[dict] = None, **kwargs\n) -> list[Document]:\n \"\"\"Load data using Html reader\n\n Args:\n file_path: path to HTML file\n extra_info: extra information passed to this reader during extracting data\n\n Returns:\n list[Document]: list of documents extracted from the HTML file\n \"\"\"\n import html2text\n\n file_path = Path(file_path).resolve()\n\n with file_path.open(\"r\") as f:\n html_text = \"\".join([line[:-1] for line in f.readlines()])\n\n # read HTML\n all_text = html2text.html2text(html_text)\n pages = (\n all_text.split(self._page_break_pattern)\n if self._page_break_pattern\n else [all_text]\n )\n\n extra_info = extra_info or {}\n\n # create Document from non-table text\n documents = [\n Document(\n text=page.strip(),\n metadata={\"page_label\": page_id + 1, **extra_info},\n )\n for page_id, page in enumerate(pages)\n ]\n\n return documents\n
Source code in libs/kotaemon/kotaemon/loaders/html_loader.py
class MhtmlReader(BaseReader):\n \"\"\"Parse `MHTML` files with `BeautifulSoup`.\"\"\"\n\n def __init__(\n self,\n cache_dir: Optional[str] = getattr(\n flowsettings, \"KH_MARKDOWN_OUTPUT_DIR\", None\n ),\n open_encoding: Optional[str] = None,\n bs_kwargs: Optional[dict] = None,\n get_text_separator: str = \"\",\n ) -> None:\n \"\"\"initialize with path, and optionally, file encoding to use, and any kwargs\n to pass to the BeautifulSoup object.\n\n Args:\n cache_dir: Path for markdwon format.\n file_path: Path to file to load.\n open_encoding: The encoding to use when opening the file.\n bs_kwargs: Any kwargs to pass to the BeautifulSoup object.\n get_text_separator: The separator to use when getting the text\n from the soup.\n \"\"\"\n try:\n import bs4 # noqa:F401\n except ImportError:\n raise ImportError(\n \"beautifulsoup4 package not found, please install it with \"\n \"`pip install beautifulsoup4`\"\n )\n\n self.cache_dir = cache_dir\n self.open_encoding = open_encoding\n if bs_kwargs is None:\n bs_kwargs = {\"features\": \"lxml\"}\n self.bs_kwargs = bs_kwargs\n self.get_text_separator = get_text_separator\n\n def load_data(\n self, file_path: Path | str, extra_info: Optional[dict] = None, **kwargs\n ) -> list[Document]:\n \"\"\"Load MHTML document into document objects.\"\"\"\n\n from bs4 import BeautifulSoup\n\n extra_info = extra_info or {}\n metadata: dict = extra_info\n page = []\n file_name = Path(file_path)\n with open(file_path, \"r\", encoding=self.open_encoding) as f:\n message = email.message_from_string(f.read())\n parts = message.get_payload()\n\n if not isinstance(parts, list):\n parts = [message]\n\n for part in parts:\n if part.get_content_type() == \"text/html\":\n html = part.get_payload(decode=True).decode()\n\n soup = BeautifulSoup(html, **self.bs_kwargs)\n text = soup.get_text(self.get_text_separator)\n\n if soup.title:\n title = str(soup.title.string)\n else:\n title = \"\"\n\n metadata = {\n \"source\": str(file_path),\n \"title\": title,\n **extra_info,\n }\n lines = [line for line in text.split(\"\\n\") if line.strip()]\n text = \"\\n\\n\".join(lines)\n if text:\n page.append(text)\n # save the page into markdown format\n print(self.cache_dir)\n if self.cache_dir is not None:\n print(Path(self.cache_dir) / f\"{file_name.stem}.md\")\n with open(Path(self.cache_dir) / f\"{file_name.stem}.md\", \"w\") as f:\n f.write(page[0])\n\n return [Document(text=\"\\n\\n\".join(page), metadata=metadata)]\n
Source code in libs/kotaemon/kotaemon/loaders/html_loader.py
def load_data(\n self, file_path: Path | str, extra_info: Optional[dict] = None, **kwargs\n) -> list[Document]:\n \"\"\"Load MHTML document into document objects.\"\"\"\n\n from bs4 import BeautifulSoup\n\n extra_info = extra_info or {}\n metadata: dict = extra_info\n page = []\n file_name = Path(file_path)\n with open(file_path, \"r\", encoding=self.open_encoding) as f:\n message = email.message_from_string(f.read())\n parts = message.get_payload()\n\n if not isinstance(parts, list):\n parts = [message]\n\n for part in parts:\n if part.get_content_type() == \"text/html\":\n html = part.get_payload(decode=True).decode()\n\n soup = BeautifulSoup(html, **self.bs_kwargs)\n text = soup.get_text(self.get_text_separator)\n\n if soup.title:\n title = str(soup.title.string)\n else:\n title = \"\"\n\n metadata = {\n \"source\": str(file_path),\n \"title\": title,\n **extra_info,\n }\n lines = [line for line in text.split(\"\\n\") if line.strip()]\n text = \"\\n\\n\".join(lines)\n if text:\n page.append(text)\n # save the page into markdown format\n print(self.cache_dir)\n if self.cache_dir is not None:\n print(Path(self.cache_dir) / f\"{file_name.stem}.md\")\n with open(Path(self.cache_dir) / f\"{file_name.stem}.md\", \"w\") as f:\n f.write(page[0])\n\n return [Document(text=\"\\n\\n\".join(page), metadata=metadata)]\n
Source code in libs/kotaemon/kotaemon/loaders/mathpix_loader.py
def wait_for_processing(self, pdf_id: str) -> None:\n \"\"\"Wait for processing to complete.\n\n Args:\n pdf_id: a PDF id.\n\n Returns: None\n \"\"\"\n url = self.url + \"/\" + pdf_id\n for _ in range(0, self.max_wait_time_seconds, 5):\n response = requests.get(url, headers=self._mathpix_headers)\n response_data = response.json()\n status = response_data.get(\"status\", None)\n\n if status == \"completed\":\n return\n elif status == \"error\":\n raise ValueError(\"Unable to retrieve PDF from Mathpix\")\n else:\n print(response_data)\n print(url)\n time.sleep(5)\n raise TimeoutError\n
Name Type Description Default endpointOptional[str]
URL to FullOCR endpoint. If not provided, will look for environment variable OCR_READER_ENDPOINT or use the default kotaemon.loaders.ocr_loader.DEFAULT_OCR_ENDPOINT (http://127.0.0.1:8000/v2/ai/infer/)
Noneuse_ocr
whether to use OCR to read text (e.g: from images, tables) in the PDF If False, only the table and text within table cells will be extracted.
True Source code in libs/kotaemon/kotaemon/loaders/ocr_loader.py
class OCRReader(BaseReader):\n \"\"\"Read PDF using OCR, with high focus on table extraction\n\n Example:\n ```python\n >> from kotaemon.loaders import OCRReader\n >> reader = OCRReader()\n >> documents = reader.load_data(\"path/to/pdf\")\n ```\n\n Args:\n endpoint: URL to FullOCR endpoint. If not provided, will look for\n environment variable `OCR_READER_ENDPOINT` or use the default\n `kotaemon.loaders.ocr_loader.DEFAULT_OCR_ENDPOINT`\n (http://127.0.0.1:8000/v2/ai/infer/)\n use_ocr: whether to use OCR to read text (e.g: from images, tables) in the PDF\n If False, only the table and text within table cells will be extracted.\n \"\"\"\n\n def __init__(self, endpoint: Optional[str] = None, use_ocr=True):\n \"\"\"Init the OCR reader with OCR endpoint (FullOCR pipeline)\"\"\"\n super().__init__()\n self.ocr_endpoint = endpoint or os.getenv(\n \"OCR_READER_ENDPOINT\", DEFAULT_OCR_ENDPOINT\n )\n self.use_ocr = use_ocr\n\n def load_data(\n self, file_path: Path, extra_info: Optional[dict] = None, **kwargs\n ) -> List[Document]:\n \"\"\"Load data using OCR reader\n\n Args:\n file_path (Path): Path to PDF file\n debug_path (Path): Path to store debug image output\n artifact_path (Path): Path to OCR endpoints artifacts directory\n\n Returns:\n List[Document]: list of documents extracted from the PDF file\n \"\"\"\n file_path = Path(file_path).resolve()\n\n # call the API from FullOCR endpoint\n if \"response_content\" in kwargs:\n # overriding response content if specified\n ocr_results = kwargs[\"response_content\"]\n else:\n # call original API\n resp = tenacious_api_post(\n url=self.ocr_endpoint, file_path=file_path, table_only=not self.use_ocr\n )\n ocr_results = resp.json()[\"result\"]\n\n debug_path = kwargs.pop(\"debug_path\", None)\n artifact_path = kwargs.pop(\"artifact_path\", None)\n\n # read PDF through normal reader (unstructured)\n pdf_page_items = read_pdf_unstructured(file_path)\n # merge PDF text output with OCR output\n tables, texts = parse_ocr_output(\n ocr_results,\n pdf_page_items,\n debug_path=debug_path,\n artifact_path=artifact_path,\n )\n extra_info = extra_info or {}\n\n # create output Document with metadata from table\n documents = [\n Document(\n text=strip_special_chars_markdown(table_text),\n metadata={\n \"table_origin\": table_text,\n \"type\": \"table\",\n \"page_label\": page_id + 1,\n **extra_info,\n },\n metadata_template=\"\",\n metadata_seperator=\"\",\n )\n for page_id, table_text in tables\n ]\n # create Document from non-table text\n documents.extend(\n [\n Document(\n text=non_table_text,\n metadata={\"page_label\": page_id + 1, **extra_info},\n )\n for page_id, non_table_text in texts\n ]\n )\n\n return documents\n
Name Type Description Default endpointOptional[str]
URL to FullOCR endpoint. If not provided, will look for environment variable OCR_READER_ENDPOINT or use the default knowledgehub.loaders.ocr_loader.DEFAULT_OCR_ENDPOINT (http://127.0.0.1:8000/v2/ai/infer/)
Noneuse_ocr
whether to use OCR to read text (e.g: from images, tables) in the PDF If False, only the table and text within table cells will be extracted.
required Source code in libs/kotaemon/kotaemon/loaders/ocr_loader.py
class ImageReader(BaseReader):\n \"\"\"Read PDF using OCR, with high focus on table extraction\n\n Example:\n ```python\n >> from knowledgehub.loaders import OCRReader\n >> reader = OCRReader()\n >> documents = reader.load_data(\"path/to/pdf\")\n ```\n\n Args:\n endpoint: URL to FullOCR endpoint. If not provided, will look for\n environment variable `OCR_READER_ENDPOINT` or use the default\n `knowledgehub.loaders.ocr_loader.DEFAULT_OCR_ENDPOINT`\n (http://127.0.0.1:8000/v2/ai/infer/)\n use_ocr: whether to use OCR to read text (e.g: from images, tables) in the PDF\n If False, only the table and text within table cells will be extracted.\n \"\"\"\n\n def __init__(self, endpoint: Optional[str] = None):\n \"\"\"Init the OCR reader with OCR endpoint (FullOCR pipeline)\"\"\"\n super().__init__()\n self.ocr_endpoint = endpoint or os.getenv(\n \"OCR_READER_ENDPOINT\", DEFAULT_OCR_ENDPOINT\n )\n\n def load_data(\n self, file_path: Path, extra_info: Optional[dict] = None, **kwargs\n ) -> List[Document]:\n \"\"\"Load data using OCR reader\n\n Args:\n file_path (Path): Path to PDF file\n debug_path (Path): Path to store debug image output\n artifact_path (Path): Path to OCR endpoints artifacts directory\n\n Returns:\n List[Document]: list of documents extracted from the PDF file\n \"\"\"\n file_path = Path(file_path).resolve()\n\n # call the API from FullOCR endpoint\n if \"response_content\" in kwargs:\n # overriding response content if specified\n ocr_results = kwargs[\"response_content\"]\n else:\n # call original API\n resp = tenacious_api_post(\n url=self.ocr_endpoint, file_path=file_path, table_only=False\n )\n ocr_results = resp.json()[\"result\"]\n\n extra_info = extra_info or {}\n result = []\n for ocr_result in ocr_results:\n result.append(\n Document(\n content=ocr_result[\"csv_string\"],\n metadata=extra_info,\n )\n )\n\n return result\n
List[Document]: list of documents extracted from the PDF file
Source code in libs/kotaemon/kotaemon/loaders/ocr_loader.py
def load_data(\n self, file_path: Path, extra_info: Optional[dict] = None, **kwargs\n) -> List[Document]:\n \"\"\"Load data using OCR reader\n\n Args:\n file_path (Path): Path to PDF file\n debug_path (Path): Path to store debug image output\n artifact_path (Path): Path to OCR endpoints artifacts directory\n\n Returns:\n List[Document]: list of documents extracted from the PDF file\n \"\"\"\n file_path = Path(file_path).resolve()\n\n # call the API from FullOCR endpoint\n if \"response_content\" in kwargs:\n # overriding response content if specified\n ocr_results = kwargs[\"response_content\"]\n else:\n # call original API\n resp = tenacious_api_post(\n url=self.ocr_endpoint, file_path=file_path, table_only=False\n )\n ocr_results = resp.json()[\"result\"]\n\n extra_info = extra_info or {}\n result = []\n for ocr_result in ocr_results:\n result.append(\n Document(\n content=ocr_result[\"csv_string\"],\n metadata=extra_info,\n )\n )\n\n return result\n
General unstructured text reader for a variety of files.
Source code in libs/kotaemon/kotaemon/loaders/unstructured_loader.py
class UnstructuredReader(BaseReader):\n \"\"\"General unstructured text reader for a variety of files.\"\"\"\n\n def __init__(self, *args: Any, **kwargs: Any) -> None:\n \"\"\"Init params.\"\"\"\n super().__init__(*args) # not passing kwargs to parent bc it cannot accept it\n\n self.api = False # we default to local\n if \"url\" in kwargs:\n self.server_url = str(kwargs[\"url\"])\n self.api = True # is url was set, switch to api\n else:\n self.server_url = \"http://localhost:8000\"\n\n if \"api\" in kwargs:\n self.api = kwargs[\"api\"]\n\n self.api_key = \"\"\n if \"api_key\" in kwargs:\n self.api_key = kwargs[\"api_key\"]\n\n \"\"\" Loads data using Unstructured.io\n\n Depending on the construction if url is set or api = True\n it'll parse file using API call, else parse it locally\n additional_metadata is extended by the returned metadata if\n split_documents is True\n\n Returns list of documents\n \"\"\"\n\n def load_data(\n self,\n file: Path,\n extra_info: Optional[Dict] = None,\n split_documents: Optional[bool] = False,\n **kwargs,\n ) -> List[Document]:\n \"\"\"If api is set, parse through api\"\"\"\n file_path_str = str(file)\n if self.api:\n from unstructured.partition.api import partition_via_api\n\n elements = partition_via_api(\n filename=file_path_str,\n api_key=self.api_key,\n api_url=self.server_url + \"/general/v0/general\",\n )\n else:\n \"\"\"Parse file locally\"\"\"\n from unstructured.partition.auto import partition\n\n elements = partition(filename=file_path_str)\n\n \"\"\" Process elements \"\"\"\n docs = []\n file_name = Path(file).name\n file_path = str(Path(file).resolve())\n if split_documents:\n for node in elements:\n metadata = {\"file_name\": file_name, \"file_path\": file_path}\n if hasattr(node, \"metadata\"):\n \"\"\"Load metadata fields\"\"\"\n for field, val in vars(node.metadata).items():\n if field == \"_known_field_names\":\n continue\n # removing coordinates because it does not serialize\n # and dont want to bother with it\n if field == \"coordinates\":\n continue\n # removing bc it might cause interference\n if field == \"parent_id\":\n continue\n metadata[field] = val\n\n if extra_info is not None:\n metadata.update(extra_info)\n\n metadata[\"file_name\"] = file_name\n docs.append(Document(text=node.text, metadata=metadata))\n\n else:\n text_chunks = [\" \".join(str(el).split()) for el in elements]\n metadata = {\"file_name\": file_name, \"file_path\": file_path}\n\n if extra_info is not None:\n metadata.update(extra_info)\n\n # Create a single document by joining all the texts\n docs.append(Document(text=\"\\n\\n\".join(text_chunks), metadata=metadata))\n\n return docs\n
Source code in libs/kotaemon/kotaemon/loaders/unstructured_loader.py
def load_data(\n self,\n file: Path,\n extra_info: Optional[Dict] = None,\n split_documents: Optional[bool] = False,\n **kwargs,\n) -> List[Document]:\n \"\"\"If api is set, parse through api\"\"\"\n file_path_str = str(file)\n if self.api:\n from unstructured.partition.api import partition_via_api\n\n elements = partition_via_api(\n filename=file_path_str,\n api_key=self.api_key,\n api_url=self.server_url + \"/general/v0/general\",\n )\n else:\n \"\"\"Parse file locally\"\"\"\n from unstructured.partition.auto import partition\n\n elements = partition(filename=file_path_str)\n\n \"\"\" Process elements \"\"\"\n docs = []\n file_name = Path(file).name\n file_path = str(Path(file).resolve())\n if split_documents:\n for node in elements:\n metadata = {\"file_name\": file_name, \"file_path\": file_path}\n if hasattr(node, \"metadata\"):\n \"\"\"Load metadata fields\"\"\"\n for field, val in vars(node.metadata).items():\n if field == \"_known_field_names\":\n continue\n # removing coordinates because it does not serialize\n # and dont want to bother with it\n if field == \"coordinates\":\n continue\n # removing bc it might cause interference\n if field == \"parent_id\":\n continue\n metadata[field] = val\n\n if extra_info is not None:\n metadata.update(extra_info)\n\n metadata[\"file_name\"] = file_name\n docs.append(Document(text=node.text, metadata=metadata))\n\n else:\n text_chunks = [\" \".join(str(el).split()) for el in elements]\n metadata = {\"file_name\": file_name, \"file_path\": file_path}\n\n if extra_info is not None:\n metadata.update(extra_info)\n\n # Create a single document by joining all the texts\n docs.append(Document(text=\"\\n\\n\".join(text_chunks), metadata=metadata))\n\n return docs\n
Main function to call the adobe service, and unzip the results. Args: file_path (str): path to the pdf file output_path (str): path to store the results
Returns:
Name Type Description output_pathstr
path to the results
Source code in libs/kotaemon/kotaemon/loaders/utils/adobe.py
def request_adobe_service(file_path: str, output_path: str = \"\") -> str:\n \"\"\"Main function to call the adobe service, and unzip the results.\n Args:\n file_path (str): path to the pdf file\n output_path (str): path to store the results\n\n Returns:\n output_path (str): path to the results\n\n \"\"\"\n try:\n from adobe.pdfservices.operation.auth.credentials import Credentials\n from adobe.pdfservices.operation.exception.exceptions import (\n SdkException,\n ServiceApiException,\n ServiceUsageException,\n )\n from adobe.pdfservices.operation.execution_context import ExecutionContext\n from adobe.pdfservices.operation.io.file_ref import FileRef\n from adobe.pdfservices.operation.pdfops.extract_pdf_operation import (\n ExtractPDFOperation,\n )\n from adobe.pdfservices.operation.pdfops.options.extractpdf.extract_element_type import ( # noqa: E501\n ExtractElementType,\n )\n from adobe.pdfservices.operation.pdfops.options.extractpdf.extract_pdf_options import ( # noqa: E501\n ExtractPDFOptions,\n )\n from adobe.pdfservices.operation.pdfops.options.extractpdf.extract_renditions_element_type import ( # noqa: E501\n ExtractRenditionsElementType,\n )\n except ImportError:\n raise ImportError(\n \"pdfservices-sdk is not installed. \"\n \"Please install it by running `pip install pdfservices-sdk\"\n \"@git+https://github.com/niallcm/pdfservices-python-sdk.git\"\n \"@bump-and-unfreeze-requirements`\"\n )\n\n if not output_path:\n output_path = tempfile.mkdtemp()\n\n try:\n # Initial setup, create credentials instance.\n credentials = (\n Credentials.service_principal_credentials_builder()\n .with_client_id(config(\"PDF_SERVICES_CLIENT_ID\", default=\"\"))\n .with_client_secret(config(\"PDF_SERVICES_CLIENT_SECRET\", default=\"\"))\n .build()\n )\n\n # Create an ExecutionContext using credentials\n # and create a new operation instance.\n execution_context = ExecutionContext.create(credentials)\n extract_pdf_operation = ExtractPDFOperation.create_new()\n\n # Set operation input from a source file.\n source = FileRef.create_from_local_file(file_path)\n extract_pdf_operation.set_input(source)\n\n # Build ExtractPDF options and set them into the operation\n extract_pdf_options: ExtractPDFOptions = (\n ExtractPDFOptions.builder()\n .with_elements_to_extract(\n [ExtractElementType.TEXT, ExtractElementType.TABLES]\n )\n .with_elements_to_extract_renditions(\n [\n ExtractRenditionsElementType.TABLES,\n ExtractRenditionsElementType.FIGURES,\n ]\n )\n .build()\n )\n extract_pdf_operation.set_options(extract_pdf_options)\n\n # Execute the operation.\n result: FileRef = extract_pdf_operation.execute(execution_context)\n\n # Save the result to the specified location.\n zip_file_path = os.path.join(\n output_path, \"ExtractTextTableWithFigureTableRendition.zip\"\n )\n result.save_as(zip_file_path)\n # Open the ZIP file\n with zipfile.ZipFile(zip_file_path, \"r\") as zip_ref:\n # Extract all contents to the destination folder\n zip_ref.extractall(output_path)\n except (ServiceApiException, ServiceUsageException, SdkException):\n logging.exception(\"Exception encountered while executing operation\")\n\n return output_path\n
Convert table from python list representation to markdown format. The input list consists of rows of tables, the first row is the header.
Parameters:
Name Type Description Default table_as_listList[str]
list of table rows Example: [[\"Name\", \"Age\", \"Height\"], [\"Jake\", 20, 5'10], [\"Mary\", 21, 5'7]]
required
Returns: markdown representation of the table
Source code in libs/kotaemon/kotaemon/loaders/utils/adobe.py
def make_markdown_table(table_as_list: List[str]) -> str:\n \"\"\"\n Convert table from python list representation to markdown format.\n The input list consists of rows of tables, the first row is the header.\n\n Args:\n table_as_list: list of table rows\n Example: [[\"Name\", \"Age\", \"Height\"],\n [\"Jake\", 20, 5'10],\n [\"Mary\", 21, 5'7]]\n Returns:\n markdown representation of the table\n \"\"\"\n markdown = \"\\n\" + str(\"| \")\n\n for e in table_as_list[0]:\n to_add = \" \" + str(e) + str(\" |\")\n markdown += to_add\n markdown += \"\\n\"\n\n markdown += \"| \"\n for i in range(len(table_as_list[0])):\n markdown += str(\"--- | \")\n markdown += \"\\n\"\n\n for entry in table_as_list[1:]:\n markdown += str(\"| \")\n for e in entry:\n to_add = str(e) + str(\" | \")\n markdown += to_add\n markdown += \"\\n\"\n\n return markdown + \"\\n\"\n
Source code in libs/kotaemon/kotaemon/loaders/utils/adobe.py
def load_excel(input_path: Union[str | Path]) -> str:\n \"\"\"Load excel file and convert to markdown\"\"\"\n\n df = pd.read_excel(input_path).fillna(\"\")\n # Convert dataframe to a list of rows\n row_list = [df.columns.values.tolist()] + df.values.tolist()\n\n for item_id, item in enumerate(row_list[0]):\n if \"Unnamed\" in item:\n row_list[0][item_id] = \"\"\n\n for row in row_list:\n for item_id, item in enumerate(row):\n row[item_id] = str(item).replace(\"_x000D_\", \" \").replace(\"\\n\", \" \").strip()\n\n markdown_str = make_markdown_table(row_list)\n return markdown_str\n
Read the table stored in an excel file given the file path
Source code in libs/kotaemon/kotaemon/loaders/utils/adobe.py
def parse_table_paths(file_paths: List[Path]) -> str:\n \"\"\"Read the table stored in an excel file given the file path\"\"\"\n\n content = \"\"\n for path in file_paths:\n if path.suffix == \".xlsx\":\n content = load_excel(path)\n break\n return content\n
Read and convert an image to base64 given the image path
Source code in libs/kotaemon/kotaemon/loaders/utils/adobe.py
def parse_figure_paths(file_paths: List[Path]) -> Union[bytes, str]:\n \"\"\"Read and convert an image to base64 given the image path\"\"\"\n\n content = \"\"\n for path in file_paths:\n if path.suffix == \".png\":\n base64_image = encode_image_base64(path)\n content = f\"data:image/png;base64,{base64_image}\" # type: ignore\n break\n return content\n
Source code in libs/kotaemon/kotaemon/loaders/utils/adobe.py
def generate_single_figure_caption(vlm_endpoint: str, figure: str) -> str:\n \"\"\"Summarize a single figure using GPT-4V\"\"\"\n if figure:\n output = generate_gpt4v(\n endpoint=vlm_endpoint,\n prompt=\"Provide a short 2 sentence summary of this image?\",\n images=figure,\n )\n if \"sorry\" in output.lower():\n output = \"\"\n else:\n output = \"\"\n return output\n
Summarize several figures using GPT-4V. Args: vlm_endpoint (str): endpoint to the vision language model service figures (List): list of base64 images max_figures_to_process (int): the maximum number of figures will be summarized, the rest are ignored.
Returns:
Name Type Description resultsList[str]
list of all figure captions and empty strings for
List
ignored figures.
Source code in libs/kotaemon/kotaemon/loaders/utils/adobe.py
def generate_figure_captions(\n vlm_endpoint: str, figures: List, max_figures_to_process: int\n) -> List:\n \"\"\"Summarize several figures using GPT-4V.\n Args:\n vlm_endpoint (str): endpoint to the vision language model service\n figures (List): list of base64 images\n max_figures_to_process (int): the maximum number of figures will be summarized,\n the rest are ignored.\n\n Returns:\n results (List[str]): list of all figure captions and empty strings for\n ignored figures.\n \"\"\"\n to_gen_figures = figures[:max_figures_to_process]\n other_figures = figures[max_figures_to_process:]\n\n with ThreadPoolExecutor() as executor:\n futures = [\n executor.submit(\n lambda: generate_single_figure_caption(vlm_endpoint, figure)\n )\n for figure in to_gen_figures\n ]\n\n results = [future.result() for future in futures]\n return results + [\"\"] * len(other_figures)\n
Source code in libs/kotaemon/kotaemon/loaders/utils/box.py
def points_to_bbox(points: List[Tuple[int, int]]):\n \"\"\"Convert list of points to bounding box\"\"\"\n all_x = [p[0] for p in points]\n all_y = [p[1] for p in points]\n return [min(all_x), min(all_y), max(all_x), max(all_y)]\n
Source code in libs/kotaemon/kotaemon/loaders/utils/box.py
def union_points(points: List[Tuple[int, int]]):\n \"\"\"Return union bounding box of list of points\"\"\"\n all_x = [p[0] for p in points]\n all_y = [p[1] for p in points]\n bbox = (min(all_x), min(all_y), max(all_x), max(all_y))\n return bbox\n
Sort cell list to create the right reading order using their locations
Parameters:
Name Type Description Default linesList[dict]
list of cells to sort
required
Returns:
Type Description
a list of cell lists in the right reading order that contain
no key or start with a key and contain no other key
Source code in libs/kotaemon/kotaemon/loaders/utils/box.py
def sort_funsd_reading_order(lines: List[dict], box_key_name: str = \"box\"):\n \"\"\"Sort cell list to create the right reading order using their locations\n\n Args:\n lines: list of cells to sort\n\n Returns:\n a list of cell lists in the right reading order that contain\n no key or start with a key and contain no other key\n \"\"\"\n sorted_list = []\n\n if len(lines) == 0:\n return lines\n\n while len(lines) > 1:\n topleft_line = lines[0]\n for line in lines[1:]:\n topleft_line_pos = topleft_line[box_key_name]\n topleft_line_center_y = (topleft_line_pos[1] + topleft_line_pos[3]) / 2\n x1, y1, x2, y2 = line[box_key_name]\n box_center_x = (x1 + x2) / 2\n box_center_y = (y1 + y2) / 2\n cell_h = y2 - y1\n if box_center_y <= topleft_line_center_y - cell_h / 2:\n topleft_line = line\n continue\n if (\n box_center_x < topleft_line_pos[2]\n and box_center_y < topleft_line_pos[3]\n ):\n topleft_line = line\n continue\n sorted_list.append(topleft_line)\n lines.remove(topleft_line)\n\n sorted_list.append(lines[0])\n\n return sorted_list\n
Merge PDF and OCR text using IOU overlapping location Args: ocr_list: List of OCR items {\"text\", \"box\", \"location\"} pdf_text_list: List of PDF items {\"text\", \"box\", \"location\"}
Returns:
Type Description
Combined list of PDF text and non-overlap OCR text
Source code in libs/kotaemon/kotaemon/loaders/utils/pdf_ocr.py
def merge_ocr_and_pdf_texts(\n ocr_list: List[dict], pdf_text_list: List[dict], debug_info=None\n):\n \"\"\"Merge PDF and OCR text using IOU overlapping location\n Args:\n ocr_list: List of OCR items {\"text\", \"box\", \"location\"}\n pdf_text_list: List of PDF items {\"text\", \"box\", \"location\"}\n\n Returns:\n Combined list of PDF text and non-overlap OCR text\n \"\"\"\n not_matched_ocr = []\n\n # check for debug info\n if debug_info is not None:\n cv2, debug_im = debug_info\n\n for ocr_item in ocr_list:\n matched = False\n for pdf_item in pdf_text_list:\n if (\n get_rect_iou(ocr_item[\"location\"], pdf_item[\"location\"], iou_type=1)\n > IOU_THRES\n ):\n matched = True\n break\n\n color = (255, 0, 0)\n if not matched:\n ocr_item[\"matched\"] = False\n not_matched_ocr.append(ocr_item)\n color = (0, 255, 255)\n\n if debug_info is not None:\n cv2.rectangle(\n debug_im,\n ocr_item[\"location\"][0],\n ocr_item[\"location\"][2],\n color=color,\n thickness=1,\n )\n\n if debug_info is not None:\n for pdf_item in pdf_text_list:\n cv2.rectangle(\n debug_im,\n pdf_item[\"location\"][0],\n pdf_item[\"location\"][2],\n color=(0, 255, 0),\n thickness=2,\n )\n\n return pdf_text_list + not_matched_ocr\n
Merge table items with OCR text using IOU overlapping location Args: table_list: List of table items \"type\": (\"table\", \"cell\", \"text\"), \"text\", \"box\", \"location\"} ocr_list: List of OCR items {\"text\", \"box\", \"location\"} pdf_list: List of PDF items {\"text\", \"box\", \"location\"}
Returns:
Name Type Description all_table_cells
List of tables, each of table is represented by list of cells with combined text from OCR
not_matched_items
List of PDF text which is not overlapped by table region
Source code in libs/kotaemon/kotaemon/loaders/utils/pdf_ocr.py
def merge_table_cell_and_ocr(\n table_list: List[dict], ocr_list: List[dict], pdf_list: List[dict], debug_info=None\n):\n \"\"\"Merge table items with OCR text using IOU overlapping location\n Args:\n table_list: List of table items\n \"type\": (\"table\", \"cell\", \"text\"), \"text\", \"box\", \"location\"}\n ocr_list: List of OCR items {\"text\", \"box\", \"location\"}\n pdf_list: List of PDF items {\"text\", \"box\", \"location\"}\n\n Returns:\n all_table_cells: List of tables, each of table is represented\n by list of cells with combined text from OCR\n not_matched_items: List of PDF text which is not overlapped by table region\n \"\"\"\n # check for debug info\n if debug_info is not None:\n cv2, debug_im = debug_info\n\n cell_list = [item for item in table_list if item[\"type\"] == \"cell\"]\n table_list = [item for item in table_list if item[\"type\"] == \"table\"]\n\n # sort table by area\n table_list = sorted(table_list, key=lambda item: box_area(item[\"bbox\"]))\n\n all_tables = []\n matched_pdf_ids = []\n matched_cell_ids = []\n\n for table in table_list:\n if debug_info is not None:\n cv2.rectangle(\n debug_im,\n table[\"location\"][0],\n table[\"location\"][2],\n color=[0, 0, 255],\n thickness=5,\n )\n\n cur_table_cells = []\n for cell_id, cell in enumerate(cell_list):\n if cell_id in matched_cell_ids:\n continue\n\n if get_rect_iou(\n table[\"location\"], cell[\"location\"], iou_type=1\n ) > IOU_THRES and box_area(table[\"bbox\"]) > box_area(cell[\"bbox\"]):\n color = [128, 0, 128]\n # cell matched to table\n for item_list, item_type in [(pdf_list, \"pdf\"), (ocr_list, \"ocr\")]:\n cell[\"ocr\"] = []\n for item_id, item in enumerate(item_list):\n if item_type == \"pdf\" and item_id in matched_pdf_ids:\n continue\n if (\n get_rect_iou(item[\"location\"], cell[\"location\"], iou_type=1)\n > IOU_THRES\n ):\n cell[\"ocr\"].append(item)\n if item_type == \"pdf\":\n matched_pdf_ids.append(item_id)\n\n if len(cell[\"ocr\"]) > 0:\n # check if union of matched ocr does\n # not extend over cell boundary,\n # if True, continue to use OCR_list to match\n all_box_points_in_cell = []\n for item in cell[\"ocr\"]:\n all_box_points_in_cell.extend(item[\"location\"])\n union_box = union_points(all_box_points_in_cell)\n cell_okay = (\n box_h(union_box) <= box_h(cell[\"bbox\"]) * PADDING_THRES\n and box_w(union_box) <= box_w(cell[\"bbox\"]) * PADDING_THRES\n )\n else:\n cell_okay = False\n\n if cell_okay:\n if item_type == \"pdf\":\n color = [255, 0, 255]\n break\n\n if debug_info is not None:\n cv2.rectangle(\n debug_im,\n cell[\"location\"][0],\n cell[\"location\"][2],\n color=color,\n thickness=3,\n )\n\n matched_cell_ids.append(cell_id)\n cur_table_cells.append(cell)\n\n all_tables.append(cur_table_cells)\n\n not_matched_items = [\n item for _id, item in enumerate(pdf_list) if _id not in matched_pdf_ids\n ]\n if debug_info is not None:\n for item in not_matched_items:\n cv2.rectangle(\n debug_im,\n item[\"location\"][0],\n item[\"location\"][2],\n color=[128, 128, 128],\n thickness=3,\n )\n\n return all_tables, not_matched_items\n
Main function to combine OCR output and PDF text to form list of table / non-table regions Args: ocr_page_items: List of OCR items by page pdf_page_items: Dict of PDF texts (page number as key) debug_path: If specified, use OpenCV to plot debug image and save to debug_path
Source code in libs/kotaemon/kotaemon/loaders/utils/pdf_ocr.py
def parse_ocr_output(\n ocr_page_items: List[dict],\n pdf_page_items: Dict[int, List[dict]],\n artifact_path: Optional[str] = None,\n debug_path: Optional[str] = None,\n):\n \"\"\"Main function to combine OCR output and PDF text to\n form list of table / non-table regions\n Args:\n ocr_page_items: List of OCR items by page\n pdf_page_items: Dict of PDF texts (page number as key)\n debug_path: If specified, use OpenCV to plot debug image and save to debug_path\n \"\"\"\n all_tables = []\n all_texts = []\n\n for page_id, page in enumerate(ocr_page_items):\n ocr_list = page[\"json\"][\"ocr\"]\n table_list = page[\"json\"][\"table\"]\n page_shape = page[\"image_shape\"]\n pdf_item_list = pdf_page_items[page_id]\n\n # create bbox additional information\n for item in ocr_list:\n item[\"box\"] = points_to_bbox(item[\"location\"])\n\n # re-scale pdf items according to new image size\n for item in pdf_item_list:\n scale_factor = page_shape[0] / item[\"page_shape\"][0]\n item[\"box\"] = scale_box(item[\"box\"], scale_factor=scale_factor)\n item[\"location\"] = scale_points(item[\"location\"], scale_factor=scale_factor)\n\n # if using debug mode, openCV must be installed\n if debug_path and artifact_path is not None:\n try:\n import cv2\n except ImportError:\n raise ImportError(\n \"Please install openCV first to use OCRReader debug mode\"\n )\n image_path = Path(artifact_path) / page[\"image\"]\n image = cv2.imread(str(image_path))\n debug_info = (cv2, image)\n else:\n debug_info = None\n\n new_pdf_list = merge_ocr_and_pdf_texts(\n ocr_list, pdf_item_list, debug_info=debug_info\n )\n\n # sort by reading order\n ocr_list = sort_funsd_reading_order(ocr_list)\n new_pdf_list = sort_funsd_reading_order(new_pdf_list)\n\n all_table_cells, non_table_text_list = merge_table_cell_and_ocr(\n table_list, ocr_list, new_pdf_list, debug_info=debug_info\n )\n\n table_texts = [table_cells_to_markdown(cells) for cells in all_table_cells]\n all_tables.extend([(page_id, text) for text in table_texts])\n all_texts.append(\n (page_id, \" \".join(item[\"text\"] for item in non_table_text_list))\n )\n\n # export debug image to debug_path\n if debug_path:\n cv2.imwrite(str(Path(debug_path) / \"page_{}.png\".format(page_id)), image)\n\n return all_tables, all_texts\n
Check if 2 columns A and B has non-empty content in the same row (to be used with merge_cols)
Parameters:
Name Type Description Default col_aList[str]
column A (list of str)
required col_bList[str]
column B (list of str)
required thresfloat
percentage of overlapping allowed
0.15
Returns: if number of overlapping greater than threshold
Source code in libs/kotaemon/kotaemon/loaders/utils/table.py
def check_col_conflicts(\n col_a: List[str], col_b: List[str], thres: float = 0.15\n) -> bool:\n \"\"\"Check if 2 columns A and B has non-empty content in the same row\n (to be used with merge_cols)\n\n Args:\n col_a: column A (list of str)\n col_b: column B (list of str)\n thres: percentage of overlapping allowed\n Returns:\n if number of overlapping greater than threshold\n \"\"\"\n num_rows = len([cell for cell in col_a if cell])\n assert len(col_a) == len(col_b)\n conflict_count = 0\n for cell_a, cell_b in zip(col_a, col_b):\n if cell_a and cell_b:\n conflict_count += 1\n return conflict_count > num_rows * thres\n
Merge column A and B if they do not have conflict rows
Parameters:
Name Type Description Default col_aList[str]
column A (list of str)
required col_bList[str]
column B (list of str)
required
Returns: merged column
Source code in libs/kotaemon/kotaemon/loaders/utils/table.py
def merge_cols(col_a: List[str], col_b: List[str]) -> List[str]:\n \"\"\"Merge column A and B if they do not have conflict rows\n\n Args:\n col_a: column A (list of str)\n col_b: column B (list of str)\n Returns:\n merged column\n \"\"\"\n for r_id in range(len(col_a)):\n if col_b[r_id]:\n col_a[r_id] = col_a[r_id] + \" \" + col_b[r_id]\n return col_a\n
Add index column as the first column of the table csv_rows
Parameters:
Name Type Description Default csv_rowsList[List[str]]
input table
required
Returns: output table with index column
Source code in libs/kotaemon/kotaemon/loaders/utils/table.py
def add_index_col(csv_rows: List[List[str]]) -> List[List[str]]:\n \"\"\"Add index column as the first column of the table csv_rows\n\n Args:\n csv_rows: input table\n Returns:\n output table with index column\n \"\"\"\n new_csv_rows = [[\"row id\"] + [\"\"] * len(csv_rows[0])]\n for r_id, row in enumerate(csv_rows):\n new_csv_rows.append([str(r_id + 1)] + row)\n return new_csv_rows\n
Compress table csv_rows by merging sparse columns (merge_cols)
Parameters:
Name Type Description Default csv_rowsList[List[str]]
input table
required
Returns: output: compressed table
Source code in libs/kotaemon/kotaemon/loaders/utils/table.py
def compress_csv(csv_rows: List[List[str]]) -> List[List[str]]:\n \"\"\"Compress table csv_rows by merging sparse columns (merge_cols)\n\n Args:\n csv_rows: input table\n Returns:\n output: compressed table\n \"\"\"\n csv_cols = [[r[c_id] for r in csv_rows] for c_id in range(len(csv_rows[0]))]\n to_remove_col_ids = []\n last_c_id = 0\n for c_id in range(1, len(csv_cols)):\n if not check_col_conflicts(csv_cols[last_c_id], csv_cols[c_id]):\n to_remove_col_ids.append(c_id)\n csv_cols[last_c_id] = merge_cols(csv_cols[last_c_id], csv_cols[c_id])\n else:\n last_c_id = c_id\n\n csv_cols = [r for c_id, r in enumerate(csv_cols) if c_id not in to_remove_col_ids]\n csv_rows = [[c[r_id] for c in csv_cols] for r_id in range(len(csv_cols[0]))]\n return csv_rows\n
Get list of text lines belong to table regions specified by table_list
Parameters:
Name Type Description Default ocr_listList[dict]
list of OCR output in Casia format (Flax)
required table_listList[dict]
list of table output in Casia format (Flax)
required
Returns:
Name Type Description _type_
description
Source code in libs/kotaemon/kotaemon/loaders/utils/table.py
def get_table_from_ocr(ocr_list: List[dict], table_list: List[dict]):\n \"\"\"Get list of text lines belong to table regions specified by table_list\n\n Args:\n ocr_list: list of OCR output in Casia format (Flax)\n table_list: list of table output in Casia format (Flax)\n\n Returns:\n _type_: _description_\n \"\"\"\n table_texts = []\n for table in table_list:\n if table[\"type\"] != \"table\":\n continue\n cur_table_texts = []\n for ocr in ocr_list:\n _iou = get_rect_iou(table[\"location\"], ocr[\"location\"], iou_type=1)\n if _iou > 0.8:\n cur_table_texts.append(ocr[\"text\"])\n table_texts.append(cur_table_texts)\n\n return table_texts\n
Source code in libs/kotaemon/kotaemon/loaders/utils/table.py
def make_markdown_table(array: List[List[str]]) -> str:\n \"\"\"Convert table rows in list format to markdown string\n\n Args:\n Python list with rows of table as lists\n First element as header.\n Example Input:\n [[\"Name\", \"Age\", \"Height\"],\n [\"Jake\", 20, 5'10],\n [\"Mary\", 21, 5'7]]\n Returns:\n String to put into a .md file\n \"\"\"\n array = compress_csv(array)\n array = add_index_col(array)\n markdown = \"\\n\" + str(\"| \")\n\n for e in array[0]:\n to_add = \" \" + str(e) + str(\" |\")\n markdown += to_add\n markdown += \"\\n\"\n\n markdown += \"| \"\n for i in range(len(array[0])):\n markdown += str(\"--- | \")\n markdown += \"\\n\"\n\n for entry in array[1:]:\n markdown += str(\"| \")\n for e in entry:\n to_add = str(e) + str(\" | \")\n markdown += to_add\n markdown += \"\\n\"\n\n return markdown + \"\\n\"\n
Extract list of table from FullOCR output (csv_content) with the specified table_texts
Parameters:
Name Type Description Default csv_contentstr
CSV output from FullOCR pipeline
required table_textsList[List[str]]
list of table texts extracted
required
Returns:
Type Description Tuple[List[str], str]
List of tables and non-text content
Source code in libs/kotaemon/kotaemon/loaders/utils/table.py
def extract_tables_from_csv_string(\n csv_content: str, table_texts: List[List[str]]\n) -> Tuple[List[str], str]:\n \"\"\"Extract list of table from FullOCR output\n (csv_content) with the specified table_texts\n\n Args:\n csv_content: CSV output from FullOCR pipeline\n table_texts: list of table texts extracted\n from get_table_from_ocr()\n\n Returns:\n List of tables and non-text content\n \"\"\"\n rows = parse_csv_string_to_list(csv_content)\n used_row_ids = []\n table_csv_list = []\n for table in table_texts:\n cur_rows = []\n for row_id, row in enumerate(rows):\n scores = [\n any(cell in cell_reference for cell in table)\n for cell_reference in row\n if cell_reference\n ]\n score = sum(scores) / len(scores)\n if score > 0.5 and row_id not in used_row_ids:\n used_row_ids.append(row_id)\n cur_rows.append([format_cell(cell) for cell in row])\n if cur_rows:\n table_csv_list.append(make_markdown_table(cur_rows))\n else:\n print(\"table not matched\", table)\n\n non_table_rows = [\n row for row_id, row in enumerate(rows) if row_id not in used_row_ids\n ]\n non_table_text = \"\\n\".join(\n \" \".join(format_cell(cell) for cell in row) for row in non_table_rows\n )\n return table_csv_list, non_table_text\n
Strip special characters from input text in markdown table format
Source code in libs/kotaemon/kotaemon/loaders/utils/table.py
def strip_special_chars_markdown(text: str) -> str:\n \"\"\"Strip special characters from input text in markdown table format\"\"\"\n return text.replace(\"|\", \"\").replace(\":---:\", \"\").replace(\"---\", \"\")\n
Convert markdown text to list of non-table spans and table spans
Parameters:
Name Type Description Default textstr
input markdown text
required
Returns:
Type Description Tuple[List[str], List[str]]
list of table spans and non-table spans
Source code in libs/kotaemon/kotaemon/loaders/utils/table.py
def parse_markdown_text_to_tables(text: str) -> Tuple[List[str], List[str]]:\n \"\"\"Convert markdown text to list of non-table spans and table spans\n\n Args:\n text: input markdown text\n\n Returns:\n list of table spans and non-table spans\n \"\"\"\n # init empty tables and texts list\n tables = []\n texts = []\n\n # split input by line break\n lines = text.split(\"\\n\")\n cur_table = []\n cur_text: List[str] = []\n for line in lines:\n line = line.strip()\n if line.startswith(\"|\"):\n if len(cur_text) > 0:\n texts.append(cur_text)\n cur_text = []\n cur_table.append(line)\n else:\n # add new table to the list\n if len(cur_table) > 0:\n tables.append(cur_table)\n cur_table = []\n cur_text.append(line)\n\n table_texts = [\"\\n\".join(table) for table in tables]\n non_table_texts = [\"\\n\".join(text) for text in texts]\n return table_texts, non_table_texts\n
Convert list of cells with attached text to Markdown table
Source code in libs/kotaemon/kotaemon/loaders/utils/table.py
def table_cells_to_markdown(cells: List[dict]):\n \"\"\"Convert list of cells with attached text to Markdown table\"\"\"\n\n if len(cells) == 0:\n return \"\"\n\n all_row_ids = []\n all_col_ids = []\n for cell in cells:\n all_row_ids.extend(cell[\"rows\"])\n all_col_ids.extend(cell[\"columns\"])\n\n num_rows, num_cols = max(all_row_ids) + 1, max(all_col_ids) + 1\n table_rows = [[\"\" for c in range(num_cols)] for r in range(num_rows)]\n\n # start filling in the grid\n for cell in cells:\n cell_text = \" \".join(item[\"text\"] for item in cell[\"ocr\"])\n start_row_id, end_row_id = cell[\"rows\"]\n start_col_id, end_col_id = cell[\"columns\"]\n span_cell = end_row_id != start_row_id or end_col_id != start_col_id\n\n # do not repeat long text in span cell to prevent context length issue\n if span_cell and len(cell_text.replace(\" \", \"\")) < 20 and start_row_id > 0:\n for row in range(start_row_id, end_row_id + 1):\n for col in range(start_col_id, end_col_id + 1):\n table_rows[row][col] += cell_text + \" \"\n else:\n table_rows[start_row_id][start_col_id] += cell_text + \" \"\n\n return make_markdown_table(table_rows)\n
Simple class for extracting text from a document using a regex pattern.
Parameters:
Name Type Description Default patternList[str]
The regex pattern(s) to use.
required output_mapdict
A mapping from extracted text to the desired output. Defaults to None.
required Source code in libs/kotaemon/kotaemon/parsers/regex_extractor.py
class RegexExtractor(BaseComponent):\n \"\"\"\n Simple class for extracting text from a document using a regex pattern.\n\n Args:\n pattern (List[str]): The regex pattern(s) to use.\n output_map (dict, optional): A mapping from extracted text to the\n desired output. Defaults to None.\n \"\"\"\n\n class Config:\n middleware_switches = {\"theflow.middleware.CachingMiddleware\": False}\n\n pattern: list[str]\n output_map: dict[str, str] | Callable[[str], str] = Param(\n default_callback=lambda *_: {}\n )\n\n def __init__(self, pattern: str | list[str], **kwargs):\n if isinstance(pattern, str):\n pattern = [pattern]\n super().__init__(pattern=pattern, **kwargs)\n\n @staticmethod\n def run_raw_static(pattern: str, text: str) -> list[str]:\n \"\"\"\n Finds all non-overlapping occurrences of a pattern in a string.\n\n Parameters:\n pattern (str): The regular expression pattern to search for.\n text (str): The input string to search in.\n\n Returns:\n List[str]: A list of all non-overlapping occurrences of the pattern in the\n string.\n \"\"\"\n return re.findall(pattern, text)\n\n @staticmethod\n def map_output(text, output_map) -> str:\n \"\"\"\n Maps the given `text` to its corresponding value in the `output_map` dictionary.\n\n Parameters:\n text (str): The input text to be mapped.\n output_map (dict): A dictionary containing mapping of input text to output\n values.\n\n Returns:\n str: The corresponding value from the `output_map` if `text` is found in the\n dictionary, otherwise returns the original `text`.\n \"\"\"\n if not output_map:\n return text\n\n if isinstance(output_map, dict):\n return output_map.get(text, text)\n\n return output_map(text)\n\n def run_raw(self, text: str) -> ExtractorOutput:\n \"\"\"\n Matches the raw text against the pattern and rans the output mapping, returning\n an instance of ExtractorOutput.\n\n Args:\n text (str): The raw text to be processed.\n\n Returns:\n ExtractorOutput: The processed output as a list of ExtractorOutput.\n \"\"\"\n output: list[str] = sum(\n [self.run_raw_static(p, text) for p in self.pattern], []\n )\n output = [self.map_output(text, self.output_map) for text in output]\n\n return ExtractorOutput(\n text=output[0] if output else \"\",\n matches=output,\n metadata={\"origin\": \"RegexExtractor\"},\n )\n\n def run(\n self, text: str | list[str] | Document | list[Document]\n ) -> list[ExtractorOutput]:\n \"\"\"Match the input against a pattern and return the output for each input\n\n Parameters:\n text: contains the input string to be processed\n\n Returns:\n A list contains the output ExtractorOutput for each input\n\n Example:\n ```pycon\n >>> document1 = Document(...)\n >>> document2 = Document(...)\n >>> document_batch = [document1, document2]\n >>> batch_output = self(document_batch)\n >>> print(batch_output)\n [output1_document1, output1_document2]\n ```\n \"\"\"\n # TODO: this conversion seems common\n input_: list[str] = []\n if not isinstance(text, list):\n text = [text]\n\n for item in text:\n if isinstance(item, str):\n input_.append(item)\n elif isinstance(item, Document):\n input_.append(item.text)\n else:\n raise ValueError(\n f\"Invalid input type {type(item)}, should be str or Document\"\n )\n\n output = []\n for each_input in input_:\n output.append(self.run_raw(each_input))\n\n return output\n
Finds all non-overlapping occurrences of a pattern in a string.
Parameters:
Name Type Description Default patternstr
The regular expression pattern to search for.
required textstr
The input string to search in.
required
Returns:
Type Description list[str]
List[str]: A list of all non-overlapping occurrences of the pattern in the string.
Source code in libs/kotaemon/kotaemon/parsers/regex_extractor.py
@staticmethod\ndef run_raw_static(pattern: str, text: str) -> list[str]:\n \"\"\"\n Finds all non-overlapping occurrences of a pattern in a string.\n\n Parameters:\n pattern (str): The regular expression pattern to search for.\n text (str): The input string to search in.\n\n Returns:\n List[str]: A list of all non-overlapping occurrences of the pattern in the\n string.\n \"\"\"\n return re.findall(pattern, text)\n
Maps the given text to its corresponding value in the output_map dictionary.
Parameters:
Name Type Description Default textstr
The input text to be mapped.
required output_mapdict
A dictionary containing mapping of input text to output values.
required
Returns:
Name Type Description strstr
The corresponding value from the output_map if text is found in the dictionary, otherwise returns the original text.
Source code in libs/kotaemon/kotaemon/parsers/regex_extractor.py
@staticmethod\ndef map_output(text, output_map) -> str:\n \"\"\"\n Maps the given `text` to its corresponding value in the `output_map` dictionary.\n\n Parameters:\n text (str): The input text to be mapped.\n output_map (dict): A dictionary containing mapping of input text to output\n values.\n\n Returns:\n str: The corresponding value from the `output_map` if `text` is found in the\n dictionary, otherwise returns the original `text`.\n \"\"\"\n if not output_map:\n return text\n\n if isinstance(output_map, dict):\n return output_map.get(text, text)\n\n return output_map(text)\n
Matches the raw text against the pattern and rans the output mapping, returning an instance of ExtractorOutput.
Parameters:
Name Type Description Default textstr
The raw text to be processed.
required
Returns:
Name Type Description ExtractorOutputExtractorOutput
The processed output as a list of ExtractorOutput.
Source code in libs/kotaemon/kotaemon/parsers/regex_extractor.py
def run_raw(self, text: str) -> ExtractorOutput:\n \"\"\"\n Matches the raw text against the pattern and rans the output mapping, returning\n an instance of ExtractorOutput.\n\n Args:\n text (str): The raw text to be processed.\n\n Returns:\n ExtractorOutput: The processed output as a list of ExtractorOutput.\n \"\"\"\n output: list[str] = sum(\n [self.run_raw_static(p, text) for p in self.pattern], []\n )\n output = [self.map_output(text, self.output_map) for text in output]\n\n return ExtractorOutput(\n text=output[0] if output else \"\",\n matches=output,\n metadata={\"origin\": \"RegexExtractor\"},\n )\n
Source code in libs/kotaemon/kotaemon/parsers/regex_extractor.py
def run(\n self, text: str | list[str] | Document | list[Document]\n) -> list[ExtractorOutput]:\n \"\"\"Match the input against a pattern and return the output for each input\n\n Parameters:\n text: contains the input string to be processed\n\n Returns:\n A list contains the output ExtractorOutput for each input\n\n Example:\n ```pycon\n >>> document1 = Document(...)\n >>> document2 = Document(...)\n >>> document_batch = [document1, document2]\n >>> batch_output = self(document_batch)\n >>> print(batch_output)\n [output1_document1, output1_document2]\n ```\n \"\"\"\n # TODO: this conversion seems common\n input_: list[str] = []\n if not isinstance(text, list):\n text = [text]\n\n for item in text:\n if isinstance(item, str):\n input_.append(item)\n elif isinstance(item, Document):\n input_.append(item.text)\n else:\n raise ValueError(\n f\"Invalid input type {type(item)}, should be str or Document\"\n )\n\n output = []\n for each_input in input_:\n output.append(self.run_raw(each_input))\n\n return output\n
Simple class for extracting text from a document using a regex pattern.
Parameters:
Name Type Description Default patternList[str]
The regex pattern(s) to use.
required output_mapdict
A mapping from extracted text to the desired output. Defaults to None.
required Source code in libs/kotaemon/kotaemon/parsers/regex_extractor.py
class RegexExtractor(BaseComponent):\n \"\"\"\n Simple class for extracting text from a document using a regex pattern.\n\n Args:\n pattern (List[str]): The regex pattern(s) to use.\n output_map (dict, optional): A mapping from extracted text to the\n desired output. Defaults to None.\n \"\"\"\n\n class Config:\n middleware_switches = {\"theflow.middleware.CachingMiddleware\": False}\n\n pattern: list[str]\n output_map: dict[str, str] | Callable[[str], str] = Param(\n default_callback=lambda *_: {}\n )\n\n def __init__(self, pattern: str | list[str], **kwargs):\n if isinstance(pattern, str):\n pattern = [pattern]\n super().__init__(pattern=pattern, **kwargs)\n\n @staticmethod\n def run_raw_static(pattern: str, text: str) -> list[str]:\n \"\"\"\n Finds all non-overlapping occurrences of a pattern in a string.\n\n Parameters:\n pattern (str): The regular expression pattern to search for.\n text (str): The input string to search in.\n\n Returns:\n List[str]: A list of all non-overlapping occurrences of the pattern in the\n string.\n \"\"\"\n return re.findall(pattern, text)\n\n @staticmethod\n def map_output(text, output_map) -> str:\n \"\"\"\n Maps the given `text` to its corresponding value in the `output_map` dictionary.\n\n Parameters:\n text (str): The input text to be mapped.\n output_map (dict): A dictionary containing mapping of input text to output\n values.\n\n Returns:\n str: The corresponding value from the `output_map` if `text` is found in the\n dictionary, otherwise returns the original `text`.\n \"\"\"\n if not output_map:\n return text\n\n if isinstance(output_map, dict):\n return output_map.get(text, text)\n\n return output_map(text)\n\n def run_raw(self, text: str) -> ExtractorOutput:\n \"\"\"\n Matches the raw text against the pattern and rans the output mapping, returning\n an instance of ExtractorOutput.\n\n Args:\n text (str): The raw text to be processed.\n\n Returns:\n ExtractorOutput: The processed output as a list of ExtractorOutput.\n \"\"\"\n output: list[str] = sum(\n [self.run_raw_static(p, text) for p in self.pattern], []\n )\n output = [self.map_output(text, self.output_map) for text in output]\n\n return ExtractorOutput(\n text=output[0] if output else \"\",\n matches=output,\n metadata={\"origin\": \"RegexExtractor\"},\n )\n\n def run(\n self, text: str | list[str] | Document | list[Document]\n ) -> list[ExtractorOutput]:\n \"\"\"Match the input against a pattern and return the output for each input\n\n Parameters:\n text: contains the input string to be processed\n\n Returns:\n A list contains the output ExtractorOutput for each input\n\n Example:\n ```pycon\n >>> document1 = Document(...)\n >>> document2 = Document(...)\n >>> document_batch = [document1, document2]\n >>> batch_output = self(document_batch)\n >>> print(batch_output)\n [output1_document1, output1_document2]\n ```\n \"\"\"\n # TODO: this conversion seems common\n input_: list[str] = []\n if not isinstance(text, list):\n text = [text]\n\n for item in text:\n if isinstance(item, str):\n input_.append(item)\n elif isinstance(item, Document):\n input_.append(item.text)\n else:\n raise ValueError(\n f\"Invalid input type {type(item)}, should be str or Document\"\n )\n\n output = []\n for each_input in input_:\n output.append(self.run_raw(each_input))\n\n return output\n
Finds all non-overlapping occurrences of a pattern in a string.
Parameters:
Name Type Description Default patternstr
The regular expression pattern to search for.
required textstr
The input string to search in.
required
Returns:
Type Description list[str]
List[str]: A list of all non-overlapping occurrences of the pattern in the string.
Source code in libs/kotaemon/kotaemon/parsers/regex_extractor.py
@staticmethod\ndef run_raw_static(pattern: str, text: str) -> list[str]:\n \"\"\"\n Finds all non-overlapping occurrences of a pattern in a string.\n\n Parameters:\n pattern (str): The regular expression pattern to search for.\n text (str): The input string to search in.\n\n Returns:\n List[str]: A list of all non-overlapping occurrences of the pattern in the\n string.\n \"\"\"\n return re.findall(pattern, text)\n
Maps the given text to its corresponding value in the output_map dictionary.
Parameters:
Name Type Description Default textstr
The input text to be mapped.
required output_mapdict
A dictionary containing mapping of input text to output values.
required
Returns:
Name Type Description strstr
The corresponding value from the output_map if text is found in the dictionary, otherwise returns the original text.
Source code in libs/kotaemon/kotaemon/parsers/regex_extractor.py
@staticmethod\ndef map_output(text, output_map) -> str:\n \"\"\"\n Maps the given `text` to its corresponding value in the `output_map` dictionary.\n\n Parameters:\n text (str): The input text to be mapped.\n output_map (dict): A dictionary containing mapping of input text to output\n values.\n\n Returns:\n str: The corresponding value from the `output_map` if `text` is found in the\n dictionary, otherwise returns the original `text`.\n \"\"\"\n if not output_map:\n return text\n\n if isinstance(output_map, dict):\n return output_map.get(text, text)\n\n return output_map(text)\n
Matches the raw text against the pattern and rans the output mapping, returning an instance of ExtractorOutput.
Parameters:
Name Type Description Default textstr
The raw text to be processed.
required
Returns:
Name Type Description ExtractorOutputExtractorOutput
The processed output as a list of ExtractorOutput.
Source code in libs/kotaemon/kotaemon/parsers/regex_extractor.py
def run_raw(self, text: str) -> ExtractorOutput:\n \"\"\"\n Matches the raw text against the pattern and rans the output mapping, returning\n an instance of ExtractorOutput.\n\n Args:\n text (str): The raw text to be processed.\n\n Returns:\n ExtractorOutput: The processed output as a list of ExtractorOutput.\n \"\"\"\n output: list[str] = sum(\n [self.run_raw_static(p, text) for p in self.pattern], []\n )\n output = [self.map_output(text, self.output_map) for text in output]\n\n return ExtractorOutput(\n text=output[0] if output else \"\",\n matches=output,\n metadata={\"origin\": \"RegexExtractor\"},\n )\n
Source code in libs/kotaemon/kotaemon/parsers/regex_extractor.py
def run(\n self, text: str | list[str] | Document | list[Document]\n) -> list[ExtractorOutput]:\n \"\"\"Match the input against a pattern and return the output for each input\n\n Parameters:\n text: contains the input string to be processed\n\n Returns:\n A list contains the output ExtractorOutput for each input\n\n Example:\n ```pycon\n >>> document1 = Document(...)\n >>> document2 = Document(...)\n >>> document_batch = [document1, document2]\n >>> batch_output = self(document_batch)\n >>> print(batch_output)\n [output1_document1, output1_document2]\n ```\n \"\"\"\n # TODO: this conversion seems common\n input_: list[str] = []\n if not isinstance(text, list):\n text = [text]\n\n for item in text:\n if isinstance(item, str):\n input_.append(item)\n elif isinstance(item, Document):\n input_.append(item.text)\n else:\n raise ValueError(\n f\"Invalid input type {type(item)}, should be str or Document\"\n )\n\n output = []\n for each_input in input_:\n output.append(self.run_raw(each_input))\n\n return output\n
A document store is in charged of storing and managing documents
Source code in libs/kotaemon/kotaemon/storages/docstores/base.py
class BaseDocumentStore(ABC):\n \"\"\"A document store is in charged of storing and managing documents\"\"\"\n\n @abstractmethod\n def __init__(self, *args, **kwargs):\n ...\n\n @abstractmethod\n def add(\n self,\n docs: Union[Document, List[Document]],\n ids: Optional[Union[List[str], str]] = None,\n **kwargs,\n ):\n \"\"\"Add document into document store\n\n Args:\n docs: Document or list of documents\n ids: List of ids of the documents. Optional, if not set will use doc.doc_id\n \"\"\"\n ...\n\n @abstractmethod\n def get(self, ids: Union[List[str], str]) -> List[Document]:\n \"\"\"Get document by id\"\"\"\n ...\n\n @abstractmethod\n def get_all(self) -> List[Document]:\n \"\"\"Get all documents\"\"\"\n ...\n\n @abstractmethod\n def count(self) -> int:\n \"\"\"Count number of documents\"\"\"\n ...\n\n @abstractmethod\n def query(\n self, query: str, top_k: int = 10, doc_ids: Optional[list] = None\n ) -> List[Document]:\n \"\"\"Search document store using search query\"\"\"\n ...\n\n @abstractmethod\n def delete(self, ids: Union[List[str], str]):\n \"\"\"Delete document by id\"\"\"\n ...\n\n @abstractmethod\n def drop(self):\n \"\"\"Drop the document store\"\"\"\n ...\n
Name Type Description Default docsUnion[Document, List[Document]]
Document or list of documents
required idsOptional[Union[List[str], str]]
List of ids of the documents. Optional, if not set will use doc.doc_id
None Source code in libs/kotaemon/kotaemon/storages/docstores/base.py
@abstractmethod\ndef add(\n self,\n docs: Union[Document, List[Document]],\n ids: Optional[Union[List[str], str]] = None,\n **kwargs,\n):\n \"\"\"Add document into document store\n\n Args:\n docs: Document or list of documents\n ids: List of ids of the documents. Optional, if not set will use doc.doc_id\n \"\"\"\n ...\n
Name Type Description Default docsUnion[Document, List[Document]]
list of documents to add
required idsOptional[Union[List[str], str]]
specify the ids of documents to add or use existing doc.doc_id
Nonerefresh_indicesbool
request Elasticsearch to update its index (default to True)
True Source code in libs/kotaemon/kotaemon/storages/docstores/elasticsearch.py
def add(\n self,\n docs: Union[Document, List[Document]],\n ids: Optional[Union[List[str], str]] = None,\n refresh_indices: bool = True,\n **kwargs,\n):\n \"\"\"Add document into document store\n\n Args:\n docs: list of documents to add\n ids: specify the ids of documents to add or use existing doc.doc_id\n refresh_indices: request Elasticsearch to update its index (default to True)\n \"\"\"\n if ids and not isinstance(ids, list):\n ids = [ids]\n if not isinstance(docs, list):\n docs = [docs]\n doc_ids = ids if ids else [doc.doc_id for doc in docs]\n\n requests = []\n for doc_id, doc in zip(doc_ids, docs):\n text = doc.text\n metadata = doc.metadata\n request = {\n \"_op_type\": \"index\",\n \"_index\": self.index_name,\n \"content\": text,\n \"metadata\": metadata,\n \"_id\": doc_id,\n }\n requests.append(request)\n\n success, failed = self.es_bulk(self.client, requests)\n print(\"Added/Updated documents to index\", success)\n print(\"Failed documents to index\", failed)\n\n if refresh_indices:\n self.client.indices.refresh(index=self.index_name)\n
Query Elasticsearch store using query format of ES client
Parameters:
Name Type Description Default querydict
Elasticsearch query format
required
Returns:
Type Description List[Document]
List[Document]: List of result documents
Source code in libs/kotaemon/kotaemon/storages/docstores/elasticsearch.py
def query_raw(self, query: dict) -> List[Document]:\n \"\"\"Query Elasticsearch store using query format of ES client\n\n Args:\n query (dict): Elasticsearch query format\n\n Returns:\n List[Document]: List of result documents\n \"\"\"\n res = self.client.search(index=self.index_name, body=query)\n docs = []\n for r in res[\"hits\"][\"hits\"]:\n docs.append(\n Document(\n id_=r[\"_id\"],\n text=r[\"_source\"][\"content\"],\n metadata=r[\"_source\"][\"metadata\"],\n )\n )\n return docs\n
Simple memory document store that store document in a dictionary
Source code in libs/kotaemon/kotaemon/storages/docstores/in_memory.py
class InMemoryDocumentStore(BaseDocumentStore):\n \"\"\"Simple memory document store that store document in a dictionary\"\"\"\n\n def __init__(self):\n self._store = {}\n\n def add(\n self,\n docs: Union[Document, List[Document]],\n ids: Optional[Union[List[str], str]] = None,\n **kwargs,\n ):\n \"\"\"Add document into document store\n\n Args:\n docs: list of documents to add\n ids: specify the ids of documents to add or\n use existing doc.doc_id\n exist_ok: raise error when duplicate doc-id\n found in the docstore (default to False)\n \"\"\"\n exist_ok: bool = kwargs.pop(\"exist_ok\", False)\n\n if ids and not isinstance(ids, list):\n ids = [ids]\n if not isinstance(docs, list):\n docs = [docs]\n doc_ids = ids if ids else [doc.doc_id for doc in docs]\n\n for doc_id, doc in zip(doc_ids, docs):\n if doc_id in self._store and not exist_ok:\n raise ValueError(f\"Document with id {doc_id} already exist\")\n self._store[doc_id] = doc\n\n def get(self, ids: Union[List[str], str]) -> List[Document]:\n \"\"\"Get document by id\"\"\"\n if not isinstance(ids, list):\n ids = [ids]\n\n return [self._store[doc_id] for doc_id in ids]\n\n def get_all(self) -> List[Document]:\n \"\"\"Get all documents\"\"\"\n return list(self._store.values())\n\n def count(self) -> int:\n \"\"\"Count number of documents\"\"\"\n return len(self._store)\n\n def delete(self, ids: Union[List[str], str]):\n \"\"\"Delete document by id\"\"\"\n if not isinstance(ids, list):\n ids = [ids]\n\n for doc_id in ids:\n del self._store[doc_id]\n\n def save(self, path: Union[str, Path]):\n \"\"\"Save document to path\"\"\"\n store = {key: value.to_dict() for key, value in self._store.items()}\n with open(path, \"w\") as f:\n json.dump(store, f)\n\n def load(self, path: Union[str, Path]):\n \"\"\"Load document store from path\"\"\"\n with open(path) as f:\n store = json.load(f)\n # TODO: save and load aren't lossless. A Document-subclass will lose\n # information. Need to edit the `to_dict` and `from_dict` methods in\n # the Document class.\n # For better query support, utilize SQLite as the default document store.\n # Also, for portability, use SQLAlchemy for document store.\n self._store = {key: Document.from_dict(value) for key, value in store.items()}\n\n def query(\n self, query: str, top_k: int = 10, doc_ids: Optional[list] = None\n ) -> List[Document]:\n \"\"\"Perform full-text search on document store\"\"\"\n return []\n\n def __persist_flow__(self):\n return {}\n\n def drop(self):\n \"\"\"Drop the document store\"\"\"\n self._store = {}\n
Name Type Description Default docsUnion[Document, List[Document]]
list of documents to add
required idsOptional[Union[List[str], str]]
specify the ids of documents to add or use existing doc.doc_id
Noneexist_ok
raise error when duplicate doc-id found in the docstore (default to False)
required Source code in libs/kotaemon/kotaemon/storages/docstores/in_memory.py
def add(\n self,\n docs: Union[Document, List[Document]],\n ids: Optional[Union[List[str], str]] = None,\n **kwargs,\n):\n \"\"\"Add document into document store\n\n Args:\n docs: list of documents to add\n ids: specify the ids of documents to add or\n use existing doc.doc_id\n exist_ok: raise error when duplicate doc-id\n found in the docstore (default to False)\n \"\"\"\n exist_ok: bool = kwargs.pop(\"exist_ok\", False)\n\n if ids and not isinstance(ids, list):\n ids = [ids]\n if not isinstance(docs, list):\n docs = [docs]\n doc_ids = ids if ids else [doc.doc_id for doc in docs]\n\n for doc_id, doc in zip(doc_ids, docs):\n if doc_id in self._store and not exist_ok:\n raise ValueError(f\"Document with id {doc_id} already exist\")\n self._store[doc_id] = doc\n
Source code in libs/kotaemon/kotaemon/storages/docstores/in_memory.py
def get(self, ids: Union[List[str], str]) -> List[Document]:\n \"\"\"Get document by id\"\"\"\n if not isinstance(ids, list):\n ids = [ids]\n\n return [self._store[doc_id] for doc_id in ids]\n
Source code in libs/kotaemon/kotaemon/storages/docstores/in_memory.py
def delete(self, ids: Union[List[str], str]):\n \"\"\"Delete document by id\"\"\"\n if not isinstance(ids, list):\n ids = [ids]\n\n for doc_id in ids:\n del self._store[doc_id]\n
Source code in libs/kotaemon/kotaemon/storages/docstores/in_memory.py
def save(self, path: Union[str, Path]):\n \"\"\"Save document to path\"\"\"\n store = {key: value.to_dict() for key, value in self._store.items()}\n with open(path, \"w\") as f:\n json.dump(store, f)\n
Source code in libs/kotaemon/kotaemon/storages/docstores/in_memory.py
def load(self, path: Union[str, Path]):\n \"\"\"Load document store from path\"\"\"\n with open(path) as f:\n store = json.load(f)\n # TODO: save and load aren't lossless. A Document-subclass will lose\n # information. Need to edit the `to_dict` and `from_dict` methods in\n # the Document class.\n # For better query support, utilize SQLite as the default document store.\n # Also, for portability, use SQLAlchemy for document store.\n self._store = {key: Document.from_dict(value) for key, value in store.items()}\n
Improve InMemoryDocumentStore by auto saving whenever the corpus is changed
Source code in libs/kotaemon/kotaemon/storages/docstores/simple_file.py
class SimpleFileDocumentStore(InMemoryDocumentStore):\n \"\"\"Improve InMemoryDocumentStore by auto saving whenever the corpus is changed\"\"\"\n\n def __init__(self, path: str | Path, collection_name: str = \"default\"):\n super().__init__()\n self._path = path\n self._collection_name = collection_name\n\n Path(path).mkdir(parents=True, exist_ok=True)\n self._save_path = Path(path) / f\"{collection_name}.json\"\n if self._save_path.is_file():\n self.load(self._save_path)\n\n def get(self, ids: Union[List[str], str]) -> List[Document]:\n \"\"\"Get document by id\"\"\"\n if not isinstance(ids, list):\n ids = [ids]\n\n for doc_id in ids:\n if doc_id not in self._store:\n self.load(self._save_path)\n break\n\n return [self._store[doc_id] for doc_id in ids]\n\n def add(\n self,\n docs: Union[Document, List[Document]],\n ids: Optional[Union[List[str], str]] = None,\n **kwargs,\n ):\n \"\"\"Add document into document store\n\n Args:\n docs: list of documents to add\n ids: specify the ids of documents to add or\n use existing doc.doc_id\n exist_ok: raise error when duplicate doc-id\n found in the docstore (default to False)\n \"\"\"\n super().add(docs=docs, ids=ids, **kwargs)\n self.save(self._save_path)\n\n def delete(self, ids: Union[List[str], str]):\n \"\"\"Delete document by id\"\"\"\n super().delete(ids=ids)\n self.save(self._save_path)\n\n def drop(self):\n \"\"\"Drop the document store\"\"\"\n super().drop()\n self._save_path.unlink(missing_ok=True)\n\n def __persist_flow__(self):\n from theflow.utils.modules import serialize\n\n return {\n \"path\": serialize(self._path),\n \"collection_name\": self._collection_name,\n }\n
Source code in libs/kotaemon/kotaemon/storages/docstores/simple_file.py
def get(self, ids: Union[List[str], str]) -> List[Document]:\n \"\"\"Get document by id\"\"\"\n if not isinstance(ids, list):\n ids = [ids]\n\n for doc_id in ids:\n if doc_id not in self._store:\n self.load(self._save_path)\n break\n\n return [self._store[doc_id] for doc_id in ids]\n
Name Type Description Default docsUnion[Document, List[Document]]
list of documents to add
required idsOptional[Union[List[str], str]]
specify the ids of documents to add or use existing doc.doc_id
Noneexist_ok
raise error when duplicate doc-id found in the docstore (default to False)
required Source code in libs/kotaemon/kotaemon/storages/docstores/simple_file.py
def add(\n self,\n docs: Union[Document, List[Document]],\n ids: Optional[Union[List[str], str]] = None,\n **kwargs,\n):\n \"\"\"Add document into document store\n\n Args:\n docs: list of documents to add\n ids: specify the ids of documents to add or\n use existing doc.doc_id\n exist_ok: raise error when duplicate doc-id\n found in the docstore (default to False)\n \"\"\"\n super().add(docs=docs, ids=ids, **kwargs)\n self.save(self._save_path)\n
Source code in libs/kotaemon/kotaemon/storages/vectorstores/base.py
class BaseVectorStore(ABC):\n @abstractmethod\n def __init__(self, *args, **kwargs):\n ...\n\n @abstractmethod\n def add(\n self,\n embeddings: list[list[float]] | list[DocumentWithEmbedding],\n metadatas: Optional[list[dict]] = None,\n ids: Optional[list[str]] = None,\n ) -> list[str]:\n \"\"\"Add vector embeddings to vector stores\n\n Args:\n embeddings: List of embeddings\n metadatas: List of metadata of the embeddings\n ids: List of ids of the embeddings\n kwargs: meant for vectorstore-specific parameters\n\n Returns:\n List of ids of the embeddings\n \"\"\"\n ...\n\n @abstractmethod\n def delete(self, ids: list[str], **kwargs):\n \"\"\"Delete vector embeddings from vector stores\n\n Args:\n ids: List of ids of the embeddings to be deleted\n kwargs: meant for vectorstore-specific parameters\n \"\"\"\n ...\n\n @abstractmethod\n def query(\n self,\n embedding: list[float],\n top_k: int = 1,\n ids: Optional[list[str]] = None,\n **kwargs,\n ) -> tuple[list[list[float]], list[float], list[str]]:\n \"\"\"Return the top k most similar vector embeddings\n\n Args:\n embedding: List of embeddings\n top_k: Number of most similar embeddings to return\n ids: List of ids of the embeddings to be queried\n\n Returns:\n the matched embeddings, the similarity scores, and the ids\n \"\"\"\n ...\n\n @abstractmethod\n def drop(self):\n \"\"\"Drop the vector store\"\"\"\n ...\n
Name Type Description Default embeddingslist[list[float]] | list[DocumentWithEmbedding]
List of embeddings
required metadatasOptional[list[dict]]
List of metadata of the embeddings
NoneidsOptional[list[str]]
List of ids of the embeddings
Nonekwargs
meant for vectorstore-specific parameters
required
Returns:
Type Description list[str]
List of ids of the embeddings
Source code in libs/kotaemon/kotaemon/storages/vectorstores/base.py
@abstractmethod\ndef add(\n self,\n embeddings: list[list[float]] | list[DocumentWithEmbedding],\n metadatas: Optional[list[dict]] = None,\n ids: Optional[list[str]] = None,\n) -> list[str]:\n \"\"\"Add vector embeddings to vector stores\n\n Args:\n embeddings: List of embeddings\n metadatas: List of metadata of the embeddings\n ids: List of ids of the embeddings\n kwargs: meant for vectorstore-specific parameters\n\n Returns:\n List of ids of the embeddings\n \"\"\"\n ...\n
{} Source code in libs/kotaemon/kotaemon/storages/vectorstores/base.py
@abstractmethod\ndef delete(self, ids: list[str], **kwargs):\n \"\"\"Delete vector embeddings from vector stores\n\n Args:\n ids: List of ids of the embeddings to be deleted\n kwargs: meant for vectorstore-specific parameters\n \"\"\"\n ...\n
Name Type Description Default embeddinglist[float]
List of embeddings
required top_kint
Number of most similar embeddings to return
1idsOptional[list[str]]
List of ids of the embeddings to be queried
None
Returns:
Type Description tuple[list[list[float]], list[float], list[str]]
the matched embeddings, the similarity scores, and the ids
Source code in libs/kotaemon/kotaemon/storages/vectorstores/base.py
@abstractmethod\ndef query(\n self,\n embedding: list[float],\n top_k: int = 1,\n ids: Optional[list[str]] = None,\n **kwargs,\n) -> tuple[list[list[float]], list[float], list[str]]:\n \"\"\"Return the top k most similar vector embeddings\n\n Args:\n embedding: List of embeddings\n top_k: Number of most similar embeddings to return\n ids: List of ids of the embeddings to be queried\n\n Returns:\n the matched embeddings, the similarity scores, and the ids\n \"\"\"\n ...\n
{} Source code in libs/kotaemon/kotaemon/storages/vectorstores/chroma.py
def delete(self, ids: List[str], **kwargs):\n \"\"\"Delete vector embeddings from vector stores\n\n Args:\n ids: List of ids of the embeddings to be deleted\n kwargs: meant for vectorstore-specific parameters\n \"\"\"\n self._client.client.delete(ids=ids)\n
None Source code in libs/kotaemon/kotaemon/storages/vectorstores/in_memory.py
def save(\n self,\n save_path: str,\n fs: Optional[fsspec.AbstractFileSystem] = None,\n **kwargs,\n):\n\n \"\"\"save a simpleVectorStore to a dictionary.\n\n Args:\n save_path: Path of saving vector to disk.\n fs: An abstract super-class for pythonic file-systems\n \"\"\"\n self._client.persist(persist_path=save_path, fs=fs)\n
{} Source code in libs/kotaemon/kotaemon/storages/vectorstores/lancedb.py
def delete(self, ids: List[str], **kwargs):\n \"\"\"Delete vector embeddings from vector stores\n\n Args:\n ids: List of ids of the embeddings to be deleted\n kwargs: meant for vectorstore-specific parameters\n \"\"\"\n self._client.delete_nodes(ids)\n
{} Source code in libs/kotaemon/kotaemon/storages/vectorstores/qdrant.py
def delete(self, ids: List[str], **kwargs):\n \"\"\"Delete vector embeddings from vector stores\n\n Args:\n ids: List of ids of the embeddings to be deleted\n kwargs: meant for vectorstore-specific parameters\n \"\"\"\n from qdrant_client import models\n\n self._client.client.delete(\n collection_name=self._collection_name,\n points_selector=models.PointIdsList(\n points=ids,\n ),\n **kwargs,\n )\n
A document store is in charged of storing and managing documents
Source code in libs/kotaemon/kotaemon/storages/docstores/base.py
class BaseDocumentStore(ABC):\n \"\"\"A document store is in charged of storing and managing documents\"\"\"\n\n @abstractmethod\n def __init__(self, *args, **kwargs):\n ...\n\n @abstractmethod\n def add(\n self,\n docs: Union[Document, List[Document]],\n ids: Optional[Union[List[str], str]] = None,\n **kwargs,\n ):\n \"\"\"Add document into document store\n\n Args:\n docs: Document or list of documents\n ids: List of ids of the documents. Optional, if not set will use doc.doc_id\n \"\"\"\n ...\n\n @abstractmethod\n def get(self, ids: Union[List[str], str]) -> List[Document]:\n \"\"\"Get document by id\"\"\"\n ...\n\n @abstractmethod\n def get_all(self) -> List[Document]:\n \"\"\"Get all documents\"\"\"\n ...\n\n @abstractmethod\n def count(self) -> int:\n \"\"\"Count number of documents\"\"\"\n ...\n\n @abstractmethod\n def query(\n self, query: str, top_k: int = 10, doc_ids: Optional[list] = None\n ) -> List[Document]:\n \"\"\"Search document store using search query\"\"\"\n ...\n\n @abstractmethod\n def delete(self, ids: Union[List[str], str]):\n \"\"\"Delete document by id\"\"\"\n ...\n\n @abstractmethod\n def drop(self):\n \"\"\"Drop the document store\"\"\"\n ...\n
Name Type Description Default docsUnion[Document, List[Document]]
Document or list of documents
required idsOptional[Union[List[str], str]]
List of ids of the documents. Optional, if not set will use doc.doc_id
None Source code in libs/kotaemon/kotaemon/storages/docstores/base.py
@abstractmethod\ndef add(\n self,\n docs: Union[Document, List[Document]],\n ids: Optional[Union[List[str], str]] = None,\n **kwargs,\n):\n \"\"\"Add document into document store\n\n Args:\n docs: Document or list of documents\n ids: List of ids of the documents. Optional, if not set will use doc.doc_id\n \"\"\"\n ...\n
Name Type Description Default docsUnion[Document, List[Document]]
list of documents to add
required idsOptional[Union[List[str], str]]
specify the ids of documents to add or use existing doc.doc_id
Nonerefresh_indicesbool
request Elasticsearch to update its index (default to True)
True Source code in libs/kotaemon/kotaemon/storages/docstores/elasticsearch.py
def add(\n self,\n docs: Union[Document, List[Document]],\n ids: Optional[Union[List[str], str]] = None,\n refresh_indices: bool = True,\n **kwargs,\n):\n \"\"\"Add document into document store\n\n Args:\n docs: list of documents to add\n ids: specify the ids of documents to add or use existing doc.doc_id\n refresh_indices: request Elasticsearch to update its index (default to True)\n \"\"\"\n if ids and not isinstance(ids, list):\n ids = [ids]\n if not isinstance(docs, list):\n docs = [docs]\n doc_ids = ids if ids else [doc.doc_id for doc in docs]\n\n requests = []\n for doc_id, doc in zip(doc_ids, docs):\n text = doc.text\n metadata = doc.metadata\n request = {\n \"_op_type\": \"index\",\n \"_index\": self.index_name,\n \"content\": text,\n \"metadata\": metadata,\n \"_id\": doc_id,\n }\n requests.append(request)\n\n success, failed = self.es_bulk(self.client, requests)\n print(\"Added/Updated documents to index\", success)\n print(\"Failed documents to index\", failed)\n\n if refresh_indices:\n self.client.indices.refresh(index=self.index_name)\n
Query Elasticsearch store using query format of ES client
Parameters:
Name Type Description Default querydict
Elasticsearch query format
required
Returns:
Type Description List[Document]
List[Document]: List of result documents
Source code in libs/kotaemon/kotaemon/storages/docstores/elasticsearch.py
def query_raw(self, query: dict) -> List[Document]:\n \"\"\"Query Elasticsearch store using query format of ES client\n\n Args:\n query (dict): Elasticsearch query format\n\n Returns:\n List[Document]: List of result documents\n \"\"\"\n res = self.client.search(index=self.index_name, body=query)\n docs = []\n for r in res[\"hits\"][\"hits\"]:\n docs.append(\n Document(\n id_=r[\"_id\"],\n text=r[\"_source\"][\"content\"],\n metadata=r[\"_source\"][\"metadata\"],\n )\n )\n return docs\n
Simple memory document store that store document in a dictionary
Source code in libs/kotaemon/kotaemon/storages/docstores/in_memory.py
class InMemoryDocumentStore(BaseDocumentStore):\n \"\"\"Simple memory document store that store document in a dictionary\"\"\"\n\n def __init__(self):\n self._store = {}\n\n def add(\n self,\n docs: Union[Document, List[Document]],\n ids: Optional[Union[List[str], str]] = None,\n **kwargs,\n ):\n \"\"\"Add document into document store\n\n Args:\n docs: list of documents to add\n ids: specify the ids of documents to add or\n use existing doc.doc_id\n exist_ok: raise error when duplicate doc-id\n found in the docstore (default to False)\n \"\"\"\n exist_ok: bool = kwargs.pop(\"exist_ok\", False)\n\n if ids and not isinstance(ids, list):\n ids = [ids]\n if not isinstance(docs, list):\n docs = [docs]\n doc_ids = ids if ids else [doc.doc_id for doc in docs]\n\n for doc_id, doc in zip(doc_ids, docs):\n if doc_id in self._store and not exist_ok:\n raise ValueError(f\"Document with id {doc_id} already exist\")\n self._store[doc_id] = doc\n\n def get(self, ids: Union[List[str], str]) -> List[Document]:\n \"\"\"Get document by id\"\"\"\n if not isinstance(ids, list):\n ids = [ids]\n\n return [self._store[doc_id] for doc_id in ids]\n\n def get_all(self) -> List[Document]:\n \"\"\"Get all documents\"\"\"\n return list(self._store.values())\n\n def count(self) -> int:\n \"\"\"Count number of documents\"\"\"\n return len(self._store)\n\n def delete(self, ids: Union[List[str], str]):\n \"\"\"Delete document by id\"\"\"\n if not isinstance(ids, list):\n ids = [ids]\n\n for doc_id in ids:\n del self._store[doc_id]\n\n def save(self, path: Union[str, Path]):\n \"\"\"Save document to path\"\"\"\n store = {key: value.to_dict() for key, value in self._store.items()}\n with open(path, \"w\") as f:\n json.dump(store, f)\n\n def load(self, path: Union[str, Path]):\n \"\"\"Load document store from path\"\"\"\n with open(path) as f:\n store = json.load(f)\n # TODO: save and load aren't lossless. A Document-subclass will lose\n # information. Need to edit the `to_dict` and `from_dict` methods in\n # the Document class.\n # For better query support, utilize SQLite as the default document store.\n # Also, for portability, use SQLAlchemy for document store.\n self._store = {key: Document.from_dict(value) for key, value in store.items()}\n\n def query(\n self, query: str, top_k: int = 10, doc_ids: Optional[list] = None\n ) -> List[Document]:\n \"\"\"Perform full-text search on document store\"\"\"\n return []\n\n def __persist_flow__(self):\n return {}\n\n def drop(self):\n \"\"\"Drop the document store\"\"\"\n self._store = {}\n
Name Type Description Default docsUnion[Document, List[Document]]
list of documents to add
required idsOptional[Union[List[str], str]]
specify the ids of documents to add or use existing doc.doc_id
Noneexist_ok
raise error when duplicate doc-id found in the docstore (default to False)
required Source code in libs/kotaemon/kotaemon/storages/docstores/in_memory.py
def add(\n self,\n docs: Union[Document, List[Document]],\n ids: Optional[Union[List[str], str]] = None,\n **kwargs,\n):\n \"\"\"Add document into document store\n\n Args:\n docs: list of documents to add\n ids: specify the ids of documents to add or\n use existing doc.doc_id\n exist_ok: raise error when duplicate doc-id\n found in the docstore (default to False)\n \"\"\"\n exist_ok: bool = kwargs.pop(\"exist_ok\", False)\n\n if ids and not isinstance(ids, list):\n ids = [ids]\n if not isinstance(docs, list):\n docs = [docs]\n doc_ids = ids if ids else [doc.doc_id for doc in docs]\n\n for doc_id, doc in zip(doc_ids, docs):\n if doc_id in self._store and not exist_ok:\n raise ValueError(f\"Document with id {doc_id} already exist\")\n self._store[doc_id] = doc\n
Source code in libs/kotaemon/kotaemon/storages/docstores/in_memory.py
def get(self, ids: Union[List[str], str]) -> List[Document]:\n \"\"\"Get document by id\"\"\"\n if not isinstance(ids, list):\n ids = [ids]\n\n return [self._store[doc_id] for doc_id in ids]\n
Source code in libs/kotaemon/kotaemon/storages/docstores/in_memory.py
def delete(self, ids: Union[List[str], str]):\n \"\"\"Delete document by id\"\"\"\n if not isinstance(ids, list):\n ids = [ids]\n\n for doc_id in ids:\n del self._store[doc_id]\n
Source code in libs/kotaemon/kotaemon/storages/docstores/in_memory.py
def save(self, path: Union[str, Path]):\n \"\"\"Save document to path\"\"\"\n store = {key: value.to_dict() for key, value in self._store.items()}\n with open(path, \"w\") as f:\n json.dump(store, f)\n
Source code in libs/kotaemon/kotaemon/storages/docstores/in_memory.py
def load(self, path: Union[str, Path]):\n \"\"\"Load document store from path\"\"\"\n with open(path) as f:\n store = json.load(f)\n # TODO: save and load aren't lossless. A Document-subclass will lose\n # information. Need to edit the `to_dict` and `from_dict` methods in\n # the Document class.\n # For better query support, utilize SQLite as the default document store.\n # Also, for portability, use SQLAlchemy for document store.\n self._store = {key: Document.from_dict(value) for key, value in store.items()}\n
Improve InMemoryDocumentStore by auto saving whenever the corpus is changed
Source code in libs/kotaemon/kotaemon/storages/docstores/simple_file.py
class SimpleFileDocumentStore(InMemoryDocumentStore):\n \"\"\"Improve InMemoryDocumentStore by auto saving whenever the corpus is changed\"\"\"\n\n def __init__(self, path: str | Path, collection_name: str = \"default\"):\n super().__init__()\n self._path = path\n self._collection_name = collection_name\n\n Path(path).mkdir(parents=True, exist_ok=True)\n self._save_path = Path(path) / f\"{collection_name}.json\"\n if self._save_path.is_file():\n self.load(self._save_path)\n\n def get(self, ids: Union[List[str], str]) -> List[Document]:\n \"\"\"Get document by id\"\"\"\n if not isinstance(ids, list):\n ids = [ids]\n\n for doc_id in ids:\n if doc_id not in self._store:\n self.load(self._save_path)\n break\n\n return [self._store[doc_id] for doc_id in ids]\n\n def add(\n self,\n docs: Union[Document, List[Document]],\n ids: Optional[Union[List[str], str]] = None,\n **kwargs,\n ):\n \"\"\"Add document into document store\n\n Args:\n docs: list of documents to add\n ids: specify the ids of documents to add or\n use existing doc.doc_id\n exist_ok: raise error when duplicate doc-id\n found in the docstore (default to False)\n \"\"\"\n super().add(docs=docs, ids=ids, **kwargs)\n self.save(self._save_path)\n\n def delete(self, ids: Union[List[str], str]):\n \"\"\"Delete document by id\"\"\"\n super().delete(ids=ids)\n self.save(self._save_path)\n\n def drop(self):\n \"\"\"Drop the document store\"\"\"\n super().drop()\n self._save_path.unlink(missing_ok=True)\n\n def __persist_flow__(self):\n from theflow.utils.modules import serialize\n\n return {\n \"path\": serialize(self._path),\n \"collection_name\": self._collection_name,\n }\n
Source code in libs/kotaemon/kotaemon/storages/docstores/simple_file.py
def get(self, ids: Union[List[str], str]) -> List[Document]:\n \"\"\"Get document by id\"\"\"\n if not isinstance(ids, list):\n ids = [ids]\n\n for doc_id in ids:\n if doc_id not in self._store:\n self.load(self._save_path)\n break\n\n return [self._store[doc_id] for doc_id in ids]\n
Name Type Description Default docsUnion[Document, List[Document]]
list of documents to add
required idsOptional[Union[List[str], str]]
specify the ids of documents to add or use existing doc.doc_id
Noneexist_ok
raise error when duplicate doc-id found in the docstore (default to False)
required Source code in libs/kotaemon/kotaemon/storages/docstores/simple_file.py
def add(\n self,\n docs: Union[Document, List[Document]],\n ids: Optional[Union[List[str], str]] = None,\n **kwargs,\n):\n \"\"\"Add document into document store\n\n Args:\n docs: list of documents to add\n ids: specify the ids of documents to add or\n use existing doc.doc_id\n exist_ok: raise error when duplicate doc-id\n found in the docstore (default to False)\n \"\"\"\n super().add(docs=docs, ids=ids, **kwargs)\n self.save(self._save_path)\n
A document store is in charged of storing and managing documents
Source code in libs/kotaemon/kotaemon/storages/docstores/base.py
class BaseDocumentStore(ABC):\n \"\"\"A document store is in charged of storing and managing documents\"\"\"\n\n @abstractmethod\n def __init__(self, *args, **kwargs):\n ...\n\n @abstractmethod\n def add(\n self,\n docs: Union[Document, List[Document]],\n ids: Optional[Union[List[str], str]] = None,\n **kwargs,\n ):\n \"\"\"Add document into document store\n\n Args:\n docs: Document or list of documents\n ids: List of ids of the documents. Optional, if not set will use doc.doc_id\n \"\"\"\n ...\n\n @abstractmethod\n def get(self, ids: Union[List[str], str]) -> List[Document]:\n \"\"\"Get document by id\"\"\"\n ...\n\n @abstractmethod\n def get_all(self) -> List[Document]:\n \"\"\"Get all documents\"\"\"\n ...\n\n @abstractmethod\n def count(self) -> int:\n \"\"\"Count number of documents\"\"\"\n ...\n\n @abstractmethod\n def query(\n self, query: str, top_k: int = 10, doc_ids: Optional[list] = None\n ) -> List[Document]:\n \"\"\"Search document store using search query\"\"\"\n ...\n\n @abstractmethod\n def delete(self, ids: Union[List[str], str]):\n \"\"\"Delete document by id\"\"\"\n ...\n\n @abstractmethod\n def drop(self):\n \"\"\"Drop the document store\"\"\"\n ...\n
Name Type Description Default docsUnion[Document, List[Document]]
Document or list of documents
required idsOptional[Union[List[str], str]]
List of ids of the documents. Optional, if not set will use doc.doc_id
None Source code in libs/kotaemon/kotaemon/storages/docstores/base.py
@abstractmethod\ndef add(\n self,\n docs: Union[Document, List[Document]],\n ids: Optional[Union[List[str], str]] = None,\n **kwargs,\n):\n \"\"\"Add document into document store\n\n Args:\n docs: Document or list of documents\n ids: List of ids of the documents. Optional, if not set will use doc.doc_id\n \"\"\"\n ...\n
Name Type Description Default docsUnion[Document, List[Document]]
list of documents to add
required idsOptional[Union[List[str], str]]
specify the ids of documents to add or use existing doc.doc_id
Nonerefresh_indicesbool
request Elasticsearch to update its index (default to True)
True Source code in libs/kotaemon/kotaemon/storages/docstores/elasticsearch.py
def add(\n self,\n docs: Union[Document, List[Document]],\n ids: Optional[Union[List[str], str]] = None,\n refresh_indices: bool = True,\n **kwargs,\n):\n \"\"\"Add document into document store\n\n Args:\n docs: list of documents to add\n ids: specify the ids of documents to add or use existing doc.doc_id\n refresh_indices: request Elasticsearch to update its index (default to True)\n \"\"\"\n if ids and not isinstance(ids, list):\n ids = [ids]\n if not isinstance(docs, list):\n docs = [docs]\n doc_ids = ids if ids else [doc.doc_id for doc in docs]\n\n requests = []\n for doc_id, doc in zip(doc_ids, docs):\n text = doc.text\n metadata = doc.metadata\n request = {\n \"_op_type\": \"index\",\n \"_index\": self.index_name,\n \"content\": text,\n \"metadata\": metadata,\n \"_id\": doc_id,\n }\n requests.append(request)\n\n success, failed = self.es_bulk(self.client, requests)\n print(\"Added/Updated documents to index\", success)\n print(\"Failed documents to index\", failed)\n\n if refresh_indices:\n self.client.indices.refresh(index=self.index_name)\n
Query Elasticsearch store using query format of ES client
Parameters:
Name Type Description Default querydict
Elasticsearch query format
required
Returns:
Type Description List[Document]
List[Document]: List of result documents
Source code in libs/kotaemon/kotaemon/storages/docstores/elasticsearch.py
def query_raw(self, query: dict) -> List[Document]:\n \"\"\"Query Elasticsearch store using query format of ES client\n\n Args:\n query (dict): Elasticsearch query format\n\n Returns:\n List[Document]: List of result documents\n \"\"\"\n res = self.client.search(index=self.index_name, body=query)\n docs = []\n for r in res[\"hits\"][\"hits\"]:\n docs.append(\n Document(\n id_=r[\"_id\"],\n text=r[\"_source\"][\"content\"],\n metadata=r[\"_source\"][\"metadata\"],\n )\n )\n return docs\n
Simple memory document store that store document in a dictionary
Source code in libs/kotaemon/kotaemon/storages/docstores/in_memory.py
class InMemoryDocumentStore(BaseDocumentStore):\n \"\"\"Simple memory document store that store document in a dictionary\"\"\"\n\n def __init__(self):\n self._store = {}\n\n def add(\n self,\n docs: Union[Document, List[Document]],\n ids: Optional[Union[List[str], str]] = None,\n **kwargs,\n ):\n \"\"\"Add document into document store\n\n Args:\n docs: list of documents to add\n ids: specify the ids of documents to add or\n use existing doc.doc_id\n exist_ok: raise error when duplicate doc-id\n found in the docstore (default to False)\n \"\"\"\n exist_ok: bool = kwargs.pop(\"exist_ok\", False)\n\n if ids and not isinstance(ids, list):\n ids = [ids]\n if not isinstance(docs, list):\n docs = [docs]\n doc_ids = ids if ids else [doc.doc_id for doc in docs]\n\n for doc_id, doc in zip(doc_ids, docs):\n if doc_id in self._store and not exist_ok:\n raise ValueError(f\"Document with id {doc_id} already exist\")\n self._store[doc_id] = doc\n\n def get(self, ids: Union[List[str], str]) -> List[Document]:\n \"\"\"Get document by id\"\"\"\n if not isinstance(ids, list):\n ids = [ids]\n\n return [self._store[doc_id] for doc_id in ids]\n\n def get_all(self) -> List[Document]:\n \"\"\"Get all documents\"\"\"\n return list(self._store.values())\n\n def count(self) -> int:\n \"\"\"Count number of documents\"\"\"\n return len(self._store)\n\n def delete(self, ids: Union[List[str], str]):\n \"\"\"Delete document by id\"\"\"\n if not isinstance(ids, list):\n ids = [ids]\n\n for doc_id in ids:\n del self._store[doc_id]\n\n def save(self, path: Union[str, Path]):\n \"\"\"Save document to path\"\"\"\n store = {key: value.to_dict() for key, value in self._store.items()}\n with open(path, \"w\") as f:\n json.dump(store, f)\n\n def load(self, path: Union[str, Path]):\n \"\"\"Load document store from path\"\"\"\n with open(path) as f:\n store = json.load(f)\n # TODO: save and load aren't lossless. A Document-subclass will lose\n # information. Need to edit the `to_dict` and `from_dict` methods in\n # the Document class.\n # For better query support, utilize SQLite as the default document store.\n # Also, for portability, use SQLAlchemy for document store.\n self._store = {key: Document.from_dict(value) for key, value in store.items()}\n\n def query(\n self, query: str, top_k: int = 10, doc_ids: Optional[list] = None\n ) -> List[Document]:\n \"\"\"Perform full-text search on document store\"\"\"\n return []\n\n def __persist_flow__(self):\n return {}\n\n def drop(self):\n \"\"\"Drop the document store\"\"\"\n self._store = {}\n
Name Type Description Default docsUnion[Document, List[Document]]
list of documents to add
required idsOptional[Union[List[str], str]]
specify the ids of documents to add or use existing doc.doc_id
Noneexist_ok
raise error when duplicate doc-id found in the docstore (default to False)
required Source code in libs/kotaemon/kotaemon/storages/docstores/in_memory.py
def add(\n self,\n docs: Union[Document, List[Document]],\n ids: Optional[Union[List[str], str]] = None,\n **kwargs,\n):\n \"\"\"Add document into document store\n\n Args:\n docs: list of documents to add\n ids: specify the ids of documents to add or\n use existing doc.doc_id\n exist_ok: raise error when duplicate doc-id\n found in the docstore (default to False)\n \"\"\"\n exist_ok: bool = kwargs.pop(\"exist_ok\", False)\n\n if ids and not isinstance(ids, list):\n ids = [ids]\n if not isinstance(docs, list):\n docs = [docs]\n doc_ids = ids if ids else [doc.doc_id for doc in docs]\n\n for doc_id, doc in zip(doc_ids, docs):\n if doc_id in self._store and not exist_ok:\n raise ValueError(f\"Document with id {doc_id} already exist\")\n self._store[doc_id] = doc\n
Source code in libs/kotaemon/kotaemon/storages/docstores/in_memory.py
def get(self, ids: Union[List[str], str]) -> List[Document]:\n \"\"\"Get document by id\"\"\"\n if not isinstance(ids, list):\n ids = [ids]\n\n return [self._store[doc_id] for doc_id in ids]\n
Source code in libs/kotaemon/kotaemon/storages/docstores/in_memory.py
def delete(self, ids: Union[List[str], str]):\n \"\"\"Delete document by id\"\"\"\n if not isinstance(ids, list):\n ids = [ids]\n\n for doc_id in ids:\n del self._store[doc_id]\n
Source code in libs/kotaemon/kotaemon/storages/docstores/in_memory.py
def save(self, path: Union[str, Path]):\n \"\"\"Save document to path\"\"\"\n store = {key: value.to_dict() for key, value in self._store.items()}\n with open(path, \"w\") as f:\n json.dump(store, f)\n
Source code in libs/kotaemon/kotaemon/storages/docstores/in_memory.py
def load(self, path: Union[str, Path]):\n \"\"\"Load document store from path\"\"\"\n with open(path) as f:\n store = json.load(f)\n # TODO: save and load aren't lossless. A Document-subclass will lose\n # information. Need to edit the `to_dict` and `from_dict` methods in\n # the Document class.\n # For better query support, utilize SQLite as the default document store.\n # Also, for portability, use SQLAlchemy for document store.\n self._store = {key: Document.from_dict(value) for key, value in store.items()}\n
Improve InMemoryDocumentStore by auto saving whenever the corpus is changed
Source code in libs/kotaemon/kotaemon/storages/docstores/simple_file.py
class SimpleFileDocumentStore(InMemoryDocumentStore):\n \"\"\"Improve InMemoryDocumentStore by auto saving whenever the corpus is changed\"\"\"\n\n def __init__(self, path: str | Path, collection_name: str = \"default\"):\n super().__init__()\n self._path = path\n self._collection_name = collection_name\n\n Path(path).mkdir(parents=True, exist_ok=True)\n self._save_path = Path(path) / f\"{collection_name}.json\"\n if self._save_path.is_file():\n self.load(self._save_path)\n\n def get(self, ids: Union[List[str], str]) -> List[Document]:\n \"\"\"Get document by id\"\"\"\n if not isinstance(ids, list):\n ids = [ids]\n\n for doc_id in ids:\n if doc_id not in self._store:\n self.load(self._save_path)\n break\n\n return [self._store[doc_id] for doc_id in ids]\n\n def add(\n self,\n docs: Union[Document, List[Document]],\n ids: Optional[Union[List[str], str]] = None,\n **kwargs,\n ):\n \"\"\"Add document into document store\n\n Args:\n docs: list of documents to add\n ids: specify the ids of documents to add or\n use existing doc.doc_id\n exist_ok: raise error when duplicate doc-id\n found in the docstore (default to False)\n \"\"\"\n super().add(docs=docs, ids=ids, **kwargs)\n self.save(self._save_path)\n\n def delete(self, ids: Union[List[str], str]):\n \"\"\"Delete document by id\"\"\"\n super().delete(ids=ids)\n self.save(self._save_path)\n\n def drop(self):\n \"\"\"Drop the document store\"\"\"\n super().drop()\n self._save_path.unlink(missing_ok=True)\n\n def __persist_flow__(self):\n from theflow.utils.modules import serialize\n\n return {\n \"path\": serialize(self._path),\n \"collection_name\": self._collection_name,\n }\n
Source code in libs/kotaemon/kotaemon/storages/docstores/simple_file.py
def get(self, ids: Union[List[str], str]) -> List[Document]:\n \"\"\"Get document by id\"\"\"\n if not isinstance(ids, list):\n ids = [ids]\n\n for doc_id in ids:\n if doc_id not in self._store:\n self.load(self._save_path)\n break\n\n return [self._store[doc_id] for doc_id in ids]\n
Name Type Description Default docsUnion[Document, List[Document]]
list of documents to add
required idsOptional[Union[List[str], str]]
specify the ids of documents to add or use existing doc.doc_id
Noneexist_ok
raise error when duplicate doc-id found in the docstore (default to False)
required Source code in libs/kotaemon/kotaemon/storages/docstores/simple_file.py
def add(\n self,\n docs: Union[Document, List[Document]],\n ids: Optional[Union[List[str], str]] = None,\n **kwargs,\n):\n \"\"\"Add document into document store\n\n Args:\n docs: list of documents to add\n ids: specify the ids of documents to add or\n use existing doc.doc_id\n exist_ok: raise error when duplicate doc-id\n found in the docstore (default to False)\n \"\"\"\n super().add(docs=docs, ids=ids, **kwargs)\n self.save(self._save_path)\n
Source code in libs/kotaemon/kotaemon/storages/vectorstores/base.py
class BaseVectorStore(ABC):\n @abstractmethod\n def __init__(self, *args, **kwargs):\n ...\n\n @abstractmethod\n def add(\n self,\n embeddings: list[list[float]] | list[DocumentWithEmbedding],\n metadatas: Optional[list[dict]] = None,\n ids: Optional[list[str]] = None,\n ) -> list[str]:\n \"\"\"Add vector embeddings to vector stores\n\n Args:\n embeddings: List of embeddings\n metadatas: List of metadata of the embeddings\n ids: List of ids of the embeddings\n kwargs: meant for vectorstore-specific parameters\n\n Returns:\n List of ids of the embeddings\n \"\"\"\n ...\n\n @abstractmethod\n def delete(self, ids: list[str], **kwargs):\n \"\"\"Delete vector embeddings from vector stores\n\n Args:\n ids: List of ids of the embeddings to be deleted\n kwargs: meant for vectorstore-specific parameters\n \"\"\"\n ...\n\n @abstractmethod\n def query(\n self,\n embedding: list[float],\n top_k: int = 1,\n ids: Optional[list[str]] = None,\n **kwargs,\n ) -> tuple[list[list[float]], list[float], list[str]]:\n \"\"\"Return the top k most similar vector embeddings\n\n Args:\n embedding: List of embeddings\n top_k: Number of most similar embeddings to return\n ids: List of ids of the embeddings to be queried\n\n Returns:\n the matched embeddings, the similarity scores, and the ids\n \"\"\"\n ...\n\n @abstractmethod\n def drop(self):\n \"\"\"Drop the vector store\"\"\"\n ...\n
Name Type Description Default embeddingslist[list[float]] | list[DocumentWithEmbedding]
List of embeddings
required metadatasOptional[list[dict]]
List of metadata of the embeddings
NoneidsOptional[list[str]]
List of ids of the embeddings
Nonekwargs
meant for vectorstore-specific parameters
required
Returns:
Type Description list[str]
List of ids of the embeddings
Source code in libs/kotaemon/kotaemon/storages/vectorstores/base.py
@abstractmethod\ndef add(\n self,\n embeddings: list[list[float]] | list[DocumentWithEmbedding],\n metadatas: Optional[list[dict]] = None,\n ids: Optional[list[str]] = None,\n) -> list[str]:\n \"\"\"Add vector embeddings to vector stores\n\n Args:\n embeddings: List of embeddings\n metadatas: List of metadata of the embeddings\n ids: List of ids of the embeddings\n kwargs: meant for vectorstore-specific parameters\n\n Returns:\n List of ids of the embeddings\n \"\"\"\n ...\n
{} Source code in libs/kotaemon/kotaemon/storages/vectorstores/base.py
@abstractmethod\ndef delete(self, ids: list[str], **kwargs):\n \"\"\"Delete vector embeddings from vector stores\n\n Args:\n ids: List of ids of the embeddings to be deleted\n kwargs: meant for vectorstore-specific parameters\n \"\"\"\n ...\n
Name Type Description Default embeddinglist[float]
List of embeddings
required top_kint
Number of most similar embeddings to return
1idsOptional[list[str]]
List of ids of the embeddings to be queried
None
Returns:
Type Description tuple[list[list[float]], list[float], list[str]]
the matched embeddings, the similarity scores, and the ids
Source code in libs/kotaemon/kotaemon/storages/vectorstores/base.py
@abstractmethod\ndef query(\n self,\n embedding: list[float],\n top_k: int = 1,\n ids: Optional[list[str]] = None,\n **kwargs,\n) -> tuple[list[list[float]], list[float], list[str]]:\n \"\"\"Return the top k most similar vector embeddings\n\n Args:\n embedding: List of embeddings\n top_k: Number of most similar embeddings to return\n ids: List of ids of the embeddings to be queried\n\n Returns:\n the matched embeddings, the similarity scores, and the ids\n \"\"\"\n ...\n
{} Source code in libs/kotaemon/kotaemon/storages/vectorstores/chroma.py
def delete(self, ids: List[str], **kwargs):\n \"\"\"Delete vector embeddings from vector stores\n\n Args:\n ids: List of ids of the embeddings to be deleted\n kwargs: meant for vectorstore-specific parameters\n \"\"\"\n self._client.client.delete(ids=ids)\n
None Source code in libs/kotaemon/kotaemon/storages/vectorstores/in_memory.py
def save(\n self,\n save_path: str,\n fs: Optional[fsspec.AbstractFileSystem] = None,\n **kwargs,\n):\n\n \"\"\"save a simpleVectorStore to a dictionary.\n\n Args:\n save_path: Path of saving vector to disk.\n fs: An abstract super-class for pythonic file-systems\n \"\"\"\n self._client.persist(persist_path=save_path, fs=fs)\n
{} Source code in libs/kotaemon/kotaemon/storages/vectorstores/lancedb.py
def delete(self, ids: List[str], **kwargs):\n \"\"\"Delete vector embeddings from vector stores\n\n Args:\n ids: List of ids of the embeddings to be deleted\n kwargs: meant for vectorstore-specific parameters\n \"\"\"\n self._client.delete_nodes(ids)\n
{} Source code in libs/kotaemon/kotaemon/storages/vectorstores/qdrant.py
def delete(self, ids: List[str], **kwargs):\n \"\"\"Delete vector embeddings from vector stores\n\n Args:\n ids: List of ids of the embeddings to be deleted\n kwargs: meant for vectorstore-specific parameters\n \"\"\"\n from qdrant_client import models\n\n self._client.client.delete(\n collection_name=self._collection_name,\n points_selector=models.PointIdsList(\n points=ids,\n ),\n **kwargs,\n )\n
Source code in libs/kotaemon/kotaemon/storages/vectorstores/base.py
class BaseVectorStore(ABC):\n @abstractmethod\n def __init__(self, *args, **kwargs):\n ...\n\n @abstractmethod\n def add(\n self,\n embeddings: list[list[float]] | list[DocumentWithEmbedding],\n metadatas: Optional[list[dict]] = None,\n ids: Optional[list[str]] = None,\n ) -> list[str]:\n \"\"\"Add vector embeddings to vector stores\n\n Args:\n embeddings: List of embeddings\n metadatas: List of metadata of the embeddings\n ids: List of ids of the embeddings\n kwargs: meant for vectorstore-specific parameters\n\n Returns:\n List of ids of the embeddings\n \"\"\"\n ...\n\n @abstractmethod\n def delete(self, ids: list[str], **kwargs):\n \"\"\"Delete vector embeddings from vector stores\n\n Args:\n ids: List of ids of the embeddings to be deleted\n kwargs: meant for vectorstore-specific parameters\n \"\"\"\n ...\n\n @abstractmethod\n def query(\n self,\n embedding: list[float],\n top_k: int = 1,\n ids: Optional[list[str]] = None,\n **kwargs,\n ) -> tuple[list[list[float]], list[float], list[str]]:\n \"\"\"Return the top k most similar vector embeddings\n\n Args:\n embedding: List of embeddings\n top_k: Number of most similar embeddings to return\n ids: List of ids of the embeddings to be queried\n\n Returns:\n the matched embeddings, the similarity scores, and the ids\n \"\"\"\n ...\n\n @abstractmethod\n def drop(self):\n \"\"\"Drop the vector store\"\"\"\n ...\n
Name Type Description Default embeddingslist[list[float]] | list[DocumentWithEmbedding]
List of embeddings
required metadatasOptional[list[dict]]
List of metadata of the embeddings
NoneidsOptional[list[str]]
List of ids of the embeddings
Nonekwargs
meant for vectorstore-specific parameters
required
Returns:
Type Description list[str]
List of ids of the embeddings
Source code in libs/kotaemon/kotaemon/storages/vectorstores/base.py
@abstractmethod\ndef add(\n self,\n embeddings: list[list[float]] | list[DocumentWithEmbedding],\n metadatas: Optional[list[dict]] = None,\n ids: Optional[list[str]] = None,\n) -> list[str]:\n \"\"\"Add vector embeddings to vector stores\n\n Args:\n embeddings: List of embeddings\n metadatas: List of metadata of the embeddings\n ids: List of ids of the embeddings\n kwargs: meant for vectorstore-specific parameters\n\n Returns:\n List of ids of the embeddings\n \"\"\"\n ...\n
{} Source code in libs/kotaemon/kotaemon/storages/vectorstores/base.py
@abstractmethod\ndef delete(self, ids: list[str], **kwargs):\n \"\"\"Delete vector embeddings from vector stores\n\n Args:\n ids: List of ids of the embeddings to be deleted\n kwargs: meant for vectorstore-specific parameters\n \"\"\"\n ...\n
Name Type Description Default embeddinglist[float]
List of embeddings
required top_kint
Number of most similar embeddings to return
1idsOptional[list[str]]
List of ids of the embeddings to be queried
None
Returns:
Type Description tuple[list[list[float]], list[float], list[str]]
the matched embeddings, the similarity scores, and the ids
Source code in libs/kotaemon/kotaemon/storages/vectorstores/base.py
@abstractmethod\ndef query(\n self,\n embedding: list[float],\n top_k: int = 1,\n ids: Optional[list[str]] = None,\n **kwargs,\n) -> tuple[list[list[float]], list[float], list[str]]:\n \"\"\"Return the top k most similar vector embeddings\n\n Args:\n embedding: List of embeddings\n top_k: Number of most similar embeddings to return\n ids: List of ids of the embeddings to be queried\n\n Returns:\n the matched embeddings, the similarity scores, and the ids\n \"\"\"\n ...\n
Source code in libs/kotaemon/kotaemon/storages/vectorstores/base.py
class LlamaIndexVectorStore(BaseVectorStore):\n \"\"\"Mixin for LlamaIndex based vectorstores\"\"\"\n\n _li_class: type[LIVectorStore | BasePydanticVectorStore] | None\n\n def _get_li_class(self):\n raise NotImplementedError(\n \"Please return the relevant LlamaIndex class in in _get_li_class\"\n )\n\n def __init__(self, *args, **kwargs):\n # get li_class from the method if not set\n if not self._li_class:\n LIClass = self._get_li_class()\n else:\n LIClass = self._li_class\n\n from dataclasses import fields\n\n self._client = LIClass(*args, **kwargs)\n\n self._vsq_kwargs = {_.name for _ in fields(VectorStoreQuery)}\n for key in [\"query_embedding\", \"similarity_top_k\", \"node_ids\"]:\n if key in self._vsq_kwargs:\n self._vsq_kwargs.remove(key)\n\n def __setattr__(self, name: str, value: Any) -> None:\n if name.startswith(\"_\"):\n return super().__setattr__(name, value)\n\n return setattr(self._client, name, value)\n\n def __getattr__(self, name: str) -> Any:\n if name == \"_li_class\":\n return super().__getattribute__(name)\n\n return getattr(self._client, name)\n\n def add(\n self,\n embeddings: list[list[float]] | list[DocumentWithEmbedding],\n metadatas: Optional[list[dict]] = None,\n ids: Optional[list[str]] = None,\n ):\n if isinstance(embeddings[0], list):\n nodes: list[DocumentWithEmbedding] = [\n DocumentWithEmbedding(embedding=embedding) for embedding in embeddings\n ]\n else:\n nodes = embeddings # type: ignore\n if metadatas is not None:\n for node, metadata in zip(nodes, metadatas):\n node.metadata = metadata\n if ids is not None:\n for node, id in zip(nodes, ids):\n node.id_ = id\n node.relationships = {\n NodeRelationship.SOURCE: RelatedNodeInfo(node_id=id)\n }\n\n return self._client.add(nodes=nodes)\n\n def delete(self, ids: list[str], **kwargs):\n for id_ in ids:\n self._client.delete(ref_doc_id=id_, **kwargs)\n\n def query(\n self,\n embedding: list[float],\n top_k: int = 1,\n ids: Optional[list[str]] = None,\n **kwargs,\n ) -> tuple[list[list[float]], list[float], list[str]]:\n \"\"\"Return the top k most similar vector embeddings\n\n Args:\n embedding: List of embeddings\n top_k: Number of most similar embeddings to return\n ids: List of ids of the embeddings to be queried\n kwargs: extra query parameters. Depending on the name, these parameters\n will be used when constructing the VectorStoreQuery object or when\n performing querying of the underlying vector store.\n\n Returns:\n the matched embeddings, the similarity scores, and the ids\n \"\"\"\n vsq_kwargs = {}\n vs_kwargs = {}\n for kwkey, kwvalue in kwargs.items():\n if kwkey in self._vsq_kwargs:\n vsq_kwargs[kwkey] = kwvalue\n else:\n vs_kwargs[kwkey] = kwvalue\n\n output = self._client.query(\n query=VectorStoreQuery(\n query_embedding=embedding,\n similarity_top_k=top_k,\n node_ids=ids,\n **vsq_kwargs,\n ),\n **vs_kwargs,\n )\n\n embeddings = []\n if output.nodes:\n for node in output.nodes:\n embeddings.append(node.embedding)\n similarities = output.similarities if output.similarities else []\n out_ids = output.ids if output.ids else []\n\n return embeddings, similarities, out_ids\n
Name Type Description Default embeddinglist[float]
List of embeddings
required top_kint
Number of most similar embeddings to return
1idsOptional[list[str]]
List of ids of the embeddings to be queried
Nonekwargs
extra query parameters. Depending on the name, these parameters will be used when constructing the VectorStoreQuery object or when performing querying of the underlying vector store.
{}
Returns:
Type Description tuple[list[list[float]], list[float], list[str]]
the matched embeddings, the similarity scores, and the ids
Source code in libs/kotaemon/kotaemon/storages/vectorstores/base.py
def query(\n self,\n embedding: list[float],\n top_k: int = 1,\n ids: Optional[list[str]] = None,\n **kwargs,\n) -> tuple[list[list[float]], list[float], list[str]]:\n \"\"\"Return the top k most similar vector embeddings\n\n Args:\n embedding: List of embeddings\n top_k: Number of most similar embeddings to return\n ids: List of ids of the embeddings to be queried\n kwargs: extra query parameters. Depending on the name, these parameters\n will be used when constructing the VectorStoreQuery object or when\n performing querying of the underlying vector store.\n\n Returns:\n the matched embeddings, the similarity scores, and the ids\n \"\"\"\n vsq_kwargs = {}\n vs_kwargs = {}\n for kwkey, kwvalue in kwargs.items():\n if kwkey in self._vsq_kwargs:\n vsq_kwargs[kwkey] = kwvalue\n else:\n vs_kwargs[kwkey] = kwvalue\n\n output = self._client.query(\n query=VectorStoreQuery(\n query_embedding=embedding,\n similarity_top_k=top_k,\n node_ids=ids,\n **vsq_kwargs,\n ),\n **vs_kwargs,\n )\n\n embeddings = []\n if output.nodes:\n for node in output.nodes:\n embeddings.append(node.embedding)\n similarities = output.similarities if output.similarities else []\n out_ids = output.ids if output.ids else []\n\n return embeddings, similarities, out_ids\n
{} Source code in libs/kotaemon/kotaemon/storages/vectorstores/chroma.py
def delete(self, ids: List[str], **kwargs):\n \"\"\"Delete vector embeddings from vector stores\n\n Args:\n ids: List of ids of the embeddings to be deleted\n kwargs: meant for vectorstore-specific parameters\n \"\"\"\n self._client.client.delete(ids=ids)\n
None Source code in libs/kotaemon/kotaemon/storages/vectorstores/in_memory.py
def save(\n self,\n save_path: str,\n fs: Optional[fsspec.AbstractFileSystem] = None,\n **kwargs,\n):\n\n \"\"\"save a simpleVectorStore to a dictionary.\n\n Args:\n save_path: Path of saving vector to disk.\n fs: An abstract super-class for pythonic file-systems\n \"\"\"\n self._client.persist(persist_path=save_path, fs=fs)\n
{} Source code in libs/kotaemon/kotaemon/storages/vectorstores/lancedb.py
def delete(self, ids: List[str], **kwargs):\n \"\"\"Delete vector embeddings from vector stores\n\n Args:\n ids: List of ids of the embeddings to be deleted\n kwargs: meant for vectorstore-specific parameters\n \"\"\"\n self._client.delete_nodes(ids)\n
{} Source code in libs/kotaemon/kotaemon/storages/vectorstores/qdrant.py
def delete(self, ids: List[str], **kwargs):\n \"\"\"Delete vector embeddings from vector stores\n\n Args:\n ids: List of ids of the embeddings to be deleted\n kwargs: meant for vectorstore-specific parameters\n \"\"\"\n from qdrant_client import models\n\n self._client.client.delete(\n collection_name=self._collection_name,\n points_selector=models.PointIdsList(\n points=ids,\n ),\n **kwargs,\n )\n