Here are major reasons for using ‘Unsupervised Learning Algorithms’:
- Unsupervised Machine Learning Algorithms finds all kinds of unknown patterns in data through pattern recognition.
- It takes place in real-time, so all the input data to be analyzed & labeled in learners’ presence.
- Unsupervised algorithms/methods help you to search for features that can be useful for categorization.
Below are the major types of Unsupervised Learning Algorithms:
Any company or business needs to focus on understanding customers: who they are & what’s driving their buying decisions?
You’ll usually have several groups of users that can be split across a few criteria. These criteria can be as simple: age & gender or as complex as a persona & purchase process. Types of Unsupervised learning Algorithms can help you accomplish this task automatically.
Clustering will run through your data & find these natural clusters if they exist. For your visitors, that might mean one cluster of 30-something artists & another of millennials who own pets. You can generally modify the number of clusters your ML algorithm looks for, which lets you adjust these groups’ granularity. There are many types of clustering you can utilize:
- K-Means Clustering: Clustering your data points or text into a character “K” of mutually exclusive clusters. A lot of the complexity surrounds how you should pick the appropriate number for K.
- Hierarchical Clustering: Clustering your data points into parent & child clusters. You might split your customers between younger & older ages & then split each of those groups into their clusters as well.
- Probabilistic Clustering: Clustering your data points or text into clusters on a probabilistic scale. These variations on the same fundamental procedure might look something like this in code:
Any clustering ML algorithm will typically output all of your data points & the other number of clusters to which they belong. It’s totally up to you to decide what they mean & exactly what the ML algorithm has found. As with much of data science – Unsupervised Learning can only do so much: value is created when humans interface with outputs & create meaning.

Dimensionality reduction (dimensions refers to how many columns are in your dataset) relies on many of the same concepts as Information Theory: it assumes that a lot of data is redundant & that you can represent most of the data in a data set with only a small fraction of the actual content.
In general, this means combining parts of your knowledge in unique ways to convey meaning. There are a couple of famous ML algorithms commonly used to decrease dimensionality:
- Principal Component Analysis (PCA): Finds the linear combinations that communicate most of your data set variance.
- Singular-Value Decomposition (SVD): Factorizes your details into the product of three other, smaller matrices. These techniques and some of their more complex cousins all rely on linear algebra concepts to break down a matrix into more digestible & informatory pieces.
Reducing the dimensionality of your information can be a crucial part of a good ML pipeline. Take this example of an image-centerpiece for the burgeoning discipline of computer vision.
If you could decrease the size of your training set by order of magnitude, that will significantly lower your compute & storage costs while making your ML models run that much faster. That’s why PCA is often run on images during preprocessing in mature ML pipelines.
Generative models are a class of Unsupervised Learning Algorithms in which training data are given & new samples are generated from the same distribution. These ML models must discover & efficiently learn the essence of the given set of data to generate similar data. This type of model’s long-term benefit is its ability to learn the given data’s features automatically.
A basic example of generative models is an image dataset or text. Given a set of basic images, a generative model could generate a set of images similar to the given set.
Representation learning is concerned with training machine learning algorithms to learn useful representations, e.g. those that are interpretable, have latent features, or can be used for transfer learning.
Deep neural networks can be considered representation learning models that typically encode information which is projected into a different subspace. These representations are then usually passed on to a linear classifier to, for instance, train a classifier.
Representation learning can be divided into:
- Supervised representation learning: learning representations on task A using annotated data and used to solve task B
- Unsupervised representation learning: learning representations on a task in an unsupervised way (label-free data). These are then used to address downstream tasks and reducing the need for annotated data when learning news tasks. Powerful models like GPT and BERT leverage unsupervised representation learning to tackle language tasks.
Below is the list of some popular Unsupervised ML Algorithms:
- K-means clustering
- KNN (k-nearest neighbors)
- Hierarchical clustering
- Anomaly detection
- Neural Networks
- Principal Component Analysis
- Independent Component Analysis
- Apriori algorithm
- Singular value decomposition
Some major applications of unsupervised ML algorithms are:
- Clustering automatically devide the dataset into groups based on their similarities.
- Anomaly detection can discover unusual text or data points in your dataset. It is useful for finding fraudulent transactions.
- Association mining identifies sets of items that often occur together in your datapoints/dataset.
- Latent variable models are broadly used for data preprocessing. Like reducing the amount of features in a dataset or decomposing the dataset into multiple components
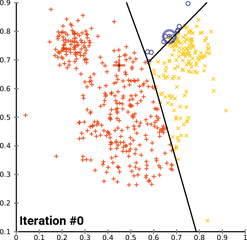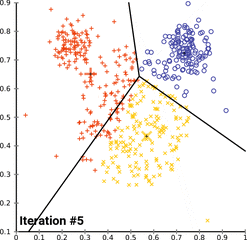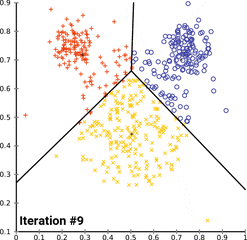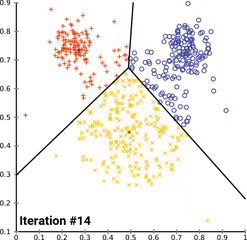
Iterative Process involving following steps :
- Random Data Points
- Cluster Assignment-----------------|______Iteration over step 2 and 3
- Cluster Update(mean/centroid)----|
BERT is an open source machine learning framework for natural language processing (NLP). BERT is designed to help computers understand the meaning of ambiguous language in text by using surrounding text to establish context. The BERT framework was pre-trained using text from Wikipedia and can be fine-tuned with question and answer datasets.
BERT, which stands for Bidirectional Encoder Representations from Transformers, is based on Transformers, a deep learning model in which every output element is connected to every input element, and the weightings between them are dynamically calculated based upon their connection. (In NLP, this process is called attention.)
Historically, language models could only read text input sequentially -- either left-to-right or right-to-left -- but couldn't do both at the same time. BERT is different because it is designed to read in both directions at once. This capability, enabled by the introduction of Transformers, is known as bidirectionality.
Using this bidirectional capability, BERT is pre-trained on two different, but related, NLP tasks: Masked Language Modeling and Next Sentence Prediction.
The objective of Masked Language Model (MLM) training is to hide a word in a sentence and then have the program predict what word has been hidden (masked) based on the hidden word's context. The objective of Next Sentence Prediction training is to have the program predict whether two given sentences have a logical, sequential connection or whether their relationship is simply random.