首先回顾一下在程序设计语言中有关将参数传递给方法(或函数)的一些专业术语。按值调用(call by value)表示方法接收的是调用者提供的值,而按引用调用(call by reference)表示方法接收的是调用者提供的变量地址。一个方法可以修改传递引用所对应的变量值,而不能修改传递值调用所对应的变量值。 它用来描述各种程序设计语言(不只是Java)中方法参数传递方式。
Java程序设计语言总是采用按值调用。也就是说,方法得到的是所有参数值的一个拷贝,也就是说,方法不能修改传递给它的任何参数变量的内容。
下面通过 3 个例子来给大家说明
public static void main(String[] args) {
int num1 = 10;
int num2 = 20;
swap(num1, num2);
System.out.println("num1 = " + num1);
System.out.println("num2 = " + num2);
}
public static void swap(int a, int b) {
int temp = a;
a = b;
b = temp;
System.out.println("a = " + a);
System.out.println("b = " + b);
}结果:
a = 20
b = 10
num1 = 10
num2 = 20
解析:
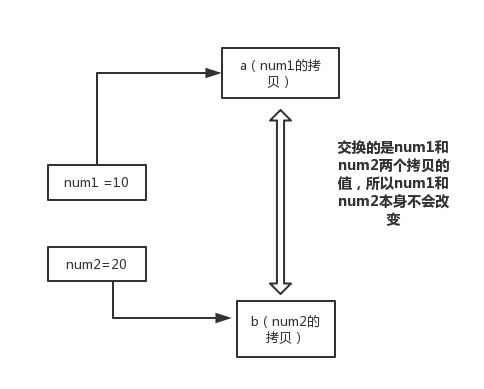
在swap方法中,a、b的值进行交换,并不会影响到 num1、num2。因为,a、b中的值,只是从 num1、num2 的复制过来的。也就是说,a、b相当于num1、num2 的副本,副本的内容无论怎么修改,都不会影响到原件本身。
通过上面例子,我们已经知道了一个方法不能修改一个基本数据类型的参数,而对象引用作为参数就不一样,请看 example2.
public static void main(String[] args) {
int[] arr = { 1, 2, 3, 4, 5 };
System.out.println(arr[0]);
change(arr);
System.out.println(arr[0]);
}
public static void change(int[] array) {
// 将数组的第一个元素变为0
array[0] = 0;
}结果:
1
0
解析:
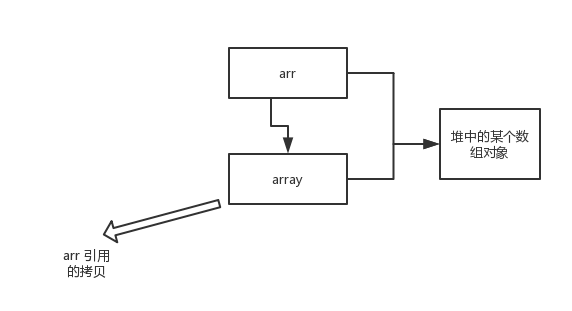
array 被初始化 arr 的拷贝也就是一个对象的引用,也就是说 array 和 arr 指向的时同一个数组对象。 因此,外部对引用对象的改变会反映到所对应的对象上。
通过 example2 我们已经看到,实现一个改变对象参数状态的方法并不是一件难事。理由很简单,方法得到的是对象引用的拷贝,对象引用及其他的拷贝同时引用同一个对象。
很多程序设计语言(特别是,C++和Pascal)提供了两种参数传递的方式:值调用和引用调用。有些程序员(甚至本书的作者)认为Java程序设计语言对对象采用的是引用调用,实际上,这种理解是不对的。由于这种误解具有一定的普遍性,所以下面给出一个反例来详细地阐述一下这个问题。
public class Test {
public static void main(String[] args) {
// TODO Auto-generated method stub
Student s1 = new Student("小张");
Student s2 = new Student("小李");
Test.swap(s1, s2);
System.out.println("s1:" + s1.getName());
System.out.println("s2:" + s2.getName());
}
public static void swap(Student x, Student y) {
Student temp = x;
x = y;
y = temp;
System.out.println("x:" + x.getName());
System.out.println("y:" + y.getName());
}
}结果:
x:小李
y:小张
s1:小张
s2:小李
解析:
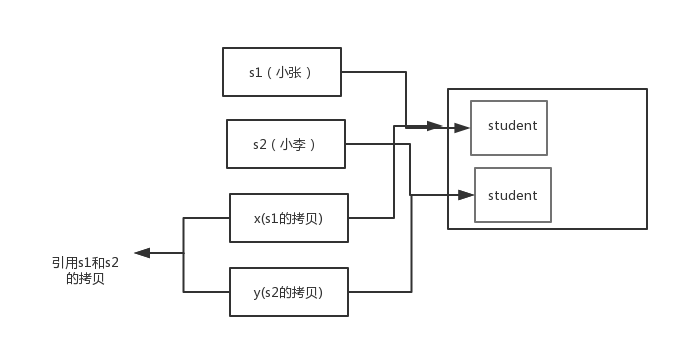
交换之前:
交换之后:
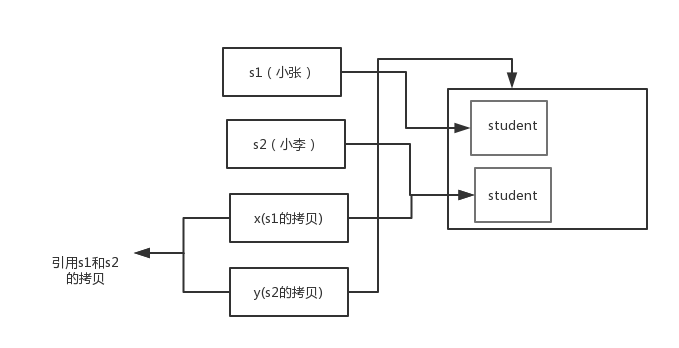
通过上面两张图可以很清晰的看出: 方法并没有改变存储在变量 s1 和 s2 中的对象引用。swap方法的参数x和y被初始化为两个对象引用的拷贝,这个方法交换的是这两个拷贝
Java程序设计语言对对象采用的不是引用调用,实际上,对象引用是按 值传递的。
下面再总结一下Java中方法参数的使用情况:
- 一个方法不能修改一个基本数据类型的参数(即数值型或布尔型》
- 一个方法可以改变一个对象参数的状态。
- 一个方法不能让对象参数引用一个新的对象。
《Java核心技术卷Ⅰ》基础知识第十版第四章4.5小节
== : 它的作用是判断两个对象的地址是不是相等。即,判断两个对象是不是同一个对象。(基本数据类型==比较的是值,引用数据类型==比较的是内存地址)
equals() : 它的作用也是判断两个对象是否相等。但它一般有两种使用情况:
- 情况1:类没有覆盖equals()方法。则通过equals()比较该类的两个对象时,等价于通过“==”比较这两个对象。
- 情况2:类覆盖了equals()方法。一般,我们都覆盖equals()方法来两个对象的内容相等;若它们的内容相等,则返回true(即,认为这两个对象相等)。
举个例子:
public class test1 {
public static void main(String[] args) {
String a = new String("ab"); // a 为一个引用
String b = new String("ab"); // b为另一个引用,对象的内容一样
String aa = "ab"; // 放在常量池中
String bb = "ab"; // 从常量池中查找
if (aa == bb) // true
System.out.println("aa==bb");
if (a == b) // false,非同一对象
System.out.println("a==b");
if (a.equals(b)) // true
System.out.println("aEQb");
if (42 == 42.0) { // true
System.out.println("true");
}
}
}说明:
- String中的equals方法是被重写过的,因为object的equals方法是比较的对象的内存地址,而String的equals方法比较的是对象的值。
- 当创建String类型的对象时,虚拟机会在常量池中查找有没有已经存在的值和要创建的值相同的对象,如果有就把它赋给当前引用。如果没有就在常量池中重新创建一个String对象。
面试官可能会问你:“你重写过 hashcode 和 equals 么,为什么重写equals时必须重写hashCode方法?”
hashCode() 的作用是获取哈希码,也称为散列码;它实际上是返回一个int整数。这个哈希码的作用是确定该对象在哈希表中的索引位置。hashCode() 定义在JDK的Object.java中,这就意味着Java中的任何类都包含有hashCode() 函数。另外需要注意的是: Object 的 hashcode 方法是本地方法,也就是用 c 语言或 c++ 实现的,该方法通常用来将对象的 内存地址 转换为整数之后返回。
/**
* Returns a hash code value for the object. This method is
* supported for the benefit of hash tables such as those provided by
* {@link java.util.HashMap}.
* <p>
* As much as is reasonably practical, the hashCode method defined by
* class {@code Object} does return distinct integers for distinct
* objects. (This is typically implemented by converting the internal
* address of the object into an integer, but this implementation
* technique is not required by the
* Java™ programming language.)
*
* @return a hash code value for this object.
* @see java.lang.Object#equals(java.lang.Object)
* @see java.lang.System#identityHashCode
*/
public native int hashCode();散列表存储的是键值对(key-value),它的特点是:能根据“键”快速的检索出对应的“值”。这其中就利用到了散列码!(可以快速找到所需要的对象)
我们以“HashSet如何检查重复”为例子来说明为什么要有hashCode:
当你把对象加入HashSet时,HashSet会先计算对象的hashcode值来判断对象加入的位置,同时也会与其他已经加入的对象的hashcode值作比较,如果没有相符的hashcode,HashSet会假设对象没有重复出现。但是如果发现有相同hashcode值的对象,这时会调用equals()方法来检查hashcode相等的对象是否真的相同。如果两者相同,HashSet就不会让其加入操作成功。如果不同的话,就会重新散列到其他位置。(摘自我的Java启蒙书《Head fist java》第二版)。这样我们就大大减少了equals的次数,相应就大大提高了执行速度。
- 如果两个对象相等,则hashcode一定也是相同的
- 两个对象相等,对两个对象分别调用equals方法都返回true
- 两个对象有相同的hashcode值,它们也不一定是相等的
- 因此,equals方法被覆盖过,则hashCode方法也必须被覆盖
- hashCode()的默认行为是对堆上的对象产生独特值。如果没有重写hashCode(),则该class的两个对象无论如何都不会相等(即使这两个对象指向相同的数据)
在这里解释一位小伙伴的问题。以下内容摘自《Head Fisrt Java》。
因为hashCode() 所使用的杂凑算法也许刚好会让多个对象传回相同的杂凑值。越糟糕的杂凑算法越容易碰撞,但这也与数据值域分布的特性有关(所谓碰撞也就是指的是不同的对象得到相同的 hashCode)。
我们刚刚也提到了 HashSet,如果 HashSet 在对比的时候,同样的 hashcode 有多个对象,它会使用 equals() 来判断是否真的相同。也就是说 hashcode 只是用来缩小查找成本。
参考:
https://blog.csdn.net/zhzhao999/article/details/53449504
https://www.cnblogs.com/skywang12345/p/3324958.html