

Spring’s journey on Data Integration started with Spring Integration. With its programming model, it provided a consistent developer experience to build applications that can embrace Enterprise Integration Patterns to connect with external systems such as, databases, message brokers, and among others.
Fast forward to the cloud-era, where microservices have become prominent in the enterprise setting. Spring Boot transformed the way how developers built Applications. With Spring’s programming model and the runtime responsibilities handled by Spring Boot, it became seamless to develop stand-alone, production-grade Spring-based microservices.
To extend this to Data Integration workloads, Spring Integration and Spring Boot were put together into a new project. Spring Cloud Stream was born.
With Spring Cloud Stream, developers can:
-
Build, test and deploy data-centric applications in isolation.
-
Apply modern microservices architecture patterns, including composition through messaging.
-
Decouple application responsibilities with event-centric thinking. An event can represent something that has happened in time, to which the downstream consumer applications can react without knowing where it originated or the producer’s identity.
-
Port the business logic onto message brokers (such as RabbitMQ, Apache Kafka, Amazon Kinesis).
-
Rely on the framework’s automatic content-type support for common use-cases. Extending to different data conversion types is possible.
-
and many more. . .
You can try Spring Cloud Stream in less then 5 min even before you jump into any details by following this three-step guide.
We show you how to create a Spring Cloud Stream application that receives messages coming from the messaging middleware of your choice (more on this later) and logs received messages to the console.
We call it LoggingConsumer.
While not very practical, it provides a good introduction to some of the main concepts
and abstractions, making it easier to digest the rest of this user guide.
The three steps are as follows:
To get started, visit the Spring Initializr. From there, you can generate our LoggingConsumer application. To do so:
-
In the Dependencies section, start typing
stream. When the “Cloud Stream” option should appears, select it. -
Start typing either 'kafka' or 'rabbit'.
-
Select “Kafka” or “RabbitMQ”.
Basically, you choose the messaging middleware to which your application binds. We recommend using the one you have already installed or feel more comfortable with installing and running. Also, as you can see from the Initilaizer screen, there are a few other options you can choose. For example, you can choose Gradle as your build tool instead of Maven (the default).
-
In the Artifact field, type 'logging-consumer'.
The value of the Artifact field becomes the application name. If you chose RabbitMQ for the middleware, your Spring Initializr should now be as follows:
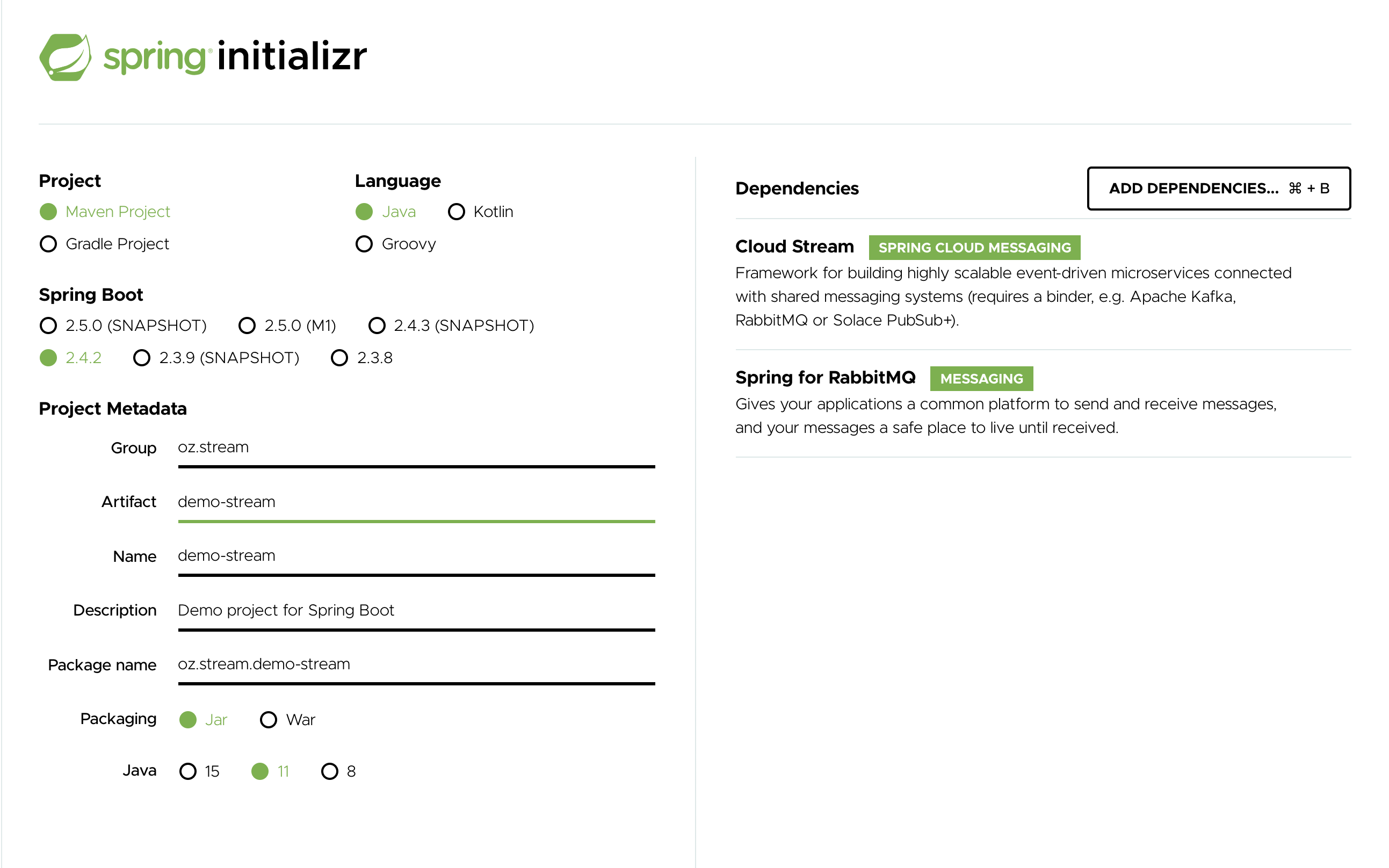
-
Click the Generate Project button.
Doing so downloads the zipped version of the generated project to your hard drive.
-
Unzip the file into the folder you want to use as your project directory.
|
Tip
|
We encourage you to explore the many possibilities available in the Spring Initializr. It lets you create many different kinds of Spring applications. |
Now you can import the project into your IDE. Keep in mind that, depending on the IDE, you may need to follow a specific import procedure. For example, depending on how the project was generated (Maven or Gradle), you may need to follow specific import procedure (for example, in Eclipse or STS, you need to use File → Import → Maven → Existing Maven Project).
Once imported, the project must have no errors of any kind. Also, src/main/java should contain com.example.loggingconsumer.LoggingConsumerApplication.
Technically, at this point, you can run the application’s main class. It is already a valid Spring Boot application. However, it does not do anything, so we want to add some code.
Modify the com.example.loggingconsumer.LoggingConsumerApplication class to look as follows:
@SpringBootApplication
public class LoggingConsumerApplication {
public static void main(String[] args) {
SpringApplication.run(LoggingConsumerApplication.class, args);
}
@Bean
public Consumer<Person> log() {
return person -> {
System.out.println("Received: " + person);
};
}
public static class Person {
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String toString() {
return this.name;
}
}
}As you can see from the preceding listing:
-
We are using functional programming model (see [Spring Cloud Function support]) to define a single message handler as
Consumer. -
We are relying on framework conventions to bind such handler to the input destination binding exposed by the binder.
Doing so also lets you see one of the core features of the framework: It tries to automatically convert incoming message payloads to type Person.
You now have a fully functional Spring Cloud Stream application that does listens for messages.
From here, for simplicity, we assume you selected RabbitMQ in step one.
Assuming you have RabbitMQ installed and running, you can start the application by running its main method in your IDE.
You should see following output:
--- [ main] c.s.b.r.p.RabbitExchangeQueueProvisioner : declaring queue for inbound: input.anonymous.CbMIwdkJSBO1ZoPDOtHtCg, bound to: input
--- [ main] o.s.a.r.c.CachingConnectionFactory : Attempting to connect to: [localhost:5672]
--- [ main] o.s.a.r.c.CachingConnectionFactory : Created new connection: rabbitConnectionFactory#2a3a299:0/SimpleConnection@66c83fc8. . .
. . .
--- [ main] o.s.i.a.i.AmqpInboundChannelAdapter : started inbound.input.anonymous.CbMIwdkJSBO1ZoPDOtHtCg
. . .
--- [ main] c.e.l.LoggingConsumerApplication : Started LoggingConsumerApplication in 2.531 seconds (JVM running for 2.897)Go to the RabbitMQ management console or any other RabbitMQ client and send a message to input.anonymous.CbMIwdkJSBO1ZoPDOtHtCg.
The anonymous.CbMIwdkJSBO1ZoPDOtHtCg part represents the group name and is generated, so it is bound to be different in your environment.
For something more predictable, you can use an explicit group name by setting spring.cloud.stream.bindings.input.group=hello (or whatever name you like).
The contents of the message should be a JSON representation of the Person class, as follows:
{"name":"Sam Spade"}
Then, in your console, you should see:
Received: Sam Spade
You can also build and package your application into a boot jar (by using ./mvnw clean install) and run the built JAR by using the java -jar command.
Now you have a working (albeit very basic) Spring Cloud Stream application.
-
Routing Function - see [Routing with functions] for more details.
-
Multiple bindings with functions (multiple message handlers) - see [Multiple functions in a single application] for more details.
-
Functions with multiple inputs/outputs (single function that can subscribe or target multiple destinations) - see [Functions with multiple input and output arguments] for more details.
-
Native support for reactive programming - since v3.0.0 we no longer distribute spring-cloud-stream-reactive modules and instead relying on native reactive support provided by spring cloud function. For backward compatibility you can still bring
spring-cloud-stream-reactivefrom previous versions.
-
Reactive module (
spring-cloud-stream-reactive) is discontinued and no longer distributed in favor of native support via spring-cloud-function. For backward compatibility you can still bringspring-cloud-stream-reactivefrom previous versions. -
Test support binder
spring-cloud-stream-test-supportwith MessageCollector in favor of a new test binder. See [Testing] for more details. -
@StreamMessageConverter - deprecated as it is no longer required.
-
The
original-content-typeheader references have been removed after it’s been deprecated in v2.0. -
The
BinderAwareChannelResolveris deprecated in favor if providingspring.cloud.stream.sendto.destinationproperty. This is primarily for function-based programming model. For StreamListener it would still be required and thus will stay until we deprecate and eventually discontinue StreamListener and annotation-based programming model.
To build the source you will need to install JDK 1.8.
The build uses the Maven wrapper so you don’t have to install a specific version of Maven. To enable the tests for Redis, Rabbit, and Kafka bindings you should have those servers running before building. See below for more information on running the servers.
The main build command is
$ ./mvnw clean install
You can also add '-DskipTests' if you like, to avoid running the tests.
|
Note
|
You can also install Maven (>=3.3.3) yourself and run the mvn command
in place of ./mvnw in the examples below. If you do that you also
might need to add -P spring if your local Maven settings do not
contain repository declarations for spring pre-release artifacts.
|
|
Note
|
Be aware that you might need to increase the amount of memory
available to Maven by setting a MAVEN_OPTS environment variable with
a value like -Xmx512m -XX:MaxPermSize=128m. We try to cover this in
the .mvn configuration, so if you find you have to do it to make a
build succeed, please raise a ticket to get the settings added to
source control.
|
The projects that require middleware generally include a
docker-compose.yml, so consider using
Docker Compose to run the middeware servers
in Docker containers. See the README in the
scripts demo
repository for specific instructions about the common cases of mongo,
rabbit and redis.
If you don’t have an IDE preference we would recommend that you use Spring Tools Suite or Eclipse when working with the code. We use the m2eclipe eclipse plugin for maven support. Other IDEs and tools should also work without issue.
We recommend the m2eclipe eclipse plugin when working with eclipse. If you don’t already have m2eclipse installed it is available from the "eclipse marketplace".
Unfortunately m2e does not yet support Maven 3.3, so once the projects
are imported into Eclipse you will also need to tell m2eclipse to use
the .settings.xml file for the projects. If you do not do this you
may see many different errors related to the POMs in the
projects. Open your Eclipse preferences, expand the Maven
preferences, and select User Settings. In the User Settings field
click Browse and navigate to the Spring Cloud project you imported
selecting the .settings.xml file in that project. Click Apply and
then OK to save the preference changes.
|
Note
|
Alternatively you can copy the repository settings from .settings.xml into your own ~/.m2/settings.xml.
|
Spring Cloud is released under the non-restrictive Apache 2.0 license, and follows a very standard Github development process, using Github tracker for issues and merging pull requests into master. If you want to contribute even something trivial please do not hesitate, but follow the guidelines below.
Before we accept a non-trivial patch or pull request we will need you to sign the contributor’s agreement. Signing the contributor’s agreement does not grant anyone commit rights to the main repository, but it does mean that we can accept your contributions, and you will get an author credit if we do. Active contributors might be asked to join the core team, and given the ability to merge pull requests.
None of these is essential for a pull request, but they will all help. They can also be added after the original pull request but before a merge.
-
Use the Spring Framework code format conventions. If you use Eclipse you can import formatter settings using the
eclipse-code-formatter.xmlfile from the Spring Cloud Build project. If using IntelliJ, you can use the Eclipse Code Formatter Plugin to import the same file. -
Make sure all new
.javafiles to have a simple Javadoc class comment with at least an@authortag identifying you, and preferably at least a paragraph on what the class is for. -
Add the ASF license header comment to all new
.javafiles (copy from existing files in the project) -
Add yourself as an
@authorto the .java files that you modify substantially (more than cosmetic changes). -
Add some Javadocs and, if you change the namespace, some XSD doc elements.
-
A few unit tests would help a lot as well — someone has to do it.
-
If no-one else is using your branch, please rebase it against the current master (or other target branch in the main project).
-
When writing a commit message please follow these conventions, if you are fixing an existing issue please add
Fixes gh-XXXXat the end of the commit message (where XXXX is the issue number).