An HPC cluster is a collection of separate servers (computers), called nodes, which are connected via a fast interconnect. All cluster nodes have the same components as a laptop or desktop: CPU cores, memory, and networking. The difference between personal computer and a cluster node is in quantity, quality and power of the components.
An HPC cluster typically contains three primary components. (1) A head node (or login node), where users log-in to the cluster often with SSH. (2) Compute nodes, where a majority of computations are run. These computations can be run both across CPU cores or GPUs. And finally, (3) storage nodes, which contain many drives (SSDs, HDDs, and sometimes tape) and provide shared storage across all other nodes in the cluster.
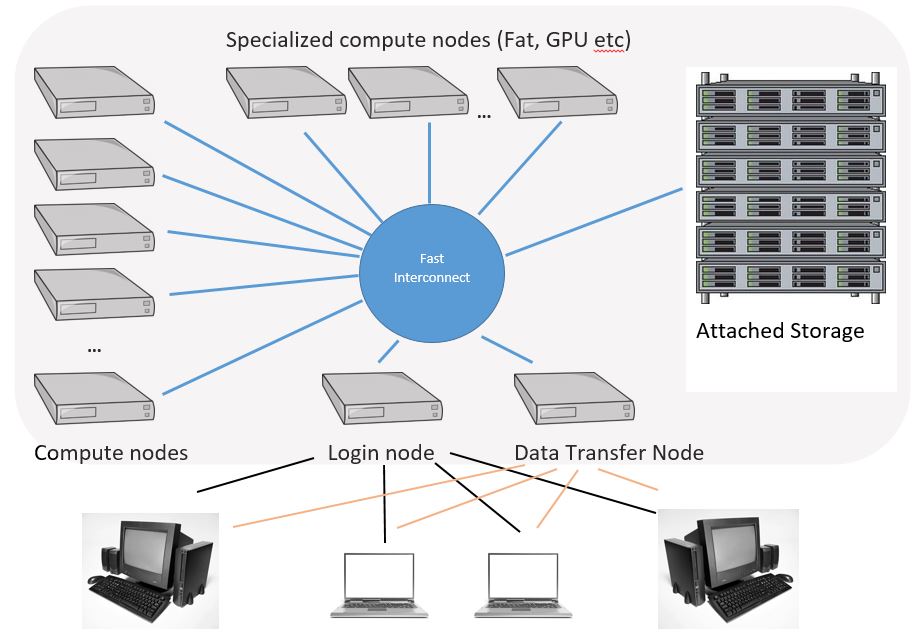

The login nodes of clusters are the portal to the outside world. Users connect to these nodes mostly using SSH (Secure Shell), which is a common method for secure remote login from one computer to another. When connecting to the cluster, you initially interact with these login nodes. The nodes handle many concurrent users, typically between 50 and 100. It's crucial that these nodes are quick and responsive to ensure that users do not spend excessive time waiting for simple commands to execute.
Compute notes are the processing component of an HPC cluster. They execute the workload using local resources, like CPU, GPU, FPGA and other processing units. These workloads also use other resources on the compute node for processing, such as the memory, storage and network adapter.
Data of HPC cluster Examples:
- Cedar: The system has a total of 1350 Nvidia GPU cards available as accelerator capability.
- Graham: The system has a total of 520 Nvidia GPU cards available as accelerator capability. Roughly one fourth of the GPU cards are the latest generation Turing T4 cards that are designed for deep learning workloads.
- Niagara: The system used to have no GPU accelerator capability, but thanks to the recent expansion funding it currently has 64 GPUs.
- Béluga: The system has a total of approximately 688 Nvidia GPU cards available as accelerator capability.
Data of HPC cluster Examples:
- Cedar: It has nearly 95 000 Intel CPU cores, spanning over 2470 nodes with available memory per node ranging from 125 GB to 3 TB (i.e., from 4 GB to 90 GB per core).
- Graham: It has nearly 42 000 Intel CPU cores, spanning over 1185 nodes with available memory per node ranging from 124 GB to 3 TB (i.e., from 4 GB to 50 GB per core).
- Niagara: It has nearly 81 000 Intel CPU cores, spanning over 2016 nodes with available memory per node fixed at 200 GB (i.e. 5 GB per core).
- Béluga: It has nearly 35 000 Intel CPU cores, spanning over 872 nodes with available memory per node ranging from 90 GB to 750 GB (i.e., from 2 GB to roughly 20 GB per core).
A storage server is dedicated to storing and managing large amounts of data across many hard drives.
The storage infrastructure of Compute Canada is designed to handle large volumes of research data efficiently. The storage servers are equipped with high-capacity disks and advanced technologies to ensure data reliability, performance, and scalability. These servers are interconnected with the compute nodes through a high-speed network, ensuring seamless data access and transfer. The storage system supports multiple tiers of storage, each optimized for different types of data and access patterns. This tiered storage approach allows users to choose the most appropriate storage medium for their specific needs, and balance performance and cost.
Communication between the storage servers and compute nodes is facilitated by a high-speed network, typically using protocols like InfiniBand or Ethernet. This network infrastructure ensures low-latency and high-throughput data transfers, which are crucial for large-scale computational tasks. The network design also incorporates redundancy to prevent data loss and ensure continuous operation.
Data of HPC cluster Examples:
- Cedar: The communication backend is a high-speed low-latency 100 Gbit/s Intel Omni-Path fabric.
- Graham: The communication backend is high-speed low-latency 56 Gbit/s (100 Gbit/s) Mellanox FDR (EDR) InfiniBand fabric.
- Niagara: The communication backend is a high-speed low-latency 100 Gbit/s Mellanox EDR InfiniBand fabric leveraging leading edge Dragonfly+ topology.
- Béluga: The communication backend is a high-speed low-latency 100 Gbit/s Mellanox EDR InfiniBand fabric.
Lustre file system, known for its high performance in large-scale, complex computing environments; manages data distribution and access efficiently across multiple storage nodes. Stripe is a key of Lustre file system. For each file or directory, it is possible change the stripe size and stripe count parameters. Stripe size is the size of the smallest block of data that is allocated on the filesystem. Stripe count is the number of disks on which the data are spread.
The tiering model for compute canada servers:
- Tier-0: node-local storage on fast SSDs.
- Tier-1: shared project and home storage on a specific cluster (e.g. Cedar) which is split over SSDs and HDDs.
- Tier-2: storage across DRAC clusters accessed via globus over a dedicated Canada-wide network infrastructure for scientific HPC.
- Tier-3: users' personal devices.
- Graham: The tiered storage system ranges from small persistent ‘home’ (at over 130 TB total capacity), and persistent ‘project’ (at 16000TB), to high-speed non-persistent ‘scratch’ (at 3600 TB).
- Cedar: The tiered storage system ranges from small persistent ‘home’ (at over 500 TB total capacity), and persistent ‘project’ (at 23 000 TB), to high-speed non-persistent ‘scratch’ (at 5400 TB).
- Niagara: The tiered storage system ranges from small persistent ‘home’ (at 200 TB total capacity), and persistent ‘project’ (at 2000 TB), to high-speed nonpersistent ‘scratch’ (at 7000 TB), and very-high speed non-persistent ‘burst’ (at 230 TB).
- Béluga: The tiered storage system ranges from small persistent ‘home’ (at over 100 TB total capacity), and persistent ‘project’ (at 25000 TB), to high-speed non-persistent ‘scratch’ (at 2600 TB).
A typical backup strategy includes differential daily backups, which capture only the changes made since the last full backup, rather than copying all files anew. Additionally, complete backups are typically conducted at a slower pace---such as monthly---and involve copying all data as it exists at that time, ensuring that a complete snapshot of data is available for recovery.