编者按:本文作者是来自 360 奇舞团的前端开发工程师刘宇晨,同时也是 W3C 性能工作组成员。
上一回,笔者介绍了 Navigation Timing 和 Resource Timing 在监控页面加载上的实际应用。
这一回,笔者将带领大家学习 Performance Timeline + User Timing 标准,并将使用相应的 API,给前端代码“跑个分”。
真实业务中,时而会出现比较消耗性能的操作,特别是频繁操作 DOM 的行为。那么如何量化这些操作的性能表现呢?
常见的做法,就是通过分别记录函数执行前和执行之后的 Date.now(),然后求差,得出具体的执行时间。
记录一两个函数还好,多了的话,还需要开发者维护一个全局的 hash ,用来统计全部数据。
随着 Performance Timeline + User Timing 标准的推出,开发者可以直接使用相应的 API,浏览器便会直接统计相关信息,从而显著简化了衡量前端性能的流程。
根据 W3C 的定义,Performance Timeline 旨在帮助 Web 开发者在 Web 应用的整个生命周期中访问、检测、获取各类性能指标,并定义相关接口。
User Timing 相较于 Performance Timeline 而言,更为细节。该标准拓展了原有的 Performance 接口,并添加了供前端开发者主动记录性能指标的新方法。
截至到 2018 年 7 月 29 日,Performance Timeline 和 User Timing 的最新标准均为 Level 2,且均处于编辑草稿状态。
图为 Performance Timeline Level 2 中 PerformanceObserver API 的支持情况:
Performance Timeline Level 2在实际应用时,主要使用PerformanceObserverAPI。
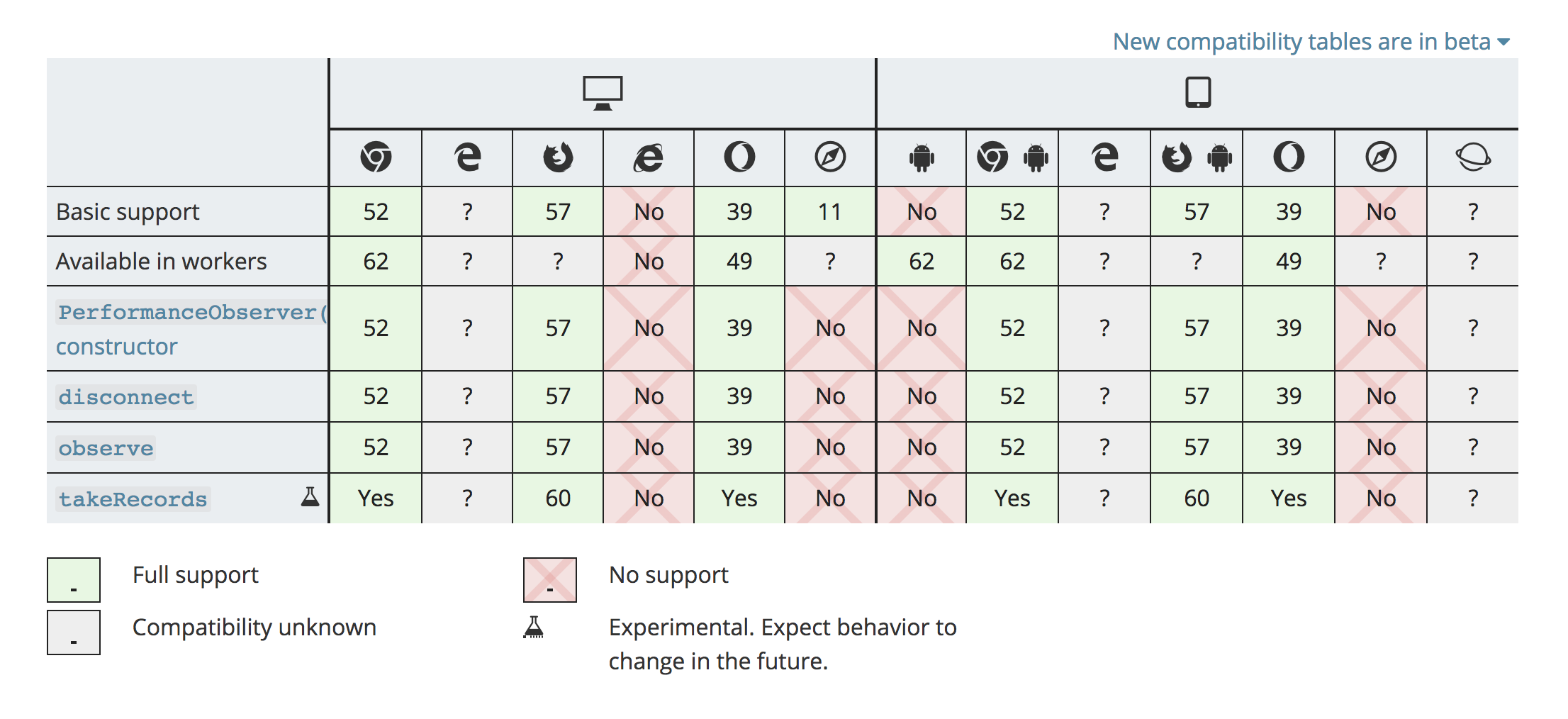
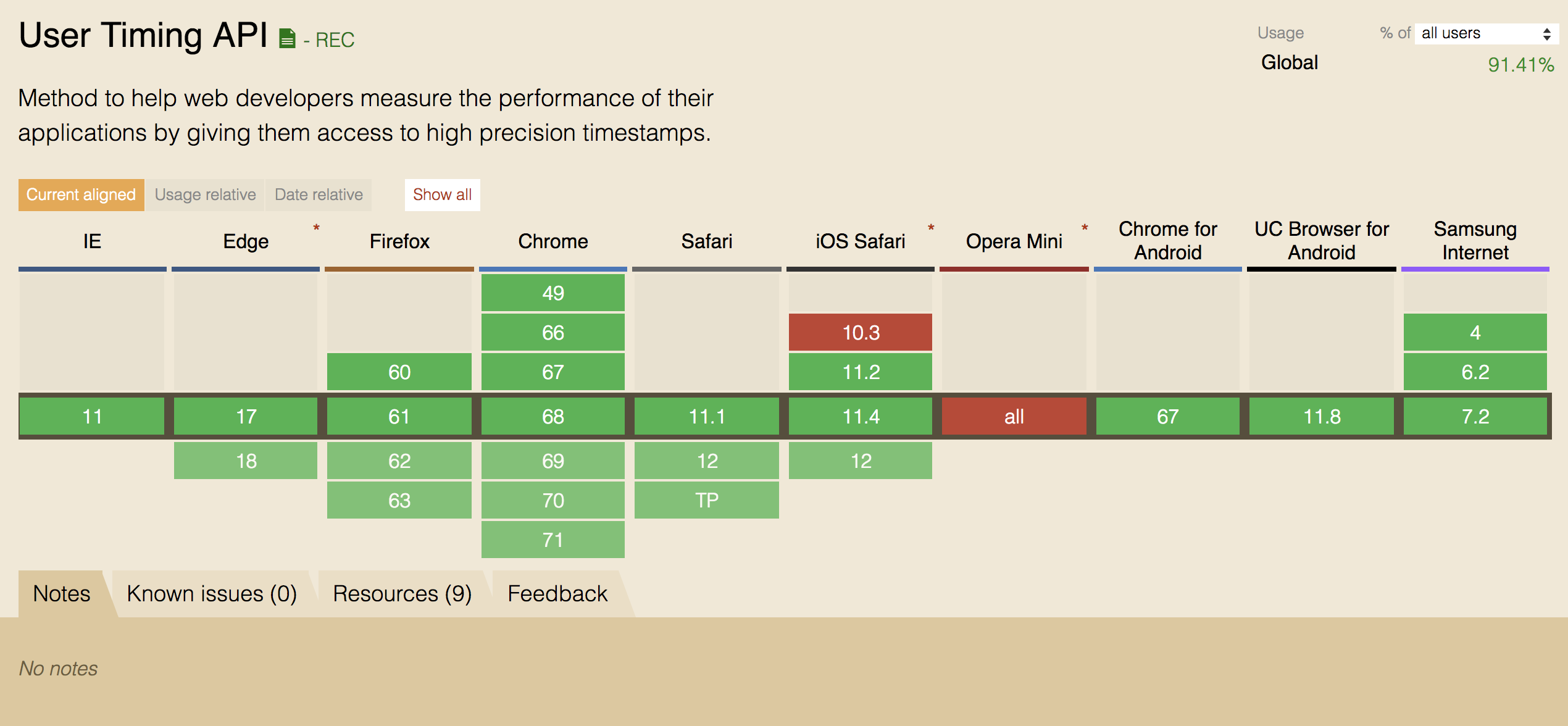
图为 User Timing 的支持情况:
假如你有一段比较耗性能的函数 foo,你好奇在不同浏览器中,执行 foo 所需的时间分别是多少,那么你可以这么做:
const prefix = fix => input => `${fix}${input}`
const prefixStart = prefix('start')
const prefixEnd = prefix('end')
const measure = (fn, name = fn.name) => {
performance.mark(prefixStart(name))
fn()
performance.mark(prefixEnd(name))
}上述代码中,使用了一个新的 API :performance.mark 。
根据标准,调用 performance.mark(markName) 时,发生了如下几步:
- 创建一个新的
PerformanceMark对象(以下称为条目); - 将
name属性设置为markName; - 将
entryType属性设置为'mark'; - 将
startTime属性设置为performance.now()的值; - 将
duration属性设置为0; - 将条目放入队列中;
- 将条目加入到
performance entry buffer中; - 返回
undefined
关于“放入队列”的含义,请参见 https://w3c.github.io/performance-timeline/ [1] 中 Queue a
PerformanceEntry
上述过程,可以简单理解为,“请浏览器记录一条名为 markName 的性能记录”。
之后,我们可以通过 performance.getEntriesByType 获取具体数据:
const getMarks = key => {
return performance
.getEntriesByType('mark') // 只获取通过 performance.mark 记录的数据
.filter(({ name }) => name === prefixStart(key) || name === prefixEnd(key))
}
const getDuration = entries => {
const { start = 0, end = 0 } = entries.reduce((last, { name, startTime }) => {
if (/^start/.test(name)) {
last.start = startTime
} else if (/^end/.test(name)) {
last.end = startTime
}
return last
})
return end - start
}
const retrieveResult = key => getDuration(getMarks(key))performance.getEntriesByType('mark') 就是指明获取由 mark 产生的数据。
“获取个数据,怎么代码还要一大坨?尤其是
getDuration中,区分开始、结束时间的部分,太琐碎吧!?“
W3C 性能小组早就料到有人会抱怨,于是进一步设计了 performance.measure 方法~
performance.measure 方法接收三个参数,依次是 measureName,startMark 以及 endMark。
startMark 和 endMark 很容易理解,就是对应开始和结束时的 markName。measureName 则是为每一个 measure 行为,提供一个标识。
调用后,performance.measure 会根据 startMark 和 endMark 对应的两条记录(均由 performance.mark 产生),形成一条 entryType 为 'measure' 的新记录,并自动计算运行时长。
幕后发生的具体步骤,和 performance.mark 很类似,有兴趣的读者可以参考规范中的 3.1.3 小节 https://www.w3.org/TR/user-timing-2/ [2]。
使用 performance.measure 重构一下前的代码:
const measure = (fn, name = fn.name) => {
const startName = prefixStart(name)
const endName = prefixEnd(name)
performance.mark(startName)
fn()
performance.mark(endName)
// 调用 measure
performance.measure(name, startName, endName)
}
const getDuration = entries => {
// 直接获取 duration
const [{ duration }] = entries
return duration
}
const retrieveResult = key => getDuration(performance.getEntriesByName(key))
// 使用时
function foo() {
// some code
}
measure(foo)
const duration = retrieveResult('foo')
console.log('duration of foo is:', duration)如何?是不是更清晰、简练了~
这里,我们直接通过
performance.getEntriesByName(measureName)的形式,获取由measure产生的数据。
异步函数?async await 来一套:
const asyncMeasure = async (fn, name = fn.name) => {
const startName = prefixStart(name)
const endName = prefixEnd(name)
performance.mark(startName)
await fn()
performance.mark(endName)
// 调用 measure
performance.measure(name, startName, endName)
}| API | 作用 | 不足 |
|---|---|---|
performance.mark |
进行某个操作时,记录一个时间戳 | 对于一个操作,需要两个时间戳才能衡量性能表现 |
performance.measure |
针对起始 + 结束的 mark 值,汇总形成一个直接可用的性能数据 |
想要测量多个操作时,需要重复调用 |
以上相关 API,全部来自于 User Timing Level 2 。当加入 Performance Timeline 后,我们可以进一步优化代码结构~
如上文所述,每次想看性能表现,似乎都要主动调用一次 retrieveResult 函数。一两次还好,次数多了,无疑增加了重复代码,违反了 DRY 的原则。
在 Performance Timeline Level 2 中,工作组添加了新的 PerformanceObserver 接口,旨在解决以下三个问题:
- 每次查看数据时,都要主动调用接口;
- 当获取不同类型的数据指标时,产生重复逻辑;
- 其他资源需要同时操作
performance buffer时,产生资源竞争情况。
对于前端工程师而言,实际使用时只是换了一套 API 。
依旧是测量某操作的性能表现,在支持 Performance Timeline Level 2 的浏览器中,可以这么写:
const observer = new PerformanceObserver(list =>
list.getEntries().map(({ name, startTime }) => {
// 如何利用数据的逻辑
console.log(name, startTime)
return startTime
})
)
observer.observe({
entryTypes: ['mark'],
buffered: true
})聪慧的你应该发现了一些变化:
- 使用了
getEntries而不是getEntriesByType; - 调用
observe方法时,设置了entryTypes和buffer
因为在调用 observe 方法时设置了想要观察的 entryTypes,所以不需要再调用 getEntriesByType。
buffered 字段的含义是,是否向 observer 的 buffer 中添加该条目(的 buffer),默认值是 false。
关于为什么会有
buffered的设置,有兴趣的读者可以参考 w3c/performance-timeline#76 [3]
回过头来看一看 PerformanceObserver。
实例化时,接收一个参数,名为 PerformanceObserverCallback,顾名思义是一个回调函数。
该函数有两个参数,分别是 PerformanceObserverEntryList 和 PerformanceObserver。前者就是我们关心的性能数据的集合。实际上我们已经见过了好几次,例如 performance.getEntriesByType('navigation') 就会返回这种数据类型;后者则是实例化对象,可以理解为函数提供了一个 this 值。
所有跟数据有关的具体操作,如上报、打印等,均可以在 PerformanceObserverCallback 中进行。
实例化后,返回一个 observer 对象。该对象具备两个关键方法,分别是 observe 和 disconnect。
observe用于告诉浏览器,“我想观察这几类性能数据”;disconnect用于断开观察,清空buffer。
为什么会有
disconnect方法?略具讽刺的一个事实是,长时间持续观察性能数据,是一个比较消耗性能的行为。因此,最好在“合适”的时间,停止观察,清空对应buffer,释放性能。
使用 PerformanceObserver + performance.measure 对之前代码进行重构:
// 在 measure.js 中
const getMeasure = () => {
const observer = new PerformanceObserver(list => {
list.getEntries().forEach(({ name, duration }) => {
console.log(name, duration)
// 操作数据的逻辑
})
})
// 只需要关注 measure 的数据
observer.observe({
entryTypes: ['measure'],
buffered: true
})
return observer
}
// 项目入口文件的顶部
let observer
if (window.PerformanceObserver) {
observer = getMeasure()
}
// 某一个合适的时间 不再需要监控性能了
if (observer) {
observer.disconnect()
}如此一来,获取性能数据的操作实现了 DRY 。
假如屏幕前的你已经摩拳擦掌,跃跃欲试,且先缓一缓,看看以下几点注意事项:
- 两个标准提供的性能监测能力,不仅仅局限于前端代码,对于哪些比较复杂的异步接口,也可以通过
async+await的形式监测“接口性能”(这里强调的是用户感知的性能,因为接口表现会显著受到网络环境、缓存使用、代理服务器等等的影响); - 如果要上报数据,需要思考,相关代码是否需要全量推送?更好的方式可能是:(基于
User Agent的)灰度; - 不要是个函数就
measure一下。应当重点关注可能出现性能瓶颈的场景。且只有真正发生瓶颈时,再尝试数据上报; - 本文目的,并非想要替代各个 benchmark 库。实际上,基础的性能测试还是应当由 benchmark 库完成。本文的关注点,更多在于“监控”,即用户体验,发现真实发生的性能瓶颈场景。
Performance Timeline + User Timing 为前端开发者提供了衡量代码性能的利器。如果遇到的项目是“性能敏感”型,那么尽早开始尝试吧~
高峰、黄小璐、刘博文与李松峰等人对文章结构、细节提出了宝贵的修订意见,排名分先后(时间顺序),特此鸣谢。